Ce cours traite des différents moyens d’échanger des données en JavaScript. Plusieurs techniques sont expliquées comme le fameux concept d'AJAX et d’autres techniques parfois plus spécifiques et permettant d’échanger des données.
Pour suivre ce cours, il faut juste avoir une base en JavaScript et en HTML et CSS. Des connaissances en XML ou éventuellement en JSON peuvent être un plus, mais c’est un peu moins important, même si la récupération de données au format XML est l’utilisation principale d'AJAX. Les exemples de scripts côté serveur seront codés en PHP, donc une connaissance basique du PHP est également importante ;) .
AJAX est l'acronyme d'Asynchronous JavaScript And XML, autrement dit JavaScript Et XML Asynchrones.
AJAX n'est ni une technologie ni un langage de programmation ; AJAX est un concept de programmation Web reposant sur plusieurs technologies comme le JavaScript et le XML – d'où le nom AJAX. A l'heure actuelle, le XML tend à être délaissé au profit du JSON, ce qui explique que certains puristes utilisent l'acronyme AJAJ – dont la prononciation laisse plutôt à désirer.
L'idée même d'AJAX est de faire communiquer une page Web avec un serveur Web sans occasionner le rechargement de la page. C'est la raison pour laquelle JavaScript est utilisé, car c'est lui qui va se charger d'établir la connexion entre la page Web et le serveur.
Contrairement à ce qui est souvent dit, le principe de fonctionnement d'AJAX a toujours existé, et ce par le biais de certaines astuces JavaScript, comme l'ajout d'un élément <script /> après le chargement de la page. Mais il a fallu attendre l'arrivée de l'objet XMLHttpRequest pour que l'utilisation de l'AJAX se démocratise. L'objet XMLHttpRequest est un objet natif JavaScript, développé à l'origine en tant qu'ActiveX dans Internet Explorer, qui facilite grandement la communication JavaScript – Serveur.
Afin de bien introduire le principe de l'AJAX, voici une comparaison du fonctionnement d'un site Web dit traditionnel et d'une application Web mettant en œuvre AJAX.
Différencions tout d'abord deux côtés applicatifs : le navigateur, à gauche, et le serveur, à droite. A ce petit schéma on va ajouter un pendule qui balance entre les deux côtés.
Site Web traditionnel
Tout d'abord le navigateur envoie une requête – via une URL – au serveur. Le serveur répond en renvoyant au navigateur le code HTML de la page ainsi que tout ce qui lui est associé comme les scripts JavaScript, les images ou les éventuels médias et autres objets embarqués – donc la réponse du serveur est beaucoup plus volumineuse que la requête. Le navigateur affiche la page et l'utilisateur peut la parcourir quelques instants avant de cliquer sur un lien hypertexte qui enverra une nouvelle requête au serveur qui lui-même renverra le HTML correspondant... et ainsi de suite.
D'un point de vue purement pratique, c'est assez aberrant comme principe car c'est extrêmement inefficace et couteux puisque le serveur va à chaque fois renvoyer tout, ce qui prend du temps et ce qui occasionne une charge pour le serveur.
Ce principe de fonctionnement montre que le navigateur n'intervient pas dans le processus si ce n'est que pour afficher la page. Le gros du travail se fait du côté du serveur. Le pendule balance donc du côté du serveur.
Application AJAX
Voyons ce même schéma du point de vue d'AJAX. Quand on utilise le concept d'AJAX dans une page Web, on parle d'application Web (ou application AJAX).
La première requête est la même – ça on ne sait rien y faire. La différence va résider dans le fait que quand l'utilisateur cliquera sur un lien – ou un autre élément cliquable – la page ne se rechargera pas et le navigateur enverra une requête au serveur, lequel renverra les données demandées dans un format léger – comme le format JSON. Dans ce cas, le serveur n'aura renvoyé qu'un minimum de données ce qui est beaucoup plus léger et donc plus rapide. Le navigateur, par le biais de JavaScript, peut alors mettre à jour une petite partie de la page avec les données reçues du serveur.
Dans ce cas, le pendule est au centre. Le serveur et le navigateur travaillent pour proposer une solution optimale. C'est l'exemple parfait de l'équilibre d'une application AJAX
Il faut cependant faire attention à ne pas mésinterpréter ce schéma, car il ne s'agit en aucun cas de remplacer la page entière, ce qui reviendrait à recharger la page. Si on se réfère au pendule, il va balancer du côté du serveur, ce qui montre qu'il y a un problème, et dans ce cas AJAX n'est pas utilisé correctement.
C'est donc la raison pour laquelle il est totalement absurde de créer un site Web entièrement en AJAX. Ce n'est pas possible car AJAX ne doit jamais se substituer à la méthode traditionnelle. AJAX doit être utilisé pour charger/modifier de petites parties d'une page. Un exemple peut être Facebook ; sur Facebook il y a la possibilité d'afficher les amis d'une personne sans recharger la page. Quand vous cliquez sur le lien Afficher les amis, une requête est envoyée au serveur, lequel renvoie la liste des amis de la personne dont vous souhaitez connaître les amis. Cette liste est alors affichée dynamiquement via JavaScript. Pas de rechargement de page, juste une requête rapide – quasi instantanée – et un confort de navigation accru.
Si le pendule est bien au centre, l'application est en équilibre et le dialogue entre le navigateur et le serveur se passe bien. Mais comment dialoguer ? Ou plutôt, en quel format parler ?
Le navigateur et le serveur ne peuvent se parler que via un format de type texte brut. Le navigateur peut donc demander au serveur "Liste amis Alyx" et le serveur renverra la liste des amis d'Alyx. C'est assez nul comme format : si la question est claire, la liste des amis que renverra le serveur le sera nettement moins et c'est ici qu'il va falloir opter pour le format adéquat. Plusieurs formats sont possibles :
Texte simple ;
HTML ;
XML ;
JSON.
Le texte simple
Comme on vient de le voir, ce format n'est pas du tout adapté s'il s'agit de recevoir des données devant êtres "formatées" ou classées comme une liste d'amis.
Le HTML
Le HTML est intéressant car il suffira de l'insérer directement dans la page avec la propriété innerHTML. C'est rapide. Cela dit le HTML est verbeux et peut se révéler assez lourd quand il s'agit d'un grand volume de données.
Avec certains objets AJAX, comme XMLHttpRequest il est possible de récupérer du texte sous forme de XML et de l'interpréter comme tel, ce qui permet de manipuler les données avec les fonctions DOM. Ca peut être intéressant mais XML souffre du même problème que le HTML : il est verbeux. De plus le traitement via DOM peut se révéler assez lent s'il s'agit d'un grand volume de données et suivant le navigateur utilisé par le client.
Reste le JSON. Le JSON est une manière de structurer l'information en utilisant la syntaxe objet de JavaScript – des objets et des tableaux. JSON est très léger, car non-verbeux mais nécessite d'être évalué par le compilateur JavaScript pour pouvoir être utilisé comme un objet. L'évaluation se fait via eval pour les navigateurs obsolètes ou via la méthode parse de l'objet natif JSON. L'évaluation est souvent décriée car peut se révéler dangereuse, mais dans la mesure où vous connaissez la source des données à évaluer il n'y a pas de danger.
Le JSON est donc le format travaillant de paire avec AJAX quand il s'agit de recevoir des données classées et structurées. Les autres formats peuvent bien évidemment servir et se révéler intéressants dans certains cas, mais d'une façon générale les grandes pointures du JavaScript, comme Douglas Crockford incitent à utiliser JSON.
La librairie json2, écrite par Doug Crockford, permet d'émuler le comportement de l'objet natif JSON s'il n'est pas pris en charge par le navigateur. La librairie crée un objet global JSON pourvu des méthodes parse et stringify. La méthode parse est en fait un eval sécurisé, c'est-à-dire qu'un traitement est fait sur la chaine à évaluer pour s'assurer qu'elle ne présente aucun danger.
Une démonstration de cette petite application peut être découverte ici. Il ne s'agit que de HTML statique bien évidemment, cela sert juste à illustrer la théorie.
La principale particularité d'AJAX est l'asynchronisme : la fonction qui envoie une requête au serveur n'est pas la même que celle qui en recevra la réponse. Avant d'aborder la pratique d'AJAX, il est bon de bien cerner cette notion d'asynchronisme qui est très importante.
Quand un programme ou un script s'exécute, il appelle les différentes instructions dans l'ordre dans lequel elles sont placées :
var plop = 0; // première instruction
plop += 2; // deuxième
alert(plop); // et troisième
Maintenant, imaginons qu'il y ait un appel de fonction :
var plop = 0; // première instruction
plop = additionner(plop, 2); // deuxième
alert(plop); // et troisième
Quand la fonction additionner est appelée, le script principal se met en pause, et attend que la fonction soit exécutée, et qu'elle ait renvoyé une valeur (si elle ne renvoie rien, c'est pareil).
On dit que le script est exécuté de façon synchrone : quand un appel externe au script principal est réalisé, le script en attend la réponse ou la fin de l'exécution.
Le contraire de synchrone est asynchrone. Quand un appel est asynchrone, le script principal n'attend pas d'avoir reçu les données pour continuer. Evidemment, si mon exemple synchrone marche bien avec des fonctions, il ne marche pas si le script est asynchrone ; imaginons donc une requête de type AJAX !
Le script s'exécute et rencontre une requête AJAX, laquelle est envoyée en mode asynchrone. Dans ce cas, la requête est envoyée, mais le script n'attend pas que la requête ait abouti, il continue quoi qu'il arrive. L'intérêt est que si la requête met quelques secondes à être traitée par le serveur, le script n'est pas ralenti.
Mais si la requête est envoyée et que le script n'attend pas sa réponse, comment savoir quand cette requête renvoie quelque chose ?
Bonne question. Et c'est ici qu'interviennent les fonctions dites de callback. Une fonction callback est exécutée quand la requête aboutit à quelque chose (que son traitement est fini). Et c'est cette fonction de callback qui va se charger de récupérer les données renvoyées par la requête.
Ainsi, quand la requête est envoyée, le script continue son exécution, et quand la requête renvoie quelque chose, c'est la fonction de callback qui est appelée, et c'est elle qui va faire "suite" au script principal, en traitant les informations renvoyées.
On peut résumer l'asynchronisme en AJAX par ce schéma :
Le principe de fonctionnement d'XMLHttpRequest est d'envoyer une requête HTTP vers le serveur, et une fois la requête envoyée, les données renvoyées par le serveur peuvent être récupérées. Pour ce faire, il faut disposer d'un objet disposant de cette fonctionnalité. Cet objet a été développé par Microsoft et implémenté dans Outlook puis dans Internet Explorer 5.5 en tant que contrôle ActiveX. Microsoft l'avait à l'époque nommé XMLHTTP.
Par la suite, les autres navigateurs suivirent et implémentèrent un objet appelé XMLHttpRequest. Cet objet fut implémenté avec les mêmes méthodes que celle d'XMLHTTP de Microsoft. Plus tard, XMLHttpRequest fut proposé au W3C en vue de devenir un standard.
A l'heure actuelle, les navigateurs récents (IE7, FF2, Opera 9, Safari...) implémentent tous cet objet.
Pour instancier (créer, déclarer) un objet XHR, on procède de la même façon que pour n'importe quel objet JavaScript à savoir avec le mot-clé new :
var xhr = new XMLHttpRequest();
Les versions d'Internet Explorer inférieures à la version 7 requièrent toujours une instanciation via un contrôle ActiveX. Il y a deux façons d'instancier un objet XHR avec un contrôle ActiveX et elles dépendent de la version d'XMLHTTP utilisée. Pour faire simple, on va utiliser un try...catch , l'instanciation indiquée dans le try étant la plus récente :
try {
var xhr = new ActiveXObject("Msxml2.XMLHTTP");
} catch(e) {
var xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
Pour faire un script homogène, rassemblons ce code en un seul, en prenant soin de tester la prise en charge des différentes méthodes d'instanciation :
var xhr = null;
if (window.XMLHttpRequest || window.ActiveXObject) {
if (window.ActiveXObject) {
try {
xhr = new ActiveXObject("Msxml2.XMLHTTP");
} catch(e) {
xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
} else {
xhr = new XMLHttpRequest();
}
} else {
alert("Votre navigateur ne supporte pas l'objet XMLHTTPRequest...");
return;
}
Par la suite, j'utiliserai une fonction qui retournera l'objet XMLHttpRequest instancié, ce sera plus simple :
function getXMLHttpRequest() {
var xhr = null;
if (window.XMLHttpRequest || window.ActiveXObject) {
if (window.ActiveXObject) {
try {
xhr = new ActiveXObject("Msxml2.XMLHTTP");
} catch(e) {
xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
} else {
xhr = new XMLHttpRequest();
}
} else {
alert("Votre navigateur ne supporte pas l'objet XMLHTTPRequest...");
return null;
}
return xhr;
}
Par la suite, pour instancier un objet XHR, il suffira de faire :
Dans un premier temps, il faut définir les modalités d'envoi avec la méthode open , et on l'enverra ensuite avec la méthode send :
var xhr = getXMLHttpRequest(); // Voyez la fonction getXMLHttpRequest() définie dans la partie précédente
xhr.open("GET", "handlingData.php", true);
xhr.send(null);
open s'utilise de cette façon : open(sMethod, sUrl, bAsync)
sMethod : la méthode de transfert : GET ou POST;
sUrl : la page qui donnera suite à la requête. Ça peut être une page dynamique (PHP, CFM, ASP) ou une page statique (TXT, XML...);
bAsync : définit si le mode de transfert est asynchrone ou non (synchrone). Dans ce cas, mettez true . Ce paramètre est optionnel et vaut true par défaut, mais il est courant de le définir quand même (je le fais par habitude).
Si vous utilisez la méthode POST, vous devez absolument changer le type MIME de la requête avec la méthode setRequestHeader , sinon le serveur ignorera la requête :
Avant de passer des variables, il est important de les protéger pour conserver les caractères spéciaux et les espaces. Pour cela, utilisez la fonction globale encodeURIComponent , comme ceci :
var sVar1 = encodeURIComponent("contenu avec des espaces");
var sVar2 = encodeURIComponent("je vois que vous êtes un bon élève... oopa !");
xhr.open("GET", "handlingData.php?variable1=" + sVar1 + "&variable2= " + sVar2, true);
xhr.send(null);
Dans mon exemple, la page handlingData.php reçoit la requête. Cette page est une page PHP, elle est donc dynamique, mais ce n'est pas obligatoire, il peut s'agir d'un fichier TXT ou même XML !
Une page PHP
Cette page se comporte comme une page PHP normale, il n'y a rien de spécifique. La récupération des variables se fait d'une façon classique (via $_GET ou $_POST, suivant la méthode d'envoi) et il ne faut pas perdre de vue de sécuriser la page, car un petit malin pourrait l'appeler directement sans passer par l'appel via XMLHttpRequest (il peut donc mettre directement l'URL de la page) :
<?php
header("Content-Type: text/plain"); // Utilisation d'un header pour spécifier le type de contenu de la page. Ici, il s'agit juste de texte brut (text/plain).
$variable1 = (isset($_GET["variable1"])) ? $_GET["variable1"] : NULL;
$variable2 = (isset($_GET["variable2"])) ? $_GET["variable2"] : NULL;
if ($variable1 && $variable2) {
// Faire quelque chose...
echo "OK";
} else {
echo "FAIL";
}
?>
Ce script ne fait évidemment rien d'intéressant, il vérifie juste si les deux variables sont renseignées. Si elles le sont, il écrit OK, et si elles ne le sont pas il écrit FAIL. C'est très important d'écrire quelque chose, car XMLHttpRequest va être capable de récupérer ce qui a été écrit, sous forme de texte brut (comme dans cet exemple) ou sous forme d'arbre XML. En écrivant OK ou FAIL, on pourra alors vérifier si le script a été correctement exécuté.
Une page statique
Comme je l'ai laissé entendre, il est possible d'utiliser des fichiers statiques. Dans le cas d'un fichier de texte (TXT), l'entièreté du texte sera récupéré, et s'il s'agit d'un fichier XML, on pourra récupérer la structure XML et l'utiliser directement.
Dans tous les cas, il faudra préciser dans quel format les données devront être récupérées. C'est ce que nous allons faire maintenant.
Récapitulons : en 1, on a envoyé la requête, et en 2 la requête a trouvé des données à récupérer (les données fournies par le fichier PHP, TXT ou XML).
Le changement d'état
Il faut savoir que quand on envoie une requête HTTP via XMLHttpRequest, celle-ci passe par plusieurs états différents :
0 : L'objet XHR a été créé, mais pas encore initialisé (la méthode open n'a pas encore été appelée)
1 : L'objet XHR a été créé, mais pas encore envoyé (avec la méthode send )
2 : La méthode send vient d'être appelée
3 : Le serveur traite les informations et a commencé à renvoyer des données
4 : Le serveur a fini son travail, et toutes les données sont réceptionnées
En vue de cela, il va donc nous falloir détecter les changements d'état pour savoir où en est la requête. Pour cela, on va utiliser la propriété onreadystatechange, et à chaque changement d'état (state en anglais), on regardera lequel il s'agit :
On utilise readyState pour connaître l'état de la requête. En addition, nous devons aussi vérifier le code d'état (comme le fameux code 404 pour les pages non trouvées ou le code 500 pour l'erreur de serveur) de la requête, pour vérifier si tout s'est bien passé. Pour cela, on utilise la propriété status. Si elle vaut 200 ou 0 (aucune réponse, pratique pour les tests en local, sans serveur d'évaluation), tout est OK.
Récupérer les données
Rien de plus simple, il suffit d'utiliser une des deux propriétés disponibles :
responseText : pour récupérer les données sous forme de texte brut
responseXML : pour récupérer les données sous forme d'arbre XML
Un alert simple
L'utilisation est assez simple, il suffit de procéder comme ceci :
Le alert c'est bien beau, mais à part vérifier si la réception est bonne, ça ne sert à rien. Si on s'amuse à récupérer des données, c'est pour les traiter ! Le traitement peut se faire directement dans la fonction anonyme définie dans onreadystatechange. Mais c'est très laid et ça n'a rien à faire là, il vaut mieux séparer les codes pour avoir deux fonctions concises plutôt qu'une grosse.
On va donc définir ce qu'on appelle une fonction dite "de callback". Une fonction de callback est une fonction de rappel, exécutée généralement après qu'un script a été exécuté. C'est pas très clair, mais c'est tout con en fait : il s'agit de passer à une fonction A le nom d'une fonction B qui sera lancée une fois que la fonction A aura été exécutée. Comme ceci en gros :
function funcA(callback) {
// instruction...
// instruction...
// instruction...
callback();
}
function funcB() {
alert("Plop");
}
funcA(funcB);
En me basant sur cet exemple de callback, il est donc facile de le transposer pour utiliser XMLHttpRequest :
function request(callback) {
var xhr = getXMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && (xhr.status == 200 || xhr.status == 0)) {
callback(xhr.responseText);
}
};
xhr.open("GET", "handlingData.php", true);
xhr.send(null);
}
function readData(sData) {
// On peut maintenant traiter les données sans encombrer l'objet XHR.
if (sData == "OK") {
alert("C'est bon");
} else {
alert("Y'a eu un problème");
}
}
request(readData);
En cliquant sur le bouton, on envoie la requête qui va se charger de récupérer les données, au format XML (avec responseXML donc). Ensuite, dans la fonction readData, on lit ces données et on crée une liste à puces que l'on va ajouter à l'élément appelé output.
Exemple 2 : envoi - traitement - réception
Ici, on va demander à l'utilisateur d'entrer son pseudonyme ainsi que son prénom. Ces deux données seront transmises à une page PHP qui renverra un texte avec les données envoyées. Ça n'a aucun intérêt comme ça, mais c'est pour vous donner une base simple.
Voici la page HTML :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Techniques AJAX - XMLHttpRequest</title>
<script type="text/javascript" src="oXHR.js"></script>
<script type="text/javascript">
<!--
function request(callback) {
var xhr = getXMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && (xhr.status == 200 || xhr.status == 0)) {
callback(xhr.responseText);
}
};
var nick = encodeURIComponent(document.getElementById("nick").value);
var name = encodeURIComponent(document.getElementById("name").value);
xhr.open("GET", "XMLHttpRequest_getString.php?Nick=" + nick + "&Name=" + name, true);
xhr.send(null);
}
function readData(sData) {
alert(sData);
}
//-->
</script>
</head>
<body>
<form>
<p>
<label for="nick">Pseudo :</label>
<input type="text" id="nick" /><br />
<label for="name">Prénom :</label>
<input type="text" id="name" />
</p>
<p>
<input type="button" onclick="request(readData);" value="Exécuter" />
</p>
</form>
</body>
</html>
Notez bien l'utilisation d'encodeURIComponent pour protéger les données transmises. Si tout se passe bien, un alert s'affichera avec la petite phrase renvoyée par le script PHP.
Grâce à readyState, on sait connaitre l'état de la requête. Il peut donc être intéressant de dire à l'internaute que la requête est en train d'être traitée et affichant un petit texte "Chargement en cours" ou bien une petite image de progression.
Si quand readyState vaut 4 tout est terminé, ça veut donc dire que si ça ne vaut pas 4, c'est en cours de traitement. De là, il n'y a qu'un pas pour afficher une image de progression comme on va le voir dans cet exemple :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Techniques AJAX - XMLHttpRequest</title>
<script type="text/javascript" src="oXHR.js"></script>
<script type="text/javascript">
<!--
function request(callback) {
var sleep = document.getElementById("sleep").value;
if (isNaN(parseInt(sleep))) {
alert(sleep + " n'est pas un nombre valide !");
return;
}
var xhr = getXMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && (xhr.status == 200 || xhr.status == 0)) {
callback(xhr.responseText);
document.getElementById("loader").style.display = "none";
} else if (xhr.readyState < 4) {
document.getElementById("loader").style.display = "inline";
}
};
xhr.open("GET", "XMLHttpRequest_getSleep.php?Sleep=" + sleep, true);
xhr.send(null);
}
function readData(sData) {
alert(sData);
}
//-->
</script>
</head>
<body>
<form>
<p>
<label for="sleep">Temps de sommeil :</label>
<input type="text" id="sleep" />
</p>
<p>
<input type="button" onclick="request(readData);" value="Exécuter" />
<span id="loader" style="display: none;"><img src="loader.gif" alt="loading" /></span>
</p>
</form>
</body>
</html>
Il s'agit simplement d'afficher l'image de progression contenue dans le spanloader. Pour être sur de bien le voir (car une simple requête comme ça prend moins d'une seconde), j'utilise une fonction sleep dans la page XMLHttpRequest_getSleep.php, page que voici :
En considérant l'exemple précédent, que se passe-t-il si l'utilisateur clique plusieurs fois sur le bouton d'envoi ? Et bien la réponse est simple, la requête est envoyée plusieurs fois. Ce qu'il faudrait c'est trouver une astuce pour annuler la requête en cours si une nouvelle est envoyée.
Pour ce fait, il va falloir stocker l'objet XMLHttpRequest dans un objet global, xhr, et il n'y aura qu'à tester l'état de cet objet avant d'envoyer une nouvelle requête. Si l'état est différent de 0 (la requête est en cours), il suffit de l'annuler pour envoyer la nouvelle. On peut aussi décider de ne pas envoyer la nouvelle, au choix ça.
Annulation de la requête en cours
var xhr = null;
function request(callback) {
if (xhr && xhr.readyState != 0) {
xhr.abort(); // On annule la requête en cours !
}
xhr = getXMLHttpRequest(); // plus de mot clé 'var'
xhr.onreadystatechange = function() {
/* ... */
};
xhr.open("GET", "XMLHttpRequest_getSleep.php?Sleep=" + sleep, true);
xhr.send(null);
}
Annulation de l'envoi de la nouvelle requête
var xhr = null;
function request(callback) {
if (xhr && xhr.readyState != 0) {
alert("Attendez que la requête ait abouti avant de faire joujou");
return;
}
xhr = getXMLHttpRequest();
/* ... */
}
Les listes liées c'est quelque chose d'assez habituel : une première liste déroulante permet de choisir une option, et en fonction de ce choix, on affiche le contenu d'une deuxième liste. C'est assez simple et c'est un bon exercice.
Principe
Une première liste déroulante est affichée, proposant à l'utilisateur de choisir un éditeur de logiciels (c'est pour l'exemple). Quand l'utilisateur choisit un éditeur, on récupère, via XHR, la liste des logiciels qui correspondent à cet éditeur, et on l'affiche dans une deuxième liste déroulante.
La liste des éditeurs et des logiciels est enregistrée dans une base de données. Dans mon exemple, j'utilise une base mySQL. Voici d'ailleurs les requêtes SQL pour créer les deux tables que je vais utiliser :
Du côté du code JavaScript pour envoyer la requête, c'est assez simple. Voici la fonction request, appelée via l'évènement onchange de l'élément <select>. Cette fonction se charge d'envoyer la requête.
function request(oSelect) {
var value = oSelect.options[oSelect.selectedIndex].value;
var xhr = getXMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && (xhr.status == 200 || xhr.status == 0)) {
readData(xhr.responseXML);
document.getElementById("loader").style.display = "none";
} else if (xhr.readyState < 4) {
document.getElementById("loader").style.display = "inline";
}
};
xhr.open("POST", "XMLHttpRequest_getListData.php", true);
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xhr.send("IdEditor=" + value);
}
La fonction readData sera appelée et se chargera de remplir le <select> avec la liste des logiciels. J'en reparlerai après le code PHP.
Javascript possède une propriété intéressante qui est celle de pouvoir charger un fichier .js à partir d'un autre et ce à n'importe quel moment. Ainsi il est possible de charger une autre page de script à partir d'une première en insérant un élément <script />, comme le montre cet exemple :
Javascript permet donc nativement, et depuis toujours, d'utiliser le principe de l'AJAX en appelant un fichier .js après que la page HTML a été chargée. Il est aussi possible d'appeler une page PHP, identifiée comme étant un fichier JS, ce qui permettra une bonne interaction avec le serveur. C'est ce que nous allons voir plus en détail ici.
On va faire quelque chose de très simple pour commencer : on va créer un élément <script /> qui appellera un fichier JS et celui-ci qui répondra avec un alert. C'est basique, mais il faut que vous compreniez la base avant d'aller plus loin.
Le script donné ci-dessus marche bien, mais utilise la vieille méthode write(), ce qui est plutôt déconseillée et qui de plus ne nous est pas d'un grand intérêt. Pour ajouter un élément <script />, nous allons utiliser le DOM :
Ce script crée et insère un élément <script /> avec un attribut src pointant vers la page JS (DynamicScriptLoading_1.js dans mon exemple), dans le body de la page HTML.
Ce petit bout de code, une fois placé appelle le fichier JS exactement comme si l'élément <script /> avait été écrit en HTML "brut". Le script contenu dans ce fichier JS est alors exécuté.
On va ajouter une fonction, appelée callback qui sera appelée par le fichier JS dès que ce dernier sera chargé. C'est en quelque sorte la réponse que le script de départ attend.
function callback(sMessage) {
alert(sMessage);
}
Le fichier JS (DynamicScriptLoading_1.js) contient juste l'appel de cette fonction :
callback("Hello world !");
En clair, on obtient quelque chose comme ça :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Dynamic Script Loading</title>
<script type="text/javascript">
<!--
function send() {
var DSLScript = document.createElement("script");
DSLScript.src = "DynamicScriptLoading_1.js";
DSLScript.type = "text/javascript";
document.body.appendChild(DSLScript);
document.body.removeChild(DSLScript);
}
function callback(sMessage) {
alert(sMessage);
}
//-->
</script>
</head>
<body>
<input type="button" value="Envoyer la requête" onclick="send()" />
</body>
</html>
Dès qu'on clique sur le bouton, la fonction send() est appelée. Cette dernière ajoute un élément <script /> lequel va charger un fichier JavaScript. Et pour finir, ce fichier JavaScript va appeler la fonction callback.
Pourquoi y a-t'il un document.body.removeChild() ?
En réalité ce type de chargement n'est pas asynchrone. Lorsque l'élément <script /> est inséré via appendChild(), le fichier JS est chargé. Quand il est chargé, removeChild() est exécutée pour supprimer l'élément <script /> qui ne nous est plus d'aucune utilité.
Je pense que vous avez compris le principe de base. On va pouvoir ajouter des variables et du PHP :) .
Maintenant, au lieu d'appeler un fichier JS, nous allons appeler une page PHP. PHP, comme vous le savez, permet de récupérer des variables transmises via l'URL (méthode GET). C'est ce que nous allons faire !
La transmission des variables se fait comme à l'accoutumée :
Pour ce qui est de la page PHP, c'est un peu plus « spécial », la voici :
<?php header("Content-type: text/javascript"); ?>
var sMessage = "Bonjour <?php echo $_GET['Prenom'] ?>, alias <?php echo $_GET['Pseudo'] ?> !";
callback(sMessage);
Gardez à l'esprit que c'est « comme » un fichier JavaScript, donc, tout ce qui n'est pas dans des balises <?php ?> est du code JavaScript ! Le code PHP peut être placé n'importe où, exactement comme si vous le placiez dans une page HTML, ce qui permet d'incorporer dans le code JavaScript.
Le code que je vous ai donné n'est pas super pratique à utiliser. Le mieux serait d'en faire des fonctions facilement déployables, acceptant un certain nombre de variables, une fonction de callback différente (qu'on ne soit pas obligé de l'appeler « callback »)...
Voici une fonction send générique :
function send(sUrl, oParams) {
for (sName in oParams) {
if (sUrl.indexOf("?") != -1) {
sUrl += "&";
} else {
sUrl += "?";
}
sUrl += encodeURIComponent(sName) + "=" + encodeURIComponent(oParams[sName]);
}
var DSLScript = document.createElement("script");
DSLScript.src = sUrl;
DSLScript.type = "text/javascript";
document.body.appendChild(DSLScript);
document.body.removeChild(DSLScript);
}
La fonction send reçoit, en plus de l'URL du fichier à charger, les variables à transmettre (c'est-à-dire à concaténer dans l'URL). L'argument oParams est un objet contenant une liste de clés/valeurs utilisant la notation JSON, comme ceci :
La valeur de la clé callback est tout simplement le nom de la fonction de callback à déclencher une fois la page PHP chargée. La notation JSON vous paraît peut-être étrange, mais c'est pratique pour transmettre une liste du type clé/valeur en une seule fois.
Et pour parcourir une telle structure, on utilise une boucle for associée au mot clé in, comme pour lister un tableau associatif. La fonction globale encodeURIComponent permet de coder les caractères spéciaux, pour ne pas avoir de problèmes lors de la transmission.
Le script de la page PHP peut alors être transformé de cette façon, de manière à appeler la fonction de callback (dont le nom est transmis dans la variable $_GET['callback']);
Et voilà, on a fait le tour de cette méthode. Elle est pratique, rapide et facile à déployer, mais comporte cependant un certain nombre de limitations. Par exemple, on ne sait utiliser que des requêtes GET, et non POST. Il n'y a non plus aucun moyen de savoir si la transmission s'est bien déroulée : si la page a renvoyé une erreur 404, on ne le sait pas.
Cela dit, Dynamic Script Loading est certainement le moyen le plus intéressant pour récupérer des données au format JSON. Voyons ça plus en détail !
JSON, ou JavaScript Object Notation est un format de structuration de données, un peu comme le XML. Mais la syntaxe est identique à la syntaxe objet de JavaScript. Ce tutoriel n'était pas un tutoriel de JSON, je ne reviendrai pas sur la structure du format.
Comme l'illustre l'exemple ci-dessus, il est très facile de récupérer une variable, et cette variable peut très bien être un objet JSON. Deux avantages de l'importation d'un objet JSON via Dynamic Script Loading peuvent être les suivants :
Facilité de mise en place
L'objet récupéré est de type object, et non de type string. Il n'y a donc pas besoin d'utiliser eval ou l'objet natif JSON pour parser la chaîne de caractères, ce qui est plutôt bénéfique. Eval is evil.
La fonction callback va donc servir à récupérer l'objet JSON oSoftwares. Il suffira ensuite de traiter ces données et de les afficher. Voici donc ma fonction callback :
function callback(oJson) {
var tree = "", nbItems;
for (sItem in oJson) {
tree += sItem + "\n";
nbItems = oJson[sItem].length;
for (var i=0; i<nbItems; i++) {
tree += "\t" + oSoftwares[sItem][i] + "\n";
}
}
alert(tree);
}
Bien évidemment, il n'y a pas besoin de faire appel à la fonction send compliquée vue ci-dessus, puisque je ne souhaite pas envoyer de variables au fichier JavaScript.
Voici donc le code complet de l'exemple :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Techniques AJAX - Dynamic Script Loading - JSON Statique</title>
<script type="text/javascript">
<!--
function send(sUrl) {
var DSLScript = document.createElement("script");
DSLScript.src = sUrl;
DSLScript.type = "text/javascript";
document.body.appendChild(DSLScript);
document.body.removeChild(DSLScript);
}
function callback(oJson) {
var tree = "", nbItems;
for (sItem in oJson) {
tree += sItem + "\n";
nbItems = oJson[sItem].length;
for (var i=0; i<nbItems; i++) {
tree += "\t" + oSoftwares[sItem][i] + "\n";
}
}
alert(tree);
}
function getInfo() {
send("DynamicScriptLoading_JSON_1.js");
}
//-->
</script>
</head>
<body>
<p id="main">
<input type="button" value="Récupérer les données" onclick="getInfo();" />
</p>
</body>
</html>
Il n'y a rien de bien compliqué non plus. La différence avec le code précédent est que la page appelée est une page PHP qui renvoie du code JavaScript, dont voici le code :
Et voici le fichier HTML. Pour différer un tantinet de l'exemple précédent, j'ai incorporé le script de gestion avec les variables, c'est plus distrayant :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Techniques AJAX - Dynamic Script Loading - JSON Dynamique</title>
<script type="text/javascript">
<!--
function sendDSL(sUrl, oParams) {
for (sName in oParams) {
if (sUrl.indexOf("?") != -1) {
sUrl += "&";
} else {
sUrl += "?";
}
sUrl += encodeURIComponent(sName) + "=" + encodeURIComponent(oParams[sName]);
}
var DSLScript = document.createElement("script");
DSLScript.src = sUrl;
DSLScript.type = "text/javascript";
document.body.appendChild(DSLScript);
document.body.removeChild(DSLScript);
}
function callback(oJson) {
var tree = "", nbItems;
for(sItem in oJson) {
tree += sItem + "\n";
nbItems = oJson[sItem].length;
for(var i=0; i<nbItems; i++) {
tree += "\t" + oSoftwares[sItem][i] + "\n";
}
}
alert(tree);
}
function getInfo() {
var oParams = { "callback": "callback" };
sendDSL("DynamicScriptLoading_JSON_2.php", oParams);
}
//-->
</script>
</head>
<body>
<p id="main">
<input type="button" value="Récupérer les données" onclick="getInfo();" />
</p>
</body>
</html>
Le Dynamic Script Loading est donc un moyen simple et efficace de récupérer des données sous forme de variables (données textuelles) et d'objets JavaScript (données formatées en JSON).
Points forts
Facilité de mise en place
Intégration parfaite avec les données JSON
Points faibles
Un peu tordu à utiliser
Limité à du texte et à du JSON. On peut récupérer aussi des données XML, mais ça implique des méthodes de création avec DOMImplementation (ce qui est assez inutile)
L'object XMLHttpRequest est pratique pour récupérer un peu n'importe quoi comme type de données (text, XML, HTML...), mais est généralement un peu lourd à utiliser. Si vous désirez juste récupérer une source de données au format XML, vous pouvez le faire via DOMImplementation.
L'interface DOMImplementation fait partie du DOM Level 2 Core et est supportée par la plupart des navigateurs. Internet Explorer supporte le DOMImplementation, mais par le biais d'un contrôle ActiveX (comme les versions 5 et 6 d'IE avec XMLHttpRequest).
En réalité IE gère le DOMImplementation, mais pas complètement. Il ne gère que la méthode hasFeature (du DOM Level 1) et pas createDocument dont nous allons nous servir. Donc pour savoir comment réagir en fonction du navigateur, il n'est pas bien malin de faire un test de gestion de l'objet implementation :
if (document.implementation) { }
Il vaut mieux tester également la prise en charge de la méthode createDocument :
if (document.implementation && document.implementation.createDocument) { }
Nous allons créer une fonction générique qui ira récupérer une source XML à l'adresse sUrl, et qui renverra le contenu dans une fonction de callback fCallback. Ainsi nous disposerons d'une fonction qui ne s'occupera que de la gestion de DOMImplementation :
function getDOMImplementation(sUrl, fCallback) {
var dom;
if (window.ActiveXObject) {
dom = new ActiveXObject("Microsoft.XMLDOM");
dom.onreadystatechange = function() {
if(dom.readyState == 4) {
fCallback(dom);
}
};
}
else if (document.implementation && document.implementation.createDocument) {
dom = document.implementation.createDocument("", "", null);
dom.onload = function() {
fCallback(dom);
}
}
else {
alert("Votre navigateur ne gère pas l'importation de fichiers XML");
return;
}
dom.load(sUrl);
}
L'ActiveX XMLDOM permettant à IE de gérer l'importation DOM fonctionne exactement comme un ActiveX XMLHTTP. Ainsi, si vous le voulez, vous pouvez contrôler le bon fonctionnement des opérations avec onreadyonchange.
L'objet implementation requiert donc la méthode createDocument qui permet de créer un document XML. Les deux premiers arguments sont le namespace et le nom qualifié du document XML. Le troisième argument est le doctype. Laissez les deux premiers vides, et le troisième nul.
Vous pouvez utiliser une page PHP pour générer un fichier XML. Dans ce cas, des variables GET peuvent être transmises à la page PHP via l'url. Voici un exemple qui charge du XML créé dynamiquement au moyen d'une page PHP.
La page HTML est rigoureusement la même que dans l'exemple ci-dessus, à l'exception de l'appel de la fonction :
<input type="button" value="Récupérer les données" onclick="getDOMImplementation('DOMImplementation_2.php?Pseudo=Thunderseb', getData);" />
La page PHP (DOMImplementation_2.php) contient ce code :
Pour ne pas rester que sur de la théorie et des exemples limités, je vous propose ici de réaliser une petite base de données (un fichier XML) laquelle est lue par un script Javascript. L'idée de l'exemple est de tenir une liste de toutes mes BD (Bandes Dessinées) et d'afficher, via une liste déroulante, les différents albums d'une série (tous les albums de la BD Pierre Tombal par exemple).
Tout d'abord, voici la structure XML que j'utilise pour ma liste de BD :
<?xml version="1.0" encoding="utf-8"?>
<bds>
<!-- PIERRE TOMBAL -->
<serie name="Pierre Tombal">
<bd num="4" title="des os pilants" />
<bd num="5" title="ô suaires" />
<bd num="12" title="la pelle aux morts" />
<bd num="21" title="k.os" />
<bd num="22" title="ne jouez pas avec la Mort !" />
<bd num="24" title="on s'éclate mortels !" />
</serie>
<!-- LES PROFS -->
<serie name="Les Profs">
<bd num="2" title="loto et colles" />
<bd num="3" title="tohu-bahut" />
<bd num="4" title="rentrée des artistes" />
<bd num="5" title="chute des cours" />
<bd num="9" title="rythme scolaire" />
</serie>
<!-- et ça continue, encore et encore, c'est que le début, d'accord d'accord... -->
</bds>
Les BD sont donc classées par série (exemple : Pierre Tombal) qui contient la liste des albums (exemple : album numéro 5 ayant comme titre ô suaire).
L'idée est de récupérer le contenu XML, via DOMImplementation, et de lister toutes les séries, et les afficher dans une liste déroulante. A partir de cette liste, l'utilisateur choisit une série et clique sur un bouton pour afficher les albums de cette série. Voici comment se présente le HTML, tout simple :
<fieldset>
<legend>Sélection de la série</legend>
<form id="bdForm" method="get" action="">
<div>
<label for="serieName">Choisir une série : </label>
<!-- On écrira le SELECT dans le SPAN ci-dessous -->
<span id="outputListDiv"><em>Liste des séries non chargée...</em></span>
</div>
<p><input type="button" value="Afficher les BD de cette série" onclick="displayBD();" /></p>
</form>
</fieldset>
<fieldset id="outputBDFieldset">
<legend>BD en ma possession</legend>
<!-- On écrira la TABLE avec la liste des albums dans le DIV ci-dessous -->
<div id="outputBDDiv"></div>
</fieldset>
DOMXML sera une variable globale dans laquelle on mettra la structure XML, de manière à l'exploiter par après. La fonction init est appelée lors du chargement (onload) et se charge de lire le fichier XML et d'appeler la fonction de callback getData.
Maintenant, getData :
function getData(oData) {
DOMXML = oData;
var series = oData.getElementsByTagName("serie");
var sorted = [];
// Classement par ordre alphabétique, via tableau à 2 dimensions
for (var i=0, c=series.length; i<c; i++) {
sorted.push([series[i].getAttribute("name"), i]);
}
sorted.sort();
// Génération du SELECT
var list = "<select name=\"serieName\" id=\"serieName\">\n";
for (var i=0, c=sorted.length; i<c; i++) {
list += "<option value=\"" + sorted[i][1] + "\">" + sorted[i][0] + "</option>\n";
}
list += "</select>\n";
document.getElementById("outputListDiv").innerHTML = list;
}
On commence par récupérer tous les éléments <serie> , et pour chaque élément, on récupère le nom de la série ainsi que l'indice de parcourt (i) que l'ont met dans un tableau, lequel tableau est ajouté dans le tableau sorted.
L'utilité de ça est d'appliquer un sort sur le tableau sorted pour ainsi trier les sous-tableaux par ordre alphabétique. Une fois que c'est fait, on reboucle pour créer le <select> que l'on ajoute dans la page.
Avec ça, on récupère les séries et on affiche le <select> . Maintenant, quand l'utilisateur clique sur un bouton, on affiche la liste des albums contenus dans la série sélectionnée.
<input type="button" value="Afficher les BD de cette série" onclick="displayBD();" />
function displayBD() {
// récup' de l'id de la série, écrit dans la VALUE de l'OPTION
with (document.getElementById("serieName")) var idSerie = parseInt(options[selectedIndex].value);
var serie = DOMXML.getElementsByTagName("serie")[idSerie];
var bds = serie.getElementsByTagName("bd");
// Création de la TABLE avec les résultats
var table = "<table class=\"sortable\" width=\"100%\">\n";
table += "<tr><th width=\"20\">N°</th><th>Titre de l'album</th></td>\n";
for (var i=0, c=bds.length; i<c; i++) {
table += "<tr><td>" + bds[i].getAttribute("num") + "</td><td>" + bds[i].getAttribute("title") + "</td></tr>\n";
}
table += "</table>\n";
document.getElementById("outputBDDiv").innerHTML = table;
}
Comme on a sauvé les données XML dans la variable globale DOMXML, on s'en sert pour récupérer les albums (variable bds) de la série donnée. L'affichage via un tableau HTML est plus pratique d'une liste ordonnée, puisque rien ne garantit que la numérotation des BD se suit, et toutes les BD ne possèdent pas le même type de numérotation (par exemples les ré-éditions au format A4 des premiers albums de Gaston Lagaffe sont numérotées R1, R2, R3, R4 et R5).
DOMImplementation est pour moi la solution la plus pratique si vous voulez charger du contenu XML. Il est fait pour ça, et il serait dommage de ne pas l'utiliser.
Vous connaissez certainement l'élément <iframe> ? Pour ceux qui ne le connaissent pas, c'est un élément qui permet d'insérer une page Web dans une autre. Cet élément faisait partie des spécifications HTML, mais a été délaissé dans XHTML en raison de sa mauvaise accessibilité. L'iframe fait néanmoins son come-back dans HTML5. La technique habituelle de remplacement d'une iframe est de faire un include en PHP dans un <div>, avec une overflow (propriété CSS pour ajouter des barres de défilement).
Voici un petit rappel de la syntaxe d'une iframe :
Comme je l'ai dit, cet élément n'est plus présent dans les spécifications XHTML. Mais l'iframe, en AJAX, peut se révéler très utile pour y faire transiter des données. Le meilleur exemple est le cas de l'upload de fichier en AJAX : un upload de fichier sans recharger la page.
Avant de vous parler de l'upload, je vais d'abord introduire d'autres notions pour manipuler les iframes en récupérant leur contenu.
Une iframe peut être symbolisée comme un document dans un document. Pour accéder au document contenu dans l'iframe, il faut d'abord accéder à l'iframe elle-même, puis à son contenu.
Ce code basique représente une iframe qui contient le fichier fichier.html. Il est très important de nommer l'iframe (attribut name), car nous allons nous en servir pour accéder à cette iframe.
Il y a trois manières d'accéder à l'iframe :
Avec l'Id
Avec le nom
Avec l'objet global frames
On ne va pas utiliser l'Id car ça va vous obliger à utiliser contentDocument pour Firefox que IE ne gère pas.
Voici donc les deux techniques en action :
var oFrame = window.myFrame; // Avec le name
var oFrame = window.frames["myFrame"]; // Avec l'objet global
Une fois l'iframe atteinte, on peut accéder à son contenu, avec l'objet document :
var oFrame = window.myFrame.document; // Avec le name
var oFrame = window.frames["myFrame"].document; // Avec l'objet global
A partir d'ici, les méthodes habituelles peuvent être utilisées, comme si vous travailliez directement dans la page courante, et non dans l'iframe ;
var oFrame = window.frames["myFrame"].document.getElementsByTagName("a").length;
var oFrame = window.frames["myFrame"].document.getElementById("idElement").innerHTML;
Pour charger un fichier dans une iframe, il y a 3 façons :
En remplissant l'attribut src directement en HTML. Le fichier est alors chargé à l'ouverture de la page contenant l'iframe
En modifiant avec JavaScript l'attribut src
En ouvrant un lien dans l'iframe, au moyen de l'attribut target, lui aussi invalide XHTML.
Les deux dernières méthodes sont assez efficaces dans le cas d'une utilisation de type AJAX. Bien qu'invalide, la méthode avec target peut se révéler terriblement pratique !
L'évènement onLoad
Les iframes possèdent un événement onload, qui se déclenche quand le contenu de l'iframe vient d'être chargé. A chaque chargement de contenu, onload est déclenché. C'est un moyen efficace pour savoir si le document est chargé, et ainsi pouvoir le récupérer. Voici un petit exemple :
Quand un document est chargé dans l'iframe, il est exécuté. Cela veut donc dire que si c'est un fichier HTML contenant du code JavaScript, il est possible de déclencher une fonction pour dire que le document est chargé. La fonction à exécuter, garante du bon chargement de la page, peut se trouver dans le fichier chargé dans l'iframe, ou bien dans la page Web qui contient l'iframe. Cela veut donc dire qu'un script contenu dans l'iframe peut appeler une fonction se trouvant dans la page Web hôte de l'iframe.
L'appel de la fonction peut alors s'écrire comme ceci :
Ces deux techniques (onload et le callback) peuvent donc être utilisées pour vérifier si le document est chargé. Dans le cas de la deuxième technique, elle peut-être utilisée pour transmettre des données sous forme d'objet JavaScript (objet JSON, String, array...).
L'attribut src
Pour changer l'url du fichier à charger dans l'iframe, quoi de plus commode que d'utiliser src :
Ainsi, l'attribut src est changé, le la nouvelle page est chargée.
Le target
Comme iframe, target est délaissé en XHTML en raison de problèmes d'accessibilité. C'est un attribut, utilisé sur les éléments <a> et <form> qui sert à définir l'endroit où va s'ouvrir le lien (nouvelle fenêtre, fenêtre parente...). Cet attribut était aussi utilisé pour spécifier la frame dans laquelle un lien allait s'ouvrir, dans le cas des framesets (framesets délaissés depuis pas mal de temps déjà, replacés par les includes des langages dynamiques).
Nous, nous allons utiliser target pour charger un lien dans l'iframe. Cet attribut n'est pas vraiment intéressant pour "juste" charger une page. Nous nous en servirons avec l'élément <form>, dans le cas de l'upload de fichiers (pour dire d'envoyer les données du formulaire dans l'iframe).
La récupération du contenu de l'iframe est assez simple. J'ai déjà montré comment accéder à l'iframe, et il n'y a plus qu'à ajouter quelques points supplémentaires.
Données structurées : arbre XML
Si vous chargez un document XML (ou HTML), vous pouvez récupérer vos données en utilisant les techniques de récupération DOM (getElementById, getElementsByTagName...).
Données textuelles : HTML et TXT
En revanche, si vous voulez récupérer les données au format texte, vous devez utiliser innerHTML. Un document chargé dans l'iframe possède un objet body. Même si c'est un fichier texte, un élément body est présent virtuellement : c'est lui qui englobe la totalité des informations disponibles.
Ainsi, vous devez passer par le body pour utiliser innerHTML (car il est impossible de faire innerHTML directement sur l'objet document) :
var sContent = window.idFrame.document.body.innerHTML;
Si le fichier est un fichier HTML, tout ce qui est dans l'élément body est récupéré. En revanche, si c'est un fichier texte, le contenu est récupéré, mais est placé dans un élément <pre>. Pour utiliser ce contenu, il suffit de faire un substring pour éliminer les balises d'ouverture et de fermeture de l'élément <pre> :
var sContent = window.idFrame.document.body.innerHTML;
sContent = sContent.substring(5, sContent.length - 6);
innerText pour Internet Explorer
Non rassurez-vous, Internet Explorer comprend très bien le code ci-dessus. Mais l'inconvénient est de faire un substring, c'est-à-dire un calcul dont l'interpréteur JavaScript se passerait bien. Internet Explorer implémente la méthode innerText qui permet de ne récupérer que du texte : il n'y a donc pas d'élément <pre> à enlever. Voici donc le code modifié pour utiliser innerText si le navigateur gère cette méthode :
Nous l'avons vu précédemment, avec le système de callback (l'inverse de onload), on peut transmettre des objets JavaScript (array, String, objets JSON...).
On va maintenant voir une utilisation vraiment pratique du système d'iFrame Loading : l'upload de fichiers. Le fichier à uploader se trouve bien-sûr sur le disque dur, on n'upload pas à partit d'une url (sinon c'est trop facile ^^ ).
Côté HTML
Le problème de l'upload est qu'il faut utiliser l'encodage multipart/form-data pour envoyer le formulaire. S'il suffisait d'utiliser une bête requête POST, on aurait pu le faire avec XMLHttpRequest. Mais XHR ne permet pas de définir l'encodage.
Le principe consiste tout simplement à envoyer le formulaire dans une iframe. Le traitement du formulaire se fait alors via PHP et le résultat de l'upload est renvoyé par le biais de l'iframe, avec un système de callback.
Grâce à ce code, une fois que l'utilisateur presse le bouton uploadSubmit, le formulaire est envoyé dans l'iframe uploadFrame pour être traité par le script contenu dans le fichier upload.php.
Le script PHP
Le script PHP s'occupe juste de l'upload. Une fois le script d'upload exécuté, les variables $error et $filename sont écrites dans le code JavaScript qui va se charger d'appeler la fonction uploadEnd. Cette dernière fonction se chargera d'informer le client de statut de l'upload, et si il est réussi, lui retournera l'url du fichier uploadé ($filename).
J'ai ajouté une fonction uploadRun qui est déclenchée quand le formulaire est envoyé (évènement onSubmit) et qui se charge de désactiver le bouton d'envoi, et qui affiche une image GIF de chargement. Quand l'upload est fini, la fonction uploadEnd se charge de réactiver le bouton d'envoi.
Les autres améliorations viennent plus dans le code PHP qui doit être sécurisé, la taille et le type du fichier doivent être vérifiés... Vous pouvez lire ce tutoriel qui porte principalement sur l'upload en PHP.
Cette page n'est pas valide XHTML, en raison de l'utilisation d'iframe et de l'attribut target. Il est possible de rendre la page valide, en utilisant JavaScript pour définir l'attribut target, et pour insérer l'iframe. Mais je ne suis pas vraiment pour ce système, c'est un peu se voiler la face en disant que la page est valide XHTML alors qu'en vérité, elle ne l'est pas (puisque target et <iframe> sont quand même utilisés).
Alternative au JavaScript
Si on regarde bien l'exemple, on peut se rendre compte que JavaScript n'est pas l'élément essentiel du système d'upload. JavaScript ne sert qu'à détecter et à traiter de façon élégante les informations renvoyées pas le script d'upload. Cela veut donc dire qu'il est très facile de rendre le script d'upload utilisable si JavaScript est désactivé.
Si JavaScript est désactivé, un problème se pose : comment informer l'utilisateur d'une erreur ou de la réussite de l'upload ? Eh bien c'est très simple, on va utiliser l'iframe ! Le truc est d'afficher l'iframe si JavaScript est désactivé. Pour ce faire, on fait l'inverse : on masque l'iframe avec JavaScript (donc si JS est désactivé, l'iframe n'est pas masquée).
Voici donc l'instruction à ajouter dans la fonction uploadInit :
document.getElementById("uploadFrame").style.display = "none";
// On n'a pas besoin non plus du <div> pour affiche le statut.
// Pensez à le masquer pas défaut avec les CSS.
document.getElementById("uploadStatus").style.display = "block";
Ensuite, on modifie le script PHP pour qu'il écrive les informations. Ces informations seront alors affichées dans l'iframe.
Les cookies sont un système qui permet à un site web de stocker des informations textuelles au sein du navigateur. Le navigateur enregistre ces données dans des fichiers sur le disque dur de l'ordinateur.
Cookies are delicious delicaciesLes cookies servent à enregistrer des informations concernant le visiteur comme le nombre de pages visitées, le pseudonyme, la langue? Les cookies sont donc un moyen d'échanger des données, et c'est la raison pour laquelle je me dois de vous en parler.
Ce concept de cookie n'est absolument pas nouveau, mais comme je l'ai dit, il représente un système d'échange de données, et peut être utilisé pour mettre en place un système AJAX, comme nous le versons plus tard avec la technique de l'Images & Cookies Loading.
Pour en savoir plus sur les cookies, vous pouvez consulter la définition sur Wikipedia. Les cookies en JavaScript
Il existe un objet cookie, sous-objet de document, qui contient la liste des cookies enregistrés pour le domaine visité. Seulement, cette liste de cookies est donnée sous la forme d'une chaîne de caractères, et JavaScript ne possède pas de méthodes ni de propriétés pour récupérer la valeur d'un cookie présent dans cette chaîne de caractères.
La « complexité » va résider dans l'analyse de la chaîne de caractères.
Ecrire un cookie est quelque chose d'assez simple. Dans un premier temps, on formate une chaîne de caractère de façon à ce qu'elle corresponde au format de stockage d'un cookie. Cette chaîne contient le nom du cookie, et sa valeur.
Une chaîne de caractère représentant un cookie ressemble à ceci :
nomDuCookie=ValeurDuCookie;
Ensuite, dès que la chaîne est formatée, on l'ajoute dans l'objet cookie :
document.cookie = sChaine;
Voici donc ce que peut donner le script complet, dans la fonction setCookie :
function setCookie(sName, sValue) {
var today = new Date(), expires = new Date();
expires.setTime(today.getTime() + (365*24*60*60*1000));
document.cookie = sName + "=" + encodeURIComponent(sValue) + ";expires=" + expires.toGMTString();
}
Il est important, quand on crée un cookie, de spécifier sa date d'expiration. Dans le code ci-dessus, le cookie est prévu pour durer un an. La date d'expiration (expires) est calculée en récupérant la date d'aujourd'hui (today), en lui ajoutant un an de millisecondes.
Pour que la date d'expiration soit reconnue par le navigateur, elle doit être écrite au format GMT, ce qui explique l'utilisation de la méthode toGMTString.
Cette petite fonction sert donc à ajouter un cookie nommé sName, et contenant sValue.
Ici, c'est plus compliqué. Il va falloir analyser la chaîne de caractères contenue dans document.cookie. Ce qu'il faut, c'est récupérer l'emplacement du point virgule, et se débrouiller pour extraire la valeur du cookie cherché. Il est à noter que la date d'expiration ne figure pas dans la chaîne retournée par document.cookie.
Si il n'y a qu'un cookie enregistré, la chaîne est simple à parcourir, mais s'il y a plusieurs cookies, c'est plus compliqué.
Il y a deux manières de récupérer la valeur d'un cookie donnée : avec une analyse de chaîne simple, ou avec une expression régulière (regex).
Analyse normale
function getCookie(sName) {
var cookContent = document.cookie, cookEnd, i, j;
var sName = sName + "=";
for (i=0, c=cookContent.length; i<c; i++) {
j = i + sName.length;
if (cookContent.substring(i, j) == sName) {
cookEnd = cookContent.indexOf(";", j);
if (cookEnd == -1) {
cookEnd = cookContent.length;
}
return decodeURIComponent(cookContent.substring(j, cookEnd));
}
}
return null;
}
Si le code peut paraître un peu compliqué, il est en réalité assez simple. On parcourt la chaîne de caractères à la recherche de sName, et une fois qu'on l'a trouvé, on récupère la position du point-virgule (si il n'y est pas, c'est que c'est le dernier cookie de la chaîne), et on fait un substring final pour récupérer ce qui se trouve entre sName et la position du point-virgule.
Expression régulière
function getCookie(sName) {
var oRegex = new RegExp("(?:; )?" + sName + "=([^;]*);?");
if (oRegex.test(document.cookie)) {
return decodeURIComponent(RegExp["$1"]);
} else {
return null;
}
}
Ici, on utilise une expression régulière pour trouver sName et récupérer sa valeur.
Voici une petite démonstration, avec un script pour écrire et lire des cookies.
Il est possible que le navigateur du client n'accepte pas les cookies (mesure de sécurité). Pour savoir si le navigateur accepte les cookies, vous pouvez faire un test avec la propriété cookieEnabled de l'objet navigator qui revoie true ou false suivant que les cookies sont autorisés, comme ceci :
if (navigator.cookieEnabled) {
// Cookies acceptés
} else {
alert("Activez vos cookies !");
}
Mais cette méthode peut-être faillible sur certains navigateurs (pas de problèmes pour IE, FF, Opera...). Un autre test consiste tout simplement à créer un cookie et à le récupérer. Si le cookie ne peut être récupéré, les cookies sont désactivés.
Supprimer un cookie
On ne sait pas supprimer un cookie directement. Ce qu'il suffit de faire, c'est de le redéfinir en lui donnant une date d'expiration dépassée. Il sera ainsi supprimé par le navigateur.
Le principe du Dynamic Script Loading était déjà un peu tordu, mais pas assez pour rivaliser avec l'Images & Cookies Loading !
Le gros problème du Dynamic Script Loading était qu'on n'avait pas de moyen réel pour savoir si le chargement avait bien eu lieu. Il nous fallait une fonction de callback, embêtante à mettre en place. Il se fait que les images possèdent un évènement onload qui permet de déclencher un script ou une fonction une fois que l'image est complètement chargée.
Eh bien c'est le principe d'Image & Cookies Loading. Mais au lieu de récupérer un fichier contenant du code JavaScript, nous allons utiliser une page PHP qui enregistrera un cookie, et qui redirigera vers une image de très petite taille. Une fois cette image chargée, l'évènement onload de l'image sera déclenché, et nous pourrons récupérer la valeur du cookie.
Comme avec Dynamic Script Loading, il faut ajouter un élément HTML qui appellera notre page PHP. Ici, nous allons tout simplement définir un objet Image :
function send() {
var oImg = new Image();
oImg.onload = function () {
alert(cleanString(getCookie("Ajax_ImagesCookies")));
}
var pseudo = encodeURIComponent("Thunderseb");
var prenom = encodeURIComponent("Sébastien");
oImg.src = "CookiesImagesLoading_1.php?Pseudo=" + pseudo + "&Prenom=" + prenom;
}
Je place sur l'évènement onload le code qui sera exécuté quand l'image sera chargée. Le contenu du cookie est récupéré avec getCookie, fonction donnée dans la partie précédente. Ne faites pas attention à l'appel de la fonction cleanString, j'y reviendrai plus tard. L'image est automatiquement chargée, car un objet Image est inséré dans l'array global document.image, ce qui explique qu'il n'y ait pas besoin d'insérer via DOM l'image dans la page.
Ce qu'il faut comprendre, c'est que ce script JS est censé appeler une image. Donc, pour donner le change, il faut que la page PHP appelée puisse renvoyer une image. Cette image sera tout simplement une image GIF blanche d'un pixel sur un pixel (elle ne sera pas affichée de toute manière).
Voici la page PHP qui réceptionne les variables passées en URL, et qui crée un cookie contenant le texte à renvoyer. Un fois ce traitement fini, le script est redirigé vers l'image :
Vous devez penser à vérifier si les cookies sont acceptés par le navigateur (comme vu dans la partie précédente), et prévoir une technique de secours si les cookies se révèlent désactivés.
Il se peut aussi que dans le message renvoyé par PHP et stocké dans le cookie, tous les espaces soient remplacés par des + . C'est la raison pour laquelle j'ai créé la fonction cleanString qui permet de remplacer les + par des espaces.
Voici d'ailleurs cette fonction :
function cleanString(sString) {
return sString.replace(/(\+)/g, " ");
}
Ce système d'image et de cookie est fait pour des petites quantités de données non-sécurisées (évitez d'y faire transiter des mots de passe). Ca peut être utile dans certains cas :) .
Points forts
Facile à mettre en place
Bon contrôle de la réception (onload)
Prévu pour la réception de petites quantités de données
Points faibles
Les cookies doivent être activés
Prévu pour des petites quantités de données (limitation de taille due aux cookies)
DOM Storage est le nom donné à un ensemble de fonctionnalités de stockage introduites dans la spécification HTML5. DOM Storage est présenté comme une alternative aux cookies en fournissant une plus grande capacité de stockage, une sécurité renforcée, et un accès plus aisé.
Ce concept de « cookies de grande capacité » n'est pas nouveau. Internet Explorer, depuis sa version 5 prend en charge un système appelé Persistence qui permet de spécifier des objets qui vont persister pendant toute une session de navigation. Persistence est quelque chose d'assez vaste et regroupe en son sein plusieurs comportements (behaviours), et nous allons nous intéresser au comportement userData, qui permet de sauvegarder de grandes quantités de données en utilisant le format XML. C'est l'équivalent de l'objet sessionStorage de DOM Storage.
Comme je l'ai déjà laissé entendre, DOM Storage est une façon simple de stocker une grande quantité d'information d'une manière sécurisée et persistante. C'est donc comme les cookies, mais en mieux.
Espace de stockage
Pour un domaine donné, on peut stocker environs 2KB de données avec des cookies. Avec DOM Storage, la capacité est étendue à environ 5120KB. Les possibilités de stockage sont donc beaucoup plus grandes. Cependant, cette taille peut varier suivant les navigateurs, car il n'y a pas de capacité définie dans la spécification HTML5 (qui spécifie le DOM Storage).
sessionStorage et localStorage
Avec DOM Storage, les méthodes pour stocker et récupérer des données sont beaucoup plus simples qu'avec les cookies, avec lesquels il faut créer des fonctions pour parcourir la chaîne de caractères et caetera. Non, DOM Storage met a disposition des méthodes très simples :
Cet exemple illustre l'utilisation de l'objet sessionStorage. Cet objet est un sous-objet de window : window.sessionStorage. On peut donc utiliser une structure conditionnelle pour savoir si le navigateur gère cet objet :
if (window.sessionStorage) {
// OK
}
sessionStorage permet de stocker des données pendant tout le temps que dure la session de navigation. Seul le domaine de création peut y accéder. Chaque sauvegarde de sessionStorage est accessible par un nom unique, que vous devez spécifier entre les crochets. Cela vous permet de créer et récupérer très facilement vos données, au contraire des cookies.
Dans le même ordre d'idée, il existe localStorage. Le fonctionnement est semblable à sessionStorage, hormis le fait que les données restent beaucoup plus longtemps en mémoire, ça ne se limite pas simplement à la session de navigation. C'est l'équivalent du cookie en fait.
L'utilisation de Persitence et plus particulièrement du comportement userData est un peu plus complexe que l'utilisation de DOM Storage.
Les données de Persistence sont entreposées sous la forme d'un arbre XML, et avant de vouloir enregistrer et récupérer des données, il faut spécifier la « branche XML » (le n'ud) sur laquelle on travaille.
Le principe de fonctionnement d'userData n'est pas identique à DOM Storage. Avec userData, il faut spécifier un élément HTML comme élément de « transit ». C'est via cet élément que les données à enregistrer et à récupérer transiteront. En fait, cet élément fera office d'objet, sur lequel nous appliquerons des méthodes et des propriétés.
Pour définir un élément de transit, on utilise la propriété CSS behavior (propriété non-W3C) :
Ainsi, l'élément (ou les éléments) avec la classe storeuserData fait office d'élément de transit.
Voici comment on écrit et on récupère des données :
// Création de l'objet oPersist
var oPersist = document.getElementById("oPersistInput");
// Ecriture
oPersist.setAttribute("user", oPersist.value);
oPersist.save("oXMLBranch");
// Lecture
oPersist.load("oXMLBranch");
alert(oPersist.getAttribute("user"));
Les méthodes load et save ont comme argument le nom de la branche XML à utiliser. Si la branche n'existe pas, elle est évidemment créée.
setAttribute et getAttribute sont exactement les mêmes méthodes que celles utilisées pour définir un attribut et y accéder via le DOM. Et en réalité, c'est logique, puisque les données sont enregistrées dans une branche XML !
Cela veut donc dire que vous pouvez ajouter plusieurs attributs à une même branche ! Les données enregistrées sont donc entreposées sous forme d'attributs XML et non sous forme de clé/valeur comme c'est le cas avec DOM Storage.
Afin de pouvoir utiliser les capacités de DOM Storage sur les navigateurs modernes et les versions antérieures d'Internet Explorer, il est bon de créer un système qui fonctionne dans les différents cas. Ce système le voici en exemple et regroupe DOM Storage et userData. Notez que je me sers d'un else if, et non d'un else, car pour le moment seuls Internet Explorer et Firefox sont à même de gérer ces principes de stockage :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Techniques AJAX - Dom Storage & Persistence</title>
<!--[if lte IE 7]>
<style>
.storeuserData { behavior: url(#default#userData); }
</style>
<![endif]-->
<script type="text/javascript">
function fnSaveInput() {
var oPersist = document.getElementById("oPersistInput");
if (window.globalStorage) {
var storage = globalStorage['nayi.free.fr'];
storage.setItem("contentTest", oPersist.value);
} else if (window.ActiveXObject) {
oPersist.setAttribute("contentTest", oPersist.value);
oPersist.save("oXMLBranch");
}
}
function fnLoadInput() {
var oPersist = document.getElementById('oPersistInput');
if (window.globalStorage) {
var storage = globalStorage["nayi.free.fr"];
oPersist.value = storage.getItem("contentTest");
} else if (window.ActiveXObject) {
oPersist.load("oXMLBranch");
oPersist.value = oPersist.getAttribute("contentTest");
}
}
</script>
</head>
<body>
<form id="oPersistForm">
<input class="storeuserData" type="text" id="oPersistInput" />
<input type="button" value="Load" onclick="fnLoadInput()" />
<input type="button" value="Save" onclick="fnSaveInput()" />
</form>
</body>
</html>
Afin de ne pas provoquer d'erreurs et de warnings au niveau des consoles d'analyse des navigateurs autres qu'Internet Explorer, j'ai placé le code CSS dans une instruction conditionnelle. Ainsi, seules les versions antérieures ou égales à la version 7 tiendront compte de ce code CSS (puisqu'Internet Explorer 8 gère nativement DOM Storage).
Avant de parler d'XMLHttpRequest cross-domain, il est nécessaire de définir ce qu'est le principe cross-domain.
Le cross-domain
Cross-domain signifie croisement de domaine. C'est un principe qui vise à faire communiquer deux domaines ensemble. Par exemple, monsite.com peut envoyer des données à tonsite.com, tout comme ce dernier peut renvoyer des données à monsite.com.
La plupart des techniques AJAX ne sont pas cross-domain pour des raisons évidentes de sécurité. Pour qu'une application cross-domain fonctionne, il faut que le domaine qui reçoit la requête soit autorisé à la traiter. C'est une mesure de sécurité obligatoire.
Il faut donc que le domaine à qui la requête est envoyée soit autorisé à répondre. Pour ce faire, on utilise l'Access Control, qui sera détaillé par la suite.
XMLHttpRequest et XDomainRequest
Faire communiquer deux scripts présents en des domaines différents est impossible avec XMLHttpRequest, dans sa spécification première.
Tous les navigateurs implémentent XMLHttpRequest dans sa spécification première (Level 1) qui ne permet pas de faire du cross-domain. Le W3C travaille sur la spécification 2 (Level 2) qui autorise le cross-domain.
Différences de point de vue
Pour résumer, pendant que le W3C travaille sur la deuxième spécification d'XMLHttpRequest, Microsoft implémente dans Internet Explorer 8 sa propre version du cross-domain, baptisée XDomainRequest. Microsoft justifie ce choix par le fait que la nouvelle version d'XMLHttpRequet ne le satisfait pas. La grosse différence entre XDomainRequest (XDR) et XHR est que ce n'est pas le même objet qui est utilisé, ce qui permet de ne pas s'embrouiller et de bien différencier les deux techniques.
Je vais donc vous parler des deux techniques bien qu'elles ne soient pas encore vraiment utilisables, car seul IE8 gère XDomainRequest et... aucun autre navigateur ne gère la version 2 d'XMLHttpRequest.
On va commencer par voir comment instancier ce nouvel objet, pour nous verrons le fonctionnement d'Access Control.
XDomainRequest fonctionne grosso modo comme XMLHttpRequest, mais un peu plus simplement. Je ne vais pas rentrer dans les détails, c'est facile à comprendre :
var xdr = new XDomainRequest();
xdr.onload = function() {
alert(xdr.responseText);
}
xdr.open("GET", "http://www.foxycode.net/dev/ajax/XDomain_1.php");
xdr.send();
Ce qui change par rapport à XHR, c'est la propriété onload qui remplace et simplifie grandement onreadystatechange, readyState et status. Si onload est déclenché, c'est que tout est bon.
XMLHttpRequest 2
L'utilisation de l'objet XHR en cross-domain est exactement la même que celle que nous avons vue. L'objet a cependant été un peu simplifié en supportant l'évènement onload (comme XDR) et onloadstart.
Ainsi, on peut résumer un code XHR 2 comme ceci :
var xdr = new XMLHttpRequest();
xdr.onload = function() {
alert(xdr.responseText);
}
xdr.open("GET", "http://www.foxycode.net/dev/ajax/XDomain_1.php");
xdr.send();
C'est simplement le même code que pour en envoi XDomainRequest, il y a juste le nom de l'objet qui change.
Combinaison des deux
Comme pour XHR, on va faire une fonction pour instancier facilement un objet XHR cross-domain. Je vais garder le nom de Microsoft pour nommer la fonction histoire de bien différencier les deux systèmes (ce qui fait que je suis plutôt en accord avec la dénomination fournie par Microsoft).
function getXDomainRequest() {
var xdr = null;
if (window.XDomainRequest) {
xdr = new XDomainRequest();
} else if (window.XMLHttpRequest) {
xdr = new XMLHttpRequest();
} else {
alert("Votre navigateur ne gère pas l'AJAX cross-domain !");
}
return xdr;
}
L'en-tête Access-Control-Allow-Origin sert à définir le domaine pour lequel les données pourront être renvoyées. Dans mon exemple, l'astérisque signifie tous les domaines. Il est bien évidemment possible d'affiner cette sélection de domaines :
<?php
header("Access-Control-Allow-Origin: *"); // Tous les domaines
header("Access-Control-Allow-Origin: monsite.com"); // Seul monsite.com peut y accéder
header("Access-Control-Allow-Origin: free.fr"); // Les sous-domaines de Free.fr sont autorisés, donc nayi.free.fr y a accès
?>
L'Access Control est en réalité beaucoup plus vaste que cela. Mais pour les besoins du tutoriel, il n'y a que Allow-Origin qui nous intéresse. Le reste est à découvrir par vous même, mais n'est pas géré complètement par les navigateurs.
Voici le fichier contenant les données. Il est hébergé sur www.foxycode.net et sera récupéré par le script sur nayi.free.fr :
<?php
header("Content-Type: text/plain");
header("Access-Control-Allow-Origin: *");
?>
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Sed hendrerit fringilla dui.
Aenean malesuada, eros nec venenatis fringilla, ipsum mauris suscipit sem, nec semper velit dui nec felis.
L'appel
Le script ci-dessous se contente simplement d'aller questionner le fichier PHP hébergé sur foxycode.net :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Techniques AJAX - XDomainRequest</title>
<script type="text/javascript">
<!--
function getXDomainRequest() {
var xdr = null;
if (window.XDomainRequest) {
xdr = new XDomainRequest();
} else if (window.XMLHttpRequest) {
xdr = new XMLHttpRequest();
} else {
alert("Votre navigateur ne gère pas l'AJAX cross-domain !");
}
return xdr;
}
function sendData() {
var xdr = getXDomainRequest();
xdr.onload = function() {
alert(xdr.responseText);
}
xdr.open("GET", "http://www.foxycode.net/dev/ajax/XDomain_1.php");
xdr.send();
}
//-->
</script>
</head>
<body>
<p>
<input type="button" onclick="sendData();" value="Récupérer" />
</p>
</body>
</html>
Vous pouvez tester cet exemple à cette adresse avec la plupart des navigateurs récents comme Firefox 3.5, Internet Explorer 8, Google Chrome 3. Cela ne fonctionne pas dans Opera 10.5.
L'XMLHttpRequest cross-domain n'en est qu'à ses débuts. Il va falloir attendre un peu pour voir ce que ça va donner. La technologie peut cependant être pleinement utilisable avec Internet Explorer 8 donc peut servir pour des applications uniquement dédiées à Internet Explorer 8.
Quoi qu'il en soit, il faut attendre que les autres navigateurs commencent à implémenter cette nouvelle technologie. Mais la spécification d'XHR 2 n'étant pas terminée, il va falloir encore attendre un peu.
Il est possible avec des scripts réalisés en Flash de créer un système d'upload avec une barre de progression, mais certaines personnes seront très probablement réticentes à utiliser du Flash et laisseront donc tomber la progression de l'upload sur leur formulaire. Heureusement, il existe une solution nommée APC.
L'avantage principal d'APC est de pouvoir fonctionner assez facilement sur n'importe quel navigateur Web car il n'y a que du Javascript et un peu de PHP, ainsi on évite certains problèmes de compatibilité qu'il peut y avoir parfois entre un navigateur et Flash (actuellement, il y a des problèmes entre Firefox 3 et Flash 10).
Vous vous dites sûrement : "Youpi ! On va pouvoir faire une barre de progression sans Flash !" Malheureusement, il faut savoir que tout n'est pas rose avec APC... En effet, pour commencer il y a beaucoup moins de fonctionnalités qu'avec SWFUpload mais ce n'est pas vraiment un problème si vous voulez seulement faire une barre de progression.
Le deuxième facteur gênant est, lui, autrement plus problématique et ce pour une raison bien précise : APC n'est codé ni en Javascript, ni en Flash, mais est en réalité une extension pour PHP ! Ce qui signifie que pour utiliser APC sur votre site web il vous faudra un hébergeur ayant au minimum la version 5.2.0 de PHP et surtout il faut qu'il ait activé l'extension APC, ce qui est vraiment très rare pour le moment. Bref, ce n'est pas gagné pour pouvoir s'en servir librement...
En revanche, vous pourrez toujours faire des tests en local car cela fonctionne tout aussi bien qu'en ligne (bien que j'ai fréquemment relevé des temps de réponse plus élevé qu'avec mon hébergeur web, un comble !).
D'ailleurs, nous allons justement voir dans la partie suivante comment installer APC ou bien comment vérifier si votre hébergeur l'a activé ou non.
Comme beaucoup d'entre vous n'ont probablement pas l'extension APC d'active chez leur hébergeur web, je vais donc tout d'abord traiter de l'activation de cette dernière sur votre ordinateur.
Tout d'abord, vérifiez la version de PHP qui est installée sur votre PC, celle-ci doit être supérieure ou égale à la version 5.2.0.
Une fois cette vérification effectuée, il vous faudra aller dans le fichier de configuration de PHP (nommé "php.ini"). Pour ceux qui utilisent Wamp, vous avez juste à aller dans ce menu pour y accéder.
Il vous faudra tout d'abord initialiser l'extension APC, pour cela entrez donc l'information suivante : extension=php_apc.dll
Une fois l'extension initialisée il faut lui définir ses paramètres principaux, pour cela allez tout en bas du fichier de configuration et entrez le code suivant :
[APC]
apc.enabled = 1
apc.rfc1867 = On
apc.shm_size = 64M
apc.max_file_size = 100M
Ceci est une configuration basique de l'extension, elle permet un fonctionnement de base sans aucune réelle optimisation car ce n'est pas vraiment notre but dans l'immédiat. Toutefois, pour ceux qui voudrait en savoir plus sur sa configuration alors c'est par ici.
Détaillons maintenant ce que l'on vient de faire :
apc.enabled = 1 permet d'activer l'extension. Bien qu'elle ait été initialisée plus haut, il faut aussi l'activer par la suite.
apc.rfc1867 = On permet (en gros) d'activer le suivi de l'upload des fichiers. J'en reparlerai plus tard.
apc.shm_size = 64M défini la taille du cache d'APC, par défaut il est à 30Mo mais là on va faire un brin d'optimisation et mettre cette valeur à 64Mo.
apc.max_file_size = 100M est la constante qui défini la taille maximale d'un fichier à mettre en cache, si cette valeur est dépassée alors l'upload n'aura pas lieu. Si j'ai mis une telle valeur (100 Mo quand même) c'est parce que la copie d'un fichier est très rapide en local, vous pouvez même augmenter si ça va toujours trop vite (mais il vous faudra de gros fichiers, prenez une distribution Linux si vous n'avez rien d'autre sous la main ^^ ).
Autre chose, il vous faudra aussi modifier la valeur de la constante upload_max_filesize et y mettre la même valeur (ou plus) que celle de apc.max_file_size si vous voulez que l'upload se déroule correctement.
Une dernière chose : Les utilisateurs de Linux pourront éviter l'envoi de gros fichiers en utilisant Trickle. Celui-ci permet la limitation de la bande passante par le biais d'une simple commande comme ci-dessous : trickle -u 20 -d 500 firefox -profilemanager --no-remote
Ainsi, cette commande permet de limiter l'upload à 20Ko/s et le download à 500Ko/s pour l'application Firefox. Les options "-profilemanager --no-remote", servent à empêcher l'ouverture de la fenêtre dans une instance existante de Firefox (ce qui a pour effet d'annuler la commande trickle). Ce sera quand même plus simple pour faire vos tests :) .
Voilà pour la configuration d'APC sur votre ordinateur. Vérifions maintenant si votre hébergeur a activé l'extension ou non.
Vérifier l'activation d'APC chez son hébergeur :
La vérification de l'initialisation d'une extension est très simple, il vous suffit de créer un fichier PHP y mettre la ligne suivante <?php phpinfo(); ?> et ensuite exécuter le fichier chez votre hébergeur web.
Si l'extension est activée vous devriez voir apparaître ceci à un moment :
Pensez bien à vérifier que l'extension est active en regardant la première ligne, celle-ci doit indiquer enabled comme sur l'image ci-dessus. Autre chose, la constante apc.rfc1867 doit être à On ou bien vous ne pourrez vous servir de la principale fonctionnalité d'APC (autrement dit, la progression de l'upload d'un fichier).
Si tout est bon, notez quelque part les valeurs des constantes suivantes car nous en aurons besoin par la suite :
apc.max_file_size
apc.rfc1867_name
apc.rfc1867_prefix
Voilà, c'est tout pour la vérification de l'activation d'APC.
Comme vous pouvez le constater, le formulaire opère exactement de la même façon qu'avec un simple upload par Iframe. Il y a seulement une ligne supplémentaire qui est celle-ci :
Le rôle de cette ligne est de permettre à APC d'identifier le fichier dont vous souhaitez connaître les informations d'upload, il s'agit là d'une clé rfc1867 (rappelez-vous, je vous avais demandé vérifier que la constante apc.rfc1867 était à On et bien c'était pour permettre l'identification du fichier uploadé). Son utilisation est simple, on crée un input de type "hidden" et on défini ses attributs. L'attribut "name" doit être de la même valeur que celle de la constante apc.rfc1867_name que je vous avais demandé de relever plus haut (par défaut il s'agit de APC_UPLOAD_PROGRESS). Quant à l'attribut "value", on va faire simple et lui attribuer un id unique grâce à la fonction PHP <?php uniqid(); ?> .
Cette valeur que nous lui avons attribué servira donc à "indexer" le fichier lorsqu'il sera en cours d'upload, ainsi on pourra récupérer les informations le concernant grâce à une requête Ajax.
Alors le formulaire c'est bien, mais si on affiche pas les informations sur la progression de notre upload c'est pas génial :-° ... Voici donc le code HTML tout bête pour cela, insérez-le où vous le souhaitez :
Voyons maintenant la requête PHP pour la progression de l'upload ! Celle-ci sera exécutée par le biais d'un script Ajax, créez donc un fichier nommé "verifUpload.php" et insérez-y le code suivant :
La variable $_POST['keyFile'] contient la clé rfc1867 du fichier dont on veut connaître les informations d'upload, on vérifie donc qu'elle est bien initialisée. Une fois cette vérification faite, on appelle la fonction apc_fetch() en spécifiant en argument la concaténation entre la valeur de la constante apc.rfc1867_prefix et la variable $_POST['keyFile'].
La fonction apc_fetch() retournera alors un tableau contenant diverses informations concernant le fichier dont vous voulez suivre l'upload. Mais il y a un problème : le tableau retourné est en PHP, or on veut analyser ce code par le biais de Javascript, il nous faut donc encoder le tableau avec la fonction json_encode() et renvoyer le tout au Javascript. Quand ce dernier aura réceptionné les informations, il n'y aura plus qu'à utiliser la fonction eval() pour créer le tableau en Javascript.
Concernant les différents valeurs de ce tableau, je vous en parlerai plus bas.
Le code Javascript :
Bien, maintenant que nous avons notre formulaire et notre fichier PHP de prêts nous allons pouvoir passer au code Javascript. Pour vérifier l'état de la progression, il va nous falloir faire appel au fichier "verifUpload.php" par le biais de l'objet XMLHttpRequest.
Tout d'abord, il nous faut une fonction d'initialisation de ce dernier que vous nommerez getXHR(), je vous laisse faire, vous êtes normalement capable de la réaliser sans problème.
Il nous faut maintenant une fonction faisant appelle au fichier "verifUpload.php" et traitant les informations reçues :
Voyons plus en détail ce code : Tout d'abord, on récupère la clé rfc1867 contenue dans le input caché de notre formulaire puis on l'envoi par la méthode POST au fichier "verifUpload.php", celui-ci renvoi par la suite le tableau associé à ce fichier. À ce moment, c'est cette partie du code qui prend le relai :
Tout d'abord, vu que l'on reçoit un tableau écrit en Javascript, il nous faut "l'émuler" par le biais de la fonction eval(). Vous constaterez que j'ai mis des parenthèses autour, c'est pour corriger un bug qui fait que l'émulation échoue sans elles ;) .
Ensuite, vu que l'on a notre tableau, il ne nous reste plus qu'à afficher les valeurs que l'on souhaite dans notre page HTML. Je ne pense pas qu'il y ait besoin de vous expliquer quoi que ce soit à ce niveau là si ce n'est qu'à un moment vous pouvez voir un calcul, il ne s'agit en fait que d'un simple calcul de pourcentage.
Et enfin, le reste du code permet de vérifier si l'upload est terminé ou non : tant que done est différent de la valeur 1 alors l'upload n'est pas terminé, il nous faut donc continuer à exécuter notre fonction afin de continuer à recevoir les informations sur l'upload.
Autre chose, je ne vous ai toujours pas donné les valeurs que contient le tableau que vous recevez par le biais de PHP, voici donc une liste des informations que vous pouvez récupérer :
filename : Le nom du fichier complet qui a été uploadé.
name : La valeur de l'attribut name de l'input qui contenait le chemin du fichier.
total : La taille totale du fichier à uploader en octets.
current : Poids uploadé en octets.
done : Précise si l'upload est terminé ou non : "1" pour oui, "0" pour non.
Il y a aussi 3 valeurs supplémentaires qui s'ajoutent lorsque done est à 1 :
temp_filename : Le chemin temporaire vers le fichier uploadé.
rate : Vitesse d'upload en octets par seconde (cette valeur n'est introduite qu'à partir de la version 3.1 d'APC, ce qui correspond normalement (et dans une configuration standard) à la version 5.2.5 de PHP).
cancel_upload : Spécifie si une erreur est apparue pendant l'upload, une valeur à "0" signifie que tout s'est bien déroulé. Si la valeur est différente de "0" alors je vous laisse vous référer à cette page pour en connaître la raison.
Bien, il ne nous reste qu'une seule et dernière petite chose mais ceci s'effectue au niveau de notre formulaire : il nous faut lancer la fonction verifUpload() dès que celui-ci est soumis. On ajoute donc onsubmit="verifUpload();" aux attributs de notre formulaire et celui-ci est maintenant prêt !
Essayer le code (Je n'ai que très légèrement modifié le code pour la présentation, vous devriez normalement vous y retrouver)
Voilà pour un upload simple. Je pense que cela vous aura suffit pour vous faire une idée sur le sujet, si vous voulez maintenant aller plus loin lisez la partie ci-dessous qui traite le multi-upload (elle est incomplète actuellement et j'en explique les raisons ;) ).
Concernant l'utilisation de eval() :
Alors oui, j'ai utilisé eval()... dans une fonction qui tourne en boucle en plus : OUTRAGE !! Alors pour ceux qui comprennent pourquoi je dis ça c'est bien, pour les autres c'est par ici.
Bref, si j'utilise cette fonction c'est pour faire court, mon but n'est pas de vous embrouiller avec un système de parsage XML qui permettrait de récupérer les informations sans eval() mais plutôt de vous montrer comment faire un upload avec APC. Donc si vous êtes motivé (ou même si vous ne l'êtes pas), je vous encourage à éviter l'utilisation de eval().
Voyons donc le multi-upload, dans cette partie mon but sera de vous faire prendre conscience d'un problème et de vous introduire à la façon de le résoudre, autrement dit, on ne va pas coder (ne fuyez pas §).
Voyez-vous le problème ? Le pourcentage de chaque upload est additionné à l'autre, en clair APC ne fait aucune distinction entre les deux, si ce n'est qu'il affiche le nom du fichier en cours d'upload. C'est un problème dans le sens que tous les uploads sont dépendants entre eux, ainsi on ne peut pas dire "je veux annuler tel upload" ou bien les repositionner.
La solution ? Oui, il y en a une (même si je n'ai pas encore réussi à l'appliquer :-° ) : Uploader chaque fichier dans un formulaire séparé ainsi on pourra bénéficier des informations individuelles de chaque fichier. Pour cela, il nous faudra créer un script permettant l'ajout de fichier ainsi que leur formulaire attitré puis effectuer un premier upload, ensuite effectuer le second, le troisième, etc...
L'affichage :
Le principe du code est assez simple à comprendre : On affiche un input file, dès que sa valeur est modifiée alors on le cache puis on ajoute son nom à la liste des fichiers à uploader avec un bouton de suppression, enfin il suffit de créer un nouvel input file vide afin que l'utilisateur puisse ajouter un nouveau fichier. Quand l'utilisateur cliquera sur le bouton de suppression cela aura pour effet de supprimer le nom du fichier dans la liste ainsi que l'input file qui lui était associé. Vous avez compris ? Si ce n'est pas le cas, voici un exemple de ce que je vous raconte.
L'upload :
C'est là que ça se complique. Le but est de parcourir les formulaires et effectuer les uploads les uns à la suite des autres, pour cela il nous faudra repérer le premier fichier et l'uploader, une fois cette opération effectuée, il faut passer au deuxième et ainsi de suite. Cela ne pose pas de réel problème car il ne s'agit que de parcourir le DOM et lancer les uploads au bon moment. Le véritable problème vient au niveau du suivi des fichiers : dans mes tests j'obtiens le suivi du fichier une fois que l'upload est terminé, pratique :-° . Autrement dit, ça m'affiche bien 100% d'upload une fois que celui-ci est terminé mais avant, rien...
APC étant une extension d'une stabilité encore assez douteuse, il se peut que ça vienne de là mais il ne faut pas non plus exclure les probables fautes dans mon code.
Voilà tout pour cette introduction, je suis bien navré de ne pouvoir vous en fournir plus mais mon cerveau sature un peu là donc il vous faudra sûrement attendre encore un peu...
Ce chapitre est maintenant terminé, j'espère que vous nous ferez de beaux formulaires avec APC (enfin si vous avez un hébergeur compatible >_ ).

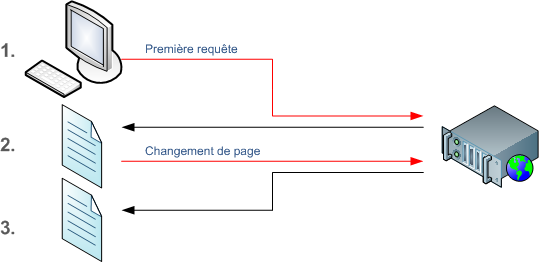
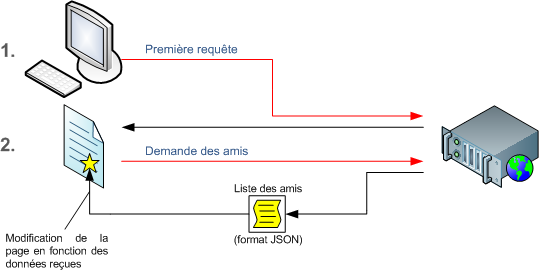









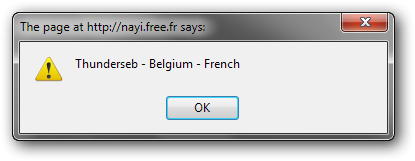

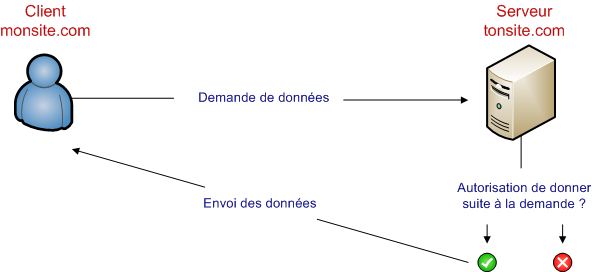
{kind=link}
{kind=link}