Vous voudriez apprendre à programmer mais ne savez pas par où commencer ? Vous avez commencé à apprendre le C mais vous vous embrouillez dans les accolades et autres symboles bizarroïdes ? Ou encore vous souhaitez apprendre un nouveau langage de programmation ? Alors ce tutoriel est fait pour vous.
Le langage Ada est certainement le meilleur langage pour apprendre à programmer : pour peu que vous connaissiez deux ou trois mots d'anglais, il vous sera facile de lire un code en Ada. Moins abstrait que beaucoup de langages, mais toutefois rigoureux, facilement compréhensible et lisible, même par un novice ... le langage Ada vous permettra de comprendre les logiques propres à la programmation et vous donnera tout de suite de bonnes habitudes.
Qui plus est, le langage Ada ne présente ni plus ni moins de fonctionnalités que les langages les plus connus (C, C++, Java, Python...). Il est seulement différent et, je me répète, plus compréhensible pour un novice.
Alors si vous êtes intéressé, nous allons pouvoir débuter de tutoriel. ;)
Ce tutoriel est prévu pour être organisé en six parties :
La partie I constitue une introduction à la programmation et vous accompagne dans votre première prise en main d'Ada.
Les parties II, III et IV traitent (ou traiteront) du langage Ada en lui-même et présenteront une difficulté progressive.
La partie V constituera une mise en pratique en vous proposant de créer des programmes fenêtrés avec GTK et Ada.
La partie VI fournira les annexes à ce tutoriel : FAQ, Glossaire, présentation de librairies tierces ...
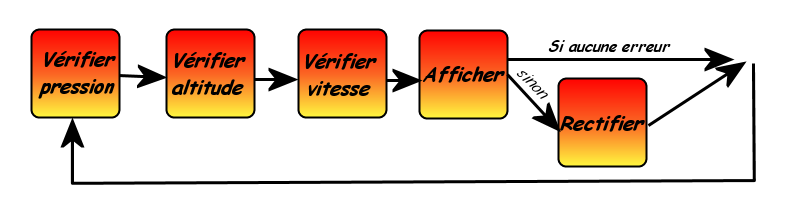
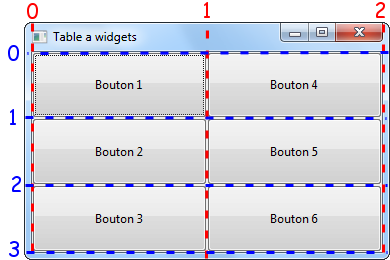
Le cours sera ponctué de travaux pratiques. Ce sont des chapitres vous proposant un projet (parfois ludique) allant du logiciel de gestion de vos DVD à des jeux de dés. Ils seront pour vous l'occasion de mettre en application vos connaissances acquises. Ces travaux pratiques sont signalés dans leur titre par la notation [TP#] (le symbole # étant remplacé par le numéro du TP). De plus, ils portent tous l'icône :
Nous allons dans ce chapitre répondre à quelques questions préliminaires. Qu'est-ce qu'un programme ? A quoi cela ressemble-t-il ? Comment crée-t-on un programme ? Qu'est-ce que l'algorithmique ? Pourquoi Ada et pas un autre langage ? Ce que j'apprends ici sera-t-il utilisable avec un autre langage ?
Bref, beaucoup de réponses existentielles trouveront (je l'espère) leur réponse ici. Ce chapitre, relativement court et sans difficultés, permettra de poser un certain nombre d'idées et de termes. Pour bien commencer, mieux vaut en effet que nous ayons le même vocabulaire. ;)
A ceux qui auraient déjà des notions de programmation, vous pouvez bien entendu éviter ce chapitre quoique je ne saurais trop vous conseiller d'y jeter un œil, histoire de remettre quelques idées au clair.
Avant de commencer, il est important que nous nous entendions sur les termes que nous allons utiliser.
Qu'appelle-t-on programme ?
Les programmes sont des fichiers informatiques particuliers. Sous Windows, ce sont généralement des fichiers se terminant par l'extension .exe ; sous MacOS ce sont globalement des fichiers .app ; sous Linux ce sont schématiquement des fichiers .bin. Cette explication est très (TRÈS) schématique, car d'autres types de fichiers peuvent correspondre à des programmes.
Ces fichiers ont comme particularité de ne pas seulement contenir des données, mais également des instructions. Lorsque vous ouvrez un fichier .exe sous windows, celui-ci transmet à votre ordinateur une liste de choses à faire comme :
ouvrir une fenêtre
afficher du texte
effectuer des opérations
...
Cette liste d'instructions envoyées au processeur, forme alors ce que l'on appelle un processus.
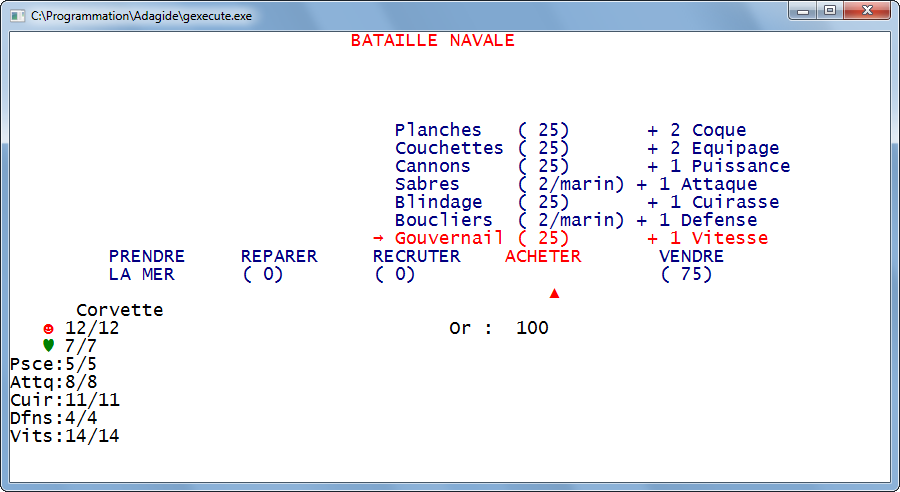
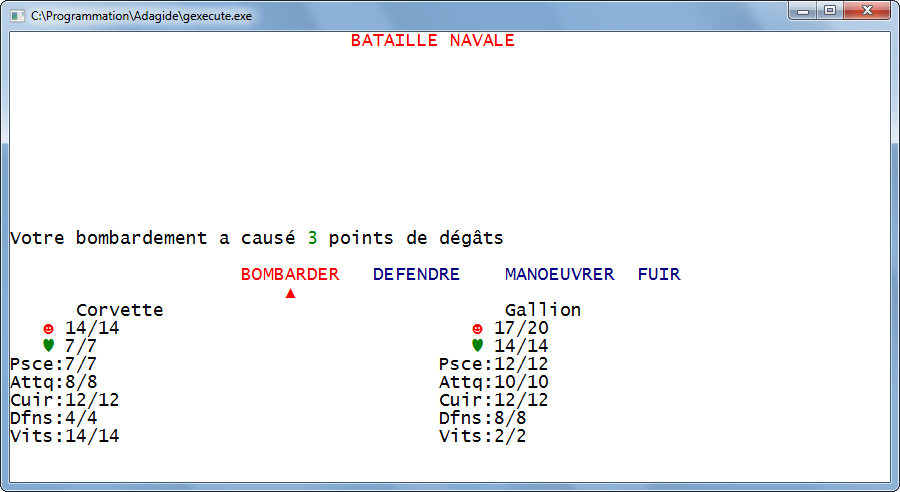
Voici quelques images de programmes :
Attention, tous les programmes ne sont pas nécessairement visibles. Beaucoup n'ouvrent même pas de fenêtre ! Pour s'en rendre compte, sous Windows, appuyez simultanément sur les touches Alt + Ctrl + Suppr puis cliquez sur le second onglet, cela affichera la liste de tous les processus en cours.
Bon nombre d'entre eux effectuent des tâches tranquillement sans que vous ne vous en rendiez compte.
Alors qu'allons-nous faire ?
Eh bien, programmer (en Ada ou autre) c'est tout simplement créer des programmes. Mais je vous arrête tout de suite, malgré tout le talent de votre humble guide, :p vous ne confectionnerez pas un jeu vidéo en 3D d'ici la fin de ce tutoriel. La plupart des logiciels, comme le navigateur internet que vous utilisez actuellement, exigent la participation de nombreuses personnes et de nombreuses autres compétences ne relevant pas de ce cours (modélisation 3D par exemple).
Les premiers programmes que nous allons concevoir seront des programmes en console. C'est à dire qu'ils ressembleront à ce qui suit :
Nous ne pourrons utiliser que le clavier ! Pas de souris ou de joystick ! Pas d'images ou de vidéos ! Pas de 3D puisqu'il n'y aura même pas de 2D ! Que tu texte blanc sur fond noir.
:waw: Aaargh ! Mais, c'est possible ?
Bon, c'est vrai qu'aujourd'hui on a tendance à oublier la console, mais il est nécessaire de passer par ce stade pour apprendre les bases de la programmation. Nous pourrons ensuite nous atteler à des programmes plus conséquents (avec des boutons, des images, la possibilité d'utiliser la souris ... ). Il faudra être patient ;)
Alors comment faire pour créer votre propre programme ? Il faut avant tout savoir comment est constitué un programme (ou tout autre type de fichier). Vous le savez peut-être déjà, mais un ordinateur a un langage très très basique. Il ne connaît que deux chiffres : 1 et 0 ! Donc tout fichier (et donc tout programme) ne peut ressembler qu'à ceci :
10001001111010110110111011011 ...
Ca rappelle Matrix ! :lol: Mais comment je fais moi ? J'y comprends rien moi à tous ces chiffres ? Il faut faire Math sup pour afficher une fenêtre ?
Non, rassurez-vous. Personne n'est capable de créer un programme informatique ainsi. C'est pourquoi ont été inventés différents langages pour la programmation : le Pascal, le Basic, le C, le C++, le Python, le Java ... et bien sûr l'Ada. Ce sont ce que l'on appelle des langages de haut niveau. A quoi cela ressemble-t-il ? voyez vous-même :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure exemple is
n : integer ;
begin
loop
Put("Saisir un nombre : ") ;
Get(n) ; Skip_line ;
if n mod 2 = 0
then Put("Ce nombre est pair ! Tres bien !") ; exit ;
else Put("Ce nombre est impair ! Recommencez. ") ;
end if ;
end loop ;
end exemple ;
Vous serez capables d'ici quelques chapitres de comprendre ce texte aisément. C'est comme apprendre une langue étrangère ; d'ailleurs si vous connaissez l'Anglais vous avez peut-être reconnu quelques mots (end, if, else, then, begin, is). C'est ainsi que nous créerons nos programmes.
Et comment on traduit ça en 1 et en 0 ?
Une fois notre texte rédigé en Ada (mais c'est aussi valable pour les autres langages), il faudra utiliser un programme-traducteur pour le convertir en un programme lisible par l'ordinateur. Les programmes-traducteurs sont appelés compilateurs.
Il ne vous reste donc plus qu'à apprendre un langage de programmation, et avec ce langage, vous apprendrez également ce que l'on appelle l'algorithmique.
Qu'est-ce que c'est encore que ça ?
L'algorithmique est une branche des mathématiques qui traite de la résolution de problèmes à l'aide d'instructions simples. J'en vois déjà certains qui paniquent à la vue du mot "Mathématiques", mais n'ayez crainte vous avez déjà vu plusieurs fois dans votre vie des algorithmes. Par exemple, comment faire pour diviser 742 par 5 ? Vous vous souvenez, c'était en primaire ? Vous aviez appris à poser l'opération comme ci-dessous et à répéter les instructions suivantes :
Dans 7, combien de fois 5 ?
Il y va 1 fois et il reste 2 !
On abaisse le 4 derrières le reste. Dans 24, combien de fois 5 ? Il y va 4 fois et il reste 4.
On abaisse le 2 derrières le reste. Dans 42, combien de fois 5 ? Il y va 8 fois et il reste 2.
Il n'y a plus de chiffre à abaisser. On arrête : le résultat est 148 et il reste 2 !.
Eh bien ça, c'était un algorithme : vous répétiez des instructions simples dans un certain ordre (abaisser les chiffres de 742, se demander "dans machin, combien de fois truc ?"...) afin de résoudre un problème plus compliqué (combien vaut ?). Et tout programme informatique n'est en fait qu'un algorithme écrit dans un langage compréhensible par votre ordinateur. Donc apprendre à programmer, c'est en fait apprendre la science de l'algorithmique dans un langage informatique donné.
Pourquoi Ada ?
Mais alors, pourquoi apprendre l'Ada et pas simplement l'algorithmique ? Et pourquoi l'Ada et pas un autre langage ?
Tout d'abord, l'algorithmique n'est pas compréhensible par les ordinateurs, je vous rappelle que c'est une science. L'algorithme de la division euclidienne vu au-dessus est expliqué en Français, or je vous ai dit qu'il doit être écrit dans un langage qui pourrait être traduit par un compilateur, un langage très structuré et normé (qui ne changera pas en changeant de compilateur), et ça c'est ce qu'on appelle la programmation. Et l'Ada répond à ces exigences.
Maintenant, pourquoi Ada et pas un autre langage ? Il est vrai que l'Ada n'est pas le langage le plus répandu. Mais il présente de nombreux avantage par rapport à d'autres langages plus répandus comme le C, le C++, le Java ...
Tout d'abord il présente un avantage pédagogique. Ada consitue un langage parfait pour apprendre à programmer. D'ailleurs de nombreuses écoles ou universités l'utilisent comme support à leurs cours de programmation. La rigueur qu'il impose au programmeur permet aux débutants d'apprendre à coder correctement, de prendre de bonnes habitudes qu'ils conserveront par la suite, même s'ils venaient à changer de langage de programmation durant leur carrière. Qui plus est, c'est un langage facilement lisible car il utilise des mots complets (begin, end, function, if ... c'est de l'Anglais en effet) plutôt que les symboles "barbares et bizarroïdes" pour un débutant que préfèrent la plupart des langages actuels. Les codes des programmes sont certes moins condensés, mais plus faciles à reprendre en cas de bogue ce qui constitue un avantage non négligeable quand on sait que les coûts de maintenance d'un logiciel sont souvent plus élevés que le coût de son développement.
Ensuite, le langage présente également des avantages pour les professionnels. Son fort typage (vous aurez l'occasion de le découvrir durant la deuxième partie) ou sa très bonne gestion des erreurs (abordé lors de la quatrième partie) garantissent des programmes fiables. Ce n'est pas pour rien qu'Ada est utilisé pour de gros projets comme Ariane, chez Thalès pour ses avions ou radars, ou encore pour la sécurité des centrales nucléaires, du trafic aérien ou ferroviaire ... Utiliser Ada est un gage de fiabilité et pour cause, il a été développé par le département de la défense américain, le fameux DoD (vous vous doutez bien que rien n'a été laissé au hasard ;) ).
Maintenant que ces quelques explications préliminaires sont faites, j'espère que vous vous sentez toujours prêts à vouloir apprendre un langage. Si cela vous semble compliqué, n'ayez crainte, nous commencerons doucement et je vous guiderai pas à pas. Nos premiers programmes seront peut-être inutiles ou ringards, mais nous apprendrons peu à peu de nouvelles notions qui nous permettront de les perfectionner.
Alors, en avant pour l'installation des logiciels nécessaires ! :pirate:
Nous allons au cours de ce chapitre, télécharger et installer les logiciels nécessaires à l'utilisation d'Ada.
Comment ça LES logiciels ? Il n'y a pas un seul logiciel Ada ?
Eh bien non. Comme tout langage, Ada a besoin de deux types de logiciels : un éditeur de texte avancé (appelé IDE) et un compilateur. Nous utiliserons l'IDE appelé Adagide (même si le logiciel GPS pourra être utilisé) et le compilateur GNAT. Après quoi nous pourrons découvrir (enfin) le joyeux monde de la programmation.
Nous avons dors et déjà parlé du compilateur : il s'agit d'un programme qui va traduire notre langage Ada en un vrai programme utilisable par l'ordinateur. Le compilateur est aussi chargé de vérifier la syntaxe de notre code : est-il bien écrit ? Sans fautes d'orthographe ou de grammaire ? Il existe plusieurs compilateurs en Ada, mais rassurez-vous, quel que soit celui que vous choisirez, les règles sur le langage Ada seront toujours les mêmes car Ada est un langage normé (il bénéficie d'une norme internationale assurant que tous les compilateurs Ada respecteront les mêmes règles). Il existe plusieurs compilateurs Ada (vous en trouverez une liste à l'adresse suivante), mais la plupart sont des programmes payants et propriétaires.
Euh ... c'était pas prévu au contrat ça ! o_O
Rassurez-vous, nous allons plutôt opter pour un compilateur libre et gratuit. ;) Ce compilateur s'appelle GNAT et est développé par la société Adacore. Il a longtemps été payant mais une version gratuite existe désormais (GNAT GPL).
L'IDE ou EDI
Mais le compilateur n'est en définitive qu'un "traducteur". Il ne créera pas de programme à votre place, c'est à vous d'écrire les instructions dans des fichiers textes. Pour cela, vous pouvez écrire vos documents sous l'éditeur de texte de votre ordinateur (notepad sous Windows par exemple), ou utiliser un éditeur de texte un peu plus avancé comme Notepad++ qui colorera votre texte intelligemment en reconnaissant le langage dans lequel vous programmerez (on appelle ça la coloration syntaxique).
Mais le plus intelligent est d'utiliser un Environnement de Développement Intégré, EDI en Français ou IDE en Anglais. Pourquoi ? Eh bien parce que ce logiciel vous fournira un éditeur de texte avec coloration syntaxique (waaah... :euh: ) et surtout vous permettra de compiler votre texte aisément, sans avoir à chercher votre compilateur et lui entrer tout plein de paramètres auxquels vous ne comprenez rien. :p Qui plus est, un IDE vous fournira divers outils utiles à la programmation.
L'IDE que nous allons utilisé s'appelle Adagide et il est gratuit.
Cliquez ici pour télécharger Adagide dans sa version 7.45 (dernière en date à l'heure où j'écris ces lignes). Puis cliquez sur "adagide-7.45-setup.exe" pour lancer le téléchargement de l'installateur.
Installation
L'installation d'Adagide ne devrait pas vous poser de problèmes. Il vous suffit de suivre les différentes étapes en cliquant sur suivant. Acceptez les termes de la licence et à l'écran "Setup Type" choisissez "Typical".
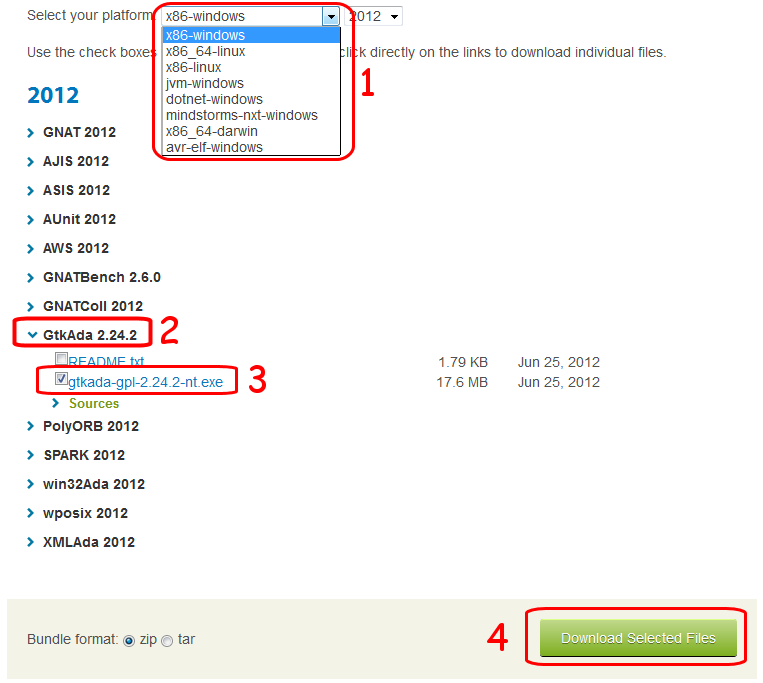
Pour télécharger le compilateur GNAT GPL, rendez-vous sur le site d'Ada Core en cliquant ici.
Si vous êtes sous Windows, vérifiez que le système d'exploitation est bien "x-86 Windows" (à la ligne "Select your platform"), puis cliquez sur GNAT_GPL et sélectionnez "gnat-gpl-2011-i686-pc-mingw32-bin.exe". Enfin, tout en bas de la page, cliquez sur le bouton "Download selected files".
Pour les utilisateurs de Linux, le système d'exploitation devrait être "x86 - Linux" (ou "x86_64 - Linux" si votre processeur est en 64 bits). De la même manière que sous Windows, cliquez sur GNAT_GPL et sélectionnez "gnat-gpl-2011-i686-gnu-linux-libc2.3-bin.tar.gz". Pour finir, cliquez sur le bouton "Download selected files" en bas de page.
Installation
L'installation est un poil plus compliquée (même si ça ne casse pas trois pattes à un canard, comme dirait ma grand-mère :p ). Le fichier téléchargé s'appelle "AdaCore.tar" et ce n'est pas un programme d'installation, seulement un fichier compressé. Pour le décompresser, utilisez un logiciel comme Winrar ou 7zip. Sous Linux, vous pouvez procéder graphiquement ou par la console. Dans le second cas, vous devrez taper la commande suivante :
tar -xvzf gnat-gpl-2011-i686-gnu-linux-libc2.3-bin.tar.gz
Sous Windows, vous obtiendrez ainsi le fameux fichier d'installation "gnat-gpl-2011-i686-pc-mingw32-bin.exe". Ouvrez-le et suivez les différentes étapes. Je vous conseille de sélectionner l'option "Install for all users", notamment si votre ordinateur dispose de plusieurs sessions, à moins que vous ne vouliez être le seul à pouvoir programmer en Ada.
Sous Linux, l'installation se fera via le fichier script appelé "doinstall". Celui-ci vous demandera si vous souhaitez installer GNAT et si oui où. Vous n'aurez qu'à appuyer deux fois sur entrée puis répondre "Yes" aux deux dernières questions en appuyant sur les touches Y ou y.
GPS est un autre IDE, mais développé par AdaCore. Il est un peu plus compliqué et j'avoue ne pas avoir réussi à le démarrer sous mon PC Windows personnel (même s'il fonctionne sur mon PC Windows de bureau ou sous mon PC Ubuntu :( ). Adagide a l'avantage d'être simple et performant, je le préfèrerai donc à GPS. Mais si vous souhaitez tout de même utilisez GPS, sachez qu'à cette étape du chapitre ... il est déjà installé ! :p Cet IDE est en effet livré avec GNAT, vous pourrez donc le tester si la curiosité vous prend : il suffit d'aller dans le menu démarrer > Programmes > GNAT > 2010 > GPS.
Bien ! Nous voilà fin prêts pour réaliser notre premier programme ! Nous allons dès le prochain chapitre entrer dans le vif du sujet. Alors soyez prêts, à vos armes ! :pirate:
Bon, nous avons installé notre IDE, Adagide, notre compilateur, GNAT. Je sens que vous commencez à perdre patience. Nous allons immédiatement pouvoir nous atteler à notre premier programme en Ada. Il s'agira de créer un programme qui nous salue.
Bon, c'est sûrement pas folichon comme objectif, mais c'est un début. Voyons ici la démarche que nous allons suivre.
Tout d'abord, nous allons faire un petit tour d'horizon des logiciels Adagide et GPS. Je vous rassure, ce sera rapide.
Puis nous écrirons notre premier programme et nous le testerons.
Enfin, nous essaierons de décrypter notre premier programme
Avant de commencer le prochain chapitre je vous proposerai quelques petits suppléments et exercices pour vous entraîner.
Pour pouvoir programmer, nous avons déjà expliqué que nous aurons besoin de l'IDE Adagide. Donc, lancez Adagide ! Vous voilà donc face à une fenêtre tout ce qu'il y a de plus ... austère :( Mais rassurez-vous, cela n'a que peu d'importance pour nous.
Tout d'abord nous allons créer un nouveau document. Pour cela, cliquez sur File > New ou sur l'icône "Nouveau" indiqué ci-dessus. Vous pourrez également à l'avenir ouvrir un document existant en cliquant sur File > Open ou sur l'icône "ouvrir".
Pour l'heure, nous allons enregistrer notre document. Cliquez sur File > Save as ou sur l'icône "enregistrer". Je vous conseille de créer un répertoire que nous nommerons "Hello", et dans ce répertoire nous allons enregistrer notre document (appelons-le également Hello). Vous remarquerez que l'extension proposée est adb. Notre code en Ada portera le nom de Hello.adb ; par la suite nous verrons à quoi peut servir l'extension ads qui est également proposée.
Bien entendu, il est possible d'écrire dans la fenêtre principale, la taille du texte pouvant être modifiée en cliquant sur le bouton "taille". En revanche, il est impossible d'écrire dans la partie basse de la fenêtre, celle-ci étant réservée au compilateur. C'est ici que le compilateur affichera les informations qui vous seront nécessaires : échec de la compilation, réussite de la compilation ...
Pour les utilisateurs de GPS (plus long)
Le logiciel GPS est un peu plus compliqué que Adagide. Il est toutefois mieux adapté à de gros projets, ce qui explique qu'il soit plus complexe et donc moins adapté pour ce cours. Lorsque vous lancez GPS, une fenêtre devrait vous demander ce que vous souhaitez faire.
Pour l'heure, choisissez "Create new project with wizard" et cliquez sur OK. Choisissez l'option "Single project" puis cliquez sur Forward. Choisissez un nom pour votre projet (j'ai choisi HelloWorld) et précisez un répertoire où l'enregistrer (je vous conseille de créer un répertoire spécifique par projet). Cliquez ensuite sur Apply sans renseigner les autres informations. Vous devriez arriver à l'écran suivant :
La fenêtre est découpée en quatre zones. La première ne nous intéresse pas pour l'instant. La seconde, juste en dessous affichera les fichiers et programmes de votre projet. Pour l'heure vous n'aurez qu'un seul fichier donc cela ne comportera pas d'intérêt pour les premiers cours. Son utilité se révèlera à partir de la Partie III. La troisième zone de la fenêtre est la zone principale, celle où vous rédigerez votre programme. Enfin, la quatrième zone est celle réservée au compilateur et à la console. Vous comprendrez son utilité bientôt.
Commençons donc par créer un nouveau fichier en cliquant sur l'icône "Nouveau" ou sur File > New. Sauvegardez tout de suite votre fichier en cliquant soit sur l'icône "Enregistrer" soit sur File > Save As. Votre fichier devra s'appeler Hello.adb" (même si vous n'avez pas besoin d'écrire l'extension). Comme je vous le disais plus haut, il existe également un fichier .ads que nous verrons plus tard et que le logiciel GPS gère aussi. Pour ouvrir un document, vous pourrez utiliser l'icône "Ouvrir" ou sur File > Open.
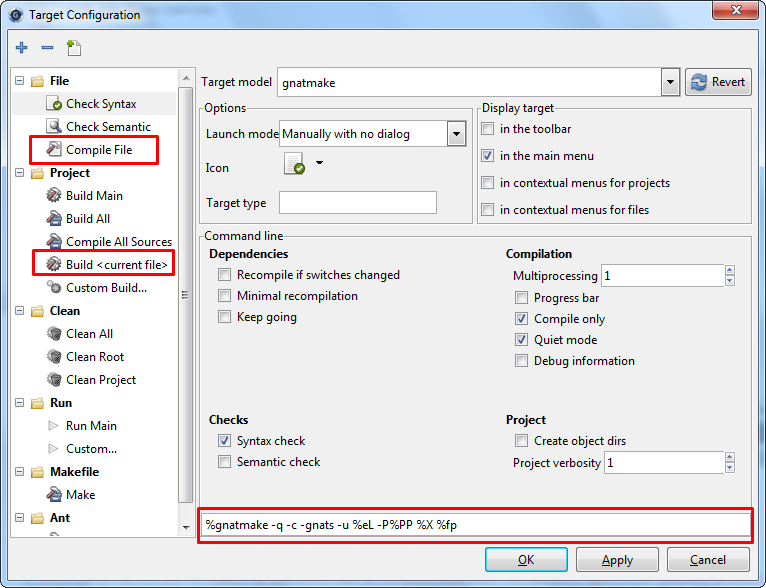
Voila pour l'essentiel, toutefois, je vais vous demander d'effectuer deux petites manipulations avant d'aller plus loin afin d'ajouter deux icônes importants. Cliquez sur le menu Build > Settings > Targets. Une fenêtre devrait s'ouvrir.
A gauche, dans la section Project, cliquez sur Build <current file> et cochez la case In the toolbar. Puis, dans la section Run, cliquez sur Custom et cochez la case In the toolbar. Enfin, cliquez sur le bouton Apply. Les deux icônes suivants devraient s'ajouter (retenez-les bien).
Maintenant que nous avons, rapidement, pris connaissance du logiciel, il est temps de nous lancer corps et âme dans la création de notre magnifique programme Hello ! Nous allons pour cela effectuer une opération de haute voltige : un copier-coller ! Voici le code d'un programme, ne cherchez pas à comprendre pour l'instant, je vous expliquerai par la suite. Pour l'heure, sélectionnez le texte, copiez-le et collez-le dans votre fichier Hello.adb sans poser de questions.
with ada.text_io ;
use ada.text_io ;
procedure Hello is
--partie réservée aux déclarations
begin
put("Salut tout le monde !") ; --on affiche un message
end Hello ;
Vous remarquerez que certains mots sont automatiquement colorés, je vous en ai déjà parlé c'est la coloration syntaxique. Elle permet de faire ressortir certains mot-clés (Adagide colore par défaut en bleu les mots réservés au langage Ada) ou certains types de texte.
Avant d'aller plus loin, si vous êtes sous Adagide (GPS effectuera cette manœuvre tout seul le moment venu), il serait bon de cliquer sur l'icône "Reformat", il est simple à trouver, c'est celui avec un grand R dessiné dessus. Cela va mettre votre code en forme : la ligne entre is et begin et la ligne entre begin et end vont être "avancées" à l'aide d'une tabulation (trois espaces sous adagide). On appelle ça l'indentation. Ca n'a l'air de rien mais c'est très important car à l'avenir votre code pourra s'étendre sur plusieurs pages, il est donc important qu'il soit le plus lisible possible. Lorsque l'on rédige un roman, on crée des paragraphes, des chapitres ... en programmation on indente son texte.
Compiler, créer ... lancer !
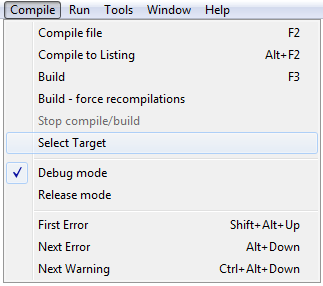
Maintenant que votre texte est écrit et mis en forme, il est temps de le faire fonctionner. Nous allons donc utiliser le compilateur. Pour cela, rien de plus simple, cliquez sur l'icône "Compiler" (ou appuyer sur F2 avec Adagide, ou encore Compile > Compile File). Le compilateur vérifiera la syntaxe de votre code. S'il n'y a pas d'erreur (et il ne devrait pas y en avoir), le compilateur devrait vous indiquer (dans la fenêtre du bas) "Completed successfully".
Mais à ce stade, votre programme n'existe pas encore, vous devez construire l'exécutable. Pour cela cliquez sur l'icône "construire" (ou appuyez sur F3 avec Adagide ou cliquez sur Compile > Build).
Pour les utilisateurs de GPS, les manipulations étant un peu longues, je vous conseille d'utiliser les icônes (c'est bien pour cela que je vous ai fait faire une petite manipulation préliminaire). Lorsque vous cliquerez sur l'icône "Construire", une fenêtre peut s'ouvrir. Ne vous souciez pas des paramètres et cliquez sur OK.
Votre fichier exécutable est désormais créé. Vous pouvez soit aller le chercher dans le répertoire Hello que vous avez créé tout à l'heure, soit cliquer sur l'icône "Exécuter" (ou appuyer sur F4 avec Adagide ou cliquer sur Run > Execute). Sous GPS, une fenêtre s'ouvrira. Ne cochez aucune case et, si la barre de texte est vide, écrivez-y le nom de votre programme : Hello (sans extension !). Puis cliquez sur OK.
Avec Adagide, vous devriez ainsi obtenir une magnifique fenêtre noire vous indiquant :
Salut tout le monde !
(Sous GPS, ces actions apparaîtront dans la fenêtre du compilateur, c'est à dire la quatrième zone de la fenêtre)
Euh ... comment dire ... c'est tout ? J'ai lu tous ces chapitres pour voir ça !!! :colere:
Ne perdez pas patience. Le chemin sera long avant que vous ne puissiez créer un programme digne d'intérêt. :ange: Prenons le temps de décortiquer ce que nous avons copié pour mieux comprendre.
Si nous jetons un œil à notre code nous pouvons nous rendre compte qu'il peut se décomposer en deux parties majeures : une sorte de titre (avec with et use) et un gros paragraphe (commençant par le mot procedure).
Le corps du programme : la procédure Hello
Le titre étant un peu compliqué à expliquer, nous allons commencer par nous intéresser au "gros paragraphe" : la procédure appelée Hello. Elle peut se décomposer elle-même en deux parties comme sur l'image ci-dessus.
Les trois bornes de la procédure
Pour l'instant, disons que le terme de "procédure" est un synonyme de "programme". Notre paragraphe commence donc par l'introduction suivante : procedure Hello is. Cette phrase permet de donner un nom à notre procédure et indique le début du texte la concernant. Remarquez que les mots procedure et is sont colorés en bleu : ce sont des mots réservés par le langage Ada, ils ont donc un sens très précis et ne peuvent être utilisés n'importe comment.
Deuxième "borne" de notre procedure : le terme begin. C'est lui aussi un mot réservé. Il indique au compilateur le début des instructions que le programme devra exécuter.
Troisième "borne" : le mot end, ou plus exactement la phrase : "end Hello ; ". Cette phrase indique au compilateur la fin de la procédure Hello. À noter que contrairement aux deux bornes précédentes, cette phrase se termine par un point-virgule. Si vous oubliez de l'écrire, le compilateur vous avertira : missing ";" !
La partie déclarations
Les trois bornes vues précédemment délimitent deux zones. La première, celle comprise entre is et begin est réservée aux déclarations. Nous verrons dans les prochains chapitres de quoi il retourne, sachez pour l'instant qu'il faut prévenir votre ordinateur lorsque avez besoin de réquisitionner de la mémoire (et nous aurons besoin d'en réquisitionner) et que c'est dans cette partie que s'effectueront ces "demandes de réquisition". Pour l'heure, il n'y a rien.
Comment ça il n'y a rien ? Il y a bien quelque chose d'écrit : "--partie réservée aux déclarations"
Eh bien non. Pour le compilateur, il n'y a rien ! :p Cette ligne verte commence par deux tirets, c'est l'indication qu'il s'agit d'un commentaire, c'est à dire d'un texte qui ne sera pas pris en compte par le compilateur. Quel intérêt d'écrire du texte s'il n'est pas pris en compte par le compilateur ? Eh bien cela permet d'apporter des annotations à votre code. Si vous relisez un code écrit par quelqu'un d'autre ou par vous même il y a longtemps, vous risquez d'avoir du mal à le comprendre. Les commentaires sont donc là pour expliquer ce que fait le programme, à quoi servent telle ou telle ligne etc... un bon code est déjà un code bien commenté (et bien indenté également).
La partie actions et notre première instruction
Puis, après le begin, vient la partie la plus intéressante, celle où l'on indique au programme ce qu'il doit faire, autrement dit, c'est là que nous écrirons les différentes instructions.
L'instruction citée ici est : "Put("Salut tout le monde!") ;". C'est assez simple à comprendre : l'instruction Put() indique à l'ordinateur qu'il doit afficher quelque chose. Et entre les parenthèses, on indique ce qu'il faut afficher. Il est possible d'afficher un nombre (par exemple, Put(13) ; affichera le nombre 13) comme du texte, mais le texte doit être écrit entre guillemets.
Remarquez là encore que l'instruction se termine par un point-virgule. D'ailleurs, toutes les instructions devront se terminer par un point virgule, à quelques exceptions près (souvenez-vous de is et begin). Le texte qui suit est bien entendu un commentaire et tout ce qui suit les double-tirets ne sera pas pris en compte par le compilateur.
Il est bien sûr possible d'afficher autre chose que "salut tout le monde !" ou d'effectuer d'autres actions. Toutefois, lorsque toutes vos actions ont été écrites, n'oubliez pas d'indiquer au compilateur que vous avez atteint la fin en utilisant le mot end.
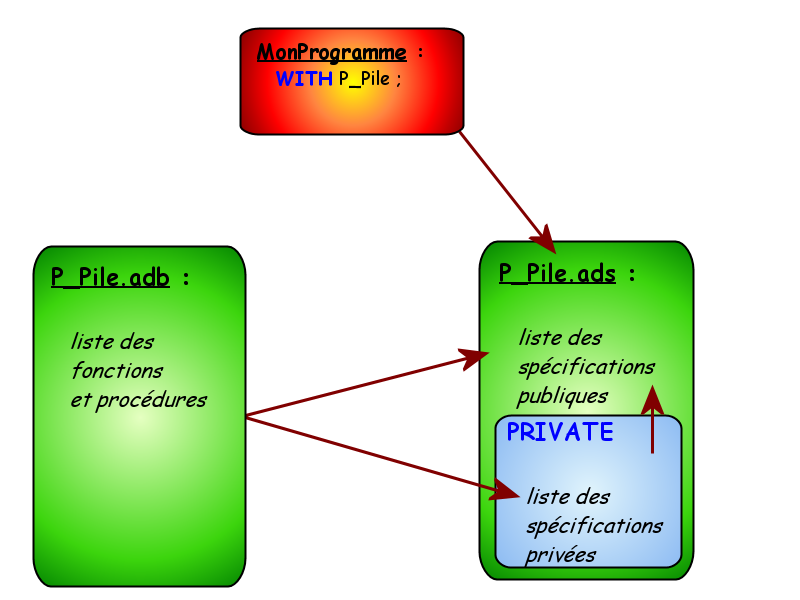
Les Packages avec With et Use
Le mot-clé WITH
Revenons maintenant au titre. Pourquoi cet intitulé ? Et d'ailleurs pourquoi l'écrire deux fois ? Je vous propose de le supprimer pour mieux comprendre. Compiler à nouveau votre code.
:waw: Argh ! ! ! Ca marche plus ! J'ai tout plein de messages rouge ! Tout est fichu !
En effet, le code n'est plus correct et ce n'est pas la peine d'essayer de reconstruire notre programme. Mais lisons les avertissements du compilateur. Tout d'abord : "Put" is undefined.
Cela signifie tout simplement que le compilateur ne connaît plus l'instruction Put() ! En effet, le compilateur ne connaît que très peu de mots et d'instructions : les mots réservés et puis c'est presque tout. Pour aller plus loin, il a besoin de fichiers qui contiennent d'avantage d'instructions comme l'instruction Put() par exemple qui se situe dans un fichier appelé Ada.Text_IO. Ces fichiers portent le nom de package en Ada (paquetages en Français). Dans d'autres langages, on parlerait de librairies.
Le compilateur nous dit également : possible missing "WITH Ada.Text_IO ; USE Ada.Text_IO ;". Traduction : ce serait bien de remettre les lignes que vous avez supprimé tout à l'heure ! Écoutons-le mais ne réécrivons que la première ligne (au tout début) :
WITH Ada.Text_IO ;
Le mot-clé USE
Réessayons de compiler.
Nouveau problème. Le compilateur m'indique : "Put" is not visible plus plein d'autres insultes incompréhensibles. Apparemment, il connait mon instruction Put() mais il n'arrive plus à la voir ?!?
Exactement. Et les lignes qui suivent indiquent que dans le package ada.Text_IO il y a plusieurs références à l'instruction Put(). En fait, il est possible après l'instruction with d'écrire de nombreux packages, autant que vous voulez même (nous verrons un exemple juste après). Mais il peut exister (et il existe) plusieurs instructions portant le nom Put(), du coup le compilateur ne sait pas d'où vient cette instruction. De laquelle s'agit-il ? Une solution est de remplacer Put() par Ada.Text_IO.Put() ! C'est compliqué, c'est long à écrire et nous aurons tout le loisir de comprendre tout cela plus tard. Donc une façon de s'épargner ces difficultés, c'est d'écrire notre instruction Use au tout début, juste après l'instruction with.
Ces deux lignes (appelées Context Clause en Ada) sont donc indispensables et vous serez souvent amenés à réécrire les mêmes (vous bénirez bientôt l'inventeur du copier-coller). Ne croyez pas que cette lourdeur soit spécifique à Ada, tout langage a besoin de packages ou librairies annexes, tout n'est pas prédéfini et heureusement pour nous : c'est ce que l'on appelle la modularité. Au final, voici la structure de notre programme (et de tout programme Ada) :
Avec plusieurs packages
J'ai essayé de bidouiller le code pour qu'il affiche 13 comme tu le disais dans un exemple. Mais le compilateur râle encore : warning : no entities of "Text_Io" are referenced, no candidate match the actuals : ... enfin bref rien ne va plus. Faut-il un autre package ?
Exactement ! Ada.Text_IO est un package créé pour gérer le texte comme son nom l'indique (Text = texte et IO = In Out, entrée et sortie). Pour afficher un nombre entier (ici 13) il faut utiliser le package Ada.Integer_Text_IO. Exemple :
WITH Ada.Text_IO,Ada.Integer_Text_IO ;
USE Ada.Text_IO,Ada.Integer_Text_IO ;
Pour plus de clareté, il est également possible d'écrire ceci :
WITH Ada.Text_IO,
Ada.Integer_Text_IO ;
USE Ada.Text_IO,
Ada.Integer_Text_IO ;
Et oui ! Bien indenter son code, c'est très important !
Une dernière remarque qui a son importance
Vous devez savoir avant de vous lancer à l'aventure que le langage Ada n'est pas "case sensitive", comme diraient nos amis Anglais, il ne tient pas compte de la casse. Autrement dit, que vous écriviez en majuscule ou en minuscule, cela revient au même : BEGIN, Begin, begin ou bEgIn seront compris de la même manière par le compilateur. Toutefois, Ada sait faire la différence lorsqu'il faut : si vous modifiez la casse dans la phrase à afficher "Salut tout le monde !", l'affichage en sera modifié.
De même, une tabulation ou un espace seront pris en compte de la même façon. Et que vous tapiez un, deux ou trois espaces ne changera rien.
Ce premier programme est peut-être simple, mais voici quelques exercices pour nous amuser encore. Nous avons vu l'instruction Put() qui affiche du texte, en voici maintenant une nouvelle : New_line. Elle permet de retourner à la ligne. N'oubliez pas le point virgule à la fin.
Énoncé
Écrire un programme affichant ceci :
Coucou
tout le
monde
! ! !
Solution
With ada.text_io ;
use ada.text_io ;
procedure Hello2 is
begin
Put("Coucou") ; New_line ;
Put("tout le") ; New_line ;
Put("monde") ; New_line ;
Put("! ! !") ;
end Hello2 ;
Exercice 2
Troisième instruction : Put_line(). Elle fonctionne comme Put(), sauf qu'elle crée automatiquement un retour à la ligne à la fin.
Énoncé
Même exercice que précédemment, mais sans utiliser New_line.
Solution
With ada.text_io ;
use ada.text_io ;
procedure Hello3 is
begin
Put_line("Coucou") ;
Put_line("tout le") ;
Put_line("monde") ;
Put("! ! !") ; --pas besoin de put_line ici, on est arrivé à la fin
end Hello3 ;
Exercice 3
Enoncé
Pourquoi ne pas créer des programmes affichant autre chose que "coucou tout le monde ! ".
Vous avez désormais créé votre premier programme. Certes, il n'est pas révolutionnaire, mais c'est un début. Nous allons pouvoir quitter la première partie de ce tutoriel et entrer dans les bases de la programmation en Ada. La prochaine partie nous permettra de manipuler des nombres, d'effectuer des opérations, de saisir des valeurs au clavier ... peu à peu nous allons apprendre à créer des programmes de plus en plus complexes.
Maintenant que Adagide et GNAT sont installés et que nous avons une idée plus précise de ce qui nous attend, nous allons pouvoir commencer notre apprentissage du langage Ada.
Nous avons dors et déjà réalisé notre premier programme. Mais chacun comprend vite les limites de notre programme "Hello". A dire vrai, un tel programme n'apporte absolument rien. Ce qui serait intéressant, ce serait que l'utilisateur de notre programme puisse entrer des informations que l'ordinateur lui demanderait. Par exemple :
Quel âge avez-vous ? _
Et là nous pourrions entrer 25, 37 ou 71 ! Le programme pourrait ensuite se charger d'enregistrer cette information dans un fichier, de nous avertir si nous sommes considérés comme majeur dans l'état du Minnesota ou encore de nous donner notre âge en 2050 ... autant d'applications que nous ne pourrons pas réaliser si l'âge que l'utilisateur indiquera n'est pas enregistré dans une zone de la mémoire.
Et c'est là que les variables interviennent ! Attention, ce chapitre n'est peut-être pas exaltant mais il est absolument nécessaire à la compréhension des prochains.
Nous allons reprendre l'exemple de l'introduction. Nous voulons indiquer un âge à notre programme. Nous aurons donc besoin d'un espace mémoire capable de stocker un nombre entier. Il faudrait effectuer une demande d'allocation d'une zone mémoire et retenir l'adresse mémoire qui nous a été attribuée et la taille de la zone allouée. o_O
Euh ... c'était pas marqué Niveau facile ?
Pas d'inquiétude. Tout cela c'est ce qu'il aurait fallu faire (entre autre) si nous n'avions pas utilisé un langage comme Ada. C'est ce qu'on appelle un langage de haut niveau, c'est à dire que l'on n'aura pas besoin de se casser la tête pour faire tout cela. Il suffira de dire " :pirate: Je veux de la mémoire !". :p
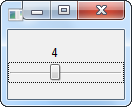
Toutefois, l'ordinateur a tout de même besoin de connaître la place mémoire dont vous aurez besoin et cela dépend du type d'information que l'on souhaite y enregistrer. Ici nous voulons enregistrer un nombre entier que nous appelons age. Le mot age est le nom de notre variable, c'est à dire l'endroit de la mémoire où seront enregistrées nos informations. Pour faire tout cela, il faut déclarer notre variable (comme on le ferait à la douane, cela permet de savoir qui vous êtes et comment vous retrouver). Une déclaration se fait toujours de la façon suivante :
NOM_DE_LA_VARIABLE:TYPE;
Il est possible de déclarer plusieurs variables d'un coup de la manière suivante :
NOM_DE_LA_VARIABLE1,NOM_DE_LA_VARIABLE2:TYPE;
Il est aussi possible, aussitôt la variable déclarée, de lui affecter une valeur à l'aide du symbole ":=". On écrira alors :
NOM_DE_LA_VARIABLE:TYPE:=VALEUR;
Où dois-je faire cette déclaration ? En préfecture ? :(
Vous vous souvenez notre premier programme ? Je vous avais parlé d'une zone réservée aux déclarations (entre is et begin). Et bien c'est ici que nous déclarerons notre variable.
Procedure VotreAge is
NOM_DE_LA_VARIABLE1 : TYPE1 := VALEUR ; --zone réservée aux déclarations
NOM_DE_LA_VARIABLE2 : TYPE2 ;
begin
Put("Quel age avez-vous ?") ;
end ;
Bien, il est temps de rentrer dans le vif du sujet : comment déclarer notre variable age ?
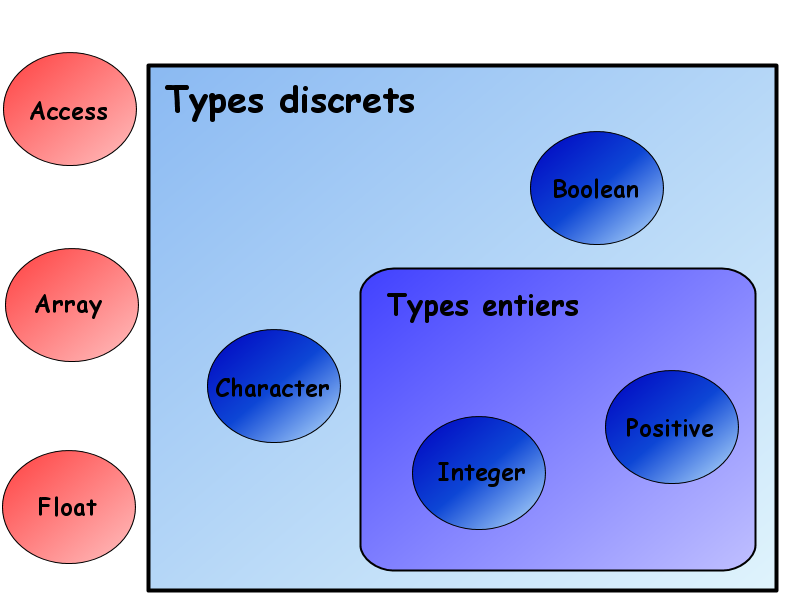
Le type Integer est réservé aux nombres entiers relatifs. Pour ceux qui ne se souviendraient pas de leur cours de Mathématiques, un entier est un nombre "qui n'a pas de chiffres après la virgule à part 0". Relatif signifie que ces entiers peuvent être positifs (avec un signe +) ou négatifs (avec un signe -).
Le type Natural est réservé aux nombres entiers naturels (c'est à dire positifs ou nul). Il est donc impossible, si vous déclarez votre variable comme un Natural, que celle-ci soit négative (ou alors vous planterez votre programme). Pour être plus précis, c'est un sous-type du type Integer. Quelle importance ? Eh bien, cela signifie que l'on pourra "mélanger" les natural et les integer sans risquer le plantage : nous pourrons les additionner entre eux, les soustraire, les multiplier ... ce qui n'est pas possible avec d'autres types. La seule restriction, que notre natural ne devienne pas négatif.
Valeurs possibles
Si N est une variable de type Integer, elle peut prendre les valeurs suivantes : 0 ; 1 ; 2 ; 3 ; 4 ... 2 147 483 647 -1 ; -2 ; -3 ... - 2 147 483 648
Si N est une variable de type Natural, elle peut prendre les valeurs suivantes : 0 ; 1 ; 2 ; 3 ... 2 147 483 647
Exemple
Si nous voulons pouvoir utiliser les Integer ou les Natural, il faudra ajouter Ada.Integer_Text_IO dans la listes des packages :
With Ada.Text_IO, Ada.Integer_Text_IO ;
Use Ada.Text_IO, Ada.Integer_Text_IO ;
Et voila pour le début de notre code :
Procedure VotreAge is
age : Integer := 27;
begin
...
Ou bien, sans affecter de valeur :
Procedure VotreAge is
age : Integer ;
begin
...
Le type Float
Définition
Le type float est chargé de représenter les nombres décimaux. Dans les faits, il n'en représente en fait qu'une partie (comme les Integer ne couvrent pas tous les nombres entiers).
Autant Natural = Naturel ; Integer = Entier, ça semblait évident, autant là : Float = Décimal !?! Je vois mal la traduction :(
Valeurs possibles
Si X est une variable de type float, elle peut prendre les valeurs suivantes : 0.0 ; 1.0 ; 2.0 ... 3,40282E38 (un nombre avec 39 chiffres) -1.0 ; -2.0 ... -3,40282E38 (un nombre avec 39 chiffres) 1.5 ; 2.07 ; 3.141592 ...
Exemple
Si nous voulons pouvoir utiliser les Float, il faudra ajouter Ada.Float_Text_IO dans la listes des packages :
With Ada.Text_IO, Ada.Float_Text_IO ;
Use Ada.Text_IO, Ada.Float_Text_IO ;
Et voila pour le début d'un programme qui demanderait votre taille et votre poids :
Procedure TaillePoids is
Taille : Float := 1.85 ;
Poids : Float := 63.0 ;
begin
...
Ou bien, sans affecter de valeur et en déclarant les deux variables en même temps :
Procedure TaillePoids is
Taille, Poids : Float ;
begin
...
Le type Character
Définition
Le type Character est réservé pour les caractères, c'est à dire les lettres. Toutefois, les espaces, les tabulations constituent aussi des caractères de même que le retour à la ligne, la fin de fichier ... qui sont des caractères non imprimables. Le type Character ne contient pas une phrase mais un seul caractère.
Valeurs possibles
Si C est une variable du type Character, elle peut prendre les valeurs suivantes : 'a', 'b', 'c' ... 'z', 'A', 'B', 'C' ... 'Z', '#', ' ', '%' ...
En réalité, les characters ont les valeurs suivantes : 0, 1, 2 ... 255. Les ordinateurs ne gèrent pas les lettres, mais les chiffres oui ! A chacun de ces nombres est associé un caractère. Dans certains langages il est donc possible d'écrire 'a'+1 pour obtenir 'b'. Mais le langage Ada, qui a un typage fort (certains diront excessif), empêche ce genre d'écriture : une lettre plus un nombre, c'est une aberration en Ada :colere: . Ne vous inquiétez pas, nous verrons plus tard les opérations possibles sur les character.
Exemple
Si nous voulons pouvoir utiliser les Character, il suffit d'avoir écrit Ada.Text_IO dans la listes des packages :
With Ada.Text_IO ;
Use Ada.Text_IO ;
Et voila pour le début d'un programme qui demanderait votre initiale :
Procedure Initiales is
Ini : Character := 'K' ; --Comme Kaji9 :-)
begin
...
Bien ! Maintenant que l'on sait déclarer les principaux types de variables, voyons comment leur attribuer une valeur (on dit qu'on leur affecte une valeur). En effet, nous avons réquisitionné une zone de la mémoire de notre ordinateur mais il n'y a encore rien d'écrit dédans. Pour cela, revenons à notre programme VotreAge :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
Procedure VotreAge is
Age : integer ;
Begin
...
Il y a deux personnes qui peuvent affecter une valeur à la variable Age : vous (le programmeur) ou l'utilisateur( peut-être vous aussi, mais pas dans le même rôle).
Affectation par le programmeur (ou le programme)
On va utiliser le symbole ":=" vu auparavant, mais cette fois, après le Begin.
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
Procedure VotreAge is
Age : integer ;
Begin
Age := 27 ;
End VotreAge ;
Ce programme se contentera d'affecter 27 à une variable Age.
Affectation par l'utilisateur
Nous savons comment poser une question à l'utilisateur avec l'instruction Put. Pour récupérer sa réponse on utilisera la fonction Get.
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
Procedure VotreAge is
Age : integer ;
Begin
Put("Quel age avez-vous ?") ; -- on est poli, on demande l'âge
Get(Age) ; -- puis on saisit la réponse de l'utilisateur
Skip_line ; -- ???
Put("Ah, vous avez ") ; Put(Age) ; -- on fait une phrase affichant la réponse
End VotreAge ;
Bien, bien. C'est pas trop compliqué. Sauf que c'est quoi ce Skip_line ?
L'instruction Skip_line
Skip_line est une instruction que je vous conseille fortement d'écrire après chaque utilisation de l'instruction Get. Pour comprendre son utilité, reprenons l'exemple du programme TaillePoids :
with Ada.Text_IO, Ada.Float_Text_IO ;
use Ada.Text_IO, Ada.Float_Text_IO ;
Procedure TaillePoids is
Taille, Poids : float ;
Begin
Put("Quelle est votre taille ?") ;
Get(Taille) ;
Put("Vous mesurez ") ;
Put(Taille) ;
Put(" m.") ;
Put("Quel est votre poids ?") ;
Get(Poids) ;
Put("Vous pesez ") ;
Put(Poids) ;
Put(" kg.") ;
End TaillePoids ;
Puis voyons ce qu'il se passe dans la console :
Quelle est votre taille ? 1.8R
Vous mesurez 1.8 m.
Quel est votre poids ?
raised ADA.IO_EXCEPTIONS.DATA_ERROR : a-tiinio.adb:89 instantiated at a-inteio.ads:18
Notre utilisateur a tapé 1.8R au lieu de 1.85 (erreur de frappe). Logiquement, le programme plante. Mais regardons en détail ce qu'il s'est passé. La taille enregistrée est 1.8, le R n'a pas été pris en compte. Alors pourquoi le programme ne nous laisse-t-il pas entrer une nouvelle taille ? Pourquoi détecte-t-il une erreur alors que nous n'avons entré aucun poids ? Et qui plus est : pourquoi ne la détecte-t-il pas plus tôt ?
En fait, en tapant 1.8R nous avons envoyé dans le buffer (la mémoire tampon) 1.8 puis R puis le "entrée" (qui constitue également un caractère). L'instruction Get(Taille) s'est emparée de 1.8, mais le R est resté en mémoire tampon puisqu'à l'évidence, il ne faisait pas partie du nombre demandé. Par conséquent, l'instruction Get(Poids) a regardé dans le buffer ce qu'il y avait à récupérer : la lettre R que vous aviez tapé par erreur ! L'instruction Get(Poids) s'est donc emparé du R qui est un character et non un Float. D'où l'erreur.
Et Skip_line dans tout ça ? o_O
Et bien l'instruction Skip_line aurait évité cette erreur, car Get(Taille) aurait saisit 1.8 pour la taille (comme tout à l'heure) et Skip_line aurait ensuite vidé la mémoire tampon : plus de R ou de touche "entrée" en mémoire. Nous aurions ainsi pu saisir notre poids tranquillement.
Voici le code, corrigé avec Skip_line :
with Ada.Text_IO, Ada.Float_Text_IO ;
use Ada.Text_IO, Ada.Float_Text_IO ;
Procedure TaillePoids is
Taille, Poids : float ;
Begin
Put("Quelle est votre taille ?") ;
Get(Taille) ; Skip_line ;
Put("Vous mesurez ") ;
Put(Taille) ;
Put(" m.") ;
Put("Quel est votre poids ?") ;
Get(Poids) ; Skip_line ;
Put("Vous pesez ") ;
Put(Poids) ;
Put(" kg.") ;
End TaillePoids ;
Cette dernière partie est plus technique. Si vous avez peur qu'elle ne vous embrouille. Je vous conseille de relire ce qui précède et de faire des exemples (c'est en forgeant que l'on devient forgeron ^^ ). Toutefois, je vous invite à revenir lire ce qui suit, aussitôt que vous maîtriserez les notions de types car les constantes et les attributs (surtout les attributs) nous serons forts utiles par la suite.
Constantes
Une variable peut ... varier. Étonnant non ? :p Ce n'est pas parce que vous l'avez initialisée à 15 qu'elle ne peut pas être modifiée plus tard pour valoir 18, bien au contraire. C'est d'ailleurs là tout leur intérêt.
N := 10 ; --la variable N prend la valeur 10
N:= 13 ; --Puis la valeur 13
N:= 102 ; --Et enfin la valeur 102 !
Mais il est parfois intéressant de fixer leur valeur une fois pour toute. La variable ne varie alors plus, elle devient une constante et doit être déclarée de la manière suivante :
MaVariable : Constant Integer := 15 ;
Nous avons ainsi une variable MaVariable qui vaudra toujours 15. Tentez seulement de modifier cette valeur et vous entraînerez un plantage de votre programme (ou plutôt, votre compilateur refusera de compiler votre code).
A quoi servent les constantes ? Exemple simple :
PI : Constant Float := 3.1415926535 ;
Chacun comprend que si la valeur de ma variable PI est modifiée, tous mes calculs d'aire de disque, de périmètre de cercle ou de volume de boule ... seront faux. Donc PAS TOUCHE A MA CONSTANTE ! ! ! :lol:
Attributs
Comment obtenir le plus petit et le plus grand Integer ? Comment savoir quel est le 93ème character ? Grâce aux attributs, bien sûr. Ce sont des sortes d'instructions qui s'appliquent aux types.
Avant d'en voir quelques uns, rappel d'Anglais : Repeat after me ! "Susan's dog" signifie "le chien de Susan". Ainsi, le petit mot " 's" exprime l'idée d'appartenance et il faut penser à inverser l'ordre des noms par rapport au Français. Pourquoi ce rappel ? Eh bien parce que les attributs s'utilisent de la même manière :
N := integer'first ; --N sera le premier des integer
M := integer'last ; --M sera le dernier des integer
C := character'val(93) ; --C sera la 93ème valeur des character
P := character'pos('f') ; --P aura pour valeur la position du character 'f'
Nous reverrons plus abondamment les attributs dans les chapitres suivants. Commencez déjà par vous faire la main sur ces quatre là : quel est le plus petit float ? Le plus grand ? Quel est la position de 'a' et du 'A' ?
Bien, nous savons maintenant déclarer une variable et lui affecter une valeur. Nous avons vu également quelques types de variables. Nous serons amenés par la suite à voir d'autres types plus complexes (tableaux, chaînes de caractères, classes, pointeurs, ...).
Avant cela, nous devrons voir un second chapitre sur les variables. C'est en effet intéressant de les avoir enregistrées en mémoire, mais il serait bien plus intéressant de pouvoir les modifier à l'aide de quelques formules mathématiques simples.
Nous allons, dans ce chapitre, aborder les opérations que l'on peut effectuer sur les différents types de variables : Integer, Natural, Float et Character. En effet, il ne suffit pas de créer des variables et de leur affecter une valeur ; encore faut-il qu'elles servent à quelque chose, que l'on effectue quelques opérations avec elles sans quoi le compilateur GNAT risque de nous renvoyer le message :
Warning : variable "Machin" is never read and never assigned
Autrement dit, votre variable ne sert à rien ! :p
Un dernier rappel : toutes les opérations d'affectation devront être écrites, je le rappelle, entre begin et end.
Je pense que les exemples abordés ci-dessus parlent d'eux-mêmes. Mais ils sont très légers. Voici quelques exemples un peu plus poussés :
Get(N) ; skip_line ; --on saisit deux variables de type integer
Get(M) ; skip_line ;
Resultat := N + M + 1 ; --La variable Resultat prend la valeur résultant
--de l'addition des deux variables N et M
Au lieu d'effectuer un calcul avec des valeurs connues, il est possible de faire des calculs avec des variables dont on ne connait pas, a priori, leur valeur.
Get(Var) ; skip_line ; --on saisit une variable de type integer
Var := Var + 1 ;
Hein ? Var est égal à Var + 1 ?!?
NON ! Le symbole n'est pas = mais := ! Ce n'est pas un symbole d'égalité mais d'affectation ! Supposons que Var soit égal à 5. Alors Var + 1 vaudra 6. Le code ci-dessus affectera donc 6 à la variable Var, qui valait auparavant 5. On change donc la valeur de la variable (Ne vous avais-je pas dit que les variables variaient ? ^^ )
N := 36.0**0.5 (résultat 6, la puissance 0.5 équivaut à la racine carre)
ABS
Valeur absolue
N := ABS(-8.7) (résultat 8.7)
Globalement, on retrouve les mêmes opérations qu'avec les Integer et les Natural. Attention toutefois à ne pas additionner (ou soustraire, multiplier ...) un Integer et un Float. Si le symbole de l'addition est le même pour les deux types, il s'agit dans les faits de deux instructions distinctes : l'une pour les Integer, l'autre pour les Float.
Mais comment je fais si j'ai besoin d'additionner un Float et un Integer ?
C'est très simple. Voici un exemple :
Procedure addition is
M : integer := 5 ;
X : float := 4.5 ;
Res_int : integer ;
Res_float : float ;
Begin
Res_int := M + Integer(X) ;
Put(Res_int) ;
Res_float := Float(M) + X ;
Put(Res_float) ;
End addition ;
L'instruction Integer(X) permet d'obtenir la valeur entière de la variable X. Comme X vaut 4.5, Integer(X) donnera comme résultat 4. L'instruction Float(M) permet d'obtenir l'écriture décimale de la variable M. Comme M vaut 5, Float(M) donnera comme résultat 5.0.
Nous avons déjà parlé dans la partie précédente des attributs. Nous aurons encore besoin d'eux dans cette partie pour effectuer des "opérations" sur les character. Voici un tableau récapitulatif de quelques attributs applicables au type character.
Attribut
Explication
Exemple
first
Renvoie le premier de tous les caractères.
c:=character'first ;
last
Renvoie le dernier de tous les caractères.
c:=character'last ;
pos(#)
Renvoie la position du caractère remplaçant #. Attention, le résultat est un Integer.
n := character'pos('z') ;
val(#)
Renvoie le #ème caractère. Attention, le symbole # doit être remplacé par un Integer
c:=character'val(165) ;
succ(#)
Renvoie le character suivant
c:=character'succ(c) ;
pred(#)
Renvoie le character précédent
c:=character'pred(c) ;
Nous avons vu au chapitre précédent que certains langage autorisaient l'écriture du calcul "'a' + 1" pour obtenir le character 'b'. Pratique, rapide ! Seul souci, on mélange deux types distincts : Character et Integer. Ce genre d'écriture est donc prohibée en Ada. On utilisera donc les attributs de la manière suivante :
character'val(character'pos('a') + 2) ;
Explication : les calculs seront effectués dans l'ordre suivant :
character'pos('a') va renvoyer le numéro de 'a', sa position dans la liste des characters disponibles.
Puis on effectue l'addition (Position de 'a' + 2). Ce qui renvoie un nombre entier correspondant à la position du 'c'.
Enfin, character'val(...) transformera le résultat obtenu en character : on devrait obtenir ainsi 'c' !
Qui plus est, cette opération aurait pu être faite à l'aide de l'attribut succ :
character'succ(character'succ('a')) ;
Si ces écritures vous semblent compliquées, rassurez-vous, nous ne les utiliserons pas tout de suite et nous les reverrons plus en détail dans le chapitre sur les fonctions. :)
Pour mettre tout de suite en pratique ce que nous venons de voir, voici quelques exercices d'application.
Exercice 1
Enoncé
Rédiger un programme appelé Multiple qui demande à l'utilisateur de saisir un nombre entier et lui retourne son double, son triple et son quintuple. J'ajoute une difficulté ! Vous n'aurez le droit qu'à deux multiplications pas une de plus !
Solution
WITH Ada.Text_IO, Ada.Integer_Text_IO ;
USE Ada.Text_IO, Ada.Integer_Text_IO ;
PROCEDURE Multiple IS
N : Integer ;
Double, Triple : Integer ;
BEGIN
Put("Saisissez un nombre entier : ") ;
Get(N) ; Skip_Line ;
Double := 2*N ;
Triple := 3*N ;
Put("Le double de ") ; Put(N) ; Put(" est ") ; Put(Double) ; New_Line ;
Put("Le triple de ") ; Put(N) ; Put(" est ") ; Put(Triple) ; New_Line ;
Put("Le quintuple de ") ; Put(N) ; Put(" est ") ; Put(Double+Triple) ;
END Multiple ;
Exercice 2
Enoncé
Rédiger un programme appelé Euclide qui demande deux nombres entiers à l'utilisateur puis renvoie le quotient et le reste de leur division euclidienne (c'est à dire la division entière telle que vous l'avez apprise en primaire).
Solution
WITH Ada.Text_IO, Ada.Integer_Text_IO ;
USE Ada.Text_IO, Ada.Integer_Text_IO ;
PROCEDURE Euclide IS
N,M : Integer ;
BEGIN
Put("Saisissez le dividende : ") ;
Get(N) ; Skip_Line ;
Put("Saisissez le diviseur : ") ;
Get(M) ; Skip_Line ;
Put("La division de ") ; Put(N) ;
Put(" par ") ; Put(M) ;
Put(" a pour quotient ") ; Put(N/M) ;
Put(" et pour reste ") ; Put(N mod M) ;
END Euclide ;
Exercice 3
Enoncé
Rédigez un programme appelé Cercle qui demande à l'utilisateur de saisir la longueur d'un rayon d'un cercle et qui affichera le périmètre et l'aire de ce cercle. Contrainte : le rayon du cercle sera un nombre entier !
Solution
WITH Ada.Text_IO, Ada.Integer_Text_IO, Ada.Float_Text_IO ;
USE Ada.Text_IO, Ada.Integer_Text_IO, Ada.Float_Text_IO ;
PROCEDURE Cercle IS
R : Integer ;
PI : constant float := 3.1415926 ;
BEGIN
Put("Saisissez le rayon du cercle : ") ;
Get(R) ; Skip_Line ;
Put("Un cercle de rayon ") ; Put(R) ;
Put(" a pour perimetre ") ; Put(2.0*PI*float(R)) ;
Put(" et pour aire ") ; Put(float(R**2)*Pi) ;
END Cercle ;
Exercice 4
Enoncé
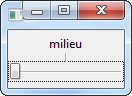
Rédiger un programme appelé Lettres qui demande à l'utilisateur de saisir deux lettres minuscules et qui affichera leur majuscule ainsi que la lettre se trouvant "au milieu" des deux. A défaut, s'il y a deux lettres, le programme choisira la "plus petite".
Solution
WITH Ada.Text_IO ;
USE Ada.Text_IO ;
PROCEDURE Lettres IS
C1,C2,C3 : character ;
BEGIN
Put("Saisissez une premiere lettre minuscule : ") ;
Get(C1) ; Skip_Line ;
Put("Sa majuscule est ") ; Put(Character'Val(Character'Pos(C1)-32)) ; New_Line ;
Put("Saisissez une deuxieme lettre minuscule : ") ;
Get(C2) ; Skip_Line ;
Put("Sa majuscule est ") ; Put(Character'Val(Character'Pos(C2)-32)) ; New_Line ;
C3 := character'val((character'pos(C1) + character'pos(C2))/2) ;
Put("La lettre du milieu est ") ; Put(C3) ;
END Lettres ;
Bien, nous voilà désormais armés pour effectuer des calculs, simples ou complexes, sur les différents types de variables connus pour l'heure. Nous aurons l'occasion de les réutiliser par la suite et de comprendre toute leur utilité, notamment pour l'opération mod, qui doit pour l'instant vous sembler bien inutile (et pourtant elle sera plus utile que vous ne le pensez).
Le prochain chapitre devrait nous permettre d'apporter plus de variété encore à nos programmes en effectuant des actions différentes selon certains critères. Ce sont les conditions.
Un programme informatique permet d'automatiser des tâches (souvent répétitives) mais n'oublions pas qu'il va s'adresser à des utilisateurs humains qui auront envie d'avoir la main et d'effectuer des choix. Nos programmes doivent donc en tenir compte et gérer ces choix : "SI l'utilisateur fait tel choix ALORS faire ceci SINON faire cela".
Nous profiterons également de ce chapitre pour voir différents opérateurs permettant de comparer nos variables. Par la suite, nous aborderons l'algèbre booléenne, terme effrayant mais qui recouvre des règles de logique qui nous permettront de gérer des conditions plus complexes.
Le programme étant suffisamment chargé, ce chapitre sera partagé en deux.
Nous allons réaliser un programme qui demande à son utilisateur s'il dispose de plusieurs ordinateurs. Cette question n'appellera que deux choix possibles : Oui et Non. Le programme renverra un message à l'écran qui dépendra de la réponse obtenue. Ce programme peut se décomposer de la manière suivante :
AFFICHER la question : "Avez-vous plusieurs ordinateurs ?"
SAISIR la réponse (Oui ou Non)
SI la réponse est oui
ALORS AFFICHER : "Vous avez bien de la chance."
Nous enregistrerons la réponse dans une variable Reponse qui sera de type Character. L'utilisateur devra taper "o" pour oui et "n" pour non. L'instruction SI se note IF en Ada, l'instruction ALORS se note quant à elle THEN. D'où le code suivant :
Procedure Questionnaire is
Reponse : Character := 'n' ; --on définit Reponse et on lui attribue
--par défaut la valeur n (pour non)
begin
Put("Avez-vous plusieurs ordinateurs ? (o/n) ") ;
Get(Reponse) ; Skip_line ; --On saisit la réponse et on vide la mémoire tampon
if Reponse = 'o' --SI Reponse est égal à o
then Put("Vous avez bien de la chance."); --ALORS on affiche la phrase.
end if ;
end Questionnaire ;
Mais pourquoi tu as écrit juste = et pas := comme avant ?
Tout simplement parce que le symbole := est utilisé pour affecter une valeur à une variable. Si nous avions écrit :
Reponse := 'o'
... alors nous aurions modifier la valeur de Reponse en lui attribuant la valeur 'o'. Or ici nous posons une question au programme : Reponse est-il bien égal à 'o' ? Le programme se chargera de répondre vrai ou faux. C'est pourquoi nous utiliserons ici le symbole =. D'ailleurs, après une instruction if, le compilateur refuserait que vous utilisiez le symbole :=.
Autres remarques, l'instruction if doit être clôturée par une instruction end if qui marquera la fin des actions à exécuter dans cette instruction if. Et s'il ne faut pas de ";" à la fin de l'instruction if, il en faut bien après end if !
Mais ce programme présente de grooooosses lacunes. Que se passe-t-il si l'utilisateur répond non (n) ? Eh bien pour l'instant, c'est très simple : rien. :lol:
Une première alternative
Nous allons donc compléter notre code de la manière suivante :
AFFICHER la question : "Avez-vous plusieurs ordinateurs ?"
SAISIR la réponse (Oui ou Non)
SI la réponse est oui
ALORS AFFICHER : "Vous avez bien de la chance."
SINON AFFICHER : "Ha ... Dommage."
L'instruction SINON se traduit par Else et nous permettra de varier un peu notre programme. ^^ Au lieu d'avoir le code suivant :
if Reponse = 'o'
then Put("Vous avez bien de la chance.") ;
end if ;
Nous allons donc écrire :
if Reponse = 'o'
then Put("Vous avez bien de la chance.") ;
else Put ("Ha ... Dommage. ") ;
end if ;
Désormais, si l'utilisateur répond non (n), il recevra tout de même une réponse, différente qui plus est ! :soleil:
Et que se passerait-t-il si l'utilisateur tapait une autre lettre, comme z par exemple ?
Pour avoir la réponse reprenons notre code ! Celui-ci ne teste qu'une seule égalité : la variable Reponse est-elle égale à 'o' ? Donc si Reponse vaut 'z', le programme apportera la même réponse que si elle vaut 'n', 'a', '@' ou autre ! Dit différemment, nous n'avons pas envisagé tous les cas. L'utilisateur peut tout à fait répondre autre chose que oui ou non. :waw: Et là vous vous demandez s'il n'existerait pas une troisième instruction après then et else. Eh bien non. Pour envisager d'avantage de cas, il va falloir ruser.
L'astuce (pas si compliquée d'ailleurs) est de réaliser plusieurs tests :
SI la réponse est oui
ALORS AFFICHER ("Vous avez bien de la chance")
SINON SI la réponse est non
ALORS AFFICHER("Ah ... Dommage.")
SINON Afficher("C'est pas une réponse ça !")
Il est en effet possible d'imbriquer plusieurs instructions if les unes dans les autres :
if Reponse = 'o'
then Put("Vous avez bien de la chance"); --cas où la réponse est oui
else if Reponse = 'n'
then Put("Ah ... Dommage."); --cas où la réponse est non
else Put("C'est pas une réponse ça !"); --cas où la réponse est... autre chose
end if ;
end if ;
Et voilà le tour est joué ! Allez, plus compliqué, si l'utilisateur répond 'p' (pour "p'têt bin que oui, p'têt bin que non") on affiche le message "Reponses normandes non valides". A vous de jouer :
if Reponse = 'o'
then Put("Vous avez bien de la chance");
else if Reponse = 'n'
then Put("Ah ... Dommage.");
else if Reponse = 'p'
then Put("Reponses normandes non valides");
else Put("C'est pas une réponse ça !");
end if ;
end if ;
end if ;
Alors vous avez réussi ? Bien joué ! Regardez toutefois le code que je vous propose : à chaque nouveau then/else, j'ai ajouté une tabulation (ou 3 espaces avec Adagide). Nous avons déjà vu cette pratique, elle s'appelle l'indentation et elle n'est pas anodine car elle vous permettra de proposer un code aéré, organisé et donc facilement lisible par vous ou un tiers. Prenez cette habitude le plus tôt possible ! C'est un conseil que je ne cesserai de vous répéter.
Toutefois vous avez du vous rendre compte que cela devient vite fatiguant d'écrire plusieurs end if et d'augmenter de plus en plus le nombre de tabulations pour avoir un code bien indenté. Heureusement zorro est arrivé :zorro: Oups. Non, heureusement les instructions else if peuvent être remplacées par une autre : elsif !
Ah ........... Et ça change quoi ? (À part une lettre en moins)
Et bien, observez par vous-même :
if Reponse = 'o'
then Put("Vous avez bien de la chance");
elsif Reponse = 'n'
then Put("Ah ... Dommage.");
elsif Reponse = 'p'
then Put("Reponses normandes non valides");
else Put("C'est pas une réponse ça !");
end if ;
Plus besoin de multiplier les end if, du coup chaque instruction elsif se présente comme un "prolongement" du if initial, limitant ainsi l'indentation.
Mais il y a une instruction encore plus lisible et particulièrement appropriée pour des choix multiples.
Cette nouvelle instruction s'appelle case. Comme son nom l'indique (si vous êtes un peu anglophone), elle permet de traiter différents CAS (= case). Alors pour la beauté de l'art, nous allons nous ajouter un cas supplémentaire : si l'utilisateur appuie sur 'f' (pour "I don't speak French" = "Je ne parle pas Français" pour les anglophobes). Et en route pour l'aventure !
case Reponse is --on indique que l'on va regarder les différents cas possibles pour Reponse
when 'o' => Put("Vous avez bien de la chance.") ; -- si oui
when 'n' => Put("Ah ... dommage. ") ; -- si non
when 'p' => Put("Reponses normandes non valides") ; -- si peut-être
when 'f' => Put("J'aurais pas du prendre Allemand ...") ; -- si "not French"
when others => Put("C'est pas une reponse.") ; -- si autre chose
end case ; -- on termine notre instruction comme avec if !
Cette nouvelle instruction a des avantages : plus compacte, elle est donc plus claire, plus lisible et surtout plus rapide à taper lorsque les choix s'avèrent nombreux. Elle présente toutefois des limites que nous verrons dans les prochaines parties.
Pour l'instant regardons la structure. La portion de code ci-dessus (on parlera de bloc) est introduite de la même manière que la procédure de votre programme : Procedure Questionnaire is. Elle se termine par end case. Les flèches sont faites du signe égal (=) suivi du signe "supérieur à" (>). Rappelons enfin que le mot when signifie QUAND et que le mot others signifie AUTRE (n'utilisez l'instruction when others qu'après avoir traité tous les cas).
Vous avez bien compris ? Alors rien ne vous empêche de trouver d'autres réponses farfelues pour vous exercer (pensez toutefois à indiquer ces nouvelles réponses possibles à l'utilisateur). Je vous invite à reprendre les parties précédentes si vous avez encore quelques doutes car la partie suivante sera un poil plus compliquée. ;)
En effet, nous pensions avoir fini notre programme, qu'il couvrait tous le choix possibles etc ... Eh bien non. Que se passera-t-il si l'utilisateur tape 'O' au lieu de 'o', ou bien 'N' au lieu de 'n' ? Pour l'ordinateur, un "n" minuscule et un "N" majuscule sont deux valeurs différentes. Il considèrera que c'est une mauvaise réponse et répondra "C'est pas une reponse" !
On va devoir créer 4 nouveaux cas pour les majuscules ? :(
Non, rassurez-vous. Mais nous allons toutefois devoir faire un peu de logique : c'est ce qu'on appelle l'algèbre booléenne. :p Nous n'aborderons pas l'algèbre booléenne dans ce chapitre. Si certaines choses ne sont pas claires, je vous conseille de relire ce chapitre car le suivant s'avèrera plus compliqué.
Tous nos tests jusque là se contentaient de vérifier une égalité. Or il est possible d'utiliser d'autres symboles mathématiques appelés opérateurs de comparaison. En voici un liste :
Opérateur
Signification
=
"est égal à"
/=
"est différent de"
<
"est plus petit que"
>
"est plus grand que"
<=
"est plus petit ou égal à"
>=
"est plus grand ou égal à"
Ainsi notre programme initial peut-être modifié de la manière suivante :
AFFICHER "Combien d'ordinateurs avez-vous?"
SAISIR la réponse
SI la réponse est supérieure ou égal à 2
ALORS AFFICHER "Génial"
SINON AFFICHER "C'est toujours ca"
D'où le programme suivant :
Procedure Questionnaire2 is
Reponse : integer := 0 ; --on définit la réponse et on l'initialise à 0
begin
Put("Combien d'ordinateurs avez-vous?") ;
Get(Reponse) ; Skip_line ;
if Reponse >= 2
then Put("Genial!") ;
else Put("C'est toujours ca") ;
end if ;
end Questionnaire2 ;
A noter que la question posée (Reponse est-elle supérieure ou égale à 2) , aussi appelée prédicat peut être remplacée par :
if Reponse>1
then Put("Genial!") ;
else Put("C'est toujours ca") ;
end if ;
Ce nouveau prédicat aura la même conclusion. De même, en inversant les instruction suivant then et else et en écrivant :
if Reponse<=1
then Put("C'est toujours ca") ;
else Put("Genial!") ;
end if ;
ou
if Reponse<2
then Put("C'est toujours ca") ;
else Put("Genial!") ;
end if ;
... on obtiendra également la même chose.
Bien. Nous avons fait un premier tour des conditions en Ada. L'élément le plus important est la suite d'instruction if/then/else, mais n'oubliez pas qu'il existe l'instruction case pour simplifier votre code.
Avec ces quelques instructions en tête, vos programmes devraient dors et déjà prendre un peu de profondeur.
Nous avons vu au précédent chapitre l'existence des instruction if/elsif/case. Mais nous sommes tombés sur un os : nos codes ne prenaient pas en compte les majuscules. Je vous propose donc de repartir du début pour simplifier votre travail de compréhesion. Notre code se résumera à
if Reponse = 'o'
then Put("Vous avez bien de la chance. ") ;
else Put("Ah ... Dommage.") ;
end if ;
L'algèbre booléenne ou algèbre de Boole (du nom du Mathématicien George Boole) est une branche des mathématiques traitant des opérations logiques. Elle a été très utile en électronique (c'est grâce à elle que nos bêtes ordinateurs savent aujourd'hui additionner, multiplier ...) et va nous servir aujourd'hui en programmation.
:euh: Mais ... euh ... je suis nul(le) en Maths ...
Pas de problème, il ne s'agit que de logique, il n'y aura pas de calcul (au sens habituel du terme).
Qu'est-ce qu'un booléen ?
Tout d'abord, lorsque l'on écrit :
if Reponse = 'o'
... il n'y a que deux alternatives possibles : ou cette affirmation est VRAIE (Reponse vaut bien 'o') ou bien elle est FAUSSE (Reponse vaut autre chose). Ces deux alternatives (VRAI/FAUX) sont les deux seules valeurs utilisées en algèbre booléenne. En ada, elles se notent true (VRAI) et false (FAUX).
Un booléen est donc un objet qui vaut soit VRAI soit FAUX. En Ada, cela se déclare de la manière suivante :
A : boolean := true ;
B : boolean := false ;
Il est également possible d'affecter à nos variables booléennes le résultat d'un prédicat :
A := (Reponse = 'o')
Hein ? A prend la valeur contenue dans Reponse ou bien il prend la valeur 'o' ? Et puis c'était pas sensé valoir true ou false ?
La variable A prendra bien comme résultat true ou false et sûrement pas 'o' ! Tout dépend de l'égalité entre parenthèses : si Reponse est bien égal à 'o' alors A vaudra true, sinon il vaudra false.
La condition suivante pourra ainsi s'écrire :
if A
then ...
end if ;
Cela signifie "Si A est vrai alors ...". La variable A remplacera ainsi notre égalité.
Les opérateurs booléen
Voici les quelques "opérations" booléennes que nous allons aborder :
Opérateur
Traduction littérale
Signification
Not
Non
Not A : "il faut que A ne soit pas vrai"
Or
Ou
A or B : "il faut que A ou B soit vrai"
And
Et
A And B : "il faut que A et B soient vrais"
Xor
Ou exclusif
A xor B : "il faut que A ou B soit vrai mais pas les deux. "
Ce ne sont pas les seuls opérateurs existant en algèbre booléenne, mais ce sont ceux que vous serez amenés à utiliser en Ada.
Revenons à notre programme. Nous voudrions inverser les deux instructions d'affichage de la manière suivante :
if Reponse = 'o'
then Put("Ah ... Dommage.") ;
else Put("Vous avez bien de la chance. ") ;
end if ;
Chacun comprend que notre programme ne répond plus correctement : si l'utilisateur a plusieurs ordinateurs, le programme lui répond "dommage" !?! Nous devons donc changer la condition : le programme doit afficher "Dommage" seulement SI Reponse ne vaut pas'o' ! La négation d'une instruction booléenne se fait à l'aide de l'instruction not. D'où le code suivant :
if Not Reponse = 'o' -- si la réponse n'est pas Oui
then Put("Ah ... Dommage.") ; -- alors on affiche "Dommage"
else Put("Vous avez bien de la chance. ") ; -- sinon on affiche le second message
end if ;
Le programme fait ainsi de nouveau ce qu'on lui demande. Retenez cette astuce car il arrive souvent que l'on se trompe dans la condition ou l'ordre des instructions entre then et else, notamment quand les conditions deviennent plus complexes.
Un peu d'algèbre booléenne maintenant :
Si A est vrai, alors Non A est faux. Si A = true alors Not A = false.
Si A est faux, alors Non A est vrai. Si A = false alors Not A = true.
Quelle que soit la valeur du booléen A, Non Non A = A (Not not A = A)
Nous avons vu dans la partie précédente que le code suivant ne gérait pas les majuscules :
if Reponse = 'o'
then Put("Vous avez bien de la chance. ") ;
else Put("Ah ... Dommage.") ;
end if ;
Il faudrait poser la condition "SI la réponse est o ou O". C'est à dire qu'il suffirait que l'une des deux conditions soit remplie pour que le programme affiche que vous avez de la chance. Pour cela, on utilise l'instruction or (OU en Français).
if Reponse = 'o' or Reponse = 'O'
then Put("Vous avez bien de la chance. ") ;
else Put("Ah ... Dommage.") ;
end if ;
Encore un peu d'algèbre booléenne : si A et B sont deux propositions (vraies ou fausses) l'instruction "A ou B" sera vraie dans les trois cas suivants :
si A est vrai
si B est vrai
si les deux sont vrais
L'instruction and
Nouveau jeu ! Inversons, comme dans la partie précédente, les instructions d'affichage. Nous devrions alors écrire une négation :
if not(Reponse = 'o' or Reponse = 'O')
then Put("Ah ... Dommage.") ;
else Put("Vous avez bien de la chance. ") ;
end if ;
Vous vous souvenez de la partie sur l'instruction Not ? Nous avons fait la même chose : puisque l'on a inversé les instructions d'affichage, nous écrivons une négation dans le prédicat. Mais cette négation peut aussi s'écrire :
if not Reponse = 'o' and not Reponse = 'O'
then Put("Ah ... Dommage.") ;
else Put("Vous avez bien de la chance. ") ;
end if ;
L'opérateur And signifie ET. Il implique que les deux conditions doivent être remplies en même temps :
Reponse ne vaut pas 'o'
ET
Reponse ne vaut pas non plus 'O'
Encore de l'algèbre booléenne.
si A est VRAI et B est FAUX alors A et B est FAUX
si A est VRAI et B est VRAI alors A et B est VRAI
si A est FAUX et B est FAUX alors A et B est FAUX
De manière schématique, retenez que la négation d'un OU est ET. Le contraire de VRAI OU VRAI est donc FAUX ET FAUX. Bon, je crois qu'il est temps d'arrêter car certains méninges doivent commencer à griller. :p Je vous invite donc à méditer ce que vous venez de lire.
Il nous reste une opération à voir, l'opération xor. Nous ne nous attarderons pas dessus car je préfèrerais que vous reteniez déjà ce que nous venons de voir sur Not, Or et And. Toutefois, si vous voulez en savoir plus, rappelons que la phrase "A ou B" sera vraie dans trois cas :
si A est vrai
si B est vrai
si A et B sont vrais tous les deux
Or il existe des cas où il ne faut pas que les deux conditions soient vraies en même temps. Au lieu d'écrire "(A ou B) et pas (A et B)", il existe l'opération OU EXCLUSIF (xor). Pour que "A xor B" soit vrai il faut que :
Maintenant que nous avons vu les opérateurs booléens, Vous pourriez reprendre votre programme Questionnaire pour qu'il puisse gérer aussi les majuscules.
Avec des elsif :
if Reponse = 'o' or Reponse = 'O'
then Put("Vous avez bien de la chance.") ;
elsif Reponse = 'n' or Reponse = 'N'
then Put("Ah ... dommage. ") ;
elsif Reponse = 'p' or Reponse = 'P'
then Put("Reponses normandes non valides") ;
elsif Reponse = 'f' or Reponse = 'F'
then Put("J'aurais pas du prendre Allemand ...") ;
else Put("C'est pas une reponse.") ;
end if ;
Il suffit juste de compléter les blocs if/elsif avec une instruction or. :)
Avec un case (un poil plus dur ; la solution proposée comporte une astuce) :
case Reponse is
when 'o' | 'O' => Put("Vous avez bien de la chance.") ; -- si oui
when 'n' | 'N' => Put("Ah ... dommage. ") ; -- si non
when 'p' | 'P' => Put("Reponses normandes non valides") ; -- si peut-être
when 'f' | 'F' => Put("J'aurais pas du prendre Allemand ...") ; -- si "not French"
when others => Put("C'est pas une reponse.") ; -- si autre chose
end case ;
Durant vos essais vous avez du remarquer que lors de l'instruction when il n'est pas possible de faire appel aux opérateurs booléens. Pour remplacer l'instruction or, il suffit d'utiliser le symbole "|" (Alt gr + touche du 6). Oui, je sais j'ai triché, vous ne pouviez pas le deviner. :euh:
Cette ultime partie doit être vue comme un complément. Elle est plutôt théorique et s'adresse à ceux qui maîtrisent ce qui précède (ou croient le maîtriser :diable: ). Si vous débutez, jetez-y tout de même un œil pour avoir une idée du sujet, mais ne vous affolez pas si vous ne comprenez rien : cela ne vous empêchera pas de suivre la suite de ce cours et vous pourrez revenir dessus plus tard, lorsque vous aurez gagné en expérience (pas avant d'être Warrior level 35 avec 500Hp :magicien: ).
Priorités avec les booléens
Si vous avez atteint au moins la cinquième, vous ne devriez pas être sans savoir ce qu'est une priorité dans un calcul. Par exemple, dans le calcul le résultat est ...
Euh... :euh: 45 ?
Argh ! :colere: Non ! Le résultat est 25 ! En effet, on dit que la multiplication est prioritaire sur l'addition, ce qui signifie qu'elle doit être faite en premier (sauf indication contraire à l'aide de parenthèses qui, elles, sont prioritaires sur tout le monde). Eh bien des règles de priorités existent également en algèbre booléenne. Découvrons-les sur quelques exemples :
je viendrai : si Albert ET Bernard viennent OU si Clara vient
Cela revient à écrire : A AND B OR C. Mais que doit-on comprendre ? (A AND B) OR C ou alors A AND (B OR C) ? Quelle opération est prioritaire AND ou OR ? Réfléchissons à notre exemple, si Clara est la seule à venir, tant pis pour Albert et Bernard, je viens.
Dans le cas (A AND B) OR C : les parenthèses m'obligent à commencer par le AND. Or, A et B sont faux tous les deux (Albert et Bernard ne viennent pas) donc (A AND B) est faux. Nous finissons avec le OR : la première partie est fausse mais C est vrai (Clara vient pour notre plus grand bonheur), donc le résultat est Vrai ! Je viens ! A priori, cette écriture correspondrait.
Dans le cas A AND (B OR C) : les parenthèses m'obligent à commencer par le OR. B est faux (Bernard ne vient pas) mais C est vrai (Clara vient :honte: ) donc (B OR C) est vrai. Nous finissons avec le AND : la deuxième partie est vraie et A est faux(Albert ne vient pas), donc le résultat est... Faux ! Je suis sensé ne pas venir ! Apparemment, cette écriture ne correspond pas à ce que l'on était sensé obtenir.
Conclusion ? Il faut commencer par le AND. Si nous enlevons les parenthèses, alors AND est prioritaire sur OR. Le ET peut être comparé à la multiplication ; le OU peut être comparé à l'addition.
Et XOR et NOT ?
XOR a la même priorité que OR, ce qui est logique. Pour NOT, retenez qu'il ne s'applique qu'à un seul booléen, il est donc prioritaire sur les autres opérations. Si vous voulez qu'il s'applique à toute une expression, il faudra user des parenthèses.
Ordre de test
L'intérêt de if, n'est pas seulement de distinguer différents cas pour appliquer différents traitements. Il est également utile pour éviter des erreurs qui pourraient engendrer un plantage en bonne et due forme de votre programme. Par exemple, prenons une variable n de type natural : elle ne peut pas (et ne doit pas) être négative. Donc avant de faire une soustraction, on s'assure qu'elle est suffisamment grande :
if n >= 5
then n := n - 5 ;
end if ;
Ce que nous allons voir ici a notamment pour intérêt d'éviter des tests qui engendreraient des erreurs. Nous reviendrons dessus durant les chapitres sur les tableaux et les pointeurs pour illustrer mon propos. Nous resterons ici dans la théorie. Supposons que nous voulions ordonner nos tests :
Vérifie si A est vrai ET SEULEMENT SI C'EST VRAI, vérifie si B est vrai
Quel intérêt ? Je ne rentrerai pas dans un exemple en programmation, mais prenons un exemple de la vie courante. Que vaut-il mieux faire :
Vérifier si ma sœur qui est ceinture noire de judo n'est pas sous la douche ET vérifier si il y a encore de l'eau chaude. ou Vérifier si ma sœur qui est ceinture noire de judo est sous la douche ET SEULEMENT SI ELLE N'EST PAS SOUS LA DOUCHE vérifier si il y a encore de l'eau chaude.
Les vicieux tenteront la première solution et finiront avec une pomme de douche greffée à la place de l'oreille. Les prudents opteront pour la deuxième solution. Autrement dit, en programmation, la première méthode peut occasionner un plantage, pas la seconde. Maintenant comment implémenter cela en Ada ?
if A=true AND THEN B=true --remarque : il n'est pas utile d'écrire "=true"
THEN ...
ELSE ...
END IF ;
Ainsi, on ne testera le prédicat "B=true" que si auparavant A était vrai. Autre possibilité :
Vérifie si A est vrai OU SI CE N'EST PAS VRAI, vérifie si B est vrai
Exemple de la vie courante. Vaut-il mieux :
Vérifier si il y a des steaks hachés dans le frigo ou chez le voisin. ou Vérifier si il y a des steaks hachés dans le frigo ou, SI VRAIMENT ON A TOUT FINI HIER aller vérifier chez le voisin.
Je ne sais pas vous, mais avant d'aller demander au voisin, je regarde si je n'ai pas ce qu'il faut dans mon frigo. Idem en programmation, si l'on peut économiser du temps-processeur et de la mémoire, on ne s'en prive pas. Donc pour implémenter cela, nous écrirons :
if A=true OR ELSE B=true --remarque : il n'est pas utile d'écrire "=true"
THEN ...
ELSE ...
END IF ;
Les mots réservés then et else peuvent donc, s'ils sont combinés respectivement avec and et or, être utilisés au moment du prédicat. Cela vous montre toute la souplesse du langage Ada cachée sous l'apparente rigidité.
L'algèbre booléenne peut vite s'avérer compliquée. Toutefois retenez l'existence de not/or/and. Ces trois opérateurs vous serviront régulièrement et permettront d'effectuer des tests plus complexes.
Nous avons terminé le chapitre sur les conditions qui était quelque peu ardu. Maintenant nous allons nous intéresser à un nouveau problème : nos programmes auront souvent besoin de répéter plusieurs fois la même action et il est hors de question de jouer du copier/coller ! Notre code doit rester propre et clair.
C'est pourquoi ont été créées les boucles. Il s'agit d'une nouvelle instruction qui va répéter autant de fois qu'on le souhaite une même opération. Intéressé ? ;) Pour comprendre tout cela, nous allons créer un programme appelé Ligne qui afficherait une ligne de '#' (leur nombre étant choisi par l'utilisateur). La structure de notre programme devrait donc ressembler à cela :
With ada.Text_IO, ada.Integer_Text_IO ;
Use ada.Text_IO, ada.Integer_Text_IO ;
Procedure Ligne is
Nb : integer ;
begin
Put("Combien de dièses voulez-vous afficher ?") ;
Get(Nb) ; Skip_line ;
--Bloc d'affichage
end Ligne ;
Avec ce que nous avons vu pour l'instant, nous aurions tendance à écrire notre bloc d'affichage ainsi :
case Nb is
when 0 => Null ; --ne rien faire
when 1 => Put("#") ;
when 2 => Put("##") ;
when 3 => Put("###") ;
when 4 => Put("####") ;
when 5 => Put("#####") ;
when others => Put("######") ;
end case ;
Le souci c'est que l'utilisateur peut très bien demander 21 dièses ou 24 et que nous n'avons pas tellement envie d'écrire tous les cas possibles et imaginables. :colere: Nous allons donc prendre le parti de n'afficher les # que un par un, et de répéter l'action autant de fois qu'il le faudra. Pour cela nous allons utiliser l'instruction loop que nous écrirons dans le bloc d'affichage.
loop --début des instructions qu'il faut répéter
Put('#') ;
end loop ; --indique la fin des instruction à répéter
Ceci définit une boucle qui répètera à l'infini tout ce qui est écrit entre loop et end loop . Génial non ?
Et ça s'arrête quand ta boucle ?
Euh ... en effet, si vous avez tester ce code, vous avez du vous rendre compte que cela ne s'arrête jamais (ou presque). Ce qui est écrit au-dessus est une boucle infinie ! C'est la grosse erreur de débutant. :-° (Bien que les boucles infinies ne soient pas toujours inutiles) Pour corriger cela, nous allons déclarer une variable appelée compteur.
Compteur : integer := 0 ;
Cette variable vaut 0 pour l'instant mais nous l'augmenterons de 1 à chaque fois que nous afficherons un dièse, et ce, jusqu'à ce qu'elle soit égale à la variable Nb où est enregistrée le nombre de dièses voulus. On dit que l'on incrémente la variable Compteur. Voici donc deux corrections possibles :
loop
if Compteur = Nb
then exit ; --si on a déjà affiché assez de dièses, alors on "casse" la boucle
else Put('#') ; --sinon on affiche un dièse et on incrémente Compteur
Compteur := Compteur +1 ;
end if ;
end loop ;
loop
exit when Compteur = Nb ; --comme tout à l'heure, on sort si on a affiché assez de dièses
Put('#') ; --on peut tranquillement afficher un dièse, car si le nombre était atteint, la boucle serait déjà cassée
Compteur := Compteur +1 ; --et on n'oublie pas d'incrémenter
end loop ;
L'instruction exit permet de "casser" la boucle et ainsi d'y mettre fin. Dans ce cas, il est important de faire le test de sortie de boucle avant d'afficher et d'incrémenter afin de permettre de tracer une ligne de zéros dièses. C'est aussi pour cela que Compteur est initialisé à 0 et pas à 1. Si l'on exige l'affichage d'au moins un dièse, alors l'ordre dans la boucle peut être modifié. Toutefois, vous devez réfléchir à l'ordre dans lequel les opérations seront effectuées. Exemple si l'utilisateur tape 3 :
Valeur de Compteur
Test de sortie
Affichage
Incrémentation
0
Négatif
#
+1
1
Négatif
#
+1
2
Négatif
#
+1
3
Positif
STOP
STOP
On affichera bien 3 dièses (pas un de moins ou de plus). Pensez notamment à tester les valeurs extrêmes : 0,1, la valeur maximale si elle existe ...
Le second code a, ici, ma préférence car plus simple et plus lisible. Bien sûr le premier peut être décliné à l'infini en variant : if, elsif, case ... Il n'est d'ailleurs pas impossible d'écrire plusieurs instructions donnant lieu à l'instruction exit. Une autre variante (plus compacte) serait de ne pas utiliser de variable Compteur et de décrémenter la variable Nb au fur et à mesure (décrémenter = soustraire 1 à chaque tour de boucle) :
loop
exit when Nb = 0 ; -- Si Nb vaut 0 on arrête tout
Nb := Nb - 1 ; -- On n'oublie pas de décrémenter ...
Put('#') ; -- ... et surtout d'afficher notre dièse !
end loop ;
Cette dernière méthode est encore plus efficace. N'oubliez pas que lorsque vous créez une variable, elle va monopoliser de l'espace mémoire. Si vous pouvez vous passer d'une d'entre elles, c'est autant d'espace mémoire qui sera dégagé pour des tâches plus importantes de votre programme (ou d'un autre). Qui plus est, votre code gagnera également en lisibilité.
Mais il y a mieux encore : pour nous éviter d'exécuter un test de sortie au milieu de notre boucle, il existe une variante à notre instruction loop : While ... loop ! En Anglais, while signifie "tant que" ; cette boucle se répètera donc tant que le prédicat inscrit dans les pointillés sera vérifié. Exemple :
while Compteur /= Nb loop
Compteur := Compteur +1 ;
Put('#') ;
end loop ;
Autre possibilité (sans déclarer de variable Compteur) :
while Nb /= 0 loop
Nb := Nb - 1 ;
Put('#') ;
end loop ;
Les programmeurs sont des gens plutôt fainéants : s'ils peuvent limiter les opérations à effectuer, ils les limitent ! Et ça tombe bien : nous aussi ! :D C'est pourquoi ils ont inventé une autre variante de loop qui leur permet de ne pas avoir à incrémenter eux même et de s'épargner la création d'une variable Compteur : la boucle for ... loop ! L'exemple en image :
for i in 1..Nb loop
put("#") ;
end loop ;
Ca c'est du condensé, hein ? Mais que fait cette boucle ? Elle se contente d'afficher des # plusieurs fois.
Ce n'est pas une boucle infinie ?
Et non ! Car elle utilise une variable qui lui sert de compteur : i. Plusieurs avantages : tout d'abord cette variable i n'a pas besoin d'être déclarée, elle est automatiquement créée puis détruite pour cette boucle (et uniquement pour cette boucle, i sera inutilisable après). Pas besoin non plus de l'incrémenter (c'est à dire écrire une ligne "i := i +1 ;") la boucle s'en charge toute seule, contrairement à beaucoup de langage d'ailleurs (comme le C). Pas besoin enfin d'effectuer des tests avec if, when ou case qui alourdissent le code. ^^
Vous vous demandez comment tout cela fonctionne ? C'est simple. Lorsque l'on écrit "for i in 1..Nb loop" :
for indique le type de boucle
i est le nom de la variable remplaçant Compteur (je n'ai pas réutilisé la variable Compteur car celle-ci nécessitait d'être préalablement déclarée, ce qui n'est pas le cas de i, je le rappelle)
in 1..Nb indique "l'intervalle" dans lequel la variable i va varier. Elle commencera avec la valeur 1, puis à la fin de la boucle elle prendra la valeur 2, puis 3 ... jusqu'à la valeur Nb avec laquelle elle effectuera la dernière boucle. (Pour les matheux : je mets "Intervalle" entre guillemets car il s'agit d'un "intervalle formé d'entiers seulement" et non de nombres réels)
loop indique enfin le début de la boucle
Tu nous as dit de vérifier les valeurs extrèmes, mais que se passera-t-il si Nb vaut 0 ?
C'est simple, il ne se passera rien. La boucle ne commencera jamais. En effet, "l'intervalle" 1..Nb est ce que l'on appelle un "integer'range" en Ada et les bornes 1 et Nb ne sont pas interchangeables dans un integer'range (intervalle fait d'entiers). La borne inférieure est forcément 1, la borne supérieur est forcément Nb. Si Nb vaut 0, alors la boucle for passera en revue tous les nombres entiers (integer) supérieurs à 1 et inférieurs à 0. Comme il n'en n'existe aucun, le travail sera vite fini.
Quant au cas Nb = 1, l'integer'range 1..1 contient un nombre : 1 ! Donc la boucle for ne fera qu'un seul tour de piste ! :magicien: Magique non ?
Et si je voulais faire le décompte "en sens inverse" ? En décrémentant plutôt qu'en incrémentant ?
En effet, comme vous l'avez sûrement compris, la boucle for parcourt l'intervalle 1..nb en incrémentant sa variable i, jamais en la décrémentant. Ce qui fait que si Nb est plus petit que 1, alors la boucle n'aura pas lieu. Si vous souhaitez faire "l'inverse", parcourir l'intervalle en décrémentant, c'est possible, il suffira de le spécifier avec l'instruction reverse. Cela indiquera que vous souhaitez parcourir l'intervalle "à l'envers", "à rebours". Voici un exemple :
for i in reverse 1..nb loop
...
end loop ;
Attention, si Nb est plus petit que 1, la boucle ne s'exécutera toujours pas !
Nous allons, dans cette partie, remonter aux origines des boucles et voir une instruction qui existait bien avant l'apparition des loop. C'est un héritage d'anciens langages, elle n'est guère utilisée aujourd'hui. C'est donc à une séance d'archéologie (voire de paléontologie) informatique à laquelle je vous invite dans cette partie en allant à la découverte de l'instruction goto (ou gotosaurus). :lol:
Cette instruction goto est la contraction des deux mots "go to" qui signifient "aller à". Elle va renvoyer le programme à une balise que le programmeur aura placé en amont dans son code. Cette balise est un mot quelconque que l'on aura écrit entre << ... >>. Exemple :
<<debut>> --on place une balise appelée "debut"
Put('#') ;
goto debut ; --cela signifie "maintenant tu retournes à <<debut>>"
Bien sûr il est préférable d'utiliser une condition pour éviter de faire une boucle infinie :
<<debut>>
if Compteur <= Nb
then Put('#') ;
Compteur := Compteur + 1 ;
goto debut ;
end if ;
Cette méthode est très archaïque (elle était présente en Basic en 1963 et fut très critiquée car elle générait des codes de piètre qualité). A noter que dans le dernier exemple l'instruction goto se trouve au beau milieu de notre instruction if ! Difficile de voir rapidement où seront les instructions à répéter, d'autant plus qu'il n'existe pas de end loop. Cette méthode est donc à proscrire, préférez-lui une belle boucle loop, while ou for (quoique goto m'ait déjà sauvé la mise deux ou trois fois :-° ).
Nous voudrions maintenant créer un programme appelé Carre qui afficherait un carré de '#' et non plus seulement une ligne.
Méthode avec une seule boucle (plutôt mathématique)
Une première possibilité est de se casser la tête. Si on veut un carré de côté n, alors cela veut dire que le carré aura n lignes et n colonnes, soit un total de n x n = n² dièses.
Donc nous pourrions utiliser une boucle allant de 1 à Nb² (de 1 à 25 pour notre exemple) et qui afficherait un retour à la ligne de temps en temps.
Il faudra donc une boucle du type "for i in 1..Nb²" plus un test du type "if i mod Nb = 0" dans la boucle pour savoir si l'on doit aller à la ligne. A vous d'essayer.
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure Carre is
Nb : integer ;
Begin
Put("Quel est le cote de votre carre ? ") ;
Get(Nb) ; Skip_line ;
for i in 1..Nb**2 loop --Nb**2 est la notation du carré, on peut aussi écrire Nb*Nb
Put('#') ; --on affiche le dièse
if i mod Nb = 0 --Si i est multiple de Nb = Si on a déjà affiché toute une ligne
then New_line ; --On retourne à la ligne
end if ;
end loop ;
end Carre ;
Vous avez :
compris ? Très bien, vous devez avoir l'esprit scientifique.
absolument rien compris ? Pas grave car nous allons justement ne pas faire cela ! C'est en effet un peu compliqué et ce n'est pas non plus naturel comme façon de coder.
Méthode avec deux boucles (plus naturelle)
La méthode précédente est quelque peu tirée par les cheveux mais constitue toutefois un bon exercice pour manipuler les opérations puissance (Nb**2) et modulo (i mod Nb). Voici une méthode plus intuitive, elle consiste à imbriquer deux boucles l'une dans l'autre de la manière suivante :
Boucle1
Boucle2
fin Boucle2
fin Boucle1
La Boucle2 sera chargée d'afficher les dièses d'une seule ligne. La Boucle1 sera chargée de faire défiler les lignes. À chaque itération, elle relancera la Boucle2 et donc affichera une nouvelle ligne. D'où le code suivant :
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure Carre is
Nb : integer ;
Begin
Put("Quel est le cote de votre carre ? ") ;
Get(Nb) ; Skip_line ;
for i in 1..Nb loop --Boucle chargée d'afficher toutes les lignes
for j in 1..Nb loop --Boucle chargée d'afficher une ligne
Put('#') ;
end loop ;
New_line ; --Après avoir affiché une ligne, pensez à retourner à la ligne
end loop ;
end Carre ;
Et voilà le travail ! C'est simple, clair et efficace. Pas besoin d'en écrire des pleines pages ou d'avoir fait Math Sup.
Pourquoi utilises-tu des lettres i, j ... et pas des noms de variable plus explicite ?
Pour trois raisons (assez personnelles) :
Raison 1 : la variable i ou j a un temps de vie très court (restreint à la seule boucle for) elle ne sera pas réutilisée plus tard. Je devrais donc réussir à me souvenir de sa signification jusqu'au end loop.
Raison 2 : la variable i ou j servira très souvent comme indice d'un tableau. Exemple : tableau(i) est la i-ème valeur du tableau. Nous verrons cela dans un prochain chapitre, mais vous pouvez comprendre qu'il est plus simple d'écrire tableau(i) que tableau(Nom_de_variable_long_et_complique).
Raison 3 : j'ai fait une filière mathématiques et en "Maths" on a pour habitude d'utiliser la variable i lorsque l'on traite d'objets ayant un comportement similaire aux boucles. Par exemple lorsque l'on veut effectuer la somme des carrés des nombres entre 1 et n on écrit :
Voilà voilà. :lol: Si maintenant vous voulez vous exercer avec des boucles imbriquées, voici quelques idées d'exercices. Je ne propose pas de solution cette fois. A vous de vous creuser les méninges.
Exercice 1
Afficher un carré creux :
######
# #
# #
# #
# #
######
Exercice 2
Afficher un triangle rectangle :
#
##
###
####
#####
######
Exercice 3
Afficher un triangle isocèle, équilatéral, un rectangle ... ou toute autre figure.
Exercice 4
Rédiger un programme testant si un nombre N est multiple de 2, 3, 4 ... N-1. Pensez à l'opération mod !
Exercice 5
Rédiger un programme qui demande à l'utilisateur de saisir une somme S, un pourcentage P et un nombre d'années T. Ce programme affichera les intérêts accumulés sur cette somme S avec un taux d'intérêt P ainsi que la somme finale, tous les ans jusqu'à la "t-ième" année.
Exercice 6
Créer un programme qui calcule les termes de la suite de Fibonacci. En voici les premiers termes : 0 ; 1 ; 1 ; 2 ; 3 ; 5 ; 8 ; 13 ; 21 ; 34 ; 55 ... Chaque terme se calcule en additionnant les deux précédents, les deux premiers termes étant 0 et 1.
Maintenant que nous avons acquis de bonnes notions sur les boucles et les conditions, nous allons pouvoir nous affairer à un nouveau type de donnée : les tableaux. Le prochain chapitre fera donc appel à tout ce que vous avez déjà vu sur le typage des données (integer, float, ...), les conditions mais aussi et surtout sur les boucles qui révèleront alors toute leur utilité (notamment la boucle for).
Nous avons vu les variables et leurs différents types et opérations, les conditions, les boucles ... autant d'éléments essentiels à tout langage, que ce soit l'Ada, le C, le C++, le Python ... Nous allons maintenant voir comment organiser, hiérarchiser notre code à l'aide des fonctions et des procédures (présentes dans tous les langages elles aussi). Ces éléments nous seront essentiels pour la suite du cours. Mais, rassurez-vous, ce n'est pas bien compliqué ... au début. :D
Vous avez déjà vu maintes fois le terme procédure. Allons, souvenez-vous :
with Ada.Text_IO ;
use Ada.Text_IO ;
procedure Main is
...
begin
...
end Main ;
Et oui ! Votre programme est constitué en fait d'une grande procédure (plus les packages en en-tête, c'est vrai :) ). Donc vous savez dors et déjà comment on la déclare :
Procedure Nom_De_Votre_Procedure is --Partie pour déclarer les variables begin --Partie exécutée par le programme end Nom_De_Votre_Procedure ;
Quel est donc l'intérêt d'en parler si on sait déjà ce que c'est ? o_O
Eh bien pour l'instant, notre programme ne comporte qu'une seule procédure qui, au fil des modifications, ne cessera de s'allonger. Et il est fort probable que nous allons être amenés à recopier plusieurs fois les mêmes bouts de code. C'est à ce moment qu'il devient intéressant de faire appel à de nouvelles procédures afin de clarifier et de structurer notre code. Pour mieux comprendre, nous allons reprendre l'exemple vu pour les boucles : dessiner un rectangle. Voici le code de notre programme :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure Figure is
nb_lignes : natural ; --nombre de lignes
begin
Put("Combien de lignes voulez-vous dessiner ?") ; --on demande le nombre de lignes
get(nb_lignes) ; skip_line ;
for i in 1..nb_lignes loop --on exécute deux boucles pour afficher notre rectangle
for j in 1..5 loop
put('#') ;
end loop ;
new_line ;
end loop ;
end Figure ;
Comme vous pouvez le voir, ce programme Figure propose d'afficher un rectangle de dièses. Chaque rectangle comporte 5 colonnes et autant de lignes que l'utilisateur le souhaite.
Nous allons remplacer la deuxième boucle (celle qui affiche les dièses) par une procédure que nous appellerons Affich_Ligne dont voici le code :
Procedure Affich_Ligne is
begin
for j in 1..5 loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
Euh, c'est bien gentil tout ça, mais je l'écris où ? :euh:
C'est très simple. Le code ci-dessus permet de déclarer au compilateur la sous-procédure Affich_Ligne. Puisqu'il s'agit d'une déclaration, il faut écrire ce code dans la partie réservée aux déclarations de notre procédure principale (avec la déclaration de la variable nb_lignes). Voici donc le résultat :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure Figure is
Procedure Affich_Ligne is
begin
for j in 1..5 loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
nb_lignes : natural ;
begin
Put("Combien de lignes voulez-vous dessiner ?") ;
get(nb_lignes ) ; skip_line ;
for i in 1..nb_lignes loop
Affich_Ligne;
end loop ;
end Figure ;
Vous remarquerez que dans la partie de la procédure principale contenant les instructions, la deuxième boucle, son contenu et le new_line ont disparu et ont laissé la place à un simple "Affich_Ligne ; ". Cette partie devient ainsi plus lisible et plus compacte.
Mouais... :( Bah, écrire tout ça pour gagner 3 lignes dans la procédure principale, moi je dis que c'est pas folichon. :colere2:
N'en jetez plus ! >_ En effet, cela ne semble pas être une opération très rentable, mais je vous invite à continuer la lecture car vous allez vite comprendre l'intérêt des sous-procédures.
Procédure avec un paramètre (ou argument)
Notre programme est pour l'heure très limité : l'utilisateur ne peut pas choisir le nombre de colonnes ! Nous savons facilement (à l'aide de Put et Get) obtenir un nombre de colonnes mais comment faire pour que notre procédure Affich_Ligne affiche le nombre de dièses désiré ? Nous ne pouvons pas effectuer la saisie de la variable Nb_Colonnes dans la procédure Affich_Ligne, car la boucle de la procédure principale demanderait plusieurs fois le nombre de colonnes désiré.
Ah ! C'est malin ! Avec tes histoires, je me suis cassé la tête et en plus je ne peux plus amélioré mon programme ! :colere:
Attendez ! :'( Il y a une solution ! Nous allons demander le nombre de colonnes en même temps que le nombre de lignes et nous allons modifier notre procédure Affich_Ligne pour qu'elle puisse écrire autant de dièses qu'on le souhaite (pas forcément 5). Voici le nouveau code de notre sous-procédure :
Procedure Affich_Ligne(nb : natural) is
begin
for j in 1..nb loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
Nous avons remplacé "j in 1..5" par "j in 1..nb". La variable nb correspondra bien évidemment au nombre de dièses désirés. Mais surtout, le nom de notre procédure est maintenant suivi de parenthèses à l'intérieur desquelles on a déclaré la fameuse variable nb.
o_O J'ai deux questions : 1- Pourquoi on la déclare pas dans la zone prévue à cet effet ? 2- Ta variable nb n'a jamais été initialisée !
Cette variable nb est ce que l'on appelle un paramètre. Elle n'est pas déclarée dans la "zone prévue à cet effet", ni initialisée, parce qu'elle vient "de l'extérieur". Petite explication : toute variable déclarée entre is et begin a une durée de vie qui est liée à la durée de vie de la procédure. Lorsque la procédure commence, la variable est créée ; lorsque la procédure se termine, la variable est détruite : plus moyen d'y accéder ! Cela va même plus loin ! Les variables déclarées entre is et begin sont inaccessibles en dehors de leur propre procédure ! Elles n'ont aucune existence possible en dehors. Le seul moyen de communication offert est à travers ce paramètre : il permet à la procédure principale d'envoyer le contenu d'une variable dans la sous-procédure.
Voilà pourquoi la variable nb est déclarée entre parenthèses : c'est un paramètre. Quant à sa valeur, elle sera déterminée dans la procédure principale avant d'être "envoyée" dans la procédure "Affich_Ligne()".
Mais revenons à notre procédure principale : Figure. Voilà ce que devient son code :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure Figure is
Procedure Affich_Ligne(nb : natural) is
begin
for j in 1..nb loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
nb_lignes, nb_colonnes : natural;
begin
Put("Combien de lignes voulez-vous dessiner ? ") ;
get(nb_lignes ) ; skip_line ;
Put("Combien de colonnes voulez-vous dessiner ? ") ;
get(nb_colonnes ) ; skip_line ;
for i in 1..nb_lignes loop
Affich_Ligne(nb_colonnes);
end loop ;
end Figure ;
Nous avons ajouté deux lignes pour saisir le nombre de colonnes voulues. L'instruction "Affich_ligne" est devenue "Affich_Ligne(nb_colonnes)". Et voilà ! Notre problème initial est résolu ! :p
Et bah moi je continue à penser que c'était bien plus simple sans sous-procédure ! :colere2:
Procédure avec plusieurs paramètres (ou arguments)
Toujours pas convaincu ? :o Et bien voilà qui devrait mettre fin à vos réticences. Nous allons perfectionner notre programme : il proposera d'afficher soit un rectangle soit un triangle rectangle isocèle (un demi-carré pour les mathophobes ;) ).
Il va donc falloir épurer notre code en créant deux procédures supplémentaires : une pour créer un rectangle (Affich_Rect) et une pour créer le triangle rectangle isocèle (Affich_Tri). Ainsi, notre procédure principale (Figure) se chargera de poser les questions à l'utilisateur, puis elle réorientera vers l'une ou l'autre de ces deux sous-procédures.
La procédure Affich_Rect prendra deux paramètres : le nombre de colonnes et le nombre de lignes.
Procedure Affich_Rect(nb_lignes : natural ; nb_colonnes : natural) is
begin
for i in 1..nb_lignes loop
Affich_Ligne(nb_colonnes);
end loop ;
end Affich_Rect ;
Et maintenant notre procédure Affich_Tri :
Procedure Affich_Tri(nb : natural) is
begin
for i in 1..nb loop
Affich_Ligne(i);
end loop ;
end Affich_Tri ;
L'utilité des procédures commence à apparaître clairement : il a suffit d'écrire "Affich_Ligne(i)" pour que le programme se charge d'afficher une ligne comportant le nombre de dièses voulus, sans que l'on ait à réécrire notre boucle et à se creuser la tête pour savoir comment la modifier pour qu'elle n'affiche pas toujours le même nombre de dièses. Alors, convaincu cette fois ? Je pense que oui. Pour les récalcitrants, je vous conseille d'ajouter des procédures Affich_Carre, Affich_Tri_Isocele, Affich_Carre_Vide ... et quand vous en aurez assez de recopier la boucle d'affichage des dièses, alors vous adopterez les procédures. ;)
Bien ! Il nous reste encore à modifier notre procédure principale. En voici pour l'instant une partie :
begin
Put_line("Voulez-vous afficher : ") ; --On propose les deux choix : rectangle ou triangle ?
Put_line("1-Un rectangle ?") ;
Put_line("2-Un triangle ?") ;
Get(choix) ; skip_line;
Put("Combien de lignes voulez-vous dessiner ? ") ; --on saisit tout de suite le nombre de lignes
get(nb_lignes ) ; skip_line ;
if choix=1 --selon le choix on procède à l'affichage de la figure
then Put("Combien de colonnes voulez-vous dessiner ? ") ;
get(nb_colonnes ) ; skip_line ;
Affich_Rect(nb_lignes, nb_colonnes) ;
else Affich_Tri(nb_lignes) ;
end if ;
end Figure ;
Notre code est tout de même beaucoup plus lisible que s'il comportait de nombreuses boucles imbriquées !
Mais ? Il y a une erreur ! :waw: Pour Affich_Rect, les paramètres doivent être séparés par un point virgule et pas par une virgule ! Rooh la honte ! :diable:
Qu'est-ce qu'une fonction ? C'est peu ou prou la même chose que les procédures. La différence, c'est que les fonctions renvoient un résultat.
Une bête fonction
Pour mieux comprendre, nous allons créer une fonction qui calculera l'aire de notre rectangle. On rappelle (au cas où certains auraient oublié leur cours de 6ème) que l'aire du rectangle se calcule en multipliant sa longueur par sa largeur !
Déclaration
Commençons par déclarer notre fonction (au même endroit que l'on déclare variables et procédures) :
function A_Rect(larg : natural, long : natural) return natural is
A : natural ;
begin
A:= larg * long ;
return A ;
end A_Rect ;
Globalement, cela ressemble beaucoup à une procédure à part que l'on utilise le mot functionau lieu de procedure. Une nouveauté toutefois : l'instruction return. Par return, il faut comprendre "résultat". Dans la première ligne, "return natural is" indique que le résultat de la fonction sera de type natural. En revanche, le "return A" de la 5ème ligne a deux actions :
Il stoppe le déroulement de la fonction (un peu comme exit pour une boucle)
Il renvoie comme résultat la valeur contenue dans la variable A.
A noter qu'il est possible de condenser le code ainsi :
function A_Rect(larg : natural; long : natural) return natural is
begin
return larg * long ;
end A_Rect ;
Utilisation
Nous allons donc déclarer une variable Aire dans notre procédure principale. Puis nous allons changer la condition de la manière suivante :
...
if choix=1
then Put("Combien de colonnes voulez-vous dessiner ? ") ;
get(nb_colonnes ) ; skip_line ;
Affich_Rect(nb_lignes, nb_colonnes) ;
Aire := A_Rect(nb_lignes, nb_colonnes) ;
Put("L'aire du rectangle est de ") ; Put(Aire) ; put_line(" dieses.") ;
else Affich_Tri(nb_lignes) ;
end if ;
...
Notre variable Aire va ainsi prendre comme valeur le résultat de la fonction A_Rect(). D'ailleurs, cela ne vous rappelle rien ? Souvenez-vous des attributs !
c := character'val(153) ;
Ces attributs agissaient comme des fonctions !
Une fonction un peu moins bête (optionnel)
Et l'aire du triangle ?
C'est un peu plus compliqué. Normalement, pour calculer l'aire d'un triangle rectangle isocèle, on multiplie les côtés de l'angle droit entre eux puis on divise par 2. Donc pour un triangle de côté 5, cela fait 5*5/2 = 12,5 dièses !?! Bizarre. Et puis, si l'on fait un exemple :
#
##
###
####
#####
Il y a en fait 15 dièses ! ! ! Pour quelle raison ? Eh bien, ce que nous avons dessiné n'est pas un "vrai" triangle. On ne peut avoir de demi-dièses, de quart de dièses ... La solution est donc un peu plus calculatoire. Remarquez qu'à chaque ligne, le nombre de dièses est incrémenté (augmenté de 1). Donc si notre triangle a pour côté N, pour connaître l'aire, il faut effectuer le calcul : 1 + 2 + 3 + ... + (N-1) + N. Les points de suspension remplaçant les nombres que je n'ai pas envie d'écrire. Comment trouver le résultat ? Astuce de mathématicien. Posons le calcul dans les deux sens :
Calcul n°1
1
+
2
+
3
+
...
+
N-2
+
N-1
+
N
Calcul n°2
N
+
N-1
+
N-2
+
...
+
3
+
2
+
1
Somme des termes
N+1
+
N+1
+
N+1
+
...
+
N+1
+
N+1
+
N+1
En additionnant les termes deux à deux, on remarque que l'on trouve toujours N+1. Et comme il y a N termes cela nous fait un total de : N * (N+1). Mais n'oublions pas que nous avons effectuer deux fois notre calcul. Le résultat est donc : N * (N+1) / 2.
Pour un triangle de côté 5, cela fait 5 * 6 / 2 = 15 dièses ! :soleil: Bon, il est temps de créer notre fonction A_Triangle !
function A_Triangle(N : natural) return natural is
A : natural ;
begin
A:= N * (N+1) / 2 ;
return A ;
end A_Triangle ;
Et voilà ce que donne le code général :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure Figure is
Procedure Affich_Ligne(nb : natural) is
begin
for j in 1..nb loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
Procedure Affich_Rect(nb_lignes : natural ; nb_colonnes : natural) is
begin
for i in 1..nb_lignes loop
Affich_Ligne(nb_colonnes);
end loop ;
end Affich_Rect ;
Procedure Affich_Tri(nb : natural) is
begin
for i in 1..nb loop
Affich_Ligne(i);
end loop ;
end Affich_Tri ;
function A_Rect(larg : natural; long : natural) return natural is
A : natural ;
begin
A:= larg * long ;
return A ;
end A_Rect ;
function A_Triangle(N : natural) return natural is
A : natural ;
begin
A:= N * (N+1) / 2 ;
return A ;
end A_Triangle ;
nb_lignes, nb_colonnes,choix,Aire : natural;
begin
Put_line("Voulez-vous afficher : ") ;
Put_line("1-Un rectangle ?") ;
Put_line("2-Un triangle ?") ;
Get(choix) ; skip_line;
Put("Combien de lignes voulez-vous dessiner ? ") ;
get(nb_lignes ) ; skip_line ;
if choix=1
then Put("Combien de colonnes voulez-vous dessiner ? ") ;
get(nb_colonnes ) ; skip_line ;
Affich_Rect(nb_lignes, nb_colonnes) ;
Aire := A_Rect(nb_lignes, nb_colonnes) ;
Put("L'aire du rectangle est de ") ; Put(Aire) ; put_line(" dieses.") ;
else Affich_Tri(nb_lignes) ;
Aire := A_Triangle(nb_lignes) ;
Put("L'aire du triangle est de ") ; Put(Aire) ; put_line(" dieses.") ;
end if ;
end Figure ;
Bilan
Rendu à ce stade, vous avez du remarquer que le code devient très chargé. Voici donc ce que je vous propose : COMMENTEZ VOTRE CODE ! Exemple :
with Ada.Text_IO, Ada.Integer_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO ;
procedure Figure is
--------------
--PROCEDURES--
--------------
Procedure Affich_Ligne(nb : natural) is
begin
for j in 1..nb loop
put('#') ;
end loop ;
new_line ;
end Affich_Ligne ;
Procedure Affich_Rect(nb_lignes : natural ; nb_colonnes : natural) is
begin
for i in 1..nb_lignes loop
Affich_Ligne(nb_colonnes);
end loop ;
end Affich_Rect ;
Procedure Affich_Tri(nb : natural) is
begin
for i in 1..nb loop
Affich_Ligne(i);
end loop ;
end Affich_Tri ;
-------------
--FONCTIONS--
-------------
function A_Rect(larg : natural; long : natural) return natural is
begin
return larg * long ;
end A_Rect ;
function A_Triangle(N : natural) return natural is
begin
return N * (N+1) / 2 ;
end A_Triangle ;
-------------
--VARIABLES--
-------------
nb_lignes, nb_colonnes,choix : natural;
------------------------
--PROCEDURE PRINCIPALE--
------------------------
begin
Put_line("Voulez-vous afficher : ") ;
Put_line("1-Un rectangle ?") ;
Put_line("2-Un triangle ?") ;
Get(choix) ; skip_line;
Put("Combien de lignes voulez-vous dessiner ? ") ;
get(nb_lignes ) ; skip_line ;
if choix=1
then Put("Combien de colonnes voulez-vous dessiner ? ") ;
get(nb_colonnes ) ; skip_line ;
Affich_Rect(nb_lignes, nb_colonnes) ;
Put("L'aire du rectangle est de ") ; Put(A_Rect(nb_lignes, nb_colonnes)) ; put_line(" dieses.") ;
else Affich_Tri(nb_lignes) ;
Put("L'aire du triangle est de ") ; Put(A_Triangle(nb_lignes)) ; put_line(" dieses.") ;
end if ;
end Figure ;
J'utilise, pour ma part, de gros commentaires afin de structurer mon code. Nous verrons bien plus tard comment créer des packages afin de libérer notre procédure principale. Autre remarque, dans cet exemple j'ai condensé mon code. J'ai notamment écrit : "Put(A_Rect(nb_lignes, nb_colonnes)) ;" ! Il est en effet possible d'imbriquer plusieurs fonctions (ou/et une procedure) les unes dans les autres pour "compacter" votre code. Faites toutefois attention à ce que les types soient compatibles !
Il est possible de donner une valeur par défaut aux paramètres d'une procédure ou d'une fonction. Par exemple :
Procedure Affich_Ligne(nb : natural := 1) is
Ainsi, il sera possible de ne pas spécifier de paramètre. En tapant "Affich_Ligne", le compilateur comprendra tout seul "Affich_Ligne(1)".
Cette astuce est surtout utile pour des fonctions exigeant de nombreux paramètres dont certains seraient optionnels. Imaginons par exemple une fonction Affich_Rect définie comme suit :
On dit qu'il s'agit du prototype de la procédure Affich_Rect(on se moque ici de la façon dont elle est codée). Nous reverrons ce mot lors du chapitre sur les packages et nous expliquerons alors pourquoi le is a été bizarrement remplacé par un point virgule.
Expliquons plutôt les différents paramètres :
nb_lignes et nb_colonnes jouent le même rôle que lors des exemples précédents.
symbole est le caractère qu'il faut afficher pour constituer le rectangle. Auparavant, ce caractère était le dièse (#).
plein est un booléen qui indique si le rectangle est creux (plein vaut false) ou plein (plein vaut true).
affich_a et affich_p sont deux booléens. Si affich_a vaut true, alors le programme affichera l'aire du rectangle. S'il vaut false, alors le programme n'affichera rien. Le paramètre affich_p joue le même rôle mais avec le périmètre au lieu de l'aire.
Nous avons ainsi une procédure vraiment complète. Le seul inconvénient c'est que lorsque l'on veut afficher deux simples rectangles formés de dièses, il faut taper :
Hormis les deux premiers, on ne changera pas souvent les paramètres :( La procédure est complète, mais un peu trop : il faudra retaper souvent la même chose ('#',true,false,false) en prenant garde de ne pas s'emmêler les pinceaux dans l'ordre des variables (très important l'ordre des variables !).
Eh bien moi, c'est certain ! Je ne ferai jamais de procédure trop compliquée ! :-°
Allons ! Cette procédure est très bien, il faut juste identifier les paramètres qui seront optionnels et leur donner une valeur par défaut. Il serait donc plus judicieux de déclarer notre procédure ainsi :
Affich_Rect(5,8) ; --Un simple rectangle 5 par 8
Affich_Rect(7,3,'@') ; --un rectangle 7 par 3 avec des @ à la place des # !
Ah oui, c'est effectivement intéressant. :D Mais si je veux un rectangle 5 par 8 classique en affichant le périmètre, je peux taper ça ?
Affich_Rect(5,8,true) ;
Mais je fais quoi alors ? :'(
C'est vrai que dans ce cas, on a un souci. Il nous faut respecter l'ordre des paramètres mais certains ne sont pas utiles. Heureusement, il y a un solution ! :ange:
Affich_Rect(5,8,affich_p => true) ;
Il suffit de spécifier le paramètre auquel on attribue une valeur ! Attention, on n'utilise pas le symbole " := " mais la flèche " => ". Ainsi, l'ordre n'a plus d'importance, on pourrait tout aussi bien noter :
Nous avons vu précédemment que les paramètres d'une fonction ou d'une procédure ne peuvent pas (et ne doivent pas) être modifiés durant le déroulement de la fonction ou de la procédure. Eh bien ... c'est faux ! Enfin non ! C'est vrai, mais disons qu'il y a un moyen de contourner cela pour les procédures.
procedure Affich_Rect(nb_lignes : in natural, nb_colonnes : in natural)is
Les instructions in indiquent que nos paramètres sont uniquement des paramètres d'entrée. Les emplacements-mémoire qui contiennent leur valeur peuvent être lus mais il vous est interdit d'y écrire : ils ne sont accessibles qu'en lecture. Donc impossible d'écrire "nb_lignes := 5" au cours de cette procédure.
Mode out
En revanche, en écrivant ceci :
procedure Affich_Rect(nb_lignes : out natural, nb_colonnes : out natural) is
... vos paramètres deviendront des paramètres de sortie. Il sera possible d'écrire dans les emplacements-mémoire réservés à nb_lignes et nb_colonnes ! Génial non ? Sauf qu'il vous sera impossible de lire la valeur initiale, donc impossible d'effectuer des tests par exemple. :( Vos paramètres ne sont accessibles qu'en écriture.
Mode in out
Heureusement, il est possible de mélanger les deux :
procedure Affich_Rect(nb_lignes : in out natural, nb_colonnes : in out natural) is
Nous avons alors des paramètres d'entrée et de sortie, accessibles en lecture ET en écriture ! Tout nous est permis ! :p
Pourquoi tous les paramètres ne sont-ils pas en mode in out par défaut ?
Réfléchissons à notre procédure Affich_Rect : est-il judicieux que nos paramètres nb_lignes et nb_colonnes soient accessibles en écriture ? Je ne pense pas. Notre procédure n'a pas besoin de les modifier et il ne serait pas bon qu'elle les modifie. Les laisser en mode in, c'est prendre l'assurance que nos paramètres ne seront pas modifiés (sinon, le rigoureux compilateur GNAT se chargera de vous rappeler à l'ordre :pirate: ). Et réciproquement, des paramètres en mode out n'ont pas à être lu. Un exemple ? Une procédure dont l'un des paramètres s'appellerait Ca_Marche et servirait à indiquer si il y a eu un échec du programme ou pas. Notre procédure n'a pas à lire cette variable, cela n'aurait pas de sens. Elle doit seulement lui affecter une valeur. C'est pourquoi vous devrez prendre quelques secondes de réflexion avant de choisir entre ces différents modes et notamment pour le mode in out.
Bien, nous savons maintenant comment mieux organiser nos codes en Ada. Cela nous permettra de créer des programmes de plus en plus complexes sans perdre en lisibilité. Nous reviendrons plus tard sur les fonctions et procédures pour aborder une méthode très utile en programmation : la récursivité. Mais cette partie étant bien plus compliquée à comprendre, nous allons pour l'heure laisser reposer ce que nous venons de voir.
Lors du prochain chapitre théorique nous aborderons un nouveau type : les tableaux ! Mais nous entrons alors dans un nouvel univers (et une nouvelle partie) : l'univers de la programmation orientée objet ou POO ! Je conseille donc à ceux qui ne seraient pas encore au point de revoir les chapitres de la seconde partie.
Mais avant tout cela, il est l'heure pour vous de mettre en application ce que nous avons vu. Le chapitre qui suit est un chapitre pratique : un TP !
Bien, jusque là je vous ai guidé lors des différents chapitres. Je vous ai même fourni les solutions des exercices (qui a dit "pas toujours" ? :colere2: ). Après ces quelques leçons de programmation en Ada, il est temps pour vous de réaliser un projet un peu plus palpitant que de dessiner des rectangles avec des dièses (#). Voila pourquoi je vous propose de vous lancer dans la réalisation d'un jeu de dé :
Le craps !
Il ne s'agira pas d'un exercice comme les précédents, car celui-ci fera appel à de nombreuses connaissances (toutes vos connaissances, pour être franc). Il sera également plus long et devra être bien plus complet que les précédents. Songez seulement à tous les cas qu'il a fallu envisager lorsque nous avons créé notre programme lors du chapitre sur les conditions : eh bien il faudra être aussi exhaustif (si ce n'est davantage).
Rassurez-vous, vous ne serez pas lâchez en pleine nature : je vais vous guider. Tout d'abord nous allons établir les règles du jeu et le cahier des charges de notre programme. Puis nous règlerons ensemble certains problèmes techniques que vous ne pouvez résoudre seuls (le problème du hasard notamment). Pour ceux qui auront des difficultés à structurer leur code et leur pensée, je vous proposerai un plan type. Et finalement, je vous proposerai une solution possible et quelques idées pour améliorer notre jeu.
Bon, avant de nous lancer tête baissée, il serait bon de définir ce dont on parle. Le craps se joue avec 2 dés et nous ne nous intéressons pas aux faces des dés mais à leur somme ! Si vos dés indiquent un 5 et un 3 alors vous avez obtenu 5+3=8 !
Le joueur mise une certaine somme, puis il lance les dés. Au premier lancer, on dit que le point est à off.
Si le joueur obtient 7 (somme la plus probable) ou 11 (obtenu seulement avec 6 et 5), il remporte sa mise. (s'il avait misé 10$, alors il gagne 10$)
S'il obtient des craps (2, 3 ou 12) alors il perd sa mise.
S'il obtient 4, 5, 6, 8, 9 ou 10, alors le point passe à on et les règles vont changer.
Une fois que le point est à on, le joueur doit parvenir à refaire le nombre obtenu (4, 5, 6, 8, 9 ou 10). Pour cela, il peut lancer le dé autant de fois qu'il le souhaite, mais il ne doit pas obtenir de 7 !
S'il parvient à refaire le nombre obtenu, le joueur remporte sa mise.
S'il obtient 7 avant d'avoir refait son nombre, le joueur perd sa mise. On peut alors hurler : SEVEN OUT ! Hum ... désolé.
Ce sont là des règles simplifiées car il est possible de parier sur les issues possibles (le prochain lancer est un 11, le 6 sortira avant le 7, le prochain lancer sera un craps...) permettant de remporter jusqu'à 15 fois votre mise. Mais nous nous tiendrons pour l'instant aux règles citées au-dessus.
Un programmeur ne part pas à l'aventure sans avoir pris connaissances des exigences de son client, car le client est roi (et ici, le client c'est moi :diable: ). Vous devez avoir en tête les différentes contraintes qui vous sont imposées avant de vous lancer :
Tout d'abord les mises se feront en $ et nous n'accepterons qu'un nombre entiers de dollars (pas de 7$23, on n'est pas à la boulangerie !)
Le joueur doit pouvoir continuer à jouer tant qu'il n'a pas atteint les 0$
Un joueur ne doit pas pouvoir avoir - 8 $ ! ! ! Scores négatifs interdits. Et pour cela, il serait bon que le croupier vérifie que personne ne mise plus qu'il ne peut perdre (autrement dit, pas de mise sans vérification).
Le joueur ne peut pas quitter le jeu avant que sa mise ait été soit perdue soit gagnée. En revanche, il peut quitter la partie en misant 0$.
L'affichage des résultats devra être lisible. Pas de
+5
mais
Vous avez gagné 5 $. Vous avez maintenant 124 $.
Le programme devra indiquer clairement quel est le point (off ou on, et dans ce cas, quel est le nombre ?), si vous avez fait un CRAPS ou un SEVEN OUT, si vous avez gagné, quelle somme vous avez gagné/perdu, ce qu'il vous reste, les faces des dés et leur somme ... Bref, le joueur ne doit pas être dans l'inconnu. Exemple :
Vous avez encore 51$. Combien misez vous ? 50
Le premier de donne 1 et le second donne 2. Ce qui nous fait 3.
C'est un CRAPS. Vous avez perdu 50 $, il ne vous reste plus que 1$.
Votre procédure principale devra être la plus simple possible, pensez pour cela à utiliser des fonctions et des sous-procédures. Vous êtes autorisés pour l'occasion à utiliser des variables en mode out ou in out. ^^
Votre code devra comporter le moins de tests possibles : chaque fois que vous testez une égalité, vous prenez du temps processeur et de la mémoire, donc soyez économes.
Compris ? Alors il nous reste seulement un petit détail technique à régler : comment simuler un lancer de dé ? (Oui, je sais, ce n'est pas vraiment un petit détail).
Je vous transmet ci-dessous une portion de code qui vous permettra de générer un nombre entre 1 et 6, choisi au hasard (on dit aléatoirement).
WITH Ada.Numerics.Discrete_Random ;
PROCEDURE Craps IS
SUBTYPE Intervalle IS Integer RANGE 1..6 ;
PACKAGE Aleatoire IS NEW Ada.Numerics.Discrete_Random(Intervalle);
USE Aleatoire;
Hasard : Generator;
...
Bah, pourquoi ?
Malheureusement, je ne peux pas vous expliquer ce code pour l'instant car il fait appel à des notions sur les packages, l'héritage, la généricité ... que nous verrons bien plus tard. Vous n'aurez donc qu'à effectuer un copier-coller. En revanche, je peux vous expliquer la toute dernière ligne : pour générer un nombre "aléatoire", l'ordinateur a besoin d'une variable appelée générateur ou germe. C'est à partir de ce générateur que le programme créera de nouveaux nombres. C'est là le sens de cette variable Hasard (de type generator).
Mais vous devrez initialiser ce générateur au début de votre procédure principale une et une seule fois ! Pour cela, il vous suffira d'écrire :
BEGIN
reset(Hasard) ;
...
Par la suite, pour obtenir un nombre compris entre 1 et 6 aléatoirement, vous n'aurez à écrire :
MaVariable := random(Hasard) ;
Et pourquoi pas une fonction qui renverrait directement un nombre entre 2 et 12 ?
Comme promis, pour ceux qui ne sauraient pas comment partir ou qui seraient découragés, voici un plan de ce que pourrait être votre programme.
Vous devez réfléchir aux fonctions essentielles : que fait un joueur de CRAPS ? Il joue tant qu'il a de l'argent. Il commence par parier une mise (s'il mise 0, c'est qu'il arrête et qu'il part avec son argent) puis il attaque la première manche (la seconde ne commençant que sous certaines conditions, on peut considérer pour l'instant qu'il ne fait que jouer à la première manche). Voilà donc un code sommaire de notre procédure principale :
RESET(hasard) ;
TANT QUE argent /= 0
| PARIER
| SI mise = 0
| | ALORS STOP
| FIN DU SI
| JOUER LA PREMIÈRE MANCHE
FIN DE BOUCLE
A vous de le traduire en Ada. Vous devriez avoir identifier une boucle while, un if et un exit. Vous devriez également avoir compris que nous aurons besoin de deux fonctions/procédures PARIER et JOUER LA PREMIÈRE MANCHE (nom à revoir bien entendu).
La procédure/fonction PARIER se chargera de demander la mise désirée et de vérifier que le joueur peut effectivement parier une telle somme :
TANT QUE mise trop importante
| DEMANDER mise
FIN DE BOUCLE
La fonction/procédure MANCHE1 se contentera de lancer les dés, de regarder les résultats et d'en tirer les conclusions :
LANCER dés
SI les dés valent
| 7 ou 11 => on gagne
| 2,3 ou 12 => on perd
| autre chose => point := on
| MANCHE2 avec valeur du point
FIN DE SI
Il est possible de réaliser une fonction/procédure LANCER qui "jettera les dés" et affichera les scores ou bien on pourra écrire le code nécessaire dans la fonction/procédure MANCHE1. Intéressons-nous à la fonction/procédure MANCHE2 :
TANT QUE point = on
| SI les dés valent
| | 7 => on perd
| | point => on gagne
| FIN DE SI
FIN DE BOUCLE
Voilà décomposé la structure des différentes fonctions/procédures que vous devrez rédiger. Bien sûr, je ne vous indique pas si vous devez choisir entre fonction ou procédure, si vous devez transmettre des paramètres, afficher du texte, choisir entre if et case, ... Je ne vais pas non plus tout faire.
Cliquez en-dessous pour visualiser le code d'une solution possible (ce n'est pas la seule) à ce TP :
WITH Ada.Text_IO,Ada.Integer_Text_IO,Ada.Numerics.Discrete_Random ;
USE Ada.Text_IO,Ada.Integer_Text_IO ;
PROCEDURE Craps IS
------------------------
--PACKAGES NECESSAIRES--
------------------------
SUBTYPE Intervalle IS Integer RANGE 1..6 ;
PACKAGE Aleatoire IS NEW Ada.Numerics.Discrete_Random(Intervalle);
USE Aleatoire;
---------------------------
--FONCTIONS ET PROCEDURES--
---------------------------
PROCEDURE Lancer (
D1 : OUT Natural;
D2 : OUT Natural;
Hasard : Generator) IS
BEGIN
D1 := Random(Hasard) ;
D2 := Random(Hasard) ;
Put(" Vous obtenez un") ; Put(D1,2) ;
Put(" et un") ; Put(D2,2) ;
put(". Soit un total de ") ; put(D1+D2,4) ; put_line(" !") ;
END Lancer ;
function parier(argent : natural) return natural is
mise : natural := 0 ;
begin
Put(" Vous disposez de") ; Put(argent) ; put_line(" $.") ;
while mise = 0 loop
Put(" Combien souhaitez-vous miser ? ") ;
Get(mise) ; skip_line ;
if mise > argent
then Put_line(" La maison ne fait pas credit, Monsieur.") ; mise := 0 ;
else exit ;
end if ;
end loop ;
return mise ;
end parier ;
procedure Manche2(Hasard : generator ; Mise : in out natural ; Argent : in out natural ; Point : in out natural) is
D1,D2 : Natural; --D1 et D2 indiquent les faces du dé 1 et du dé 2
begin
while point>0 loop
Lancer(D1,D2,Hasard) ;
if D1 + D2 = Point
then Put(" Vous empochez ") ; Put(Mise,1) ; put(" $. Ce qui vous fait ") ;
Argent := Argent + Mise ; point := 0 ; mise := 0 ;
Put(Argent,1) ; Put_line(" $. Bravo.") ; new_line ;
elsif D1 + D2 = 7
then Put(" Seven Out ! Vous perdez ") ; Put(Mise,1) ; put(" $. Plus que ") ;
Argent := Argent - Mise ; point := 0 ; mise := 0 ;
Put(Argent,1) ; Put_line(" $. Dommage.") ; new_line ;
end if ;
end loop ;
end Manche2 ;
procedure Manche1(Hasard : generator ; Mise : in out natural ; Argent : in out natural) is
D1,D2 : Natural; --D1 et D2 indiquent les faces du dé 1 et du dé 2
Point : Natural := 0; --0 pour off, les autres nombres indiquant que le point est on
begin
Lancer(D1,D2,Hasard) ;
CASE D1 + D2 IS
WHEN 7 | 11 => Put(" Vous empochez ") ; Put(Mise,1) ; put(" $. Ce qui vous fait ") ;
Argent := Argent + Mise ; Mise := 0 ;
Put(Argent,1) ; Put_line(" $. Bravo.") ; new_line ;
WHEN 2 | 3 | 12 => Put(" CRAPS ! Vous perdez ") ; Put(Mise,1) ; put(" $. Plus que ") ;
Argent := Argent - Mise ; Mise := 0 ;
Put(Argent,1) ; Put_line(" $. Dommage.") ; new_line ;
WHEN OTHERS => Point := D1 + D2 ;
Put(" Le point est etabli a ") ; Put(point,5) ; New_line ;
Manche2(Hasard,Mise,Argent,Point) ;
END CASE ;
end Manche1 ;
-------------
--VARIABLES--
-------------
Hasard : Generator; --Ce generator nous servira à simuler le hasard
Argent : Natural := 100; --On commence avec 100$
Mise : Natural := 0; --montant misé, on l'initialise à 0 pour débuter.
------------------------
--PROCEDURE PRINCIPALE--
------------------------
BEGIN
Reset(Hasard) ;
Put_Line(" Bienvenue au CRAPS ! ! !") ; New_Line ;
while argent > 0 loop
Mise := Parier(argent) ;
exit when Mise = 0 ;
Put_line(" Les jeux sont faits !") ;
Manche1(Hasard,Mise,Argent) ;
new_line ;
END LOOP ;
Put("Vous repartez avec ") ; Put(Argent,5) ; put("$ !") ;
END Craps ;
Voila notre jeu de craps réalisé : vous avez bien travaillé.
Mais, tu nous avais dit que tu proposerais des améliorations. :o
En effet, en voici quelques unes. Certaines ne seront peut-être réalisables que bien plus tard.
Prendre en compte tous les types de paris. Pour davantage de détails, aller voir les règles sur ce site.
Prendre en compte un parieur extérieur, un second joueur.
Enregistrer les meilleurs scores dans un fichier (pour plus tard)
Proposer un système de "médaille" : celui qui part avec moins de 100$ aura la médaille de "rookie", plus de 1000$ la médaille du "Dieu des dés" ... à vous d'inventer différents sobriquets.
Et que pourrait faire le joueur de tout cet argent gagné ? S'acheter une bière, une moto, un cigare, un carambar ?
A vous de trouver vos idées, de bidouiller, de tester ... c'est comme ça que vous progresserez. N'ayez pas peur de modifier ce que vous avez fait !
Les chapitres et notions abordés dans cette partie sont essentiels et seront réutilisés constamment. Il est donc important que vous les ayez assimilés avant de commencer la prochaine partie. N'hésitez pas à la relire ou à reprendre certains exercices pour les approfondir car la troisième partie se révèlera plus complique. Nous aborderons des types de données plus complexes (tableaux, chaînes de caractères, listes, pointeurs ...), la programmation modulaire et la programmation orientée objet. Ce sera l'occasion de revenir sur certaines notions, comme les packages, que nous n'avons pas pu approfondir.
Comme prévu, nous allons aborder dans ce chapitre un nouveau type de données, les tableaux ou array en Ada. Ce sera pour nous l'occasion d'aborder et d'expliquer ce que sont les types composites. Puis nous nous concentrerons sur notre premier type composite, les tableaux. À quoi cela ressemble-t-il en Ada ? Quel intérêt à faire des tableaux ? Comment faire des tableaux uni-, bi-, tridimensionnels ? Ce sera également l'occasion de réinvestir ce que nous avons vu dans la seconde partie, notamment sur les boucles.
N'ayez crainte, vous pourrez continuer à suivre ce tutoriel, même si vous n'avez pas bien compris ce qu'est un type composite : toute la partie III y est consacrée. En fait, disons que si les types composites vont nous ouvrir de nombreuses portes qui nous étaient pour l'instant fermées, elle ne va pas pour autant révolutionner notre façon de coder ni remettre en cause ce que nous avons déjà vu.
Pour mieux comprendre, souvenons-nous de notre TP sur le craps. Nous avions beaucoup de variables à manipuler et donc à transmettre à chaque procédure ou fonction. Par exemple, il nous fallait une variable Dé1, une variable Dé2, une variable Hasard et peut-être même une variable SommeDés. Il aurait été plus pratique de ne manipuler qu'un seul objet (appelé MainJoueur ou Joueur) qui aurait géré ces 4 variables. De même un objet Bourse aurait pu gérer la mise et la somme en dollars dont disposait le joueur.
Pour schématiser, les types composites ont pour but de nous faire manipuler des objets plus complexes que de simples variables. Prenons un autre exemple, nous voudrions créer un programme qui crée des fenêtres et permet également de leur donner un titre, de les agrandir ou rétrécir... dans l'optique de le réutiliser plus tard pour créer des programmes plus ambitieux. Nous devrons alors créer notamment les variables suivantes :
X, Y : position de la fenêtre sur l'écran
Long,Larg : longueur et largeur de la fenêtre
Epais : épaisseur des bords de la fenêtre
Titre : le titre de la fenêtre
Rfond, Vfond, Bfond : trois variables pour déterminer la couleur du fond de la fenêtre (R:rouge ; V : vert ; B : bleu)
Actif : une variable pour savoir si la fenêtre est sélectionnée ou non
Reduit : une variable pour savoir si la fenêtre est réduite dans la barre des tâches ou non
...
Eh oui, ça devient complexe de gérer tout ça ! Et vous avez du vous rendre compte lors du TP que cela devient de plus en plus compliqué de gérer un grand nombre de variables (surtout quand les noms sont mal trouvés comme ci-dessus). Il serait plus simple de définir un objet F de type Fenêtre. Imaginons la tête de nos fonctions :
Sans compter que, vous mis à part, personne ne connaît le nom et la signification des paramètres à moins de n'avoir lu tout le code (sans moi :-° ). Imaginez également le chantier si l'on désirait créer une deuxième fenêtre (il faudra trouver de nouveaux noms de variable, Youpiiii ! Il serait bien plus simple de n'avoir qu'à écrire :
Nous n'aurions pas à nous soucier de tous ces paramètres et de leur nom. C'est là tout l'intérêt des types composites : nous permettre de manipuler des objets très compliqués de la manière la plus simple possible.
Le premier type composite que nous allons voir est le tableau, et pour commencer le tableau unidimensionnel, appelé array en Ada.
Quel est l'intérêt de créer des tableaux ? Pas la peine de se compliquer la vie !
Les tableaux n'ont pas été créés pour nous "compliquer la vie". Comme toute chose en informatique, ils ont été inventés pour faire face à des problèmes concrets. Voici un exemple : en vue d'un jeu (de dé, de carte ou autre) à 6 joueurs, on a besoin d'enregistrer les scores des différents participants. D'où le code suivant :
Un peu long et redondant, d'autant plus qu'il vaut mieux ne pas avoir besoin de rajouter ou d'enlever un joueur car nous serions obligés de revoir tout notre code ! Il serait judicieux, pour éviter de créer autant de variables, de les classer dans un tableau de la manière suivante :
15
45
27
8
19
27
Chaque case correspond au score d'un joueur, et nous n'avons besoin que d'une seule variable d'un seul objet : Scores de type T_tableau. On dit que ce tableau est unidimensionnel car il a plusieurs colonnes mais une seule ligne !
Création d'un tableau en Ada
Déclaration
Je vous ai dit qu'un tableau se disait array en Ada. Mais il serait trop simple d'écrire :
Car il existe plusieurs types de tableaux unidimensionnels : tableaux d'integer, tableaux de natural, tableaux de float, tableau de boolean, tableau de character ... Il faut donc créer un type précis ! Et cela se fait de la manière suivante :
HEIN ?!? Qu'est-ce qu'il raconte là ?
Non je ne suis pas en plein délire, rassurez-vous. En fait, nous avons oublié lorsque nous avons écrit le tableau de numéroter les cases. Le plus évident est de le numéroter ainsi :
n°1
n°2
n°3
n°4
n°5
n°6
15
45
27
8
19
27
Il faudra donc écrire le code suivant :
Type T_Tableau is array(1..6) of integer ;
Scores : T_Tableau ;
Mais le plus souvent les informaticiens auront l'habitude de numéroter ainsi :
n°0
n°1
n°2
n°3
n°4
n°5
15
45
27
8
19
27
Il faudra alors changer notre code de la façon suivante :
Type T_Tableau is array(0..5) of integer ;
Scores : T_Tableau ;
La première case est donc la numéro 0 et la 6ème case est la numéro 5 ! C'est un peu compliqué, je sais, mais je tiens à l'évoquer car beaucoup de langages numérotent ainsi leurs tableaux sans vous laisser le choix (notamment le fameux langage C ;) ). Bien sûr, en Ada il est possible de numéroter de 1 à 6, de 0 à 5, mais aussi de 15 à 20, de 7 à 12 ... il suffit pour cela de changer l'intervalle écrit dans les parenthèses.
Dernier point, il est possible en Ada d'utiliser des variables pour déclarer la taille d'un tableau, sauf que ces variables devront être ... constantes !
TailleMax : constant natural := 5 ;
Type T_Tableau is array(0..TailleMax) of integer ;
Scores : T_Tableau ;
Il vous sera donc impossible de créer un tableau de taille variable (pour l'instant tout du moins).
Affectation globale
Maintenant que nous avons déclaré un tableau d'entiers (Scores de type T_Tableau), encore faut-il lui affecter des valeurs. Cela peut se faire de deux façons distinctes. Première façon, la plus directe possible :
Scores := (15,45,27,8,19,27) ;
Simple, efficace. Chaque case du tableau a désormais une valeur. Il est également possible d'utiliser des agrégats. De quoi s'agit-il ? Le plus simple est de vous en rendre compte par vous-même sur un exemple. Nous voudrions que les cases n°1 et n°3 valent 17 et que les autres valent 0. Nous pouvons écrire :
Scores := (17,0,17,0,0,0) ;
Ou bien utiliser les agrégats :
Scores := (1|3 => 17, others => 0) ;
Autrement dit, nous utilisons une sorte de case pour définir les valeurs de notre tableau. Autre possibilité, définir les trois premières valeurs puis utiliser un intervalle d'indices pour les dernières valeurs.
Scores := (17,0,17,4..6 => 0) ;
L'ennui c'est que l'on peut être amené à manipuler des tableaux très très grands (100 cases), et que cette méthode aura vite ses limites.
Affectation valeur par valeur
C'est pourquoi on utilise souvent la seconde méthode :
Quand nous écrivons Scores(1), Scores(2) ... il ne s'agit pas du tableau mais bien des cases du tableau. Scores(1) est la case numéro 1 du tableau Scores. Cette case réagit donc comme une variable de type Integer.
Euh ... c'est pas pire que la première méthode ça ?
Utilisé tel quel, si ça l'est. :D Mais en général, on la combine avec une boucle. Disons que nous allons initialiser notre tableau pour le remplir de 0 sans utiliser les agrégats. Voici la méthode à utiliser :
for i in 1..6 loop
T(i) := 0 ;
end loop ;
L'intervalle de définition d'un type T_Tableau est très important et doit donc être respecté. Supposons que nous n'ayons pas utilisé une boucle for mais une boucle while avec une variable i servant de compteur que nous incrémenterons nous-même de manière à tester également si la case considérée ne vaut pas déjà 0 :
while i <= 6 and T(i) /= 0 loop
T(i) := 0 ;
i := i + 1 ;
end loop ;
La portion de code ci-dessus est censée parcourir le tableau et mettre à zéro toutes les cases non-nulles du tableau. La boucle est censée s'arrêter quand i vaut 7. Seulement que se passe-t-il lorsque i vaut 7 justement ? L'instruction if teste si 7 est plus petit ou égal à 6 (Faux) et si T(7) est différent de zéro. Or T(7) n'existe pas ! Ce code va donc planter notre programme. Nous devons être plus précis et ne tester T(i) que si la première condition est remplie. Ca ne vous rappelle rien ? Alors regardez le code ci-dessous :
while i <= 6 and then T(i) /= 0 loop
T(i) := 0 ;
i := i + 1 ;
end loop ;
Il faut donc remplacer l'instruction and par and then. Ainsi, si le premier prédicat est faux, alors le second ne sera pas testé. Cette méthode vous revient maintenant ? Nous l'avions abordée lors du chapitre sur les booléens. Peux être sera-t-il temps d'y rejeter un œil si jamais vous aviez lu les suppléments en diagonale.
Attributs pour les tableaux
Toutefois, pour parcourir un tableau, la meilleure solution est, de loin, l'usage de la boucle for. Et nous pouvons même faire encore mieux. Comme nous pourrions être amenés à modifier la taille du tableau ou sa numérotation, voici un code plus intéressant encore :
for i in T'range loop
T(i) := 0 ;
end loop ;
L'attribut T'range indiquera l'intervalle de numérotation des cases du tableau : 1..6 pour l'instant, ou 0..5 si l'on changeait la numérotation par exemple. Remarquez que l'attribut s'applique à l'objet T et pas à son type T_Tableau. De même, si vous souhaitez afficher les valeurs contenues dans le tableau, vous devrez écrire :
for i in T'range loop
put(T(i)) ;
end loop ;
Voici deux autres attributs liés aux tableaux et qui devraient vous servir : T'first et T'last. T'first vous renverra le premier indice du tableau T ; T'last renverra le dernier indice du tableau. Si les indices de votre tableau vont de 1 à 6 alors T'first vaudra 1 et T'last vaudra 6. Si les indices de votre tableau vont de 0 à 5 alors T'first vaudra 0 et T'last vaudra 5. L'attribut T'range quant à lui, équivaut à écrire T'first..T'last.
Quel est l'intérêt de ces deux attributs puisqu'on a T'range ?
Il peut arriver (nous aurons le cas dans les exercices suivants), que vos boucles aient besoin de commencer à partir de la deuxième case par exemple ou de s'arrêter avant la dernière. Auquel cas, vous pourrez écrire :
for i in T'first +1 .. T'last - k loop
...
Dernier attribut intéressant pour les tableaux : T'length. Cet attribut renverra la longueur du tableau, c'est à dire son nombre de cases. Cela vous évitera d'écrire : T'last - T'first +1 ! Par exemple, si nous avons le tableau suivant :
Compliquons notre exercice : nous souhaitons enregistrer les scores de 4 équipes de 6 personnes. Nous pourrions faire un tableau unidimensionnel de 24 cases, mais cela risque d'être compliqué de retrouver le score du 5ème joueur de le 2ème équipe :-° Et c'est là qu'arrivent les tableaux à 2 dimensions ou bidimensionnels ! Nous allons ranger ces scores dans un tableau de 4 lignes et 6 colonnes.
15
45
27
8
19
27
41
5
3
11
3
54
12
13
14
19
0
20
33
56
33
33
42
65
Le 5ème joueur de la 2ème équipe a obtenu le score 3 (facile à retrouver).
Déclaration
La déclaration se fait très facilement de la manière suivante :
type T_Tableau is array(1..4,1..6) of natural ;
Le premier intervalle correspond au nombre de lignes, le second au nombre de colonnes.
On voit alors que cette méthode, si pratique avec des tableaux unidimensionnels devient très lourde avec une seconde dimension. Quant à l'affectation valeur par valeur, elle exigera d'utiliser deux boucles imbriquées :
for i in 1..4 loop
for j in 1..6 loop
T(i,j) := 0 ;
end loop ;
end loop ;
Tableaux tridimensionnels et plus
Vous serez parfois amenés à créer des tableaux à 3 dimensions ou plus. La déclaration se fera tout aussi simplement :
type T_Tableau3D is array(1..2,1..4,1..3) of natural ;
type T_Tableau4D is array(1..2,1..4,1..3,1..3) of natural ;
Je ne reviens pas sur l'affectation qui se fera avec trois boucles for imbriquées, l'affectation directe devenant compliquée et illisible. Ce qui est plus compliqué, c'est de concevoir ces tableaux. Voici une illustration d'un tableau tridimensionnel :
Notre tableau est en 3D, c'est un pavé droit (parallélépipède rectangle) découpé en cases cubiques. T(1,4,2) est donc le cube qui se trouve dans la première ligne, dans la 4ème colonne et dans la 2ème "rangée". Les choses se corsent encore pour un tableau en 4 dimensions, il faut s'imaginer avoir une série de tableaux en 3D (la quatrième dimension jouant le rôle du temps) :
T(1,4,1,2) est donc le cube situé à la 1ère ligne, 4ème colonne, 1ère rangée du 2ème pavé droit.
Et mes attributs ?
C'est bien gentil de ne pas revenir sur l'affectation avec les boucles imbriquées, mais moi j'ai voulu remplir un tableau de type T_Tableau3D avec des 0, en utilisant des attributs, mais je cherche encore !
Nous avons effectivement un souci. T_Tableau3D est un type de tableau avec 2 lignes, 4 colonnes et 3 rangées, donc quand nous écrivons T'range cela correspond à l'intervalle 1..2 ! Pas moyen d'avoir les intervalles 1..4 ou 1..3 ? Eh bien si ! Il suffit d'indiquer à notre attribut de quelle dimension nous parlons. Pour obtenir l'intervalle 1..4 il faut écrire T'range(2) (l'intervalle de la seconde dimension ou le second intervalle), pour obtenir l'intervalle 1..3 il faut écrire T'range(3) (l'intervalle de la troisième dimension ou le troisième intervalle). Donc T'range signifie en fait T'range(1) !
Attribut
Résultat
T'range(1)
1..2
T'range(2)
1..4
T'range(3)
1..3
T'first(1)
1
T'first(2)
1
T'first(3)
1
T'last(1)
2
T'last(2)
4
T'last(3)
3
T'length(1)
2
T'length(2)
4
T'length(3)
3
Et mes agrégats ?
Voici une manière d'initialiser un tableau bidimensionnel de 2 lignes et 4 colonnes :
T := (1 => (0,0,0,0), 2 => (0,0,0,0)) ;
On indique que la ligne 1 est (0,0,0,0) puis même chose pour la ligne 2. On peut aussi condenser tout cela :
T := (1..2 => (0,0,0,0)) ;
Ou encore :
T := (1..2 => (1..4 => 0)) ;
Il devient toutefois clair que les agrégats deviendront vite illisibles dès que nous souhaiterons manipuler des tableaux avec de nombreuses dimensions.
Vous devriez commencer à vous rendre compte que les tableaux apportent de nombreux avantages par rapport aux simples variables. Toutefois, un problème se pose : ils sont contraints. Leur taille ne varie jamais, ce qui peut être embêtant. Reprenons l'exemple initial : nous voudrions utiliser un tableau pour enregistrer les scores des équipes. Seulement nous voudrions également que notre programme nous laisse libre de choisir le nombre de joueurs et le nombre d'équipes. Comment faire ? Pour l'heure, la seule solution est de construire un type T_Tableau suffisamment grand (500 par 800 par exemple) pour décourager quiconque vouloir dépasser ses capacités (il faut avoir du temps à perdre pour se lancer dans une partie avec plus de 500 équipes de plus de 800 joueurs ^^ ). Mais la plupart du temps, 80% des capacités seront gâchées, entraînant une perte de mémoire considérable ainsi qu'un gâchis de temps processeur. La solution est de créer un type T_Tableau qui ne soit pas précontraint. Voici une façon de procéder avec un tableau unidimensionnel :
type T_Tableau is array (integer range <>) of natural ;
Notre type T_Tableau est ainsi "un peu" plus générique.
T'aurais du commencer par là ! Enfin des tableaux quasi infinis ! :pirate:
Attention ! Ici, c'est le type T_Tablau qui n'est pas contraint. Mais les objets de type T_Tableau devront toujours être contraints et ce, dès la déclaration. Celle-ci s'effectuera ainsi :
T : T_Tableau(1..8) ;
-- OU
N : natural := 1065 ;
Tab : T_Tableau(5..N) ;
Affectation par tranche
D'où l'intérêt d'employer les attributs dans vos boucles afin de disposer de procédures et de fonctions génériques (non soumises à une taille prédéfinie de tableau). Faites toutefois attention à la taille de vos tableaux, car il vous sera impossible d'écrire T := Tab ; du fait de la différence de taille entre vos deux tableaux Tab et T.
Heureusement, il est possible d'effectuer des affectations par tranches (slices en Anglais). Supposons que nous ayons trois tableaux définis ainsi :
T : T_Tableau(1..10) ;
U : T_Tableau(1..6) ;
V : T_Tableau(1..4) ;
Il sera possible d'effectuer nos affectations de la façon suivante :
T(1..6) := U ;
T(7..10) := V ;
Ou même, avec les attributs :
T(T'first..T'first+U'length-1) := U ;
T(T'first+U'length..T'first+U'length+V'length-1) := V ;
Déclarer un tableau en cours de programme
Mais cela ne répond toujours pas à la question : "Comment créer un tableau dont la taille est définie par l'utilisateur ?". Pour cela, nous allons sortir du cadre des tableaux et découvrir un nouveau bloc d'instruction : le bloc declare. L'instruction declare va nous permettre de déclarer des objets ou des variables en cours de programme. Explication par l'exemple :
procedure main is
n : Integer ;
type T_Tableau is array (integer range <>) of integer ;
begin
Put("Quelle est la longueur du tableau ? ") ;
get(n); skip_line ;
declare
tab : T_Tableau(1..n) ;
begin
--instructions ne nous intéressant pas
end;
end main;
Ainsi, nous saisissons une variable n, puis avec declare, nous ouvrons un bloc de déclaration nous permettant de créer notre tableau tab à la longueur souhaitée. Puis, il faut terminer les déclarations et ouvrir un bloc d'instruction avec begin. Ce nouveau bloc d'instructions se terminera avec le end;.
Voici quelques exercices pour mettre en application ce que nous venons de voir.
Exercice 1
Énoncé
Créer un programme Moyenne qui saisit une série de 8 notes sur 20 et calcule la moyenne de ces notes. Il est bien sûr hors de question de créer 8 variables ni d'écrire une série de 8 additions car le programme devra pouvoir être modifié très simplement pour pouvoir calculer la moyenne de 7, 9, 15 ... notes, simplement en modifiant une variable !
Solution
with Ada.Text_IO, Ada.Integer_Text_IO, Ada.Float_Text_IO ;
use Ada.Text_IO, Ada.Integer_Text_IO, Ada.Float_Text_IO ;
procedure Moyenne is
Nb_Notes : constant integer := 8 ; --Constante donnant la taille des tableaux
type T_Tableau is array(1..Nb_notes) of float ; --type tableau pour enregistrer les notes
Notes : T_Tableau ; --tableau de notes
Moy : float ; --variable servant à enregistrer la moyenne
function saisie return T_Tableau is --fonction effectuant la saisie des valeurs d'un tableau
T : T_Tableau ;
begin
for i in T'range loop
Put("Entrez la ") ; Put(i,1) ;
if i=1
then put("ere note : ") ;
else put("eme note : ") ;
end if ;
get(T(i)) ; skip_line ;
end loop ;
return T ;
end saisie ;
function somme(T:T_Tableau) return float is --fonction effectuant la somme des valeurs contenues dans un tableau
S : float := 0.0 ;
begin
for i in T'range loop
S:= S + T(i) ;
end loop ;
return S ;
end somme ;
begin --Procédure principale
Notes := saisie ;
Moy := Somme(Notes)/float(Nb_Notes) ;
Put("La moyenne est de ") ; Put(Moy) ;
end Moyenne ;
J'ai un problème dans l'affichage de mon résultat ! Le programme affiche 1.24000E+01 au lieu de 12.4 !
Par défaut, l'instruction Put() affiche les nombres flottants sous forme d'une écriture scientifique (le E+01 remplaçant une multiplication par dix puissance 1). Pour régler ce problème, Vous n'aurez qu'à écrire :
Put(Moy,2,2,0) ;
Que signifient tous ces paramètres ? C'est simple, l'instruction put() s'écrit en réalité ainsi :
L'instruction Put utilisée ici est celle provenant du package Ada.Float_Text_IO.
Le paramètre Item est le nombre de type float qu'il faut afficher.
Le paramètre Fore est le nombre de chiffres placés avant la virgule qu'il faut afficher (Fore pour Before = Avant). Cela évite d'afficher d'immenses blancs avant vos nombres.
Le paramètre Aft est le nombre de chiffres placés après la virgule qu'il faut afficher (Aft pour After = Après).
Le paramètre Exp correspond à l'exposant dans la puissance de 10. Pour tous ceux qui ne savent pas (ou ne se souviennent pas) ce qu'est une puissance de 10 ou une écriture scientifique, retenez qu'en mettant 0, vous n'aurez plus de E à la fin de votre nombre.
En écrivant Put(Moy,2,2,0) nous obtiendrons donc un nombre avec 2 chiffres avant la virgule, 2 après et pas de E+01 à la fin.
Exercice 2
Énoncé
Rédiger un programme Pascal qui affichera le triangle de Pascal jusqu'au rang 10. Voici les premiers rangs :
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
Ce tableau se construit de la manière suivante : pour calculer une valeur du tableau, il suffit d'additionner celle qui se trouve au dessus et celle qui se trouve au-dessus à gauche. Le triangle de Pascal est très utile en Mathématiques.
Comme on ne peut créer de tableaux "triangulaires", on créera un tableau "carré" de taille 10 par 10 rempli de zéros que l'on n'affichera pas. On prendra soin d'afficher les chiffres des unités les uns en dessous des autres.
Solution
with Ada.Text_IO,Ada.Integer_Text_IO ;
use Ada.Text_IO,Ada.Integer_Text_IO ;
procedure Pascal is
Taille : constant integer := 10 ;
type T_Tableau is array(1..Taille, 1..Taille) of integer ;
Pascal : T_Tableau ;
function init return T_Tableau is
T : T_Tableau ;
begin
T := (others => 0)
return T ;
end init ;
function CreerTriangle (Tab : T_Tableau) return T_Tableau is
T : T_Tableau := Tab ; --comme on ne peut pas modifier le paramètre, on en crée une copie
Begin
for i in T'range loop
T(i,1) := 1 ; --le premier nombre vaut toujours 1
for j in 2..i loop --on remplit ensuite la ligne à partir du deuxième nombre
T(i,j) := T(i-1,j) + T(i-1,j-1) ;
end loop ;
end loop ;
Return T ;
end CreerTriangle ;
Procedure Afficher(T : T_Tableau) is
begin
for i in T'range loop
for j in 1..i loop
Put(T(i,j),4) ;
end loop ;
new_line ;
end loop;
end Afficher ;
begin
Pascal := init ;
Pascal := CreerTriangle(Pascal) ;
Afficher(Pascal) ;
end Pascal ;
Pourquoi dans ta fonction CreerTriangle tu n'as pas écrit ça :
for i in T'range loop
for j in 1..i loop --on remplit ensuite la ligne à partir du deuxième nombre
if i = 1
then T(i,j) := 1 ;
else T(i,j) := T(i-1,j) + T(i-1,j-1) ;
end if ;
end loop ;
end loop ;
Surtout pas ! Car à chaque itération (chaque tour de boucle) il aurait fallu faire un test, or un test coûte de la place en mémoire et surtout du temps processeur. Cela aurait fait perdre beaucoup d'efficacité à notre programme alors que le cas de figure testé (savoir si l'on est dans la première colonne) est relativement simple à gérer et ne nécessite pas de condition. De même pour l'affichage, je n'ai pas testé si les nombres valaient 0, il suffit d'arrêter la boucle avant de les atteindre, et ça, ça se calcule facilement.
Il est également possible pour améliorer ce code, de fusionner les fonctions init et CreerTriangle en une seule de la manière suivante :
function init return T_Tableau is
Begin
for i in T'range loop
T(i,1) := 1 ; --le premier nombre vaut toujours 1
for j in 2..i loop --on remplit ensuite la ligne à partir du deuxième nombre
T(i,j) := T(i-1,j) + T(i-1,j-1) ;
end loop ;
for j in i+1 .. T'last loop --on complète avec des 0
T(i,j) := 0 ;
end loop ;
end loop ;
Return T ;
end init ;
Exercice 3
Énoncé
Créer un programme TriTableau qui crée un tableau unidimensionnel avec des valeurs entières aléatoires, l'affiche, trie ses valeurs par ordre croissant et enfin affiche le tableau une fois trié.
Solution
With ada.Text_IO, Ada.Integer_Text_IO,Ada.Numerics.Discrete_Random ;
Use ada.Text_IO, Ada.Integer_Text_IO ;
Procedure TriTableau is
Taille : constant natural := 12 ;
Type T_Tableau is array(1..Taille) of integer ;
--init renvoie un tableau à valeurs aléatoires
function init return T_Tableau is
T:T_Tableau ;
subtype Intervalle is integer range 1..100 ;
package Aleatoire is new Ada.numerics.discrete_random(Intervalle) ;
use Aleatoire ;
Hasard : generator ;
begin
Reset(Hasard) ;
for i in T'range loop
T(i) := random(Hasard) ;
end loop ;
return T ;
end init ;
--Afficher affiche les valeurs d'un tableau sur une même ligne
procedure Afficher(T : T_Tableau) is
begin
for i in T'range loop
Put(T(i),4) ;
end loop ;
end Afficher ;
--Echanger est une procédure qui échange deux valeurs : a vaudra b et b vaudra a
procedure Echanger(a : in out integer ; b : in out integer) is
c : integer ;
begin
c := a ;
a := b ;
b := c ;
end Echanger ;
--Rangmin cherche la valeur minimale dans une partie d'un tableau ; du rang debut au rang fin
--Elle ne renvoie pas le minimum mais son rang, son indice dans le tableau
function RangMin(T : T_Tableau ; debut : integer ; fin : integer) return integer is
Rang : integer := debut ;
Min : integer := T(debut) ;
begin
for i in debut..fin loop
if T(i)<Min
then Min := T(i) ;
Rang := i ;
end if ;
end loop ;
return Rang ;
end RangMin ;
--Trier est une fonction qui renvoie un tableau trié du plus petit au plus grand
--Principe, elle cherche la valeur minimale du tableau et l'échange avec la première valeur
--puis elle cherche le minimum dans le tableau à partir de la deuxième valeur et l'échange
--avec la première valeur, puis elle recommence avec la troisième valeur ...
function Trier(Tab : T_Tableau) return T_Tableau is
T : T_Tableau := Tab ;
begin
for i in T'range loop
Echanger(T(i),T(RangMin(T,i,T'last))) ;
end loop ;
return T ;
end Trier ;
T : T_Tableau ;
begin
T := init ;
Put_line("Le tableau genere par l'ordinateur est le suivant :") ;
Afficher(T) ; New_line ;
Put_line("Voici le tableau, une fois trie : ") ;
Afficher(Trier(T)) ;
end TriTableau ;
L'exemple que je vous donne est un algorithme de tri par sélection. C'est disons l'un des algorithmes de tri les plus barbares. C'est la méthode la plus logique à première vue, mais sa complexité n'est pas vraiment intéressante (par complexité, on entend le nombre d'opérations et d'itérations nécessaires et pas le fait que vous ayez compris ou pas). Nous verrons plus tard d'autres algorithmes de tri plus efficaces. En attendant, si ce code vous semble compliqué, je vous invite à lire le tutoriel de K-Phoen sur le tri par sélection : lui, il a cherché le maximum et pas le minimum, mais le principe est le même ; en revanche, son code est en C, mais cela peut être l'occasion de voir par vous même les différences et ressemblances entre l'Ada et le C.
Nous reviendrons durant la quatrième partie sur la complexité des algorithmes et nous en profiterons pour aborder des algorithmes de tris plus puissants. Mais avant cela, vous avez beaucoup de pain sur la planche ! ^^
Maintenant que vous connaissez les tableaux, notre prochain chapitre portera sur un type similaire : les chaînes de caractères ou string (en Ada). Je ne saurais trop vous conseiller de vous exercer à l'utilisation des tableaux car nous serons amenés à les utiliser très souvent par la suite, et le prochain chapitre ne s'en éloignera guère. Donc s'il vous reste des questions, des zones d'ombre, je ne saurais trop vous conseiller de relire ce cours et d'effectuer les exercices. N'hésitez pas non plus à vous fixer des projets ou des TP personnels. N'oubliez pas que c'est en forgeant que l'on devient forgeron.
Après les tableaux voici un nouveau type composite Ada : les chaînes de caractères ou strings. Rentrez les langues les garçons, il n'y aura rien de sexuel dans ce chapitre. A dire vrai, vous avez déjà manipuler des strings par le passé (je veux dire, en Ada) et ce chapitre ne fera que mettre les choses au clair car vous disposez dors et déjà de toutes les connaissances nécessaires.
Comme je viens de vous le dire, vous avez déjà manipulé des strings ou chaînes de caractères. Notamment lorsque vous écrivez :
Put("Bonjour !") ;
Le texte entre guillemets "Bonjour !" est un string.
Ah ... c'est pas ce que j'avais pensé... :( on va faire tout un chapitre dessus ?
Ce chapitre ne sera pas long. Nous avons toutes les connaissances utiles, il s'agit juste de découvrir un type composite que nous utilisons depuis longtemps sans nous en rendre compte. Qu'est-ce finalement qu'une chaîne de caractères ? Eh bien le string ci-dessus se résume en fait à ceci :
n°1
n°2
n°3
n°4
n°5
n°6
n°7
n°8
n°9
'B'
'o'
'n'
'j'
'o'
'u'
'r'
' '
'!'
Eh oui ! Ce n'est rien d'autre qu'un tableau de caractères indexé à partir de 1. Notez que certains langages comme le célèbre C, commencent leurs indices à 0 et ajoutent un dernier caractère à la fin : le caractère de fin de texte. Ce n'est pas le cas en Ada où le type String est très aisément manipulable.
Nous allons créer un programme ManipString. Nous aurons besoin du package ada.text_io. De plus, avant de créer des instructions, nous allons devoir déclarer notre string de la manière suivante :
with ada.text_io ;
use ada.text_io ;
procedure ManipString is
txt : string(1..6) ;
begin
txt := "Salut!" ;
put(txt) ;
end ManipString
Eh oui ! Un string n'étant rien d'autre qu'un tableau de caractères, il est donc contraint : son nombre de cases est limité et doit être indiqué à l'avance. Par conséquent, il est possible de lui affecté la chaîne de caractères "Salut!" mais pas la chaîne "Salut !" qui comporte 7 caractères (n'oubliez pas qu'un espace est le caractère ' ' !). Il est aussi possible de déclarer notre objet txt tout en lui affectant une valeur initiale :
with ada.text_io ;
use ada.text_io ;
procedure ManipString is
txt : string := "Salut!" ;
begin
put(txt) ;
end ManipString
Comme pour un tableau, il est possible d'accéder à l'une des valeurs contenues dans le string. Par exemple :
with ada.text_io ;
use ada.text_io ;
procedure ManipString is
txt : string := "Bonjour jules !" ;
indice : integer ;
begin
put_line(txt) ;
for i in txt'range loop
if txt(i) = 'e'
then indice := i ;
end if ;
end loop ;
txt(indice) := 'i' ;
txt(indice+1) := 'e' ;
put("oups. ") ;
put(txt) ;
end ManipString ;
Ce programme cherche la dernière occurence de la lettre 'e' et la remplace par un 'i'. Il affichera ainsi :
Bonjour jules !
oups. Bonjour julie !
Remarquez au passage qu'il est toujours possible d'utiliser les attributs.
Accès à plusieurs valeurs
Nous voudrions maintenant modifier "Bonjour Jules !" en "Bonsoir Julie !". Cela risque d'être un peu long de tout modifier lettre par lettre. Voici donc une façon plus rapide :
with ada.text_io ;
use ada.text_io ;
procedure ManipString is
txt : string := "Bonjour jules !" ;
begin
put_line(txt) ;
txt(4..7) := "soir" ;
for i in txt'range loop
if txt(i) = 'e'
then txt(i) := 'i' ;
txt(i+1) := 'e' ;
exit ;
end if ;
end loop ;
put("oups. ") ;
put(txt) ;
end ManipString ;
Il est ainsi possible d'utiliser les intervalles pour remplacer tout un paquet de caractères d'un coup. Vous remarquerez que j'en ai également profité pour condenser mon code et supprimer la variable indice. Personne n'est parfait : il est rare d'écrire un code parfait dès la première écriture. La plupart du temps, vous tâtonnerez et peu à peu, vous parviendrez à supprimer le superflu de vos codes.
Modifier la casse
Autre modification possible : modifier la casse (majuscule/minuscule). Nous aurons besoin pour cela du package Ada.characters.handling. Le code suivant va ainsi écrire "Bonjour" en majuscule et transformer le 'j' de Jules en un 'J' majuscule.
with ada.text_io, Ada.characters.handling ;
use ada.text_io, Ada.characters.handling ;
procedure ManipString is
txt : string := "Bonjour jules !" ;
begin
put_line(txt) ;
txt(1..7) := to_upper(txt(1..7)) ;
for i in txt'range loop
if txt(i) = 'e'
then txt(i) := 'i' ;
txt(i+1) := 'e' ;
elsif txt(i) = 'j'
then txt(i) := to_upper(txt(i)) ;
end if ;
end loop ;
put("oups. ") ;
put(txt) ;
end ManipString
La fonction to_upper() transforme un character ou un string pour le mettre en majuscule. Il existe également une fonction to_lower() qui met le texte en minuscule.
Concaténation
Nous allons maintenant écrire un programme qui vous donne le choix entre plusieurs prénom (entre plusieurs strings) et affiche ensuite une phrase de bienvenue. Les différents prénoms possibles seront : "Jules", "Paul" et "Frederic". Contrainte supplémentaire : il faut utiliser le moins d'instructions Put() pour saluer notre utilisateur.
with Ada.Text_IO ;
use Ada.Text_IO ;
procedure ManipString is
txt : string := "Bienvenue, " ;
Nom_1 : string := "Jules." ;
Nom_2 : string := "Paul." ;
Nom_3 : string := "Frederic." ;
choix : integer ;
begin
Put_line("Comment vous appelez-vous ?") ;
Put_line("1 - " & Nom_1) ;
Put_line("2 - " & Nom_2) ;
Put_line("3 - " & Nom_3) ;
Get(choix) ; skip_line ;
case choix is
when 1 => Put(txt & Nom_1) ;
when 2 => Put(txt & Nom_2) ;
when others => Put(txt & Nom_3) ;
end case ;
end ManipString ;
Nous avons utilisé le symbole & pour effectuer une opération de concaténation. Cela signifie que l'on met bout-à-bout deux strings (ou plus) pour en obtenir un plus long.
case choix is
when 1 => txt := txt & Nom_1 ;
when 2 => txt := txt & Nom_2 ;
when others => txt := txt & Nom_3 ;
end case ;
Transformer une variable en string et inversement
Transformer une variable en string
Et si au lieu de "Bienvenue ####", je veux afficher une ligne disant "Vous avez fait le choix n°#, vous vous appelez donc ####", je peux concaténer des strings et des variables de types integer ?
Euh ... non ! Rappelez-vous, je vous ai dit que le langage Ada avait un fort typage, autrement dit on ne mélange pas les choux et les carottes, les strings et les integer ! Par contre, il y a un moyen de parvenir à votre but en respectant ces contraintes de fort typage, grâce aux ... attributs (eh oui encore) !
Put("Vous avez fait le choix n°" & integer'image(choix) & ", vous vous appelez donc " & Nom_1) ;
L'attribut integer'image() renvoie un string, une "image" de l'integer placé entre parenthèses. Bien entendu, cet attribut n'est pas réservé au type integer et s'applique à tous types de variables ou d'objets.
Transformer un string en variable
Et l'inverse ? Si je veux transformer un string en variable ?
Eh bien tout dépend du type de variable souhaité. Si vous voulez une variable du type integer, alors vous pourrez utilisé l'attribut integer'value(). Entre les parenthèses, vous n'aurez qu'à écrire votre string et l'attribut 'value le transformera en un integer (ou un natural, ou un float ...).
Comparaison
Oui, il est possible de comparer des strings ! :-° Il est possible de tester leur égalité avec l'opérateur = ; il est aussi possible d'utiliser les opérateurs d'ordre <, >, <=, >= !
Et il compare quoi le programme ? Ca veut dire quoi si j'écris "Avion" > "Bus" ?
Les opérateurs d'ordres utilisent l'ordre alphabétique et sont insensibles à la casse (Majuscule/Minuscule). La comparaison "Avion" > "Bus" devrait donc renvoyer false, à ceci prêt que le compilateur ne voudra pas que vous l'écriviez tel quel. Il préfèrera :
...
txt1 : string := "Avion" ;
txt2 : string := "Bus" ;
BEGIN
if txt1 > txt2
then ...
Saisie au clavier
Et si je souhaite saisir un nom directement au clavier ?
Alors il existe une fonction pour cela : get_line. Elle saisira tout ce que vous tapez au clavier jusqu'à ce que vous appuyiez sur Entrée (donc pas besoin d'utiliser skip_line par la suite) et renverra ainsi une chaîne de caractères :
Il existe une façon de gérer des chaînes de caractères sans être limité par leur longueur. Pour cela, vous aurez besoin du package Ada.Strings.Unbounded. Et nous déclarerons notre variable ainsi :
txt : unbounded_string ;
Cela signifie que txt sera une "chaîne de caractère illimitée" ! ! !
:p Wouhouh ! J'essaye ça tout de suite ! T'aurais du commencer par là ! ! !
Attendez ! Les unbounded_string ne s'utilisent pas de la même manière que les string normaux ! Simplement parce que leur nature est différente. Lorsque vous déclarez un tableau, par exemple :
txt : string(1..8) ;
L'ordinateur va créer en mémoire l'équivalent de ceci :
1
2
3
4
5
6
7
8
?
?
?
?
?
?
?
?
Lorsque vous déclarez un unbounded_string comme nous l'avons fait tout à l'heure, l'ordinateur créera ceci :
{ }
C'est en fait une liste, vide certes mais une liste tout de même. À cette liste, le programme ajoutera des caractères au fur et à mesure. Il n'est plus question d'indices, ce n'est plus un tableau. Nous verrons les listes après avoir vu les pointeurs, ce qui vous éclairera sur les limites du procédé.
Opérations sur les unbounded_string
Nous pouvons ensuite affecter une valeur à nos unbounded_string. Seulement il est impossible d'écrire ceci :
Pourquoi tu ne présentes pas ça sous la forme d'un tableau, ce serait plus clair et on n'aurait pas besoin de compter pour connaître l'emplacement d'un caractère ?
En effet, de nombreuses fonctionnalités liées aux tableaux ne sont plus disponibles. Voici donc quelques fonctions pour les remplacer :
n := length(txt) ; --la variable n (natural) prendra comme valeur la longueur de l'unbounded_string txt
char := Element(txt,5) ; -- la variable char (character) prendra la 5ème valeur de l'unbounded_string txt
Replace_Element(txt,6,char) ; --le 6ème élément de txt est remplacé par le character char
txt := Null_Unbounded_String ; --txt est réinitialisé en une liste vide
Une indication tout de même, si vous ne souhaitez utiliser qu'une certaine partie de votre unbounded_string et que vous voudriez écrire txt(5..8), vous pouvez vous en sortir en utilisant To_String() et To_Unbounded_String() de la manière suivante :
Comme vous pouvez vous en rendre compte, la manipulation des unbounded_strings est plus lourde que celle des strings. Voila pourquoi nous préfèrerons utiliser en général les strings, nous réserverons l'utilisation des unbounded_strings aux cas d'extrêmes urgence. :D
Nous voila à la fin de ce chapitre sur les strings et les unbounded_strings. Cela constitue également un bon exercice sur les tableaux. Dans le prochain chapitre, nous aborderons la programmation modulaire ou pour être plus clair, l'utilisation et la création de packages.
Ce chapitre sera encore l'occasion de travailler sur les tableaux. Puis, nous apprendrons à manipuler des fichiers, notamment les fichiers textes, et ce sera de nouveau un prétexte pour manipuler les strings et les unbounded_strings.
Bref, vous avez compris, la manipulation des tableaux est LE gros morceau de cette partie sur les types composites. Après cela, les tableaux n'auront plus aucun secret pour vous. ;)
Pour ce nouveau chapitre, nous allons revenir sur le chapitre sur les tableaux.
Encore des tableaux ? Avec les strings, ça va faire le troisième chapitre !
Rassurez-vous, les tableaux ne constitueront qu'un prétexte et non pas le coeur de ce chapitre. Nous avons vu tout ce qu'il y avait à voir sur les tableaux. Mais cela ne doit pas nous faire oublier leur existence, bien au contraire. Nous allons très régulièrement les utiliser. Mais, si vous avez effectué les exercices sur les tableaux, vous avez du vous rendre compte qu'il fallait très régulièrement réécrire les mêmes fonctions, les mêmes procédures, les mêmes déclarations de type ... Se pose alors la question : "Ne serait-il pas possible de mettre tout cela dans un fichier réutilisable à l'envie ?"
Et la réponse, vous vous en doutez, est oui ! Ces fichiers, ce sont les fameux packages !
Avant de créer notre premier package, nous allons créer un nouveau programme appelé Test. dans lequel nous allons pouvoir tester toutes les procédures, fonctions, types, variables que nous allons créer dans notre package. Voici la structure initiale de ce programme :
with Integer_Array ;
use Integer_Array ;
procedure Test is
T : T_Vecteur ;
begin
end Test ;
C'est quoi ce package integer_array et ce type T_Vecteur ?
Ce package integer_array, c'est justement le package que nous allons créer et le type T_Vecteur est un "array of integer" de longueur 10 (pour l'instant). Pour l'instant si l'on tente de compiler ce programme nous nous trouvons face à deux obstacles :
Il n'y a aucune instruction entre begin et end !
Le package Integer_Array est introuvable (tout simplement parce qu'il est inexistant)
Nous allons donc devoir créer ce package. Comment faire ? Vous allez voir, c'est très simple : cliquez sur File > New deux fois pour obtenir deux nouvelles feuilles vierges.
Deux fois ? On voulait pas créer un seul package ? Y a pas erreur ?
Non, non ! J'ai bien dit deux fois ! Vous comprendrez pourquoi ensuite. Sur l'une des feuilles, nous allons écrire le code suivant :
WITH Ada.Integer_Text_IO, Ada.Text_IO ;
USE Ada.Integer_Text_IO, Ada.Text_IO ;
PACKAGE BODY Integer_Array IS
END Integer_Array ;
Puis, dans le même répertoire que votre fichier Test.adb, enregistrer ce nouveau fichier sous le nom Integer_Array.adb.
Dans le second fichier vierge, écrivez :
PACKAGE Integer_Array IS
END Integer_Array ;
Enfin, toujours dans le même répertoire, enregistrer ce fichier sous le nom Integer_Array.ads !
Vous remarquerez que cela ressemble un peu à ce que l'on a l'habitude d'écrire, sauf qu'au lieu de créer une procédure, on crée un package.
Ca me dit toujours pas pourquoi je dois créer deux fichiers qui comportent peu ou prou la même chose ! :colere2:
Nous y arrivons. Pour comprendre, nous allons créer une procédure qui affiche un tableau. Vous vous souvenez ? Nous en avons déjà écrit plusieurs (souvent appelées Afficher). Moi, je décide que je vais l'appeler Put() comme c'est d'usage en Ada.
Euh ... il existe déjà des procédures Put() et elles ne sont pas faites pour les tableaux ! o_O Ca sent le plantage ça ... :-°
Encore une fois, rassurez-vous et faites moi confiance, tout va bien se passer et je vous expliquerai tout ça à la fin ("Oui, ça fait beaucoup de choses inexpliquées", dixit Mulder & Scully :soleil: ). Dans le fichier Test.adb, nous allons écrire
WITH Integer_Array ;
USE Integer_Array ;
PROCEDURE Test IS
T : T_Vecteur(1..10) ;
BEGIN
T := (others => 0) ;
Put(T,2) ;
END Test ;
Je voudrais en effet, que notre procédure Put() puisse également gérer le nombre de chiffres affichés, si besoin est. Puis dans le fichier Integer_Array.ads, nous allons ajouter ces lignes entre is et end :
TYPE T_Vecteur IS ARRAY(integer range <>) OF Integer ;
PROCEDURE Put (T : IN T_Vecteur; Fore : IN Integer := 11);
Je prends les devants : il n'y a aucune erreur, j'ai bien écrit un point-virgule à la fin de la procédure et pas le mot is. Pourquoi ? Pour la simple et bonne raison que notre fichier Integer_Array.ads n'est pas fait pour contenir des milliers de lignes de codes et d'instructions ! Il ne contient qu'une liste de tout ce qui existe dans notre package. On dit que la ligne "PROCEDURE Put (T : IN T_Vecteur; Fore : IN Integer := 11);" est le prototype de la procédure Put(). Le prototype de notre procédure ne contient pas les instructions nécessaires à son fonctionnement, il indique seulement au compilateur : "voilà, j'ai une procédure qui s'appelle Put() et qui a besoin de ces 2 paramètres !".
Le contenu de notre procédure, nous allons l'écrire dans notre fichier Integer_Array.adb, entre is et end. Vous pouvez soit reprendre l'une de vos procédures d'affichage déjà créées et la modifier, soit recopier la procédure ci-dessous :
PROCEDURE Put(T : IN T_Vecteur ; Fore : IN Integer := 11) IS
BEGIN
FOR I IN T'RANGE LOOP
Put(T(I),Fore) ;
put(" ; ") ;
END LOOP ;
END Put ;
Enregistrer vos fichiers, compiler votre programme Test.adb et lancez-le : vous obtenez une jolie suite de 0 séparés par des points virgules. Cela nous fait donc un total de trois fichiers, dont voici les codes :
Test.adb :
WITH Integer_Array ;
USE Integer_Array ;
PROCEDURE Test IS
T : T_Vecteur(1..10) ;
BEGIN
T := (others => 0) ;
Put(T,2) ;
END Test ;
Integer_Array.ads :
PACKAGE Integer_Array IS
TYPE T_Vecteur IS ARRAY(Integer range <>) OF Integer ;
PROCEDURE Put (T : IN T_Vecteur; Fore : IN Integer := 11);
END Integer_Array ;
Integer_Array.adb :
WITH Ada.Integer_Text_IO, Ada.Text_IO ;
USE Ada.Integer_Text_IO, Ada.Text_IO ;
PACKAGE BODY Integer_Array IS
PROCEDURE Put(T : IN T_Vecteur ; Fore : IN Integer := 11) IS
BEGIN
FOR I IN T'RANGE LOOP
Put(T(I),Fore) ;
put(" ; ") ;
END LOOP ;
END Put ;
END Integer_Array ;
Nous pourrions résumer la situation par ce schéma :
Reste l'histoire de la procédure Put(). La procédure Put() ne constitue pas un mot réservé du langage, pour l'utiliser vous êtes obligés de faire appel à un package :
Integer_Text_IO pour afficher un Integer ;
Float_text_IO pour afficher un float ;
notre package Integer_Array pour afficher un T_Vecteur.
À chaque fois, c'est une procédure Put() différente qui apparaît et ce qui les différencie pour le compilateur, ce sont le nombre et le type des paramètres de ces procédures. En cas d'hésitation, le compilateur vous demandera de spécifier de quelle procédure vous parlez en écrivant :
Pour l'heure, notre package ne contient pas grand chose : le type T_Vecteur et une procédure Put(). Il nous faut donc le compléter. De quoi avons-nous besoin ?
Des procédures d'affichage,
Des procédures de création,
Des fonctions de tri,
Des fonctions pour les opérations élémentaires.
Procédures d'affichage
PROCEDURE Put(T : IN T_Vecteur ; FORE : IN integer := 11) ;
PROCEDURE Put_line(T : IN T_Vecteur ; FORE : IN integer := 11) ;
PROCEDURE Put_Column(T : IN T_Vecteur ; FORE : IN integer := 11 ; Index : IN Boolean := true) ;
Procédures de création
PROCEDURE Get(T : IN OUT T_Vecteur) ;
PROCEDURE Init(T : IN OUT T_Vecteur ; Val : IN integer := 0) ;
PROCEDURE Generate(T : IN OUT T_Vecteur ; Min : integer := integer'first ; Max : integer := integer'last) ;
Fonctions de tri
FUNCTION Tri_Selection(T : T_Vecteur) RETURN T_Vecteur ;
Voici les packages Integer_Array.adb et Integer_Array.ads tels que je les ai écrits. Je vous conseille d'essayer de les écrire par vous-même avant de copier-coller ma solution, ce sera un très bon entraînement. ;) Autre conseil, pour les opérations élémentaires, je vous invite à lire la sous-partie qui suit afin de comprendre les quelques ressorts mathématiques.
Integer_Array.adb :
WITH Ada.Integer_Text_IO, Ada.Text_IO, Ada.Numerics.Discrete_Random ;
USE Ada.Integer_Text_IO, Ada.Text_IO ;
package body Integer_Array IS
--------------------------
--Procédures d'affichage--
--------------------------
PROCEDURE Put (
T : IN T_Vecteur;
Fore : IN Integer := 11) IS
BEGIN
FOR I IN T'RANGE LOOP
Put(T(I),Fore) ;
put(" ; ") ;
END LOOP ;
END Put ;
PROCEDURE Put_Column (
T : IN T_Vecteur;
Fore : IN Integer := 11) IS
BEGIN
FOR I IN T'RANGE LOOP
Put(T(I),Fore) ;
new_line ;
END LOOP ;
END Put_Column ;
PROCEDURE Put_Line (
T : IN T_Vecteur;
Fore : IN Integer := 11) IS
BEGIN
Put(T,Fore) ;
New_Line ;
END Put_line ;
------------------------
--Procédures de saisie--
------------------------
PROCEDURE Init (
T : OUT T_Vecteur;
Value : IN Integer := 0) IS
BEGIN
T := (OTHERS => Value) ;
END Init ;
procedure generate(T : in out T_Vecteur ; min : in integer := integer'first ; max : in integer := integer'last) is
subtype Random_Range is integer range min..max ;
Package Random_Array is new ada.Numerics.Discrete_Random(Random_Range) ;
use Random_Array ;
G : generator ;
begin
reset(G) ;
T := (others => random(g)) ;
end generate ;
procedure get(T : in out T_Vecteur) is
begin
for i in T'range loop
put(integer'image(i) & " : ") ;
get(T(i)) ;
skip_line ;
end loop ;
end get ;
--------------------
--Fonctions de tri--
--------------------
function Tri_Selection(T : T_Vecteur) return T_Vecteur is
function RangMin(T : T_Vecteur ; debut : integer ; fin : integer) return integer is
Rang : integer := debut ;
Min : integer := T(debut) ;
begin
for i in debut..fin loop
if T(i)<Min
then Min := T(i) ;
Rang := i ;
end if ;
end loop ;
return Rang ;
end RangMin ;
procedure Echanger(a : in out integer ; b : in out integer) is
c : integer ;
begin
c := a ;
a := b ;
b := c ;
end Echanger ;
Tab : T_Vecteur := T ;
begin
for i in Tab'range loop
Echanger(Tab(i),Tab(RangMin(Tab,i,Tab'last))) ;
end loop ;
return Tab ;
end Tri_Selection ;
---------------------------
--Opérations élémentaires--
---------------------------
function Somme(T:T_Vecteur) return integer is
S : integer := 0 ;
begin
for i in T'range loop
S:= S + T(i) ;
end loop ;
return S ;
end somme ;
FUNCTION "+" (Left,Right : T_Vecteur) return T_Vecteur is
T : T_Vecteur ;
begin
for i in Left'range loop
T(i) := Left(i) + Right(i) ;
end loop ;
return T ;
end "+" ;
FUNCTION "*" (Left : integer ; Right : T_Vecteur) return T_Vecteur is
T : T_Vecteur ;
begin
for i in Right'range loop
T(i) := Left * Right(i) ;
end loop ;
return T ;
end "*" ;
FUNCTION "*" (Left,Right : T_Vecteur) return Integer is
S : Integer := 0 ;
begin
for i in Left'range loop
S := S + Left(i) * Right(i) ;
end loop ;
return S ;
end "*" ;
FUNCTION Minimum(T : T_Vecteur) return integer is
min : integer := T(T'first) ;
BEGIN
FOR I in T'range loop
if T(i)<min
then min := T(i) ;
end if ;
end loop ;
return min ;
end Minimum ;
FUNCTION Maximum(T : T_Vecteur) return integer is
max : integer := T(T'first) ;
BEGIN
FOR I in T'range loop
if T(i)>max
then max := T(i) ;
end if ;
end loop ;
return max ;
end Maximum ;
END Integer_Array ;
Integer_Array.ads :
PACKAGE Integer_Array IS
-------------------------------------
--Définition des types et variables--
-------------------------------------
Taille : CONSTANT Integer := 10;
TYPE T_Vecteur IS ARRAY(1..Taille) OF Integer ;
--------------------------
--Procédures d'affichage--
--------------------------
PROCEDURE Put (
T : IN T_Vecteur;
Fore : IN Integer := 11);
PROCEDURE Put_Column (
T : IN T_Vecteur;
Fore : IN Integer := 11);
PROCEDURE Put_Line (
T : IN T_Vecteur;
Fore : IN Integer := 11);
------------------------
--Procédures de saisie--
------------------------
PROCEDURE Init (
T : OUT T_Vecteur;
Value : IN Integer := 0);
PROCEDURE Generate (
T : IN OUT T_Vecteur;
Min : IN Integer := Integer'First;
Max : IN Integer := Integer'Last);
PROCEDURE Get (
T : IN OUT T_Vecteur);
--------------------
--Fonctions de tri--
--------------------
function Tri_Selection(T : T_Vecteur) return T_Vecteur ;
---------------------------
--Opérations élémentaires--
---------------------------
function Somme(T:T_Vecteur) return integer ;
FUNCTION "+" (Left,Right : T_Vecteur) return T_Vecteur ;
FUNCTION "*" (Left : integer ; Right : T_Vecteur) return T_Vecteur ;
FUNCTION "*" (Left,Right : T_Vecteur) return Integer ;
FUNCTION Minimum(T : T_Vecteur) return integer ;
FUNCTION Maximum(T : T_Vecteur) return integer ;
END Integer_Array ;
Vous remarquerez que j'utilise autant que possible les attributs et agrégats. Pensez que vous serez amenés à réutiliser ce package régulièrement et sûrement aussi à modifier la longueur de nos tableaux T_Vecteur. Il ne faut pas que vous ayez besoin de relire toutes vos procédures et fonctions pour les modifier !
Depuis le début de ce chapitre, nous parlons de T_Vecteur au lieu de tableau à une dimension, pourquoi ?
Le terme T_Vecteur (ou Vector) n'est pas utilisé par le langage Ada, contrairement à d'autres (voir C, C++). Pour Ada, cela reste toujours un array. Mais des analogies peuvent être faites avec l'objet mathématique appelé T_Vecteur. Alors, sans faire un cours de Mathématiques, qu'est-ce qu'un T_Vecteur ?
De manière (très) schématique un T_Vecteur est la représentation d'un déplacement, symbolisé par une flèche :
Ainsi, sur le schéma ci-dessus, le T_Vecteur se déplace de 3 unités vers la droite et de 1 unité vers le haut. Il représente donc le même déplacement que le T_Vecteur et on peut écrire (on remarquera que ces T_Vecteurs sont "parallèles", de même "longueur" et dans le même sens). Du coup, on peut dire que ces deux T_Vecteurs ont comme coordonnées : ou , ce qui devrait commencer à vous rappeler nos tableaux, non ? :lol: Pour les récalcitrants, sachez qu'il est possible en Mathématiques de travailler avec des T_Vecteurs en 3, 4, 5 ... dimensions. Les coordonnées d'un T_Vecteur ressemblent alors à cela :
ou
Ca ressemble sacrément à nos tableaux T_Vecteurs non ? :p
Calcul vectoriel
Plusieurs opérations sont possibles sur les T_Vecteurs. Tout d'abord, l'addition ou Relation de Chasles. Sur le schéma ci-dessus, chacun des T_Vecteurs ou a été décomposé en deux T_Vecteurs noirs tracés en pointillés : que l'on aille de A à B en suivant le T_Vecteur ou en suivant le premier T_Vecteur noir puis le second, le résultat est le même, on arrive en B ! Eh bien, suivre un T_Vecteur puis un autre, cela revient à les additionner. D'où la formule :
Il est aussi possible de multiplier un T_Vecteur par un nombre. Cela revient simplement à l'allonger ou à le rétrécir (notez que multipliez un T_Vecteur par un nombre négatif changera le sens du T_Vecteur). Par exemple :
Troisième opération : le produit scalaire. Il s'agit ici de multiplier deux T_Vecteurs entre eux. Nous ne rentrerons pas dans le détail, ce serait trop long à expliquer et sans rapport avec notre sujet. Voici comment effectuer le produit scalaire de deux T_Vecteurs :
Bien, nous en avons fini avec l'explication mathématique des T_Vecteurs. Pour ceux qui ne connaissaient pas les T_Vecteurs, ceci devrait avoir quelque peu éclairci votre lanterne. Pour ceux qui les connaissaient déjà, vous me pardonnerez d'avoir pris quelques légèretés avec la rigueur mathématique pour pouvoir "vulgariser" ce domaine fondamental des Maths.
Nous avons maintenant un joli package Integer_Array. Nous pourrons l'utiliser aussi souvent que possible, dès lors que nous aurons besoin de tableaux à une seule dimension contenant des integers. Il vous est possible également de créer un package Integer_Array2D pour les tableaux à deux dimensions.
Mais surtout, conserver ce package car nous le complèterons au fur et à mesure avec de nouvelles fonctions de tri, plus puissantes et efficaces, notamment lorsque nous aborderons la récursivité ou les notions de complexité d'algorithme. Lors du chapitre sur la généricité, nous ferons en sorte que ce package puisse être utilisé avec des float, des natural, ... Bref, nous n'avons pas fini de l'améliorer.
Qui plus est, vous avez sûrement remarqué que ce chapitre s'appelle "La programmation modulaire I". C'est donc que nous aborderons plus tard un chapitre "La programmation modulaire II". Mais rassurez-vous, vous en savez suffisamment aujourd'hui pour créer vos packages. Le chapitre II permettra seulement d'améliorer nos packages et ce sera l'occasion d'aborder les notions d'héritage et de privatisation.
Nos programmes actuels souffrent d'un grave inconvénient : tout le travail que nous pouvons effectué, tous les résultats obtenus, toutes les variables enregistrées en mémoire vive ... ont une durée qui se limite à la durée d'utilisation de notre programme. Sitôt fermé, nous perdons toutes ces données, alors qu'elle pourraient s'avérer fort utiles pour une future utilisation.
Il serait donc utile de pouvoir les enregistrer, non pas en mémoire vive, mais sur le disque dur. Et, pour cela, nous devons être capable de créer des fichiers, de les lire ou de les modifier. C'est d'ailleurs ainsi que procèdent la plupart des logiciels. Word ou OpenOffice ont besoin d'enregistrer le travail effectué par l'utilisateur dans un fichier .doc, .odt ... De même, n'importe quel jeu a besoin de créer des fichiers de sauvegardes mais aussi de lire continuellement des fichiers (les images ou les vidéos notamment) s'il veut fonctionner correctement.
C'est donc aux fichiers que nous allons nous intéresser dans ce chapitre. Vous allez voir, cela ne sera pas très compliqué, car vous disposez déjà de la plupart des notions nécessaires. Il y a juste quelques points à comprendre avant de pouvoir nous amuser. ;)
Nous allons voir plusieurs types de fichiers utilisables en Ada. Le premier type est le fichier texte. La première chose à faire lorsque l'on veut manipuler un fichier, c'est de l'ouvrir ! :p Cette remarque peut paraître idiote et pourtant : toute modification d'un fichier existant ne peut se faire que si votre programme a préalablement ouvert le fichier concerné. Et bien entendu, la dernière chose à faire est de le fermer.
Package nécessaire
Le package à utiliser, vous le connaissez déjà : Ada.Text_IO ! Le même que nous utilisions pour afficher du texte ou en saisir sur l'écran de la console. En fait, la console peut être considérée comme une sorte de fichier qui s'ouvre et se ferme automatiquement.
Le type de l'objet
Comme toujours, nous devons déclarer nos variables ou nos objets avant de pouvoir les manipuler. Nous allons créer un objet-fichier qui fera le lien avec le vrai fichier texte :
MonFichier : File_type ;
Fermer un fichier
Pour fermer un fichier, rien de plus simple, il suffit de taper l'instruction suivante (toujours entre begin et end, bien sûr :
close(MonFicher) ;
Euh... avant de le fermer, ne vaudrait-il pas mieux l'ouvrir ? :o
En effet ! :D Si vous fermez un fichier qui n'est pas ouvert, alors vous aurez droit à cette magnifique erreur :
raised ADA.IO_EXCEPTIONS.STATUS_ERROR : file not open
Il faut donc ouvrir avant de fermer ! Mais je commence par la fermeture car c'est ce qu'il y a de plus simple ^^
Ouvrir un fichier
Il y a une subtilité lorsque vous désirez ouvrir un fichier, je vous demande donc de lire toute cette partie et la suivante en me faisant confiance : pas de questions, j'y répondrai par la suite. Il faut distinguer deux cas pour ouvrir un fichier :
Soit ce fichier existe déjà.
Soit ce fichier n'existe pas encore.
Ouvrir un fichier existant
Voici le prototype de l'instruction permettant d'ouvrir un fichier existant :
procedure open(File : in out file_type ;
Mode : in File_Mode := Out_File ;
Name : in string) ;
File est le nom de l'objet-fichier : ici, nous l'avons appelé MonFichier. Nous reviendrons dans la partie suivante sur Mode, pour l'instant nous allons l'ignorer vu qu'il est déjà prédéfini. Name est le nom du fichier concerné, extension comprise. Par exemple, si notre fichier a l'extension .txt et s'appelle enregistrement alors Name doit valoir "enregistrement.txt". Nous pouvons ainsi taper le code suivant :
WITH Ada.Text_IO ;
USE Ada.Text_IO ;
PROCEDURE TestFichier IS
MonFichier : File_type ;
BEGIN
open(MonFichier,Name => "enregistrement.txt") ;
close(MonFichier) ;
END TestFichier ;
Seul souci, si le compilateur ne voit aucune erreur, la console nous affiche toutefois ceci :
raised ADA.IO_EXCEPTIONS.NAME_ERROR : enregistrement.txt: No error
Le fichier demandé n'existe pas. Deux possibilités :
Soit vous le créez "à la main" dans le même répertoire que votre programme.
Soit vous lisez la sous-sous-partie suivante. :p
Créer un fichier
Voici le prototype de l'instruction permettant la création d'un fichier :
procedure Create(File : in out File_Type;
Mode : in File_Mode := Out_File;
Name : in String);
Elle ressemble beaucoup à la procédure open(). Et pour cause, elle fait la même chose (ouvrir un fichier) à la différence qu'elle commence par créer le fichier demandé. Nous pouvons donc écrire le code suivant :
WITH Ada.Text_IO ;
USE Ada.Text_IO ;
PROCEDURE TestFichier IS
MonFichier : File_type ;
BEGIN
create(MonFichier,Name => "enregistrement.txt") ;
close(MonFichier) ;
END TestFichier ;
Et cette fois pas d'erreur après compilation ! Ca marche !
Euh... ça marche, ça marche ... c'est vite dit. Il se passe absolument rien ! Je pensais que mon programme allait ouvrir le fichier texte et que je le verrais à l'écran !
Dans l'exemple donné ci-dessus, notre programme ouvre un fichier, et ne fait rien de plus que de le fermer. Pas d'affichage, pas de modification ... Nous verrons dans ce chapitre comment modifier le fichier, mais nous ne verrons que beaucoup plus tard comment l'afficher (dernière partie du cours).
Alors deuxième question : que se passe-t-il si le fichier existe déjà ?
Eh bien testez ! C'est la meilleure façon de le savoir. Si vous avez déjà lancé votre programme, alors vous disposez d'un fichier "enregistrement.txt". Ouvrez-le avec NotePad par exemple et tapez quelques mots dans ce fichier. Enregistrez, fermez et relancez votre programme. Ouvrez à nouveau votre fichier : il est vide !
La procédure open() se contente d'ouvrir le fichier, mais celui-ci doit déjà exister. La procédure create() crée le fichier, quoiqu'il arrive. Si un fichier porte déjà le même nom, il est supprimé et remplacé par un nouveau, vide.
Détruire un fichier
Puisqu'il est possible de créer un fichier, il doit être possible de le supprimer ?
Tout à fait. Voici le prototype de la procédure en question :
Nous avons laissé une difficulté de côté tout à l'heure : le paramètre mode. Il existe trois modes possibles pour les fichiers en Ada (et dans la plupart des langages) :
Lecture seule : In_File
Ecriture seule : Out_File
Ajout : Append_File
Ca veut dire quoi ?
Lecture seule
En mode Lecture seule, c'est à dire si vous écrivez ceci :
Open(MonFichier,In_File,"enregisrement.txt") ;
Vous ne pourrez que lire ce qui est écrit dans le fichier, impossible de le modifier. C'est un peu comme si notre fichier était un paramètre en mode in.
Ecriture seule
En mode Ecriture seule, c'est à dire si vous écrivez ceci :
Open(MonFichier,Out_File,"enregisrement.txt") ;
Vous ne pourrez qu'écrire dans le fichier à partir du début, en écrasant éventuellement ce qui est déjà écrit, impossible de lire ce qui existe déjà. C'est un peu comme si notre fichier était un paramètre en mode out.
Ajout
Le mode Ajout, c'est à dire si vous écrivez ceci :
Vous pourrez écrire dans le fichier, comme en mode Out_File. La différence, c'est que vous n'écrirez pas en partant du début, mais de la fin. Vous ajouterez des informations à la fin au lieu de supprimer celles existantes.
Et il n'y aurait pas un mode in out des fois ?
Eh bien non. Il va falloir faire avec. D'ailleurs, même Word ne peut guère faire mieux : soit il écrit dans le fichier au moment de la sauvegarde, soit il le lit au moment de l'ouverture. Les autres opérations (mise en gras, changement de police, texte nouveau...) ne sont pas effectuées dans le fichier mais dans Word et ne seront inscrites dans le fichier que si Word les enregistre.
Une fois notre fichier ouvert, il serait bon de pouvoir effectuer quelques opérations avec. Attention, les opérations disponibles ne seront pas les mêmes selon que vous avez ouvert votre fichier en mode In_File ou en mode Out_File/Append_File !
Mode lecture seule : In_File
Saisir un caractère
Tout d'abord vous allez devoir tout au long de ce chapitre imaginez votre fichier et l'emplacement du curseur :
Dans l'exemple ci-dessus, vous pouvez vous rendre compte que mon curseur se trouve à la seconde ligne, vers la fin du mot "situé". Ainsi, si je veux connaître le prochain caractère, je vais devoir utiliser la procédure get() que vous connaissez déjà, mais de manière un peu différente :
procedure Get (File : in File_Type; Item : out Character);
Comme vous pouvez vous en rendre compte en lisant ce prototype, il ne suffira pas d'indiquer entre les parenthèses dans quelle variable de type character vous voulez enregistrer le caractère saisi, il faudra aussi indiquer dans quel fichier ! Comme dans l'exemple ci-dessous :
Get(MonFichier,C) ;
Autre remarque d'importance : si vous êtes en fin de ligne, en fin de page ou en fin de fichier, vous aurez droit à un joli message d'erreur ! Le curseur ne retourne pas automatiquement à la ligne. Pour pallier à cela, deux possibilités. Première possibilité : vous pouvez utiliser préalablement les fonctions suivantes :
function End_Of_Line (File : in File_Type) return Boolean;
function End_Of_Page (File : in File_Type) return Boolean;
function End_Of_File (File : in File_Type) return Boolean;
Elle renvoient true si vous êtes, respectivement, en fin de ligne, en fin de page ou en fin de fichier. Selon les cas, vous devrez alors utiliser ensuite les procédures :
procedure Skip_Line (File : in File_Type; Spacing : in Positive_Count := 1);
procedure Skip_Page (File : in File_Type);
procedure Reset (File : in out File_Type);
Skip_line(MonFichier) vous permettra de passer à la ligne suivante (nous l'utilisions jusque là pour vider le tampon). Il est même possible de lui demander de sauter plusieurs lignes grâce au paramètre Spacing en écrivant Skip_Line(MonFichier,5). Skip_Page(MonFichier) vous permettra de passer à la page suivante. Reset(MonFichier) aura pour effet de remettre votre curseur au tout début du fichier. D'où le code suivant :
loop ;
if end_of_line(MonFichier)
then skip_line(MonFichier) ;
elsif end_of_page(MonFichier)
then skip_page(MonFichier) ;
elsif end_of_file(MonFichier)
then reset(MonFichier) ;
else get(C) ; exit ;
end if ;
end loop ;
Cette boucle permet de traiter les différents cas possibles et de recommencer tant que l'on n'a pas saisi un vrai caractère ! Attention, si le fichier est vide, vous risquez d'attendre un moment :p
Deuxième possibilité :
procedure Look_Ahead(File : in File_Type;
Item : out Character;
End_Of_Line : out Boolean);
Cette procédure ne fait pas avancer le curseur mais regarde ce qui se trouve après : si l'on se trouve en fin de ligne, de page ou de fichier, le paramètre End_Of_Line vaudra true et le paramètre Item ne vaudra rien du tout. Dans le cas contraire, End_Of_Line vaudra false et Item aura la valeur du caractère suivant. Je le répète, le curseur n'est pas avancé dans ce cas là ! Exemple avec une variable fin de type boolean et une variable C de type Character :
Look_Ahead(MonFichier,C,fin);
if not fin
then put("Le caractère vaut :") ; put(C) ;
else put("C'est la fin des haricots !") ;
end if ;
Saisir un string
Pour saisir directement une ligne et pas un seul caractère, vous pourrez utiliser l'une des procédures dont voici les prototypes :
procedure Get (File : in File_Type; Item : out String);
procedure Get_Line(File : in File_Type ; Item : out String ; Last : out Natural);
function Get_Line(File : in File_Type) return string ;
La procédure Get() saisit tout le texte présent dans l'objet-fichier File et l'enregistre dans le string Item (le curseur se trouve alors à la fin du fichier). La procédure get_line() saisit tout le texte situé entre le curseur et la fin de la ligne et l'affecte dans le string Item ; elle renvoie également la longueur de la chaîne de caractère dans la variable Last (le curseur sera alors placé au début de la ligne suivante). Enfin, la fonction Get_line se contente de renvoyer le texte entre le curseur et la fin de ligne (comme la procédure, seule l'utilisation et l'absence de paramètre last diffèrent).
Mais nous nous retrouvons face à un inconvénient de taille : nous ne connaissons pas à l'avance la longueur des lignes et donc la longueur des strings qui seront retournés. A cela, deux solutions : soit nous utilisons des strings suffisamment grands en priant pour que les lignes ne soient pas plus longues (et il faudra prendre quelques précautions à l'affichage), soit nous faisons appel aux unbounded_strings :
Première méthode :
...
S : string(1..100) ;
MonFichier : file_type ;
long : natural ;
BEGIN
open(MonFichier, In_File, "enregistrement.txt") ;
get_line(MonFichier, S, long) ;
put_line(S(1..long)) ;
...
Vous devriez commencer à vous douter des opérations d'écriture applicables aux fichiers textes, car , à dire vrai, vous les avez déjà vues. Voici quelques prototypes :
procedure New_Line (File : in File_Type; Spacing : in Positive_Count := 1);
procedure New_Page (File : in File_Type);
procedure Put (File : in File_Type; Item : in Character);
procedure Put (File : in File_Type; Item : in String);
procedure Put_Line(File : in File_Type; Item : in String);
Ai-je besoin de tout réexpliquer ? J'espère que non, mais si certains en ont tout de même besoin, les explications sont cachées ci-dessous.
New_line() insère un saut de ligne dans notre fichier à l'emplacement du curseur (par défaut, mais le paramètre spacing permet d'insérer 2, 3, 4 ... sauts de lignes). New_Page() insére un saut de page. Les procédures Put() permettent d'insérer un caractère ou toute une chaîne de caractères. La procédure put_line() insère une chaîne de caractères et un saut de ligne.
Autres opérations
Il existe également quelques fonctions ou procédures utilisables quelle que soient les modes ! En voici quelques-unes pour se renseigner sur notre fichier :
Pour connaître le mode dans lequel un fichier est ouvert (In_File, Out_File, Append_File). Permet d'éviter des erreurs de manipulation.
function Mode (File : in File_Type) return File_Mode;
Pour connaître le nom du fichier ouvert.
function Name (File : in File_Type) return String;
Pour savoir si un fichier est ouvert ou non. Pour éviter de fermer un fichier déjà fermé, ou d'ouvrir un fichier déjà ouvert etc ...
function Is_Open (File : in File_Type) return Boolean;
Et en voici quelques autres pour déplacer le curseur ou se renseigner sur sa position. Pour information, le type Positive_Count sont en fait des natural mais 0 en est exclu (les prototypes ci-dessous sont écrits tels qu'ils le sont dans le package Ada.Text_IO).
Pour placer le curseur à une certaine colonne.
procedure Set_Col (File : in File_Type; To : in Positive_Count);
Pour placer le curseur à une certaine ligne.
procedure Set_Line (File : in File_Type; To : in Positive_Count);
Pour connaître la colonne où se situe le curseur.
function Col (File : in File_Type) return Positive_Count;
Pour connaître la ligne où se situe le curseur.
function Line (File : in File_Type) return Positive_Count;
Pour connaître la page où se situe le curseur.
function Page (File : in File_Type) return Positive_Count;
Et on ne peut manipuler que des fichiers contenant du texte ? Comment je fais si je veux enregistrer les valeurs contenues dans un tableau par exemple ? Je dois absolument utiliser les attributs 'image et 'value ?
Non, le fichier texte n'est pas obligatoire, mais il a l'avantage d'être modifiable par l'utilisateur grâce à un simple éditeur de texte, type notepad par exemple. Mais si vous ne souhaitez qu'enregistrer des integer (par exemple), il est possible d'enregistrer vos données dans des fichiers binaires prévus à cet effet.
C'est quoi un fichier binaire ?
C'est un fichier constitué d'une suite de bits (les chiffres 0 et 1, seuls chiffres connus de l'ordinateur). Ca ne vous aide pas beaucoup ? :( Eh bien c'est le but. :p Ces fichiers contiennent une suite d'informations illisibles par l'utilisateur. Pour pouvoir lire ces données, il faut faire appel à un logiciel qui connaitra le type d'informations contenues dans le fichier et qui saura comment les traiter. Par exemple :
Les fichiers MP3, sont illisibles par le commun des mortels. En revanche, en utilisant un logiciel tel VLC ou amarok vous pourrez écouter votre morceau de musique.
Les fichiers images (.bmp, .tiff, .png, . jpg, .gif ...) ne seront lisibles qu'à l'aide d'un logiciel comme photofiltre par exemple.
On pourrait encore multiplier les exemples, la plupart des fichiers utilisés aujourd'hui étant des fichiers binaires.
Parmi ces fichiers binaires, il en existe deux sortes : les fichiers séquentiels et les fichiers à accès direct. La différence fondamentale réside dans la façon d'accéder aux données qu'ils contiennent. Les premiers sont utilisables comme les fichiers textes (qui sont eux-même des fichiers séquentiels), c'est pourquoi nous allons les aborder de ce pas. Les seconds sont utilisés un peu différemment, et nous les verrons dans la sous-partie suivante.
Nous allons créer un programme Enregistrer qui, comme son nom l'indique, enregistrera des données de type integer dans un fichier binaire à accès séquentiel. Nous devons d'abord régler le problème des packages. Celui que nous allons utiliser ici est Ada.sequential_IO. Le souci, c'est qu'il est fait pour tous les types de données (float, natural, array, string, integer, character ...), on dit qu'il est générique (nous aborderons cette notion dans la quatrième partie de ce cours). La première chose à faire est donc de créer un package plus spécifique :
WITH Ada.Sequential_IO, Ada.Integer_Text_IO ;
USE ada.Integer_Text_IO ;
PROCEDURE Enregistrer IS
PACKAGE integer_file IS NEW Ada.Sequential_IO(integer) ;
USE integer_file ;
...
Comme vous pouvez le remarquer, Ada.Sequential_IO n'est pas déclaré après USE (du fait de sa généricité) et doit être "redéclaré" plus loin : nous créeons un package integer_file qui est en fait le package Ada.Sequential_IO mais réservé aux données de type integer. Et nous pouvons ensuite écrire notre clause use integer_file. Nous avons déjà vu ce genre de chose durant notre premier TP pour créer des nombres aléatoires. Je ne vais pas m'étendre davantage sur cette notion un peu compliquée car nous y reviendrons plus tard.
Nous allons ensuite déclarer notre objet-fichier, notre type T_Tableau et notre objet T de type T_Tableau. Je vous laisse le choix dans la manière de saisir les valeurs de T. Puis nous allons devoir créer notre fichier, l'ouvrir et le fermer :
...
MonFichier : File_Type ; --tout ça c'est du déjà vu
type T_Tableau is array(1..5,1..5) of integer ;
T : T_Tableau ;
BEGIN
-----------------------------------------
-- Saisie libre de T (débrouillez-vous)--
-----------------------------------------
create(MonFichier,Out_File,"sauvegarde.inf") ;
-------------------------------
-- enregistrement (vu après) --
-------------------------------
close(MonFichier) ;
END Enregistrer ;
Comme je vous l'ai dit, l'encart "Saisie libre de T" est à votre charge (affectation au clavier, aléatoire ou prédéterminée, à vous de voir). La procédure create() peut être remplacée par la procédure open(), comme nous en avions l'habitude avec les fichiers textes. Les modes d'ouverture (In_File, Out_File, Append_File) sont également les mêmes. Concentrons-nous plutôt sur le deuxième encart : comment enregistrer nos données ? Les procédures put_line() et put() ne sont plus utilisables ici ! En revanche, elles ont une "sœur jumelle" : write() ! Traduction pour les anglophobes : "écrire". Notre second encart va donc pouvoir être remplacé par ceci :
...
for i in T'range(1) loop
for j in T'range(2) loop
write(MonFichier,T(i,j)) ;
end loop ;
end loop ;
...
Compiler votre code et exécutez-le. Un fichier "sauvegarde.inf" doit avoir été créé. Ouvrez-le avec le bloc-notes : il affiche des symboles bizarres, mais rien de ce que vous avez enregistré ! Je vous rappelle qu'il s'agit d'un fichier binaire ! Donc il est logique qu'il ne soit pas lisible avec un simple éditeur de texte. Pour le lire, nous allons créer, dans le même répertoire, un second programme : Lire. Il faudra donc "redéclarer" notre package integer_file et tout et tout. ;) Pour la lecture, nous ne pouvons, bien entendu, pas non plus utilisé get() ou get_line(). Nous utiliserons la procédure read() (traduction : lire) pour obtenir les informations voulues et la fonction Enf_Of_File() pour être certains de ne pas saisir de valeur une fois rendu à la fin du fichier (à noter que les fins de ligne ou fins de page n'existe pas dans un fichier binaire).
WITH Ada.Sequential_IO, Ada.Integer_Text_IO ;
USE ada.Integer_Text_IO ;
PROCEDURE Lire IS
PACKAGE integer_file IS NEW Ada.Sequential_IO(integer) ;
USE integer_file ;
MonFichier : File_Type ;
type T_Tableau is array(1..5,1..5) of integer ;
T : T_Tableau ;
BEGIN
open(MonFichier,In_File,"sauvegarde.dat") ;
for i in T'range(1) loop
for j in T'range(2) loop
exit when Enf_Of_File(MonFichier) ;
read(MonFichier,T(i,j)) ;
put(T(i,j)) ;
end loop ;
end loop ;
close(MonFichier) ;
END Lire ;
Voilà, nous avons dors et déjà fait le tour des fichiers binaires à accès séquentiel. Le principe n'est guère différent des fichiers textes (qui sont, je le rappelle, eux aussi à accès séquentiels), retenez simplement que put() est remplacé par write(), que get() est remplacé par read() et qu'il faut préalablement spécifier le type de données enregistrées dans vos fichiers. Nous allons maintenant attaquer les fichiers binaires à accès direct. :pirate:
Les fichiers binaires à accès directs fonctionnent à la manière d'un tableau. Chaque élément enregistré dans le fichier est doté d'un numéro, d'un indice, comme dans un tableau. Tout accès à une valeur, que ce soit en lecture ou en écriture, se fait en indiquant cet indice. Première conséquence et première grande différence avec les fichiers séquentiels, le mode Append_File n'est plus disponible. En revanche, un mode InOut_File est enfin disponible ! :D
Nous allons enregistrer cette fois les valeurs contenues dans un tableau de float unidimensionnel. Nous utiliserons donc le package Ada.Direct_IO qui, comme Ada.Sequential_IO, est un package générique (fait pour tous types de données). Il nous faudra donc créer un package comme précédemment avec integer_file (mais à l'aide de Ada.Direct_IO cette fois). Voici le code de ce programme :
WITH Ada.Direct_IO, Ada.Float_Text_IO ;
USE Ada.Float_Text_IO ;
PROCEDURE FichierDirect IS
PACKAGE float_file IS NEW Ada.Direct_IO(Float) ;
USE float_file ;
MonFichier : File_Type ;
TYPE T_Vecteur IS ARRAY(1..8) OF Float ;
T : T_Vecteur := (1.0,2.0,4.2,6.5,10.0,65.2,5.3,101.01);
x : float ;
BEGIN
create(MonFichier,InOut_File,"vecteur.inf") ;
for i in 1..8 loop
write(MonFichier,T(i),count(i)) ;
read(MonFichier,x,count(i)) ;
put(x) ;
end loop ;
close(MonFichier) ;
END FichierDirect ;
Là encore, si vous tentez d'ouvrir votre fichier "vecteur.inf", vous aurez droit à un joli texte incompréhensible.
En effet, l'instruction set_index() place le curseur à l'endroit voulu, et il existe une deuxième procédure write() qui ne spécifie pas l'indice où vous souhaitez écrire. Cette procédure écrit donc là où se trouve le curseur. Et il en est de même pour la procédure Read().
Créer un fichier texte appelé "poeme.txt" et dans lequel vous copierez le texte suivant :
Que j'aime a faire apprendre un nombre utile aux sages ! Immortel Archimede, artiste, ingenieur, Qui de ton jugement peut priser la valeur ? Pour moi ton probleme eut de pareils avantages.
Jadis, mysterieux, un probleme bloquait Tout l'admirable procede, l'oeuvre grandiose Que Pythagore decouvrit aux anciens Grecs. O quadrature ! Vieux tourment du philosophe
Insoluble rondeur, trop longtemps vous avez Defie Pythagore et ses imitateurs. Comment integrer l'espace plan circulaire ? Former un triangle auquel il equivaudra ?
Nouvelle invention : Archimede inscrira Dedans un hexagone ; appreciera son aire Fonction du rayon. Pas trop ne s'y tiendra : Dedoublera chaque element anterieur ;
Toujours de l'orbe calculee approchera ; Definira limite ; enfin, l'arc, le limiteur De cet inquietant cercle, ennemi trop rebelle Professeur, enseignez son probleme avec zele
Ce poème est un moyen mnémotechnique permettant de réciter les chiffres du nombre (), il suffit pour cela de compter le nombre de lettres de chacun des mots (10 équivalant au chiffre 0).
Puis créer un programme poeme.exe qui lira ce fichier et l'affichera dans la console.
Solution
with ada.Text_IO, ada.Strings.Unbounded ;
use ada.Text_IO, ada.Strings.Unbounded ;
procedure poeme is
F : File_Type ;
txt : unbounded_string ;
begin
open(F,in_file,"poeme.txt") ;
while not end_of_file(F) loop
txt :=to_unbounded_string(get_line(F)) ;
put_line(to_string(txt)) ;
end loop ;
close(F) ;
end poeme ;
Exercice 2
Enoncé
Plus compliqué, reprendre le problème précédent et modifier le code source de sorte que le programme affiche également les chiffres du nombre . Attention ! La ponctuation ne doit pas être comptée et je rappelle que la seule façon d'obtenir 0 est d'avoir un nombre à 10 chiffres !
Solution
WITH Ada.Text_IO, Ada.Integer_Text_IO, Ada.Strings.Unbounded ;
USE Ada.Text_IO, Ada.Integer_Text_IO, Ada.Strings.Unbounded ;
PROCEDURE Poeme IS
F : File_Type;
Txt : Unbounded_String;
PROCEDURE Comptage (Txt : String) IS
N : Natural := 0;
BEGIN
FOR I IN Txt'RANGE LOOP
CASE Txt(I) IS
WHEN ' ' => IF N/=0 THEN Put(N mod 10,3) ; N:= 0 ; END IF ;
WHEN '.' | '?' | ',' | ';' | '!' | ':' | ''' => IF N/=0 THEN Put(N mod 10,3) ; N:= 0 ; END IF ;
WHEN others => n := n+1 ;
END CASE ;
END LOOP ;
END Comptage ;
BEGIN
Open(F,In_File,"poeme.txt") ;
WHILE NOT End_Of_File(F) LOOP
Txt :=To_Unbounded_String(Get_Line(F)) ;
Put_Line(To_String(Txt)) ;
Comptage(To_String(Txt)) ;
New_line ;
END LOOP ;
Close(F) ;
END Poeme ;
Exercice 3
Enoncé
Nous allons créer un fichier "Highest_Score.txt" dans lequel seront enregistrés les informations concernant le meilleur score obtenu à un jeu (ce code pourra être mis en package pour être réutilisé plus tard). Seront demandés : le nom du gagnant, le score obtenu, le jour, le mois et l'année d'obtention de ce résultat.
Voici ci-dessous un exemple de la présentation de ce fichier texte. Pas d'espaces, les intitulés sont en majuscule suivis d'un signe =. Il y aura 4 valeurs entières à enregistrer et un string.
Le programme donnera le choix entre lire le meilleur score et en enregistrer un nouveau. Vous aurez besoin pour cela du package Ada.Calendar et de quelques fonctions :
clock : renvoie la date du moment. Résultat de type Time.
year(clock) : extrait l'année de la date du moment. Résultat : integer.
month(clock) : extrait le mois de la date du moment. Résultat : integer.
day(clock) : extrait le jour de la date du moment. Résultat : integer.
Solution
with Ada.Text_IO, Ada.Integer_Text_IO, Ada.Calendar, Ada.Characters.Handling, Ada.Strings.Unbounded ;
use Ada.Text_IO, Ada.Integer_Text_IO, Ada.Calendar, Ada.Characters.Handling, Ada.Strings.Unbounded ;
procedure BestScore is
--------------------
--Lecture du score--
--------------------
procedure read_score(F : file_type) is
txt : unbounded_string ;
long : natural ;
Score, Jour, Mois, Annee : natural ;
Nom : unbounded_string ;
begin
while not end_of_file(F) loop
txt:=To_Unbounded_String(get_line(F)) ;
long := length(txt) ;
if long>=6
then if To_String(txt)(1..6)="SCORE="
then Score := natural'value(To_String(txt)(7..long)) ;
end if ;
if To_String(txt)(1..6)="MONTH="
then Mois := natural'value(To_String(txt)(7..long)) ;
end if ;
end if ;
if long >= 5
then if To_String(txt)(1..5)="YEAR="
then Annee := natural'value(To_String(txt)(6..long)) ;
end if ;
if To_String(txt)(1..5)="NAME="
then Nom := to_unbounded_string(To_string(txt)(6..long)) ;
end if ;
end if ;
if long >= 4 and then To_String(txt)(1..4)="DAY="
then Jour := natural'value(To_String(txt)(5..long)) ;
end if ;
end loop ;
Put_line(" " & to_string(Nom)) ;
Put("a obtenu le score de ") ; Put(Score) ; New_line ;
Put("le " & integer'image(jour) & "/" & integer'image(mois) & "/" & integer'image(annee) & ".") ;
end read_score ;
---------------------
--Ecriture du score--
---------------------
procedure Write_Score(F : file_type) is
txt : unbounded_string ;
score : integer ;
begin
Put("Quel est votre nom ? ") ; txt := to_unbounded_string(get_line) ;
Put_line(F,"NAME=" & to_string(txt)) ;
Put("Quel est votre score ? ") ; get(score) ; skip_line ;
Put_line(F,"SCORE=" & integer'image(score)) ;
Put_line(F,"YEAR=" & integer'image(year(clock))) ;
Put_line(F,"MONTH=" & integer'image(month(clock))) ;
Put_line(F,"DAY=" & integer'image(day(clock))) ;
end Write_Score ;
------------------------------
-- PROCEDURE PRINCIPALE --
------------------------------
c : character ;
NomFichier : constant string := "Highest_Score.txt" ;
F : file_type ;
begin
loop
Put_line("Que voulez-vous faire ? Lire (L) le meilleur score obtenu,");
Put("ou en enregistrer un nouveau (N) ? ") ;
get_immediate(c) ; new_line ; new_line ;
c := to_upper(c) ;
exit when c = 'L' or c = 'N' ;
end loop ;
if c = 'L'
then open(F,In_File,NomFichier) ;
read_score(F) ;
close(F) ;
else create(F,Out_File,NomFichier) ;
write_score(F) ;
close(F) ;
open(F,In_File,NomFichier) ;
read_score(F) ;
close(F) ;
end if ;
end BestScore ;
Ce chapitre sur les fichiers est un peu long mais au final vous n'aurez pas appris tant de nouveautés que cela.Toutefois, vous voilà désormais armés pour créer des programmes plus complets. Vous pouvez dors et déjà réinvestir ce que vous avez vu et conçu dans ces derniers chapitres pour améliorer votre jeu de craps (vous vous souvenez, le TP) en permettant au joueur de sauvegarder son (ses) score(s), par exemple.
Nous allons, maintenant mettre de côté les tableaux (vous les retrouverez vite, rassurez vous :-° ) pour créer nos propres objets. ;)
Marre de parler d'objets sans en voir vraiment l'utilité ? Peu ou pas convaincu par la révolution des tableaux et des strings ? Alors ce chapitre est fait pour vous ! Nous allons cette fois créer nos propres objets. Oui oui, vous avez bien lu. ;)
Nous allons ici apprendre à créer des types d'objets, à les modifier, à les faire évoluer et même à créer "sous-types" de nos propres types d'objet !
Cette partie n'est pas la plus folichonne : nous allons réutiliser des types préexistants pour en créer des nouveaux. Malgré tout, elle vous sera souvent très utile et elle n'est pas très compliquée à comprendre.
Sous-type comme intervalle
Schématiquement, Integer couvre les nombres entiers (0, 1, 2, 3, ... -1, -2, -3, ...) et natural les nombres entiers naturels (0, 1, 2, 3, ...). Nous souhaiterions créer un type T_positif et un type T_negatif qui ne comportent pas le nombre 0. Pour cela, nous allons créer un sous-type (subtype) de natural ou de integer qui couvrira l'intervalle (range) allant de 1 à l'infini (symbole : ) pour les positifs et de "l'infini négatif" (symbole : ) à -1 pour les négatifs.
Nous allons donc, dans la partie déclarative, écrire soit :
subtype T_positif is integer range 1..integer'last ;
subtype T_negatif is integer range integer'first..-1 ;
Soit :
subtype T_positif is natural range 1..natural'last ;
Il sera alors impossible d'écrire ceci :
n : T_positif := 0 ;
m : T_negatif := 1 ;
Comme T_positif et T_negatifdérivent des types integer ou natural (lui-même dérivant du type integer), toutes les opérations valables avec les integer/natural, comme l'addition ou la multiplication, sont bien sûr valables avec les types T_positif et T_negatif, tant que vous ne sortez pas des intervalles définis.
Types modulaires
Deuxième exemple, nous souhaiterions créer un type T_chiffre allant de 0 à 9. Nous écrirons alors :
subtype T_chiffre is integer range 0..9 ;
Seulement, les opérations suivantes engendreront une erreur :
...
c : T_chiffre ;
BEGIN
c:= 9 ; --Jusque là, tout va bien
c:= c+2 ; --c devrait valoir 11. Ouille ! Pas possible !
...
Il serait donc plus pratique si après 9, les comptes recommençaient à 0 ! Dans ce cas 9+1 donnerait 0, 9+2 donnerait 1, 9+3 donnerait 2 ... C'est à cela que servent les sous-types modulaires que l'on définira ainsi :
type T_chiffre is mod 10;
Le type T_chiffre comportera 10 nombres : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ! Pour ceux qui ont de bonnes connaissances en mathématiques, c= 9 équivaudra à écrire , c'est à dire que "c est congru à 9 modulo 10".
Autre exemple, nous allons créer des types T_Heure, T_Minute, T_Seconde, T_Milliseconde pour indiquer le temps. Remarquez que depuis le début, j'introduis mes types par la lettre T, ce qui permet de distinguer rapidement si un mot correspond à un type ou à une variable.
type T_Heure is mod 24 ;
type T_Minute is mod 60 ;
type T_Seconde is mod 60 ;
type T_Milliseconde is mod 1_000 -- on peut aussi écrire 1000, mais le symbole _ (touche 8)
-- permet de séparer les chiffres pour y voir plus clair
Continuons avec notre exemple du temps. Les types T_Heure, T_Minute, T_Seconde et T_Milliseconde ont été créés comme des types modulaires. Créer un type T_Annee ne devrait pas vous poser de soucis. Très bien. Mais pour les jours ou les mois, il serait bon de distinguer trois types distincts :
T_Numero_Jour : type allant de 1 à 31 (non modulaire car commençant à 1 et non 0)
T_Nom_Jour : type égal à LUNDI, MARDI, MERCREDI ...
T_Mois : type égal à JANVIER, FEVRIER, MARS ...
Nous savons déclarer les premiers types :
subtype T_Numero_Jour is integer range 1..31 ;
Pour les suivants, il faut créer ce que l'on appelle un type énuméré (un type où il faut énumérer toutes les valeurs disponibles), de la manière suivante :
type T_Mois is (JANVIER,FEVRIER,MARS,AVRIL,MAI,JUIN,
JUILLET,AOUT,SEPTEMBRE,OCTOBRE,NOVEMBRE,DECEMBRE) ;
type T_Nom_Jour is (LUNDI,MARDI,MERCREDI,JEUDI,VENDREDI,SAMEDI,DIMANCHE) ;
Pourquoi ne pas se contenter d'un nombre pour représenter le jour ou le mois ?
Eh bien par souci de clarté et de mémorisation. Est-il plus simple d'écrire : "jour = 4" ou "jour = JEUDI" ? "mois := 5" ou "mois := MAI" ? La deuxième façon est bien plus lisible. Et souvenez-vous des fichiers et de leur mode d'ouverture : ne vaut-il pas mieux écrire "In_File", "Out_File" ou "Append_File" que 0, 1 ou 2 ? Ne vaut-il mieux pas écrire true ou false que 1 ou 0 ? De plus, il est possible d'utiliser les attributs avec les types énumérés :
T_Mois'first renverra JANVIER (le premier mois)
T_Nom_Jour'last renverra DIMANCHE (le dernier jour)
T_Mois'succ(JUIN) renverra JUILLET (le mois suivant JUIN)
T_Mois'pred(JUIN) renverra MAI (le mois précédant JUIN)
T_Mois'pos(JUIN) renverra 5 (le numéro du mois de JUIN dans la liste)
T_Mois'val(1) renverra FEVRIER (le mois n°1 dans la liste, voir après)
put(T_Nom_Jour'image(MARDI)) permettra d'écire MARDI à l'écran
Par conséquent, il est même possible de comparer des variables de type énuméré : MARDI>JEUDI renverra false ! Enfin, les affectations se font de la manière la plus simple qu'il soit :
Nous disposons maintenant des types T_Heure, T_Minute, T_Seconde, T_Milliseconde, T_Annee (je vous ai laissé libres de le faire), T_Mois, T_Nom_Jour et T_Numero_Jour, ouf ! C'est un peu long tout ça non ? :waw: Il serait plus pratique de tout mettre dans un seul type de données (T_Temps ou T_Date par exemple) de manière à éviter de déclarer tout un escadron de variables pour enregistrer une simple date.
C'est ce que nous permettent les types structurés ou types articles (d'ailleurs en C, le mot clé est struct, pour une fois les termes du C me semblent plus clairs :D ). Nous allons donc créer notre type structuré en écrivant "type T_Temps is" comme d'habitude puis nous allons ouvrir un bloc record. L'exemple par l'image :
type T_Temps is
record
...
end record ;
Rappelons que "to record" signifie "Enregistrer". C'est donc entre les instructions record et end record que nous allons enregistrer le contenu du type T_Temps, c'est à dire l'heure, les minutes, les secondes et les millisecondes :
type T_Temps is
record
H : T_Heure ;
Min : T_Minute ;
S : T_Seconde ;
Milli : T_Milliseconde ;
end record ;
Ainsi, c'est comme si l'on déclarait quatre variables de types différents sauf que ce que l'on déclare, ce sont les quatre composantes de notre type. Par la suite, nous n'aurons plus qu'une seule variable de type T_Temps à déclarer et à modifier. Il est même possible d'attribuer des valeurs par défaut à nos différentes composantes. Ainsi, contrairement aux autres types de variables ou d'objets prédéfinis, il sera possible d'initialiser un objet de type T_Temps simplement en le déclarant.
type T_Temps is
record
H : T_Heure := 0 ;
Min : T_Minute := 0 ;
S : T_Seconde := 0 ;
Milli : T_Milliseconde := 0 ;
end record ;
t : T_Temps ; --Sans rien faire, t vaut automatiquement 0 H 0 Min 0 S 0 mS !
La pratique
Quelques petits exercices d'application bêtes et méchant :
créer un type T_Jour contenant le nom et le numéro du jour
créer le type T_Date contenant le jour, le mois et l'année
La réponse
type T_Jour is
record
nom : T_Nom_Jour := LUNDI;
num : T_Numero_Jour := 1 ;
end record ;
type T_Date is
record
jour : T_Jour ;
mois : T_Mois ;
annee : T_Annee ;
end record ;
Ordre des déclarations
En effet, le type T_Jour a besoin pour être déclaré que les types T_Numero_Jour et T_Nom_Jour soient déjà déclarés, sinon, lors de la compilation, le compilateur va tenter de construire notre type T_Jour et découvrir que pour cela il a besoin de deux types inconnus ! Car le compilateur va lire votre code du haut vers le bas et il lève les erreurs au fur et à mesure qu'elles apparaissent.
Pour pallier à ce problème, soit vous respectez l'ordre logique des déclarations, soit vous ne voulez pas (c'est bête) ou vous ne pouvez pas (ça arrive) respecter cet ordre et auquel cas, je vous conseille d'écrire les prototypes des types nécessaires auparavant :
type T_Nom_Jour ; --Liste des prototypes évitant les soucis à la compilation
type T_Numero_Jour ;
type T_Jour ;
type T_Date is --début des déclarations des sources (le tout en vrac)
record
...
end record ;
type T_Jour is
record
...
end record ;
type T_Nom_Jour is
record
...
end record ;
type T_Numero_Jour is
record
...
end record ;
Déclarer et modifier un objet de type structuré
Déclaration d'un objet de type structuré
Le langage Ada considère automatiquement les types que vous construisez comme les siens. Et donc la déclaration se fait le plus simplement du monde, comme pour n'importe quelle variable :
t : T_Temps ;
prise_bastille : T_Date ;
Affectation d'un objet de type structuré
Comment attribuer une valeur à notre objet t de type T_Temps ? Il y a plusieurs façons. Tout d'abord avec les agrégats, comme pour les tableaux (à la différence que les valeurs ne sont pas toutes du même type) :
t := (11,55,48,763) ; --pensez à respecter l'ordre dans lequel les composantes
--ont été déclarées lors du record : H,Min,S,Milli
-- OU BIEN
t := (7, Min => 56, Milli => 604 , S => 37) ; --Plus de soucis d'orde
Cette méthode est rapide, efficace mais pas très lisible ? Si on ne connaît pas bien le type T_Temps, on risque de se tromper dans l'ordre des composantes. Et puis, si on veut seulement faire une affectation sur les minutes ? Voici donc une seconde façon, sans agrégats :
t.H := 11 ;
t.S := 48 ;
t.Min := 55 ;
t.Milli := 763 ;
...
t.Min := t.Min + 15 ; --Possible car t.Min est la composante de type T_Minute qui est un type modulaire
--En revanche, les t.H n'est pas incrémenté pour autant !
Un nouvel exercice et sa correction
A vous d'affecter une valeur à notre objet prise_bastille ! Pour rappel, la Bastille est tombée le 14 juillet 1789 (et c'était un mardi).
Il faudra, pour la deuxième méthode, utiliser deux fois les points pour accéder à la composante de composante.
22 ! Rev'là les tableaux !
Compliquons notre tâche en mélangeant tableaux et dates !
Tableau dans un type
Tout d'abord, il pourrait être utile que certaines dates aient un nom ("Marignan ", "La Bastille ", "Gergovie "...) enregistré dans un string de 15 cases (par exemple). Reprenons notre type T_Date :
type T_Date is
record
nom : string(1..15) := "Pas d'An 0 !!! ";
jour : T_Jour := (LUNDI,1) ;
mois : T_Mois := JANVIER;
annee : T_Annee := 0 ;
end record ;
Il contient désormais un tableau (le string). Les opérations suivantes sont alors possibles :
...
prise_bastille : T_Date ;
BEGIN
prise_bastille.nom := "La Mastique " ;
prise_bastille.nom(4) := 'B' ;
prise_bastille.nom(9..10) := "ll" ;
Type dans un tableau (Euh... Van Gogh ? :-° )
Plus compliqué, on veut créer un tableau avec des dates à retenir (10 dates par exemple). Une fois notre type T_Date déclaré, déclarons notre type T_Chronologie et une variable T :
type T_Chronologie is array(1..10) of T_Date ;
T : T_Chronologie ;
Cette fois c'est T qui est notre tableau et T(1), T(2) ... sont des dates. Allons-y pour quelques affectations :
Le polymorphisme est la propriété d'avoir plusieurs formes, plusieurs apparences. En informatique, c'est l'idée de permettre à un type donné, d'avoir plusieurs apparences distinctes. Nos types T_Date et T_Temps ne conviennent plus à cette partie, prenons un nouvel exemple : un type T_Bulletin qui contient les moyennes d'un élèves dans différentes matières. Selon que notre élève est en primaire, au collège ou au lycée, il n'aura pas les mêmes matières (nous n'entrerons pas dans le détail des filières et des options par classe, l'exemple doit rester compréhensible, quitte à être caricatural). Considérons les données suivantes :
Un élève de primaire a du Français, des Maths et du Sport.
Un élève de collège a du Français, des Maths, du Sport, une langue étrangère (LV1) et de la Biologie.
Un élève de lycée a du Français, des Maths, du Sport, une langue étrangère (LV1), de la Biologie, de la chimie et une deuxième langue étrangère (LV2).
Notre type T_Bulletin n'a pas besoin d'avoir une composante chimie si notre élève est en primaire ; il doit donc s'adapter à l'élève ou plutôt à sa classe ! Nous allons donc définir deux autres types : un type énumératif T_Classe et un type structuré T_Eleve.
type T_Classe is (PRIMAIRE, COLLEGE, LYCEE) ;
type T_Eleve is
record
nom : string(1..20) ; --20 caractères devraient suffire
prenom : string(1..20) ; --on complètera au besoin par des espaces
classe : T_Classe ; --Tout l'intérêt d'écrire un T devant le nom de notre type ! ! !
end record ;
Créer un type polymorphe T_Bulletin
Maintenant, nous allons pouvoir créer notre type T_Bulletin, mais comme nous l'avons dit, sa structure dépend de l'élève et surtout de sa classe. Il faut donc paramétré notre type T_Classe !
Paramétrer un type ? C'est possible ?
Bien sûr, souvenez vous des tableaux ! Le type array est générique, il peut marcher avec des integer, des float ... Pour notre type T_Bulletin, cela devrait donner ceci :
type T_Bulletin(classe : T_Classe) is
record
--PARTIE FIXE
francais, math, sport : float ; --ou float range 0.0..20.0 ;
--PARTIE VARIABLE : COLLEGE ET LYCEE
case classe is
when PRIMAIRE =>
null ;
when COLLEGE | LYCEE =>
lv1, bio : float ;
--PARTIE SPECIFIQUE AU LYCEE
case classe is
when LYCEE =>
chimie, lv2 : float ;
when others =>
null ;
end case ;
end case ;
end record ;
Ce paramétrage nous permet ainsi d'éviter d'avoir à définir plusieurs types T_Bulletin_Primaire, T_Bulletin_College, T_Bulletin_Lycee. Il suffit de fournir en paramètre la classe en question. Attention toutefois ! Le paramètre fournit doit être discret.
Parce qu'un paramètre peut-être bruyant ? o_O
Non, discret n'est pas ici le contraire de bruyant ! C'est une notion mathématique qui signifie que les valeurs sont toutes "isolées les unes des autres" ou, d'une autre façon, si je prends deux valeurs au hasard, il n'y a qu'un nombre fini de valeurs comprises entre les deux que j'ai prises. Exemple : les integer sont de type discret (entre 2 et 5, il n'y a que 3 et 4, soit 2 nombres) ; les nombres réels (et le type float) ne sont pas discrets (entre 2.0 et 5.0, il y a une infinité de nombres comme 3.0 ou 3.01 ou 3.001 ou 3.00000000002 ou 4.124578521 ...). De même, nos types énumérés sont discrets, mais les types structurés ne sont pas acceptés comme discrets !
Autre souci : c'était pas plus simple d'utiliser if/elsif plutôt que des case imbriqués ?
Vous vous doutez bien que non ! Les conditions sont strictes lorsque l'on construit un type polymorphe. Pas de if, ne pas faire de répétition dans l'instruction when (ne pas répéter la composante lv1 par exemple), un seul case et c'est fini (d'où l'obligation de les imbriquer plutôt que d'en écrire deux distincts)... c'est qu'on ne ferait plus ce que l'on veut ! :p
Des objets polymorphes
Maintenant que nous avons déclarer nos types, il faut déclarer nos objets :
Il faut fournir un paramètre quand on définit Bltn_Kevin et Bltn_Laura, sans quoi le compilateur échouera et vous demandera de préciser votre pensée.
Par conséquent, lorsque vous déclarez les objets Kevin et Laura, vous devez les avoir initialisés (ou tout du moins avoir initialisé Kevin.classe et Laura.classe).
Nous avons ainsi obtenu deux objets Bltn_Kevin et Bltn_Laura qui n'ont pas la même structure. Bltn_Kevin a comme composantes :
Bltn_Kevin.classe : accessible seulement en lecture, pour des tests par exemple.
Bltn_Kevin.Math, Bltn_Kevin.Francais et Bltn_Kevin.sport : accessibles en lecture et en écriture.
Quant à lui, l'objet Bltn_Laura a davantage de composantes :
Bltn_Laura.classe : en lecture seulement
Bltn_Laura.Math, Bltn_Laura.francais, Bltn_Laura.sport : en lecture et écriture (comme Bltn_Kevin)
Bltn_Laura.lv1, Bltn_Laura.lv2, Bltn_Laura.bio, Bltn_Laura.chimie : en lecture et écriture.
Il est ensuite possible de créer des sous-types (pour éviter des erreurs par exemple) :
type T_Bulletin_Primaire is T_Bulletin(PRIMAIRE) ;
type T_Bulletin_College is T_Bulletin(COLLEGE) ;
type T_Bulletin_Lycee is T_Bulletin(LYCEE) ;
Les types structurés mutants
Comment peut-on muter ?
Je vous arrête tout de suite : il ne s'agit pas de monstres ou de types avec des pouvoirs spéciaux ! Non, un type mutant est simplement un type structuré qui peut muter, c'est-à-dire changer. Je vais pour cela reprendre mon type T_Bulletin. Attention ça va aller très vite :
type T_Bulletin(classe : T_Classe := PRIMAIRE) is
record
--PARTIE FIXE
francais, math, sport : float ; --ou float range 0.0..20.0 ;
--PARTIE VARIABLE : COLLEGE ET LYCEE
case classe is
when PRIMAIRE =>
null ;
when COLLEGE | LYCEE =>
lv1, bio : float ;
--PARTIE SPECIFIQUE AU LYCEE
case classe is
when LYCEE =>
chimie, lv2 : float ;
when others =>
null ;
end case ;
end case ;
end record ;
Euh ... t'aurais pas oublier de faire une modification après ton copier-coller ?
Non, regardez bien mon paramètre classe tout en haut : il a désormais une valeur par défaut : PRIMAIRE ! Vous allez me dire que ça ne change pas grand chose, et pourtant si ! Ainsi vous allez pouvoir écrire :
Eric : T_Eleve ; -- non prédéfini
Bltn_Eric : T_Bulletin ; -- pas la peine d'indiquer un paramètre, il est déjà prédéfini
Et désormais, Bltn_Eric est un type mutant, il va pouvoir changer de structure en cours d'algorithme ! Nous pourrons ainsi écrire :
...
Eric : T_Eleve ;
Bltn_Eric : T_Bulletin ;
BEGIN
Bltn_Eric := (COLLEGE,12.5,13.0,9.5,15.0,8.0) ;
Bltn_Eric := Bltn_Kevin ; --On suppose bien-sûr que Bltn_Kevin est déjà "prérempli"
...
Toujours plus loin !
Pour aller plus loin il serait judicieux de "fusionner" les types T_Eleve et T_Bulletin de la manière suivante :
type T_Bulletin(classe : T_Classe := PRIMAIRE) is --!!! POUR L'INSTANT, PAS DE CHANGEMENTS !!!
record
--PARTIE FIXE
francais, math, sport : float ; --ou float range 0.0..20.0 ;
--PARTIE VARIABLE : COLLEGE ET LYCEE
case classe is
when PRIMAIRE =>
null ;
when COLLEGE | LYCEE =>
lv1, bio : float ;
--PARTIE SPECIFIQUE AU LYCEE
case classe is
when LYCEE =>
chimie, lv2 : float ;
when others =>
null ;
end case ;
end case ;
end record ;
type T_Eleve is --!!! LA MODIFICATION SE FAIT ICI !!!
record
nom : string(1..20) ;
prenom : string(1..20) ;
bulletin : T_Bulletin ;
end record ;
Inutile de garder deux types : le type T_Bulletin sera intégré au type T_Eleve. En revanche il faudra que le type T_Eleve soit déclaré après le type T_Bulletin. Si cela se révélait impossible, vous pouvez toujours éviter ce problème en écrivant le prototype de T_Eleve, puis en décrivant T_Bulletin et enfin T_Eleve :
type T_Eleve ; -- !!! AJOUTE D'UN PROTOTYPE !!! Le reste ne change pas
type T_Bulletin(classe : T_Classe := PRIMAIRE) is
record
--PARTIE FIXE
francais, math, sport : float ; --ou float range 0.0..20.0 ;
--PARTIE VARIABLE : COLLEGE ET LYCEE
case classe is
when PRIMAIRE =>
null ;
when COLLEGE | LYCEE =>
lv1, bio : float ;
--PARTIE SPECIFIQUE AU LYCEE
case classe is
when LYCEE =>
chimie, lv2 : float ;
when others =>
null ;
end case ;
end case ;
end record ;
type T_Eleve is
record
nom : string(1..20) ;
prenom : string(1..20) ;
bulletin : T_Bulletin ;
end record ;
Plus besoin non plus de garder une composante classe dans le type T_Eleve puisqu'elle existe dans la composante bulletin !
Mais pourquoi ne pas avoir fait ça tout de suite ?
Pour plusieurs raisons : tout d'abord, avec un type polymorphe, la déclaration de la composante bulletin du type T_Eleve eût été inutilement compliquée et mon but n'est pas de vous embrouiller. Deuxième raison, j'ai changé mon fusil d'épaule en cours de rédaction du tutoriel :p : quel manque d'anticipation, c'est consternant. Sauf que cela me conduit à ma troisième raison : plutôt que de tout modifier, j'ai pensé qu'il était préférable de vous faire suivre un cheminement de pensée. Il est rare que l'on ait tout de suite la bonne idée, programmer exige une réflexion préalable sur les types qu'il faut définir, les fonctions ou procédures nécessaires etc ... or en cours de développement, des détails techniques peuvent parfois (et doivent) vous amener à revoir vos plans. Programmer, c'est anticiper, mais aussi s'adapter (aux contraintes techniques, aux choix du client ...)
Vous voilà désormais armés pour créer vos propres types (énumérés, sous-types, structurés [non paramétré, polymorphe ou mutant]). Combiné à l'usage des tableaux, voilà qui élargit vraiment nos horizons et nos possibilités. Combiné avec les packages, cela nous permet de créer l'équivalent des classes des langages C++, Java ...
Si nous développions notre type T_Eleve et les fonctionnalités qui s'y rapportent, nous pourrions créer un package volumineux et complet permettant d'établir une sorte de base de données des élèves d'un établissement : création et modification de "fichiers élèves" ou d'un seul grand fichier binaire enregistrant les différents objets de type T_Eleve possibles, enregistrement du numéro de téléphone, de l'adresse, des notes par matière (dans des tableaux inclus dans le type T_Eleve), création de fonctions calculant les moyennes, moyennes pondérées (avec coefficient), note minimale, note maximale ... la seule limite est votre imagination et votre temps libre :lol:
D'ailleurs, nous allons réaliser ce genre de programme dans le prochain chapitre : il s'agira de créer un logiciel gérant, non pas des élèves, mais votre collection de CD, DVD ... Comme vous l'avez deviné, notre prochain chapitre ne sera pas théorique, ce sera un TP ! Alors, si certains points vous posent encore problème, n'hésitez pas à les revoir.
Bienvenue dans le premier TP de la partie III, c'est-à-dire le second TP de ce cours. Comme je vous le disais dans le précédent chapitre, nous allons cette fois créer un logiciel pour gérer votre collection de CD, DVD, VHS, BluRay ... Plus précisément, notre programme permettra d'enregistrer un film, un album de musique, un jeu vidéo ou un autre type de donnée, mais aussi de consulter a posteriori la liste des œuvres. Je vous propose d'appeler notre programme Maktaba, ce qui signifie "Bibliothèque" en Swahili (pourquoi pas ? On a bien Ubuntu, Amarok ...).
Cela nous permettra de réutiliser les types de données structurés (pour enregistrer un film, il faut indiquer son titre, le type de support, son genre ...), les types énumérés (les supports CD, DVD, ...), les fichiers binaires ou texte (pour enregistrer notre liste d'œuvres ou exporter des informations sur une œuvre), les strings (pour enregistrer les titres des morceaux de musique par exemple) ou encore les packages (notre programme devrait être assez conséquent).
Cette fois encore, je commencerai ce TP par vous fournir un cahier des charges : que veut-on comme fonctionnalités ? comme données ? quelle structure pour nos fichiers et notre code source ? Puis je vous guiderai dans la conception du programme : nous ne réaliserons pas tout en seule fois, je commencerai par vous demander de réaliser un programme simple (simpliste ?) avant d'ajouter des fonctionnalités supplémentaires ou de prendre en charge des cas particuliers. Enfin, je vous transmettrai les sources et les prototypes d'une solution possible (bien entendu il n'y a pas qu'une seule solution mais bien plusieurs, chacune ayant ses avantages et inconvénients). En conclusion, comme pour le premier TP, je vous soumettrai quelques idées d'améliorations possibles de notre programme.
Prêt à démarrer ce nouveau challenge ? Alors au travail ! :soleil:
Pour établir les types dont nous pourrions avoir besoin, nous devons lister les données nécessaires à notre programme pour l'enregistrement ou la lecture.
Le contenu d'une œuvre
Nous souhaitons enregistrer des œuvres, mais qu'est-ce qu'une œuvre ? C'est avant tout :
un titre : "autant en emporte le vent", "mario bros 3", "Nevermind" ...
une catégorie : FILM, JEU (VIDEO), ALBUM (DE MUSIQUE), AUTRE ...
un support : CD, DVD, BLURAY, VHS, HDDVD ...
une note : de zéro à trois étoiles
Ensuite, selon la catégorie de l'œuvre, d'autres informations peuvent être nécessaires. Pour un film, nous aurons besoin :
du nom du réalisateur.
de savoir si le film est en VF
Pour un jeu vidéo nous aurons besoin :
de la console : Nes, PS1, PC, Nintendo64 ...
de savoir si vous avez terminé le jeu.
Pour un album de musique, nous aurons besoin :
du nom de l'artiste : "Nirvana", "ACDC", "Bob Marley" ...
D'une liste des morceaux dans l'ordre : "Come as you are", "Something in the way"
Il serait bon également qu'un type d'oeuvre par défaut existe : appréciation 0, ayant pour titre "" ...
Des types en cascade
Suite à cela, vous avez du comprendre que nous aurons besoin d'un type T_oeuvre qui soit structuré et polymorphe (voire même mutable, ce serait encore mieux et je vous le conseille fortement). Ce type structuré devrait comprendre de nombreuses composantes de types aussi divers que du texte (string mais pas d'unbounded_string, je vous expliquerai plus tard pourquoi), des tableaux, des booléens, des types énumérés (pour les supports ou la catégorie) ...
Rien que ça ? T'avais pas plus long ? :(
Tout cela laisse supposer que nous devrions créer un package spécifique pour déclarer notre type T_Oeuvre afin de libérer notre code source principal. Enfin, dernière information, nos textes devant être enregistrés dans des fichiers, nous ne pourrons pas utiliser les unbounded_string, mais seulement les string. L'explication technique vous sera révélée à la fin de la partie III, lors du chapitre sur les listes. Mais cela implique donc que vos strings devront être suffisamment longs pour pouvoir accueillir des titres à rallonge comme "Frances Farmer will have her revenge on Seattle" (titre de Nirvana, un peu long non ?).
Les types de fichiers
Qui dit enregistrement dit nécessairement fichiers. Aux vues de notre type structuré T_Oeuvre, cela signifie que nous aurions besoin d'un fichier binaire pour jouer le rôle de base de donnée (séquentiel ou à accès direct, c'est à vous de voir, pour ma part j'ai choisi les fichiers séquentiels dont la manipulation sera plus simple pour vous). Il serait même bon de séparer les bases de données (une pour les jeux, une pour la musique... ). Ces fichiers porteront par conséquent les noms de "ListeJeu.bdd", "ListeAlbum.bdd", "ListeFilm.bdd" et "ListeAutre.bdd" (bdd = Base De Données).
Quelle architecture pour les fichiers
Notre programme ayant besoin de divers types de fichiers, il serait judicieux de ne pas tout mélanger.
Maktaba.exe devra se trouver dans un répertoire Maktaba, libre à vous de placer un raccourci sur le bureau si vous le souhaitez.
Les bases de données ListeJeu.bdd et autres devront se trouver dans un sous-répertoire "data".
Un sous-répertoire "Manual" permettra l'enregistrement d'un fichier texte.
Cela nous fait donc un répertoire principal et deux sous-répertoires.
Quelles fonctionnalités pour quelles fonctions et procédures ?
Maktaba.exe devra proposer les fonctionnalités suivantes :
Saisie d'une nouvelle œuvre par l'utilisateur.
Enregistrement d'une nouvelle œuvre par l'utilisateur (ajout dans la base de donnée).
Modification par l'utilisateur d'une œuvre existante.
Suppression par l'utilisateur d'une œuvre existante.
Affichage de la base de donnée ou d'une oeuvre dans la console (sous la forme d'un tableau).
Accès aux fonctionnalités par lignes de commande : l'utilisateur devra taper add, modify, delete, print pour accéder à une fonctionnalité. Le programme gèrera bien-sûr d'éventuelles erreurs de frappe commises par l'utilisateur.
Possibilité d'accéder à un manuel en console par la commande manual. Ce manuel sera rédigé dans un fichier texte "manual.txt" placé dans le sous-répertoire "manual" évoqué précédemment et décrira les différentes commandes possibles.
Architecture du code source
Argh ! ! ! :waw: Mais jamais je ne parviendrai à faire tout ça ! Je savais bien que je n'aurais pas du me lancer dans cette galère ! :'(
Gardez espoir ! Ce ne sera pas aussi compliqué que cela peut paraître. En revanche, cela risque d'être long (notamment le codage des procédures de saisie et d'affichage), donc il sera nécessaire d'y aller étape par étape et d'adopter une approche par modules (tiens, ça devrait vous rappeler les packages ça). Nous aurons donc à créer les fichiers Ada suivants :
Maktaba.adb : la procédure principale qui ne se chargera que de l'interface utilisateur, du cœur du logiciel.
Maktaba_Types.ads : pour déclarer nos types et nos constantes.
Maktaba_Functions.adb et Maktaba_Functions.ads : pour les différentes fonctionnalités liées à la base de données (lecture, saisie, enregistrement, affichage).
Cette partie n'est pas obligatoire, elle permettra toutefois à ceux qui hésitent à se lancer ou qui ne voient pas comment faire, de trouver une méthode ou des voies pour programmer. Attention, il ne s'agit pas d'une solution toute faite (celle-ci sera fournie à la fin) mais plutôt d'un guide et je vous invite à essayer de réaliser ce TP par vous même, en recourant le moins possible à cette partie.
Création des types
Nous allons commencer par créer deux fichiers : Maktaba.adb et Maktaba_Types.ads. Notre fichier Maktaba.adb ne contiendra pour l'instant pas grand chose :
WITH Maktaba_Types ; USE Maktaba_Types ;
WITH Ada.Text_IO ; USE Ada.Text_IO ;
PROCEDURE Maktaba IS
Oeuvre : T_Oeuvre ;
BEGIN
END Maktaba ;
Comme vous pouvez le constater il n'y a quasiment rien. Nous allons nous concentrer sur le fichier Maktaba_Types.ads et les différents types : nous devons créer un type structuré et polymorphe (et même mutable) T_Oeuvre. Ce type devra contenir différentes composantes :
titre de l’œuvre, realisateur, console et artiste seront des strings (avec les contraintes que cela implique en terme de taille), mais surtout pas des unbounded_string (cela poserait problème pour l'enregistrement). Il serait bon que les strings soient initialisés.
Categorie et support seront des types énumérés.
VF et Termine seront des boolean (vrai ou faux).
Note sera un sous-type natural de 0 à 3 ou Integer (voire modulaire).
Morceaux sera un tableau de 30 strings (ou plus).
A vous donc de créer ce type T_Oeuvre ainsi que les types énumérés T_Categorie et T_Support et le sous-type T_Note. Pensez toutefois que, pour être polymorphe, T_Oeuvre doit dépendre de la catégorie de l'oeuvre et que pour être mutable, cette catégorie doit être initialisée :
type T_Oeuvre(categorie : T_Categorie := #Une_Valeur#)is
record
...
case categorie is
when FILM => ...
...
end case ;
end record ;
Affichage d'une œuvre
Il est temps de créer nos fichiers Maktaba_Functions.adb et Maktaba_Functions.ads ! Nous aurons besoin à l'avenir d'afficher l'intégralité de notre base de données, mais avant d'afficher 300 œuvres, nous devrions créer une fonction ou procédure qui en affiche une et une seule. Cela nous permettra d'avoir dors et déjà un programme Maktaba.exe opérationnel qui saisirait une œuvre (arbitrairement pour l'instant) puis l'afficherait.
procedure Affichage(oeuvre : T_Oeuvre) ;
Pensez à faire un affichage compact et clair : il y aura à terme des dizaines d'oeuvres ! Pensez également à terminer l'affichage par un ou plusieurs new_line pour éviter les soucis d'affichage plus tard.
Saisie d'une oeuvre
La première chose à faire par la suite sera de créer une procédure ou une fonction de saisie d'une œuvre. Le sous-programme de saisie ne sera pas compliqué à mettre en oeuvre mais sera long à rédiger car il devra prévoir toutes les composantes. Mais avant de vous lancer dans la saisie d'une œuvre, je vous conseille d'implémenter une fonction de saisie de string. Il existe bien get_line ou get, mais si vous souhaitez saisir un string de taille 20, il ne faut pas que l'utilisateur saisisse un texte de 35 ou 3 caractères. Or l'utilisateur final n'aura généralement aucune connaissance de ces contraintes, donc je conseille de commencer par là :
function get_text(taille : natural) return string ;
Autre indication pour simplifier votre code, il serait bon que votre fonction de saisie d’œuvre (appelons-la Saisie_Oeuvre) ne s’occupe pas de la saisie de la catégorie. Ce travail sera effectué par une fonction tierce (Saisie_Categorie) qui fournira à la première la catégorie à saisir. Cela simplifiera grandement votre travail et votre réflexion. De manière générale, une grande partie de vos fonctions et procédures devraient avoir la catégorie de l'œuvre en paramètre.
Function Saisie_Categorie return T_Categorie ;
Function Saisie_Oeuvre(Cat : T_Categorie) return T_Oeuvre ;
Les saisies de strings se feront avec notre fonction get_text. En revanche, les saisies d'entiers devront gérer les cas où l'utilisateur entrerait une note supérieure à 3 :
TANT QUE choix>3
| Saisir(choix)
FIN DE BOUCLE
De même, pour saisir un booléen ou un type structuré, vous pourrez proposer à l'utilisateur un choix similaire à celui-ci :
Votre film est enregistré sur :
1. un CD
2. un DVD
3. une VHS
Votre film est-il en VF ? (O : oui / N : Non) _
Donc prévoyez les cas où l'utilisateur répondrait de travers pour limiter les plantages.
Gestion des fichiers
La plupart des opérations suivantes se feront uniquement sur les fichiers : sauvegarde dans la base de données (bdd), affichage d'une bdd, modification d'un élément d'une bdd, suppression d'un élément d'une bdd ... Nous devrons créer un package pour manipuler des fichiers binaires. Comme dit précédemment, je vous invite à utiliser les fichiers séquentiels plutôt qu'à accès direct pour éviter de rajouter de la difficulté à la difficulté (bien sûr vous êtes libres de votre choix, le type de fichier binaire ne fait pas partie du cahier des charges).
Sauvegarde et affichage avec la BDD
L'implémentation de ces deux fonctionnalités ne devrait pas poser de problème. Il vous suffira d'ouvrir un fichier, de le fermer, en pensant entre temps à soit ajouter un élément (Append_File), soit parcourir le fichier pour le lire (In_file).
Mais si vous avez essayé d'implémenter ces fonctionnalités, vous avez du vous rendre compte qu'elles exigent toutes les deux de commencer par traiter une question toute bête : "Quel fichier dois-je ouvrir ? ". Et cette question, vous devrez vous la reposer à chaque fois. Donc il y a plusieurs façons de faire : soit on la joue gros bourrin et alors "Vive le copier-coller ! " :pirate: Soit on est un peu plus futé et on rédige une procédure qui se charge d'ouvrir le bon fichier selon la catégorie fournie en paramètre (paramètre pouvant être lui-même fourni par la fonction Saisie_categorie évoquée précédemment) :
Modification et suppression d'un élément de la BDD
Le plus simple pour effectuer cette opération est de ne manipuler que des fichiers : pas la peine de se casser la tête à tenter de supprimer un élément du fichier. Voici une méthode pour supprimer l'élément numéro N d'un fichier F :
Ouvrir le fichier F (Nom : truc)
Ouvrir le fichier G (Nom : truc2)
Copier les (N-1) premiers éléments de F dans G
sauter le N-ème élément de F
Copier le reste des éléments de F dans G
Supprimer F
Recreer F (Nom : Truc) comme une copie de G
Fermer F
Fermer G
Un raisonnement similaire peut être effectué pour la modification de la BDD.
Affichage du manuel
Là j'espère bien que vous n'avez pas besoin de moi ! :colere:
Les commandes
Jusque là, notre fichier Maktaba.adb ne contient rien de bien sérieux, il ne nous sert qu'à tester nos procédures et fonctions. Mais puisque nous avons fini, nous allons pouvoir le rédiger correctement. L'idée ici est simple : si l'utilisateur tape un mot particulier, le programme réalise une opération particulière. Nous allons donc réutiliser notre fonction get_text pour la saisie des commandes. Le corps de la procédure principale sera simple : une boucle infinie qui se contente de demander de saisir du texte et qui, si le texte correspond à une commande connue, lance quelques sous-programmes déjà rédigés. L'un de ces strings entraînera bien entendu la sortie de la boucle (commande : quit ou exit par exemple). En cas d'erreur de l'utilisateur, le programme affichera toutefois une phrase du genre "Si vous ne comprenez rien, vous n'avez qu'à taper Manual pour lire ce #*§%$€ de Manuel (RTFM)" (en plus aimable bien sûr :-° ) de façon à ne pas laisser l'utilisateur sans indications.
Comme promis, voici une solution possible à comparer avec votre travail.
Maktaba.adb :
------------------------------------------------------------------------------
-- --
-- PROJET MAKTABA --
-- --
-- MAKTABA.ADS --
-- --
-- --
-- AUTEUR : KAJI9 --
-- DATE : 13/11/2011 --
-- --
-- Contient la procédure principale du logiciel MAKTBA ainsi que les --
-- procédures d'affichage et de saisie. --
-- --
------------------------------------------------------------------------------
--Retrouvez le tuto à l'adresse suivante http://www.siteduzero.com/tutoriel-3-558031-1-second-tp-un-logiciel-de-gestion-de-bibliotheque.html
with Maktaba_Types ; use Maktaba_Types ;
with Maktaba_Functions ; use Maktaba_Functions ;
with Ada.Characters.Handling ; use Ada.Characters.Handling ;
with Ada.Text_IO ; use Ada.Text_IO ;
procedure Maktaba is
oeuvre : T_Oeuvre ;
reponse : string(1..6) ;
begin
loop
Put("> ") ; reponse := Get_Text(6) ;
reponse := To_Upper(Reponse) ;
if reponse = "QUIT " or reponse = "EXIT "
then exit ;
elsif reponse = "NEW "
then oeuvre := saisie(get_categorie) ;
sauvegarde(oeuvre) ;
elsif reponse = "MANUAL"
then Affichage_Manuel ;
elsif reponse = "INIT " or reponse = "ERASE "
then creation(get_categorie) ;
elsif reponse = "PRINT "
then affichage_bdd(get_categorie) ;
elsif reponse = "EDIT "
then Edit_bdd(get_categorie) ;
else put_line("Commande inconnue. Pour plus d'informations, tapez l'instruction MANUAL. ") ;
end if ;
end loop ;
end Maktaba ;
Maktaba_Types.ads :
------------------------------------------------------------------------------
-- --
-- PROJET MAKTABA --
-- --
-- MAKTABA_TYPES.ADS --
-- --
-- --
-- AUTEUR : KAJI9 --
-- DATE : 13/11/2011 --
-- --
-- Contient les différents types nécessaires au fonctionnement du logiciel --
-- MAKTABA. --
-- --
------------------------------------------------------------------------------
--Retrouvez le tuto à l'adresse suivante http://www.siteduzero.com/tutoriel-3-558031-1-second-tp-un-logiciel-de-gestion-de-bibliotheque.html
package Maktaba_Types is
type T_Categorie is (FILM,JEU,ALBUM,AUTRE) ;
type T_Support is (CD, DVD, BLURAY, VHS, HDDVD) ;
type T_Morceaux is array(1..30) of string(1..50) ;
type T_Oeuvre(categorie : T_Categorie := AUTRE) is
record
titre : string(1..50) := (others => ' ') ;
support : T_Support := CD ;
note : natural range 0..3 ;
case categorie is
when FILM => realisateur : string(1..20) := (others => ' ') ;
VF : boolean := false ;
when JEU => console : string(1..20) := (others => ' ') ;
termine : boolean := false ;
when ALBUM => artiste : string(1..20) := (others => ' ') ;
morceaux : T_Morceaux := (others =>(others => ' ')) ;
when AUTRE => null ;
end case ;
end record ;
type T_Film is new T_Oeuvre(FILM) ;
type T_Jeu is new T_Oeuvre(JEU) ;
type T_Album is new T_Oeuvre(ALBUM) ;
type T_Autre is new T_Oeuvre(AUTRE) ;
end ;
Maktaba_Functions.ads :
------------------------------------------------------------------------------
-- --
-- PROJET MAKTABA --
-- --
-- MAKTABA_FUNCTIONS.ADS --
-- --
-- --
-- AUTEUR : KAJI9 --
-- DATE : 13/11/2011 --
-- --
-- Contient les fonctions de saisie, d'affichage, de sauvegarde ... du --
-- logiciel MAKTABA. --
-- --
------------------------------------------------------------------------------
--Retrouvez le tuto à l'adresse suivante http://www.siteduzero.com/tutoriel-3-558031-1-second-tp-un-logiciel-de-gestion-de-bibliotheque.html
with Maktaba_Types ; use Maktaba_Types ;
WITH Ada.Sequential_IO ;
package Maktaba_Functions is
Package P_Fichier is new Ada.Sequential_IO(T_Oeuvre) ;
use P_Fichier ;
subtype T_Fichier is P_Fichier.File_type ;
procedure sauvegarde(Oeuvre : in T_Oeuvre) ;
procedure sauvegarde(oeuvre : in T_Oeuvre ; rang : natural) ;
procedure creation(cat : T_categorie) ;
procedure Ouvrir(F: in out T_Fichier ; mode : P_Fichier.File_Mode := P_Fichier.In_file ; cat : T_Categorie);
procedure supprimer(cat : T_Categorie ; rang : natural) ;
-- SAISIES
function get_text(size : integer) return string ;
function get_categorie return T_Categorie ;
function saisie(cat : T_Categorie) return T_Oeuvre ;
-- MANIPULATION DE LA BDD
procedure affichage_oeuvre(Oeuvre : in T_Oeuvre) ;
procedure affichage_bdd(cat : T_categorie) ;
procedure Edit_bdd(cat : T_Categorie) ;
-- Manuel
procedure affichage_manuel ;
end Maktaba_Functions ;
Maktaba_Functions.adb :
------------------------------------------------------------------------------
-- --
-- PROJET MAKTABA --
-- --
-- MAKTABA_FUNCTIONS.ADB --
-- --
-- --
-- AUTEUR : KAJI9 --
-- DATE : 13/11/2011 --
-- --
-- Contient les fonctions de saisie, d'affichage, de sauvegarde ... du --
-- logiciel MAKTABA. --
-- --
------------------------------------------------------------------------------
--Retrouvez le tuto à l'adresse suivante http://www.siteduzero.com/tutoriel-3-558031-1-second-tp-un-logiciel-de-gestion-de-bibliotheque.html
with Ada.Text_IO ; use Ada.Text_IO ;
with Ada.Integer_Text_IO ; use Ada.Integer_Text_IO ;
with Ada.Characters.Handling ; use Ada.Characters.Handling ;
with ada.Strings.Unbounded; Use ada.Strings.Unbounded ;
package body Maktaba_Functions is
-----------------------------------------------
-- GESTION DES FICHIERS --
-----------------------------------------------
procedure sauvegarde(Oeuvre : in T_Oeuvre) is
F : T_Fichier ;
begin
ouvrir(F,Append_File,oeuvre.categorie) ;
write(F,Oeuvre) ;
close(F) ;
end sauvegarde ;
procedure sauvegarde(oeuvre : in T_Oeuvre ; rang : natural) is
F,G : T_Fichier ;
tmp : T_Oeuvre ;
begin
-- Ouverture de F en In et de G en Append
ouvrir(F,In_File,oeuvre.categorie) ;
create(G,Append_File,Name(F) & "2") ;
-- copie de F+oeuvre dans G
for i in 1..rang-1 loop
read(F,tmp) ;
write(G,tmp) ;
end loop ;
write(G,oeuvre) ;
read(F,tmp) ; --lecture de l'élément à supprimer
while not end_of_file(F) loop
read(F,tmp) ;
write(G,tmp) ;
end loop ;
-- Suppression de F / recréation de F
-- fermeture de G / réouverture de G
delete(F) ;
creation(oeuvre.categorie) ;
ouvrir(F,Append_File,oeuvre.categorie) ;
close(G) ;
open(G,In_File,Name(F) & "2") ;
-- copie de G dans F
while not end_of_file(G) loop
read(G,tmp) ;
write(F,tmp) ;
end loop ;
--Fermeture de F / Suppression de G
close(F) ;
delete(G) ;
end sauvegarde ;
procedure Creation(cat : T_categorie) is
F : T_Fichier ;
begin
case cat is
when FILM => create(F,out_file,"./data/ListeFilm.bdd") ;
close(F) ;
when JEU => create(F,out_file,"./data/ListeJeu.bdd") ;
close(F) ;
when ALBUM => create(F,out_file,"./data/ListeAlbum.bdd") ;
close(F) ;
when AUTRE => create(F,out_file,"./data/ListeAutre.bdd") ;
close(F) ;
end case ;
end creation ;
procedure Ouvrir(F: in out T_Fichier ;
mode : P_Fichier.File_Mode := P_Fichier.In_file ;
cat : T_Categorie) is
begin
case cat is
when FILM => open(F,mode,"./data/ListeFilm.bdd") ;
when JEU => open(F,mode,"./data/ListeJeu.bdd") ;
when ALBUM => open(F,mode,"./data/ListeAlbum.bdd") ;
when AUTRE => open(F,mode,"./data/ListeAutre.bdd") ;
end case ;
end Ouvrir;
procedure supprimer(cat : T_Categorie ; rang : natural) is
F,G : T_Fichier ;
tmp : T_Oeuvre ;
begin
-- Ouverture de F en In et de G en Append
ouvrir(F,In_File,cat) ;
create(G,Append_File,Name(F) & "2") ;
-- copie de F-1 oeuvre dans G
for i in 1..rang-1 loop
read(F,tmp) ;
write(G,tmp) ;
end loop ;
read(F,tmp) ;
while not end_of_file(F) loop
read(F,tmp) ;
write(G,tmp) ;
end loop ;
-- Suppression de F / recréation de F
-- fermeture de G / réouverture de G
delete(F) ;
creation(cat) ;
ouvrir(F,Append_File,cat) ;
close(G) ;
open(G,In_File,Name(F) & "2") ;
-- copie de G dans F
while not end_of_file(G) loop
read(G,tmp) ;
write(F,tmp) ;
end loop ;
--Fermeture de F / Suppression de G
close(F) ;
delete(G) ;
end supprimer ;
----------------------------------
-- SAISIE --
----------------------------------
function get_text(size : integer) return string is
U : Unbounded_String := Null_Unbounded_String ;
T : string(1..size) := (others => ' ') ;
begin
U := to_unbounded_string(get_line) ;
if length(U) > size
then T := to_string(U)(1..size) ;
else T(1..length(U)) := to_string(U) ;
for i in length(U)+1..size loop
T(i) := ' ' ;
end loop ;
end if ;
return T ;
end get_text ;
function get_categorie return T_Categorie is
choix_cat : character ;
begin
Put_line("Choisissez la categorie desiree : ") ;
Put_line("F-Film M-Album de Musique") ;
Put_line("J-Jeu Video Autre ?") ;
Get_Immediate(choix_cat) ; choix_cat := to_upper(choix_cat) ;
case choix_cat is
when 'F' => return FILM ;
when 'M' => return ALBUM ;
when 'J' => return JEU;
when others => return AUTRE ;
end case ;
end get_categorie ;
function saisie(cat : T_Categorie) return T_Oeuvre is
oeuvre : T_Oeuvre(cat) ;
choix : character ;
note : integer ;
begin
-- SAISIE DES PARAMETRES COMMUNS
Put_line("Quel est le titre de l'oeuvre ? ") ;
oeuvre.titre := get_text(50) ;
Put_line("Quelle note donneriez-vous ? (Entre 0 et 3) ") ;
loop
get(note) ; skip_line ;
if note in 0..3
then oeuvre.note := note ;
exit ;
else Put_line("ERREUR ! La note doit être comprise entre 0 et 3 !") ;
end if ;
end loop ;
Put_line("Sur quel type de support l'oeuvre est-elle enregistree ?") ;
Put_line("1-VHS 2-CD 3-DVD") ;
Put_Line("4-HDDVD 5-BLURAY") ;
loop
get_immediate(choix) ; choix := to_upper(choix) ;
case choix is
when '1' => oeuvre.support := VHS ; exit ;
when '2' => oeuvre.support := CD ; exit ;
when '3' => oeuvre.support := DVD ; exit ;
when '4' => oeuvre.support := HDDVD ; exit ;
when '5' => oeuvre.support := BLURAY ; exit ;
when others => Put_line("Veuillez reconfirmer votre choix.") ;
end case ;
end loop ;
-- SAISIE DES PARAMETRES SPECIFIQUES
case cat is
when FILM => Put_line("Quel est le realisateur ? ") ;
oeuvre.realisateur:= get_text(20) ;
Put_line("Le film est-il en VF ? (O : Oui / N : Non)") ;
loop
get_immediate(choix) ; choix := to_upper(choix) ;
if choix = 'O'
then oeuvre.vf := true ; exit ;
elsif choix = 'N'
then oeuvre.vf := false ; exit ;
else Put_line("Veuillez appuyer sur O pour Oui ou sur N pour Non") ;
end if ;
end loop ;
return oeuvre ;
when ALBUM => Put_line("Quel est l'artiste ? ") ;
oeuvre.artiste := get_text(20) ;
for i in oeuvre.morceaux'range loop
Put_line("Voulez-vous ajouter un morceau ? (O : Oui / N : Non)") ;
get_immediate(choix) ; choix := to_upper(choix) ;
if choix = 'O'
then Put_line("Quel est le titre du morceau ? ") ;
oeuvre.morceaux(i) := get_text(50) ;
else exit ;
end if ;
end loop ;
return oeuvre ;
when JEU => Put_line("Quelle est la console ? ") ;
oeuvre.console := get_text(20) ;
Put_line("Avez-vous fini le jeu ? (O : Oui / N : Non)") ;
loop
get_immediate(choix) ; choix := to_upper(choix) ;
if choix = 'O'
then oeuvre.termine := true ; exit ;
elsif choix = 'N'
then oeuvre.termine := false ; exit ;
else Put_line("Veuillez appuyer sur O pour Oui ou sur N pour Non") ;
end if ;
end loop ;
return oeuvre ;
when AUTRE => return oeuvre ;
end case ;
end Saisie ;
-----------------------------------------------
-- AFFICHAGE D'UNE BDD --
-----------------------------------------------
procedure affichage_oeuvre(oeuvre : T_oeuvre) is --Affiche une seule oeuvre
null_string : constant string(1..50) := (others => ' ') ;
begin
put(" >>>Titre : ") ; put(Oeuvre.titre) ; new_line ;
put(" >>>Support : ") ; put(T_Support'image(Oeuvre.support)) ; new_line ;
put(" >>>Note : ") ; put(Oeuvre.note,1) ; new_line ;
case oeuvre.categorie is
when FILM => put(" >>>Realisateur : ") ; put(Oeuvre.realisateur) ; new_line ;
put(" >>>VF : ") ;
if Oeuvre.vf
then put("oui") ;
else put("non") ;
end if ; new_line(2) ;
when JEU => put(" >>>Console : ") ; put(Oeuvre.console) ; new_line ;
put(" >>>Termine : ") ;
if Oeuvre.termine
then put("oui") ;
else put("non") ;
end if ; new_line(2) ;
when ALBUM => put(" >>>Artiste : ") ; put(Oeuvre.artiste) ; new_line ;
put_line(" >>>Morceaux : ") ;
for i in Oeuvre.morceaux'range loop
exit when Oeuvre.morceaux(i) = null_string ;
put(" ") ; put(i,2) ; put(" : ") ; Put(oeuvre.morceaux(I)); New_Line;
end loop ;
new_line(2) ;
when AUTRE => new_line ;
end case ;
end affichage_oeuvre ;
procedure affichage_bdd(cat : T_categorie) is --Affiche toute une base de données selon la catégorie demandée
n : natural := 1 ;
suite : character ;
Oeuvre : T_Oeuvre(cat) ;
F : T_Fichier ;
begin
ouvrir(F,In_File,cat) ;
while not end_of_file(F) loop
if n = 0
then put("Cliquez pour continuer") ;
get_immediate(suite) ; new_line ;
end if ;
read(F,Oeuvre) ;
Affichage_oeuvre(oeuvre) ;
n := (n + 1) mod 5 ;
end loop ;
close(F) ;
end Affichage_bdd ;
------------------------------------------------------
-- EDITION DE LA BASE DE DONNEES --
------------------------------------------------------
procedure Edit_bdd(cat : T_Categorie) is --Edite une base de données pour modification ou suppression
choix : character ;
n : natural := 1 ;
Oeuvre : T_Oeuvre(cat) ;
F : T_Fichier ;
begin
ouvrir(F,In_File,cat) ;
while not end_of_file(F) loop
read(F,Oeuvre) ;
Affichage_oeuvre(oeuvre) ;
put_line("Que voulez-vous faire : Supprimer(S), Modifier(M), Quitter(Q) ou Continuer ?") ;
Get_Immediate(choix) ; choix := to_upper(choix) ;
if choix = 'M'
then close(F) ;
oeuvre := saisie(cat) ;
sauvegarde(oeuvre,n) ;
exit ;
elsif choix = 'S'
then close(F) ;
Supprimer(cat,n) ;
exit ;
elsif choix = 'Q'
then close(F) ;
exit ;
end if ;
n := n + 1 ;
end loop ;
if Is_Open(F)
then close(F) ;
end if ;
end Edit_bdd ;
------------------------------------------------------
-- EDITION DE LA BASE DE DONNEES --
------------------------------------------------------
procedure affichage_manuel is
F : Ada.text_IO.File_Type ;
begin
open(F,In_File,"./manual/manual.txt") ;
while not end_of_file(F) loop
put_line(get_line(F)) ;
end loop ;
close(F) ;
end affichage_manuel ;
end Maktaba_Functions ;
Manual.txt :
Commandes :
Quitter : Quit / Exit
Nouveau : New
Manuel : Manual
Réinitialiser une base : Init / Erase
Afficher une base : Print
Modifier une base : Edit
Chose promise, chose due ! Voici quelques idées d'amélioration de notre programme :
Fournir une interface graphique plutôt que cette vilaine console. Pour l'instant, vous ne pouvez pas encore le faire, mais cela viendra.
Proposer de gérer d'autres types de supports : disque durs, clés USB ...
Proposer l'enregistrement de nouvelles informations : le genre de l’œuvre (film d'horreur ou d'aventure, album rock ou rap...), une description, les acteurs du film, les membres du groupe de musique, l'éditeur du jeu vidéo, la durée des morceaux ...
Proposer l'exportation de vos bases de données sous formes de fichiers textes consultables plus aisément ou l'importation d'une œuvre à partir d'un fichier texte.
Permettre de compléter les instructions en ligne de commande par des options : modify -f modifierait un film par exemple.
Implémenter un service de recherche d’œuvre par titre, par auteur ou même par mots-clés !
Encore une fois, ce ne sont pas les idées qui manquent pour développer un tel logiciel. J'espère toutefois que ce TP vous aura permis de faire un point sur les notions abordées depuis le début de la partie III car nous allons maintenant nous atteler à un type de données plus complexe : les pointeurs. Et, de la même manière que nous avons parlé, reparlé et rereparlé des tableaux, nous allons parler, reparler et rereparler des pointeurs dans les prochains chapitres.
Voici très certainement LE chapitre de la troisième partie du cours. Pourquoi ? Eh bien parce que c'est, à n'en pas douter LE plus dur de tous. Les pointeurs constituent une véritable épine dans le pied de tout jeune programmeur. Non pas qu'ils soient compliqués à manipuler, non bien au contraire ! Vous connaissez déjà les opérations qui leur sont applicables. Non. Le souci, c'est qu'ils sont difficiles à conceptualiser, à comprendre.
Comment ça marche ? Je pointe sur quoi en ce moment ? A quoi ça sert ? C'est un pointeur ou un objet pointé ? Je mets un pointeur ou pas ? Au secours ! :colere: Voilà résumé en quelques questions tout le désarroi qui vous submergera sûrement en manipulant les pointeurs. C'est en tous cas celui qui m'a submergé lorsque j'ai commencé à les utiliser et ce, jusqu'à obtenir le déclic. Et, rassurez-vous, je compte bien prendre le temps de vous expliquer pour que vous aussi vous ayez le déclic à votre tour.
Ce chapitre étant long et compliqué il a donc été divisé en deux. La première moitié (celle que vous lisez actuellement) se chargera de vous expliquer les bases : qu'est-ce qu'un pointeur ? Comment cela marche-t-il ? A quoi cela ressemble-t-il en Ada ? La seconde moitié aura pour but de couvrir toutes les possibilités offertes par le langage Ada en la matière. Aussi compliqués soient-ils (et même si le langage Ada fait moins appel à eux que d'autres comme le C/C++), les pointeurs nous seront très utiles par la suite notamment pour le chapitre 10. N'hésitez pas à relire ce double chapitre, si besoin est, pour vous assurer que vous avez assimilé toutes les notions.
Notre premier objectif sera donc de comprendre ce qu'est un pointeur. Et pour cela, il faut avant tout se rappeler ce qu'est une variable !
On va pas tout reprendre à zéro quand même ? o_O
Et si ! Ou presque. Reprenons calmement et posons-nous la question suivante : que se passe-t-il lorsque l'on écrit dans la partie déclarative la ligne ci-dessous et quoi cela sert-il ?
MaVariablePerso : integer ;
En écrivant cela, nous indiquons à l'ordinateur que nous aurons besoin d'un espace en mémoire suffisamment grand pour accueillir un nombre de type integer, c'est à dire compris entre - 2 147 483 648 et + 2 147 483 647. Mon ordinateur va devoir réquisitionner une zone mémoire pour ma variable MaVariablePerso. Et pour la retrouver, cette zone mémoire disposera d'un adresse, par exemple le n°6025. Ainsi, à cette adresse, je suis sûr de trouver MaVariablePerso et rien d'autre ! Il ne peut y avoir qu'une seule variable par adresse.
Ainsi, si par la suite je venais à écrire :
MaVariablePerso := 5 ;
Alors l'emplacement mémoire n°6025 qui était encore vide (ou qui contenait d'anciennes données sans aucun rapport avec notre programme actuel) va recevoir la valeur 5 qu'il conservera jusqu'à la fin du programme.
En revanche, nous ne pourrons pas écrire :
MaVariablePerso := 5.37 ;
Car 5.37 est un float, et un float n'est pas codé de la même manière par l'ordinateur qu'un integer ou un character. Donc l'ordinateur sait qu'à l'adresse n°6025, il ne pourra enregistrer que des données de type integer sous peine de plantage. L'avantage des langages dits de haut niveau (tels Ada), c'est qu'ils s'occupent de gérer la réquisition de mémoire, d'éviter en amont de mauvaises affectations et surtout, ces langages nous permettent de ne pas avoir à nous tracasser de l'adresse mémoire utilisée (le n°6025). Il nous suffit d'indiquer le nom de cet emplacement (MaVariablePerso) pour pouvoir y accéder en écriture ou/et en lecture.
Or il est parfois utile de passer non plus par le nom de cet emplacement, mais par son adresse, et c'est là qu'interviennent les pointeurs ! Au lieu de dire "je veux modifier/lire la variable qui s'appelle MaVariablePerso" nous devrons dire "je veux modifier/lire ce qui est écrit à l'adresse n°6025".
Pour comprendre ce qu'est un pointeur, mettons-nous dans la peau de l'inspecteur Derrick (la classe ! :soleil: Non ?). Il sait que le meurtrier qu'il recherche vit à l'adresse 15 rue Mozart, bâtiment C, 5ème étage appartement 34. Mais il ne connaît pas son nom. Que fait-il ? Soit il imprime quelque part dans son cerveau l'adresse du criminel (vue l'adresse, ça sera pas facile, mais ... c'est Derrick ! :soleil: ) soit il utilise un bon vieux post-it pour la noter (moins glamour mais plus sérieux vu son âge). Bon ensuite, il se rend à l'adresse indiquée, fait ce qu'il a à faire (interrogatoire, arrestation ...) termine l'enquête et youpi, il peut jeter son post-it car il a résolu une nouvelle enquête.
Et c'est quoi le pointeur dans cette histoire ? o_O
Eh bien mon pointeur c'est : le post-it ! Ou le coin du cerveau de Derrick qui a enregistré cette adresse si compliquée ! Traduit en langage informatique, cela signifie qu'une adresse mémoire est trop compliquée pour être retenue ou utilisée par l'utilisateur, mieux vaut l'enregistrer quelque part, et le plus sérieux, c'est d'enregistrer cette adresse dans une bonne vieille variable tout ce qu'il y a de plus classique (ou presque). Et c'est cette variable, contenant une adresse mémoire intéressante qui est notre pointeur.
Sur mon schéma, le pointeur est donc la case n°1025 ! Cette case contient l'adresse (le n°3073) d'un autre emplacement mémoire. Un pointeur n'est donc rien de plus qu'une variable au contenu inutilisable en tant que tel puisque ce contenu n'est rien d'autre que l'adresse mémoire d'informations plus importantes. Le pointeur n'est donc pas tant intéressant par ce qu'il contient que par ce qu'il pointe.
Le terme Ada pour pointeur est access ! Malheureusement, comme pour les tableaux, il n'est pas possible d'écrire :
Toujours pour éviter des problèmes de typage, il nous faut définir auparavant un type T_Pointeur indiquant sur quel type de données nous souhaitons pointer. Pour changer, choisissons que le type T_Pointeur pointera sur ... des integer ! Oui je sais, c'est toujours des integer. :) Nous allons donc déclarer notre type de la manière suivante :
type T_Pointeur is access Integer ;
Puis nous pourrons déclarer des variable Ptr1, Ptr2 et Ptr3 de type T_pointeur :
Ptr1, Ptr2, Ptr3 : T_Pointeur ;
Que contient mon pointeur ?
En faisant cette déclaration, le langage Ada initialise automatiquement vos pointeurs (tous les langages ne le font pas, il est alors important de l'initialiser soi-même). Mais attention ! Ils ne pointent sur rien pour l'instant (il ne faudrait pas qu'ils pointent au hasard sur des données de type float, character ou autre). Ces pointeurs sont donc initialisés avec une valeur nulle : null. C'est comme si nous avions écrit :
Ptr1, Ptr2, Ptr3 : T_Pointeur := Null ;
Autrement dit, ils sont vides !
Bon alors maintenant, comment on leur donne une valeur utile ?
Ooh ! Malheureux ! Vous oubliez quelque chose ! La valeur du pointeur n'est pas utile en tant que telle car elle doit correspondre à un adresse mémoire qui, elle, nous intéresse ! Or le souci, c'est que cet emplacement mémoire n'est pas encore créé ! A quoi bon affecter une adresse à notre pointeur s'il n'y a rien à l'adresse indiquée ! La première chose à faire est de créer cet emplacement mémoire (et bien entendu, de le lier par la même occasion à notre pointeur). Pour cela nous écrirons :
Ptr1 := new integer ;
Ainsi, Ptr1 "pointera" sur une adresse qui elle, comportera un integer !
Où dois-je écrire cette ligne ? Dans la partie déclaration ?
Non ! Surtout pas ! Je sais que c'est normalement dans la partie déclarative que se font les réquisitions de mémoire, mais nous n'y déclarerons que le type T_Pointeur et nos trois pointeurs Ptr1, Ptr2 et Ptr3. La ligne de code précédente doit s'écrire après le begin, dans le corps de votre procédure ou fonction. C'est ce que l'on appelle l'allocation dynamique. Ce procédé permet, pour simplifier, de "créer et supprimer des variables n'importe quand durant le programme". Nous entrerons dans les détails durant l'avant-dernière sous-partie, rassurez-vous. Retenez simplement qu'à la déclaration, nos pointeurs ne pointent sur rien et que pour leur affecter une valeur, il faut créer un nouvel emplacement mémoire.
Une dernière chose, pas la peine d'écrire des Put(Ptr1) ou Get(Ptr1), car je vous ai un petit peu menti au début de ce chapitre, le contenu de Ptr1 n'est pas un simple integer (ce serait trop simple), l'adresse contenue dans notre pointeur est un peu plus compliquée et d'ailleurs, vous n'avez pas besoin de la connaître, la seule chose qui compte c'est qu'elle pointe bien sur une adresse valide.
Comment accéder aux données ?
Et mon pointeur, il pointe sur quoi ? :-°
Ben... pour l'instant sur pas grand chose à vrai dire puisque l'emplacement mémoire est vide. :( Bah oui, un pointeur ça pointe et puis c'est tout... ou presque ! L'emplacement mémoire pointé n'a pas de nom (ce n'est pas une variable) il n'est donc pas possible pour l'heure de le modifier ou de lire sa valeur. Alors comment faire ? Une première méthode serait de revoir l'affectation de notre pointeur ainsi :
Ptr1 := new integer'(124) ;
Ainsi, Ptr1 pointera sur un emplacement mémoire contenant 124. Le souci, c'est qu'on ne va pas réquisitionner un nouvel emplacement mémoire à chaque fois alors que l'on pourrait réutiliser celui existant ! Voici donc une autre façon :
Ptr2 := new integer ;
Ptr2.all := 421 ;
Eh oui, je vous avais bien dit que les pointeurs étaient un poil plus compliqué. Ils comportent une "sorte" de composante comme les types structurés ! Sauf que all a beau ressemblé à une composante, ce n'est pas une composante du pointeur, mais la valeur contenue dans l'emplacement mémoire pointé !
Il existe une troisième façon de procéder, si l'on souhaite avoir un pointeur sur une variable ou une constante déjà connue. Mais nous verrons cette méthode plus loin, à la fin de ce chapitre.
Opérations sur les pointeurs
Quelles opérations peut-on donc faire avec des pointeurs ? Eh bien je vous l'ai déjà dit : pas grand chose de plus que ce que vous savez déjà faire ! Voire même moins de choses. Je m'explique : vous pouvez tester l'égalité (ou la non égalité) de deux pointeurs, effectuer des affectations ... et c'est tout. Oh, certes vous pouvez effectuer toutes les opérations que vous souhaitez sur Ptr1.all puisque ce n'est pas un pointeur mais un integer ! Mais sur Ptr1, (et je ne me répète pas pour le plaisir) vous n'avez le droit qu'au test d'égalité (et non-égalité) et à l'affectation ! Vous pouvez ainsi écrire :
if Ptr1 = Ptr2
then ...
Ou :
if Ptr1 /= Ptr2
then ...
Mais surtout pas :
Ca n'aurait aucun sens ! En revanche vous pouvez écrire :
Ptr1 := Ptr2 ;
Cela signifiera que Ptr1 pointera sur le même emplacement mémoire que Ptr2 ! Cela signifie aussi que l'emplacement qu'il pointait auparavant est perdu : il reste en mémoire, sauf qu'on a perdu son adresse ! Cet emplacement sera automatiquement supprimé à la fin de notre programme.
Ptr2.all := 5 ; --Ptr2 pointe sur "5"
Ptr1 := Ptr2 ; --On modifie l'adresse contenue dans Ptr1 ! ! !
Ptr1.all := 9 ; --Ouais ! Ptr1 pointe sur "9" maintenant !
--Sauf que du coup, Ptr2 aussi puisqu'ils
--pointent sur le même emplacement ! ! !
Donc, évitez ce genre d'opération autant que possible. Préférez plutôt :
Ptr2.all := 5 ; --Ptr2 pointe sur "5"
Ptr1.all := Ptr2.all ; --Ptr1 pointe toujours sur la même adresse
--On a simplement modifié le contenu de cette adresse
Ptr1.all := 9 ; --Maintenant Ptr1 pointe sur "9" !
--Mais comme Ptr1 et Ptr2 pointent sur
--deux adresses distinctes, il n'y a pas de problème.
Une erreur à éviter
Eh bien parce que si ptr ne pointe sur rien (s'il vaut Null), lorsque vous effectuerez ce test, le programme testera également si Ptr.all est positif (supérieur à 0). Or si Ptr ne pointe sur rien du tout alors Ptr.all n'existe pas ! ! ! Nous devrons donc prendre la précaution suivante (comme nous l'avions vu avec les tableaux) :
Avant de commencer cette partie, je vais vous demander de copier et de compiler le code ci-dessous :
with ada.text_io ; use ada.Text_IO ;
procedure aaa is
type T_Pointeur is access Integer ;
P : T_Pointeur ;
c : character ;
begin
for i in 1..8 loop
for j in 1..10**i loop
P := new integer'(i*j) ;
end loop ;
get(c) ; skip_line;
end loop ;
end aaa ;
Comme vous pouvez le voir, ce code ne fait rien de bien compliqué : il crée un pointeur auquel il affecte 10 valeurs successives, puis 100 (), puis 1 000 (), puis 10 000 () ... et ainsi de suite. Mais l'intérêt de ce programme n'est pas là. Nous allons regarder sa consommation mémoire. Pour cela, ouvrez un gestionnaire de tâche :
si vous êtes sous Windows : appuyez sur les touches Alt+Ctrl+Suppr puis cliquez sur l'onglet Processus. Le programme apparaîtra en tête de liste.
si vous êtes sous Linux ou Mac : un gestionnaire (appelé Moniteur d'activité sous Mac) est généralement disponible dans votre liste de programmes, mais vous pouvez également ouvrir une console et taper la commande top.
Lancez votre programme aaa.exe et admirez la quantité de mémoire utilisée : environ 780 Ko au démarrage mais après chaque saisie du caractère C, la mémoire utilisée augmente de manière exponentielle (quadratique en fait :D ). Ci-dessous, une capture d'écran avec 200 Mo de mémoire utilisée par ce "petit" programme (mais on peut faire bien mieux).
Mais comment se fait-il qu'un si petit programme puisse utiliser autant de mémoire ?
C'est ce que nous allons expliquer maintenant avant de fournir une solution à ce problème qui ne nous est jamais arrivé avec nos bonnes vieilles variables.
Un problème de mémoire
Reprenons nos schémas précédents car ils étaient un peu trop simplistes. Lorsque vous lancez votre programme, l'ordinateur va réserver des emplacements mémoire. Pour le code du programme tout d'abord, puis pour les variables que vous aurez déclaré entre is et begin. Ainsi, avant même d'effectuer le moindre calcul ou affichage, votre programme va réquisitionner la mémoire dont il va avoir besoin : c'est à cela que sert cette fameuse partie déclarative et le typage des variables. On dit que les variables sont stockées en mémoire statique, car la taille de cette mémoire ne va pas varier.
A cela, il faut ajouter un autre type de mémoire : la mémoire automatique. Au démarrage, l'ordinateur ne peut connaître les choix que l'utilisateur effectuera. Certains choix ne nécessiteront pas d'avantage de mémoire, d'autres entraîneront l'exécution de sous-programmes disposant de leurs propres variables ! Le même procédé de réservation aura alors lieu dans ce que l'on appelle la pile d'exécution : à noter que cette pile a cette fois une taille variable dépendant du déroulement du programme et des choix de l'utilisateur.
Mais ce procédé a un défaut : il gaspille la mémoire ! Toute variable déclarée ne disparaît qu'à la fin de l'exécution du programme ou sous-programme qui l'a généré. Ni votre système d'exploitation ni votre compilateur ne peuvent deviner si une variable est devenue inutile. Elle continue donc d'exister malgré tout. A l'inverse, ce procédé ne permet pas de déclarer des tableaux de longueur indéterminée : il faut connaître la taille avant même l'exécution du code source ! Contraignant. :colere2:
C'est pourquoi existe un dernier type de mémoire appelé Pool ou Tas. Ce pool, comme la pile d'exécution, n'a pas de taille prédéfinie. Ainsi, lorsque vous déclarez un pointeur P dans votre programme principal, l'ordinateur réserve suffisamment d'emplacements en mémoire statique pour pouvoir enregistrer une adresse. Puis, lorsque votre programme lit :
P := new integer ; --suivie éventuellement d'une valeur
Celui-ci va automatiquement allouer, dans le Pool, suffisamment d'emplacements mémoires pour enregistrer un Integer. On parle alors d'allocation dynamique. Donc si nous répétons cette instruction (un peu comme nous l'avons fait dans le programme donné en début de sous-partie), l'ordinateur réservera plusieurs emplacements mémoire dans le Pool.
Résolution du problème
Unchecked_Deallocation
Il est donc important lorsque vous manipuler des pointeurs de penser aux opérations effectuées en mémoire par l'ordinateur. Allouer dynamiquement de la mémoire est certes intéressant mais peut conduire à de gros gaspillages si l'on ne réfléchit pas à la portée de notre pointeur : tant que notre pointeur existe en mémoire statique, les emplacements alloués en mémoire dynamique demeurent et s'accumulent.
La mémoire dynamique n'était pas sensée régler ce problème de gaspillage justement ?
Bien sûr que oui. Nous disposons d'une instruction d'allocation de mémoire (new), il nous faut donc utiliser une instruction de désallocation. Malheureusement celle-ci n'est pas aisée à mettre en œuvre et est risquée. Nous allons devoir faire appel à une procédure : Ada.Unchecked_Deallocation ! Mais attention, il s'agit d'une procédure générique (faite pour tout type de pointeur) qui est donc inutilisable en tant que telle. Il va falloir lui créer une sœur jumelle, que nous appellerons Free, prévue pour notre type T_Pointeur. Voici le code corrigé :
with ada.text_io ; use ada.Text_IO ;
with Ada.Unchecked_Deallocation ;
procedure aaa is
type T_Pointeur is access Integer ;
P : T_Pointeur ;
c : character ;
procedure free is new Ada.Unchecked_Deallocation(Integer,T_Pointeur) ;
begin
for i in 1..8 loop
for j in 1..10**i loop
P := new integer'(i*j) ;
free(P) ;
end loop ;
get(c) ; skip_line;
end loop ;
end aaa ;
Vous remarquerez tout d'abord qu'à la ligne 2, j'indique avec with que mon programme va utiliser la procédure Ada.Unchecked_Deallocation (pas de use, cela n'aurait aucun sens puisque ma procédure est générique). Puis, à la ligne 8, je crée une procédure Free à partir de Ada.Unchecked_Deallocation : on dit que l'on instancie (mais nous verrons tout cela plus en détail dans la partie IV). Pour cela, il faut préciser tout d'abord le type de donnée qui est pointé puis le type de Pointeur utilisé.
Enfin, à la ligne 13, j'utilise ma procédure Free pour libérer la mémoire du Pool. Mon pointeur P ne pointe alors plus sur rien du tout et il est réinitialisé à Null. Vous pouvez compiler ce code et le tester : notre problème de "fuite de mémoire" a disparu !
Risques inhérents à la désallocation
Il est toutefois risqué d'utiliser Ada.Unchecked_Deallocation et la plupart du temps, je ne l'utiliserai pas. Imaginez que vous ayez deux pointeurs P1 et P2 pointant sur un même espace mémoire :
Le compilateur considèrera ce code comme correct mais que se passera-t-il ? Lorsque P1 est désalloué à la ligne 4, il est remis à Null mais cela signifie aussi que l'emplacement vers lequel il pointait disparaît. Et P2 ? Il pointe donc désormais vers un emplacement mémoire qui a disparu et il ne vaut pas Null ! Voilà donc pourquoi on évitera la désallocation lorsque cela est possible.
Une autre méthode
Je veux bien, mais tu nous exposes un problème, tu nous donne la solution et ensuite tu nous dis de ne surtout pas l'employer ! Je fais moi ? o_O
Une autre solution consiste à réfléchir (oui, je sais c'est dur :p ) à la portée de notre type T_pointeur. En effet, lorsque le bloc dans lequel ce type est déclaré (la procédure ou la fonction le plus souvent) se termine, le type T_pointeur disparaît et le pool de mémoire qu'il avait engendré disparaît lui aussi. Ainsi, pour éviter tout problème avec Ada.Unchecked_Deallocation, il peut être judicieux d'utiliser un bloc de déclaration avec l'instruction declare.
with ada.text_io ; use ada.Text_IO ;
procedure aaa is
c : character ;
begin
for i in 1..8 loop
for j in 1..10**i loop
declare
type T_Ptr is access Integer ;
P : T_Ptr ;
begin
P := new integer'(i*j) ;
end ;
end loop ;
get(c) ; skip_line;
end loop ;
end aaa ;
Crée trois pointeurs Ptr1, Ptr2 et Ptr3 sur des integer
Demande à l'utilisateur de saisir les valeurs pointées par Ptr1 et Ptr2
Enregistre dans l'emplacement mémoire pointé par Ptr3, la somme des deux valeurs saisies précédemment.
Je sais, c'est bidon comme exercice et vous pourriez le faire les yeux fermés avec des variables. Sauf qu'ici, je vous demande de manipuler non plus des variables, mais des objets appelés pointeurs ! :p
Solution
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Integer_Text_IO ; USE Ada.Integer_Text_IO ;
WITH Ada.Unchecked_Deallocation ;
procedure Test_Pointeur is
type T_Pointeur is access Integer ;
procedure Free is new Ada.Unchecked_Deallocation(Integer, T_Pointeur) ;
Ptr1, Ptr2, Ptr3 : T_Pointeur ;
begin
Ptr1 := new Integer ;
Put("Quelle est la premiere valeur pointee ? ") ;
get(Ptr1.all) ; skip_line ;
Ptr2 := new Integer ;
Put("Quelle est la seconde valeur pointee ? ") ;
get(Ptr2.all) ; skip_line ;
Ptr3 := new Integer'(Ptr1.all + Ptr2.all) ;
Free(Ptr1) ; --on libère nos deux premiers pointeurs
Free(Ptr2) ;
Put("Leur somme est de ") ;
Put(Ptr3.all) ;
Free(Ptr3) ; --on libère le troisième, mais est-ce vraiment utile ? ^^
end Test_Pointeur ;
Exercice 2
Énoncé
Deuxième exercice, vous allez devoir créer un programme Inverse_pointeur qui saisit une première valeur pointée par Ptr1, puis une seconde pointée par Ptr2 et qui inversera les pointeurs. Ainsi, à la fin du programme, Ptr1 devra pointer sur la seconde valeur et Ptr2 sur la première. Attention, les valeurs devront être saisies une et une seule fois, elle seront ensuite fixée !
Une indication : vous aurez sûrement besoin d'un troisième pointeur pour effectuer cet échange.
Solution
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Integer_Text_IO ; USE Ada.Integer_Text_IO ;
WITH Ada.Unchecked_Deallocation ;
procedure Inverse_Pointeur is
type T_Pointeur is access Integer ;
procedure Free is new Ada.Unchecked_Deallocation(Integer,T_Pointeur) ;
Ptr1, Ptr2, Ptr3 : T_Pointeur ;
begin
Ptr1 := new Integer ;
Put("Quelle est la premiere valeur pointee ? ") ;
get(Ptr1.all) ; skip_line ;
Ptr2 := new Integer ;
Put("Quelle est la seconde valeur pointee ? ") ;
get(Ptr2.all) ; skip_line ;
Ptr3 := Ptr1 ;
Ptr1 := Ptr2 ;
Ptr2 := Ptr3 ; Free(Ptr3) ; --Attention à ne pas libérer Ptr1 ou Ptr2 !
Put("Le premier pointeur pointe sur : ") ;
Put(Ptr1.all) ; Free(Ptr1) ;
Put(" et le second sur : ") ;
Put(Ptr2.all) ; Free(Ptr2) ;
end Inverse_Pointeur ;
Vous êtes parvenus à la fin de la première moitié de ce double-chapitre. Comme je vous l'avais dit en introduction, si des doutes subsistent, n'hésitez pas à relire ce chapitre ou à poster vos questions avant que les difficultés ne s'accumulent. La seconde moitié du chapitre sera en effet plus complexe. Elle vous apprendra à créer des pointeurs sur des variables, des constantes, des programmes... ou à créer des fonctions ou procédures manipulant des pointeurs. Le programme est encore chargé ^^
Après un premier chapitre présentant la théorie sur les pointeurs (ou accesseurs) et l'allocation dynamique, nous allons dans cette seconde partie nous intéresser aux différentes possibilités offertes par le langage Ada : comment pointer sur une variable ou une constante déjà créée ? Comment créer des pointeurs constants ? Comment passer un pointeur en argument dans une fonction ou une procédure ? Comment créer puis manipuler des pointeurs sur des programmes ? C'est ce à quoi nous allons tenter de répondre dans ce chapitre avant d'effectuer quelques exercices d'application.
Pour l'instant, nous avons été obligés de pointer sur des valeurs définies par vos propres soins. Nous voudrions désormais pouvoir pointer sur une valeur générée par l'utilisateur ou par le programme, sans que le programmeur en ait eu préalablement connaissance. Une difficulté se pose : lorsque vous créez un "pointeur sur 7", vous demandez à l'ordinateur de créer dans une zone non utilisée de la mémoire un emplacement contenant la valeur 7. Or pour pointer sur une variable, il ne faudra rien créer ! La variable est créée dès le démarrage de votre programme dans une zone de la mémoire qui a été préalablement réquisitionnée et dont la taille ne varie pas (c'est à cela que servent les déclarations). Il faut donc revoir notre type T_Pointeur pour spécifier qu'il peut pointer sur tout !
Type T_Pointeur is access all integer ;
L'instruction all permet d'indiquer que l'on peut pointer sur un emplacement mémoire créé en cours de programme (on parle de mémoire dynamique, comme pour l'allocation dynamique), mais aussi sur un emplacement mémoire déjà existant (on parle de mémoire statique) comme une variable.
La déclaration des pointeurs se fera normalement, en revanche, les variables que vous autoriserez à être pointées devront être clairement spécifiées pour éviter d'éventuels problèmes grâce à l'instruction aliased.
Ptr : T_Pointeur ;
N : aliased integer ;
Et maintenant comment je récupère l'adresse de ma variable ?
C'est simple, grâce à un attribut : access !
...
begin
N := 374 ; --N prend une valeur, ici 374
Ptr := N'access ; --Ptr prend comme valeur l'adresse de N
Ainsi, Ptr.all correspondra à la variable N ! Retenez donc ces trois choses :
le type T_Pointeur doit être généralisé avec all ;
les variables doivent être spécifiées avec aliased ;
l'adresse (ou plus exactement, la référence) peut être récupérée avec l'attribut access.
Pointeur sur une constante et pointeur constant
Pointeur sur une constante
De la même manière, il est possible de créer des pointeurs pointant sur des constantes. Pour cela, notre type T_Pointeur doit être défini ainsi grâce à l'instruction constant :
type T_Pointeur is access constant Integer ;
Notre pointeur et notre constante seront donc déclarées ainsi :
Ptr est déclaré de la même manière que d'habitude. Quant à notre constante N, elle doit être spécifiée comme pouvant être pointée grâce à l'instruction aliased ; elle doit être indiquée comme constante avec l'instruction constant et elle doit être indiquée comme de type Integer (bien sûr) valant 35 (par exemple). Puis, nous pourrons affecter l'adresse mémoire de N à notre pointeur Ptr :
Ptr := N'access ;
Il est donc possible par la suite de modifier la valeur de notre pointeur, par exemple en écrivant :
Ptr := N'access ;
Ptr := M'access ; --M doit bien-sûr être défini comme aliased constant integer
En revanche il n'est pas possible de modifier la valeur pointée car c'est elle qui doit être constante. Vous ne pourrez donc pas écrire :
Pointeur constant
Il est toutefois possible de créer des pointeurs constants. Redéfinissons de nouveau notre type T_Pointeur et nos objets et variables :
type T_Pointeur is access all integer ;
N : integer ;
Ptr : constant T_Pointeur := N'access ;
Dans ce cas-ci, c'est le pointeur qui est contant : il pointera sur l'emplacement mémoire de la variable N et ne bougera plus. Maintenant, rien n'empêche N (et donc son emplacement mémoire) de prendre différentes valeurs (d'ailleurs, pour l'heure, Ptr pointe sur N mais N n'a aucune valeur). Exemple d'opérations possibles :
N := 5 ;
Ptr.all := 9 ;
Exemple d'opérations interdites dès lors que notre pointeur est constant :
N'oubliez pas : ici c'est le pointeur qui est constant et donc l'adresse ne doit pas changer (par contre ce qui se trouve à cette adresse peut changer, ou pas).
Pointeur sur pointeur
L'idée semble saugrenue et pourtant elle fera l'objet de notre avant dernier chapitre : créer un pointeur sur un pointeur sur un integer ! Nous devrons donc créer deux types de pointeurs distincts : un type "pointeur sur integer" et un type "pointeur sur pointeur sur integer" !
type T_Pointeur_Integer is access Integer ;
type T_Pointeur_Pointeur is access T_Pointeur_Integer ;
PtrI : T_Pointeur_Integer ; --PtrI pour Pointeur-Integer
PtrP : T_Pointeur_Pointeur ; --PtrP pour Pointeur-Pointeur
Cela devrait nous permettre de créer une sorte de liste de pointeurs qui se pointent les uns les autres (mais nous verrons cela plus en détail dans l'avant dernier chapitre) !
Attention, cela apporte quelques subtilités :
PtrI := new Integer ;
PtrI.all := 78 ;
PtrP := new T_Pointeur_Integer ;
PtrP.all := PtrI ;
PtrP est un pointeur sur un pointeur, donc PtrP.all est lui aussi un pointeur, mais un pointeur sur un entier cette fois ! Si je souhaite modifier cet entier, deux solutions s'offrent à moi : soit utiliser PtrI.all, soit utiliser PtrP de la manière suivante :
PtrP.all.all := 79 ;
Il serait même judicieux de reprendre notre code et de ne pas créer de pointeur PtrI. Tout devrait pouvoir être fait avec PtrP. Voyons cela en exemple :
...
type T_Pointeur_Integer is access Integer ;
type T_Pointeur_Pointeur is access T_Pointeur_Integer ;
PtrP : T_Pointeur_Pointeur ; --PtrP pour Pointeur-Pointeur
begin
PtrP := new T_Pointeur_Integer ;
PtrP.all := new Integer ;
PtrP.all.all := 78 ;
...
Avec une seule variable PtrP, nous pouvons manipuler 3 emplacements mémoire :
L'emplacement mémoire du pointeur sur pointeur PtrP
L'emplacement mémoire du pointeur sur integer PtrP.all
L'emplacement mémoire de l'integer PtrP.all.all qui vaut ici 78 !
Et avec un pointeur sur pointeur sur pointeur sur pointeur sur pointeur ... nous pourrions peut-être parvenir à créer, avec une seule variable, une liste d'informations liées les unes aux autres et de longueur infinie (ou tout du moins non contrainte, il suffirait d'utiliser l'instruction new à chaque fois que l'on souhaiterait allonger cette liste. Ces "listes" sont la principale application des pointeurs que nous verrons dans ce cours et fera l'objet d'un prochain chapitre ! Alors encore un peu de patience. ^^
Avant de passer aux exercices finaux, il nous reste un dernier point à traiter : comment transmettre un pointeur comme paramètre à une fonction ou une procédure ? Supposons que nous ayons deux procédures Lire() et Ecrire() et une fonction Calcul()nécessitant un pointeur sur Integer en paramètre. Voyons tout d'abord comment déclarer nos procédures et fonctions sur des prototypes :
Avec cette seconde façon de procéder, il suffira de fournir en paramètre n'importe quel type de pointeur sur Integer, qu'il soit de type T_Pointeur ou autre. Par la suite, nous pourrons appeler nos sous-programmes de différentes façons :
...
Ptr : T_Pointeur ;
N : aliased Integer := 10 ;
BEGIN
Ptr := new Integer ;
Lire(Ptr) ;
Ecrire(N'access) ;
N := Calcul(new integer'(25)) ;
...
Chacun de ces appels est correct. Mais il faut prendre une précaution : le pointeur que vous transmettez à vos fonctions/procédures doit absolument être initialisé et ne pas valoir null ! Faute de quoi, vous aurez le droit à un joli plantage de votre programme.
Seconde remarque d'importance : les pointeurs transmis en paramètres sont de mode in. Autrement dit, la valeur du pointeur (l'adresse sur laquelle il pointe) ne peut pas être modifiée. Cependant, rien n'empêche de modifier la valeur pointée. Ptr n'est accessible qu'en lecture ; Ptr.all est accessible en lecture ET en écriture ! C'est donc comme si nous transmettions Ptr.all comme paramètre en mode in out. Continuons la réflexion : pour les fonctions, il est normalement interdit de fournir des paramètres en mode out ou in out, mais en fournissant un pointeur comme paramètre, cela permet donc d'avoir, dans une fonction, un paramètre Ptr.all en mode in out !
Cette dernière partie théorique s'avère plus compliquée que les autres. Si vous pensez ne pas être encore suffisamment au point sur les pointeurs (joli jeu de mot :-° ), je vous en déconseille la lecture pour l'instant et vous invite à vous exercer davantage. Si vous êtes suffisamment aguerris, alors nous allons passer aux chose très, TRES sérieuses ! :pirate:
Un exemple simple
Commençons par prendre un exemple simple (simpliste même, mais rassurez-vous, l'exemple suivant sera bien plus ardu). Nous disposons de trois fonctions appelées Double( ), Triple( ) et Quadruple( ) dont voici les prototypes :
function Double(n : integer) return integer ;
function Triple(n : integer) return integer ;
function Quadruple(n : integer) return integer ;
Peu nous importe de savoir comment elles ont été implémentées, ce que l'on sait c'est qu'elles nécessitent un paramètre de type integer et renvoient toutes un integer qui est, au choix, le double, le triple ou le quadruple du paramètre fournit. Seulement nous voudrions maintenant créer une procédure Table( ) qui affiche le double, le triple ou le quadruple de tous les nombres entre a et b (a et b étant deux nombres choisis par l'utilisateur, la fonction choisie l'étant elle aussi par l'utilisateur). Nous aurions besoin que les fonctions double( ), triple( ) ou quadruple( ) puissent être transmise à la procédure Table( ) comme de simples paramètres, ce qui éviterait que notre sous-procédure ait à se soucier du choix effectué par l'utilisateur. Nous voudrions ce genre de prototype :
procedure Table(MaFonction : function ;
a,b : integer) ;
Malheureusement, cela n'est pas possible en tant que tel. Pour arriver à cela, nous allons devoir transmettre en paramètre, non pas une fonction, mais un pointeur sur une fonction. Donc première chose : comment déclarer un pointeur sur une fonction ? C'est un peu compliqué car qu'est-ce qu'une fonction ? C'est avant tout des paramètres d'un certain type qui vont être modifiés afin d'obtenir un résultat d'un certain type. Ainsi, si un pointeur pointe sur une fonction à un paramètre, il ne pourra pas pointer sur une fonction à deux paramètres. Si un pointeur pointe sur une fonction renvoyant un integer, il ne pourra pas pointer sur une fonction renvoyant un float. Donc nous devons définir un type T_Ptr_Fonction qui prenne en compte tout cela : nombre et type des paramètres, type de résultat. Ce qui nous amène à la déclaration suivante :
type T_Ptr_Fonction is access function(n : integer) return integer ;
f : T_Ptr_Fonction ;
--f est la notation mathématique usuelle pour fonction
--mais n'oubliez pas qu'il s'agit uniquement d'un pointeur !
Définissons maintenant notre procédure Table :
procedure Table(MaFonction : T_Ptr_Fonction ;
a,b : integer) is
begin
for i in a..b loop
put(i) ;
put(" : ") ;
put(MaFonction.all(i)) ;
new_line ;
end loop ;
end Table ;
Heureusement, le langage Ada nous permet de remplacer la ligne 7 par la ligne ci-dessous pour plus de commodité et de clareté :
put(MaFonction(i)) ;
Toutefois, n'oubliez pas que MaFonction n'est pas une fonction ! C'est un pointeur sur une fonction ! Ada nous fait grâce du .all pour les fonctions pointées à la condition que les paramètres soient écrits. Enfin, il ne reste plus qu'à appeler notre procédure Table( ) dans la procédure principale :
--Choix de la fonction à traiter
put("Souhaitez-vous afficher les doubles(2), les triples(3) ou les quadruples(4) ?") ;
get(choix) ; skip_line ;
case choix is
when 2 => f := double'access ;
when 3 => f := triple'access ;
when others => f := quadruple'access ;
end case ;
--Choix des bornes de l'intervalle
put("A partir de ") ; get(a) ; skip_line ;
put("jusqu'à ") ; get(b) ; skip_line ;
--Affichage de la table de a à b de la fonction f choisie
Table(f,a,b) ;
En procédant ainsi, l'ajout de fonctions Quintuple( ), Decuple( ), Centuple( ) ... fonctionnant sur le même principe que les précédentes se fera très facilement sans modifier le code de la fonction Table( ), mais uniquement la portion de code où l'utilisateur doit faire un choix entre les fonctions. Cela peut paraître anodin à notre niveau, mais ce petit gain de clarté et d'efficacité devient très important lors de projets plus complexes faisant intervenir plusieurs programmeurs. Celui rédigeant le programme Table( ) n'a pas besoin d'attendre que celui rédigeant les fonctions Double( ), Triple( ) ... ait terminé, il peut dors et déjà coder sa procédure en utilisant une fonction f théorique.
Un exemple de la vie courante
Je ne vois toujours pas l'intérêt de créer des pointeurs sur des fonctions ?
Ah bon ? Pourtant vous utilisez en ce moment même ce genre de procédé. ^^ Alors même que vous lisez ces lignes, votre ordinateur doit gérer une liste de programmes divers et variés. Il vous suffit d'appuyer sur Alt+Ctrl+Suppr sous Windows puis de cliquer sur l'onglet Processus pour voir la liste des processus en cours. Sous Linux, ouvrez la console et tapez la commande ps (pour process status).
Comment votre système d'exploitation fait-il pour gérer plusieurs processus ? Entre Explorer, votre navigateur internet, votre antivirus, l'horloge ... sans compter les programmes que vous pourriez encore ouvrir ou fermer, il faut bien que votre système d'exploitation (que ce soit Windows, Linux, MacOS ...) puisse gérer une liste changeante de programmes ! C'est, très schématiquement, ce que nous permettent les pointeurs : gérer des listes de longueurs indéfinies (voir le prochain chapitre) de pointeurs vers des programmes alternativement placés en mémoire vive ou traités par le processeur. Rassurez-vous, je ne compte pas vous faire développer un système d'exploitation dans votre prochain TP, je vous propose là simplement une illustration de notre travail.
Un exemple très ... mathématique
Ce troisième et dernier exemple s'adresse à ceux qui ont des connaissances mathématiques un peu plus poussées (disons, niveau terminale scientifique). En effet, les fonctions sont un outil mathématique très puissant et très courant. Et deux opérations essentielles peuvent-être appliquées aux fonctions : la dérivation et l'intégration. Je souhaiterais traiter ici l'intégration. Ou plutôt, une approximation de l'intégrale d'une fonction par la méthode des trapèzes.
Pour rappel, et sans refaire un cours de Maths, l'intégrale entre a et b d'une fonction f correspond à l'aire comprise entre la courbe représentative de la fonction (entre a et b) et l'axe des abscisses. Pour approximer cette aire, plusieurs méthodes furent inventées, notamment la méthode des rectangles qui consiste à approcher l'aire de cette surface par une série de rectangles. La méthode des trapèzes consiste quant à elle à l'approximer par une série de trapèzes rectangles.
Dans l'exemple ci-dessus, on a cherché l'aire sous la courbe entre 1 et 4. L'intervalle [ 1 ; 4 ] a été partagé en 3 sous-intervalles de longueur 1. La longueur de ces sous-intervalles est appelée le pas. Comment calculer l'aire du trapèze ABB'A' ? De la manière suivante : . Et on remarquera que , , ...
Nous allons donc définir quelques fonctions dont voici les prototypes :
function carre(x : float) return float ;
function cube(x : float) return float ;
function inverse(x : float) return float ;
Nous allons également définir un type T_Pointeur :
type T_Pointeur is access function(x : float) return float ;
Nous aurons besoin d'une fonction Aire_Trapeze et d'une fonction Integrale dont voici les prototypes :
--aire_trapeze() ne calcule l'aire que d'un seul trapèze
--f est la fonction étudiée
--x le "point de départ" du trapèze
--pas correspond au pas, du coup, x+pas est le "point d'arrivée" du trapèze
function aire_trapeze(f : T_Pointeur ; x : float ; pas : float) return float ;
--integrale() effectue la somme des aires de tous les trapèzes ainsi que le calcul du pas
--f est la fonction étudiée
--min et max sont les bornes
--nb_inter est le nombre de sous-intervalles et donc de trapèzes,
--ce qui correspond également à la précision de la mesure
function integrale(f: T_pointeur ;
min,max: float ;
nb_inter : integer) return float is
Je vous laisse le soin de rédiger seuls ces deux fonctions. Cela constituera un excellent exercice sur les pointeurs mais aussi sur les intervalles et le pas. Il ne reste donc plus qu'à appeler notre fonction integrale( ) :
--a,b sont des float saisis par l'utilisateur représentant les bornes de l'intervalle d'intégration
--i est un integer saisi par l'utilisateur représentant le nombre de trapèzes souhaités
integrale(carre'access,a,b,i) ;
integrale(cube'access,a,b,i) ;
integrale(inverse'access,a,b,i) ;
Bon allez ! Je suis bon joueur, :p je vous transmets tout de même un code source possible. Attention, ce code est très rudimentaire, il ne teste pas si la borne inférieure est bel et bien inférieure à la borne supérieure, rien n'est vérifié quant à la continuité ou au signe de la fonction étudiée ... bref, il est éminemment perfectible pour un usage mathématique régulier. Mais là, pas la peine d'insister, vous le ferez vraiment tous seuls. ;)
with ada.Text_IO, ada.Integer_Text_IO, ada.Float_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO, ada.Float_Text_IO ;
procedure integration is
---------------------------
-- Fonctions de x --
---------------------------
function carre(x : float) return float is
begin
return x**2 ;
end carre ;
function inverse(x:float) return float is
begin
return 1.0/x ;
end inverse ;
function cube(x:float) return float is
begin
return x**3 ;
end cube ;
------------------
-- Types --
------------------
type T_Pointeur is access function (x : float) return float ;
-------------------------
-- Fonctions de f --
-------------------------
function aire_trapeze(f : T_Pointeur ; x : float ; pas : float) return float is
begin
return ((f.all(x)+f(x+pas))/2.0)*pas ;
end aire_trapeze ;
function integrale(f: T_pointeur ; min,max: float ; nb_inter : integer) return float is
res : float := 0.0 ;
pas : float ;
begin
pas := (max-min)/float(nb_inter) ;
for i in 0..nb_inter-1 loop
res := res + aire_trapeze(f,min+float(i)*pas,pas) ;
end loop ;
return res ;
end integrale ;
-------------------------------
-- Procédure principale --
-------------------------------
a,b : float ;
i : integer ;
begin
put("Entre quelles valeurs souhaitez-vous integrer les fonctions ?") ;
get(a) ; get(b) ; skip_line ;
put("Combien de trapezes souhaitez-vous construire ?") ;
get(i) ; skip_line ;
put("L'integrale de la fonction carre est : ") ;
put(integrale(carre'access,a,b,i),Exp=>0) ; new_line ;
put("L'integrale de la fonction inverse est : ") ;
put(integrale(inverse'access,a,b,i),Exp=>0) ; new_line ;
put("L'integrale de la fonction cube est : ") ;
put(integrale(cube'access,a,b,i),Exp=>0) ; new_line ;
end integration ;
Voici un programme tout ce qu'il y a de plus simple :
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure programme is
n,m : integer ;
begin
Put("Choisissez un nombre n :") ; get(n) ; skip_line ;
Put("Choisissez un nombre m :") ; get(m) ; skip_line ;
Put("La somme des nombres choisis est ") ;
Put(n+m) ;
end programme ;
Vous devez modifier ce code de façon à changer le contenu des variables n et m, sans jamais modifier les variables elles-mêmes. Ainsi, le résultat affiché sera faux.
Solution
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure programme is
n,m : aliased integer ;
type T_Pointeur is access all integer ;
P : T_Pointeur ;
begin
Put("Choisissez un nombre n :") ; get(n) ; skip_line ;
P := n'access ;
P.all := P.all + 1 ;
Put("Choisissez un nombre m :") ; get(m) ; skip_line ;
P := m'access ;
P.all := P.all * 3 ;
Put("La somme des nombres choisis est ") ;
Put(n+m) ;
end programme ;
Exercice 2
Énoncé
Reprendre l'exercice précédent, en remplaçant les deux variables n et m par un tableau T de deux entiers puis en modifiant ses valeurs uniquement à l'aide d'un pointeur.
Solution
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure programme is
type T_Tableau is array(1..2) of integer ;
type T_Pointeur is access all T_Tableau ;
T : aliased T_Tableau ;
P : T_Pointeur ;
begin
Put("Choisissez un nombre n :") ; get(T(1)) ; skip_line ;
Put("Choisissez un nombre m :") ; get(T(2)) ; skip_line ;
P := T'access ;
P.all(1):= P.all(1)*18 ;
P.all(2):= P.all(2)/2 ;
Put("La somme des nombres choisis est ") ;
Put(T(1)+T(2)) ;
end programme ;
Exercice 3
Énoncé
Reprendre le premier exercice, en remplaçant les deux variables n et m par un objet de type structuré comportant deux composantes entières puis en modifiant ses composantes uniquement à l'aide d'un pointeur.
Solution
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure programme is
type T_couple is
record
n,m : integer ;
end record ;
type T_Pointeur is access all T_couple ;
Couple : aliased T_couple ;
P : T_Pointeur ;
begin
Put("Choisissez un nombre n :") ; get(couple.n) ; skip_line ;
Put("Choisissez un nombre m :") ; get(couple.m) ; skip_line ;
P := Couple'access ;
P.all.n:= P.all.n**2 ;
P.all.m:= P.all.m mod 3 ;
Put("La somme des nombres choisis est ") ;
Put(Couple.n + Couple.m) ;
end programme ;
Exercice 4
Énoncé
Reprendre le premier exercice. La modification des deux variables n et m se fera cette fois à l'aide d'une procédure dont le(s) paramètres seront en mode in.
Solution
with ada.Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Integer_Text_IO ;
procedure programme is
procedure modif(P : access integer) is
begin
P.all := P.all*5 + 8 ;
end modif ;
n,m : aliased integer ;
begin
Put("Choisissez un nombre n :") ; get(n) ; skip_line ;
modif(n'access) ;
Put("Choisissez un nombre m :") ; get(m) ; skip_line ;
modif(m'access) ;
Put("La somme des nombres choisis est ") ;
Put(n+m) ;
end programme ;
Exercice 5 (Niveau Scientifique)
Énoncé
Rédiger un programme calculant le coefficient directeur de la sécante à la courbe représentative d'une fonction f en deux points A et B. A partir de là, il sera possible de réaliser une seconde fonction qui donnera une valeur approchée de la dérivée en un point de la fonction f.
Par exemple, si , alors la fonction Secante(f,2,7) renverra . La fonction Derivee(f,5) renverra quant à elle où h devra être suffisamment petit afin d'améliorer la précision du calcul.
Solution
with ada.Text_IO, ada.Float_Text_IO, ada.Integer_Text_IO ;
use ada.Text_IO, ada.Float_Text_IO, ada.Integer_Text_IO ;
procedure derivation is
type T_Ptr_Fonction is access function(x : float) return float ;
function carre (x : float) return float is begin
return x**2 ;
end carre ;
function cube(x : float) return float is begin
return x**3 ;
end cube;
function inverse(x : float) return float is begin
return 1.0/x ;
end inverse;
function secante(f : T_Ptr_Fonction ;
a : float ;
b : float ) return float is
begin
return (f(b)-f(a))/(b-a) ;
end secante ;
function derivee(f : T_Ptr_Fonction ;
x : float ;
precision : float := 0.000001) return float is
begin
return secante(f,x,x+precision) ;
end derivee ;
choix : integer := 1 ;
f : T_Ptr_Fonction ;
x: float ;
begin
loop
put("Quelle fonction souhaitez-vous deriver ? Inverse(1), Carre(2) ou Cube(3) .") ;
get(choix) ; skip_line ;
case choix is
when 1 => f := inverse'access ;
when 2 => f := carre'access ;
when 3 => f := cube'access ;
when others => exit ;
end case ;
put("Pour quelle valeur de x souhaitez-vous connaitre la derivee ?") ;
get(x) ; skip_line ;
put("La derivee vaut environ") ; put(derivee(f,x),Exp=>0,Aft=>3) ; put(" pour x =") ; put(x,Exp=>0,Aft=>2) ;
new_line ; new_line ;
end loop ;
end derivation ;
Il est possible de demander à l'utilisateur de régler la "précision" lui-même, mais j'ai retiré cette option car elle alourdissait l'utilisation du programme sans apporter de substantiels avantages.
Bien, si vous lisez ces lignes c'est que vous devriez être venus à bout de ces deux chapitres éprouvants. Il est fort possible que vous soyez encore assaillis de nombreuses questions. C'est pourquoi je vous conseille de pratiquer. Ce cours vous a proposé de nombreux exercices, il n'est peut-être pas inutile de reprendre des exercices déjà faits (affichage de tableau, de rectangles ...) et de les retravailler à l'aide des pointeurs car cette notion est réellement compliquée. N'hésitez pas non plus à relire le cours à tête reposée.
Si d'aventure vous pensez maîtriser les pointeurs, alors un véritable test vous attend maintenant. Nous allons mettre en pratique les pointeurs, la récursivité et les packages en créant avec nos petites mains un nouveau type de donnée et les outils pour le manipuler : les types abstraits de donnée ! Là encore, ce sera un chapitre complexe, mêlant théorie et pratique. Mais une fois maîtrisé, il ne vous restera plus que le TP ultime de la partie 3 ! Alors, courage !
Le chapitre que vous vous apprêtez à lire est lui aussi compliqué, mais je vous rassure, vous n'aurez pas de nouveaux objets compliqués à manipuler, non. Vous n'allez même rien apprendre de nouveau concernant la programmation orientée objet.
Mais alors quel intérêt de faire ce chapitre ? o_O
Nous allons aborder une notion d'algorithmique importante et qui nous servira pour le prochain chapitre : la récursivité. Ceux qui mènent (ou ont mené) des études scientifiques devraient me dire : "Ce serait pas plutôt récurrence que récursivité ? " Eh bien non ! Il n'y a pas d'erreur, mais cette notion est très proche du raisonnement par récurrence vu en 1ère et terminale scientifique. Pour ceux qui n'ont pas mené ce genre d'étude, n'ayez aucune crainte, nous allons tout prendre à la base, comme toujours. :D
On dit qu'un programme est récursif si pour parvenir au résultat voulu il se réemploie lui-même. Cela peut s'illustrer par les images suivantes :
Triangle de Sierpinski
Pour réaliser le triangle de sierpinski (premier exemple), on relie les milieux des 3 côtés du grand triangle de manière à former trois triangles "noirs" et un triangle "blanc" à l'envers par rapport aux autres. Puis on reproduit cette opération sur les triangles noirs, et encore, et encore ... jusqu'au nombre désiré (Cette figure fait partie de la grande famille des fractales qui ont pour principe de répéter à l'infini sur elles-mêmes la même opération).
Nautile
Idem pour le nautile, on comprend que pour développer une coquille à 30 alvéoles, le nautile doit avoir développé 29 alvéoles puis en créer seulement une supplémentaire. Le nautile répète ainsi sur lui-même à l'infini ou un grand nombre de fois, la même opération : "ajouter une alvéole". Un dernier exemple : l'éponge de Menger, une autre fractale inspirée du carré de Sierpinski. On a ici détaillé les 4 premières étapes :
Bon, c'est gentil les illustrations, mais à part les coquillages et la géométrie, ça donne quoi en programmation ?
Imaginons que vous deviez créer un programme affichant un petit bonhomme devant monter N marches d'un escalier et que vous disposez pour cela d'une procédure appelée MonterUneMarche. Il y aura deux façons de procéder. Tout d'abord la manière itérative :
PROCÉDURE MonterALaMarche(n) :
POUR i ALLANT de 1 à N
| MonterUneMarche ;
FIN DE BOUCLE
FIN DE PROCÉDURE
Ou alors on emploie une méthode récursive :
PROCÉDURE MonterALaMarche(n) :
SI n > 0
| MonterALaMarche(n-1) ;
| MonterUneMarche ;
FIN DE SI
FIN DE PROCÉDURE
La méthode récursive est un peu bizarre non ? Une explication ? Si on veut monter 0 marche, c'est facile, il n'y a rien à faire. On a gagné ! En revanche, dans le cas contraire, il faut déjà avoir monté n-1 marches puis en gravir une autre. La procédure MonterMarche fait donc appel à elle-même pour une marche de moins. Prenons un exemple, si l'on souhaite monter 4 marches :
4 marches > 0 ! Donc on doit monter déjà 3 marches :
3 marches > 0 ! Donc on doit monter déjà 2 marches :
2 marches > 0 ! Donc on doit monter déjà 1 marche :
1 marche > 0 ! Donc on doit monter déjà 0 marche :
0 marche ! ! ! c'est gagné !
Là on sait faire : le résultat renvoyé est que marche = 0.
On incrémente marche : le résultat renvoyé est que marche = 1.
On incrémente marche : le résultat renvoyé est que marche = 2.
On incrémente marche : le résultat renvoyé est que marche = 3.
On incrémente marche : le résultat renvoyé est que marche = 4.
Ce procédé est un peu plus compliqué à comprendre que la façon itérative (avec les boucles loop). Attention ! Comme pour les boucles itératives, il est possible d'engendrer une "boucle récursive infinie" ! Il est donc très important de réfléchir à la condition de terminaison. En récursivité, cette condition est en général le cas trivial, le cas le plus simple qu'il soit, la condition initiale : l'âge 0, la marche n°0, la lettre 'a' ou la case n°1 d'un tableau. Comme pour les boucles itératives, il est parfois utile de dérouler un exemple simple à la main pour être sûr qu'il n'y a pas d'erreur (souvent l'erreur se fait sur le cas initial).
Nous allons créer une fonction Produit(a,b) qui effectuera le produit (la multiplication) de deux nombres entiers naturels (c'est à dire positifs) a et b. Facile me direz-vous. Sauf que j'ajoute une difficulté : il sera interdit d'utiliser de symbole *. Nous devrons donc implémenter cette fonction uniquement avec des additions et de manière récursive. Cet exemple peut paraître complètement idiot. Toutefois, il vous permettra de réaliser votre premier algorithme récursif et vous verrez que déjà, ce n'est pas de la tarte.
Si vous souhaitez vous lancez seuls, allez-y, je vous y invite. C'est d'ailleurs la meilleure façon de comprendre les difficultés. Sinon, je vous donne quelques indications tout de suite, avant de vous révéler une solution possible.
Indications
Le cas trivial
Tout d'abord quel est le cas trivial, évident ? Autrement dit, quelle sera la condition de terminaison de notre boucle récursive ?
Le cas le plus simple est le cas Produit(a,0) ou Produit(0,b) puisqu'ils renvoient invariablement 0.
Il y a donc deux cas à traiter : si a = 0 ET/OU si b = 0.
Commutativité
o_O Erh ... c'est quoi encore ça ? Je comptais pas faire Bac +10 ! ! !
Pas d'inquiétude. La propriété de commutativité signifie juste que les nombres d'une multiplication peuvent être "commutés", c'est à dire échangés. Autrement dit . En effet, que vous écriviez ou , cela reviendra au même : le résultat vaudra 6 ! C'est une propriété évidente dont ne bénéficie pas la soustraction ou la division par exemple.
Si c'est si évident, pourquoi en parler ?
Eh bien pour régler un problème simple : pour effectuer Produit(2,3), c'est à dire , va-t-on faire (c'est à dire "3 fois" 2) ou (c'est à dire "2 fois" 3) ? Le deuxième choix semble plus rapide car il nécessitera moins d'additions et donc moins de récursions (boucles récursives). Il serait donc judicieux de traiter ce cas avant de commencer. Selon que a sera inférieur ou pas à b, on effectuera Produit(a,b) ou Produit(b,a).
Mise en œuvre
Supposons que a soit plus petit que b. Que doit faire Produit(a,b) (hormis le test de terminaison et d'inversion de a et b) ? Prenons un exemple : Produit(3,5). Nous partons d'un résultat temporaire égal à 0 (res = 0).
3 > 0. Donc notre résultat temporaire est augmenté de 5 (res = 5) et on fait le produit de 2 par 5 : Produit(2,5).
2 > 0. Donc notre résultat temporaire est augmenté de 5 (res = 10) et on fait le produit de 1 par 5 : Produit(1,5).
1 > 0. Donc notre résultat temporaire est augmenté de 5 (res = 15) et on fait le produit de 0 par 5 : Produit(0,5).
0 ! ! ! Facile. On renvoie le résultat temporaire.
Se pose alors un souci : comment transmettre la valeur temporaire de Res, notre résultat ? La fonction Produit n'a que deux paramètres a et b ! L'idée, est de ne pas surcharger la fonction Produit inutilement avec des paramètres inutiles pour l'utilisateur final. Deux solutions s'offrent à vous : soit vous créez un paramètre Res initialisé à 0 (l'utilisateur n'aura ainsi pas besoin de le renseigner) ; soit vous créez une sous-fonction (Pdt, Mult, Multiplication, appelez-la comme vous voudrez) qui, elle, aura trois paramètres.
Tests et temps processeur
Il est temps de faire un bilan : Produit(a,b) doit tester si a est plus petit que b ou égal car sinon il doit lancer Produit(b,a). Puis il doit tester si a vaut 0, auquel cas il renvoie le résultat, sinon il doit lancer Produit(a-1,b).
Nouveau problème, car en exécutant Produit(a-1,b), notre programme va à nouveau tester si a-1 < b ! Or si a était plus petit que b, a - 1 ne risque pas de devenir plus grand. On effectue donc un test inutile. Ce pourrait être anodin, sauf qu'un test prend du temps au processeur et de la mémoire, et ce temps-processeur et cette mémoire seraient plus utiles pour autre chose. Si nous demandons le résultat de Produit(7418,10965), notre programme devra effectuer 7418 tests inutiles ! Quel gâchis.
Deuxième et dernier bilan :
Notre fonction Produit(a,b) se contentera de vérifier si a est plus petit ou égal à b. Et c'est tout. Elle passera ensuite le relais à une sous-fonction (que j'appellerais Pdt).
Notre sous-fonction Pdt sera la vraie fonction récursive. Elle admettra trois paramètres : a, b et res. Le paramètre a devra être impérativement plus petit que b (c'est le travail de la fonction-mère) et res permettra de transmettre la valeur du résultat d'une récursion à l'autre.
Une solution possible
Le code ci-dessous ne constitue en aucun cas la seule et unique solution, mais seulement une solution possible :
function Produit(a,b : natural) return natural is
--------------------------
-- Insérer ici --
-- le code source de --
-- la fonction Pdt --
--------------------------
begin
if a <= b
then return Pdt(a,b,0) ;
else return Pdt(b,a,0) ;
end if ;
end Produit ;
Pour plus de clarté, j'ai écrit une fonction Produit non récursive, mais faisant appel à une sous-fonction Pdt dont le code source n'est pas écrit. Cela permet à la fois d'effectuer la disjonction de cas et surtout de fournir une fonction Produit avec seulement deux paramètres. Rassurez-vous, je vous donne tout de même le code de la sous-fonction récursive :
function Pdt(a,b,res : natural) return natural is
begin
if a = 0
then return res ;
else return Pdt(a-1, b, res + b) ;
end if ;
end Pdt ;
Voici désormais un nouveau programme à réaliser au cours duquel la récursivité va prendre tout son sens. Le principe est d'implémenter un programme Dichotomie() qui recherche un nombre entier dans un tableau préalablement classé par ordre croissant (et sans doublons).
Principe
Par exemple, nous souhaiterions savoir où se trouve le nombre 9 dans le tableau ci-dessous :
1
2
3
4
5
6
7
8
9
0
2
3
5
7
9
15
20
23
Une méthode de bourrin consiste à passer tous les nombres du tableau en revue, de gauche à droite. Dans cet exemple, il faudra donc tester les 6 premiers nombres pour savoir que le 6ème nombre est un 9 ! Comme je vous l'ai dit, 6 tests, c'est une méthode de bourrin. Je vous propose de le faire en 3 étapes seulement avec la méthode par dichotomie (prononcez "dikotomie").
Ca veut dire quoi dichotomie ?
Ce mot vient du grec ancien et signifie "couper en deux". On retrouve le suffixe "tomie" présent dans les mots appendicectomie (opération consistant à couper l'appendice), mammectomie (opération consistant à couper un sein pour lutter contre le cancer du même nom), lobotomie (opération consistant à couper et retirer une partie du cerveau) ... Bref, on va couper notre tableau en deux parties (pas nécessairement égales). Pour mieux comprendre, nous allons dérouler un algorithme par dichotomie avec l'exemple ci-dessus.
Tout d'abord, on regarde le nombre du "milieu", c'est à dire le numéro 5 (opération : ) 1 2 3 4 5 6 7 8 9 0 2 3 5 7 9 15 20 23
Comme il est plus petit que 9, on recommence mais seulement avec la partie supérieure du tableau car comme le tableau est ordonné, il ne peut y avoir de 9 avant ! 6 7 8 9 9 15 20 23
On prend à nouveau le nombre du "milieu". L'opération donne 7,5 ! Donc nous allons considérer que le nombre du "milieu" est le n°7 (je sais, ce n'est pas mathématiquement rigoureux, mais c'est bien pour cela que j'utilise des guillemets depuis le début). 6 7 8 9 9 15 20 23
Le nombre obtenu est plus grand que 9, on recommence donc avec la partie inférieure du tableau.
69
Le nombre du "milieu" est le n°6 (logique) et il vaut 9. C'est gagné ! Notre résultat est que "le 9 est à la 6ème case". 69
1
2
3
4
5
6
7
8
9
0
2
3
5
7
9
15
20
23
6
7
8
9
9
15
20
23
6
7
8
9
9
15
20
23
6
9
6
9
Avec cet algorithme, je n'ai testé que la 5ème, la 7ème et la 6ème valeur du tableau, soit seulement 3 tests au lieu de 6 pour la méthode "bourrin". Et cet écart peut très vite s'accroître notamment pour rechercher de grandes valeurs dans un grand tableau. Nous verrons dans le chapitre sur la complexité des algorithmes que le premier algorithme a une complexité en , tandis que le second a une complexité en . Oui, je sais, pour vous c'est du Chinois. Nous expliquerons cela plus tard, retenez seulement que cela signifie que pour un petit tableau, l'intérêt de la dichotomie est discutable ; en revanche pour un grand ou très grand tableau, il n'y a pas photo sur la plus grande efficacité de la dichotomie.
Mise en œuvre
Nous allons désormais implémenter notre programme Dichotomie(). Toutefois, vous aurez remarqué qu'il utilise des tableaux de tailles différentes. Nous avons donc un souci car nous ne savons déclarer que des tableaux de taille fixe. Deux solutions sont possibles :
Regarder le chapitre de la partie 4 sur la généricité pour pouvoir faire des tableaux dont on ne connaît pas préalablement la taille. Le problème, c'est que l'on risque de vite se mélanger les pinceaux, d'autant plus que ce chapitre est dans une partie encore plus dure.
Faire en sorte que notre programme manipule un tableau T de taille fixe mais aussi deux variables Min et Max qui indiqueront la "plage" du tableau qui nous intéresse ("cherche dans le tableau T entre l'indice Min et l'indice Max"). Nous retiendrons pour l'instant, vous vous en doutez, cette seconde solution. Toutefois, il sera judicieux de reprendre ce programme après avoir vu la généricité.
Autre question : que donne la division 15/2 en Ada ? Réponse :
Reponse : 7_
Puisque nous divisons deux integer, Ada nous renvoie également un integer. Or vous savez bien que cette division ne "tombe pas juste" et qu'elle devrait donner 7,5 ! Mais Ada doit faire un choix : soit la valeur approchée à l'unité près par excès (8) soit la valeur approchée à l'unité près par défaut (7). Le choix a été fait de renvoyer la valeur par défaut car elle correspond à la partie entière du nombre décimal. Toutefois, si vous vouliez savoir durant la programmation de cet algorithme, si un nombre est pair ou impair, je vous rappelle qu'il existe l'opération mod !
Exemple : 15 mod 2 = 1 (Donc 15 est impair) ; 18 mod 2 = 0 (Donc 18 est pair).
Dernier problème à régler : que faire s'il n'y a pas de 9 ? Renvoyer une valeur particulière ? Ce n'est pas la meilleure idée. L'utilisateur final n'est pas sensé le savoir. Renvoyé l'indice de la valeur la plus proche ? Pourquoi pas mais si l'utilisateur ne connaît pas cette nuance, cela peut poser problème. Le mieux serait de renvoyer deux résultats : un booléen Existe indiquant si la valeur existe ou non dans le tableau et une variable Indice indiquant la valeur trouvée (seulement si Existe vaut true).
Dès lors, plusieurs solutions s'offrent à vous : vous pouvez créer un type structuré (avec record) pour renvoyer deux résultats en même temps. Vous pouvez créer une procédure avec deux paramètres en mode out ou bien utiliser un pointeur sur booléen comme paramètre à votre fonction pour savoir savoir si le résultat existe. A vous de choisir.
Solution
Voici une solution possible pour le programme Dichotomie() :
Procedure Dichotomie is
type T_Tableau is array(1..50) of integer ; --à vous de choisir la taille du tableau
type T_Ptr_Bool is access boolean ;
----------------------------------
-- Insérer ici le code source --
-- de la fonction récursive --
----------------------------------
T : T_Tableau ;
Existe : T_Ptr_Bool ;
Indice : integer ;
begin
Init(T) ; --à vous d'initialiser ce tableau
Existe := new boolean ; --création et initialisation du pointeur
Existe.all := false ;
Indice := Dicho(T, 13, Existe, T'first, T'last) ; --on cherche le nombre 13 dans le tableau T
if Existe.all
then put("Le nombre 13 est à l'indice numero") ;
put(Indice) ;
else put("Le nombre 13 n'est pas présent dans le tableau") ;
end if ;
end Dichotomie ;
Dans le programme ci-dessus, on recherche le nombre 13 dans un tableau de 50 cases. La procédure d'initialisation n'est pas écrite, je vous laisse le faire (pensez que le tableau doit être ordonné !). Voici maintenant le code de la fonction Dicho() :
function Dicho(T : T_Tableau ;
N : integer ;
Existe : T_Ptr_Bool ;
Min, Max : integer) return integer is
Milieu : integer ;
begin
Milieu := (Min+Max) / 2 ;
if T(Milieu) = N --Cas où on trouve le nombre N cherché
then Existe.all := true ;
return Milieu ;
elsif Min = Max --Cas où l'on n'a pas trouvé N et où on ne peut plus continuer
then Existe.all := false ; --On indique que N n'existe pas et on renvoie 0.
return 0 ;
elsif T(Milieu) > N --Cas où on peut continuer avec un sous-tableau
then return Dicho(T,N,Existe,Min,Milieu-1) ;
else return Dicho(T,N,Existe,Milieu+1,Max) ;
end if ;
end Dicho ;
Nous avons cette fois réalisé un programme où l'utilisation de la récursivité est vraiment pertinente. À quoi reconnaît-on qu'un programme pourrait être traité de manière récursive ? Tout d'abord il faut avoir besoin de répéter certaines actions. La question est plutôt : pourquoi choisir un algorithme récursif plutôt que itératif ? La réponse est en grande partie dans la définition même de la récursivité. Il faut se trouver face à un problème qui ne se résolve qu'en réemployant les mêmes procédés sur un même objet. Les algorithmes récursifs nécessitent généralement de disjoindre deux cas : le cas simple, trivial et le cas complexe. Ce dernier peut être lui-même subdivisé en plusieurs autres cas (a<b et a>b ; n pair et n impair ...).
Rédiger une fonction récursive Factorielle( ) qui calcule ... la factorielle du nombre donné en argument. Pour exemple, la factorielle de 7 est donnée ainsi : . Ainsi, votre fonction Factorielle(7) renverra 5040.
Solution
function factorielle(n : integer) return integer is
begin
if n>0
then return n*factorielle(n-1) ;
else return 1 ;
end if ;
end factorielle ;
Alors pourquoi ces résultats ? C'est ce que l'on appelle l'overflow. Je vous ai souvent mis en garde : l'infini en informatique n'existe pas, les machines ont beau être ultra-puissantes, elles ont toujours une limite physique. Par exemple, les integer sont codés par le langage Ada sur 32 bits, c'est à dire que l'ordinateur ne peut retenir que des nombres formés de maximum 32 chiffres (ces chiffres n'étant que des 0 ou des 1, c'est ce que l'on appelle le code binaire, seul langage compréhensible par un ordinateur). Pour être plus précis même, le 1er chiffre (on dit le premier bit) correspond au signe : 0 pour positif et 1 pour négatif. Il ne reste donc plus que 31 bits pour coder le nombre. Le plus grand integer enregistrable est donc . Si jamais nous enregistrions un nombre plus grand encore, il nécessiterait plus de bits que l'ordinateur ne peut en fournir, c'est ce que l'on appelle un dépassement de capacité ou overflow. Du coup, le seul bit supplémentaire possible est celui du signe + ou -, ce qui explique les erreurs obtenues à partir de 17.
Exercice 2
Énoncé
Rédiger une fonction récursive Puissance(a,n) qui calcule la puissance n du nombre a (c'est à dire ), mais seulement en utilisant des multiplications.
Solution
function puissance(a,n : integer) return integer is
begin
if n > 0
then return a*puissance(a,n-1) ;
else return 1 ;
end if ;
end puissance ;
Exercice 3
Énoncé
Rédiger des fonction récursives Affichage( ) et Minimum( ). Chacune devra parcourir un tableau, soit pour l'afficher soit pour indiquer l'indice du plus petit élément du tableau.
Solution
type T_Tableau is array(1..10) of integer ;
Procedure Affichage(T : T_Tableau) is
procedure Afg(T : T_Tableau ; dbt : integer) is
begin
put(T(dbt),1) ; put(" ; ") ;
if dbt < T'last
then Afg(T,dbt+1) ;
end if ;
end Afg ;
begin
Afg(T,T'first) ;
end Affichage ;
function Minimum(T:T_Tableau) return integer is
function minimum(T:T_Tableau ; rang, res, min : integer) return integer is
--rang est l'indice que l'on va tester
--res est le résultat temporaire, l'emplacement du minimum trouvé jusque là
--min est le minimum trouvé jusque là
min2 : integer ;
res2 : integer ;
begin
if T(rang) < min
then min2 := T(rang) ;
res2 := rang ;
else min2 := min ;
res2 := res ;
end if ;
if rang = T'last
then return res2 ;
else return minimum(T,rang+1,res2,min2) ;
end if ;
end minimum ;
begin
return minimum(T,T'first+1,T'first,T(T'first)) ;
end Minimum ;
Exercice 4
Énoncé
Rédiger une fonction récursive Effectif(T,x) qui parcourt un tableau T à la recherche du nombre d'apparition de l'élément x. Ce nombre d'apparition est appelé effectif. En le divisant par le nombre total d'élément dans le tableau, on obtient la fréquence (exprimée en pourcentages si vous la multipliez par 100). Cela vous permettra ainsi de rédiger une seconde fonction appelée Fréquence(T,x). Le tableau T pourra contenir ce que vous souhaitez, il peut même s'agir d'un string.
Solution
function effectif(T: T_Tableau ; x : integer) return integer is
function effectif(T:T_Tableau ; x : integer ; rang, eff : integer) return integer is
eff2 : integer ;
begin
if T(rang) = x
then eff2 := eff +1 ;
else eff2 := eff ;
end if ;
if rang=T'last
then return eff2 ;
else return effectif(T,x,rang+1,eff2) ;
end if ;
end effectif ;
begin
return effectif(T,x,T'first,0) ;
end effectif ;
function frequence(T : T_Tableau ; x : integer) return float is
begin
return float(effectif(T,x))/float(T'length)*100.0 ;
end frequence ;
Bien, nous avons désormais terminé ce chapitre sur la récursivité. Mais comme je vous le disais en introduction, cette notion va nous être utile au prochain chapitre puisque nous allons aborder un nouveau type d'objet : les types abstraits de données. Ce chapitre fera appel aux pointeurs, aux types structurés et à la récursivité. Ce sera le dernier chapitre de cette partie et probablement le plus compliqué, donc si vous avez encore des difficultés avec l'une de ces trois notions, je vous invite à relire les chapitres précédents et à vous entraîner car les listes sont des objets un peu plus compliqués à manipuler.
J'espère que ce chapitre vous aura permis d'avoir une idée assez précise de ce qu'est la récursivité et de l'intérêt qu'elle peut représenter en algorithmique. Pour disposer d'un second point de vue, je vous conseille également la lecture du tutoriel de bluestorm disponible sur le site du zéro en cliquant ici. Toutefois, s'il est plus complet concernant la notion de récursivité, ce tutoriel n'est pas rédigé en Ada, vous devrez donc vous contenter de ses explications.
Dans ce chapitre, nous allons aborder un nouveau type d'objet : les Types Abstraits de Données, aussi appelés TAD. De quoi s'agit-il ? Eh bien pour le comprendre, il faut partir du problème qui amène à leur création. Nous avons vu au début de la partie III le type array. Les tableaux sont très pratiques mais ont un énorme inconvénient : il sont contraints. Leur taille est fixée au début du programme et ne peut plus bouger. Imaginons que nous réalisions un jeu d'aventure. Notre personnage découvre des trésors au fil de sa quête, qu'il ajoute à son coffre à trésor. Ce serait idiot de créer un objet coffre de type Tableau. S'il est prévu pour contenir 100 items et que l'on en découvre 101, il sera impossible d'enregistrer notre 101ème item dans le coffre ! Il serait judicieux que le coffre puisse contenir autant de trésors qu'on le souhaite.
Mais il existe bien des unbounded_strings ?!? Alors il y a peut-être des unbounded_array ?
Eh bien non, pas tout à fait. Nous allons donc devoir en créer nous mêmes, avec nos petits doigts : des "listes" d'éléments possiblement infinies. C'est ce que l'on appelle les TAD. Nous ferons un petit tour d'horizon théorique de ce que sont les Types Abstraits de Données. Puis nous créerons dans les parties suivantes quelques types abstraits avant de voir ce que le language Ada nous propose. Nous créerons également les outils minimums nécessaires à leur manipulation avant de voir un exemple d'utilisation.
Comme je viens de vous le dire, les Types Abstraits de Données peuvent s'imaginer comme des "listes" d'éléments. Les tableaux constituent un type possible de TAD. Mais ce qui nous intéresserait davantage, ce serait des "listes infinies". Commençons par faire un point sur le vocabulaire employé. Lorsque je parle de "liste", je commets un abus de langage. En effet, il existe plusieurs types abstraits, et les listes (je devrais parler plus exactement de "listes chaînées" par distinction avec les tableaux) ne constituent qu'un type abstrait parmi tant d'autres. Mais pour mieux comprendre ce que peut être un TAD, nous allons pour l'instant nous accommoder de cet abus (je mettrai donc le mot liste entre guillemets). Voici une représentation possible d'un Type Abstrait de Donnée :
"Liste" vide : un emplacement mémoire a été réquisitionné pour la liste, mais il ne contient rien.
"Liste" contenant un élément : le premier emplacement mémoire contient un nombre (ici 125) et pointe sur un second emplacement mémoire, encore vide pour l'instant.
"Liste" contenant 3 éléments : trois emplacements mémoires ont été réquisitionnés pour contenir des nombres qui se sont ajoutés les uns à la suite des autres. Chaque emplacement pointe ainsi sur le suivant. Le troisième pointe quant à lui sur un quatrième emplacement mémoire vide.
Autres cas
L'exemple ci-dessus est particulier, à plusieurs égards. Il n'existe pas qu'un seul type de "liste" (et je ne compte pas les traiter toutes). La "liste" vue précédemment dispose de certaines propriétés qu'il nous est possible de modifier pour en élaborer d'autres types.
Contraintes de longueur
La "liste" vue ci-dessus n'a pas de contrainte de longueur. On peut y ajouter autant d'éléments que la mémoire de l'ordinateur peut en contenir mais il est impossible d'obtenir le 25ème élément directement, il faut pour cela la parcourir à partir du début. Les tableaux sont quant à eux des listes contraintes et indexées de manière à accéder directement à tout élément, mais la taille est donc définie dès le départ et ne peut plus être modifiée par la suite. Mais vous aurez compris que dans ce chapitre, les tableaux et leurs contraintes de longueur ne nous intéressent guère.
Chaînage
Chaque élément pointe sur son successeur. On dit que la "liste" est simplement chaînée. Une variante serait que chaque élément pointe également sur son prédécesseur. On dit alors que la "liste" est doublement chaînée.
Linéarité
Chaque élément ne pointe que sur un seul autre élément. Il est possible de diversifier cela en permettant à chaque élément de pointer sur plusieurs autres (que ce soit un nombre fixe ou illimité d'éléments). On parlera alors d'arbre et non plus de "liste".
Méthode d'ajout
Chaque élément ajouté l'a été en fin de "liste". Cette méthode est dite FIFO pour First In/First Out, c'est à dire "premier arrivé, premier servi". Le second élément ajouté sera donc en deuxième position, le troisième élément en troisième position ... notre "liste" est ce que l'on appelle une file (en Français dans le texte). C'est ce qui se passe avec les imprimantes reliées à plusieurs PC : le premier à appuyer sur "Impression" aura la priorité sur tous les autres. Logique, me direz-vous.
Mais ce n'est pas obligatoirement le cas. La méthode "inverse" est dite LIFO pour "Last In/First Out", c'est à dire "dernier arrivé, premier servi". Le premier élément ajouté sera évidemment le premier de la "liste". Lorsque l'on ajoute un second élément, c'est lui qui devient le premier de la "liste" et l'ex-premier devient le second. Si on ajoute un troisième élément, il sera le premier de la "liste", l'ex-premier devient le second, l'ex-second (l'ex-ex-premier) devient le troisième ... on dira alors que notre "liste" est une pile. On peut se représenter la situation comme une pile d'assiette : la dernière que vous ajoutez devient la première de la pile. L'historique de navigation de votre navigateur internet agit tel une pile : lorsque vous cliquez sur précédent, la première page qui s'affichera sera la dernière à laquelle vous aviez accédé. La "liste" des modifications apportées à un document est également gérée telle une pile : cliquez sur Annuler et vous annulerez la dernière modification.
Cyclicité
Le dernier élément de notre liste ne pointe sur rien du tout ! Or nous pourrions faire en sorte qu'il pointe sur le premier élément. Il n'y a alors ni début, ni fin : notre liste est ce que l'on appelle un cycle.
Il est bien sûr possible de combiner différentes propriétés : arbres partiellement cycliques, cycles doublement chaînés ... pour élaborer de nouvelles structures.
Primitives
Mais un type abstrait de données se définit également par ses primitives. De quoi s'agit-il ? Les primitives sont simplement les fonctions essentielles s'appliquant à notre structure. Ainsi, pour une file, la fonction Ajouter_a_la_fin( ) constitue une primitive. Pour une pile, ce pourrait être une fonction Ajouter_sur_la_pile( ).
En revanche, une fonction Ranger_a_l_envers(p : pile ) ou Mettre_le_chantier(f : file) ou Reduire_le_nombre_de_branche(a:arbre) ne sont pas des primitives : ce ne sont pas des fonctions essentielles au fonctionnement et à l'utilisation de ces structures (même si ces fonctions ont tout à fait le droit d'exister).
Donc créer un TAD tel une pile, une file ... ce n'est pas seulement créer un nouveau type d'objet, c'est également fournir les primitives qui permettront au programmeur final de le créer, de le détruire, de le manipuler ... sans avoir besoin de connaître sa structure. C'est cet ensemble TAD-Primitives qui constitue ce que l'on appelle une Structure de données.
Mais alors, qu'est-ce que c'est exactement qu'une liste (sans les guillemets) ? :colere2: Tu nous a même parlé de liste chaînée : c'est quoi ?
Une liste chaînée est une structure de données (c'est à dire un type abstrait de données fourni avec des primitives) linéaire et non contrainte. Elle peut être cyclique ou non, simplement ou doublement chaînée. L'accès aux données doit pouvoir se faire librement (ni en FIFO, ni en LIFO) : il doit être possible d'ajouter/modifier/retirer n'importe quel élément sans avoir préalablement retiré ceux qui le précédaient ou le suivaient. Toutefois, il faudra très souvent parcourir la liste chaînée depuis le début avant de pouvoir effectuer un ajout, une modification ou une suppression.
Pour mieux comprendre, je vous propose de créer quelques types abstraits de données (que je nommerai désormais TAD, je sais je suis un peu fainéant :D ). Je vous propose de construire successivement une pile puis une file avant de nous pencher sur les listes chaînées. Cela ne couvrira sûrement pas tout le champ des TAD (ce cours n'y suffirait pas) mais devrait vous en donner une bonne idée et vous livrer des outils parmi les plus utiles à tout bon programmeur.
Nous allons tout d'abord créer un type T_Pile ainsi que les primitives associées. Pour faciliter la réutilisation de ce type d'objet, nous écrirons tout cela dans un package que nous appellerons P_Piles. Vous remarquerez les quelques subtilités d'écriture : P_Pile pour le package ; T_Pile pour le type ; Pile pour la variable. Ce package comportera donc le type T_Pile et les primitives. Nous ajouterons ensuite quelques procédures et fonctions utiles (mais qui ne sont pas des primitives).
Création du type T_Pile
Tout d'abord, rappelons succinctement ce que l'on entend par "pile". Une pile est un TAD linéaire, non cyclique, simplement chaîné et non contraint. Tout ajout/suppression se fait par la méthode LIFO : Last In, First Out ; c'est à dire que le programmeur final ne peut accéder qu'à l'élément placé sur le dessus de la pile. Alors, comment créer une liste infinie de valeurs liées les unes aux autres ? Nous avions dors et déjà approché cette idée lors du précédent chapitre sur les pointeurs. Il suffirait d'un pointeur pointant sur un pointeur pointant sur un pointeur pointant sur un pointeur ... Mais, premier souci, où et comment enregistre-t-on nos données s'il n'y a que des pointeurs ? Une idée ? Avec un type structuré bien sûr ! Schématiquement, nous aurions ceci :
DECLARATION DE MonType :
Valeur : integer, float ou que sais-je ;
Pointeur_vers_le_prochain : pointeur vers MonType ;
FIN DE DECLARATION
Nous pourrions également ajouter une troisième composante (appelée Index ou Indice) pour numéroter nos valeurs. Nous devrons également déclarer notre type de pointeur ainsi :
TYPE T_Pointeur IS ACCESS MonType ;
Sauf que, deuxième souci, si nous le déclarons après MonType, le compilateur va se demander à quoi correspond la composante Pointeur_vers_le_prochain. Et si nous déclarons T_Pointeur avant MonType, le compilateur ne comprendra pas vers quoi il est sensé pointé. :(
Comment résoudre ce dilemme ? C'est le problème de l’œuf et de la poule : qui doit apparaître en premier ? Réfléchissez. Là encore, vous connaissez la solution. Nous l'avons employée pour les packages : il suffit d'employer les prototypes ! Il suffit que nous déclarions MonType avec un prototype (pour rassurer le compilo :) ), puis le type T_Pointeur et enfin que nous déclarions vraiment MonType. Compris ? Alors voilà le code correspondant :
TYPE T_Cellule; --T_Cellule correspond à un élément de la pile
TYPE T_Pile IS ACCESS T_Cellule; --T_Pile correspond au pointeur sur un élément
TYPE T_Cellule IS
RECORD
Valeur : Integer; --Ici on va créer une pile d'entiers
Index : Integer; --Le dernier élément aura l'index N°1
Suivant : T_Pile ; --Le suivant correspond à une "sous-pile"
END RECORD;
Création des primitives
L'idée, en créant ce package, est de concevoir un type T_Pile et toutes les primitives nécessaires à son utilisation de sorte que tout programmeur utilisant ce package n'ait plus besoin de connaître la structure du type T_Pile : il doit tout pouvoir faire avec les primitives fournies sans avoir à mettre les mains dans le cambouis (Nous verrons plus tard comment lui interdire tout accès à ce "cambouis" avec la privatisation de nos packages). De quelles primitives a-t-on alors besoin ? En voici une liste avec le terme Anglais généralement utilisé et une petite explication :
Empiler (Push) : ajoute un élément sur le dessus de la pile. Cet élément devient alors le premier et son indice (composante Index) est supérieur d'une unité à "l'ex-premier" élément.
Dépiler (Pop) : retire le premier élément de la pile, la première cellule. Cette fonction renvoie en résultat la valeur de cette cellule.
Pile_Vide (Empty) : renvoie true si la pile est vide (c'est à dire si pile = null). Primitive importante car il est impossible de dépiler une pile vide.
Longueur (Length) : renvoie la longueur de la pile, c'est à dire le nombre de cellules qu'elle contient.
Premier (First) : renvoie la valeur de la première cellule de la pile sans la dépiler.
Bien, il ne nous reste plus qu'à créer ces primitives. Commençons par la procédure Push(P,n). Elle va recevoir une pile P, qui n'est rien d'autre qu'un pointeur vers la cellule située sur le dessus de la pile. P sera en mode in out. Elle recevra également un Integer n (puisque nous avons choisi les Integer, mais nous pourrions tout aussi bien le faire avec des float ou autre chose). Elle va devoir créer une cellule (et donc un index), la faire pointer sur la cellule située sur le dessus de la pile avant d'être elle-même pointée par P. Compris ? Alors allez-y !
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) IS
Cell : T_Cellule;
BEGIN
Cell.Valeur := N ;
IF P /= NULL
THEN Cell.Index := P.All.Index + 1 ;
Cell.Suivant := P.All'ACCESS ;
ELSE Cell.Index := 1 ;
END IF ;
P := NEW T_Cellule'(Cell) ;
END Push ;
Votre procédure Push() est créée ? Enregistrez votre package et créez un programme afin de le tester. Exemple :
with ada.Text_IO, Ada.Integer_Text_IO, P_Pile ;
use ada.Text_IO, Ada.Integer_Text_IO, P_Pile ;
Procedure test is
P : T_Pile ;
BEGIN
Push(P,3) ; Push(P,5) ; Push(P,1) ; Push(P,13) ;
Put(P.all.Index) ; Put(P.all.Valeur) ; new_line ;
Put(P.Suivant.Index) ; Put(P.Suivant.Valeur) ; new_line ;
Put(P.Suivant.suivant.Index) ; Put(P.Suivant.suivant.Valeur) ; new_line ;
Put(P.suivant.suivant.suivant.Index) ; Put(P.Suivant.Suivant.Suivant.Valeur) ;
end Test ;
Maintenant, la procédure Pop(P,N). Je ne reviens pas sur les paramètres ou sur le sens de cette fonction, j'en ai déjà parlé. Je vous rappelle toutefois que cette procédure doit retourner, non pas un objet de type T_Cellule, mais une variable de type Integer, et "rétrécir" la pile. Les paramètres devront donc être en mode OUT (voire IN OUT). Dernier point, si la pile est vide, le programmeur final ne devrait pas la dépiler, mais il lui revient de le vérifier à l'aide de la primitive Empty : ce n'est pas le rôle de nos primitives de gérer les éventuelles bêtises du programmeur final. En revanche, c'est à vous de gérer le cas où la pile ne contiendrait qu'une seule valeur et deviendrait vide dans le code de votre primitive.
PROCEDURE pop(P : IN OUT T_Pile ; N : OUT Integer) IS
BEGIN
N := P.all.valeur ; --ou P.valeur
--P.all est censé exister, ce sera au programmeur final de le vérifier
IF P.all.suivant /= NULL
THEN P := P.suivant ;
ELSE P := null ;
END IF ;
END Pop ;
Maintenant que vos deux procédures principales sont créées (je vous laisse le soin de les tester) nous n'avons plus que trois primitives (assez simples) à coder : Empty( ), First( ) et Length( ). Toutes trois sont des fonctions ne prenant qu'un seul paramètre : une pile P. Elles retourneront respectivement un booléen pour la première et un integer pour les deux suivantes. Je vous écris ci-dessous le code source de P_Pile.adb et P_Pile.ads. Merci qui ?
P_Pile.adb :
PACKAGE BODY P_Pile IS
PROCEDURE Push (
P : IN OUT T_Pile;
N : IN Integer) IS
Cell : T_Cellule;
BEGIN
Cell.Valeur := N ;
IF P /= NULL
THEN
Cell.Index := P.All.Index + 1 ;
Cell.Suivant := P.All'ACCESS ;
ELSE
Cell.Index := 1 ;
END IF ;
P := NEW T_Cellule'(Cell) ;
END Push ;
PROCEDURE Pop (
P : IN OUT T_Pile;
N : OUT Integer) IS
BEGIN
N := P.All.Valeur ; --ou P.valeur
--P.all est censé exister, ce sera au programmeur final de le vérifier
IF P.All.Suivant /= NULL
THEN
P := P.Suivant ;
ELSE
P := NULL ;
END IF ;
END Pop ;
FUNCTION Empty (
P : IN T_Pile)
RETURN Boolean IS
BEGIN
IF P=NULL
THEN
RETURN True ;
ELSE
RETURN False ;
END IF ;
END Empty ;
FUNCTION Length(P : T_Pile) RETURN Integer IS
BEGIN
IF P = NULL
THEN RETURN 0 ;
ELSE RETURN P.Index ;
END IF ;
END Length ;
FUNCTION First(P : T_Pile) RETURN Integer IS
BEGIN
RETURN P.Valeur ;
END First ;
END P_Pile;
P_Pile.ads :
PACKAGE P_Pile IS
TYPE T_Cellule; --T_Cellule correspondant à un élément de la pile
TYPE T_Pile IS ACCESS ALL T_Cellule;--T_Pile correspondant au pointeur sur un élément
TYPE T_Cellule IS
RECORD
Valeur : Integer; --On crée une pile d'entiers
Index : Integer;
Suivant : T_Pile; --Le suivant correspond à une "sous-pile"
END RECORD;
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
END P_Pile;
Jouons avec le package P_Pile
Notre package est enfin fini. Notre TAD est prêt à l'emploi et j'impose maintenant une règle : interdiction de manipuler nos piles autrement qu'à l'aide de nos 5 primitives ! Donc, plus de P.valeur, seulement des First(P) ! Plus de P.suivant, il faudra faire avec Pop(P) ! Cela va quelque peu compliquer les choses mais nous permettra de comprendre comment se manipulent les TAD sans pour autant partir dans des programmes de 300 lignes. L'objectif avec notre type T_Pile, sera de créer une procédure Put(p : T_Pile) qui se charge d'afficher une pile sous forme de colonne. Attention, le but de ce cours n'est pas de créer toutes les fonctions ou procédures utiles à tous les TAD. Il serait par exemple intéressant de créer une procédure ou une fonction get(P). Mais nous n'allons nous concentrer que sur une seule procédure à chaque fois. Libre à vous de combler les manques.
Concernant notre procédure Put(P), deux possibilités s'offrent à nous : soit nous employons une boucle itérative (loop, for, while), soit nous employons une boucle récursive. Vous allez vous rendre compte que la récursivité sied parfaitement aux TAD (ce sera donc ma première solution), mais je vous proposerai également deux autres façons de procéder (avec une boucle for et une boucle while). Voici le premier code, avec la méthode récursive :
procedure Put(P : T_Pile) is
Pile : T_Pile := P ;
N : integer ;
begin
if not Empty(Pile)
then pop(Pile, N) ;
Put(N) ;
new_line ;
Put(Pile) ;
end if ;
end Put ;
Regardons un peu ce code. Tout d'abord, c'est un code que j'aurais tout à fait pu vous proposer avant le chapitre sur les pointeurs : qui peut deviner en voyant ces lignes comment est constitué le type T_Pile ? Personne, car nous avons fourni tous les moyens pour ne pas avoir besoin de le savoir (c'est ce que l'on appelle l'encapsulation, encore une notion que nous verrons dans la partie IV). Que fait donc ce code ? Tout d'abord il teste si la pile est vide ou non. Ce sera toujours le cas. Si elle est vide, c'est fini ; sinon, on dépile la pile afin de pouvoir afficher son premier élément puis on demande d'afficher la nouvelle pile, privée de sa première cellule. J'aurais pu également écrire Put(First(Pile)) avant de dépiler, mais cela m'aurait contraint à manipuler deux fois la pile sans pour autant économiser de variable.
D'ailleurs, tu aurais aussi pu économiser un objet ! Ton objet Pile n'a aucun intérêt, il suffit de dépiler P et d'afficher P !
Non ! Surtout pas ! Tout d'abord, je vous rappelle que P est obligatoirement en mode IN puisqu'il est transmis à une fonction (Empty). Or, la procédure pop( ) a besoin d'un paramètre en mode OUT pour pouvoir dépiler. Il y aurait un conflit. Ensuite, en supposant que le compilateur ne bronche pas, que deviendrait P après son affichage ? Eh bien P serait vide, on aurait perdu toutes les valeurs qui la composait, simplement pour un affichage. C'est pourquoi j'ai créé un objet Pile qui sert ainsi de "roue de secours". Voici maintenant une solution itérative :
while not Empty(Pile) loop
put(First(P)) ;
pop(Pile, N) ;
new_line ;
end loop ;
On répète ainsi les opérations tant que la liste n'est pas vide : afficher le premier élément, dépiler. Enfin, voici une seconde solution itérative (dernière solution proposée) :
for i in 1..Length(P) loop
put(first(Pile)) ;
pop(Pile,N) ;
new_line ;
end loop ;
Ce qui est utilisé ici, ce n'est pas le fait que la liste soit vide, mais le fait que sa longueur soit nulle. Les opérations sont toutefois toujours les mêmes.
Deuxième exemple, les files. Nous allons donc créer un nouveau package P_File. La différence avec la pile ne se fait pas au niveau de l'implémentation. Les files restent linéaires, non cycliques, simplement chaînées et non contraintes.
TYPE T_Cellule;
TYPE T_File IS ACCESS ALL T_Cellule;
TYPE T_Cellule IS
RECORD
Valeur : Integer;
Index : Integer;
Suivant : T_File;
END RECORD;
La différence se fait donc au niveau des primitives puisque c'est la "méthode d'ajout" qui diffère. Les files sont gérées en FIFO : first in, first out. Imaginez pour cela une file d'attente à une caisse : tout nouveau client (une cellule) doit se placer à la fin de la file, la caissière (le programmeur final ou le programme) ne peut traiter que le client en début de file, les autres devant attendre leur tour. Alors de quelles primitives a-t-on besoin ?
Enfiler (Enqueue) : ajoute un élément à la fin de la file. Son indice est donc supérieur d'une unité à l'ancien dernier élément.
Défiler (Dequeue) : renvoie le premier élément de la file et le retire. Cela implique de renuméroter toute la file.
File_Vide (Empty) ; Longueur (Length) ; Premier (First) : même sens et même signification que pour les piles.
Notre travail consistera donc à modifier notre package P_Pile en conséquence. Attention à ne pas aller trop vite ! Les changements, même s'ils semblent a priori mineurs, ne portent pas seulement sur les noms des primitives. L'ajout d'une cellule notamment, n'est plus aussi simple qu'auparavant. Ce travail étant relativement simple (pour peu que vous le preniez au sérieux), il est impératif que vous le fassiez par vous-même ! Cela constituera un excellent exercice sur les pointeurs et la récursivité. Ne consultez mon code qu'à titre de correction. C'est important avant d'attaquer des TAD plus complexes.
PACKAGE BODY P_File IS
PROCEDURE Enqueue (F : IN OUT T_File ; N : IN Integer) IS
Cell : T_Cellule;
BEGIN
Cell.Valeur := N ;
Cell.Suivant := NULL ;
IF F = NULL --Cas où la liste est vide
THEN Cell.Index := 1 ;
F := NEW T_Cellule'(Cell) ;
ELSIF F.Suivant = NULL --Cas où l'on se "situe" sur le dernier élément
THEN Cell.Index := F.Index + 1 ;
F.Suivant := NEW T_Cellule'(Cell) ;
ELSE Enqueue(F.Suivant, N) ; --Cas où l'on n'est toujours pas à la fin de la file
END IF ;
END Enqueue;
PROCEDURE Dequeue (F : IN OUT T_File ; N : OUT Integer) IS
procedure Decrement(F : IN T_File) is
begin
if F /= null
then F.index := F.index - 1 ;
Decrement(F.suivant) ;
end if ;
end Decrement ;
BEGIN
N := F.Valeur ; --F.all est censé exister, ce sera au Programmeur final de le vérifier
IF F.Suivant /= NULL
THEN decrement(F) ; -- !!! Il faut décrémenter les indices !!!
F := F.Suivant ;
ELSE F := NULL ;
END IF ;
END Dequeue;
FUNCTION Empty (F : IN T_File) RETURN Boolean IS
BEGIN
IF F=NULL
THEN RETURN True ;
ELSE RETURN False ;
END IF ;
END Empty ;
FUNCTION Length (F : T_File) RETURN Integer IS
BEGIN
IF F = NULL
THEN RETURN 0 ;
ELSIF F.Suivant = NULL
THEN RETURN F.Index ;
ELSE RETURN Length(F.Suivant) ;
END IF ;
END Length ;
FUNCTION First ( F : T_File) RETURN Integer IS
BEGIN
RETURN F.Valeur ;
END First ;
END P_File;
PACKAGE P_Pile IS
TYPE T_Cellule; --T_Cellule correspondant à un élément de la pile
TYPE T_Pile IS ACCESS ALL T_Cellule;--T_Pile correspondant au pointeur sur un élément
TYPE T_Cellule IS
RECORD
Valeur : Integer; --On crée une pile d'entiers
Index : Integer;
Suivant : T_Pile; --Le suivant correspond à une "sous-pile"
END RECORD;
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
END P_Pile;
Amusons-nous encore
Comme promis, nous allons désormais tester notre structure de données. Mais hors de question de se limiter à refaire une procédure Put( ) ! Ce serait trop simple. Cette fois nous allons également créer une fonction de concaténation !
Rooh ! Encore de la théorie ! Il a pas fini avec ses termes compliqués ? :waw:
Pas d'emballement ! La concaténation est une chose toute simple ! Cela consiste juste à mettre bout à bout deux listes pour en faire une plus grande ! Le symbole régulièrement utilisé en Ada (et dans de nombreux langages) est le symbole & (le ET commercial, aussi appelé esperluette). Donc à vous de créer cette fonction de sorte que l'on puisse écrire : File1 := File2 & File 3 ! N'oubliez pas auparavant de créer une procédure put( ) pour contrôler vos résultats et prenez garde que l'affichage d'une file ne la défile pas définitivement !
procedure Put(F : in out T_File) is
N : integer ;
begin
for i in 1..length(F) loop
dequeue(F,N) ;
put(N) ;
enqueue(F,N) ; --on n'oublie pas de réenfiler l'élement N pour ne pas vider notre file !
end loop ;
end Put ;
function"&"(left,right : in T_File) return T_File is
N : integer ;
L : T_File := Left ;
R : T_File := Right ;
res : T_File ;
begin
for i in 1..length(left) loop --on place les éléments de la file de gauche dans la file résultat
dequeue(L,N) ;
enqueue(res,N) ;
enqueue(L,N) ;
end loop ;
for i in 1..length(right) loop --puis on place ceux de la file de droite dans la file résultat
dequeue(R,N) ;
enqueue(res,N) ;
enqueue(R,N) ;
end loop ;
return res ;
end ;
Explication : si vous avez une liste (3;6;9) et que vous employez un algorithme récursif vous allez d'abord défiler le 3 pour l'afficher et avant de le renfiler, vous allez relancer votre algorithme, gardant le 3 en mémoire. Donc vous défiler le 6 pour l'afficher et avant de le renfiler, vous allez relancer votre algorithme, gardant le 6 en mémoire. Enfin, vous défiler le 9 pour l'afficher, la liste étant vide désormais vous réenfiler le 9, puis le 6, puis le 3. Au final, un simple affichage fait que vous vous retrouvez non plus avec une liste (3;6;9) mais (9;6;3). o_O Ce problème peut être résolu en employant un sous-programme qui inversera la file, mais cette façon de procéder vous semble-t-elle naturelle ? Pas à moi toujours. ;)
Comme vous vous en êtes sûrement rendu compte en testant vos fonctions et procédures, l'utilisation des files, si elle semble similaire à celle des piles, est en réalité fort différente. Chacun de ces TAD a ses avantages et inconvénients. Mais le principal défaut de ces TAD est d'être obligé de défiler/dépiler les éléments les uns après les autres pour pouvoir les traiter, ce qui oblige à les rempiler/renfiler par la suite avec tous les risques que cela implique quant à l'ordre des éléments. Notre troisième TAD va donc régler ce souci puisque nous allons traiter des listes chaînées (et ce sera le dernier TAD linéaire que nous traiterons).
Comme dit précédemment, les listes chaînées sont linéaires, doublement chaînées, non cycliques et non contraintes. Qui plus est, elles pourront être traitées en LIFO (comme une pile) ou en FIFO (comme une file) mais il sera également possible d'insérer un élément au beau "milieu" de la liste. Pour cela, il devra être possible de parcourir la liste sans la "démonter" comme nous le faisions avec les piles ou les files.
Encore un nouveau package ? Je commence à me lasser, moi :o
Heureusement pour vous, le langage Ada intègre, depuis la norme 2005, de nouveaux packages appelés Ada.Containers et qui nous fournissent quelques TAD comme les tables de hachage (que nous verrons bien plus tard) mais surtout les Doubly_Linked_List (listes doublement chaînées) et les Vectors (vecteurs). Ces deux derniers types sont relativement similaires et correspondent aux listes chaînées. Leur différence ? Les Vectors se comportent un peu à la manière des tableaux, chaque vector étant indexé (en général, indexé avec des entiers naturels commençant à 0 ou 1) de sorte qu'il suffit de disposer du numéro d'indice pour accéder à l'élément voulu, alors que les Doubly_Linked_Lists n'utilisent pas d'indices mais un curseur qui pointe sur un élément de la liste et que l'on peut déplacer vers le début ou la fin de la liste.
Le package Ada.Containers.Doubly_Linked_Lists
Mise en place
Commençons par évoquer le type List. Il est accesible via le package Ada.Containers.Doubly_Linked_Lists. Pour lire les spécifications de ce package, il vous suffit d'ouvrir le fichier appelé a-cdlili.ads situé dans le répertoire d'installation de GNAT. Vous trouverez normalement ce répertoire à l'adresse C:\GNAT sous Windows. Il faudra ensuite ouvrir les dossiers 2011\lib\gcc\i686-pc-mingw32\4.5.3\adainclude (ou quelque chose de ce style, les dénominations pouvant varier d'une version à l'autre).
Comme le package Ada.Numerics.Discrete_Random qui nous servait à générer des nombres aléatoires, le package Ada.Containers.Doubly_Linked_Lists est un package générique (nous verrons bientôt la généricité, patience), fait pour n'importe quel type de donnée et nous ne pouvons donc pas l'utiliser en l'état. Nous devons tout d'abord l'instancier, c'est à dire créer un sous-package prévu pour le type de données désiré. Exemple en image :
with Ada.Containers.Doubly_Linked_Lists ;
...
type T_Score is record
name : string(1..3) := " ";
value : natural := 0 ;
end record ;
package P_Lists is new Ada.Containers.Doubly_Linked_Lists(T_Score) ;
use P_Lists ;
L : List ;
C : Cursor ;
Primitives
Nous avons ainsi créé un package P_Lists nous permettant d'utiliser des listes chaînées contenant des éléments de type T_Score. Une liste chaînée est de type List (sans S à la fin !). Nous disposons des primitives suivantes pour comparer deux listes, connaître la longueur d'une liste, savoir si elle est vide, la vider, ajouter un élément au début (Prepend) ou l'ajouter à la fin (Append) :
function "=" (Left, Right : List) return Boolean; --comparaison de deux listes
function Length (Container : List) return Count_Type; --longueur de la liste
function Is_Empty (Container : List) return Boolean; --la liste est-elle vide ?
procedure Clear (Container : in out List); --vide la liste
procedure Prepend --ajoute un élément en début de liste
(Container : in out List;
New_Item : Element_Type;
Count : Count_Type := 1);
procedure Append --ajoute un élément en fin de liste
(Container : in out List;
New_Item : Element_Type;
Count : Count_Type := 1);
De même, il est possible de connaître le premier ou le dernier élément (sans le "délister"), de le supprimer, de savoir si la liste contient un certain élément ou pas ou encore d'inverser la liste à l'aide des primitives suivante :
function First_Element (Container : List) return Element_Type; --renvoie le premier élément
function Last_Element (Container : List) return Element_Type; --renvoie le dernier élément
procedure Delete_First --supprime le premier élément
(Container : in out List;
Count : Count_Type := 1);
procedure Delete_Last --supprime le dernier élément
(Container : in out List;
Count : Count_Type := 1);
function Contains --indique si la liste contient cet élément
(Container : List;
Item : Element_Type) return Boolean;
procedure Reverse_Elements (Container : in out List); --renverse la liste
Bon d'accord, L est une liste chaînée, mais que vient faire C ici ? C'est quoi ce cursor ? o_O
Ce curseur est là pour nous situer sur la liste, pour pointer un élément. Nous ne pouvons travailler seulement avec le premier et le dernier élément. Supposons que nous ayons la liste suivante :
Doubly_Linked_List de scores
Le curseur indique le second élément de la liste. Dès lors, nous pouvons lire cet élément, le modifier, insérer un nouvel élément juste avant lui, le supprimer ou bien l'échanger avec un élément pointé par un second curseur avec les primitives suivantes :
function Element (Position : Cursor) return Element_Type; --renvoie l'élément pointé
procedure Replace_Element --modifie l'élément pointé
(Container : in out List;
Position : Cursor;
New_Item : Element_Type);
procedure Insert --insère un élément devant l'élément pointé
(Container : in out List;
Before : Cursor;
New_Item : Element_Type;
Count : Count_Type := 1);
procedure Delete --supprime l'élément pointé
(Container : in out List;
Position : in out Cursor;
Count : Count_Type := 1);
procedure Swap --échange deux éléments pointés
(Container : in out List;
I, J : Cursor);
Ce curseur peut être placé au début, à la fin de la liste ou être déplacé élément après élément.
function First (Container : List) return Cursor; --place le curseur au début
function Last (Container : List) return Cursor; --place le curseur à la fin
function Next (Position : Cursor) return Cursor; --déplace le curseur sur l'élément suivant
procedure Next (Position : in out Cursor);
function Previous (Position : Cursor) return Cursor; --déplace le curseur sur l'élément précédent
procedure Previous (Position : in out Cursor);
Enfin, il est possible d'appliquer une procédure à tous les éléments d'une liste en utilisant un pointeur sur procédure avec procedure Iterate(Container : List; Process : not null access procedure (Position : Cursor));
Une application
Nous allons créer un programme créant une liste de 5 scores et les affichant. Je vais vous proposer deux procédures d'affichage distinctes. Mais tout d'abord, créons notre liste :
Vous avez remarqué, j'ai créé la même liste que tout à l'heure, avec la procédure Append. Une autre façon de procéder, mais avec la procédure Prepend donnerait
Enfin, voici une première façon, laborieuse d'afficher les éléments de la liste :
procedure put(score : T_SCore) is
begin
Score := Element(C) ;
put_line(Score.name & " a obtenu " & integer'image(Score.value) & " points.") ;
end put ;
...
begin
C := first(L) ;
for i in 1..length(L)-1 loop
put(Element(c)) ;
next(c) ;
end loop ;
put(Element(c)) ;
end ;
Cette première façon utilise le curseur et passe en revue chacun des éléments les uns après les autres. Attention toutefois au cas du dernier élément qui n'a pas de successeur ! A noter également qu'une procédure récursive aurait aussi bien pu faire l'affaire. Enfin, voici une seconde façon de procéder utilisant les pointeurs sur procédure cette fois :
procedure put(C : Cursor) is
score : T_SCore;
begin
Score := Element(C) ;
put_line(Score.name & " a obtenu " & integer'image(Score.value) & " points.") ;
end put ;
...
begin
iterate(L,Put'access) ;
end ;
En utilisant la procédure iterate, nous nous épargnons ici un temps considérable. Cela justifie amplement les efforts que vous avez fourni pour comprendre ce qu'étaient les pointeurs sur procédure.
Le package Ada.Containers.Vectors
Mise en place
Évoquons maintenant le type vector. Il est accesible via le package Ada.Containers.Vectors. Pour lire les spécifications de ce package, il vous suffit d'ouvrir le fichier appelé a-convec.ads. Encore une fois, ce package doit être instancié de la manière suivante :
with Ada.Containers.Vectors ;
...
package P_Vectors is new Ada.Containers.Vectors(Positive,T_Score) ;
use P_Vectors ;
V : Vector ;
Nous créons ainsi un package P_Vectors indexé à l'aide du type Positive (nombre entiers strictement positifs) et contenant des éléments de type T_Score. Nous aurions pu utiliser le type Natural pour l'indexation, mais le type Positive nous garantit que le premier élément du Vector V sera le numéro 1 et non le numéro 0.
Primitives
Les primitives disponibles avec les Doubly_Linked_Lists sont également disponibles pour les Vectors :
overriding function "=" (Left, Right : Vector) return Boolean; --test d'égalité entre deux vectors
function Length (Container : Vector) return Count_Type; --renvoie la longueur du vector
function Is_Empty (Container : Vector) return Boolean; --renvoie true si le vector est vide
procedure Clear (Container : in out Vector); --vide le vector
procedure Prepend --ajoute un élément au début du vector
(Container : in out Vector;
New_Item : Vector);
procedure Append --ajoute un élément à la fin du vector
(Container : in out Vector;
New_Item : Vector);
function First_Element (Container : Vector) return Element_Type; --renvoie la valeur du premier élément du vector
function Last_Element (Container : Vector) return Element_Type; --renvoie la valeur du premier élément du vector
procedure Delete_First --supprimer le premier élément du vector
(Container : in out Vector;
Count : Count_Type := 1);
procedure Delete_Last --supprime le dernier élément du vector
(Container : in out Vector;
Count : Count_Type := 1);
function Contains --indique si un élément est présent dans le vector
(Container : Vector;
Item : Element_Type) return Boolean;
procedure Reverse_Elements (Container : in out Vector); --renverse l'ordre des éléments du vector
D'autres primitives font appel à un curseur, mais je n'y ferai pas référence (vous pouvez les découvrir par vous même). Mais elles ont en général leur équivalent, sans emploi du curseur mais avec un indice.
function Element --renvoie la valeur de l'élément situé à l'indice spécifié
(Container : Vector;
Index : Index_Type) return Element_Type;
procedure Replace_Element --supprime l'élément situé à l'indice spécifié
(Container : in out Vector;
Index : Index_Type;
New_Item : Element_Type);
procedure Insert --insère un nouvel élément avant l'indice spécifié
(Container : in out Vector;
Before : Extended_Index;
New_Item : Element_Type;
Count : Count_Type := 1);
procedure Delete --supprime l'élément situé à l'indice spécifié
(Container : in out Vector;
Index : Extended_Index;
Count : Count_Type := 1);
procedure Swap (Container : in out Vector; I, J : Index_Type); --échange deux éléments
function First_Index (Container : Vector) return Index_Type; --renvoie l'indice du premier élément
function Last_Index (Container : Vector) return Extended_Index; --renvoie l'indice du dernier élément
procedure Iterate --applique la procédure Process à tous les éléments du Vector
(Container : Vector;
Process : not null access procedure (Position : Cursor));
A ces primitives similaires à celles des listes doublement chaînées, il faut encore en ajouter quelques autres :
--Fonctions de concaténation
function "&" (Left, Right : Vector) return Vector;
function "&" (Left : Vector; Right : Element_Type) return Vector;
function "&" (Left : Element_Type; Right : Vector) return Vector;
function "&" (Left, Right : Element_Type) return Vector;
procedure Set_Length --crée un vecteur de longueur donnée
(Container : in out Vector;
Length : Count_Type);
procedure Insert_Space --insère un élément vide avant l'indice spécifié
(Container : in out Vector;
Before : Extended_Index;
Count : Count_Type := 1);
function Find_Index --trouve l'indice d'un élément dans un tableau
(Container : Vector;
Item : Element_Type;
Index : Index_Type := Index_Type'First) return Extended_Index;
Bien sûr, je ne vous ai pas dressé la liste de toutes les fonctions et procédures disponibles, mais vous avez ainsi les principales. A savoir : le type Element_type correspond au type avec lequel vous aurez instancié votre package. De plus, le type Count est une sorte de type integer.
Nous en avons fini avec ce cours semi-théorique, semi-pratique. Nous n'avons bien sûr pas fait le tour de tous les TAD, mais il ne vous est pas interdit (bien au contraire) de développer vos propres types comme des arbres ou des cycles. Cela constitue un excellent exercice d'entraînement à l'algorithmique et à la programmation, vous pousse à manipuler les pointeurs et à user de programmes récursifs.
Nous allons dans le prochain chapitre utiliser ces TAD au travers d'un TP.
La troisième partie se termine ("Enfin !" diront certains) et nous allons donc la conclure comme il se doit par un troisième TP ! Après avoir hésité entre la conception de divers programmes, tel un éditeur de carte ou un éditeur de texte, je me suis dit qu'après le difficile TP n°2 et cette longue partie III, vous aviez bien mérité un TP moins décourageant et plus ludique. C'est pourquoi, après de longues réflexions, j'ai opté pour un jeu : le jeu du Serpent. Vous savez ce vieux jeu que l'on avait sur les vieux portables où un serpent devait manger sans cesse de gros pixels afin de grandir en prenant garde de ne jamais dévorer sa propre queue ou de sortir de l'écran.
Comme d'habitude, je vais vous guider dans sa mise en œuvre, et comme d'habitude tout se fera en console mais ... avec des couleurs ! Prêts ? Voici une image pour vous mettre en bouche :
Comme toujours, avant de nous lancer à l'aveuglette, nous devons définir les fonctionnalités de notre programme, les limites du projet. Il n'est pas question de créer un jeu en 3D ou avec des boutons, des images, une base de données ... nous allons faire plus sobre. Notre programme devra :
s'exécuter en console, je vous l'ai dit. Toutefois, nous ferons en sorte d'afficher quelques couleurs pour égayer tout ça et surtout rendre notre programme facilement jouable. Rassurez-vous, je vous fournirais un package pour cela.
se jouer en temps réel, pas au tour par tour ! Si le joueur ne touche pas au clavier alors son serpent ira droit dans le mur.
gérer et donc éviter les bogues : serpent faisant demi-tour sur lui-même, sortant de la carte ou dont le corps ne suivrait pas la tête dans certaines configurations (je ne rigole pas, vous commettrez sûrement ce genre d'erreur).
permettre au joueur de diriger le serpent au clavier à l'aide des touches fléchées.
Organisation des types et variables
Nous ne savons pas quand le joueur perdra, notre serpent devra donc pouvoir s'allonger indéfiniment (en théorie). Il serait donc judicieux d'utiliser les TAD vus précédemment pour enregitrer les différents anneaux de notre reptile : il sera plus aisé d'agrandir notre serpent à l'aide des primitives append ou prepend qu'en déclarant des tableaux ou je ne sais quoi d'autre. De même, déplacer le serpent reviendra simplement à retirer le dernier anneau de son corps pour le placer en premier dans une nouvelle position. Vous avez le choix entre tous les TAD que vous voulez, mais les Doubly_Linked_Lists ou les Vectors sont les mieux adaptés et comme j'ai une préférence pour le type Vector, la solution que je vous fournirai utilise donc ... les Doubly_Linked_Lists (cherchez la cohérence :p ).
Mais que contiendra notre liste ? Elle contiendra toute une suite de coordonnées : les coordonnées des différentes parties du corps du serpent. Mais ce n'est pas tout ! Le serpent ne peut se limiter à une liste de coordonnées, il faudra également que notre type T_Serpent contienne la direction de la tête du serpent.
Enfin, la taille de l'aire de jeu, la vitesse de déplacement du serpent ou les couleurs utilisées devraient être enregistrées dans des variables (ou des constantes si besoin) toutes inventoriées dans un package. En faisant cela, ces variables deviendront des variables globales, ce qui est généralement risqué mais clarifiera notre code et simplifiera toute modification des paramètres du jeu. Nous reviendrons sur les variables globales dans la prochaine partie.
Depuis le début je vous dis que notre programme sera en couleur, donc il est temps de vous fournir le package nécessaire pour utiliser des couleurs dans la console. Il ne s'agit ni d'un package officiel, ni d'un package de mon crû (mea maxima culpa :( ) mais d'un vieux package mis à notre disposition par Jerry van Dijk et libre de diffusion, appelé NT_Console :
-----------------------------------------------------------------------
--
-- File: nt_console.adb
-- Description: Win95/NT console support
-- Rev: 0.3
-- Date: 08-june-1999
-- Author: Jerry van Dijk
-- Mail: [email protected]
--
-- Copyright (c) Jerry van Dijk, 1997, 1998, 1999
-- Billie Holidaystraat 28
-- 2324 LK LEIDEN
-- THE NETHERLANDS
-- tel int + 31 71 531 43 65
--
-- Permission granted to use for any purpose, provided this copyright
-- remains attached and unmodified.
--
-- THIS SOFTWARE IS PROVIDED ``AS IS'' AND WITHOUT ANY EXPRESS OR
-- IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED
-- WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
--
-----------------------------------------------------------------------
pragma C_Pass_By_Copy (128);
with Interfaces; use Interfaces;
package body NT_Console is
pragma Linker_Options ("-luser32");
---------------------
-- WIN32 INTERFACE --
---------------------
Beep_Error : exception;
Fill_Char_Error : exception;
Cursor_Get_Error : exception;
Cursor_Set_Error : exception;
Cursor_Pos_Error : exception;
Buffer_Info_Error : exception;
Set_Attribute_Error : exception;
Invalid_Handle_Error : exception;
Fill_Attribute_Error : exception;
Cursor_Position_Error : exception;
subtype DWORD is Unsigned_32;
subtype HANDLE is Unsigned_32;
subtype WORD is Unsigned_16;
subtype SHORT is Short_Integer;
subtype WINBOOL is Integer;
type LPDWORD is access all DWORD;
pragma Convention (C, LPDWORD);
type Nibble is mod 2 ** 4;
for Nibble'Size use 4;
type Attribute is
record
Foreground : Nibble;
Background : Nibble;
Reserved : Unsigned_8 := 0;
end record;
for Attribute use
record
Foreground at 0 range 0 .. 3;
Background at 0 range 4 .. 7;
Reserved at 1 range 0 .. 7;
end record;
for Attribute'Size use 16;
pragma Convention (C, Attribute);
type COORD is
record
X : SHORT;
Y : SHORT;
end record;
pragma Convention (C, COORD);
type SMALL_RECT is
record
Left : SHORT;
Top : SHORT;
Right : SHORT;
Bottom : SHORT;
end record;
pragma Convention (C, SMALL_RECT);
type CONSOLE_SCREEN_BUFFER_INFO is
record
Size : COORD;
Cursor_Pos : COORD;
Attrib : Attribute;
Window : SMALL_RECT;
Max_Size : COORD;
end record;
pragma Convention (C, CONSOLE_SCREEN_BUFFER_INFO);
type PCONSOLE_SCREEN_BUFFER_INFO is access all CONSOLE_SCREEN_BUFFER_INFO;
pragma Convention (C, PCONSOLE_SCREEN_BUFFER_INFO);
type CONSOLE_CURSOR_INFO is
record
Size : DWORD;
Visible : WINBOOL;
end record;
pragma Convention (C, CONSOLE_CURSOR_INFO);
type PCONSOLE_CURSOR_INFO is access all CONSOLE_CURSOR_INFO;
pragma Convention (C, PCONSOLE_CURSOR_INFO);
function GetCh return Integer;
pragma Import (C, GetCh, "_getch");
function KbHit return Integer;
pragma Import (C, KbHit, "_kbhit");
function MessageBeep (Kind : DWORD) return DWORD;
pragma Import (StdCall, MessageBeep, "MessageBeep");
function GetStdHandle (Value : DWORD) return HANDLE;
pragma Import (StdCall, GetStdHandle, "GetStdHandle");
function GetConsoleCursorInfo (Buffer : HANDLE; Cursor : PCONSOLE_CURSOR_INFO) return WINBOOL;
pragma Import (StdCall, GetConsoleCursorInfo, "GetConsoleCursorInfo");
function SetConsoleCursorInfo (Buffer : HANDLE; Cursor : PCONSOLE_CURSOR_INFO) return WINBOOL;
pragma Import (StdCall, SetConsoleCursorInfo, "SetConsoleCursorInfo");
function SetConsoleCursorPosition (Buffer : HANDLE; Pos : COORD) return DWORD;
pragma Import (StdCall, SetConsoleCursorPosition, "SetConsoleCursorPosition");
function SetConsoleTextAttribute (Buffer : HANDLE; Attr : Attribute) return DWORD;
pragma Import (StdCall, SetConsoleTextAttribute, "SetConsoleTextAttribute");
function GetConsoleScreenBufferInfo (Buffer : HANDLE; Info : PCONSOLE_SCREEN_BUFFER_INFO) return DWORD;
pragma Import (StdCall, GetConsoleScreenBufferInfo, "GetConsoleScreenBufferInfo");
function FillConsoleOutputCharacter (Console : HANDLE; Char : Character; Length : DWORD; Start : COORD; Written : LPDWORD) return DWORD;
pragma Import (Stdcall, FillConsoleOutputCharacter, "FillConsoleOutputCharacterA");
function FillConsoleOutputAttribute (Console : Handle; Attr : Attribute; Length : DWORD; Start : COORD; Written : LPDWORD) return DWORD;
pragma Import (Stdcall, FillConsoleOutputAttribute, "FillConsoleOutputAttribute");
WIN32_ERROR : constant DWORD := 0;
INVALID_HANDLE_VALUE : constant HANDLE := -1;
STD_OUTPUT_HANDLE : constant DWORD := -11;
Color_Value : constant array (Color_Type) of Nibble := (0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15);
Color_Type_Value : constant array (Nibble) of Color_Type :=
(Black, Blue, Green, Cyan, Red, Magenta, Brown, Gray,
Black, Light_Blue, Light_Green, Light_Cyan, Light_Red,
Light_Magenta, Yellow, White);
-----------------------
-- PACKAGE VARIABLES --
-----------------------
Output_Buffer : HANDLE;
Num_Bytes : aliased DWORD;
Num_Bytes_Access : LPDWORD := Num_Bytes'Access;
Buffer_Info_Rec : aliased CONSOLE_SCREEN_BUFFER_INFO;
Buffer_Info : PCONSOLE_SCREEN_BUFFER_INFO := Buffer_Info_Rec'Access;
-------------------------
-- SUPPORTING SERVICES --
-------------------------
procedure Get_Buffer_Info is
begin
if GetConsoleScreenBufferInfo (Output_Buffer, Buffer_Info) = WIN32_ERROR then
raise Buffer_Info_Error;
end if;
end Get_Buffer_Info;
--------------------
-- CURSOR CONTROL --
--------------------
function Cursor_Visible return Boolean is
Cursor : aliased CONSOLE_CURSOR_INFO;
begin
if GetConsoleCursorInfo (Output_Buffer, Cursor'Unchecked_Access) = 0 then
raise Cursor_Get_Error;
end if;
return Cursor.Visible = 1;
end Cursor_Visible;
procedure Set_Cursor (Visible : in Boolean) is
Cursor : aliased CONSOLE_CURSOR_INFO;
begin
if GetConsoleCursorInfo (Output_Buffer, Cursor'Unchecked_Access) = 0 then
raise Cursor_Get_Error;
end if;
if Visible = True then
Cursor.Visible := 1;
else
Cursor.Visible := 0;
end if;
if SetConsoleCursorInfo (Output_Buffer, Cursor'Unchecked_Access) = 0 then
raise Cursor_Set_Error;
end if;
end Set_Cursor;
function Where_X return X_Pos is
begin
Get_Buffer_Info;
return X_Pos (Buffer_Info_Rec.Cursor_Pos.X);
end Where_X;
function Where_Y return Y_Pos is
begin
Get_Buffer_Info;
return Y_Pos (Buffer_Info_Rec.Cursor_Pos.Y);
end Where_Y;
procedure Goto_XY
(X : in X_Pos := X_Pos'First;
Y : in Y_Pos := Y_Pos'First) is
New_Pos : COORD := (SHORT (X), SHORT (Y));
begin
Get_Buffer_Info;
if New_Pos.X > Buffer_Info_Rec.Size.X then
New_Pos.X := Buffer_Info_Rec.Size.X;
end if;
if New_Pos.Y > Buffer_Info_Rec.Size.Y then
New_Pos.Y := Buffer_Info_Rec.Size.Y;
end if;
if SetConsoleCursorPosition (Output_Buffer, New_Pos) = WIN32_ERROR then
raise Cursor_Pos_Error;
end if;
end Goto_XY;
-------------------
-- COLOR CONTROL --
-------------------
function Get_Foreground return Color_Type is
begin
Get_Buffer_Info;
return Color_Type_Value (Buffer_Info_Rec.Attrib.Foreground);
end Get_Foreground;
function Get_Background return Color_Type is
begin
Get_Buffer_Info;
return Color_Type_Value (Buffer_Info_Rec.Attrib.Background);
end Get_Background;
procedure Set_Foreground (Color : in Color_Type := Gray) is
Attr : Attribute;
begin
Get_Buffer_Info;
Attr.Foreground := Color_Value (Color);
Attr.Background := Buffer_Info_Rec.Attrib.Background;
if SetConsoleTextAttribute (Output_Buffer, Attr) = WIN32_ERROR then
raise Set_Attribute_Error;
end if;
end Set_Foreground;
procedure Set_Background (Color : in Color_Type := Black) is
Attr : Attribute;
begin
Get_Buffer_Info;
Attr.Foreground := Buffer_Info_Rec.Attrib.Foreground;
Attr.Background := Color_Value (Color);
if SetConsoleTextAttribute (Output_Buffer, Attr) = WIN32_ERROR then
raise Set_Attribute_Error;
end if;
end Set_Background;
--------------------
-- SCREEN CONTROL --
--------------------
procedure Clear_Screen (Color : in Color_Type := Black) is
Length : DWORD;
Attr : Attribute;
Home : COORD := (0, 0);
begin
Get_Buffer_Info;
Length := DWORD (Buffer_Info_Rec.Size.X) * DWORD (Buffer_Info_Rec.Size.Y);
Attr.Background := Color_Value (Color);
Attr.Foreground := Buffer_Info_Rec.Attrib.Foreground;
if SetConsoleTextAttribute (Output_Buffer, Attr) = WIN32_ERROR then
raise Set_Attribute_Error;
end if;
if FillConsoleOutputAttribute (Output_Buffer, Attr, Length, Home, Num_Bytes_Access) = WIN32_ERROR then
raise Fill_Attribute_Error;
end if;
if FillConsoleOutputCharacter (Output_Buffer, ' ', Length, Home, Num_Bytes_Access) = WIN32_ERROR then
raise Fill_Char_Error;
end if;
if SetConsoleCursorPosition (Output_Buffer, Home) = WIN32_ERROR then
raise Cursor_Position_Error;
end if;
end Clear_Screen;
-------------------
-- SOUND CONTROL --
-------------------
procedure Bleep is
begin
if MessageBeep (16#FFFFFFFF#) = WIN32_ERROR then
raise Beep_Error;
end if;
end Bleep;
-------------------
-- INPUT CONTROL --
-------------------
function Get_Key return Character is
Temp : Integer;
begin
Temp := GetCh;
if Temp = 16#00E0# then
Temp := 0;
end if;
return Character'Val (Temp);
end Get_Key;
function Key_Available return Boolean is
begin
if KbHit = 0 then
return False;
else
return True;
end if;
end Key_Available;
begin
--------------------------
-- WIN32 INITIALIZATION --
--------------------------
Output_Buffer := GetStdHandle (STD_OUTPUT_HANDLE);
if Output_Buffer = INVALID_HANDLE_VALUE then
raise Invalid_Handle_Error;
end if;
end NT_Console;
-----------------------------------------------------------------------
--
-- File: nt_console.ads
-- Description: Win95/NT console support
-- Rev: 0.2
-- Date: 08-june-1999
-- Author: Jerry van Dijk
-- Mail: [email protected]
--
-- Copyright (c) Jerry van Dijk, 1997, 1998, 1999
-- Billie Holidaystraat 28
-- 2324 LK LEIDEN
-- THE NETHERLANDS
-- tel int + 31 71 531 43 65
--
-- Permission granted to use for any purpose, provided this copyright
-- remains attached and unmodified.
--
-- THIS SOFTWARE IS PROVIDED ``AS IS'' AND WITHOUT ANY EXPRESS OR
-- IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED
-- WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
--
-----------------------------------------------------------------------
package NT_Console is
----------------------
-- TYPE DEFINITIONS --
----------------------
subtype X_Pos is Natural range 0 .. 79;
subtype Y_Pos is Natural range 0 .. 24;
type Color_Type is
(Black, Blue, Green, Cyan, Red, Magenta, Brown, Gray,
Light_Blue, Light_Green, Light_Cyan, Light_Red,
Light_Magenta, Yellow, White);
----------------------
-- EXTENDED PC KEYS --
----------------------
Key_Alt_Escape : constant Character := Character'Val (16#01#);
Key_Control_At : constant Character := Character'Val (16#03#);
Key_Alt_Backspace : constant Character := Character'Val (16#0E#);
Key_BackTab : constant Character := Character'Val (16#0F#);
Key_Alt_Q : constant Character := Character'Val (16#10#);
Key_Alt_W : constant Character := Character'Val (16#11#);
Key_Alt_E : constant Character := Character'Val (16#12#);
Key_Alt_R : constant Character := Character'Val (16#13#);
Key_Alt_T : constant Character := Character'Val (16#14#);
Key_Alt_Y : constant Character := Character'Val (16#15#);
Key_Alt_U : constant Character := Character'Val (16#16#);
Key_Alt_I : constant Character := Character'Val (16#17#);
Key_Alt_O : constant Character := Character'Val (16#18#);
Key_Alt_P : constant Character := Character'Val (16#19#);
Key_Alt_LBracket : constant Character := Character'Val (16#1A#);
Key_Alt_RBracket : constant Character := Character'Val (16#1B#);
Key_Alt_Return : constant Character := Character'Val (16#1C#);
Key_Alt_A : constant Character := Character'Val (16#1E#);
Key_Alt_S : constant Character := Character'Val (16#1F#);
Key_Alt_D : constant Character := Character'Val (16#20#);
Key_Alt_F : constant Character := Character'Val (16#21#);
Key_Alt_G : constant Character := Character'Val (16#22#);
Key_Alt_H : constant Character := Character'Val (16#23#);
Key_Alt_J : constant Character := Character'Val (16#24#);
Key_Alt_K : constant Character := Character'Val (16#25#);
Key_Alt_L : constant Character := Character'Val (16#26#);
Key_Alt_Semicolon : constant Character := Character'Val (16#27#);
Key_Alt_Quote : constant Character := Character'Val (16#28#);
Key_Alt_Backquote : constant Character := Character'Val (16#29#);
Key_Alt_Backslash : constant Character := Character'Val (16#2B#);
Key_Alt_Z : constant Character := Character'Val (16#2C#);
Key_Alt_X : constant Character := Character'Val (16#2D#);
Key_Alt_C : constant Character := Character'Val (16#2E#);
Key_Alt_V : constant Character := Character'Val (16#2F#);
Key_Alt_B : constant Character := Character'Val (16#30#);
Key_Alt_N : constant Character := Character'Val (16#31#);
Key_Alt_M : constant Character := Character'Val (16#32#);
Key_Alt_Comma : constant Character := Character'Val (16#33#);
Key_Alt_Period : constant Character := Character'Val (16#34#);
Key_Alt_Slash : constant Character := Character'Val (16#35#);
Key_Alt_KPStar : constant Character := Character'Val (16#37#);
Key_F1 : constant Character := Character'Val (16#3B#);
Key_F2 : constant Character := Character'Val (16#3C#);
Key_F3 : constant Character := Character'Val (16#3D#);
Key_F4 : constant Character := Character'Val (16#3E#);
Key_F5 : constant Character := Character'Val (16#3F#);
Key_F6 : constant Character := Character'Val (16#40#);
Key_F7 : constant Character := Character'Val (16#41#);
Key_F8 : constant Character := Character'Val (16#42#);
Key_F9 : constant Character := Character'Val (16#43#);
Key_F10 : constant Character := Character'Val (16#44#);
Key_Home : constant Character := Character'Val (16#47#);
Key_Up : constant Character := Character'Val (16#48#);
Key_PageUp : constant Character := Character'Val (16#49#);
Key_Alt_KPMinus : constant Character := Character'Val (16#4A#);
Key_Left : constant Character := Character'Val (16#4B#);
Key_Center : constant Character := Character'Val (16#4C#);
Key_Right : constant Character := Character'Val (16#4D#);
Key_Alt_KPPlus : constant Character := Character'Val (16#4E#);
Key_End : constant Character := Character'Val (16#4F#);
Key_Down : constant Character := Character'Val (16#50#);
Key_PageDown : constant Character := Character'Val (16#51#);
Key_Insert : constant Character := Character'Val (16#52#);
Key_Delete : constant Character := Character'Val (16#53#);
Key_Shift_F1 : constant Character := Character'Val (16#54#);
Key_Shift_F2 : constant Character := Character'Val (16#55#);
Key_Shift_F3 : constant Character := Character'Val (16#56#);
Key_Shift_F4 : constant Character := Character'Val (16#57#);
Key_Shift_F5 : constant Character := Character'Val (16#58#);
Key_Shift_F6 : constant Character := Character'Val (16#59#);
Key_Shift_F7 : constant Character := Character'Val (16#5A#);
Key_Shift_F8 : constant Character := Character'Val (16#5B#);
Key_Shift_F9 : constant Character := Character'Val (16#5C#);
Key_Shift_F10 : constant Character := Character'Val (16#5D#);
Key_Control_F1 : constant Character := Character'Val (16#5E#);
Key_Control_F2 : constant Character := Character'Val (16#5F#);
Key_Control_F3 : constant Character := Character'Val (16#60#);
Key_Control_F4 : constant Character := Character'Val (16#61#);
Key_Control_F5 : constant Character := Character'Val (16#62#);
Key_Control_F6 : constant Character := Character'Val (16#63#);
Key_Control_F7 : constant Character := Character'Val (16#64#);
Key_Control_F8 : constant Character := Character'Val (16#65#);
Key_Control_F9 : constant Character := Character'Val (16#66#);
Key_Control_F10 : constant Character := Character'Val (16#67#);
Key_Alt_F1 : constant Character := Character'Val (16#68#);
Key_Alt_F2 : constant Character := Character'Val (16#69#);
Key_Alt_F3 : constant Character := Character'Val (16#6A#);
Key_Alt_F4 : constant Character := Character'Val (16#6B#);
Key_Alt_F5 : constant Character := Character'Val (16#6C#);
Key_Alt_F6 : constant Character := Character'Val (16#6D#);
Key_Alt_F7 : constant Character := Character'Val (16#6E#);
Key_Alt_F8 : constant Character := Character'Val (16#6F#);
Key_Alt_F9 : constant Character := Character'Val (16#70#);
Key_Alt_F10 : constant Character := Character'Val (16#71#);
Key_Control_Left : constant Character := Character'Val (16#73#);
Key_Control_Right : constant Character := Character'Val (16#74#);
Key_Control_End : constant Character := Character'Val (16#75#);
Key_Control_PageDown : constant Character := Character'Val (16#76#);
Key_Control_Home : constant Character := Character'Val (16#77#);
Key_Alt_1 : constant Character := Character'Val (16#78#);
Key_Alt_2 : constant Character := Character'Val (16#79#);
Key_Alt_3 : constant Character := Character'Val (16#7A#);
Key_Alt_4 : constant Character := Character'Val (16#7B#);
Key_Alt_5 : constant Character := Character'Val (16#7C#);
Key_Alt_6 : constant Character := Character'Val (16#7D#);
Key_Alt_7 : constant Character := Character'Val (16#7E#);
Key_Alt_8 : constant Character := Character'Val (16#7F#);
Key_Alt_9 : constant Character := Character'Val (16#80#);
Key_Alt_0 : constant Character := Character'Val (16#81#);
Key_Alt_Dash : constant Character := Character'Val (16#82#);
Key_Alt_Equals : constant Character := Character'Val (16#83#);
Key_Control_PageUp : constant Character := Character'Val (16#84#);
Key_F11 : constant Character := Character'Val (16#85#);
Key_F12 : constant Character := Character'Val (16#86#);
Key_Shift_F11 : constant Character := Character'Val (16#87#);
Key_Shift_F12 : constant Character := Character'Val (16#88#);
Key_Control_F11 : constant Character := Character'Val (16#89#);
Key_Control_F12 : constant Character := Character'Val (16#8A#);
Key_Alt_F11 : constant Character := Character'Val (16#8B#);
Key_Alt_F12 : constant Character := Character'Val (16#8C#);
Key_Control_Up : constant Character := Character'Val (16#8D#);
Key_Control_KPDash : constant Character := Character'Val (16#8E#);
Key_Control_Center : constant Character := Character'Val (16#8F#);
Key_Control_KPPlus : constant Character := Character'Val (16#90#);
Key_Control_Down : constant Character := Character'Val (16#91#);
Key_Control_Insert : constant Character := Character'Val (16#92#);
Key_Control_Delete : constant Character := Character'Val (16#93#);
Key_Control_KPSlash : constant Character := Character'Val (16#95#);
Key_Control_KPStar : constant Character := Character'Val (16#96#);
Key_Alt_EHome : constant Character := Character'Val (16#97#);
Key_Alt_EUp : constant Character := Character'Val (16#98#);
Key_Alt_EPageUp : constant Character := Character'Val (16#99#);
Key_Alt_ELeft : constant Character := Character'Val (16#9B#);
Key_Alt_ERight : constant Character := Character'Val (16#9D#);
Key_Alt_EEnd : constant Character := Character'Val (16#9F#);
Key_Alt_EDown : constant Character := Character'Val (16#A0#);
Key_Alt_EPageDown : constant Character := Character'Val (16#A1#);
Key_Alt_EInsert : constant Character := Character'Val (16#A2#);
Key_Alt_EDelete : constant Character := Character'Val (16#A3#);
Key_Alt_KPSlash : constant Character := Character'Val (16#A4#);
Key_Alt_Tab : constant Character := Character'Val (16#A5#);
Key_Alt_Enter : constant Character := Character'Val (16#A6#);
--------------------
-- CURSOR CONTROL --
--------------------
function Cursor_Visible return Boolean;
procedure Set_Cursor (Visible : in Boolean);
function Where_X return X_Pos;
function Where_Y return Y_Pos;
procedure Goto_XY
(X : in X_Pos := X_Pos'First;
Y : in Y_Pos := Y_Pos'First);
-------------------
-- COLOR CONTROL --
-------------------
function Get_Foreground return Color_Type;
function Get_Background return Color_Type;
procedure Set_Foreground (Color : in Color_Type := Gray);
procedure Set_Background (Color : in Color_Type := Black);
--------------------
-- SCREEN CONTROL --
--------------------
procedure Clear_Screen (Color : in Color_Type := Black);
-------------------
-- SOUND CONTROL --
-------------------
procedure Bleep;
-------------------
-- INPUT CONTROL --
-------------------
function Get_Key return Character;
function Key_Available return Boolean;
end NT_Console;
Vous savez désormais comment fonctionnent les packages : copiez chacun de ces textes dans un fichier séparé et enregistrez-les sous les noms NT_Console.adb et NT_Console.ads dans le répertoire de votre projet et n'oubliez pas d'écrire la ligne ci-dessous en en-tête de votre projet :
With NT_Console ; Use NT_Console ;
Le contenu en détail
Voyons maintenant le contenu de ce package. Pour cela, ouvrez le fichier NT_Console.ads (le code source ne nous intéresse pas, nous n'allons observer que les spécifications). Pour les plus craintifs, suivez le guide. Pour ceux qui peuvent s'en sortir seuls (et c'est faisable) lisez ce fichier par vous-mêmes.
C'est l'histoire de trois types ...
Ce package est très bien ficelé, il commence par présenter le package : nom, nom de l'auteur, version, date de création, droits ... Je vous conseille de vous en inspirer pour plus de lisibilité dans vos packages. Mais venons-en à ce qui nous intéresse. NT_Console commence par définir trois types et seulement trois :
X_Pos : c'est un Natural entre 0 et 79. Il correspond à la position de votre curseur sur une ligne de votre console : le premier emplacement est le numéro 0, le dernier est le numéro 79. Autrement dit, vous pouvez afficher 80 caractères par ligne.
Y_Pos : c'est un Natural entre 0 et 24. Il correspond au numéro de la ligne à laquelle se situe votre curseur. La première ligne est la numéro 0, la dernière la numéro 24 d'où un total de 25 lignes affichables dans la console. A elles deux, des variables de type X_Pos et Y_Pos vous indiquent où se situe votre curseur à l'écran. Attention, encore une fois, le premier emplacement est le numéro (0,0)
Color_Type : c'est un type énuméré comptant 15 noms de couleur. C'est ce type qui va nous servir à définir la couleur du texte ou de l'arrière plan. Pour ceux qui auraient du mal avec l'Anglais, c'est comme si vous aviez ceci :
type Color_Type is
(Noir, Bleu, Vert, Cyan, Rouge, Magenta, Marron, Gris,
Bleu_Clair, Vert_Clair, Cyan_clair, Rouge_Clair,
Magenta_Clair, Jaune, Blanc);
Puis vient une longue (très longue) liste de constantes correspondant aux valeurs de certaines touches ou combinaisons de touches du clavier.
Et pour quelques fonctions de plus
Nous en venons donc à l'essentiel : les procédures et fonctions. Elles sont très bien rangées en cinq catégories : contrôle du curseur, contrôle de la couleur, contrôle de l'écran, contrôle du son et contrôle des entrées (entrées-clavier bien sûr).
Contrôle du curseur
Pour savoir si le curseur est visible ou non, utilisez la fonction Cursor_Visible. Pour définir si le curseur sera visible ou non utilisez la procédure Set_Cursor(un_booleen).
Pour connaître la position du curseur, c'est à dire connaître ses coordonnées X_Pos et Y_Pos, vous pourrez les fonctions Where_X et Where_Y (Where = où). Enfin, pour modifier cette position, vous utiliserez la procédure Goto_XY() qui prend en paramètre une variable de type X_Pos et une de type Y_Pos.
Contrôle de la couleur
Il y a deux éléments dont nous pouvons modifier la couleur à l'affichage : la couleur du texte (l'avant-plan ou premier plan) et la couleur du fond, du surlignage (l'arrière-plan). C'est à cela que correspondent Foreground (l'avant-plan) et Background (arrière-plan).
Comme toujours, deux actions sont possibles : lire et écrire. Si vous souhaitez connaître la couleur de l'arrière plan, vous devez la lire, la saisir et vous utiliserez donc la fonction get_Background qui vous retournera la couleur de fond. Si vous souhaitez modifier cette couleur, alors saisir une nouvelle couleur, la redéfinir et vous utiliserez la procédure Set_Background(une_couleur). Même chose pour l'avant-plan bien entendu.
Cette section, comme la suivante, ne comporte qu'une seule procédure : Clear_Screen(). Cette procédure prend en paramètre une couleur (une variable de type Color_Type) et, comme son nom l'indique, nettoie l'écran. Plus rien n'est affiché et en plus vous pouvez changer en même temps la couleur de fond de la console. Attention, la couleur de fond de la console est différente de la couleur d'arrière-plan de votre texte !
Contrôle du son
Une seule procédure sans grand intérêt : Bleep. Cette procédure se contente d'émettre un bip, comme si Windows avait rencontré une erreur.
Contrôle des entées clavier
Lorsque l'utilisateur appuie sur les touches du clavier (même sans que votre programme ne l'y ai invité), celui-ci transmet une information à votre ordinateur qui la stocke en mémoire (on parle de mémoire tampon ou de Buffer, souvenez-vous, nous en avions parlé quand nous avions vu l'instruction Skip_line). Ainsi, la mémoire tampon peut contenir toute une série de caractères avant même que le programme n'en ait besoin ou bien être vide alors que le programme attend une réponse. La fonction key_available vous permet de savoir si une touche a été stockée en mémoire tampon. Les fonctions et procédures get, get_line, get_immediate ... se contentent ainsi de piocher dans la mémoire tampon, au besoin en attendant qu'elle se remplisse.
La fonction get_key quant à elle agit un peu à la manière de la procédure get_immediate : elle pioche immédiatement dans la mémoire tampon sans attendre que l'utilisateur valide la saisie avec entrée. Quel intérêt ? Eh bien il y a une petite différence, notamment dans la gestion des touches "spéciales". Par "touches spéciales", j'entends les touches flèches ou F10 par exemple. Essayez ce code :
with nt_console ; use nt_console ;
with ada.text_io ; use ada.Text_IO ;
with ada.Integer_Text_IO ; use ada.Integer_Text_IO ;
procedure test is
c : character ;
begin
loop
c := get_key ;
put("valeur correspondante :") ;
put(character'pos(c)) ;
new_line ;
end loop ;
end test01 ;
Vous vous rendrez compte que toute touche spéciale envoie en fait deux caractères : le caractère n°0 suivi d'un second. Ainsi, la flèche gauche envoie le caractère n°0 suivi du caractère n°75. A l'aide de ce petit programme, vous pourrez récupérer les numéros des touches fléchées qui serviront au joueur à diriger le serpent.
La fonction key_available quant à elle indique si le buffer est vide ou pas. Si elle renvoie true, c'est qu'il y a au moins un caractère en mémoire tampon et que l'on peut le saisir. Chose importante, elle n'attend pas que l'utilisateur appuie sur un touche ! Ainsi, à l'aide de cette fonction, nous pourrons faire en sorte que le serpent continue à avancer sans attendre que l'utilisateur appuie sur une touche ! Nous n'utiliserons get_key que dans le cas où key_available aura préalablement renvoyé true.
Pour mesurer le temps et définir ainsi la vitesse de jeu, nous aurons besoin d'un second package (officiel celui-là) : Ada.Calendar !
Le package Ada.calendar est fait pour nous permettre de manipuler l'horloge. Si vous cherchez le fichier correspondant, il porte le nom a-calend.ads. Deux types essentiels le composent : le type Duration et le type Time (même si Time est une copie de Duration). Duration mesure les durées, Time correspond aux dates. Ce sont tous deux des nombres décimaux, puisque le temps est mesuré en secondes. Attention toutefois aux problèmes de typage ! Nous allons définir deux variables : temps et duree.
temps : time ;
duree : Duration ;
Pour saisir la date actuelle (jour, mois, année, seconde), il faut utiliser la fonction clock :
temps := clock ;
Il est ensuite possible d'effectuer des opérations, par exemple :
duree := clock - temps ;
En soustrayant le temps enregistré dans la variable temps au temps actuel fourni par la fonction clock, on obtient une durée. Il est également possible de soustraire (ou d'ajouter) une durée à un temps, ce qui donne alors un temps. Il est également possible de comparer des variables de type Time ou Duration. Enfin, pour afficher une variable de type Time ou Duration, pensez à la convertir préalablement en Float. Pour en savoir plus sur le package Ada.Calendar, n'hésitez pas à éplucher les fichiers a-calend.adb et a-calend.ads, ils ne sont pas très longs.
Comment je fais pour jouer en temps réel ? Mon serpent ne peut pas avancer tout seul et en même temps attendre que je lui indique la direction à prendre !
Nous allons devoir combiner les deux packages dont je viens de vous parler pour parvenir à ce petit exploit. Le serpent avance case par case, chaque avancée prend un certain temps (pour ma part, j'ai pris une durée de 0.2 secondes) durant lequel le joueur peut appuyer sur les touches de son clavier pour modifier la direction du serpent. Une fois ce temps écoulé, le serpent avance d'une case. Cela nous amène à l'algorithme suivant :
TANT QUE duree<0.2 REPETER
| attendre_une_réaction_du_joueur ;
FIN REPETER
Avancer_le_serpent ;
Le soucis, c'est que si le joueur n'appuie jamais sur le clavier, le programme reste bloqué sur l'instruction attendre_une_réaction_du_joueur et on ne sort jamais de la boucle ...
C'est là qu'intervient le package NT_Console ! Nous ne devons pas attendre que le joueur ait saisi une touche mais simplement nous demander s'il a appuyé sur une touche. Si oui, on saisit effectivement cette touche, sinon on continue à parcourir notre boucle. Cela nous amène à l'algorithme suivant :
if Key_available
then c:=get_key ;
end if ;
Ainsi, le programme ne reste pas bloqué sur get_key indéfiniment. Cependant, nous attendons que le joueur appuie sur une touche fléchée, pas sur une lettre ! Comme je vous l'ai dit, les touches spéciales envoient deux caractères consécutivement : le numéro 0 puis le véritable caractère. Donc nous devons reprendre le code précédent ainsi :
if Key_available
then if character'pos(get_key)=0
then c:=get_key ;
traitement ;
end if ;
end if ;
Comment afficher un serpent et une zone de jeu en couleur ?
Pour cela, regardons la capture d'écran que je vous ai fournie, elle n'est pas parole d'évangile mais elle va nous guider :
Jeu du serpent
Que remarque-t-on ? Tout d'abord, le fond de la console est gris, contrairement à l'aire de jeu qui elle est blanche et au serpent qui est dessiné en bleu par-dessus l'aire de jeu. Nous avons donc trois niveau de couleur :
La couleur de fond de la console : elle sera obtenue lorsque vous utiliser la procédure clear_screen().
La couleur de la zone de jeu : elle est obtenue en fixant la couleur d'arrière-plan et en affichant de simples espaces. Attention à ne pas afficher de caractères avec un arrière-plan blanc en dehors de cette zone. Notamment si vous affichez du texte comme le score ou un message de défaite.
La couleur des items affichés sur la zone de jeu : ces items comme les morceaux du serpent ou l'objet qu'il doit manger, doivent avoir un arrière-plan blanc et un avant-plan bleu (ou n'importe quelle autre couleur de votre choix).
Pensez également que lorsque votre serpent avancera d'une case, il ne suffira pas d'afficher le nouveau serpent, il faudra également penser à effacer l'ancien de l'écran !
Mais d'où tu sors tes ronds, tes rectangles et tes triangles ?
C'est simple. Il suffit de réaliser un petit programme qui affiche tous les caractères du numéro 0 au numéro 255 (à l'aide des attributs 'pos et 'val). On découvre ainsi plein de caractères bizarroïdes comme le trèfle, le cœur, le pique et le carreau ou des flèches, des carrés, ... Pour les rectangles du corps du serpent, j'ai utilisé character'val(219) et character'val(178), pour les triangles j'ai utilisé character'val(16), character'val(17), character'val(30) ou character'val(31) et quant à l'espèce de soleil, il s'agit de character'val(15). Mais ne vous contentez pas de reprendre mot à mot mes propositions, faites des essais et trouvez les symboles qui vous paraissent les plus appropriés.
Par où commencer ?
Nous en sommes au troisième TP, il serait bon que vous commenciez à établir vous-même votre approche du problème. Je ne vais donc pas détailler énormément cette partie. Voici comment j'aborderais ce TP (en entrecoupant chaque étape de divers tests pour trouver d'éventuels bogues) :
Création des types nécessaires pour faire un serpent.
Réalisation des procédures d'affichage de l'aire de jeu et du serpent.
Réalisation des procédures de déplacement et d'agrandissement du serpent + actualisation éventuelle des procédures d'affichage
Réalisation des procédures permettant au Joueur de piloter le Serpent au clavier
Mise en place des règles : interdiction de sortir de l'espace de jeu, de mordre le corps du serpent, d'effectuer des demi-tours.
Réalisation des procédures générant l'item à avaler (appelé Anneau dans mon code) et actualisation des règles : "si le serpent mange l'anneau alors il grandit", "un anneau ne peut apparaître directement sur le serpent".
Éventuels débogages et ajouts de fonctionnalités.
Voilà pour le plan de bataille. Il est succinct mais devrait vous fournir des objectifs partiels facilement atteignables. Je me répète mais n'hésitez pas à effectuer des tests réguliers et approfondis pour être sûr de ne pas avoir créé de bogues. Par exemple, ce n'est pas parce que votre serpent avance correctement vers le haut, qu'il avancera correctement vers la droite ou après avoir effectué un ou deux virages. Et en cas de difficultés persistantes, n'hésitez pas à poser des questions.
with nt_console ; use nt_console ;
with Snake_Variables ; use Snake_Variables ;
with Snake_Programs ; use Snake_Programs ;
with Snake_Screen ; use Snake_Screen ;
procedure Snake is
Serpent : T_Serpent ;
begin
Set_Cursor(false) ;
print_ecran(snake) ;
print_ecran(ready) ;
print_ecran(start) ;
Clear_screen(Couleur_Ecran) ;
print_plateau ;
Init_Serpent(Serpent) ;
Print_Serpent(Serpent) ;
Game(Serpent) ;
end Snake ;
Le package contenant quelques types et surtout les variables nécessaires au programme :
with nt_console ; use nt_console ;
package Snake_Variables is
type T_Coord is record
x,y : integer := 0 ;
end record ;
Longueur : Natural := 30 ;
Hauteur : Natural := 15 ;
subtype Intervalle_Alea is natural range 1..Longueur*Hauteur ;
HDecalage : Natural := (X_Pos'last-X_Pos'first+1-Longueur)/2 ;
VDecalage : Natural := (Y_Pos'last-Y_Pos'first+1-Hauteur)/2 ;
Couleur_Ecran : Color_Type := gray ;
Couleur_Fond : Color_Type := white ;
Couleur_Texte : Color_Type := light_blue ;
Couleur_Anneau: Color_Type := red ;
Duree : Duration := 0.2 ;
Score : Natural := 0 ;
touche : Character ;
end Snake_Variables ;
Le package contenant la plupart des programmes servant au jeu :
with nt_console ; use nt_console ;
with ada.text_io ; use ada.Text_IO ;
with ada.Integer_Text_IO ; use ada.Integer_Text_IO ;
with ada.Calendar ; use ada.Calendar ;
package body Snake_Programs is
---------------------------------
-- AFFICHAGE PLATEAU --
---------------------------------
procedure print_plateau is
begin
print_score ;
new_line(Count(VDecalage)) ;
for j in 1..Hauteur loop
set_background(Couleur_Ecran) ;
for i in 1..HDecalage loop
put(' ') ;
end loop ;
set_background(Couleur_Fond) ;
for i in 1..longueur loop
put(' ') ;
end loop ;
new_line ;
end loop ;
end print_plateau ;
procedure print_score is
begin
set_foreground(green) ;
set_background(Couleur_Ecran) ;
goto_XY(0,0) ;
put("SCORE = ") ; put(Score,4) ;
set_foreground(Couleur_Texte) ;
set_background(Couleur_Fond) ;
end print_score ;
--------------------------------
-- CREATION SERPENT --
--------------------------------
procedure Init_Serpent(Serpent : in out T_Serpent) is
begin
Append(Serpent.corps,(15,7)) ; --placement des anneaux du serpent
Append(Serpent.corps,(15,8)) ;
Append(Serpent.corps,(15,9)) ;
Append(Serpent.corps,(14,9)) ;
Append(Serpent.corps,(13,9)) ;
Serpent.curseur := First(Serpent.corps) ; --placement du curseur sur la tête du serpent
Serpent.direction := (0,-1) ; --direction vers le haut
end Init_Serpent ;
procedure move(Serpent : in out T_Serpent) is
coord: T_coord ;
begin
efface_queue(Serpent) ; --on efface la queue
coord.x := Element(Serpent.curseur ).x + Serpent.direction.x ;
coord.y := Element(Serpent.curseur ).y + Serpent.direction.y ;
Prepend(Serpent.corps,coord) ; --on ajoute une nouvelle tête
Serpent.curseur := Last(Serpent.corps) ;
Delete(serpent.corps,Serpent.curseur) ; --on supprime la queue
Serpent.curseur := First(Serpent.corps) ;
print_serpent(serpent) ; --on affiche le nouveau corps
end move ;
procedure grow(Serpent : in out T_Serpent) is
coord: T_coord ;
begin
coord.x := First_Element(Serpent.corps).x + Serpent.direction.x ;
coord.y := First_Element(Serpent.corps).y + Serpent.direction.y ;
Prepend(Serpent.corps,coord) ; --on ajoute une nouvelle tête
Serpent.curseur := First(Serpent.corps) ;
print_serpent(serpent) ; --on affiche le nouveau corps
end grow ;
function est_sorti(Serpent : T_Serpent) return boolean is
tete : T_Coord ;
begin
tete := First_Element(Serpent.corps) ;
if tete.x < 1 or tete.x > Longueur or tete.y < 1 or tete.y > hauteur
then return true ;
else return false ;
end if ;
end est_sorti ;
function est_mordu(Serpent : T_Serpent) return boolean is
tete : T_Coord ;
Serpent2 : T_Serpent := Serpent ;
begin
tete := First_Element(Serpent2.corps) ;
Delete_first(Serpent2.corps) ;
if Find(Serpent2.corps,tete) /= No_Element --Is_In(tete,Serpent2.corps)
then return true ;
else return false ;
end if ;
end est_mordu ;
function a_mange(Serpent : T_Serpent ; Anneau : T_Coord) return boolean is
tete : T_Coord ;
begin
tete := First_Element(Serpent.corps) ;
if tete = Anneau
then return true ;
else return false ;
end if ;
end a_mange ;
---------------------------------
-- AFFICHAGE SERPENT --
---------------------------------
procedure print_tete(Serpent : in T_Serpent) is
begin
if serpent.direction.x < 0
then put(character'val(17)) ; --regard vers la gauche
elsif serpent.direction.x > 0
then put(character'val(16)) ; --regard vers la droite
elsif serpent.direction.y <0
then put(character'val(30)) ; --regard vers le haut
else put(character'val(31)) ; --regard vers le bas
end if ;
end print_tete ;
procedure print_corps(nb : natural) is
begin
if nb mod 2 =0
then put(character'val(219)) ;
else put(character'val(178)) ;
end if ;
end print_corps ;
procedure print_serpent(Serpent : in out T_Serpent) is
begin
Set_Foreground(Couleur_Texte) ;
for i in 1..length(Serpent.corps) loop
Goto_XY(Element(serpent.curseur).x + HDecalage-1,
Element(serpent.curseur).y + VDecalage-1) ;
if i = 1
then print_tete(serpent) ;
else print_corps(integer(i)) ;
end if ;
Next(Serpent.curseur) ;
end loop ;
Serpent.curseur := First(Serpent.corps) ;
end print_serpent ;
procedure efface_queue(Serpent : in out T_Serpent) is
begin
Serpent.curseur := Last(Serpent.corps) ;
Goto_XY(Element(serpent.curseur).x + HDecalage-1,
Element(serpent.curseur).y + VDecalage-1) ;
put(' ') ;
Serpent.curseur := First(Serpent.corps) ;
end efface_queue ;
---------------------------------
-- GESTION DES ANNEAUX --
---------------------------------
function generer(germe : generator ; Serpent : T_Serpent) return T_Coord IS
temp1,temp2 : Natural ;
anneau : T_Coord ;
BEGIN
loop
temp1 := random(germe) ; temp2 := random(germe) ;
Anneau := (temp1 mod longueur + 1, temp2 mod hauteur +1) ;
if Find(Serpent.corps,Anneau) = No_Element
then return Anneau ;
end if ;
end loop ;
end generer ;
procedure print_anneau(anneau : T_Coord) is
begin
set_foreground(Couleur_Anneau) ;
Goto_XY(anneau.x+Hdecalage-1,anneau.y+Vdecalage-1) ;
put(character'val(15)) ;
set_foreground(Couleur_Texte) ;
end print_anneau ;
--------------------------------
-- PROGRAMME DE JEU --
--------------------------------
procedure Erreur(Message : in String) is
begin
Goto_XY(HDecalage+5,VDecalage+Hauteur+2) ;
set_background(Couleur_Ecran) ;
set_foreground(light_Red) ;
Put(Message) ; delay 1.0 ;
end Erreur ;
procedure un_tour(Serpent : in out T_Serpent) is
choix_effectue : boolean := false ;
Temps : constant Time := clock ;
New_direction : T_Coord ;
begin
while clock-temps<duree loop
if not choix_effectue and then key_available and then character'pos(get_key) = 0
then touche := get_key ;
case character'pos(touche) is
when 72 => New_direction := (0,-1) ; --haut
when 75 => New_direction := (-1,0) ; --gauche
when 77 => New_direction := (1,0) ; --droite
when 80 => New_direction := (0,1) ; --bas
when others => null ;
end case ;
if New_direction.x /= Serpent.direction.x and New_direction.y /= Serpent.direction.y
then Serpent.direction := New_direction ;
choix_effectue := true ;
end if ;
end if ;
end loop ;
end un_tour ;
procedure game(Serpent : in out T_Serpent) is
germe : generator ;
Anneau : T_Coord ;
begin
reset(germe) ;
Anneau := generer(germe,Serpent) ;
Print_anneau(Anneau) ;
loop
un_tour(Serpent) ;
--test pour savoir si le serpent grandit ou avance
if a_mange(serpent,anneau)
then grow(serpent) ;
Score := Score + 100 ;
Print_score ;
Anneau := generer(germe,serpent) ;
Print_anneau(Anneau) ;
else move(serpent) ;
end if ;
--test pour savoir si le serpent meurt
if est_sorti(serpent)
then Erreur("Vous " & character'val(136) & "tes sortis !") ; exit ;
elsif est_mordu(serpent)
then Erreur("Vous vous " & character'val(136) & "tes mordu !") ; exit ;
end if ;
end loop ;
end game ;
end Snake_Programs ;
with Snake_Variables ; use Snake_Variables ;
with ada.Numerics.Discrete_Random ;
with ada.Containers.Doubly_Linked_Lists ; use ada.Containers ;
package Snake_Programs is
package P_Liste is new Ada.Containers.Doubly_Linked_Lists(T_coord) ;
use P_Liste ;
package P_Aleatoire is new ada.Numerics.Discrete_Random(Intervalle_Alea) ;
use P_Aleatoire ;
Type T_Serpent is record
corps : List ;
Curseur : Cursor ;
direction : T_Coord ;
end record ;
procedure print_plateau ;
procedure print_score ;
procedure Init_Serpent(Serpent : in out T_Serpent) ;
procedure move(Serpent : in out T_Serpent) ;
procedure grow(Serpent : in out T_Serpent) ;
function est_sorti(Serpent : T_Serpent) return boolean ;
function est_mordu(Serpent : T_Serpent) return boolean ;
procedure print_tete(Serpent : in T_Serpent) ;
procedure print_corps(nb : natural) ;
procedure print_serpent(Serpent : in out T_Serpent) ;
procedure efface_queue(Serpent : in out T_Serpent) ;
function generer(germe : generator ; Serpent : T_Serpent) return T_Coord ;
procedure print_anneau(anneau : T_Coord) ;
procedure Erreur(Message : in String) ;
procedure un_tour(Serpent : in out T_Serpent) ;
procedure game(Serpent : in out T_Serpent) ;
end Snake_Programs ;
Enfin, le package servant à l'affichage de mes écrans de titre :
with ada.text_IO ; use ada.Text_IO ;
with NT_Console ; use NT_Console ;
With Snake_Variables ; use Snake_Variables ;
package body Snake_screen is
procedure print_line(line : string) is
begin
for i in line'range loop
case line(i) is
when 'R' => set_background(Red) ;
put(' ') ;
set_background(Couleur_Ecran) ;
when 'G' => set_background(Green) ;
put(' ') ;
set_background(Couleur_Ecran) ;
when 'Y' => set_background(Yellow) ;
put(' ') ;
set_background(Couleur_Ecran) ;
when '#' => set_background(Black) ;
put(' ') ;
set_background(Couleur_Ecran) ;
when others => put(' ') ;
end case ;
end loop ;
new_line ;
end print_line ;
procedure print_fichier(name : string) is
F : file_type ;
begin
open(F,In_File,name) ;
clear_screen(couleur_ecran) ;
set_background(Couleur_Ecran) ;
while not end_of_file(f) and not end_of_page(f) loop
print_line(get_line(f) ) ;
end loop ;
close(f) ;
end print_fichier;
procedure print_ecran(Ecran : T_Ecran) is
begin
case Ecran is
when SNAKE => print_fichier("Snake.pic") ; delay 2.5 ;
when START => print_fichier("Start.pic") ; delay 1.0 ;
when READY => print_fichier("Ready.pic") ; delay 1.5 ;
end case ;
end print_ecran;
end Snake_Screen ;
package Snake_Screen is
type T_Ecran is(START,READY,SNAKE) ;
procedure print_line(line : string) ;
procedure print_fichier(name : string) ;
procedure print_ecran(Ecran : T_Ecran) ;
end Snake_Screen ;
Pour finir, je vous transmets également les fichiers .pic (en fait des fichiers textes) servant de support à ces fameux écrans titres (je suis preneur pour tout écran titre pouvant remplacer celui qui ressemble vaguement à un serpent ^^ ):
.
GGGGGGGG
Y YG
G YG
Y YG
GY
GG
GY
GGY
GGGGGGGGGGGY
YGGYGYGYGYGYG
GGGGY
GGY
GGY
GG
GG
YGG
GGGG
YYGGGGGG
YYGGGGGG
YYGGGGG
YYYG
Cette fois, la partie III est bel et bien terminée. Mais vous pouvez bien entendu perfectionner ce jeu en proposant différent niveaux de difficulté (en faisant varier la vitesse, la taille de l'aire de jeu ... ), en ajoutant des adversaires, en proposant un enregistrement des meilleurs scores ... n'hésitez surtout pas à bidouiller, à faire des essais. C'est ainsi que l'on apprend et que l'on progresse. Sur ce, nous allons pouvoir passer à la partie IV. ^^
Nous avons aborder dans ce chapitre la plupart des notions qu'il nous manquait en découvrant des types plus complexes comme les tableaux, les pointeurs, les types abstraits de données ... Vous avez dors et déjà fait un large tour des possibilités et savez désormais programmer en Ada ! :) Enfin, en Ada83. Mais la science de l'informatique évolue sans cesse et la programmation n'échappe pas à cette règle. La norme Ada95 a fait entré le langage Ada dans la catégorie des langages orientés objets. Découvrir cette fameuse POO (Programmation Orientée Objet) sera l'objectif principal de la partie IV.
Et quand est-ce que l'on fera des programmes en Ada plus jolis que ces vilaines consoles ? :'(
Ce sera le rôle de la cinquième partie que d'aborder ces notions au travers de GTK, une librairie qui nous permettra de créer de jolies fenêtres avec de jolis boutons et tout et tout ! ;) Les plus curieux (ou pressés) pourront s'y rendre directement, car il vous sera dors et déjà possible d'obtenir des résultats. Toutefois, pour des applications plus poussées et pour une meilleure compréhension, il sera nécessaire de lire la partie IV.
Lors du chapitre sur les tableaux (partie III), nous avions abordé l'algorithme de tri par sélection (Exercice 3). Cet algorithme consistait à trier un tableau d'entiers du plus petit au plus grand en comparant progressivement les éléments d'un tableau avec leurs successeurs, quitte à effectuer un échange (n'hésitez pas à relire cet exercice si besoin). Comme je vous l'avais alors dit, cet algorithme de tri est très rudimentaire et sa complexité était forte.
C'est quoi la complexité ? Comment peut-on mieux trier un tableau ?
Ce sont les deux questions auxquelles nous allons tenter de répondre. Nous commencerons par évoquer quelques algorithmes de tri (sans chercher à être exhaustif) : tri par sélection (rappel), tri à bulles, tri par insertion, tri rapide, tri fusion et tri par tas. Je vous expliquerai le principe avant de vous proposer un implémentation possible. Ensuite, nous expliquerons en quoi consiste la complexité d'un algorithme et aborderons les aspects mathématiques nécessaires de ce chapitre. Enfin, nous étudierons la complexité de ces différents algorithmes de manière empirique en effectuant quelques mesures.
Commençons par évoquer les algorithmes les plus lents (cette notion de lenteur sera précisée et nuancée plus tard) : tri par sélection, tri par insertion et tri à bulles. Nous aurons par la suite besoin de quelques programmes essentiels : initialisation et affichage d'un tableau, échange de valeurs. Je vous fournis de nouveau le code nécessaire ci-dessous.
function init return T_Tableau is
T:T_Tableau ;
subtype Intervalle is integer range 1..100 ;
package Aleatoire is new Ada.numerics.discrete_random(Intervalle) ;
use Aleatoire ;
Hasard : generator ;
begin
Reset(Hasard) ;
for i in T'range loop
T(i) := random(Hasard) ;
end loop ;
return T ;
end init ;
--Afficher affiche les valeurs d'un tableau sur une même ligne
procedure Afficher(T : T_Tableau) is
begin
for i in T'range loop
Put(T(i),4) ;
end loop ;
end Afficher ;
--Echanger est une procédure qui échange deux valeurs : a vaudra b et b vaudra a
procedure Echanger(a : in out integer ; b : in out integer) is
c : integer ;
begin
c := a ;
a := b ;
b := c ;
end Echanger ;
Tri par sélection (ou par extraction)
Principe
1
2
3
4
5
7
3
18
13
7
Nous allons trier le tableau ci-dessus par sélection. Le principe est simple : nous allons chercher le minimum du tableau et l'échanger avec le premier élément :
Rang 1
1
2
3
4
5
7
3
18
13
7
1
2
3
4
5
3
7
18
13
7
Puis on réitère l'opération : on recherche le minimum du tableau (privé toutefois du premier élément) et on l'échange avec le second (ici pas d'échange nécessaire).
Rang 2
1
2
3
4
5
3
7
18
13
7
On réitère à nouveau l'opération : on recherche le minimum du tableau (privé cette fois des deux premiers éléments) et on l'échange avec le troisième.
Rang 3
1
2
3
4
5
3
7
18
13
7
1
2
3
4
5
3
7
7
13
18
On réitère ensuite avec le quatrième élément et on obtient ainsi un tableau entièrement ordonné par ordre croissant. C'est l'un des algorithmes les plus simples et intuitifs. Pour aller plus loin ou pour davantage d'explications, vous pouvez consulter le tutoriel de K-Phoen à ce sujet (langage utilisé : C).
Mise en œuvre
Le code source de l'algorithme de tri par sélection quelque peu modifié par rapport à la fois précédente :
function RangMin(T : T_Tableau ; debut : integer ; fin : integer) return integer is
Rang : integer := debut ;
Min : integer := T(debut) ;
begin
for i in debut..fin loop
if T(i)<Min
then Min := T(i) ;
Rang := i ;
end if ;
end loop ;
return Rang ;
end RangMin ;
function Trier(Tab : T_Tableau) return T_Tableau is
T : T_Tableau := Tab ;
begin
for i in T'range loop
Echanger(T(i),T(RangMin(T,i,T'last))) ;
end loop ;
return T ;
end Trier ;
Tri par insertion
Principe
Le principe du tri par insertion est le principe utilisé par tout un chacun pour ranger ses cartes : on les classe au fur et à mesure. Imaginons que dans une main de 5 cartes, nous ayons déjà trié les trois premières, nous arrivons donc à la quatrième carte. Que fait-on ? Eh bien c'est simple, on la sort du paquet de cartes pour l'insérer à la bonne place dans la partie des cartes déjà triées. Exemple :
1
2
3
4
5
5
9
10
6
7
1
2
3
4
5
5
6
9
10
7
Il faudra ensuite s'occuper du cinquième élément mais là n'est pas la difficulté, car vous vous en doutez peut-être, mais il est impossible d'insérer un élément entre deux autres dans un tableau. Il n'y a pas de case n°1,5 ! Donc "réinsérer" le quatrième élément dans le tableau consistera en fait à décaler tous ceux qui lui sont supérieurs d'un cran vers la droite. Pour aller plus loin ou pour davantage d'explications, vous pouvez consulter le tutoriel de bluestorm à ce sujet (langage utilisé : C) et sa suite utilisant les listes (langage utilisé : OCaml).
Mise en œuvre
Je vous invite à rédiger cet algorithme par vous-même avant de consulter la solution que je vous propose, c'est la meilleure façon de savoir si vous avez compris le principe ou non (d'autant plus que cet algorithme est relativement simple).
function tri_insertion(T : T_Tableau) return T_Tableau is
Tab : T_Tableau := T ;
begin
for i in T'first + 1 .. T'last loop
for j in reverse T'first + 1..i loop
exit when Tab(j-1)<=Tab(j) ;
echanger(Tab(j-1),Tab(j)) ;
end loop ;
end loop ;
return Tab ;
end Tri_insertion ;
L'instruction exit située au cœur des deux boucles peut être remplacée par un if :
if Tab(j-1)<=Tab(j)
then exit ;
else echanger(Tab(j-1),Tab(j)) ;
end if ;
Tri à bulles (ou par propagation)
Principe
Voici enfin le plus "mauvais" algorithme. Comme les précédents il est plutôt intuitif mais n'est vraiment pas efficace. L'algorithme de tri par propagation consiste à inverser deux éléments successifs s'ils ne sont pas classés dans le bon ordre et à recommencer jusqu'à ce que l'on parcourt le tableau sans effectuer une seule inversion. Ainsi, un petit élément sera échangé plusieurs fois avec ses prédécesseurs jusqu'à atteindre son emplacement définitif : il va se propager peu à peu, ou "remonter" vers la bonne position lentement, comme une bulle d'air remonte peu à peu à la surface (j'ai l'âme d'un poète aujourd'hui ^^ ).
Je ne pense pas qu'un exemple soit nécessaire. L'idée (simple, voire simpliste) est donc de parcourir plusieurs fois le tableau jusqu'à obtenir la solution. Vous vous en doutez, cette méthode est assez peu évoluée et demandera de nombreux passages pour obtenir un tableau rangé. Pour aller plus loin ou pour davantage d'explications, vous pouvez consulter le tutoriel de shareman à ce sujet (langage utilisé : C++).
Mise en œuvre
Là encore, vous devriez être capable en prenant un peu de temps, de coder cet algorithme par vous-même.
function Tri_Bulles(T : T_Tableau) return T_Tableau is
Tab : T_Tableau := T ;
Echange_effectue : boolean := true ;
begin
while Echange_effectue loop
--possibilité d'afficher le tableau en écrivant ici
--Afficher(Tab) ;
Echange_effectue := false ;
for i in Tab'first .. Tab'last-1 loop
if Tab(i) > Tab(i+1)
then echanger(Tab(i), Tab(i+1)) ;
Echange_effectue := true ;
end if ;
end loop ;
end loop ;
return Tab ;
end Tri_Bulles ;
Si vous faites quelques essais en affichant Tab à chaque itération, vous vous rendrez vite compte qu'avec cet algorithme le plus grand élément du tableau est immédiatement propager à la fin du tableau dès le premier passage. Il serait donc plus judicieux de modifier les bornes de la deuxième boucle en écrvant :
Tab'first .. Tab'last-1 - k
Où k correspondrait au nombre de fois que le tableau a été parcouru. Autre amélioration possible : puisque les déplacements des grands éléments vers la droite se font plus vite que celui des petits vers la gauche (déplacement maximal de 1 vers la gauche), pourquoi ne pas changer de sens une fois sur deux : parcourir le tableau de gauche à droite, puis de droite à gauche, puis de gauche à droite ... c'est ce que l'on appelle le Tri Cocktail (Shaker Sort), un poil plus efficace.
Enfin, une dernière amélioration mérite d'être signalée (mais non traitée), c'est le Combsort. Il s'agit d'un tri à bulles nettement amélioré puisqu'il peut rivaliser avec les meilleurs algorithmes de tri. L'idée, plutôt que de comparer des éléments successifs, est de comparer des éléments plus éloignés afin d'éviter les tortues, c'est à dire ces petits éléments qui ne se déplacent que d'un seul cran vers la gauche avec le tri à bulles classique. Ce cours n'ayant pas vocation à rédiger tous les algorithmes de tri possibles et imaginables, consultez le lien ci-dessus ou wikipedia pour en savoir plus.
L'algorithme de tri rapide (ou Quick Sort) a un fonctionnement fort différent des algorithmes précédents et un peu (beaucoup) plus compliqué. Le principe de base est simple mais bizarre a priori : on choisit une valeur dans le tableau appelée pivot (nous prendrons ici la première valeur du tableau) et on déplace avant elle toutes celles qui lui sont inférieures et après elle toutes celles qui lui sont supérieures. Puis, on réitère le procédé avec la tranche de tableau inférieure et la tranche de tableau supérieure à ce pivot. Un exemple serait bon :
13
18
9
15
7
Nous prenons le premier nombre en pivot : 13 et nous plaçons les nombres 9 et 7 avant le 13, les nombres 15 et 18 après le 13 :
9
7
13
15
18
Il ne reste plus ensuite qu'à réitérer l'algorithme sur les deux sous-tableaux :
9
7
15
18
Le premier aura comme pivot 9 et sera réorganisé, le second aura comme pivot 15 et ne nécessitera aucune modification. Il restera alors deux sous-sous-tableaux :
7
18
Comme ces sous-sous-tableaux se résument à une seule valeur, l'algorithme s'arrêtera. Cet algorithme est donc récursif et l'une des difficultés est de répartir les valeurs de part et d'autre du nombre pivot. Revenons, à notre tableau initial. Nous allons chercher le premier nombre plus petit que 13 de gauche à droite avec une variable i, et le premier nombre plus grand que 13 de droite à gauche avec une variable j, jusqu'à ce que i et j se rencontrent :
13
18
9
15
7
On trouve 18 et 7. On les inverse et on continue :
13
7
9
15
18
Le rangement est presque fini, il ne reste plus qu'à inverser le pivot avec le 9 :
9
7
13
15
18
Pour aller plus loin ou pour davantage d'explication, vous pouvez consulter le tutoriel de GUILOooo à ce sujet (langages utilisés : C et OCaml).
Mise en œuvre
Cet algorithme va être plus compliqué à mettre en œuvre. Je vous conseille d'essayer par vous-même afin de faciliter la compréhension de la solution que je vous fournis :
function tri_rapide (T : vecteur) return vecteur is
procedure tri_rapide(T : in out vecteur ; premier,dernier : integer) is
index_pivot : integer := (premier+dernier)/2 ;
j : integer := premier + 1;
begin
if premier < dernier
then echanger(T(premier),T(index_pivot)) ;
index_pivot := premier ;
for i in premier+1..dernier loop
if T(i) < T(index_pivot)
then echanger(T(i),T(j)) ;
j := j +1 ;
end if ;
end loop ;
echanger(T(index_pivot),T(j-1)) ;
index_pivot := j-1 ;
tri_rapide(T, premier, Index_pivot-1) ;
tri_rapide(T, Index_pivot+1, dernier) ;
end if ;
end tri_rapide ;
Tab : Vecteur := T ;
begin
tri_rapide(Tab,Tab'first,Tab'last) ;
return Tab ;
end tri_rapide ;
Nous verrons un peu plus tard pourquoi j'ai du utiliser une procédure plutôt qu'une fonction pour effectuer ce tri.
Tri fusion (ou Merge Sort)
Principe
Ah ! Mon préféré. ^^ Le principe est simple mais rudement efficace (un peu moins que le tri rapide toutefois). Prenons le tableau ci-dessous :
8
5
13
7
10
L'idée est de "scinder" ce tableau en cinq cases disjointes que l'on va "refusionner ensuite, mais dans le bon ordre. Par exemple, les deux premières cases, une fois refusionnées donneront :
5
8
Les deux suivantes donneront :
7
13
Et la dernière va rester seule pour l'instant. Ensuite, on va "refusionner" nos deux minitableaux (la dernière case restant encore seule) :
5
7
8
13
Et enfin, on fusionne ce dernier tableau avec la dernière case restée seule depuis le début :
5
7
8
10
13
Vous l'aurez compris, le tri se fait au moment de la fusion des sous-tableaux. L'idée n'est pas si compliquée à comprendre, mais un peu plus ardue à mettre en œuvre. En fait, nous allons créer une fonction tri_fusion qui sera récursive et qui s'appliquera à des tranches de tableaux (les deux moitiés de tableaux, puis les quatre moitiés de moitiés de tableaux, puis ...) avant de les refusionner. Pour aller plus loin ou pour davantage d'explication, vous pouvez consulter le tutoriel de renO à ce sujet (langage utilisé : Python).
Mise en œuvre
Nous aurons besoin de deux fonctions pour effectuer le tri fusion : une fonction fusion qui fusionnera deux tableaux triés en un seul tableau trié ; et une fonction tri_fusion qui se chargera de scinder le tableau initial en sous-tableaux triés avant de les refusionner à l'aide de la précédente fonction.
function fusion(T1,T2 : Vecteur) return Vecteur is
T : Vecteur(1..T1'length + T2'length) ;
i : integer := T1'first ;
j : integer := T2'first ;
begin
if T1'length = 0
then return T2 ;
elsif T2'length = 0
then return T1 ;
end if ;
for k in T'range loop
if i > T1'last and j > T2'last
then exit ;
elsif i > T1'last
then T(k..T'last) := T2(j..T2'last) ; exit ;
elsif j > T2'last
then T(k..T'last) := T1(i..T1'last) ; exit ;
end if ;
if T1(i) <= T2(j)
then T(k) := T1(i) ;
i := i + 1 ;
else T(k) := T2(j) ;
j := j + 1 ;
end if ;
end loop ;
return T ;
end fusion ;
FUNCTION Tri_fusion(T: Vecteur) RETURN Vecteur IS
lg : constant Integer := T'length;
BEGIN
if lg <= 1
then return T ;
else declare
T1 : Vecteur(T'first..T'first-1+lg/2) ;
T2 : Vecteur(T'first+lg/2..T'last) ;
begin
T1 := tri_fusion(T(T'first..T'first-1+lg/2)) ;
T2 := tri_fusion(T(T'first+lg/2..T'last)) ;
return fusion(T1,T2) ;
end ;
end if ;
END Tri_Fusion;
Tri par tas
Noms alternatifs
Le tri par tas porte également les noms suivants :
Tri arbre
Tri Maximier
Heapsort
Tri de Williams
Principe
5
7
3
8
12
6
L'idée du tri pas tas est de concevoir votre tableau tel un arbre. Par exemple, le tableau ci-dessus devra être vu ainsi :
Chaque "case" de l'arbre est appelée nœud, le premier nœud porte le nom de racine, les derniers le nom de feuille. Si l'on est rendu au nœud numéro (indice dans le tableau initial), ses deux feuilles les numéros et .
L'arbre n'est pas trié pour autant. Pour cela nous devrons le tamiser, c'est-à-dire prendre un nombre et lui faire descendre l'arbre jusqu'à ce que les nombres en dessous lui soient inférieurs. Pour l'exemple, nous allons tamiser le premier nœud (le 5).
En dessous de lui se trouvent deux nœuds : 7 et 3. On choisit le plus grand des deux : 7. Comme 7 est plus grand que 5, on les inverse.
On recommence : les deux nœuds situés en dessous sont 8 et 12. Le plus grand est 12. Comme 12 est plus grand que 5, on les inverse.
Vous avez compris le principe du tamisage ? Très bien. Pour trier notre arbre par tas, nous allons le tamiser en commençant, non pas par la racine de l'arbre, mais par les derniers nœuds (en commençant par la fin en quelque sorte). Bien sûr, il est inutile de tamiser les feuilles de l'arbre : elles ne descendront pas plus bas ! Pour limiter les tests inutiles, nous commencerons par tamiser le 3, puis le 7 et enfin le 5. Du coup, nous ne tamiserons que la moitié des nœuds de l'arbre. Faites l'essai, cela devrait vous donner ceci :
Hein ?!? Plus on descend dans l'arbre plus les nombres sont petits, mais c'est pas trié pour autant ! o_O
En effet. ^^ Mais rassurez-vous, il reste encore une étape, un peu plus complexe. Nous allons parcourir notre arbre en sens inverse encore une fois. Nous allons échanger le dernier nœud de notre arbre tamisé (le 3) avec le premier (le 12) qui est également le plus grand nombre le l'arbre.
Une fois cet échange effectué, nous allons tamiser notre nouvelle racine, en considérant que la dernière feuille ne fait plus partie de l'arbre (elle est correctement placée désormais). Ce qui devrait nous donner ceci :
Cette manœuvre a ainsi pour but de placer sur la dernière feuille, le nombre le plus grand, tout en gardant un sous-arbre qui soit tamisé. Il faut ensuite répéter cette manœuvre avec l'avant-dernière feuille, puis l'avant-avant-dernière feuille ... Jusqu'à arriver à la deuxième (et oui, inutile d'échanger la racine avec elle-même, soyons logique). Nous devrions ainsi obtenir ceci :
Cette fois, l'arbre est trié dans le bon ordre, l'algorithme est terminé. Il ne vous reste plus qu'à l'implémenter. ^^
Mise en œuvre
Vous l'aurez deviné je l'espère, il nous faut une procédure tamiser, en plus de notre fonction Tri_tas. Commencez par la créer et l'essayer sur le premier élément comme nous l'avons fait dans cette section avant de vous lancer dans votre fonction de tri. Pensez qu'il doit être possible de limiter la portion de tableau à tamiser et que pour passer d'un nœud à celui du dessous, il faut multiplier par 2 (pour accéder au nœud en dessous à gauche) et éventuellement lui ajouter 1 (pour accéder à celui en dessous à droite).
procedure tamiser(T : in out vecteur ;
noeud : integer ;
max : integer) is
racine : integer := noeud ;
feuille : integer := 2 * noeud ;
begin
while feuille <= max loop
if feuille+1 <= max and then T(feuille)<T(feuille+1)
then feuille := feuille + 1 ;
end if ;
if T(racine)<T(feuille)
then echanger(T(racine), T(feuille)) ;
end if ;
racine := feuille ;
feuille := 2 * racine ;
end loop ;
end tamiser ;
function tri_tas(T : vecteur) return vecteur is
Arbre : vecteur(1..T'length) := T ;
begin
for i in reverse 1..Arbre'length/2 loop
tamiser(Arbre,i,Arbre'length) ;
end loop ;
for i in reverse 2..Arbre'last loop
echanger(Arbre(i),Arbre(1)) ;
tamiser(Arbre,1,i-1) ;
end loop ;
return Arbre ;
end tri_tas ;
Si vous avez dors et déjà testé les programmes ci-dessus sur de grands tableaux, vous avez du vous rendre compte que certains étaient plus rapides que d'autres, plus efficaces. C'est ce que l'on appelle l'efficacité d'un algorithme. Pour la mesurer, la quantifier, on s'intéresse davantage à son contraire, la complexité. En effet, pour mesurer la complexité d'un algorithme il "suffit" de mesurer la quantité de ressources qu'il exige (mémoire ou temps-processeur).
En effet, le simple fait de déclarer un tableau exige de réquisitionner des emplacements mémoires qui seront rendus inutilisables par d'autres programmes comme votre système d'exploitation. Tester l'égalité entre deux variables va nécessiter de réquisitionner temporairement le processeur, le rendant très brièvement inutilisable pour toute autre chose. Vous comprenez alors que parcourir un tableau de 10 000 cases en testant chacune des cases exigera donc de réquisitionner au moins 10 000 emplacements mémoires et d'interrompre 10 000 fois le processeur pour faire nos tests. Tout cela ralentit les performances de l'ordinateur et peut même, pour des algorithmes mal ficelés, saturer la mémoire entraînant l'erreur STORAGE_ERROR : EXCEPTION_STACK_OVERFLOW.
D'où l'intérêt de pouvoir comparer la complexité de différents algorithmes pour ne conserver que les plus efficaces, voire même de prédire cette complexité. Prenons par exemple l'algorithme dont nous parlions précédemment (qui lit un tableau et teste chacune de ses cases) : si le tableau a 100 cases, l'algorithme effectuera 100 tests ; si le tableau à 5000 cases, l'algorithme effectuera 5000 tests ; si le tableau a cases, l'algorithme effectuera tests ! On dit que sa complexité est en .
L'écriture O
Ca veut dire quoi ce zéro ?
Ce n'est pas un zéro mais la lettre O ! Et se lit "grand O de n". Cette notation mathématique signifie que la complexité de l'algorithme est proportionnelle à (le nombre d'éléments contenus dans le tableau). Autrement dit, la complexité vaut "grosso-modo" .
C'est pas "grosso modo égal à n" ! C'est exactement égal à n ! :colere2:
Prenons un autre exemple : un algorithme qui parcourt lui aussi un tableau à éléments. Pour chaque case, il effectue deux tests : le nombre est-il positif ? Le nombre est-il pair ? Combien va-t-il effectuer de tests ? La réponse est simple : deux fois plus que le premier algorithme, c'est à dire . Autrement dit, il est deux fois plus lent. Mais pour le mathématicien ou l'informaticien, ce facteur 2 n'a pas une importance aussi grande que cela, l'algorithme a toujours une complexité proportionnelle au premier, et donc en .
Mais alors tous les algorithmes ont une complexité en si c'est comme ça !
Non, bien sûr. Un facteur 2, 3, 20 ... peut être considéré comme négligeable. En fait, tout facteur constant peut être considéré comme négligeable. Reprenons encore notre algorithme : il parcourt toujours un tableau à éléments, mais à chaque case du tableau, il reparcourt tout le tableau depuis le début pour savoir s'il n'y aurait pas une autre case ayant la même valeur. Combien va-t-il faire de tests ? Pour chaque case, il doit faire tests et comme il y a cases, il devra faire en tout tests. Le facteur n'est cette fois pas constant ! On dira que cet algorithme a une complexité en et, vous vous en doutez, ce n'est pas terrible du tout. Et pourtant, c'est la complexité de certains de nos algorithmes de tris ! :-°
Donc, vous devez commencer à comprendre qu'il est préférable d'avoir une complexité en qu'en . Malheureusement pour nous, en règle général, il est impossible d'atteindre une complexité en pour un algorithme de tri (sauf cas particulier comme avec un tableau déjà trié, et encore ça dépend des algorithmes :( ). Un algorithme de tri aura une complexité optimale quand celle-ci sera en .
Quelques fonctions mathématiques
Qu'est-ce que c'est encore que cette notation ?
C'est une fonction mathématique que l'on appelle le logarithme népérien. Les logarithmes sont les fonctions mathématiques qui ont la croissance la plus faible (en fait elles croissent très très vite au début puis ralentissent par la suite). Inversement, les fonctions exponentielles sont celles qui ont la croissance la plus rapide (très très lentes au début puis de plus en plus rapide).
Mon but ici n'est pas de faire de vous des mathématiciens, encore moins d'expliquer en détail les notions de fonction ou de "grand O", mais pour que vous ayez une idée de ces différentes fonctions, de leur croissance et surtout des complexités associées, je vous en propose quelques-unes sur le graphique ci-dessous :
Légende : Complexité en (e : exponentielle) Complexité en Complexité en (log : logarithme) Complexité en Complexité en
Plus l'on va vers la droite, plus le nombre d'éléments à trier, tester, modifier ... augmente. Plus l'on va vers le haut, plus le nombre d'opérations effectuées augmente et donc plus la quantité de mémoire ou le temps processeur nécessaire augmente. On voit ainsi qu'une complexité en ou , c'est peu ou prou pareil, serait parfaite (on parle de complexité logarithmique) : elle augmente beaucoup moins vite que le nombre d'éléments à trier ! Le rêve. Sauf que ça n'existe pas pour nos algorithmes de tri, donc oubliez-la.
Une complexité en serait donc idéale (on parle de complexité linéaire). C'est possible dans des cas très particuliers : par exemple l'algorithme de tri par insertion peut atteindre une complexité en O(n) lorsque le tableau est déjà trié ou "presque" trié, alors que les algorithmes de tri rapide ou fusion n'en sont pas capables. Mais dans la vie courante, il est rare que l'on demande de trier des tableaux déjà triés. :o
On comprend donc qu'atteindre une complexité en est déjà satisfaisant (on parle de complexité linéarithmique), on dit alors que la complexité est asymptotiquement optimale, bref, on ne peut pas vraiment faire mieux dans la majorité des cas.
Une complexité en , dite complexité quadratique, est courante pour des algorithmes de tri simples (voire simplistes), mais très mauvaise. Si au départ elle ne diffère pas beaucoup d'une complexité linéaire (en ), elle finit par augmenter très vite à mesure que le nombre d'éléments à trier augmente. Donc les algorithmes de tri de complexité quadratique seront réservés pour de petits tableaux.
Enfin, la complexité exponentielle (en ) est la pire chose qui puisse vous arriver. La complexité augmente à vite grand V, de façon exponentielle (logique me direz-vous). N'ajoutez qu'un seul élément et vous aurez beaucoup plus d'opérations à effectuer. Pour un algorithme de tri, c'est le signe que vous coder comme un cochon. :p Attention, les jugements émis ici ne concernent que les algorithmes de tri. Pour certains problèmes, vous serez heureux d'avoir une complexité en seulement .
Un algorithme pour mesurer la complexité ... des algorithmes
Après cette section très théorique, retournons à la pratique. Nous allons rédiger un programme qui va mesurer le temps d'exécution des différents algorithmes avec des tableaux de plus en plus grands. Ces temps seront enregistrés dans un fichier texte de manière à pouvoir ensuite transférer les résultats dans un tableur (Calc ou Excel par exemple) et dresser un graphique. Nous en déduirons ainsi, de manière empirique, la complexité des différents algorithmes. Pour ce faire, nous allons de nouveau faire appel au package Ada.Calendar et effectuer toute une batterie de tests à répétition avec nos divers algorithmes. Le principe du programme sera le suivant :
POUR i ALLANT DE 1 A 100 REPETER
| Créer Tableau Aléatoire de taille i*100
| Mesurer Tri_Selection(Tableau)
| Mesurer Tri_Insertion(Tableau)
| Mesurer Tri_Bulles(Tableau)
| Mesurer Tri_Rapide(Tableau)
| Mesurer Tri_Fusion(Tableau)
| Mesurer Tri_Tas(Tableau)
| Afficher "Tests effectués pour taille" i*100
| incrémenter i
FIN BOUCLE
La boucle devrait effectuer 100 tests, ce qui sera largement suffisant pour nos graphiques. Nous ne dépasserons pas des tableaux de taille 10 000 (les algorithmes lents devraient déjà mettre de 1 à 4 secondes pour effectuer leur tri), car au-delà, vous pourriez vous lassez. Par exemple, il m'a fallu 200s pour trier un tableau de taille 100 000 avec le tri par insertion et 743s avec le tri à bulles alors qu'il ne faut même pas une demi-seconde aux algorithmes rapides pour faire ce travail. Si vous le souhaitez, vous pourrez reprendre ce principe avec des tableaux plus importants pour les algorithmes plus rapides (vous pouvez facilement aller jusqu'à des tableaux de taille 1 million).
Mais que vont faire ces procédures Mesurer ?
C'est simple, elles doivent :
ouvrir un fichier texte ;
lire "l'heure" ;
exécuter l'algorithme de tri correspondant ;
lire à nouveau "l'heure" pour en déduire la durée d'exécution ;
enregistrer la durée obtenue dans le fichier ;
fermer le fichier ;
Cela impliquera de créer un type de pointeur sur les fonctions de tri. Voici le code source du programme :
procedure sort is
type T_Ptr_Fonction is access function(T : Vecteur) return Vecteur ;
type T_Tri is (SELECTION, INSERTION, BULLES, FUSION, RAPIDE, TAS) ;
procedure mesurer(tri : T_Ptr_Fonction; T : Vecteur; choix : T_Tri) is
temps : time ;
duree : duration ;
U :Vecteur(T'range) ;
F : File_Type ;
begin
case choix is
when SELECTION => open(F,Append_file,"./mesures/selection.txt") ;
when INSERTION => open(F,Append_file,"./mesures/insertion.txt") ;
when BULLES => open(F,Append_file,"./mesures/bulles.txt") ;
when FUSION => open(F,Append_file,"./mesures/fusion.txt") ;
when RAPIDE => open(F,Append_file,"./mesures/rapide.txt") ;
when TAS => open(F,Append_file,"./mesures/tas.txt") ;
end case ;
temps := clock ;
U := Tri(T) ;
duree := clock - temps ;
put(F,float(duree),Exp=>0) ;
new_line(F) ;
close(F) ;
end mesurer ;
tri : T_Ptr_Fonction ;
F : File_Type ;
begin
create(F,Append_file,"./mesures/selection.txt") ; close(F) ;
create(F,Append_file,"./mesures/insertion.txt") ; close(F) ;
create(F,Append_file,"./mesures/bulles.txt") ; close(F) ;
create(F,Append_file,"./mesures/fusion.txt") ; close(F) ;
create(F,Append_file,"./mesures/rapide.txt") ; close(F) ;
create(F,Append_file,"./mesures/tas.txt") ; close(F) ;
for i in 1..100 loop
declare
T : Vecteur(1..i*100) ;
begin
generate(T,0,i*50) ;
tri := Tri_select'access ;
mesurer(tri,T,SELECTION) ;
tri := Tri_insertion'access ;
mesurer(tri,T,INSERTION) ;
tri := Tri_bulles'access ;
mesurer(tri,T,BULLES) ;
tri := Tri_fusion'access ;
mesurer(tri,T,FUSION) ;
tri := Tri_rapide'access ;
mesurer(tri,T,RAPIDE) ;
tri := Tri_tas'access ;
mesurer(tri,T,TAS) ;
end ;
put("Tests effectues pour la taille ") ; put(i*100) ; new_line;
end loop ;
end sort ;
Traiter nos résultats
A l'aide du programme précédent, vous devez avoir obtenu six fichiers textes contenant chacun 100 valeurs décimales.
Et j'en fais quoi maintenant ? Je vais pas tout comparer à la main !
Bien sûr que non. Ouvrez donc un tableur (tel Excel ou Calc d'OpenOffice) et copiez-y les résultats obtenus. Sélectionnez les valeurs obtenues puis cliquez sur Insertion>Diagramme afin d'obtenir une représentation graphique des résultats obtenus. Je vous présente ci-dessous les résultats obtenus avec mon vieux PC :
Avant même de comparer les performances de nos algorithmes, on peut remarquer une certaine irrégularité : des pics et des creux apparaissent et semblent (en général) avoir lieu pour tous les algorithmes. Ces pics et ces creux correspondent aux pires et aux meilleurs cas possibles. En effet, si notre programme de génération aléatoire de tableaux vient à créer un tableau quasi-trié, alors le temps mis par certains algorithmes chutera drastiquement. Inversement, certaines configurations peuvent être réellement problématiques à certains algorithmes : prenez un tableau quasi-trié mais dans le mauvais ordre ! Ce genre de tableau est catastrophique pour un algorithme de tri à bulles qui devra effectuer un nombre de passages excessif : il suffit, pour s'en convaincre, de regarder le dernier pic de la courbe jaune ci-dessus (tri à bulles) ; d'ailleurs ce pic est nettement atténué sur la courbe orange (tri par insertion) et quasi inexistant sur la courbe bleu (tri par sélection).
Qui plus est, il apparaît assez nettement que le temps de traitement des algorithmes rapides (tri rapide, tri fusion et tri par tas) est quasiment négligeable par rapport à celui des algorithmes lents (tri par insertion, tri par sélection et tri à bulles), au point que seuls ces derniers apparaissent sur le graphique.
Pour y voir plus clair, je vous propose de traiter nos chiffres avec un peu plus de finesse : nous allons distinguer les algorithmes lents des algorithmes rapides et nous allons lisser nos résultats. Par lisser, j'entends modifier nos résultats pour ne plus être gênés par ces pics et ces creux et voir apparaître une courbe plus agréable représentant la tendance de fond.
Lissage des résultats par moyenne mobile : Pour ceux qui se demanderaient ce qu'est ce lissage par moyenne mobile, voici une explication succincte (ce n'est pas un cours de statistiques non plus). Au lieu de traiter nos 100 nombres, nous allons créer une nouvelle liste de valeurs. La première valeur est obtenue en calculant la moyenne des 20 premiers nombres (du 1er au 20ème), la seconde est obtenu en calculant la moyenne des nombres entre le 2nd et le 21ème, la troisième valeur est obtenue en calculant la moyenne des nombres entre le 3ème et le 22ème ... La nouvelle liste de valeurs est ainsi plus homogène mais aussi plus courte (il manquera 20 valeurs).
Algorithmes lents
Algorithmes rapides
Ainsi retravaillés, nos résultats sont plus lisibles et on voit apparaître qu'en moyenne, l'algorithme le plus efficace est le tri rapide, puis viennent le tri par tas et le tri fusion. Mais même le tri fusion reste, en moyenne, en dessous de 0,025 seconde pour un tableau à 10 000 éléments sur mon vieil ordinateur (son score est sûrement encore meilleur chez vous), ce qui est très très loin des performances des trois autres algorithmes. Pour les trois plus lents, on remarque que le "pire" d'entre eux est, en moyenne, le tri à bulles, puis viennent le tri par insertion et le tri par sélection (avec des écarts de performance toutefois très nets entre eux trois).
Le lissage par moyenne mobile nous permet également de voir se dégager une tendance, une courbe théorique débarrassées des impuretés (pire cas et meilleur cas). Si l'on considère les algorithmes lents, on distingue un début de courbe en U, même si le U semble très écrasé par l'algorithme de tri par sélection. Cela nous fait donc penser à une complexité en où n est le nombre d'éléments du tableau.
Et pourquoi pas en ?
Prenez un tableau à éléments que l'on voudrait trier avec le pire algorithme : le tri à bulles. Dans le pire des cas, le tableau est trié en sens inverse et le plus petit élément est donc situé à la fin. Et comme le tri à bulle ne déplace le plus petit élément que d'un seul cran à chaque passage, il faudra donc effectuer passages pour que ce minimum soit à sa place et le tableau trié. De plus, à chaque itération, l'algorithme doit effectuer comparaison (et au plus échanges). D'où un total de comparaisons. Or, , donc la complexité est "de l'ordre de" . Dans le pire cas, l'algorithme de tri à bulles a une complexité en . Cette famille d'algorithme a donc une complexité quadratique et non exponentielle.
Considérons maintenant nos trois algorithmes rapides, leur temps d'exécution est parfaitement négligeable à côté des trois précédents, leurs courbes croissent peu : certaines semblent presque être des droites. Mais ne vous y trompez pas, leur complexité n'est sûrement pas linéaire, ce serait trop beau. Elle est toutefois linéarithmique c'est-à-dire en . Ces trois algorithmes sont donc asymptotiquement optimaux.
Par exemple, notre algorithme de tri fusion est un tri en place : nous n'avons pas créer de second tableau pour effectuer notre tri afin d'économiser la mémoire, denrée rare si l'on trie de très grands tableaux (plusieurs centaines de millions de cases). Une variante consiste à ne pas l'effectuer en place : on crée alors un second tableau et l'opération de fusion gagne en rapidité. Dans ce cas, l'algorithme de tri fusion acquièrent une complexité comparable à celle du tri fusion en réalisant moins de comparaisons, mais devient gourmande en mémoire.
De la même manière, nous avons évoqué le Combsort qui est une amélioration du tri à bulles et qui permet à notre "pire" algorithme de côtoyer les performances des "meilleurs". Encore un dernier exemple, le "lent" algorithme de tri par insertion atteint une complexité linéaire en sur des tableaux quasi-triés alors que l'algorithme de tri rapide garde sa complexité linéarithmique en .
Comme je vous l'avais dit en introduction, ce chapitre n'est pas fondamental à la compréhension du reste du cours sur le langage Ada. En revanche, il vous aura permis de vous interroger sur l'efficacité des algorithmes que vous rédigez. Programmer, ce n'est pas seulement parvenir à un résultat, c'est aussi faire en sorte que notre programme soit le moins gourmand en mémoire ou en temps processeur. Où en serions-nous dans le traitement du génome humain si nous n'avions utilisé que des algorithmes bourrins ? J'espère également que ce chapitre vous aura fait prendre conscience de l'importance des Mathématiques en Informatique et notamment que l'Algorithmique en constitue une branche à part entière.
Le chapitre que nous allons aborder est très théorique et traite de diverses notions ayant trait à la mémoire de l'ordinateur : comment est-elle gérée ? Comment les informations y sont-elles représentées ? ... Nous allons passer le plus clair du chapitre à ne pas parler de programmation (étrange me direz-vous pour un cours de programmation :D ) mais ce n'est que pour mieux revenir sur les types Integer, Character et Float, sur de nouveaux types (Long_Long_Float, Long_Long_Integer... ) ou sur certaines erreurs vues au fil du cours.
Chaque partie de ce chapitre abordera la manière dont l'ordinateur représente les nombres entiers, décimaux ou les caractères en mémoire. Ce sera l'occasion de parler binaire, hexadécimal, virgule flottante ... avant de soulever certains problèmes liés à ces représentations et d'en déduire quelques bonnes pratiques.
Nous allons essayer au cours des parties suivantes de comprendre comment l'ordinateur s'y prend pour représenter les nombres entiers, les caractères ou les nombres décimaux, car cela a des implications sur la façon de programmer. En effet, depuis le début, nous faisons comme s'il était normal que l'ordinateur sache compter de - 2 147 483 648 à 2 147 483 647, or je vous rappelle qu'un ordinateur n'est jamais qu'un amas de métaux et de silicone. Alors comment peut-il compter ? Et pourquoi ne peut-il pas compter au-delà de 2 147 483 647 ? Que se passe-t-il si l'on va au-delà ? Comment aller au delà ? Reprenons tout à la base.
Tout d'abord, un ordinateur fonctionne à l'électricité (jusque là rien de révolutionnaire) et qu'avec cette électricité nous avons deux états possibles : éteint ou allumé.
Eh ! Tu me prends pour un idiot ou quoi ? :colere2:
Bien sûr que non, mais c'est grâce à ces deux états de l'électricité que les Humains ont pu créer des machines aussi perfectionnées capables d'envoyer des vidéos à l'autre bout du monde. En effet, à chaque état peut-être associé un nombre :
0
1
Lorsque le courant passe, cela équivaut au chiffre 1, lorsqu'il ne passe pas, ce chiffre est 0. De même lorsqu'un accumulateur est chargé, cela signifie qu'un 1 est en mémoire, s'il est déchargé, le chiffre 0 est enregistré en mémoire. Nos ordinateurs ne disposent donc que de deux chiffres 0 et 1. Nous comptons quant à nous avec 10 chiffres (0, 1, 2 ... 8, 9) : on dit que nous comptons en base 10 ou décimale. Les ordinateurs comptent donc en base 2, aussi appelé binaire. Les chiffres 1 et 0 sont appelés bits, pour binary digits c'est à dire chiffre binaire.
Mais, comment faire un 2 ou un 3 ? o_O
Il faut procéder en binaire comme nous le faisons en base 10 : lorsque l'on compte jusqu'à 9 et que l'on a épuisé tous nos chiffres, que fait-on ? On remet le chiffre des unités à 0 et on augmente la dizaine. Eh bien c'est pareil pour le binaire : après 0 et 1, nous aurons donc 10 puis 11. On peut ensuite ajouter une "centaine" et recommencer. Voici une liste des premiers nombres en binaire :
Décimal
Binaire
0
0000
1
0001
2
0010
3
0011
4
0100
5
0101
6
0110
7
0111
8
1000
9
1001
10
1010
Conversions entre décimal et binaire
Vous aurez remarqué les répétitions : pour les bits des "unités" on écrit un 0 puis un 1, puis un 0 ... pour les bits des "dizaines" on écrit deux 0 puis deux 1, puis deux 0 ... pour les bits des "centaines", on écrit quatre 0, puis quatre 1, puis quatre 0 ... et ainsi de suite. Mais il y a une ombre au tableau. Nous n'allons pas faire un tableau allant jusqu'à 2 147 483 647 pour pouvoir le convertir en binaire ! Nous devons trouver un moyen de convertir rapidement un nombre binaire en décimal et inversement.
Conversion binaire => décimal
Imaginons que nous recevions le signal suivant :
Ce message correspond au nombre binaire 10110 qui se décompose en 0 "unités", 1 "dizaine", 1 "centaine", 0 "millier" et 1 "dizaine de millier". Ce qui s'écrirait normalement :
Sauf qu'en binaire, on ne compte pas avec dix chiffres mais avec seulement deux ! Il n'y a pas de "dizaines" ou de "centaines". Donc en binaire notre nombre correspond en fait à :
Ainsi, il suffit donc d'effectuer ce calcul pour trouver la valeur en base 10 de 10110 et de connaître les puissances de deux :
Autre méthode pour effectuer la conversion, il suffit de dresser le tableau ci-dessous. Dans la première ligne, on écrit les puissances de 2 : 1, 2, 4, 8, 16 ... Dans la seconde ligne on écrit les bits :
16
8
4
2
1
1
0
1
1
0
Il y va ainsi une fois 2, plus une fois 4 plus une fois 16 (et 0 fois pour le reste), d'où 22 !
Conversion décimal => binaire
Imaginons, cette fois que nous souhaitions envoyer en message le nombre 13. Pour cela, nous allons dresser le même tableau que précédemment :
8
4
2
1
-
-
-
-
Et posons-nous la question : dans 13 combien de fois 8 ? Une fois bien-sûr ! Et il reste 5. D'où le tableau :
8
4
2
1
1
-
-
-
Maintenant, recommençons ! Dans 5 combien de fois 4 ? Une fois et il reste 1 !
8
4
2
1
1
1
-
-
Dans 1 combien de fois 2. Zéro fois, logique. Et dans 1 combien de fois 1 : 1 fois.
8
4
2
1
1
1
0
1
Donc le nombre 13 s'écrit 1101 en binaire. Le tour est joué.
Retour sur le langage Ada
Représentation des Integer en Ada
Vous avez compris le principe ? Si la réponse est encore non, je vous conseille de vous entraîner à faire diverses conversions avant d'attaquer la suite, car nous n'en sommes qu'au B-A-BA. En effet, les ordinateurs n'enregistre pas les informations bits par bits, mais plutôt par paquets. Ces paquets sont appelés octets, c'est à dire des paquets de 8 bits (même s'il est possible de faire des paquets de 2, 4 ou 9 bits).
Pour enregistrer un Integer, le langage Ada utilise non pas un seul mais quatre octets, c'est à dire bits ! Avec un seul bit, on peut coder deux nombres (0 et 1), avec deux bits on peut coder quatre nombres (0, 1, 2, 3), avec trois bits on peut coder huit nombres ... avec 32 bits, on peut ainsi coder nombres, soit 4 294 967 296 nombres.
Mais la difficulté ne s'arrête pas là. En effet, le plus grand Integer n'est pas 4 294 967 296, mais 2 147 483 647 (c'est à dire presque la moitié). Pourquoi ? Tout simplement parce qu'il faut partager ces 4 294 967 296 nombres en deux : les positifs et les négatifs. Comment les distinguer ?
La réponse est simple : tous les Integer commençant par un 0 seront positifs (exemple : 00101001 10011101 10100011 11111001) ; tous les integer commençant par un 1 seront négatifs (exemple : 10101001 10011101 10100011 11111001). Ce premier bit est appelé bit de poids fort. Facile hein ? Eh bien non ! :colere2: Car il y a encore un problème : on se retrouve avec deux zéros !
C'est dommage et cela complique les opérations d'un point de vue électronique. Du coup, il faut décaler les nombres négatifs d'un cran : le nombre 10000000 00000000 00000000 00000000 correspondra non pas à mais à . Le premier 1 signifie que le nombre est négatif, les 31 zéros, si on les convertit en base 10, devraient donner 0, mais avec ce décalage, on doit ajouter 1, ce qui nous donne - 1 !
Conséquence immédiate : l'Overflow et les types long
OUF ! :waw: C'est un peu compliqué tout ça ... Et ça sert à quoi ?
Patience, je vous entraîne peu à peu dans les méandres de l'informatique afin de mieux revenir sur notre sujet : le langage Ada et la programmation. Cette façon de coder les nombres entiers, qui n'est pas spécifique au seul langage Ada, a deux conséquences. Tout d'abord le plus grand Integer positif est 2 147 483 647 (), quand le plus petit Integer négatif est - 2 147 483 648 () : il y a un décalage de 1 puisque 0 est codé comme un positif et pas comme un négatif par la machine.
Deuxième conséquence, nous n'avons que nombres à notre disposition, dont le plus grand est seulement . C'est très largement suffisant en temps normal, mais pour des calculs plus importants, cela peut s'avérer un peu juste (souvenez-vous seulement des calculs de factorielles). En effet, si vous dépassez ce maximum, que se passera-t-il ? Eh bien plusieurs possibilités. Soient vous y allez façon "déménageur" en rédigeant un code faisant clairement appel à des nombres trop importants :
n : = 2**525 ;
p := Integer'last + 1 ;
Et alors, le compilateur vous arrêtera tout de suite par un doux message : value not in range of type "Standard.Integer". Ou bien vous y allez de façon "masquée" ( :zorro: ), le compilateur ne détectant rien (une boucle itérative ou récursive, un affichage du type Put(Integer'last+1);). Vos nombres devenant trop grands, ils ne peuvent plus être codés sur seulement quatre octets, il y a ce que l'on appelle un dépassement de capacité (aussi appelé overflow [j'adore ce mot :ange: ]). Vous vous exposez alors à deux types d'erreurs : soit votre programme plante en affichant une jolie erreur du type
Soit il ne détecte pas l'erreur (c'est ce qui est arrivé avec notre programme de calcul de factorielles) : le nombre positif devient trop grand, il "déborde" sur le bit de poids fort normalement réservé au signe, ce qui explique que nos factorielles devenaient étrangement négatives.
Comment remédier à ce problème si l'on souhaite par exemple connaître la factorielle de 25 ?
Eh bien le langage Ada a tout prévu. Si les Integer ne suffisent plus, il est possible d'utiliser d'autres types : Long_Integer (avec le package Ada.Long_Integer_Text_IO) et Long_Long_Integer (avec le package Ada.Long_Long_Integer_Text_IO). Les Long_Integer sont codés sur 4 octets soit 32 bits comme les Integer. Pourquoi ? Eh bien cela dépend de vos distributions en fait. Sur certaines plateformes, les Integer ne sont codés que sur 16 bits soit 2 octets d'où la nécessité de faire appel aux Long_Integer. Pour augmenter vos capacités de calcul, utilisez donc plutôt les Long_Long_Integer qui sont codés sur 8 octets soit 64 bits. Ils s'étendent donc de +9 223 372 036 854 775 807 à -9 223 372 036 854 775 808, ce qui nous fait fois plus de nombres que les Long_Integer.
Utiliser les bases
En Ada, il est possible de travailler non plus avec des nombres entiers en base 10 mais avec des nombres binaires ou des nombres en base 3, 5, 8, 16 ...On parlera d'Octal pour la base 8 et d'hexadécimal pour la base 16 (bases très utilisées en Informatique). Par exemple, nous savons que le nombre binaire 101 correspond au nombre 5. Pour cela, nous écrirons :
N : Integer ;
BEGIN
N := 2#101# ;
Put(N) ;
Le premier nombre (2) correspond à la base. Le second (101) correspond au nombre en lui-même exprimé dans la base indiquée : Attention ! En base 2, les chiffres ne doivent pas dépasser 1. Chacun de ces nombres doit être suivi d'un dièse (#). Le souci, c'est que ce programme affichera ceci :
5
Il faudra donc modifier notre code pour spécifier la base voulue : Put(N,Base => 2) ; ou Put(N,5,2) ; (le 5 correspondant au nombre de chiffres que l'on souhaite afficher). Votre programme affichera alors votre nombre en base 2.
Il sera possible d'écrire également :
N := 8#27# --correspond au nombre 7+ 8*2 = 23
N := 16#B# --en hexadécimal, A correspond à 10 et B à 11
Il est même possible d'écrire un exposant à la suite de notre nombre :
N := 2#101#E3 ;
Notre variable N est donc donnée en base 2, elle vaut donc 101 en binaire, soit 5. Mais l'exposant E3 signifie que l'on doit multiplier 5 par . La variable N vaut donc en réalité 40. Ou, autre façon de voir la chose : notre variable N ne vaut pas 101 (en binaire bien sûr) mais 101000 (il faut en réalité ajouter 3 zéros).
Imposer la taille
Imaginez que vous souhaitiez réaliser un programme manipulant des octets. Vous créez un type modulaire T_Octet de la manière suivante :
Type T_Octet is mod 2**8 ;
Vous aurez ainsi des nombres allant de 0000 0000 jusqu'à 1111 1111. Sauf que pour les enregistrer, votre programme va tout de même réquisitionner 4 octets. Du coup, l'octet 0100 1000 sera enregsitré ainsi en mémoire : 00000000 00000000 0000000001001000. Ce qui nous fait une perte de trois octets. Minime me direz-vous. Sauf que si l'on vient à créer des tableaux d'un million de cases de types T_Octets, pour créer un nouveau format de fichier image par exemple, nous perdrons pour rien. Il est donc judicieux d'imposer certaines contraintes en utilisant l'attribut 'Size de la sorte :
Type T_Octet is mod 2**8 ;
For T_Octet'size use 8 ;
Ainsi, nos variables de type T_Octet, ne prendront réellement que 1 octet en mémoire.
Avant de nous attaquer à la représentation des décimaux et donc des Float, qui est particulièrement complexe, voyons rapidement celle du texte. Vous savez qu'un String n'est rien de plus qu'un tableau de characters et qu'un Unbounded_String est en fait une liste de Characters. Mais comment sont représentés ces characters en mémoire ? Eh bien c'est très simple, l'ordinateur n'enregistre pas des lettres mais des nombres.
Hein ? Et comment il retrouve les lettres alors ?
Grâce à une table de conversion. L'exemple le plus connu est ce que l'on appelle la table ASCII (American Standard Code for Information Interchange). Il s'agit d'une table de correspondance entre des characters et le numéro qui leur est attribué. Cette vieille table (elle date de 1961) est certainement la plus connue et la plus utilisée. La voici en détail :
Comme vous pouvez le voir, cette table contient 128 caractères allant de 'A' à 'z' en passant par '7', '#' ou des caractères non imprimables comme la touche de suppression ou le retour à la ligne. Vous pouvez dors et déjà constater que seuls les caractères anglo-saxons sont présents dans cette table (pas de 'ö' ou de 'è') ce qui est contraignant pour nous Français. De plus, cette table ne comporte que 128 caractères, soit , Chaque caractère ne nécessite donc que 7 bits pour être codé en mémoire, même pas un octet ! Heureusement, cette célèbre table s'est bien développée depuis 1961, donnant naissance à de nombreuses autres tables. Le langage Ada n'utilise donc pas la table ASCII classique mais une sorte de table ASCII modifiée et étendue. En utilisant le 8ème bit, cette table permet d'ajouter 128 nouveaux caractères et donc de bénéficier de caractères en tout.
Donc tu nous mens depuis le début ! Il est possible d'utiliser le 'é' ! :colere:
Non, je ne vous ai pas menti et vous ne pouvez pas tout à fait utiliser les caractères accentués comme les autres. Ainsi si vous écrivez ceci :
...
C : Character
BEGIN
C := 'ê' ; Put(C) ;
...
Vous aurez droit à ce genre d'horreur :
Û
Vous devrez donc écrire les lignes ci-dessous si vous souhaitez obtenir un e minuscule avec un accent circonflexe :
...
C : Character
BEGIN
C := Character'val(136) ; Put(C) ;
...
Enfin, dernière remarque, les caractères imprimés dans la console ne correspondent pas toujours à ceux imprimés dans un fichier texte. Ainsi du caractère N°230 : il vaut 'æ' dans un fichier texte mais 'µ' dans la console. Je vous fournis ci-dessous la liste des caractères tels qu'ils apparaissent dans un fichier texte :
Vous remarquerez les ressemblances avec la table ASCII, mais aussi les différences quant aux caractères spéciaux. Le character n°12 correspond au saut de page et le n°9 à la tabulation.
Nous arrivons enfin à la partie la plus complexe. S'il vous paraît encore compliqué de passer du binaire au décimal avec les nombres entiers, je vous conseille de relire la sous-partie concernée avant d'attaquer celle-ci car la représentation des float est un peu tirée par les cheveux. Et vous devrez avoir une notion des puissances de 10 pour comprendre ce qui suit (je ne ferai pas de rappels, il ne s'agit pas d'un cours de Mathématiques).
Représentation des float
Représentation en base 10
Avant toute chose, nous allons voir comment écrire différemment le nombre dans notre base 10. Une convention, appelée écriture scientifique, consiste à n'écrire qu'un seul chiffre, différent de 0, avant la virgule : . Mais pour compenser cette modification, il faut multiplier l résultat obtenu par 1000 pour indiquer qu'en réalité il faut décaler la virgule de trois chiffres vers la droite. Ainsi, s'écrira ou même .
Eh ! o_O Ça me rappelle les écritures bizarres qu'on obtient quand on utilise Put( ) avec des float !
Eh oui, par défaut, c'est ainsi que sont représentés les nombres décimaux par l'ordinateur, le E3 signifiant . Il suffit donc simplement de modifier l'exposant (le 3) pour décaler la virgule vers la gauche ou la droite : on parle ainsi de virgule flottante.
Représentation en binaire
Cette écriture en virgule flottante prend tout son sens en binaire : pour enregistrer le nombre il faudra enregistrer en réalité le nombre . Mais comme le chiffre avant la virgule ne peut pas être égale à 0, ce ne peut être qu'un 1 en binaire ! Autrement dit, il faudra enregistrer trois nombres :
le signe : 1 (le nombre est négatif)
l'exposant : 11 (pour E3, rappelons que 3 s'écrit 11 en binaire)
la mantisse : 0011 (on ne conserve pas le 1 avant la virgule, c'est inutile)
D'où une écriture en mémoire qui ressemblerait à cela :
Signe
Exposant
Mantisse
1
11
0011
Pourquoi ne pas avoir enregistré seulement deux nombres ? La partie entière et la partie décimale ?
En simple précision, les nombres à virgule flottante sont représentés sur 4 octets. Comment se répartissent les différents bits ? C'est simple :
D'abord 1 bit pour le signe,
puis 8 bits pour l'exposant,
enfin le reste (soit 23 bits) pour la mantisse.
Sauf que l'exposant, nous venons de le voir peut être négatif et qu'il ne va pas être simple de gérer des exposants négatifs comme nous le faisions avec les Integer. Pas question d'avoir un bit pour le signe de l'exposant et 7 pour sa valeur absolue ! Le codage est un peu compliqué : on va décaler. L'exposant pourra aller de -127 à +128. Si l'exposant vaut 0000 0000, cela correspondra au plus petit des exposants : . Il y a un décalage de 127 par rapport à l'encodage normal des Integer.
Un exemple
Nous voulons convertir le nombre 6,75 en binaire et en virgule flottante. Tout d'abord, convertissons-le en binaire :
Donc notre nombre s'écrira 110,11. Passons en écriture avec virgule flottante : ou . Rappelons qu'il faut décaler notre exposant de 127 : . Et comme 129 s'écrit 10000001 en binaire, cela nous donnera :
Signe
Exposant
Mantisse
0
1000 0001
1011000 00000000 00000000
Cas particuliers
Ton raisonnement est bien gentil, mais le nombre 0 n'a aucun chiffre différent de 0 avant la virgule !
En effet, ce raisonnement n'est valable que pour des nombres dont l'exposant n'est ni 0000 0000 ni 1111 1111, c'est à dire si les nombres sont normalisés. Dans le cas contraire, on associe des valeurs particulières :
Exposant 0 Mantisse 0 : le résultat est 0.
Exposant 0 : on tombe dans le cas des nombres dénormalisés, c'est à dire dont le chiffre avant la virgule est 0 (nous n'entrerons pas davantage dans le détail pour ce cours)
Exposant 1111 1111 Mantisse 0 : le résultat est l'infini.
Exposant 1111 1111 : le résultat n'est pas un nombre (Not A Number : NaN).
Remarquez que du coup, pour les flottants, il est possible d'avoir et ! Bien. Vous connaissez maintenant les bases du codage des nombres flottants (pour plus de précisions, voir le tutoriel de Mewtow), il est grand temps de voir les implications que cela peut avoir en Ada.
Implications sur le langage Ada
De nouveaux types pour gagner en précision
Bien entendu, vous devez vous en doutez, il existe un type Short_Float (mais pas short_short_float), et il est possible de travailler avec des nombres à virgule flottante de plus grande précision à l'aide des types Long_Float (codé sur 8 octets au lieu de 4, c'est le format double précision) et Long_Long_Float (codé sur 16 octets). Vous serez alors amenés à utiliser les packages Ada.Short_Float_IO, Ada.Long_Float_IO et Ada.Long_Long_Float_IO (mais ai-je encore besoin de le spécifier ?).
Problèmes liés aux arrondis
Les nombres flottants posent toutefois quelques soucis techniques. En effet, prenons un nombre de type float. Il dispose de 23 bits pour coder sa mantisse, plus un "bit fantôme" puisque le chiffre avant la virgule n'a pas besoin d'être codé. Donc il est possible de coder un nombre de 24 chiffres, mais pas de 25 chiffres. Par exemple , en binaire, correspond à un nombre de 26 chiffres : le premier et le dernier vaudront 1, les autres 0. Essayons le code suivant :
...
x : Float ;
Begin
x := 2.0**25 ;
put(integer(x), base => 2) ; new_line ; --on affiche son écriture en binaire (c'est un entier)
put(x, exp => 0) ; new_line ; --et on affiche le nombre flottant
x := x + 1.0 ; --on incrémente
put(integer(x), base => 2) ; new_line ; --et rebelote pour l'affichage
put(x, exp => 0) ;
...
Que nous renvoie le programme ? Deux fois le même résultat ! o_O Etrange. Pourtant nous avons bien incrémenté notre variable x ! Je vous ai déjà donné la réponse dans le précédent paragraphe : le nombre de bits nécessaire pour enregistrer les chiffres (on parle de chiffres significatifs) est limité à 23 (24 en comptant le bit avant la virgule). Si nous dépassons ces capacités, il ne se produit pas de plantage comme avec les Integer, mais le processeur renvoie un résultat arrondi d'où une perte de précision.
De même, si vous testez le code ci-dessous, vous devriez avoir une drôle de surprise. Petite explication sur ce code : on effectue une boucle avec deux compteurs. L'un est un flottant que l'on augmente de 0.1 à chaque itération, l'autre est un integer que l'on incrémente. Nous devrions donc avoir 1001 itérations et à la fin, n vaudra 1001 et x vaudra 101.0. Logique non ? ;) Eh bien testez donc ce code.
...
x := 0.0 ;
n := 0 ;
while x < 100.0 loop
x := x + 0.1 ;
n := n + 1 ;
end loop ;
Put("x vaut ") ; put(x,exp=>0) ; new_line ;
Put_line("n vaut" & Integer'image(n)) ;
Alors, que vaut n ? 1001, tout va bien. Mais que vaut x ? 100.09904 !!! o_O Qu'a-t-il bien pu se passer encore ? Pour comprendre, il faut savoir que le nombre décimal 0.1 s'écrit approximativement 0.000 1100 1100 1100 1100 1100 en binaire ... Cette écriture est infinie, donc l'ordinateur doit effectuer un arrondi. Si la conversion d'un nombre entier en binaire tombe toujours juste, la conversion d'un nombre décimal quant à elle peut poser problème car l'écriture peut être potentiellement infinie. Et même chose lorsque l'on transforme le nombre binaire en nombre décimal, on ne retrouve pas 0.1 mais une valeur très proche ! Cela ne pose pas de véritable souci lorsque l'on se contente d'effectuer une addition. Mais lorsque l'on effectue de nombreuses additions, ce problème d'arrondi commence à se voir. La puissance des ordinateurs et la taille du type float (4 octets) est largement suffisante pour pallier dans la plupart des cas à ce problème d'arrondi en fournissant une précision bien supérieure à nos besoins, mais cela peut toutefois être problématique dans des cas où la précision est de mise.
Car si cette perte de précision peut paraître minime, elle peut parfois avoir de lourdes conséquences : imaginez que votre programme calcule la vitesse qu'une fusée doive adopter pour se poser sans encombre sur Mars en effectuant pour cela des milliers de boucles ou qu'il serve à la comptabilité d'une grande banque américaine gérant des millions d'opérations à la seconde. Une légère erreur d'arrondie qui viendrait à se répéter des milliers ou des millions de fois pourrait à terme engendrer la destruction de votre fusée ou une crise financière mondiale (comment ça ? Vous trouvez que j'exagère ? :D ).
Plus simplement, ces problèmes d'arrondis doivent vous amener à une conclusion : les types flottants ne doivent pas être utilisés à la légère ! Partout où les types entiers sont utilisables, préférez-les aux flottants (vous comprenez maintenant pourquoi depuis le début, je rechigne à utiliser le type Float). N'utilisez pas de flottant comme compteur dans une boucle car les problèmes d'arrondis pourraient bien vous jouer des tours. ^^
Delta et Digits
Toujours pour découvrir les limites du type float, testez le code ci-dessous :
...
x : float ;
begin
x:=12.3456789;
put(x,exp=>0) ;
...
Votre programme devrait afficher la valeur de x, or il n'affiche que :
12.34568
Eh oui, votre type float ne prend pas tous les chiffres ! Il peut manipuler de très grands ou de très petits nombres, mais ceux-ci ne doivent pas, en base 10, excéder 7 chiffres significatifs, sinon ... il arrondit ! Ce n'est pas très grave, mais cela constitue encore une fois une perte de précision. Alors certes vous pourriez utiliser le type Long_Float qui gère 16 chiffres significatifs, ou long_long_Float qui en gère 20 ! Mais il vous est également possible en Ada de définir votre propre type flottant ainsi que sa précision. Exemple :
type MyFloat is digits 9 ;
x : MyFloat :=12.3456789 ;
Le mot digits indiquera que ce type MyFloat gèrera au moins 9 chiffres significatifs ! Pourquoi "au moins" ? Eh bien parce qu'en créant ainsi un type Myfloat, nous créons un type de nombre flottant particulier utilisant un nombre d'octet particulier. Ici, notre type Myfloat sera codé dans votre ordinateur de sorte que sa mantisse utilise 53 bits. Ce type Myfloat pourra en fait gérer des nombres ayant jusqu'à 15 chiffres significatifs, mais pas au-delà.
Enfin, nous avons beaucoup parlé des nombres en virgule flottante, car c'est le format le plus utilisé pour représenter les nombres décimaux. Mais comme évoqué plus haut, il existe également des nombres en virgule fixe. L'idée est simple : le nombre de chiffres après la virgule est fixé dès le départ et ne bouge plus. Inconvénient : si vous avez fixé à 2 chiffres après la virgule, vous pourrez oubliez les calculs avec 0.00003 ! Mais ces nombres ont l'avantage de permettre des calculs plus rapides pour l'ordinateur. Vous en avez déjà rencontré : les types Duration ou Time sont des types à virgule fixe (et non flottante). Pour créer un type de nombre en virgule fixe vous procèderez ainsi :
type T_Prix is delta 0.01 ;
Prix_CD : T_Prix := 15.99 ;
Le mot clé delta indique l'écart minimal pouvant séparer deux nombres en virgule fixe (ici, notre prix de 15€99, s'il devait augmenter, passerait à €) et donc le nombre de chiffres après la virgule (2 pas plus).
Une précision toutefois : il est nécessaire de combiner delta avec digits ou range ! Exemple :
type T_Livret_A is delta 0.01 digits 6 ;
Toute variable de type T_Livret_A aura deux chiffres après la virgule et 6 chiffres en tout. Sa valeur maximale sera donc 9999.99. Une autre rédaction serait :
type T_Livret_A is delta 0.01 range 0.0 .. 9999.99 ;
Toutefois, gardez à l'esprit que malgré leurs limites (arrondis, overflow ...) les nombres en virgule flottante demeurent bien plus souples que les nombres en virgule fixe. Ces derniers ne seront utilisés que dans des cas précis (temps, argent ...) où le nombre de chiffres après la virgule est connu à l'avance.
Bien, c'est enfin la fin de ce chapitre si théorique. J'espère qu'il vous aura appris beaucoup sur le fonctionnement de l'ordinateur à défaut d'avoir beaucoup apporté de notions de programmation. J'y ferai plusieurs fois référence à l'occasion des prochains chapitres, donc ne négligez pas son importance et, au besoin, n'hésitez pas à effectuer plusieurs conversions binaire-décimal pour mieux maîtriser les notions abordées, notamment les risques d'erreurs liés aux différents types.
Avec ce chapitre nous allons entrer de plein pied dans la programmation orientée objet (souvent appelée par son doux acronyme de POO). L'objectif de ce chapitre est double :
expliquer ce que sont les notions de POO, de classes ...
fournir une première application de ce concept de POO en abordant l'encapsulation.
Cette notion de programmation orientée objet est une notion compliquée et nous allons prendre le temps d'aborder au travers de ce chapitre et des quatre suivants. Alors, prenez un grand bol d'air car avec la POO nous allons faire une longue plongée dans une nouvelle façon de programmer de d'utiliser nos packages, en commençant par l'encapsulation.
Au cours de la partie III, nous avons manipulé des types plus complexes : tableaux, pointeurs, types structurés ... nous nous sommes ainsi approché de cette notion d'objet en manipulant des types qui n'étaient déjà plus des variables. Mais il ne s'agissait pas encore de véritables objets.
Mais alors c'est quoi un objet ? Si c'est encore plus compliqué que les pointeurs et les types structurés j'abandonne ! :(
Vous vous souvenez de l'époque où nous avions réalisé notre TP sur le craps ? A la suite de cela, je vous avais dit qu'il aurait été plus judicieux que nos nombreuses variables soient toutes rassemblées en un seul et même contenant :
Avec nos connaissances actuelles, nous savons que ces différentes variables pourraient être rassemblées en un seul type structuré de la manière suivante :
type T_MainJoueur is record
de1, de2 : natural range 1..6 ;
hasard : generator ;
somme : natural range 2..12 ;
end record ;
Voire mieux encore, nous pourrions tout rassembler (le type T_MainJoueur, les variables, les fonctions et les procédures associées) dans un seul package appelé P_MainJoueur ! A la manière suivante :
Ainsi, nous aurions au sein d'un même paquetage à la fois les variables, les types et les programmes nécessaires à son utilisation (génération des dés, lecture de leur somme ...). Bref, aujourd'hui, vous ne procèderiez plus comme à l'époque où tout était en vrac dans le programme principal.
En effet, :D j'admets avoir fait d'énormes progrès en très peu de temps, en primaire déjà mes instits ... Eh ! Mais tu dérives là ! :colere: Tu ne réponds pas à ma question : C'EST QUOI UN OBJET ?!?
Un objet ? C'est justement cela : un type de donnée muni d'une structure comprenant l'ensemble des outils nécessaires à la représentation d'un objet réel ou d'une notion. Vous ne devez plus voir vos packages simplement comme une bibliothèque permettant de stocker "tout-et-n'importe-quoi-du-moment-que-ça-ne-me-gène-plus-dans-mon-programme-principal" mais plutôt comme une entité à part entière, porteuse d'un sens et d'une logique propre. Ainsi, notre package P_MainJoueur pour qu'il puisse être considéré comme un type d'objet devrait contenir tout ce qui concerne la main du joueur, ses dés, et les outils pour lire ou modifier cette main ... mais rien qui ne concerne son score !
Ainsi, concevoir un objet c'est non seulement concevoir un type particulier mais également tous les outils nécessaires à sa manipulation par un tiers utilisateur et une structure pour englober tout cela.
J'insiste sur le mot "nécessaire" ! Prenez par exemple un programmeur qui a conçu un type T_Fenetre avec tout plein de procédures et de fonctions pour faire une jolie fenêtre sous Windows, Linux ou Mac. Il souhaite faire partager son travail au plus grand nombre : il crée donc un package P_Fenetre qu'il va diffuser. Ce package P_Fenetre n'a pas besoin de contenir des types T_Image_3D, ce serait hors sujet. Mais l'utilisateur a-t-il besoin d'accéder aux procédures Creer_Barre_De_Titre, Creer_Bouton_Fermer, Creer_Bouton_Agrandir ... ? Non, il n'a besoin que d'une procedure Creer_Fenetre ! La plupart des petits programmes créés par le programmeur n'intéresseront pas l'utilisateur final : il faudra donc permettre l'accès pour l'utilisateur à certaines fonctionnalités, mais pas à toutes !
Posons le vocabulaire
Pour faire de la programmation orientée objet, il faut que nous établissions un vocabulaire précis. Le premier point à éclaircir est la différence entre les termes "classe" et "objet". La classe correspond à notre type (nous nuancerons cette assertion plus tard) : elle doit toutefois être munie d'un package dans lequel sont décrits le type et les fonctions et procédures pour le manipuler. A partir de ce "schéma", il est possible de créer plusieurs objets : on dit alors que l'on instancie des objets à partir d'une classe (de la même manière que l'on déclare des variables d'un certain type).
Autre point de vocabulaire, les procédures et fonctions issues d'une classe et s'appliquant à notre objet sont appelées méthodes. Pour mettre les choses au clair, reprenons l'exemple de notre jeu de craps en image :
Enfin, certaines catégories de méthodes portent un nom selon le rôle qu'elles jouent : constructeur pour initialiser les objets, destructeur pour les détruire proprement (en libérant la mémoire dynamique par exemple, nous reverrons cela dans le chapitre sur la finalisation), accesseur, modifieur pour lire ou modifier un attribut, itérateur pour appliquer une modification à une pile par exemple ...
De nouvelles contraintes
On attache à la Programmation Orientée Objet, non seulement la notion de classe englobant à la fois le type et les programmes associés, mais également divers principes comme :
L'encapsulation : c'est l'une des propriétés fondamentales de la POO. Les informations contenues dans l'objet ne doivent pas être "bidouillables" par l'utilisateur. Elles doivent être protégées et manipulées uniquement à l'aide des méthodes fournies par le package. Si l'on prend l'exemple d'une voiture : le constructeur de la voiture fait en sorte que le conducteur n'ait pas besoin d'être mécanicien pour l'utiliser. Il crée un volant, des sièges et des pédales pour éviter que le conducteur ne vienne mettre son nez dans le moteur (ce qui serait un risque). Nous avons commencé à voir cette notion avec la séparation des spécifications et du corps des packages et nous allons y ajouter la touche finale au cours de ce chapitre avec la privatisation.
La généricité : nous l'avons régulièrement évoquée au cours de ce tutoriel. Elle consiste à réaliser des packages applicables à divers types de données. Il en était ainsi pour les Doubly_Linked_Lists ou les Vectors qui pouvaient contenir des float, des integer ou des types personnalisés. Nous verrons cette notion plus en profondeur lors du prochain chapitre sur la programmation modulaire.
L'héritage : deuxième notion fondamentale de la conception orientée objet. Plus complexe, elle sera traitée après la généricité.
" :soleil: Ici c'est un club privé, on n'entre pas ! :soleil: "
Vous avez peut-être déjà entendu cette tirade ? Eh bien nous allons pouvoir nous venger aujourd'hui en faisant la même chose avec nos packages. :pirate: Bon certes, personne ne comptait vraiment venir danser avec nous devant le tuto ... Disons qu'il s'agit de rendre une partie de notre code "inaccessible". Petite explication : lorsque nous avons rédigé nos packages P_Pile et P_File, je vous avais bien précisé que nous voulions proposer à l'utilisateur ou au programmeur final toute une gamme d'outils qui lui permettraient de ne pas avoir à se soucier de la structure des types T_File et T_Pile. Ainsi, pour accéder au deuxième élément d'une pile, il lui suffit d'écrire :
...
n : integer ;
P : T_Pile
BEGIN
...
--création de la pile
pop(P,n) ;
put(first(P)) ;
La logique est simple : il dépile le premier élément puis affiche le premier élément de la sous-pile restante. Simple et efficace ! C'est d'ailleurs pour cela que nous avions créé toutes ces primitives. Mais en réalité, rien n'empêche notre programmeur d'écrire :
...
P : T_Pile
BEGIN
...
--création de la pile
put(P.suivant.valeur) ;
Et là c'est plutôt embêtant non ? Car nous avons rédigé des procédures et des fonctions justement dans le but qu'il ne puisse pas utiliser l'écriture avec pointeurs. Cette écriture présente des risques, nous le savons et avons pu le constater en testant nos packages P_Pile et P_File ! Alors il est hors de question que nous ayons fait tous ces efforts pour fournir un code sûr et qu'un olibrius s'amuse finalement à "détourner" notre travail. Si cela n'a pas de grande incidence à notre échelle, cela peut poser des problèmes de stabilité et de sécurité du code dans de plus grands projets nécessitant la coopération de nombreuses personnes.
Bah oui mais on ne peut pas empêcher les gens de faire n'importe quoi ? :-°
Eh bien si, justement ! La solution consiste à rendre la structure de nos types T_Pile, T_File et T_Cellule illisible en dehors de leurs propres packages. Actuellement, n'importe qui peut la manipuler à sa guise simplement en faisant appel au bon package. On dit que nos types sont publics. Par défaut, tout type, variable, sous-programme ... déclaré dans un package est public.
Pour restreindre l'accès à un type, une variable ... il faut donc le déclarer comme privé (private en Ada). Pour réaliser cela, vous allez devoir changer votre façon de voir vos packages ou tout du moins les spécifications. Vous lez voyiez jusqu'alors comme une sorte de grande boîte où l'on stockait tout et n'importe quoi, n'importe comment. Vous allez devoir apprendre que cette grande boîte est en fait compartimentée :
AVANT
MAINTENANT
Package P_Pile is
Vos fonctions, procédures, types, variables ...
end P_Pile ;
Package P_Pile is
Vos fonctions, procédures, types, variables ... publics
private
Vos fonctions, procédures, types, variables ... privés
end P_Pile ;
Comme l'indique le schéma ci-dessus, le premier compartiment, celui que vous utilisiez, correspond à la partie publique du package. Il est introduit par le mot is. Le second compartiment correspond à la partie privée et est introduit par le mot private, mais comme cette partie était jusqu'alors vide, nous n'avions pas à la renseigner. Reprenons le code du fichier P_Pile.ads pour lui ajouter une partie privée :
PACKAGE P_Pile IS
-- PARTIE PUBLIQUE : NOS PRIMITIVES
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
PRIVATE
-- PARTE PRIVÉE : NOS TYPES
TYPE T_Cellule;
TYPE T_Pile IS ACCESS ALL T_Cellule;
TYPE T_Cellule IS
RECORD
Valeur : Integer;
Index : Integer;
Suivant : T_Pile;
END RECORD;
END P_Pile;
Les utilisateurs doivent garder l'accès aux primitives, elles ont été faites pour eux tout de même. En revanche, ils n'ont pas à avoir accès à la structure de nos types, donc nous les rendons privés. Et voilà ! Le tour est joué ! Pas besoin de modifier le corps de notre package, tout se fait dans les spécifications.
Visibilité
Mais ça marche pas tes affaires ! o_O A la compilation, GNAT m'indique "T_Pile" is undefined (more references follow)
Ah oui ... c'est embêtant. :( Cela m'amène à vous parler de la visibilité du code. Lorsque vous créez un programme faisant appel à P_Pile (avec l'instruction WITH P_Pile ;), ce programme n'a pas accès à l'intégralité du package ! Il aura simplement accès aux spécifications et, plus précisément encore, aux spécifications publiques ! Toute la partie privée et le corps du package demeurent invisibles, comme l'indique le schéma ci-dessous :
Une flèche indique qu'une partie "a accès à" ce qui est écrit dans une autre
On voit ainsi que seul le corps du package sait comment est constituée la partie privée puisqu'il a pleine visibilité sur l'ensemble du fichier ads. Donc seul le body peut manipuler librement ce qui est dans la partie private.
Comment peut-on alors créer un type T_Pile si ce type est invisible ?
L'utilisateur doit pouvoir voir ce type sans pour autant pouvoir le lire. "Voir notre type" signifie que l'utilisateur peut déclarer des objets de type T_Pile et utiliser des programmes utilisant eux-même ce type. En revanche, il ne doit pas en connaître la structure, il ne doit donc pas pouvoir "lire notre type". Comment faire cela ? Eh bien, nous devons indiquer dans la partie publique que nous disposons de types privés. Voici donc le code du package P_Pile tel qu'il doit être écrit (concentrez-vous sur la ligne 5) :
PACKAGE P_Pile IS
-- PARTIE PUBLIQUE
TYPE T_Pile IS PRIVATE ; --On indique qu'il y a un type T_Pile mais que celui-ci est privé
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
PRIVATE
-- PARTE PRIVÉE
TYPE T_Cellule;
TYPE T_Pile IS ACCESS ALL T_Cellule; --on décrit ce qu'est le type T_Pile
TYPE T_Cellule IS
RECORD
Valeur : Integer;
Index : Integer;
Suivant : T_Pile;
END RECORD;
END P_Pile;
Et cette fois, c'est fini : votre type T_Pile est visible mais plus lisible, vous avez créé un véritable type privé et par la même occasion, votre première classe et vos premiers vrais objets !
Nous avons dit que le type T_Pile était privé et donc qu'il était visible mais non lisible. Par conséquent, il est impossible de connaître la structure d'une pile P et donc d'écrire :
En revanche, il est possible de déclarer des variables de type T_Pile, d'affecter une pile à une autre ou encore de tester l'égalité ou l'inégalité de deux piles :
-- TOUTES LES OPÉRATIONS CI-DESSOUS SONT THÉORIQUEMENT POSSIBLES
P1, P2, P3 : T_Pile --déclaration
BEGIN
...
P2 := P1 ; --affectation
if P2 = P1 and P3/=P1 --comparaison (égalité et inégalité seulement)
then ...
Mais à moins que vous ne les surchargiez, les opérateurs +, *, / ou - ne sont pas définis pour nos types T_Pile et ne sont donc pas utilisables, de même pour les test d'infériorité (< et <=) ou de supériorité (> et >=).
Restreindre encore notre type
Type limité et privé
Eh ! Mais si P1, P2 et P3 sont des piles, ce sont donc des pointeurs ! C'est pas un peu dangereux d'écrire P2 := P1 dans ce cas ?
Si, en effet. Vous avez bien retenu la leçon sur les pointeurs. :lol: Il est effectivement risqué de laisser à l'utilisateur la possibilité d'effectuer des comparaisons et surtout des affectations. Heureusement, le langage Ada a tout prévu ! Pour restreindre encore les possibilités, il est possible de créer un type non plus private, mais limited private (privé et limité) ! Et c'est extrêmement facile à réaliser puisqu'il suffit juste de modifier la ligne n°5 du fichier ads :
PACKAGE P_Pile IS
-- PARTIE PUBLIQUE
TYPE T_Pile IS LIMITED PRIVATE ; --Le type T_Pile est désormais privé ET limité ! ! !
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
PRIVATE
-- PARTE PRIVÉE
TYPE T_Cellule;
TYPE T_Pile IS ACCESS ALL T_Cellule; --on décrit ce qu'est le type T_Pile
TYPE T_Cellule IS
RECORD
Valeur : Integer;
Index : Integer;
Suivant : T_Pile;
END RECORD;
END P_Pile;
Désormais, l'utilisateur ne pourra QUE déclarer ses piles ! Plus d'affectation ni de comparaison !
Mais ?!? o_O A quoi ça sert d'avoir un objet si on ne peut pas lui affecter de valeur ?
Pensez aux fichiers et au type File_Type. Aviez-vous besoin d'effectuer des affectations ou des comparaisons ? Non bien sûr. Cela n'aurait eu aucun sens ! Mais cela ne vous a pas empêché d'employer des objets de type File_Type et de leur appliquer diverses méthodes comme Put(), Get(), End_Of_Page() et tant d'autres. Le principe est exactement le même dans le cas présent : est-ce cohérent d'affecter UNE valeur à une pile ? Je ne crois pas. D'ailleurs, nous avons la primitive Push() pour ajouter une valeur à celles déjà existantes. En revanche, il pourrait être utile d'ajouter quelques méthodes à notre package P_Pile pour copier une pile dans une autre ou pour tester si les piles contiennent un ou des éléments identiques. Le but étant d'avoir un contrôle total sur les affectations et les tests : avec un type LIMITED PRIVATE, rien à part la déclaration ne peut se faire sans les outils du package associé.
Type seulement limité
Pour information, il est possible de déclarer un type qui soit seulement limited. Par exemple :
TYPE T_Vainqueur IS LIMITED RECORD
Nom : String(1..3) ;
Score : Natural := 0 ;
END RECORD ;
Ainsi, il sera impossible d'effectuer une affectation directe ou un test d'égalité (ou inégalité) :
En revanche, puisque le type T_Vainqueur n'est pas privé, sa structure est accessible et il demeure possible d'effectuer des tests ou des affectations sur ses attributs. Le code ci-dessous est donc correct :
Toi.nom := "JIM" ;
If Moi.score > Toi.score
then put("Je t'ai mis la misere ! ! ! " ;
end if ;
L'intérêt d'un type uniquement LIMITED est plus discutable et vous ne le verrez que très rarement. En revanche, les types LIMITED PRIVATE vont devenir de plus en plus courants, croyez-moi.
Sur le même principe, modifier votre package P_File afin que votre type T_File soit privé et limité.
Solution
PACKAGE P_Pile IS
TYPE T_Pile IS LIMITED PRIVATE ;
PROCEDURE Push (P : IN OUT T_Pile; N : IN Integer) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT Integer) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN Integer ;
PRIVATE
TYPE T_Cellule;
TYPE T_Pile IS ACCESS ALL T_Cellule;
TYPE T_Cellule IS
RECORD
Valeur : Integer;
Index : Integer;
Suivant : T_Pile;
END RECORD;
END P_Pile;
Exercice 2
Énoncé
Créer une classe T_Perso contenant le nom d'un personnage de RPG, ses points de vie et sa force. La classe sera accompagnée d'une méthode pour saisir un objet de type T_Perso et d'une seconde pour afficher ses caractéristiques.
Solution
package P_Perso is
type T_Perso is private ; --éventuellement limited private
procedure get(P : out T_Perso) ;
procedure put(P : in T_Perso) ;
private
type T_Perso is record
Nom : string(1..20) ;
PV : Natural := 0 ;
Force : Natural := 0 ;
end record ;
end P_Perso ;
with ada.text_io ; use ada.text_io ;
with ada.integer_text_io ; use ada.integer_text_io ;
package body P_Perso is
procedure get(P : out T_Perso) is
begin
put("Entrez un nom (moins de 20 lettres) : ") ; get(P.Nom) ; skip_line ;
put("Entrez ses points de vie : ") ; get(P.PV) ; skip_line ;
put("Entrez sa force : ") ; get(P.Force) ; skip_line ;
end get ;
procedure put(P : in T_Perso) is
begin
put_line(P.nom) ;
put_line(" VIE : " & integer'image(P.PV)) ;
put_line(" FORCE : " & integer'image(P.Force)) ;
end put ;
end P_Perso ;
Voilà qui est fait pour notre entrée en matière avec la POO. Rassurez-vous, ce chapitre n'était qu'une entrée en matière. Si l'intérêt de la POO vous semble encore obscur ou que certains points mériteraient des éclaircissement, je vous conseille de continuer la lecture des prochains chapitres durant lesquels nous allons préciser la notion d'objet et de classe. La prochaine étape est la généricité, notion déjà présente en Ada83 et dont je vous ai déjà vaguement parlé au cours des précédents chapitres.
Cela fait déjà plusieurs chapitres que ce terme revient : générique. Les packages Ada.Containers.Doubly_Linked_Lists ou Ada.Containers.Vectors étaient génériques. Mais bien avant cela, le package Ada.Numerics.Discrete_Random qui nous permettait de générer des nombres aléatoirement était générique ! Nous côtoyons cette notion depuis la partie II déjà sans avoir pris beaucoup de temps pour l'expliquer : c'est que cette notion est très présente en Ada. Et pour cause, la norme Ada83 permettait déjà la généricité. Il est donc temps de lever le voile avant de revenir à la programmation orientée objet et à l'héritage.
Avant de parler de packages génériques, il serait bon d'évoquer le problème qui a mené à cette notion de généricité. Vous avez du remarquer au cours de ce tutoriel que vous étiez souvent amenés à réécrire les mêmes bouts de code, les mêmes petites fonctions ou procédures qui servent sans arrêt. Par exemple, des procédures pour échanger les valeurs de deux variables, pour afficher le contenu d'un tableau, en extraire le plus petit élément ou encore en effectuer la somme ... bref, ce genre de sous-programme revient régulièrement et les packages ne suffisent pas à résoudre ce problème : notre bon vieux package P_Integer_Array ne résolvait certains de ces soucis que pour des tableaux contenant des Integer, mais pas pour des tableaux de float, de character, de types personnalisés ... De même, nous avons créé des packages P_Pile et P_File uniquement pour des Integer, et pour disposer d'une pile de Float, il faudrait jouer du copier-coller : c'est idiot !
D'où la nécessité de créer des programmes génériques, c'est à dire pouvant traiter "toute sorte" de types de données. A-t-on vraiment besoin de connaître le type de deux variables pour les intervertir ? Non bien sûr, tant qu'elles ont le même type ! L'idée est donc venue de proposer aux programmeurs la possibilité de ne rédiger un code qu'une seule fois pour ensuite le réemployer rapidement selon les types de données rencontrées.
Le langage Ada utilise le terme (suffisamment explicite je pense) de generic pour indiquer au compilateur quels sont les types ou variables génériques utilisés par les sous-programmes. D'autres langages parlent en revanche de modèle et utilisent le terme de template : on indique au compilateur que le sous-programme est un "cas-général", un "moule", une sorte de plan de montage pour sous-programme en kit ^^ . Même difficulté, même approche mais des termes radicalement différents.
Plan de bataille
Il est possible de créer des fonctions génériques, des procédures génériques ou encore des packages génériques : nous parlerons d'unités de programmes génériques. Ces unités de programmes ne seront génériques que parce qu'elles accepteront des paramètres eux-mêmes génériques. Ces paramètres sont en général des types, mais il est également possible d'avoir comme paramètre générique une variable ou une autre unité de programme! Ce dernier cas (plus complexe) sera vu à la fin de ce chapitre. Pour l'instant, nous allons retenir que pour réaliser une unité de programme générique il faut avant-tout déclarer le (ou les) type(s) générique(s) qui sera (seront) utilisé(s) par la suite. D'où un premier schéma de déclaration :
DÉCLARATION DU (OU DES) TYPE(S) GÉNÉRIQUE(S)
SPÉCIFICATION DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
CORPS DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
Ensuite, une unité de programme générique, seule, ne sert à rien. Il n'est pas possible de l'utiliser directement avec un type concret comme Integer ou Float. Vous devrez préalablement recréer une nouvelle unité de programme spécifique au type désiré. Rassurez-vous, cette étape se fera très rapidement : c'est ce que l'on appelle l'instanciation. D'où un plan de bataille modifié :
DÉCLARATION DU (OU DES) TYPE(S) GÉNÉRIQUE(S)
SPÉCIFICATION DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
CORPS DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
INSTANCIATION D'UNE UNITÉ DE PROGRAMME SPÉCIFIQUE
Un dernier point de vocabulaire
Bon ça y est, on commence ? :)
Pas encore, nous avons un petit point de théorie à éclaircir. Vous l'aurez compris, nous allons pouvoir définir des types génériques, seulement les types peuvent être classés en plusieurs catégories qu'il n'est pas toujours évident de distinguer : on dit qu'il existe plusieurs classes de types (tiens, encore ce mot "classe" ;) ).
Nous avons ainsi les types tableaux, les types flottants, les types entiers, les types pointeurs ... mais aussi les types discrets. De quoi s'agit-il ? Ce ne sont pas des types qui ne font pas de bruit ! :p Non, le terme discret est un terme mathématique signifiant que chaque élément (sauf cas extrêmes) a un prédécesseur et un successeur. Le type Natural par exemple est un type discret : si vous prenez un élément N au hasard parmi le type Natural (175 par exemple), vous pouvez lui trouver un successeur avec l'instruction Natural'succ(N) (=176) et un prédécesseur avec l'instruction Natural'pred(N) (=174). Et cela marchera pour tous les Natural hormis 0 qui n'a pas de prédécesseur et Natural'last qui n'a pas de successeur. Il en va de même pour les tous les types entiers comme Positive ou Integer, pour les types Character, Boolean ou même les types énumérés.
En revanche, le type Float n'est pas un type discret. Prenez un flottant X au hasard (175.0 par exemple). Quel est son successeur ? 176.0 ou 175.1 ? Et pourquoi pas 175.0002 ou 175.0000001 ? De même, les tableaux ou les pointeurs ne sont évidemment pas des types discrets.
Pourquoi vous parlez de cela ? Eh bien parce qu'avant de déclarer des types génériques, il est important de savoir à quelle classe de type il appartiendra : intervertir deux variables ne pose pas de soucis, mais effectuer une addition par 1 ne peut se faire qu'avec un type entier et pas flottant, connaître le successeur d'une variable ne peut se faire qu'avec des types discrets, connaître le nème élément ne peut se faire qu'avec un type tableau ... Bref, faire de la généricité, ce n'est pas faire n'importe quoi : il est important d'indiquer au compilateur quels types seront acceptables pour nos unités de programmes génériques.
Bon ! Il est temps désormais de voir un cas concret ! Nous allons créer une procédure qui échange deux éléments (nous l'appellerons Swap, c'est le terme Anglais pour Echanger). Voilà à quoi elle ressemblerait :
procedure swap(a,b : in out Positive) is
c : Positive ;
begin
c:=a ;
a:=b ;
b:=c ;
end swap ;
Mais elle est conçue pour échanger des Positive : pas des Natural ou des Integer, non ! Seulement des Positive ! Peut-être pourrions-nous élargir son champ d'action à tous les types entiers, au moins ?
Créer un type générique
Nous allons donc créer un type générique appelé T_Entier. Attention, ce type n'existera pas réellement, il ne servira qu'à la réalisation d'une procédure générique (et une seule). Pour cela nous allons devoir ouvrir un bloc generic dans la partie réservée aux déclarations :
generic
type T_Entier is range <> ;
Notez bien le range <> ! Le diamant (<>) est le symbole indiquant que les informations nécessaires ne seront transmises que plus tard. La combinaison de range et du diamant indique plus précisément que le type attendu est un type entier (Integer, Natural, Positive, Long_Long_integer ...) et pas flottant ou discret ou que-sais-je encore !
Notez également qu'il n'y a pas d'instruction endgeneric ! Pourquoi ? Tout simplement parce que ce type générique ne va servir qu'une seule fois et ce sera pour l'unité de programme que l'on va déclarer ensuite. Ainsi, c'est le terme function, procedure ou package qui jouera le rôle du endgeneric et mettra un terme aux déclarations génériques. Le type T_Entier doit donc être vue comme un paramètre de l'unité de programme générique.
Créer une procédure générique
Comme nous l'avions dit précédemment, la déclaration du type T_Entier doit être immédiatement suivie de la spécification de la procédure générique, ce qui nous donnera le code suivant :
generic
type T_Entier is range <> ;
procedure Generic_Swap(a,b : in out T_Entier) ;
Comme vous le constater, notre procédure utilise désormais le type T_Entier déclaré précédemment (d'où son nouveau nom Generic_Swap). Cette procédure prend en paramètres deux variables a et b indiquées entre parenthèses mais aussi un type T_Entier indiqué dans sa partie generic.
Ne reste plus désormais qu'à rédiger le corps de notre procédure un peu plus loin dans notre programme :
procedure Generic_Swap(a,b : in out T_Entier) is
c : T_Entier ;
begin
c:=a ;
a:=b ;
b:=c ;
end swap ;
Utiliser une méthode générique
Instanciation
Mais, j'essaye depuis tout à l'heure ce code, et il ne marche pas :
...
n : Integer := 3 ;
m : Integer := 4 ;
BEGIN
Generic_Swap(n,m) ;
...
C'est normal, votre procédure Generic_Swap() est faite pour un type générique seulement. Pas pour les Integer spécifiquement. Le travail que nous avons fait consistait simplement à rédiger une sorte de "plan de montage", mais nous n'avons pas encore réellement "monté notre meuble". En programmation, cette étape s'appelle l'instanciation : nous allons devoir créer une instance de Generic_Swap, c'est-à-dire une nouvelle procédure appelée Swap_Integer. Et cela se fait grâce à l'instruction new :
procedure swap_integer is new Generic_Swap(Integer) ;
Le schéma d'instanciation est relativement simple et sera systématiquement le-même pour toutes les unités de programmes :
procedure
Nom_Unite_Specifique
is new
Nom_Unite_Generique
(Types spécifiques)
function
package
Surcharge
Ainsi, le compilateur se chargera de générer lui-même le code de notre procédure swap_integer, vous laissant d'avantage de temps pour vous concentrer sur votre programme. Et puis, si vous aviez besoin de disposer de procédures swap_long_long_integer ou swap_positive_integer, il vous suffirait simplement d'écrire :
procedure swap_integer is new Generic_Swap(Integer) ;
procedure swap_long_long_integer is new Generic_Swap(long_long_integer) ;
procedure swap_positive is new Generic_Swap(Positive) ;
Hop ! Trois procédures générées en seulement trois lignes ! Pas mal non ? Et nous pourrions faire encore mieux, en générant trois instances de Generic_Swap portant toutes trois le même nom : swap ! Ainsi, en surchargeant la procédure, nous économisons de nombreux caractères à taper ainsi que la nécessité de systématiquement réfléchir aux types employés :
procedure swap is new Generic_Swap(Integer) ;
procedure swap is new Generic_Swap(long_long_integer) ;
procedure swap is new Generic_Swap(Positive) ;
Et désormais, nous pourrons effectuer des inversions à notre guise :
...
generic
type T_Entier is range <> ;
procedure Generic_Swap(a,b : in out T_Entier) ;
procedure Generic_Swap(a,b : in out T_Entier) is
c : T_Entier ;
begin
c:=a ;
a:=b ;
b:=c ;
end swap ;
procedure swap is new Generic_Swap(Integer) ;
n : integer := 3 ;
m : integer := 4 ;
BEGIN
swap(n,m) ;
...
Bien, vous connaissez désormais les rudiments de la généricité en Ada. Toutefois, notre déclaration du type T_Entier implique que vous ne pourrez pas utiliser cette procédure pour des character !
Et si je veux qu'elle fonctionne pour les character aussi, comment je fais ?
Eh bien il va falloir modifier notre classe de type générique :
Pour couvrir tous les types discrets (entiers mais aussi character, boolean ou énumérés), on utilisera le diamant seul :
type T_Discret is (<>) ;
Pour couvrir les types réels à virgule flottante (comme Float, Long_Float, Long_Long_Float ou des types flottants personnalisés), on utilisera la combinaison de digits et du diamant :
type T_Flottant is digits <> ;
Pour couvrir les types réels à virgule fixe (comme Duration, Time ou les types réels à virgule fixe personnalisés), on utilisera la combinaison de delta et du diamant, voire de delta, digits et du diamant (revoir le chapitre Variables III : Gestion des données si besoin) :
type T_Fixe is delta <> ; type T_Fixe is delta <> digits <> ;
Enfin, pour couvrir les types modulaires (revoir le chapitre Créer vos propres objets si besoin), on utilisera la combinaison de mod et du diamant :
type T_Modulaire is mod <> ;
Types génériques privés
Mais, on ne peut pas faire de procédure encore plus générique ? Comme une procédure qui manipulerait des types discrets mais aussi flottants ?
Si, c'est possible. Pour que votre type générique soit "le plus générique possible", il vous reste deux possibilités :
Si vous souhaitez que votre type bénéficie au moins de l'affectation et de la comparaison, il suffira de le déclarer ainsi :
type T_Generique is private ;
Et si vous souhaitez un type le plus générique possible, écrivez :
Pour déclarer un type tableau, nous avons toujours besoin de spécifier les indices : le tableau est-il indexé de 0 à 10, de 3 à 456, de 'a' à 'z', de JANVIER à FEVRIER ... ? Par conséquent, pour déclarer un tableau générique, il faut au minimum deux types génériques : le type (nécessairement discret) des indices et le type du tableau. Exemple :
generic
type T_Indice is (<>) ;
type T_Tableau is array(T_Indice) of Float ;
procedure Generic_Swap(T : in out T_Tableau ; i,j : T_Indice) ;
procedure Generic_Swap(T : in out T_Tableau ; i,j : T_Indice) is
tmp : Float ;
begin
tmp := T(i) ;
T(i) := T(j) ;
T(j) := tmp ;
end Generic_Swap ;
Notre procédure Generic_Swap dispose alors de deux paramètres formels (T_Indice et T_Tableau) qu'il faudra spécifier à l'instanciation dans l'ordre de leur déclaration :
...
subtype MesIndices is integer range 1..10 ;
type MesTableaux is array(MesIndices) of Float ;
procedure swap is new Generic_Swap(MesIndices,MesTableaux) ;
T : MesTableaux := (9.0, 8.1, 7.2, 6.3, 5.4, 4.5, 3.6, 2.7, 1.8, 0.9) ;
begin
swap(T,3,5) ;
...
Avec un tableau non contraint
Une première amélioration peut être apportée à ce code. Déclaré ainsi, notre type de tableaux est nécessairement contraint : tous les tableaux de type MesTableaux sont obligatoirement indexés de 1 à 10. Pour lever cette restriction, il faut tout d'abord modifier notre type formel :
generic
type T_Indice is (<>) ;
type T_Tableau is array(T_Indice range <>) of Float ;
--l'ajout de "range <>" nous laisse la liberté de contraindre nos tableaux plus tard
procedure Generic_Swap(T : in out T_Tableau ; i,j : T_Indice) ;
Puis nous pourrons modifier les types effectifs :
...
type MesTableaux is array(Integer range <>) of Float ;
--on réécrit "range <>" pour bénéficier d'un type non contraint !
procedure swap is new Generic_Swap(Integer,MesTableaux) ;
T : MesTableaux(1..6) := (7.2, 6.3, 5.4, 4.5, 3.6, 2.7) ;
--Cette fois, on contraint notre tableau en l'indexant de 1 à 6 ! Étape obligatoire !
begin
swap(T,3,5) ;
...
Un tableau entièrement générique
Seconde amélioration : au lieu de disposer d'un type T_Tableau contenant des Float, nous pourrions créer un type contenant toute sorte d'élément. Cela impliquera d'avoir un troisième paramètre formel : un type T_Element :
generic
type T_Indice is (<>) ;
type T_Element is private ;
--Nous aurons besoin de l'affectation pour la procédure Generic_Swap donc T_Element ne peut être limited
type T_Tableau is array(T_Indice range <>) of T_Element;
procedure Generic_Swap(T : in out T_Tableau ; i,j : T_Indice) ;
Je ne vous propose pas le code du corps de Generic_Swap, j'espère que vous serez capable de le modifier par vous-même (ce n'est pas bien compliqué). En revanche, l'instanciation devra à son tour être modifiée :
type MesTableaux is array(Integer range <>) of Float ;
--Jusque là pas de grosse différence
procedure swap is new Generic_Swap(Integer,Float,MesTableaux) ;
--Il faut indiquer le type des indices + le type des éléments + le type du tableau
L'inconvénient de cette écriture c'est qu'elle n'est pas claire : le type T_Tableau doit-il être écrit en premier, en deuxième ou en troisième ? Les éléments du tableau sont des Integer ou des Float ? Bref, on s'emmêle les pinceaux et il faut régulièrement regarder les spécifications de notre procédure générique pour s'y retrouver. On préfèrera donc l'écriture :
procedure swap is new Generic_Swap(T_Indice => Integer,
T_Element => Float,
T_Tableau => MesTableaux) ;
--RAPPEL : L'ordre n'a alors plus d'importance ! ! !
--CONSEIL : Indentez correctement votre code pour plus de lisibilité
Pointeurs génériques
De la même manière, il est possible de créer des types pointeurs génériques. Et comme pour déclarer un type pointeur, il faut absolument connaître le type pointé, cela impliquera d'avoir deux paramètres formels. Exemple :
generic
type T_Element is private ;
type T_Pointeur is access T_Element ;
procedure Access_Swap(P,Q : in out T_Pointeur) ;
D'où l'instanciation suivante :
type MesPointeursPersos is access character ;
procedure swap is new Access_Swap(character,MesPointeursPersos) ;
-- OU MIEUX :
procedure swap is new Access_Swap(T_Pointeur => MesPointeursPersos,
T_Element => Character) ;
Paramètre de type programme : le cas d'un paramètre limited private
Bon, j'ai compris pour les différents types tableaux, pointeurs etc ... Mais quel intérêt de créer un type limited private ET generic ? On ne pourra rien faire ! Ça ne sert à rien pour notre procédure d'échange ! o_O
En effet, nous sommes face à un problème : les types limited private ne nous autorisent pas les affectations or nous aurions bien besoin d'un sous-programme pour effectuer cette affectation. Prenons un exemple : nous allons réaliser un package appelé P_Point qui saisit, lit, affiche ... des points et leurs coordonnées. Voici quelle pourrait être sa spécification :
package P_Point is
type T_Point is limited private ;
procedure set_x(P : out T_Point ; x : in float) ;
procedure set_y(P : out T_Point ; y : in float) ;
function get_x(P : in T_Point) return float ;
function get_y(P : in T_Point) return float ;
procedure put(P : in T_Point) ;
procedure copy(From : in T_Point ; To : out T_Point) ;
private
type T_Point is record
x,y : Float ;
end record ;
end P_Point ;
Ce type T_Point est bien limited private mais son package nous fournit une procédure pour réaliser une copie d'un point dans un autre. Reprenons désormais notre procédure générique :
generic
type T_Element is limited private ;
with procedure copier_A_vers_B(a : in T_Element ; b : out T_Element) ;
procedure Generic_Swap(a,b : in out T_Element) ;
Nous ajoutons un nouveau paramètre formel : une procédure appelée copier_A_vers_B et qu'il faudra préciser à l'instanciation. Mais revenons avant cela au code source de la procédure Generic_Swap. Si elle ne peut pas utiliser le symbole d'affectation :=, elle pourra toutefois utiliser cette nouvelle procédure générique copier_A_vers_B :
procedure Generic_Swap(a,b : in out T_Element) is
c : T_Element ;
begin
copier_A_vers_B(b,c) ;
copier_A_vers_B(a,b) ;
copier_A_vers_B(c,a) ;
end generic_swap ;
A l'instanciation, vous devrez donc préciser le nom de la procédure qui effectuera cette copie de A vers B :
procedure swap is new generic_swap(T_Point,copy) ;
-- OU BIEN
procedure swap is new generic_swap(T_Element => T_Point,
Copier_A_vers_B => copy) ;
Une dernière remarque : si vous ne souhaitez pas être obligé de spécifier le nom de la procédure de copie à l'instanciation, il suffit de modifier la ligne :
with procedure copier_A_vers_B(a : in T_Element ; b : out T_Element) ;
en y ajoutant un diamant (mais n'oubliez pas de modifier le code source de Generic_Swap en conséquence) :
with procedure copy(a : in T_Element ; b : out T_Element) is <> ;
Vous avez dors et déjà appris l'essentiel de ce qu'il y a à savoir sur la généricité en Ada. Mais pour plus de clarté, nous n'avons utilisé qu'une procédure générique. Or, la plupart du temps, vous ne créerez pas un seul programme générique, mais bien plusieurs, de manière à offrir toute une palette d'outil allant de paire avec l'objet générique que vous proposerez. Prenez l'exemple de nos packages P_Pile et P_File (encore et toujours eux) : quel intérêt y a-t-il à ne proposer qu'une seule procédure générique alors que vous disposez de plusieurs primitives ? Dans 95% des cas, vous devrez donc créer un package générique.
Pour illustrer cette dernière (et courte) partie, et en guise d'exercice final, vous allez donc modifier le package P_Pile pour qu'il soit non seulement limité privé, mais également générique ! Ce n'est pas bien compliqué : retenez le schéma que je vous avais donné en début de chapitre :
DÉCLARATION DU (OU DES) TYPE(S) GÉNÉRIQUE(S)
SPÉCIFICATION DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
CORPS DE L’UNITÉ DE PROGRAMME GÉNÉRIQUE
INSTANCIATION D'UNE UNITÉ DE PROGRAMME SPÉCIFIQUE
La différence, c'est que le tout se fait dans des fichiers séparés :
DÉCLARATION DU (OU DES) TYPE(S) GÉNÉRIQUE(S)
SPÉCIFICATION DU PACKAGE GÉNÉRIQUE
CORPS DU PACKAGE GÉNÉRIQUE
INSTANCIATION D'UN PACKAGE SPÉCIFIQUE
La structure de votre fichier ads va donc devoir encore évoluer :
SCHÉMA INITIAL
SCHÉMA ACTUEL
NOUVEAU SCHEMA
Package P_Pile is
Vos fonctions, procédures, types, variables ...
end P_Pile ;
Package P_Pile is
Vos fonctions, procédures, types, variables ... publics
private
Vos fonctions, procédures, types, variables ... privés
end P_Pile ;
Generic
Vos paramètres formels : variables, types, programmes ...
Package P_Pile is
Vos fonctions, procédures, types, variables ... publics
private
Vos fonctions, procédures, types, variables ... privés
end P_Pile ;
Vous êtes prêts pour le grand plongeon ? Alors allez-y ! ^^
Solution
GENERIC
TYPE T_Element IS PRIVATE ;
PACKAGE P_Pile IS
TYPE T_Pile IS LIMITED PRIVATE ;
PROCEDURE Push (P : IN OUT T_Pile; N : IN T_Element ) ;
PROCEDURE Pop (P : IN OUT T_Pile ; N : OUT T_Element ) ;
FUNCTION Empty (P : IN T_Pile) RETURN Boolean ;
FUNCTION Length(P : T_Pile) RETURN Integer ;
FUNCTION First(P : T_Pile) RETURN T_Element ;
PRIVATE
TYPE T_Cellule;
TYPE T_Pile IS ACCESS ALL T_Cellule;
TYPE T_Cellule IS
RECORD
Valeur : T_Element ; --On crée une pile générique
Index : Integer;
Suivant : T_Pile;
END RECORD;
END P_Pile;
PACKAGE BODY P_Pile IS
PROCEDURE Push (
P : IN OUT T_Pile;
N : IN T_Element ) IS
Cell : T_Cellule;
BEGIN
Cell.Valeur := N ;
IF P /= NULL
THEN
Cell.Index := P.All.Index + 1 ;
Cell.Suivant := P.All'ACCESS ;
ELSE
Cell.Index := 1 ;
END IF ;
P := NEW T_Cellule'(Cell) ;
END Push ;
PROCEDURE Pop (
P : IN OUT T_Pile;
N : OUT T_Element ) IS
BEGIN
N := P.All.Valeur ; --ou P.valeur
--P.all est censé exister, ce sera au programmeur final de le vérifier
IF P.All.Suivant /= NULL
THEN
P := P.Suivant ;
ELSE
P := NULL ;
END IF ;
END Pop ;
FUNCTION Empty (
P : IN T_Pile)
RETURN Boolean IS
BEGIN
IF P=NULL
THEN
RETURN True ;
ELSE
RETURN False ;
END IF ;
END Empty ;
FUNCTION Length(P : T_Pile) RETURN Integer IS
BEGIN
IF P = NULL
THEN RETURN 0 ;
ELSE RETURN P.Index ;
END IF ;
END Length ;
FUNCTION First(P : T_Pile) RETURN T_Element IS
BEGIN
RETURN P.Valeur ;
END First ;
END P_Pile;
Application
Vous pouvez désormais créer des piles de Float, de tableaux, de boolean ... il vous suffira juste d'instancier votre package :
With P_Pile ; --Pas de clause Use, cela n'aurait aucun sens car P_Pile est générique
procedure MonProgramme is
package P_Pile_Character is new P_Pile(Character) ;
use P_Pile_Character ;
P : T_Pile ;
begin
push(P,'Z') ;
push(P,'#') ;
...
end MonProgramme ;
With P_Pile ;
procedure MonProgramme is
package P_Pile_Character is new P_Pile(Character) ;
use P_Pile_Character ;
package P_Pile_Float is new P_Pile(Float) ;
use P_Pile_Float ;
P : T_Pile ; --Est-ce une pile de Float ou une pile de Character ?
begin
...
end MonProgramme ;
Privilégiez alors l'écriture pointée afin de préciser l'origine de vos objets et méthodes :
P : P_Pile_Float.T_Pile ; --Plus de confusion possible
Comme vous avez pu le constater, la généricité est une notion compliquée mais puissante. Elle vous permettra d'élaborer des outils complexes (comme les piles ou les files) disponibles pour toute une panoplie de type. Elle nécessite en revanche que vous réfléchissiez aux classes de types qui pourraient être employées. Ne vous avais-je pas dit que le langage Ada avait un fort typage ?
Après un chapitre sur la généricité plutôt (voire carrément) théorique, nous enchaînons avec un second tout aussi compliqué, mais ô combien important. Je dirais même que c'est le chapitre phare de cette partie IV : l'héritage. Et pour cause, l'héritage est, avec l'encapsulation, la propriété fondamentale de la programmation orientée objet.
Nous allons, tout au long de ce chapitre, prendre un exemple pour illustrer ce concept compliqué : imaginez que nous souhaitions créer un jeu de stratégie médiéval. Votre mission (si vous l'acceptez :soleil: ) : créer des objets pour modéliser les différentes unités du jeu : chevalier, archer, arbalétrier, catapulte, voleur, écuyer ... ainsi que leurs méthodes associées : attaque frontale, défense, tir, bombardement, attaque de flanc ...
Eh bien c'est quand papy décède et que les enfants et petits-enfants se partagent le pactole ! :p
Mouais, :( j'espérais un peu plus de sérieux. Mais vous n'êtes pas si loin de la définition d'héritage en programmation. Non, nos programmes ne vont pas décéder mais ils vont transmettre leurs biens. En effet, dire qu'un objet B hérite d'un objet A, cela revient à dire que B bénéficiera de tous les attributs de A : types, fonctions, procédures, variables ... et ce, sans avoir besoin de tout redéfinir.
On dit alors que A est l'objet père et B l'objet fils. On parle alors d'héritage Père-Fils (ou mère-fille, c'est selon les accords). De même, si un objet C hérite de B, alors il bénéficiera des attributs de B, mais aussi de A par héritage. On dira que C est le fils de B et le petit-fils de A.
Un dernier exemple : si un deuxième objet D hérite de A, on dira que D et B sont deux objets frères. Ils bénéficient chacun des attributs du père A, mais B ne peut pas bénéficier des attributs de son frère D et réciproquement : il n'y a pas d'héritage entre frères en programmation. Comment cela vous êtes perdus ? :p Allez, pour ceux qui ont toujours été nuls en généalogie, voici un petit schéma :
Chaque flèche signifie "hérite de".
Héritage : une approche par l'exemple
Pour mieux comprendre l'utilité de l'héritage (et avant de découvrir son fonctionnement en Ada), revenons à l'exemple donné en introduction. Nous souhaiterions créer un type d'objet pour représenter des unités militaires pour un jeu de stratégie. Quelles sont les attributs et fonctionnalités de base d'une unité militaire ? Elle doit disposer d'un potentiel d'attaque, de défense et de mouvement. Elle doit également pouvoir attaquer, se défendre et se déplacer.
Toutefois, certaines unités ont des "pouvoirs spéciaux" afin de rendre le jeu plus attrayant : certaines sont montées à cheval pour prendre l'ennemi de vitesse et l'attaquer par le côté ; d'autres ont la capacité d'attaquer à distance à l'aide d'arcs, d'arbalètes ou d'engin de siège ; et dans le cas des engins de siège, les unités qui en sont dotées ont alors en plus la possibilité de bombarder l'ennemi pour l'affaiblir avant l'assaut. Résumons par un petit schéma :
Les unités d'artillerie bénéficient des capacités des unités archères, qui elles-mêmes disposent des capacités des Unités classiques(mais l'inverse n'est pas vrai). De même, les unités montéesdisposent des capacités des unités classiquesmais pas de celles des unités archères. On dit alors que tous ces types d'unités font partie de la classe de typesUnité. Les types Archer et Artillerie font partie de la sous-classe fille Archers, mais pas de la sous-classe sœur Unités montées.
Mais plutôt que ce lourd tableau, nous modéliserons cette situation à l'aide d'un diagramme de classe UML comme nous l'avons fait précédemment avec nos objets A, B, C et D :
Bien ! Maintenant que les idées sont fixées, voyons comment réaliser ce fameux héritage en Ada.
Supposons que nous disposions d'un package P_Unit contenant le type T_Unit et ses méthodes :
package P_Unit is
type T_Unit is record
Att, Def, Mov, Vie : Integer := 0 ;
end record ;
procedure Attaque(Attaquant, Defenseur : in out T_Unit) ;
procedure Defense(Defenseur : in out T_Unit) ;
procedure Deplacer(Unite : in out T_Unit) ;
function Est_Mort(Unite : in T_Unit) return Boolean ;
end P_Unit ;
Le corps des méthodes sera minimal, pour les besoins du cours :
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Unit is
procedure Attaque(Attaquant, Defenseur : in out T_Unit) is
begin
Put_line(" >> Attaque frontale !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.att) ;
end Attaque ;
procedure Defense(Defenseur : in out T_Unit) is
begin
put_line(" >> Votre unite se defend.") ;
Defenseur.def := integer(float(Defenseur.def) * 1.25) ;
end Defense ;
procedure Deplacer(Unite : in out T_Unit) is
begin
Put_line(" >> Votre unite se deplace") ;
end Deplacer ;
function Est_Mort(Unite : in T_Unit) return Boolean is
begin
return (Unite.vie <= 0) ;
end Est_Mort ;
end P_Unit ;
On n'est pas sensé mettre le type T_Unit en generic et private voire limited private ?
Un type générique ? Non, ça n'a rien à voir avec l'héritage. Ce doit être un type concret ! En revanche, nous devrions encapsuler notre type pour réaliser proprement notre objet mais pour les besoins du cours, nous ne respecterons pas cette règle d'or (pour l'instant seulement).
Nous disposons également d'un programme Strategy :
with P_Unit ; use P_Unit ;
with Ada.Text_IO ; use Ada.Text_IO ;
procedure Strategy is
Hallebardier : T_Unit := (Att => 3,
Def => 5,
Mov => 1,
Vie => 10) ;
Chevalier : T_Unit := (Att => 5,
Def => 2,
Mov => 3,
Vie => 8) ;
begin
Attaque(Chevalier,Hallebardier) ;
if Est_mort(Hallebardier)
then put_line("Echec et Mat, baby !") ;
else put_line("Pas encore !") ;
end if ;
end Strategy ;
Un premier package fils
Mais comme Chevalier devrait être une unité montée, nous voudrions proposer le choix au joueur entre attaquer et attaquer par le flanc. Nous allons donc créer un package spécifique pour gérer ces unités montées : nous ne nous soucierons pas du type pour l'instant, seulement du package. Nous ne voudrions pas être obligés de recréer l'intégralité du package P_Unit, nous allons donc devoir utiliser cette fameuse propriété d'héritage. Attention, ouvrez grand les yeux, ça va aller très vite :
package P_Unit.Mounted is
procedure Attaque_de_flanc(Attaquant, Defenseur : in out T_Unit) ;
end P_Unit.Mounted ;
:magicien: TADAAA ! ! ! C'est fini, merci pour le déplacement !
:waw: :waw: :waw: ............ Attend ! C'est tout ? Mais t'as absolument rien fait ? :pirate:
Mais bien sûr que si ! Soyez attentifs au nom : package P_Unit.Mounted ! Le simple fait d'étendre le nom du package père (P_Unit) à l'aide d'un point suivi d'un suffixe (Mounted) suffit à réaliser un package fils. Simple, n'est-ce pas ? En plus, il est complètement inutile d'écrire with P_Unit, puisque notre package hérite de toutes les fonctionnalités de son père (types, méthodes, variables ...) !
Quant au corps de ce package, il sera lui aussi très succinct :
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Unit.Mounted is
procedure Attaque_de_flanc(Attaquant, Defenseur : in out T_Unit) is
begin
Put_line(" >> Attaque par le flanc ouest !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.att*Attaquant.mov) ;
end Attaque_de_flanc ;
end P_Unit.Mounted ;
Utilisation de notre package
Maintenant, revenons à notre programme Strategy. Nous souhaitons laisser le choix au joueur entre Attaque et Attaque_De_Flanc, ou plus exactement entre P_Unit.Attaque et P_Unit.Mounted.Attaque_De_Flanc. Nous devons donc spécifier ces deux packages, le père et le fils, en en-tête :
with P_unit ; use P_Unit ;
with P_Unit.Mounted ; use P_Unit.mounted;
with Ada.Text_IO ; use Ada.Text_IO ;
procedure Strategy is
Hallebardier : T_Unit := (Att => 3,
Def => 5,
Mov => 1,
Vie => 10) ;
Chevalier : T_Unit := (Att => 5,
Def => 2,
Mov => 3,
Vie => 8) ;
choix : character ;
begin
Put("Voulez-vous attaquer frontalement (1) ou par le flanc (2) ? ") ;
get(choix) ; skip_line ;
if choix = '1'
then Attaque(Chevalier,Hallebardier) ;
else Attaque_de_flanc(Chevalier,Hallebardier) ;
end if ;
if Est_mort(Hallebardier)
then put_line("Echec et Mat, baby !") ;
else put_line("Pas encore !") ;
end if ;
end Strategy ;
Il n'y a là rien d'extraordinaire, vous l'auriez deviné vous-même.
Deux héritages successifs !
Passons maintenant à nos packages pour archers et artillerie. Le premier doit hériter de P_Unit, mais vous savez faire désormais (n'oubliez pas de réaliser le corps du package également) :
package P_Unit.Archer is
procedure Attaque_a_distance(Attaquant, Defenseur : in out T_Unit) ;
end P_Unit.Archer ;
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Unit.Archer is
procedure Attaque_a_distance(Attaquant, Defenseur : in out T_Unit) is
begin
Put_line(" >> Une pluie de fleches est decochee !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.tir) ;
end Attaque_a_distance ;
end P_Unit.Archer ;
Quant au package pour l'artillerie, nous souhaiterions qu'il hérite de P_Unit.Archer, de manière à ce que les catapultes et trébuchets puisse attaquer, attaquer à distance et en plus bombarder ! Il va donc falloir réutiliser la notation pointée :
package P_Unit.Archer.Artillery is
procedure Bombarde(Attaquant, Defenseur : in out T_Unit) ;
end P_Unit.Archer.Artillery ;
package body P_Unit.Archer.Artillery is
procedure Bombarde(Attaquant, Defenseur : in out T_Unit) is
begin
Put_line(" >> Bombardez-moi tout ça !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.bomb) ;
end Bombarde ;
end P_Unit.Archer.Artillery ;
Et le tour est joué ! Seulement, cela va devenir un peu laborieux d'écrire en en-tête de notre programme :
with P_Unit.Archer.Artillery ; use P_Unit.Archer.Artillery ;
Alors pour les "fainéants du clavier", Ada a tout prévu ! Il y a une instruction de renommage : renames. Celle-ci va nous permettre de créer un package qui sera exactement le package P_Unit.Archer.Artillery mais avec un nom plus court :
With P_Unit.Archer.Artillery ;
package P_Artillery renames P_Unit.Archer.Artillery ;
Notez qu'il est complètement inutile de réaliser le corps de ce package P_Artillery, ce n'est qu'un surnommage.
Héritage avec des packages privés
Perso, je ne vois pas vraiment l'intérêt de ce fameux héritage. :( On aurait très bien pu faire trois packages P_Mounted, P_Archer et P_Artillery avec un With P_Unit, et le tour était joué ! Quel intérêt de faire des packages Père-fils ?
L'intérêt est double : primo, cela permet de hiérarchiser notre code et notre travail, ce qui n'est pas négligeable lors de gros projets. Secundo, vous oubliez que nous avons négligé l'encapsulation ! Il n'est pas bon que notre type T_Unit soit public. En fait, nous devrions modifier notre package P_Unit pour privatiser T_Unit et lui fournir une méthode pour l'initialiser :
package P_Unit is
type T_Unit is private ;
Function Init(Att, Def, Mov, Vie : Integer := 0) return T_Unit ;
procedure Attaque(Attaquant, Defenseur : in out T_Unit) ;
procedure Defense(Defenseur : in out T_Unit) ;
procedure Deplacer(Unite : in out T_Unit) ;
function Est_Mort(Unite : in T_Unit) return Boolean ;
private
type T_Unit is record
Att, Def, Mov, Vie : Integer := 0 ;
end record ;
end P_Unit ;
Mais, si T_Unit devient privé, alors les procédures Attaque_De_Flanc, Attaque_a_distance ou Bombarde n'y auront plus accès puisqu'elles ne sont pas dans le corps du package P_Unit !?! o_O
Tout dépend de la solution que vous adoptez. Si vous faites appel aux instructions With et pas à l'héritage, ces procédures rencontreront effectivement des problèmes. Mais si vous faites appel à l'héritage alors il n'y aura aucun souci, car les spécifications d'un package fils ont visibilité sur les spécifications publiques et privées du package père ! L'héritage se fait donc également sur la partie private. L'inverse n'est bien sûr pas vrai : le père n'hérite rien de ses fils.
Rappels : les flèches signifient qu'une partie a la visibilité sur ce qui est écrit dans une autre.
On comprend alors que la propriété d'héritage donne de très nombreux droits d'accès aux packages fils, bien plus que ne l'autorisent les clauses With. Les packages fils peuvent ainsi manipuler à leur guise les types privés, ce qui ne serait pas possible autrement. Pour rappel, vous pouvez revoir la visibilité d'un programme sur un package en cliquant ci-dessous :
Héritage avec des packages génériques
Réalisation
Nous allons considérer pour cette sous-partie, et cette sous-partie seulement, que nos points de vie, d'attaque, de défense ... ne sont pas des integer comme indiqués précédemment mais des types entiers génériques ! Je sais, ça devient compliqué mais il faut que vous vous accrochiez. ;) Nous obtenons donc un nouveau package P_Unit :
generic
type T_Point is range <> ;
Valeur_Initiale : T_Point ; --Tiens ! Une variable générique ?!?
package P_Unit is
type T_Unit is private ;
Function Init(Att, Def, Mov, Vie : T_Point := Valeur_Initiale) return T_Unit ; --Revoilà la variable générique !
procedure Attaque(Attaquant, Defenseur : in out T_Unit) ;
procedure Defense(Defenseur : in out T_Unit) ;
procedure Deplacer(Unite : in out T_Unit) ;
function Est_Mort(Unite : in T_Unit) return Boolean ;
private
type T_Unit is record
Att, Def, Mov, Vie : T_Point := Valeur_Initiale ; --Encore cette variable générique !
end record ;
end P_Unit ;
Nous avons donc un type d'objet T_Unit qui est non seulement privé mais également générique : les points de vie, de défense ... sont entiers mais on ne sait rien de plus : sont-ce des Integer ? des Natural ? des Positive ? ... On n'en sait rien et c'est d'ailleurs pour cela que j'ai du ajouter une variable générique pour connaître la valeur initiale (eh oui, 0 ne fait pas partie des Positive par exemple :) ). Mais la difficulté n'est pas là. Puisque les fils héritent des propriétés du père, si P_Unit est générique alors nécessairement tous ses descendants le seront également ! Prenons le cas de P_Unit.Mounted, nous allons devoir le modifier ainsi :
generic
package P_Unit.Mounted is
procedure Attaque_de_flanc(Attaquant, Defenseur : in out T_Unit) ;
end P_Unit.Mounted ;
Tu as oublié de réécrire le type T_Point et la variable Valeur_Initiale après generic !
Non, je n'ai rien oublié. Le type T_Point et la variable Valeur_Initiale ont déjà été défini dans le package père, donc P_Unit.Mounted les connaît déjà. On doit simplement réécrire le mot generic mais sans aucun paramètre formel (à moins que vous ne vouliez en ajouter d'autres bien sûr).
Instanciation
Et c'est à l'instanciation que tout cela devient vraiment (mais alors VRAIMENT :diable: ) pénible. Si vous souhaitez utiliser P_Unit.Mounted vous allez devoir l'instancier, vous vous en doutez ! Sauf qu'il n'a pas de paramètres formels ! Donc il faut préalablement instancier le père :
package MesUnites is new P_Unit(Natural,0) ;
Et pour instancier le fils, il faudra utiliser non plus le package générique père P_Unit mais le package que vous venez d'instancier :
package MesUnitesMontees is new MesUnites.Mounted ;
Je vois que certains commencent à peiner. Alors revenons à des packages non-génériques, cela vaudra mieux.
Nous n'avons fait pour l'instant que réaliser des packages pères-fils avec de nouvelles méthodes mais notre diagramme de classe indiquait que les unités d'archers devaient bénéficier de points de tir et les unités d'artillerie de points de tir et de bombardement.
Comment faire ? Nous avons la possibilité d'utiliser des types structurés polymorphes ou mutants mais cela va à l'encontre de la logique de nos packages ! Il faudrait que P_Unit prévoit dès le départ la possibilité de disposer de points de tir ou de bombardement alors qu'il ne les utilisera pas. De plus, sur d'importants projets, le programmeur réalisant le package P_Unit n'est pas nécessairement le même que celui qui réalise P_Unit.Archer ! Les fonctionnalités liées au tir et au bombardement ne le concernent donc pas, ce n'est pas à lui de réfléchir à la façon dont il faut représenter ces capacités. Enfin, les types mutants ou polymorphes impliquent une structure très lourde (souvenez vous des types T_Bulletins et des nombreux case imbriqués les uns dans les autres) : difficile de relire un tel code, il sera donc compliqué de le faire évoluer, de le maintenir, voire même simplement de le réaliser.
C'est là qu'interviennent les types étiquetés ou tagged en Ada. L'idée du type étiqueté est de fournir un type de base T_Unit fait pour les unités de base, puis d'en faire des "produits dérivés" appelés T_Mounted_Unit, T_Archer_Unit ou T_Artillery_Unit enrichis par rapport au type initial. Pour cela nous allons d'abord étiqueter notre type T_Unit, pour spécifier au compilateur que ce type pourra être dérivé en d'autres types (attention, on ne parle pas ici d'héritage mais de dérivation, nuance) :
package P_Unit is
type T_Unit is tagged private ;
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Unit ;
procedure Attaque(Attaquant, Defenseur : in out T_Unit) ;
procedure Defense(Defenseur : in out T_Unit) ;
procedure Deplacer(Unite : in out T_Unit) ;
function Est_Mort(Unite : in T_Unit) return Boolean ;
private
type T_Unit is tagged record
Att, Def, Mov, Vie : Integer := 0 ;
end record ;
end P_Unit ;
Chacun aura remarqué l'ajout du mot tagged pour indiquer l'étiquetage du type. Vous aurez également remarqué que le type T_Unit ne fait toujours pas mention des compétences Tir ou Bomb et pour cause. Nous allons maintenant créer un type T_Archer_Unit qui dérivera du type T_Unit initial :
package P_Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
procedure Attaque_a_distance(Attaquant : in out T_Archer_Unit ; Defenseur : in out T_Unit) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Unit.Archer ;
Vous remarquerez que le type T_Archer_Unit ne comporte pas de mention tagged. Normal, c'est un type dérivé d'un type étiqueté, il est donc lui-même étiqueté. L'instruction type T_Archer_Unit is new T_Unit ... est claire : T_Archer_Unit est un nouveau type d'unité, issu de T_Unit. L'instruction with record indique les spécificités de ce nouveau type, les options supplémentaires si vous préférez. A noter que l'instruction with n'a pas ici le même sens que lorsque nous écrivons with Ada.Text_IO, c'est là toute la souplesse du langage Ada.
Et nos méthodes ?
Méthodes héritées de la classe mère
Mais ?!? Comme T_Archer_Unit n'est pas un subtype de T_Unit, notre procédure Attaque ne va plus marcher avec les archers ?! :o
Eh bien si ! Un type étiqueté hérite automatiquement des méthodes du type père ! C'est comme si nous bénéficiions automatiquement d'un méthode procedure Attaque(Attaquant, Defenseur : in out T_Archer_Unit) sans avoir eu besoin de la rédiger. On dit que la méthode est polymorphe puisqu'elle accepte plusieurs "formes" de données. Sympa non ?
Méthodes s'appliquant à l'intégralité de la classe
Attend ! T'es en train de me dire que les archers ne pourront attaquer que d'autres archers ? Comme je fais pour qu'un archer puisse attaquer une unité à pied ou un cavalier ? Je dois faire du copier-coller et surcharger la méthode Attaque ?
En effet, c'est problématique et ça risque d'être long.
Heureusement, vous savez désormais que le type T_Archer_Unit est de la classe de type de T_Unit, il suffit simplement de revoir notre méthode pour qu'elle s'applique à toute la classe T_Unit, c'est-à-dire le type T_Unit et sa descendance ! Il suffira que le paramètre Defenseur soit accompagné de l'attribut 'class :
package P_Unit is
type T_Unit is tagged private ;
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Unit ;
procedure Attaque(Attaquant : in T_Unit ; Defenseur : in out T_Unit'class) ;
procedure Defense(Defenseur : in out T_Unit) ;
procedure Deplacer(Unite : in out T_Unit) ;
function Est_Mort(Unite : in T_Unit) return Boolean ;
private
type T_Unit is tagged record
Att, Def, Mov, Vie : Integer := 0 ;
end record ;
end P_Unit ;
Vous remarquerez que je n'abuse pas de cet attribut puisque tous les types dérivant de T_Unit hériteront automatiquement des autres méthodes. De même, nous pouvons modifier notre package P_Unit.Archer pour que l'attaque à distance s'applique à toute la classe de type T_Unit :
package P_Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
procedure Attaque_a_distance(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Unit.Archer ;
Grâce à l'attribut 'class, nous avons donc indiqué que notre méthode ne s'applique pas qu'à un seul type mais à toute une classe de type. Compris ? Bien, nous allons maintenant créer le type T_Artillery en le dérivant de T_Archer_Unit. Enfin, quand je dis "nous", je veux dire "vous allez créer ce type" ! Moi j'ai assez travaillé :soleil: .
package P_Unit.Archer.Artillery is
type T_Artillery_Unit is new T_Archer_Unit with private ;
procedure Bombarde(Attaquant : in T_Artillery_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Artillery_Unit is new T_Archer_Unit with record
bomb : integer := 0 ;
end record ;
end P_Unit.Archer.Artillery ;
Là encore, pas besoin d'étiqueter T_Artillery_Unit puisqu'il dérive du type T_Archer_Unit qui lui-même dérive du type étiqueté T_Unit. De même, notre nouveau type hérite des méthodes des classes T_Unit et T_Archer_Unit.
Eh ! Mais comment on fait pour T_Mounted_Unit vu qu'il n'a aucun attribut de plus que T_Unit ?
La réponse en image (ou plutôt en code source) :
package P_Unit.Mounted is
Type T_Mounted_Unit is new T_Unit with private ;
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Unit ; Defenseur : in out T_Unit'class) ;
private
Type T_Mounted_Unit is new T_Unit with null record ;
end P_Unit.Mounted ;
Eh oui, il suffit d'indiquer with null record : c'est-à-dire "sans aucun enregistrement". Et n'oubliez pas que notre nouveau type héritera directement des méthodes de la classe mère T_Unit, mais pas de celles des classes sœurs.
Surcharge de méthodes
C'est normal que mon code ne compile plus ? GNAT ne veut plus de mon type T_Archer_Unit à cause de la fonction Init ?!? o_O
C'est normal en effet puisque par héritage, la classe de type T_Archer_Unit bénéficie d'une méthode function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit. Sauf que cette méthode a été prévue à la base pour renvoyer un type structuré contenant 4 attributs : att, def, mov et vie. Or le type T_Archer_Unit en contient un cinquième supplémentaire : Tir ! Il y a donc une incohérence et GNAT vous impose donc de remplacer cette méthode ("Init" must be overridden). Pour cela, rien de plus simple, il suffit de réécrire cette méthode :
package P_Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit ;
procedure Attaque_a_distance(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Unit.Archer ;
Le mot-clé overriding apparu avec Ada2005, permet d'indiquer que nous réécrivons la méthode et qu'elle remplace donc la méthode mère. Toutefois, ce mot-clé est optionnel et rien ne serait chamboulé si vous le retiriez hormis peut-être la lisibilité de votre code. Notez également qu'aucun attribut Tir n'a été ajouté, la méthode devra donc attribuer une valeur par défaut à cet attribut. Pour disposer d'une véritable fonction d'initialisation, il faudra surcharger la méthode :
package P_Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit ;
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Archer_Unit ;
procedure Attaque_a_distance(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Unit.Archer ;
Notez qu'il n'est pas nécessaire de remplacer cette méthode pour les T_Mounted_Unit qui sont identiques aux T_Unit, mais que le même travail devra en revanche s'appliquer à la classe de type T_Artillery_Unit :
package P_Unit.Archer.Artillery is
type T_Artillery_Unit is new T_Archer_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Artillery_Unit ;
function Init(Att, Def, Mov, Vie, Tir, Bomb : Integer := 0) return T_Artillery_Unit ;
procedure Bombarde(Attaquant : in T_Artillery_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Artillery_Unit is new T_Archer_Unit with record
bomb : integer := 0 ;
end record ;
end P_Unit.Archer.Artillery ;
Un autre avantage des classes
Vous remarquerez que toutes mes méthodes à deux paramètres ont toujours en premier paramètre l'attaquant. Pourquoi est-ce important ? Eh bien car avec une classe il est possible d'éluder le premier paramètre en écrivant ceci :
Chevalier.attaque(Hallebardier) ;
Au lieu du sempiternel et peu parlant :
Attaque(Chevalier,Hallebardier) ;
Plus clair non ? Les deux écritures demeurent possibles, mais vous constaterez que l'écriture pointée aura de plus en plus ma préférence (notamment car elle est utilisée dans la plupart des langages orientés objets actuels comme Java ... ). Pour que cette écriture puisse être possible il faut que votre type soit étiqueté (qu'il définisse une classe) et qu'il coïncide avec le premier paramètre de vos méthodes ! C'est donc pour cela que l'attaquant était mon premier paramètre : il est plus logique d'écrire Attaquant.attaque(defenseur) que defenseur.attaque(attaquant) ! :-°
Bilan :
Avant d'aller encore plus loin dans ces notions de classe, d'héritage et de dérivation, faisons un point sur ce que l'on sait de la programmation orientée objet.
Pour créer un objet (exemple : Chevalier) nous devons préalablement créer une classe (exemple : T_Unit ou T_Mounted_Unit).
En Ada, une classe correspond à un type étiqueté (tagged) et à toute sa descendance.
Une classe doit être encapsulée et donc de type private ou limited private.
Une classe doit donc disposer de méthodes permettant de créer des objets, de les modifier, de les supprimer ... La méthode ne s'applique à la classe entière que si le type parent est suivi de l'attribut 'class.
Pour parfaire l'encapsulation, types et méthodes doivent être enfermés dans un package spécifique. Les types dérivés sont eux enfermés dans des packages-fils : c'est l'héritage.
Éventuellement, la classe peut être générique permettant à d'autres programmeurs d'employer vos outils avec divers types de données.
Enfin, terminons par un bref historique car il est intéressant de remarquer que le langage Ada proposait, dès la norme Ada83, bon nombre de ces propriétés : types structurés mutants et polymorphes, héritage via le système de packages, types privés et limités privés, généricité ... bref, bon nombre de rudiments de POO qui seront plus tard complétés par la norme Ada95 avec l'ajout de l'étiquetage et la classification. Notez également que le langage Ada a conservé le système de package et de fort typage quand le C++ ou le Java (et bon nombre d'autres langages orientés objets) ont opté pour un mot-clé class qui, en quelques sortes, "fusionne" ces notions mais ne permet plus de choisir parmi les différentes propriétés vues précédemment.
Ce chapitre est en lien direct avec le précédent : nous allons approfondir nos connaissances sur la dérivation de type et surtout améliorer notre façon de concevoir nos objets. Vous allez le voir, notre façon de procéder pour concevoir nos unités militaires est encore rudimentaire et n'exploite pas toutes les capacités du langage Ada en matière de POO. Il y a encore une propriété fondamentale de la POO que nous n'avons pas exploitée : le polymorphisme.
Nous allons continuer à bricoler nos packages. Désormais, toutes nos unités peuvent attaquer de front puisque par dérivation du type étiqueté T_Unit, toutes bénéficient de la même méthode attaque(). Malheureusement, s'il semble logique qu'un fantassin ou un cavalier puisse attaquer de front, il est plutôt suicidaire d'envoyer un archer ou une catapulte en première ligne. Il faudrait que les types issus de la classe T_Archer_Unit disposent d'une méthode attaque() spécifique.
En fait il faudrait surcharger la méthode attaque() c'est ça ?
Pas exactement. Surcharger la méthode consisterait à écrire une seconde méthode attaque() (distincte) avec des paramètres différents (de par leur nombre, leur type ou leur mode de passage). Or nous bénéficions déjà, par dérivation de type, d'une méthode attaque(attaquant : in T_Archer_Unit ; defenseur : out T_Unit'class). Nous ne souhaitons pas la surcharger mais bien la réécrire.
Bref, tu veux qu'on utilise overriding c'est cela ?
C'est cela en effet. Notre package P_Unit.Archer deviendrait ainsi :
package P_Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit ;
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Archer_Unit ;
procedure Attaque_a_distance(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
overriding
procedure Attaque(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Unit.Archer ;
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Unit.Archer is
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit is
begin
return (Att, Def, Mov, Vie, 0) ;
end Init ;
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Archer_Unit is
begin
return (Att, Def, Mov, Vie, Tir) ;
end Init ;
procedure Attaque_a_distance(Attaquant, Defenseur : in out T_Unit) is
begin
Put_line(" >> Une pluie de fleches est decochee !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.tir) ;
end Attaque_a_distance ;
procedure Attaque((Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) is
begin
Put_line(" >> Une attaque frontale avec ... des archers ?!? Ecrasez-les !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - 1) ;
end Attaque ;
end P_Unit.Archer ;
En procédant ainsi, notre méthode de classe Attaque() aura diverses formes selon que ses paramètres seront de la sous-classe T_Archer_Unit ou non. On dit alors que la méthode est polymorphe. Quel intérêt ? Créons par exemple un sous-programme Tour_joueur :
procedure Tour_Joueur(Joueur1, Joueur2 : in out T_Unit'class) is
choix : character ;
begin
put_line("Voulez-vous Attaquer ou Defendre ?") ;
get(choix) ; skip_line ;
if choix='a' or choix='A'
then Joueur1.attaque(joueur2) ;
else Joueur1.defense ;
end if ;
end Tour_Joueur ;
Que va afficher la console ? >> Attaque frontale ! ou >> Une attaque frontale avec ... des archers ?!? Ecrasez-les ! ? Eh bien vous n'en savez rien, même au moment de la compilation ! Tout dépendra des choix effectués par l'utilisateur : selon que Joueur1 sera un archer (ou une artillerie) ou bien un fantassin (ou un cavalier), le programme n'effectuera pas le même travail. Le choix de la méthode attaque() est ainsi reporté au moment de l'utilisation du logiciel, et non au moment de la compilation.
Objets polymorphes
Objets polymorphes non mutants
Poussons le polymorphisme plus loin encore. Nous souhaiterions maintenant proposer un système de héros au joueur. Pas besoin de créer une classe T_Heros, le principe est simple : un héros est une unité presque comme les autres, sauf qu'elle est unique et qu'il sera possible au joueur de choisir sa classe : fantassin, archer, cavalier ou ... artillerie ?!? o_O . Nous voudrions donc créer un objet Massacror de la classe de type T_Unit mais qui aurait la possibilité de devenir de type T_Mounted_Unit ou T_Archer_Unit selon la volonté du joueur, et ainsi de bénéficier de telle ou telle capacité.
On n'est pas censé ne pas pouvoir changer de type ? :-° T'arrêtes pas de répéter qu'Ada est un langage fortement typé !
En effet, nos objets ne peuvent changer de type ou de classe. Nous ne pourrons pas écrire ceci :
Ce qui est bien embêtant. Heureusement, la rigueur du langage Ada n'exclut pas un peu de souplesse ! Et si nous faisions appel à l'attribut 'class ? Déclarons Massacror :
Problème, GNAT me demande alors d'initialiser mon objet ! Plusieurs choix sont possibles. Vous pouvez utiliser l'une des méthodes d'initialisation, par exemple :
Massacror : T_Unit'class := P_Unit.Archer.Init(150,200,20,200,300) ; --Ca c'est du bourrin !
Votre objet sera alors automatiquement défini comme de type T_Archer_Unit. Pas terrible pour ce qui est du choix laissé au joueur. :( Une autre façon est de l'initialiser avec un autre objet :
Massacror : T_Unit'class := Hallebardier ;
Mais on retrouve le même problème : Massacror sera du même type que Hallebardier. Vous pouvez certes utiliser des blocs declare, mais vous risquez de créer un code lourd, redondant et peu lisible. La solution est davantage de demander à l'utilisateur de faire son choix au moment de la déclaration de votre objet à l'aide d'un nouveau sous-programme Choix_Unite. Ce sous-programme renverra non pas un objet de type T_Unit mais de la classe T_Unit'class :
function Choix_Unite return T_Unit'class is
choix : character ;
begin
put_line("Archer, Hallebardier ou Chevalier ?") ;
get(choix) ; skip_line ;
if choix='a' or choix='A'
then return P_Unit.Archer.init(6,1,1,8,7) ;
elsif choix='H' or choix='h'
then return P_Unit.init(5,8,1,10) ;
else return P_Unit.Mounted.init(7,3,2,15) ;
end if ;
end choix_unit ;
...
Massacror : T_unit'class := choix_unit ;
Ainsi, il est impossible au programmeur de connaître à l'avance le type qui sera renvoyé et donc le type de Massacror ! Génial non ? C'est l'avantage du polymorphisme.
Euh ... j'ai comme un doute sur le fait qu'un chevalier puisse lancer des flèches... :colere2: Comment je fais ensuite pour savoir si je peux utiliser Attaque_a_distance ou pas ?
Pas d'affolement, vous pouvez toujours tester l'appartenance de Massacror à tel ou tel type ou classe de type et ainsi éviter les erreurs d'utilisation de méthodes, simplement en écrivant :
if Massacror in T_Archer_Unit'class
then ...
if Massacror in T_Mounted_Unit
then ...
Objets polymorphes et mutants
Allons toujours plus loin dans le polymorphisme. Pourquoi nos héros ne pourraient-ils pas changer de type ? Un héros, c'est fait pour évoluer au cours du jeu sinon ça n'a aucun intérêt. Que seraient devenus Songoku, Wolverine, Tintin ou le roi Arthur s'ils n'avaient jamais évoluer ? Pourquoi ne pas écrire :
Seulement là, ce n'est pas le compilateur qui va vous arrêter (rien ne cloche du point de vue du langage), mais votre programme. Tout ira bien si vous ne changez pas le type de Massacror. Mais si vous décidez qu'il sera archer, puis chevalier ... PATATRA ! raised CONSTRAINT_ERROR : ###.adb:## tag check failed ! Autrement dit, problème lié à l'étiquetage. En effet, après la déclaration-initialisation de votre objet Massacror, celui-ci dispose d'un type bien précis. Le programmeur ne le connaît pas, certes, mais ce type est bien défini, et il n'a pas de raison de changer ! En fait, il n'a surtout pas le droit de changer.
Bref, c'est complètement bloqué. Même l'attribut 'class ne sert à rien. On est vite rattrapé par la rigueur du langage. :colere2:
Rassurez-vous, il y a un moyen de s'en sortir. L'astuce consiste à faire appel aux pointeurs en créant des pointeurs sur la classe entière (le type racine et toute sa descendance).
Argh ! Noooon ! Pas les pointeurs ! :waw:
Rassurez-vous, nous n'aurons pas besoin de notions très poussées (pour l'instant) et je vous ai fait faire bien pire. Comme nous l'avons dit, Ada est un langage à fort typage : il doit connaître à la compilation la quantité de mémoire statique qui sera nécessaire au programme. Or,entre un objet de type T_Unit et un objet de type T_Archer_unit, il y a une différence notable (la compétence Tir notamment). Impossible de redimensionner durant l'exécution l'emplacement mémoire de notre objet Massacror. A moins de faire appel aux pointeurs et à la mémoire dynamique ! Un pointeur n'étant en définitive qu'une adresse, sa taille ne variera pas, qu'il pointe sur un T_Unit ou un T_Archer_Unit ! Nous allons pour cela faire de nouveau appel à l'attribut 'class :
type T_Heros is access all T_Unit'class ;
Massacror : T_Heros ;
Et, "ô merveille!", plus aucune initialisation n'est nécessaire ! Toutefois, n'oubliez pas que vous manipulerez un pointeur et qu'il peut donc valoir null ! Redéfinissons donc notre sous-programme Choix_Unite
function choix_unit return T_Heros is
choix : character ;
begin
put_line("Archer, Hallebardier ou Chevalier ?") ;
get(choix) ; skip_line ;
if choix='a' or choix='A'
then return new T_Archer_Unit'(init(6,1,1,8,7)) ;
elsif choix='H' or choix='h'
then return new T_Unit'(init(5,8,1,10)) ;
else return new T_Mounted_Unit'(init(7,3,2,15)) ;
end if ;
end choix_unit ;
Désormais, plus rien ne peut vous arrêter. Vous pouvez changer de type à volonté et surtout, user et abuser du polymorphisme :
Et là, bien malin sera le programmeur qui saura vous dire si le programme affichera >> Une attaque frontale avec ... des archers ?!? Ecrasez-les ! ou >> Attaque frontale !. Le compilateur lui-même ne saurait vous le dire puisque les objets sont polymorphes et mutants (et donc leur type dépend du bon vouloir du joueur) et que le sous-programme Tour_Joueur fait appel, je vous le rappelle, à la méthode Attaque() qui est elle-même polymorphe !
Compliquons encore la chose, nous souhaiterions cette fois créer une super classe T_Item dont toutes les autres hériteraient : les unités civiles (notées T_Civil), les bâtiments (T_Building) et même les unités militaires (T_Unit) ! A quoi correspondrait la classe T_Item dans notre jeu de stratégie ? Pas à grand chose, je vous l'accorde, mais cela permettrait de mieux hiérarchiser notre code et de regrouper sous une même classe mère les unités militaires du jeu, les unités civiles et les bâtiments ! Et qui dit "même classe mère" dit mêmes méthodes. Cela nous permettra d'utiliser les mêmes méthodes Est_Mort() ou Defend() pour toutes ces classes, et d'user du polymorphisme autant que nous le souhaiterons.
Il est évident qu'aucun objet du jeu ne sera de type T_Item ! Tous les objets appartenant à la classe T_Item seront de type T_Unit, T_Civil, T_Mounted_Unit ... mais jamais (JAMAIS) de type T_Item. Ce type restera seulement théorique : on parle alors de type abstrait et le terme Ada correspondant (apparu avec Ada95) est tout simplement abstract ! Dès lors, vous vous en doutez, nous devrons dériver ce type car il sera impossible de l'instancier. Conséquence, un type abstrait (abstract) est obligatoirement étiqueté (tagged). Un exemple :
type T_Item is abstract tagged record
Def, Vie : Integer ;
end record ;
-- OU ENCORE
type T_Item is abstract tagged private ;
...
private
type T_Item is abstract tagged record
Def, Vie : Integer ;
end record ;
Cela nous obligera à revoir la définition de notre type T_Unit :
type T_Unit is new T_Item with record
Att, Mov : Integer ;
end record ;
Très souvent, le type abstrait est même vide : il ne contient aucun attribut et n'existe que comme une racine à l'ensemble des classes :
type T_Item is abstract tagged null record
Un autre intérêt des classes abstraites est de pouvoir déclarer un seul type de pointeur pointant sur l'ensemble des sous-classes grâce à l'attribut 'class. Cette possibilité nous permettra de jouer à fond la carte du polymorphisme :
type T_Ptr_Item is access all T_Item'class ;
Méthodes abstraites
Qui dit type abstrait dit évidemment, méthodes abstraites. Comme pour les types, il s'agit de méthodes théoriques, inutilisables en l'état : elles auront donc seulement des spécifications et pas de corps (celui-ci sera défini plus tard, avec un type concret) :
procedure defense(defenseur : in out T_Item'class) is abstract ;
function Est_Mort(Item : in T_Item'class) return Boolean is abstract ;
Autre façon de déclarer des méthodes abstraites :
procedure defense(defenseur : in out T_Item'class) is null ;
function Est_Mort(Item : in T_Item'class) return Boolean is null ;
Le terme null indique que cette fonction ne fait absolument rien, cela revient à écrire :
procedure defense(defenseur : in out T_Item'class) is
begin
null ;
end defense ;
Mais qu'est-ce que l'on peut bien faire avec des méthodes abstraites ? o_O
Eh bien, comme pour les types abstraits, on ne peut rien en faire en l'état. Le moment venu, lorsque vous disposerez d'un type concret ou mieux, d'une classe de types concrète, il vous faudra réaliser le corps de cette méthode en la réécrivant à l'aide de l'instruction overriding (c'est pourquoi certains langages parlent plutôt de méthodes retardées). Ces méthodes abstraites nous permettront d'établir une sorte de "plan de montage", une super-méthode pour super-classe, applicable tout autant aux bâtiments qu'aux unités civiles ou militaires. Elles nous évitent de disposer de méthodes distinctes et incompatibles d'un type à l'autre. Bref, ces méthodes abstraites permettent de conserver le paradigme de polymorphisme (et c'est très important en POO). Tout cela nous amène au package suivant (attention, il n'y a pas de corps pour ce package) :
package P_Item is
type T_Item is abstract tagged private ;
procedure Defense(I : in out T_Item'class) is abstract ;
function Est_Mort(I : T_Item'class) return boolean is abstract ;
private
type T_Item is abstract tagged record
def,vie : integer ;
end record ;
end P_Item ;
Et nous oblige à modifier nos anciens packages.
package P_Item.Unit is
type T_Unit is new T_Item with private ;
procedure Init(Unite : out T_Unit'class ; Att, Def, Mov, Vie : Integer := 0) ;
procedure Attaque(Attaquant : in T_Unit'class ; Defenseur : in out T_Unit'class ) ;
procedure Defense(Defenseur : in out T_Item'class) ; --Réalisation concrète de la méthode Defense
procedure Deplacer(Unite : in out T_Unit'class ) ;
function Est_Mort(Unite : in T_Item'class ) return Boolean ; --Réalisation concrète de la méthode Est_Mort
private
type T_Unit is new T_Item with record
Att, Mov : Integer := 0 ;
end record ;
end P_Item.Unit ;
package P_Item.Unit.Archer is
type T_Archer_Unit is new T_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit ;
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Archer_Unit ;
procedure Attaque_a_distance(Attaquant, Defenseur : in out T_Unit) ;
private
type T_Archer_Unit is new T_Unit with record
tir : Integer := 0 ;
end record;
end P_Item.Unit.Archer ;
package P_Item.Unit.Archer.Artillery is
type T_Artillery_Unit is new T_Archer_Unit with private ;
overriding
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Artillery_Unit ;
function Init(Att, Def, Mov, Vie, Tir, Bomb : Integer := 0) return T_Artillery_Unit ;
procedure Bombarde(Attaquant : in out T_Artillery_Unit'class ; Defenseur : in out T_Unit'class) ;
private
type T_Artillery_Unit is new T_Archer_Unit with record
bomb : integer := 0 ;
end record ;
end P_Item.Unit.Archer.Artillery ;
package P_Item.Unit.Mounted is
type T_Mounted_Unit is new T_Unit with private ;
procedure Attaque_de_flanc(Attaquant, Defenseur : in out T_Unit'class) ;
private
type T_Mounted_Unit is new T_Unit with null record ;
end P_Item.Unit.Mounted ;
Nous souhaiterions désormais créer une nouvelle classe d'objet : T_Mounted_Archer ! Pour jouer avec des archers montés disposant à la fois des capacités des archers mais également de celles des unités montées (des cavaliers huns ou mongols par exemple ^^ ). Cette classe dériverait des classes T_Archer_Unit et T_Mounted_Unit comme l'indique le diagramme de classe ci-dessous :
Le seul soucis ... c'est qu'en Ada, comme en Java, il n'y a pas d'héritage multiple !
Hein ?!? Mais y a tromperie sur la marchandise ! C'était marqué dans le titre : héritage multiple. Et pourquoi tu nous parles du langage Java ? Je comptais pas tout réapprendre maintenant que j'ai lu presque tout ce chapitre ! :colere:
Du calme, du calme ... vous devez comprendre au préalable que le diagramme ci-dessus pose un sérieux problème (appelé problème du diamant en raison de sa forme en losange). Les types T_Mounted_Unit et T_Archer_Unit héritent tous deux de la classe de type T_Unit. Ils héritent donc de la méthode Attaque(). Oui, mais celle-ci a été redéfinie pour les archers, souvenez-vous ! Et puisque T_Mounted_Archer devrait hériter des méthodes de T_Mounted_Unit et de T_Archer_Unit, que doit afficher la méthode Attaque() pour un archer monté ? >> Une attaque frontale avec ... des archers ?!? Ecrasez-les ! ou >> Attaque frontale ! ? Il y a un sérieux conflit d'héritage alors que l'atout majeur du langage Ada est censé être la fiabilité. :( Voilà pourquoi l'héritage multiple n'est pas autorisé en Ada comme en Java.
Et si je vous parle du langage Java, c'est parce qu'il s'agit d'un langage entièrement tourné vers la programmation orientée objet : c'est à lui notamment que je pensais quand je vous disais que certains langages comportaient un mot clé class. En revanche, le langage Ada, même s'il disposait de très bons atouts pour aborder la POO, n'était pas conçu pour cela à l'origine. La norme Ada95 aura résolu cette lacune grâce à l'introduction du mot clé tagged et de l'attribut 'class, entre autres. Mais concernant l'héritage multiple et les risques de sécurité qu'il pouvait entraîner, point de solutions. Et c'est du côté du langage Java qu'est venue l'inspiration. Ce dernier n'admet pas non plus d'héritage multiple pour ses class mais dispose d'une entité supplémentaire : l'interface ! La norme Ada2005 s'en est inspirée pour fournir à son tour des types interface.
Qu'est-ce qu'une interface ? C'est simplement un type super-abtrait disposant de méthodes obligatoirement abstraites et qui peut être hérité plusieurs fois par une classe (et sans risques). Nous allons donc créer un type interface T_Mounted qui bénéficiera d'une méthode Attaque_de_flanc et dont hériteront les types T_Mounted_Unit et T_Mounted_Archer. Ce qui nous donnera le diagramme suivant :
Vous aurez remarqué que les flèches d'héritage sont en pointillés pour les interfaces et que leur nom est précédé du terme <<interface>>. On ne dit d'ailleurs pas "hériter d'une interface" mais "implémenter implémenter une interface".
Réaliser des interfaces Ada
Avec une seule interface
Venons-en maintenant au code :
with P_Item.Unit ; use P_Item.Unit ;
package I_Mounted is
type T_Mounted is interface ;
procedure Attaque_de_flanc(Attaquant : in T_Mounted ; Defenseur : in out T_Unit'class) is abstract ;
end I_Mounted ;
Et le corps du package ?
Le corps ? Quel corps ? Le type T_Mounted étant une interface, il est 100% abstrait et ses méthodes associées (comme Attaque_de_flanc) doivent obligatoirement être abstraites. Donc ce package ne peut pas avoir de corps. De plus, il est recommandé de créer un package spécifique pour votre type interface si vous ne voulez pas que GNAT rechigne à compiler. C'est d'ailleurs pour cela que mon package s'appelle I_Mounted et non P_Mounted (I pour interface bien sûr).
Bien ! Notre interface et ses méthodes étant créées, nous pouvons revenir aux spécifications de notre type T_Mounted_Unit qui doit désormais implémenter notre interface :
With I_Mounted ; Use I_Mounted ;
package P_Item.Unit.Mounted is
type T_Mounted_Unit is new T_Unit and T_Mounted with private ;
overriding
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Mounted_Unit is new T_Unit and T_Mounted with null record ;
end P_Item.Unit.Mounted ;
Il n'est pas utile de modifier le corps de notre package puisque la procédure Attaque_de_flanc() existait déjà. Comme vous avez du vous en rendre compte, il suffit d'ajouter and T_Mounted à la définition de notre type pour implémenter l'interface.
Venons-en maintenant à notre objectif principal : créer un type T_Mounted_Archer :
With I_Mounted ; Use I_Mounted ;
package P_Item.Unit.Archer.Mounted is
type T_Mounted_Archer is new T_Archer_Unit and T_Mounted with private ;
overriding
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) ;
private
type T_Mounted_Archer is new T_Archer_Unit and T_Mounted with null record ;
end P_Item.Unit.Archer.Mounted ;
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Item.Unit.Archer.Mounted is
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) is
begin
Put_line(" >> Décochez vos flèches sur le flanc ouest !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.tir*Attaquant.mov) ;
end Attaque_de_flanc ;
end P_Item.Unit.Archer.Mounted ;
Le code est finalement très similaire à celui des unités montées, à ceci près que vous devez écrire le corps du package cette fois. Remarquez que j'ai changé la méthode de calcul ainsi que le texte affiché, mais vous pouvez bien-sûr écrire exactement le même code que pour les T_Mounted_Unit.
Mais quel intérêt de réécrire la même chose ? Je pensais que l'héritage nous permettait justement d'éviter cette redondance de code. :(
J'avoue avoir eu moi aussi du mal à comprendre cela à mes débuts. Mais le but principal des types abstraits et des interfaces n'est pas de limiter la redondance du code, mais de permettre le polymorphisme. Sans interface, nous aurions deux méthodes Attaque_de_flanc distinctes ; avec l'interface, ces deux méthodes n'en forme plus qu'une, mais polymorphe !
Avec plusieurs interfaces
Dans le même esprit, pourquoi ne pas créer une interface I_Archer ? Ainsi, les archers montés hériteraient directement de T_Unit et implémenteraient I_Mounted et I_Archer. La réalisation de l'interface I_Archer n'est pas très compliquée :
with P_Item.Unit ; use P_Item.Unit ;
package I_Archer is
type T_Archer is interface ;
procedure Attaque_a_distance(Attaquant : in T_Archer ; Defenseur : in out T_Unit'class) is abstract ;
end I_Archer ;
Que devient alors notre type T_Archer_Unit ? Là encore, rien de bien compliqué :
With I_Archer ; Use I_Archer ;
package P_Item.Unit.Archer is
type T_Archer_Unit is new T_Unit and T_Archer with private ;
overriding
function Init(Att, Def, Mov, Vie : Integer := 0) return T_Archer_Unit ;
function Init(Att, Def, Mov, Vie, Tir : Integer := 0) return T_Archer_Unit ;
-- Réécriture de la méthode héritée de l'interface I_Archer
overriding
procedure Attaque_a_distance(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
-- Réécriture de la méthode héritée de la classe T_Unit
overriding
procedure Attaque(Attaquant : in T_Archer_Unit ; Defenseur : in out T_Unit'class) ;
private
type T_Archer_Unit is new T_Unit and T_Archer with record
Tir : integer ;
end record ;
end P_Item.Unit.Mounted ;
Mais ce qui nous intéresse vraiment, c'est notre type T_Mounted_Archer :
With I_Mounted ; Use I_Mounted ;
package P_Item.Unit.Archer.Mounted is
type T_Mounted_Archer is new T_Archer_Unit and T_Mounted and T_Archer with private ;
overriding
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) ;
overriding
procedure Attaque_a_distance(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) ;
private
type T_Mounted_Archer is new T_Archer_Unit and T_Mounted and T_Archer with null record ;
end P_Item.Unit.Archer.Mounted ;
With ada.text_IO ; Use Ada.Text_IO ;
package body P_Item.Unit.Archer.Mounted is
procedure Attaque_de_flanc(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) is
begin
Put_line(" >> Décochez vos flèches sur le flanc ouest !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.tir*Attaquant.mov) ;
end Attaque_de_flanc ;
procedure Attaque_a_distance(Attaquant : in T_Mounted_Archer ; Defenseur : in out T_Unit'class) is
begin
Put_line(" >> Parez ... Tirez !") ;
Defenseur.vie := integer'max(0,Defenseur.vie - Attaquant.tir) ;
end Attaque_a_distance ;
end P_Item.Unit.Archer.Mounted ;
Comme vous pouvez le constater, mon type T_Mounted_Archer hérite désormais ses multiples attributs du type T_Archer_Unit et de deux interfaces I_Archer et I_Mounted. Il est ainsi possible de multiplier les implémentations : pourquoi ne pas imaginer des classes implémentant 4 ou 5 interfaces ?
Interface implémentant une autre interface
Et nos artilleries ? Nous pourrions également créer une interface I_Artillerie ! Et comme les artilleries héritent des archers, notre interface I_Artillerie hériterait de I_Archer.
Attends, là. Une interface peut hériter d'une autre interface ? o_O
Bien sûr ! Tout ce que vous avez à faire, c'est de lui adjoindre de nouvelles méthodes (abstraites bien sûr). Cela se fait très facilement. Regardez ce que cela donnerait avec nos artilleries :
with I_Archer ; use I_Archer ;
with P_Item.Unit ; use P_Item.Unit ;
package I_Artillery is
type T_Artillery is interface and T_Archer ;
procedure Bombarde(Attaquant : in T_Artillery ; Defenseur : in out T_Unit'class) ;
end I_Artillery ;
Inutile de préciser que T_Artillery hérite de la méthode abstraite Attaque_a_distance et qu'elle pourrait hériter de plusieurs interfaces (si l'envie vous prenait). Bien, avant de clore ce chapitre, il est temps de faire un point sur notre diagramme de classe. Celui-ci a en effet bien changé depuis le début du chapitre précédent. Je vous fais un résumé de la situation ? :D
Fatigués ? :p C'est normal, vous venez de lire un chapitre intense. Polymorphisme et abstraction ne sont pas des notions évidentes à appréhender. Rassurez-vous, nous en aurons bientôt terminé avec la POO. Il nous reste toutefois un dernier chapitre à aborder avant de nous faire la main sur un nouveau TP : la finalisation et les types contrôlés. Ce chapitre sera bien plus court que les précédents. Alors, encore un peu de courage ! ^^
Il est un point dont je vous ai parlé très tôt dans cette partie et sur lequel je ne me suis pas beaucoup étendu (pour ne pas dire pas du tout). Je vous avais dit que procédures et fonctions portaient le nom de méthodes en POO. J'avais également ajouté que certaines méthodes possédaient un nom particulier : constructeur, destructeur, modifieur ... C'est à ces trois méthodes spécifiques que nous allons nous intéresser. Pour cela, nous prolongerons (encore une fois) l'exemple vu au chapitre précédent du héros pouvant être de type T_Unit, T_Mounted_Unit ou T_Archer_Unit. Ce sera également l'occasion de revenir sur un oubli (volontaire rassurez-vous).
Moi je veux bien que tu me parles de constructeur mais ça sert à quoi ? Qu'est-ce qu'elles ont de particuliers tes méthodes ?
Constructeur
Par constructeur, on entend une méthode qui va initialiser nos objets. Nos types étant généralement private, nous avons été obligés de fournir une (ou plusieurs) méthode(s) Init avec nos classes. C'est ce que l'on appelle un constructeur. Mais que se passe-t-il si l'on n'initialise pas un objet de type T_Unit par exemple ? Eh bien, le programme va réserver un espace en mémoire pour enregistrer notre objet, mais cet espace ne contiendra aucune information valide. Et si nous somme amenés à lire cet objet, nous ferons alors lamentablement planté notre ordinateur. Il est donc important d'initialiser nos objets. Une solution consiste à prendre l'habitude de le faire systématiquement et de faire en sorte que les personnes qui travaillent avec vous le fasse elles-aussi systématiquement. Mais ce qui serait préférable, ce serait que nos objets s'initialisent d'eux-mêmes (cela éviterait les oublis ^^ ). Nous allons justement rédiger des constructeurs par défaut "automatiques".
Destructeur
Je vous avais expliqué lors du chapitre sur les pointeurs qu'il était important de désallouer la mémoire lorsqu'un pointeur ne servait plus, tout en spécifiant que cette opération était risquée (problème de pointages multiples). Ainsi au chapitre précédent, je vous avais fourni un code similaire à ceci :
...
type T_Heros is access all T_Unit'class ;
Massacror, Vengeator : T_Heros ;
begin
loop
Massacror := Choix_Unite ;
Vengeator := Choix_Unite ;
Tour_Joueur(Massacror.all,Vengeator.all) ;
Tour_Joueur(Vengeator.all,Massacror.all) ;
end loop ;
end ;
Supposons qu'il s'agisse là non pas du programme principal mais d'un sous-programme. Que se passe-t-il en mémoire après la ligne 11 ? Les pointeurs Massacror et Vengeator terminent leur portée : ils arrivent au bout du programme dans lequel ils avaient été définis. Les emplacements mémoires liés à ces deux pointeurs sont donc libérés. Oui mais un pointeur n'est jamais qu'une adresse ! C'est bien beau de se débarrasser des adresses mais qu'advient-il des données situées à ces fameuses adresses pointées ? Mystère. Certains compilateurs Ada disposent de ce que l'on appelle un ramasse-miette (ou garbage collector) qui se charge de libérer les emplacements mémoires dont on a perdu l'adresse, mais ce n'est nullement une obligation imposée par la norme ! Donc mieux vaut ne pas compter dessus. Ce qu'il faut faire, comme vous le savez désormais, c'est faire appel au package Ada.unchecked_Deallocation :
With Ada.Unchecked_Deallocation ;
...
type T_Heros is access all T_Unit'class ;
procedure free is new Ada.Unchecked_Deallocation(T_Unit'class,T_Heros) ;
Massacror, Vengeator : T_Heros ;
begin
loop
Massacror := Choix_Unite ;
Vengeator := Choix_Unite ;
Tour_Joueur(Massacror.all,Vengeator.all) ;
Tour_Joueur(Vengeator.all,Massacror.all) ;
end loop ;
free(Massacror) ;
free(Vengeator) ;
end ;
Cette procédure est lourde, et il serait plus pratique que cette désallocation se fasse automatiquement. Ce sera donc le rôle des destructeurs de mettre fin proprement (et automatiquement) à la vie d'un objet dès lors qu'il aura atteint la fin de sa portée.
Modifieur
Les modifieurs, quant à eux, ont pour but de gérer les affectations. Quel intérêt ? Eh bien cela vous permettra de mieux contrôler les opérations d'affectations. Que se passerait-t-il si un utilisateur entrait 0H 75Min 200s pour un temps, 35/13/2001 pour une date ? Rien de bon, c'est sûr. Que se passerait-t-il si un programmeur, utilisant vos packages sans en connaître le détail, écrivait Massacror := Vengeator ou pile1 := pile2 (voire chapitre sur les TAD) ? Inconscient qu'il manipule en réalité des pointeurs, il affecterait une adresse pensant affecter des données, prenant ainsi des risques quant à la sécurité de ses données. Bref, il est bon dans certains cas de maîtriser les opérations d'affectation sans pour autant les interdire (contrairement aux types limited private par exemple). Les modifieurs seront donc des procédures qui seront appelées (automatiquement là encore) dès lors qu'une affectation aura lieu.
Comment s'y prendre ?
Bon, je pense pouvoir faire cela tout seul, sauf une chose : comment faire pour que ces méthodes soient appelées automatiquement ? :euh:
Il n'y a pas de technique particulière à apprendre, seulement un type particulier (ou deux) à employer. Les seuls types Ada permettant d'avoir un modifieur, un constructeur et un destructeur par défaut appelés automatiquement, sont les types dits contrôlés (appelés controlled). Un second type permet de disposer d'un constructeur et d'un destructeur automatiques (mais pas d'un modifieur), il s'agit du type limited_controlled.
Ces deux types ne sont pas des types standards, vous devrez donc faire appel au package Ada.Finalization pour les utiliser. Si vous prenez la peine d'ouvrir le fichier a-finali.ads vous découvrirez la déclaration de ces deux types :
type Controlled is abstract tagged private;
type Limited_Controlled is abstract tagged limited private;
Eh oui ! Ces deux types sont des types privés, abstraits et donc étiquetés ; le type Limited_Controlled est même privé et limité. Mais vous savez ce que cela signifie désormais : ces deux types sont inutilisables en l'état, il va falloir les dériver. :p Et si vous continuez à regarder ce package, vous trouverez les méthodes suivantes :
procedure Initialize (Object : in out Controlled);
procedure Adjust (Object : in out Controlled);
procedure Finalize (Object : in out Controlled);
...
procedure Initialize (Object : in out Limited_Controlled);
procedure Finalize (Object : in out Limited_Controlled);
Ce sont les fameuses méthodes dont je vous parle depuis le début de ce chapitre, méthodes qu'il nous faudra réécrire :
Bon c'est bien beau tout cela, mais j'en fais quoi, moi, des ces types contrôlés ?
Eh bien dérivons-les ! Ou plutôt implémentons-les puisque ce sont des types abstraits. Reprenons l'exemple du type T_Heros et étoffons-le : un héros disposera d'un niveau d'expérience. Ce qui nous donne la déclaration suivante :
--On définit notre type "pointeur sur la classe T_Unit"
Type T_Unit_Access is access all T_Unit'class ;
--On définit ensuite notre type T_Heros !
Type T_Heros is new Controlled with record
exp : integer ;
unit : T_Unit_Access ;
end record ;
Nous obtenons ainsi un type contrôlé, c'est à dire un type étiqueté dérivant du type controlled. Et puisque ce type est étiqueté, nous pouvons également dériver le type T_Heros à volonté, par exemple en créant un nouveau type fils appelé T_Super_Heros. Les super-héros auront eux un niveau de mana pour utiliser de la magie ou des super-pouvoirs :
type T_Super_Heros is new T_Heros with record
mana : integer ;
end record ;
Ce nouveau type sera lui aussi contrôlé : comme vous devez maintenant le savoir, tout type dérivant de T_Heros sera lui aussi un type contrôlé.
Mise en place de nos méthodes
Venons-en maintenant, à nos constructeurs, modifieurs et destructeurs. Nous ne traiterons que le cas des types controlled.
Constructeur
Commençons par réécrire notre constructeur Initialize :
procedure Initialize (Object : in out T_Heros) is
begin
Object.exp := 0 ;
Object.unit := null ;
end Initialize ;
Le code ci-dessus initialise notre Héros avec des valeurs nulles par défaut. Mais il est également possible de laisser la main à l'utilisateur :
procedure Initialize (Object : in out T_Heros) is
begin
Put_line("Quelle est le niveau d'experience de votre heros ?") ;
get(Object.exp) ; skip_line ;
Object.unit := choix_unit ; --on appelle ici la méthode d'initialisation qui demande
--à l'utilisateur de choisir entre plusieurs types d'unités
end Initialize ;
Dès lors, il suffira que vous déclariez un objet de type T_Heros pour que cette procédure soit automatiquement appelée. La ligne ci-dessous :
Massacror : T_Heros ;
équivaudra à elle seule à celle-ci :
Massacror : T_Heros := Massacror.Initialize ; --c'est plus long et surtout complètement inutile
Destructeur
Le destructeur sera généralement inutile. Mais dans le cas d'un type nécessitant des pointeurs, je vous recommande grandement son emploi afin de vous épargner les nombreuses désallocation de mémoire. Commençons par établir notre procédure de libération de mémoire :
Type T_Unit_Access is access all T_Unit'class ;
procedure free is new Ada.Unchecked_Deallocation(T_Unit'class, T_Unit_Access) ;
Pour notre méthode Finalize, la seule chose que nous avons à faire, c'est de libérer la mémoire pointée par l'attribut Unit. Cela nous donnerait ceci :
procedure Finalize (Object : in out T_Heros) is
begin
free(Object.unit) ;
end Finalize ;
Prenons un exemple d'utilisation désormais. Déclarons un objet de type T_Heros soit dans une procédure-fonction soit dans un bloc de déclaration :
...
Massacror : T_Heros ; --appel automatique de Initialize
begin
...
--on effectue ce que l'on veut avec notre objet Massacror
end ;
--la portée de l'objet Massacror s'arrête ici
--la méthode Finalize est appelée automatiquement
Modifieur
Finissons en beauté avec le modifieur. Pour bien comprendre, nous allons commencer par un exemple d'application de la méthode Adjust :
...
Massacror, Vengeator : T_Heros ;
begin
Massacror := Vengeator ; --affectation d'un objet vers un autre
...
Mais ce petit bout de code anodin présente deux soucis :
L'attribut-pointeur Massacror.Unit est modifié, certes, mais qu'advient-il de l'emplacement mémoire sur lequel il pointait ? Eh bien cet emplacement est perdu mais n'est pas libéré !
L'attribut Massacror.unit est un pointeur : il va donc pointé sur le même emplacement mémoire que Vengeator.Unit alors qu'il serait préférable qu'il pointe sur un nouvel emplacement mémoire identique à celui de Vengeator.Unit.
Voilà pourquoi il est important de définir des types contrôlés. Ces deux problèmes peuvent être régler : le premier sera réglé grâce à la méthode Finalize, le second va constituer le cahier des charges de notre procédure adjust.
Mais comment faire une procédure d'affectation avec un seul paramètre ?
Eh bien, vous devez comprendre que la procédure Adjust ne se charge pas de l'affectation en elle-même mais de l'ajustement de notre objet. Lors d'une affectation, la procédure Finalize est appelée en tout premier (détruisant ainsi l'objet Massacror et résolvant le premier problème), puis l'affectation est opérée (réalisant le second problème). La méthode Adjust est enfin appelée en tout dernier lieu pour rectifier les erreurs commises à l'affectation. Il nous reste donc seulement à créer un nouvel emplacement mémoire sur lequel pointera Massacror.Unit :
procedure Adjust (Object : in out T_Heros)is
Temp : T_Unit'class := Object.Unit.all ;
begin
Object.Unit := new T_Unit'class ;
Object.Unit.all := Temp ;
end ;
Maintenant que nos trois méthodes sont écrites, revenons à notre exemple :
...
Massacror, Vengeator : T_Heros ; -- appel automatique de Initialize
begin
...
Massacror := Vengeator ; -- 1. appel automatique de Finalize
-- 2. affectation
-- 3. appel automatique de Adjust
...
end ; -- appel automatique de Finalize
Avant d'en venir aux types limited_Controlled, un dernier exemple d'application de la méthode Adjust avec un type T_Horaire. Comme dit au début de ce chapitre, un horaire ne peut valoir 0H 75Min 200s ! Définissons donc un type contrôlé T_Horaire et sa méthode Adjust.
type T_Horaire is new Controlled with record
H, Min, Sec : Natural ;
end record ;
procedure Adjust (Object : in out T_Heros)is
begin
if Object.sec > 60
then Object.H := Object.H + Object.sec / 3600 ;
Object.sec := Object.sec mod 3600 ;
Object.Min := Object.Min + Object.sec / 60 ;
Object.sec := Object.sec mod 60 ;
end if ;
if Object.Min > 60
then Object.H := Object.H + Object.min / 60 ;
Object.min := Object.min mod 60 ;
end if ;
end Adjust ;
Types contrôlés et limités
Les types Limited_Controlled fonctionnent exactement comme les types Controlled, à la différence qu'ils sont limités. Aucune affectation n'est donc possible avec ces types et la méthode Adjust est donc inutile.
C'en est cette fois terminé des longs chapitres de théorie sur la programmation orientée objet. Ce dernier chapitre sur la programmation orientée objet aura été le plus court de tous, mais comme il nécessitait des notions sur les types limités, la dérivations des types étiquetés, la programmation par classe de type ... nous ne pouvions commencer par lui. Vous aurez ainsi vus les notions essentielles de la POO : encapsulation, généricité, héritage, dérivation, abstraction, polymorphisme et pour finir, finalisation. Vous allez enfin pouvoir passer à un bon vieux TP pour mettre tout cela en pratique. Après quoi, nous aborderons des thèmes aussi différents et exigeants que les exceptions, l'interfaçage ou le multitasking.
Après tous ces chapitres sur la POO, nous allons prendre un peu de bon temps pour mettre toutes les notions apprises en pratique. Je vous propose de nouveau de créer un jeu. Il ne s'agira pas d'un jeu de plateau mais d'un jeu de bataille navale. Mais attention ! Pas le bon vieux jeu où on visait au hasard les cases B7 puis E4 en espérant toucher ou couler un porte-avion ! Non. Je pensais plutôt à une sorte de jeu de rôle au tour par tour. Vous disposerez d'un navire (une frégate, un galion ...) et devrez affronter un navire adverse, le couler ou l'arraisonner. Le but étant de gagner de l'or, de perfectionner votre navire, d'augmenter votre équipage ...
L'objectif est bien sûr de mettre en œuvre la conception orientée objet dont je vous parle et reparle depuis plusieurs chapitres. Comme à chaque fois, je commencerai par vous décrire le projet, ses objectifs, ses contraintes ... puis je vous fournirai quelques conseils ou pistes avant de vous livrer une solution possible. Prêt ? Alors à l'abordage ! :pirate:
Comme indiqué en introduction, il s'agira d'un jeu de rôle au tour par tour. Votre navire enchaînera les combats. Entre deux combats, trois actions seront possibles :
Retourner au port pour effectuer des réparations, recruter des matelots, améliorer votre navire ou sauvegarder.
Rester en mer pour de nouveaux combats.
Partir au large pour affronter des adversaires plus puissants.
A chaque combat, le jeu proposera plusieurs choix au joueur :
Bombarder : le navire attaquera son adversaire à coups de canon.
Aborder : le navire attaquera son adversaire en lançant un abordage. :pirate:
Défendre : l'équipage du navire se préparera à subir un abordage et renforcera temporairement sa défense.
Manœuvrer : le navire tentera d'esquiver les boulets de canon de l'adversaire.
Fuir : le joueur met fin à l'assaut et fuit.
Les navires
Il existera différents types de navires : les navires de guerre, les navires de commerce, les navires pirates et les navires corsaires. Ceux-ci pourront être classés en deux catégories :
Navires légaux : cette catégorie comprendra les navires de guerre, les navires de commerce et les navires corsaires. Ils auront la capacité de bombarder les navires adverses afin de les couler.
Navires illégaux : cette catégorie comprendra les navires pirates et les navires corsaires. Ils auront la capacité de se lancer à l'abordage des navires adverses afin de les capturer.
Vous aurez remarqué que les corsaires feront partie des deux catégories ce qui devrait vous rappeler l'héritage multiple. Chaque type de navire aura bien sûr ses spécificités :
Navires de guerre : ils disposeront d'une force de frappe supérieure aux autres navires et accumuleront des points d'honneur donnant droit à divers bonus.
Navires de commerce : les plus faibles, ils auront la capacité de vendre des marchandises dans les ports, leur permettant de gagner davantage d'or.
Navires pirates : navires rapides, ils gagneront davantage d'or à l'issue d'un combat et auront la possibilité de piller les ports.
Navires corsaires : sans capacité particulière supplémentaire.
Les statistiques
Tout navire disposera des statistiques suivantes, ainsi que des bonus associés :
Coque : mesure l'état de la coque. Une fois à 0, le navire coule et est perdu.
Equipage : mesure le nombre d'hommes sur le navire. Une fois à 0, un navire ne peut plus être dirigé et est donc perdu.
Puissance : mesure la puissance de feu des canons des navires légaux.
Attaque : mesure la force d'attaque de l'équipage des navires illégaux.
Cuirasse : mesure la résistance du navire aux boulets de canon.
Défense : mesure la résistance de l'équipage aux abordages.
Vitesse : mesure la vitesse du navire, ce qui lui permet plus facilement d'esquiver.
A noter que les deux premières statistiques nécessiteront une valeur maximale et une valeur courante. Les navires de commerce disposeront d'un stock de marchandises échangeable contre de l'or au port.
Venons-en désormais aux détails techniques. Encore une fois, le jeu se déroulera en mode console (oui je sais, vous avez hâte de pouvoir faire des fenêtres avec des boutons et tout, mais encore un tout petit peu de patience :ange: ). Pour égayer tout cela, il serait bon que vous fassiez appel au package NT_Console en apportant un peu de couleur à notre vieille console ainsi que quelques bip. Le jeu devra pouvoir se jouer au clavier à l'aide des touches ←, ↑, →, ↓, Entrée ou Escape. Pensez à faire appel à la fonction get_key pour cela. Pour vous donner un ordre d'idée de ce que j'ai obtenu, voici quelques captures d'écran :
A vrai dire, j'aurais voulus insérer quelques ASCII arts mais ça ne rendait pas très bien ^^
Comme vous pouvez le voir sur les captures, le joueur devra avoir accès aux stats de son navire à tout moment et, lors des combats, à celles de son adversaire. Il est évident que les choix proposés au joueur devront être clairs (plus de "tapez sur une touche pour voir ce qui va se passer") et que le jeu devra retourner un message à la suite de chaque action, afin par exemple de savoir si le tir de canon a échoué ou non, combien de points ont été perdus, pourquoi votre navire a perdu (coque déchiquetée ou équipage massacré ?) ... Bref, cette fois, j'exige que votre programme soit présentable.
Je vais également vous imposer de proposer la sauvegarde-chargement de vos parties. Puisque vous pourrez améliorer vos navires pour vous confronter à des adversaires toujours plus durs, il serait dommage de ne pas proposer la possibilité de sauvegarder votre jeu.
Les calculs
Pour le calcul des dégâts liés à vos coups de cannons ou de sabre, je vous laisse libre (mon programme n'est d'ailleurs pas toujours très équilibré en la matière). Voici toutefois les formules que j'ai utilisées pour ma part :
Ici, correspond aux dégâts occasionnés, à la puissance, à l'attaque, à l'équipage, à l'attaquant et au défenseur. Pour savoir si un navire esquivera ou non vos tirs, j'ai tiré un nombre entre 0 et 100 et regardé s'il était ou non supérieur à :
Où est bien entendu la vitesse du navire, 120 étant un coefficient permettant de compliqué encore davantage l'esquive des boulets. Ces formules valent ce qu'elles valent, elles ne sont pas paroles d'évangile et si vous disposez de formules plus pertinentes, n'hésitez pas à les utiliser.
POO
Enfin, pour ceux qui ne l'auraient pas encore compris, je vais vous imposer l'emploi de "tactiques orientées objet" :
utiliser des types tagged pour vos navires,
utiliser au moins une interfaceet un type abstract,
disposer de méthodes polymorphes (je n'ai pas dit que toutes devaient l'être),
utiliser des méthodes private,
créer au moins un couple de packages père-fils.
Attention, je ne vous impose pas que tout votre code soit conçu façon objet : tout n'a pas besoin d'être encapsulé, toutes les méthodes n'ont pas besoin d'être polymorphes ... j'exige simplement que ces cinq points (au moins) soient intégrés à votre projet. Rien ne vous empêche d'employer la généricité ou des types contrôlés si le cœur vous en dit, bien entendu.
Voici le diagramme de classe que j'ai utilisé (encore une fois, rien ne vous oblige à employer le même). Libre à vous de faire hériter les méthodes de bombardement et d'abordage de vos interfaces ou de votre classe mère.
Comme à chaque TP, je compte bien vous fournir une solution. Mais cette solution est bien entendu perfectible. Elle est également complexe et nécessitera quelques explications. Tout d'abord, évoquons l'organisation de mes packages :
Game : la procédure principale. Elle ne contient que très peu de chose, l'essentiel se trouvant dans les packages.
P_Point : propose le type T_Point et les méthodes associées. Ce type permet pour chaque statistique (par exemple la vitesse), de disposer d'une valeur maximale, d'une valeur courante et d'une valeur bonus.
P_Navire : gère les classes, méthodes, interfaces liées aux différents types navires. Ce package aurait du être scindé en plusieurs sous-package pour respecter les règles d'encapsulation. Mais pour que le code gagne en lisibilité et surtout en compacité, j'ai préféré tout réunir en un seul package. Cela vous permettra d'analyser plus facilement le code, les méthodes ...
P_Navire.list : le package fils. Celui-ci est fait pour proposer différents navires (frégates, galions, corvette ...) au joueur et à l'ordinateur.
P_Variables : gère les variables globales du projet (coût d'une amélioration, temps d'affichage des messages ... ) ainsi que les fonctionnalités aléatoires.
P_Data : gère l'enregistrement et la sauvegarde des navires dans des fichiers texte.
P_Screen : gère tous les affichages : affichage de texte accentué, affichage des messages de combat (tir manqué, abordage réussi, fuite ...), affichage des différents menus (menu de combat, menu du marché, menus pour choisir entre une nouvelle partie et une ancienne, menu pour choisir le type de bateau sur lequel vous souhaitez naviguer ...)
P_Modes : package le plus important, c'est lui qui gère tout ce que vous faites au clavier, que ce soit durant les phases de combat, lors de l'affichage du menu du marché ... bref, c'est le cœur du jeu. Attention, les menus sont affichés grâce à P_Screen, mais seulement affichés, leur utilisation se fait grâce à P_Modes.
Le code
Game.adb
Venons-en au code à proprement parler. Voici à quoi se limite la procédure principale :
WITH Nt_Console ; USE Nt_Console ;
WITH P_Navire ; USE P_Navire ;
WITH P_Modes ; USE P_Modes ;
PROCEDURE Game IS
BEGIN
set_cursor(visible => false) ;
DECLARE
Joueur : T_Navire'Class := first_mode ;
BEGIN
market_mode(joueur) ;
END ;
END Game ;
On déclare un objet joueur de la classe T_Navire que l'on initialise en lançant First_mode. Celui-ci proposera de choisir entre créer une nouvelle partie et en charger une ancienne. Dans chacun des cas, un Navire est renvoyé.
Ensuite, on lance le mode marché (Market_mode) lequel se chargera de lancer les autres modes si besoin est.
P_Point
Ce package présente peu d'intérêt et de difficultés :
PACKAGE P_Point IS
TYPE T_Point IS TAGGED RECORD
Max, Current, Bonus : Integer ;
END RECORD ;
Function "-" (left : T_Point ; right : integer) return integer ;
FUNCTION Total (P : T_Point) RETURN Integer ;
FUNCTION Ecart(P : T_Point) RETURN Integer ;
PROCEDURE Raz(P : OUT T_Point) ;
PROCEDURE Init(P : IN OUT T_Point) ;
PROCEDURE Init(P : IN OUT T_Point ; N : Natural) ;
end P_Point ;
PACKAGE BODY P_Point IS
FUNCTION "-" (Left : T_Point ; Right : Integer) RETURN Integer IS
BEGIN
RETURN Integer'Max(0,Left.Current - Right) ;
END "-" ;
FUNCTION Total(P : T_Point) RETURN Integer IS
BEGIN
RETURN P.Current + P.Bonus ;
END Total ;
FUNCTION Ecart(P : T_Point) RETURN Integer IS
BEGIN
RETURN P.Max - P.Current ;
END Ecart ;
PROCEDURE Raz(P : OUT T_Point) IS
BEGIN
P.Bonus := 0 ;
END Raz ;
PROCEDURE Init(P : IN OUT T_Point) IS
BEGIN
P.Current := P.Max ;
P.Bonus := 0 ;
END Init ;
PROCEDURE Init(P : IN OUT T_Point ; N : Natural) IS
BEGIN
P.Max := N ;
P.Current := P.Max ;
P.Bonus := 0 ;
END Init ;
end P_Point ;
P_Navire
L'un des principaux packages du jeu. Il définit mon type T_Navire comme abstract, mes interface T_Legal et T_Illegal. Trois méthodes abstraites sont proposées : Bombarde, Aborde et Init. Des trois, seule Init est réellement polymorphe. Les deux autres emploient chacune une méthode privée afin de limiter le code. J'aurais pu choisir de modifier le code de bombardement pour les navires de guerre, mais j'ai préféré modifier les statistiques pour accroître les points de Puissance initiaux afin de fournir un avantage initial aux navires de guerre qui peut toutefois être comblé pour les autres navires. Autrement dit, le bonus se fait grâce à Init mais pas grâce à Bombarde. Il en est de même pour aborde. Cela évite également que le code devienne gigantesque, ce qui ne vous faciliterait pas non plus son analyse.
WITH P_Point ; USE P_Point ;
WITH Ada.Strings.Unbounded ; USE Ada.Strings.Unbounded ;
PACKAGE P_Navire IS
-------------------------------
--TYPES ET METHODES ABSTRAITS--
-------------------------------
TYPE T_Navire IS ABSTRACT TAGGED RECORD
Nom : Unbounded_string := Null_unbounded_string ;
Coque : T_Point ;
Equipage : T_Point ;
Puissance : T_Point ;
Attaque : T_Point ;
Cuirasse : T_Point ;
Defense : T_Point ;
Vitesse : T_Point ;
Playable : Boolean := False ;
Gold : Natural := 0 ;
END RECORD ;
TYPE T_Stat_Name IS (Coque, Equipage, Puissance, Attaque, Cuirasse, Defense, Vitesse, Gold);
TYPE T_Stat IS ARRAY(T_Stat_Name RANGE coque..Gold) OF Natural ;
PROCEDURE Bombarde(Att : IN T_Navire ; Def : in out T_Navire'Class) IS ABSTRACT ;
PROCEDURE Aborde (Att : IN T_Navire ; Def : IN OUT T_Navire'Class) IS ABSTRACT ;
FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Navire IS ABSTRACT ;
TYPE T_Legal IS INTERFACE ;
TYPE T_Illegal IS INTERFACE ;
-------------------
--TYPES CONCRETS --
-------------------
TYPE T_Warship IS NEW T_Navire AND T_Legal WITH NULL RECORD ;
TYPE T_Tradeship IS NEW T_Navire AND T_Legal WITH RECORD
Stock : Integer ;
END RECORD ;
TYPE T_Corsair IS NEW T_Navire AND T_Legal AND T_Illegal WITH NULL RECORD ;
TYPE T_Pirate IS NEW T_Navire AND T_Illegal WITH NULL RECORD ;
----------------------
--METHODES CONCRETES--
----------------------
OVERRIDING PROCEDURE Bombarde(Att : IN T_Warship ; Def : in out T_Navire'Class) ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Tradeship ; Def : in out T_Navire'Class) ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Corsair ; Def : in out T_Navire'Class) ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Pirate ; Def : IN OUT T_Navire'Class) IS NULL ;
OVERRIDING PROCEDURE Aborde(Att : IN T_Warship ; Def : in out T_Navire'Class) is null ;
OVERRIDING PROCEDURE Aborde(Att : IN T_Tradeship ; Def : in out T_Navire'Class) is null ;
OVERRIDING PROCEDURE Aborde(Att : IN T_Corsair ; Def : in out T_Navire'Class) ;
OVERRIDING PROCEDURE Aborde(Att : IN T_Pirate ; Def : in out T_Navire'Class) ;
OVERRIDING FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Warship ;
OVERRIDING FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Tradeship ;
OVERRIDING FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Corsair ;
OVERRIDING FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Pirate ;
PROCEDURE Defend(Bateau : IN OUT T_Navire'Class) ;
PROCEDURE Manoeuvre(Bateau : IN OUT T_Navire'Class) ;
FUNCTION Est_Mort(Bateau : T_Navire'Class) return boolean ;
PROCEDURE Raz_Bonus(Bateau : OUT T_Navire'Class) ;
PROCEDURE Reparer (Navire : in out T_Navire'Class) ;
PROCEDURE Recruter (Navire : in out T_Navire'Class) ;
PROCEDURE Vendre (Navire : IN OUT T_Tradeship) ;
PROCEDURE Ameliorer_Coque (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Equipage (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Puissance(Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Attaque (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Cuirasse (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Defense (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Ameliorer_Vitesse (Navire : IN OUT T_Navire'Class) ;
PROCEDURE Bat(Vainqueur : IN OUT T_Navire'Class ; Perdant : IN T_Navire'Class) ;
PROCEDURE Perd(Navire : IN T_Navire'Class) ;
PRIVATE
PROCEDURE Private_Bombarde(Att : IN T_Navire'Class ; Def : IN OUT T_Navire'Class) ;
PROCEDURE Private_Aborde (Att : IN T_Navire'Class ; Def : IN OUT T_Navire'Class) ;
FUNCTION Esquive(Def : IN T_Navire'Class ; Att : IN T_Navire'Class) RETURN Boolean ;
END P_Navire ;
WITH P_Variables ; USE P_Variables ;
WITH Ada.Text_Io ; USE Ada.Text_Io ;
WITH P_Screen ; USE P_Screen ;
WITH Nt_Console ; USE NT_Console ;
PACKAGE BODY P_Navire IS
-------------------------------------------
--CAPACITE D'ESQUIVE AU COURS D'UN ASSAUT--
-------------------------------------------
FUNCTION Esquive(Def : IN T_Navire'Class ; Att : IN T_Navire'Class) RETURN Boolean IS
BEGIN
RETURN Random > (Att.Vitesse.total*120 /(Att.Vitesse.total + Def.Vitesse.Total));
END Esquive ;
-------------------------
--CAPACITE DE BOMBARDER--
-------------------------
PROCEDURE Private_Bombarde(Att : IN T_Navire'class ; Def : in out T_Navire'Class) IS --FORMULE GENERALE
degats : integer := 0 ;
BEGIN
IF Def.Esquive(Att)
THEN IF att.Playable
THEN Put_Esquive_Message(Light_Red) ;
else Put_Esquive_Message(Green) ;
end if ;
ELSE
Degats := Integer(
float(Att.Puissance.total**2) /
float(Att.Puissance.Total + Def.Cuirasse.Total)) ;
Def.Coque.Current := Def.Coque - Degats ;
IF Att.Playable
THEN Put_Bombard_Message(Degats,Green) ;
ELSE Put_Bombard_Message(Degats,Light_Red) ;
END IF ;
END IF ;
END Private_Bombarde ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Warship ; Def : in out T_Navire'Class) IS --POUR BATEAUX DE GUERRE
BEGIN
Private_Bombarde(Att,Def) ;
END Bombarde ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Tradeship ; Def : in out T_Navire'Class) IS --POUR BATEAUX COMMERCIAUX
BEGIN
Private_Bombarde(Att,Def) ;
END Bombarde ;
OVERRIDING PROCEDURE Bombarde(Att : IN T_Corsair ; Def : in out T_Navire'Class) IS --POUR CORSAIRES
BEGIN
Private_Bombarde(Att,Def) ;
END Bombarde ;
-------------------------
--CAPACITE D'ABORDER--
-------------------------
PROCEDURE Private_aborde(Att : IN T_Navire'class ; Def : in out T_Navire'Class) IS --FORMULE GENERALE
degats : integer := 0 ;
BEGIN
IF Def.Esquive(Att)
THEN IF att.Playable
THEN Put_Esquive_Message(Light_Red) ;
ELSE Put_Esquive_Message(Green) ;
END IF ;
ELSE Degats := Integer(
Float(Att.Attaque.Total)**2 /
Float(Att.Attaque.Total + Def.Defense.Total) *
Float(Att.Equipage.Current)/Float(Att.Equipage.Max)) ;
Def.Equipage.Current := Def.Equipage - Degats ;
IF Att.Playable
THEN Put_Abordage_Message(Degats,Green) ;
ELSE Put_Abordage_Message(Degats,Light_Red) ;
END IF ;
END IF ;
END Private_aborde ;
OVERRIDING PROCEDURE aborde(Att : IN T_Corsair ; Def : in out T_Navire'Class) IS --POUR CORSAIRES
BEGIN
Private_aborde(Att,Def) ;
END aborde ;
OVERRIDING PROCEDURE aborde(Att : IN T_Pirate ; Def : in out T_Navire'Class) IS --POUR PIRATES
BEGIN
Private_aborde(Att,Def) ;
END aborde ;
------------------
--INITIALISATION--
------------------
FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_warship IS
Navire : T_Warship ;
BEGIN
Navire.Nom := Nom ;
Navire.Coque.init(Stat(Coque)) ;
Navire.Equipage.init (Stat(Equipage)) ;
Navire.Puissance.init(Stat(Puissance)*120/100) ;
Navire.Attaque.init (Stat(Attaque)) ;
Navire.Cuirasse.init (Stat(Cuirasse)) ;
Navire.Defense.init (Stat(Defense)) ;
Navire.Vitesse.init (Stat(Vitesse)*70/100) ;
Navire.Playable := False ;
Navire.Gold := Stat(Gold) ;
RETURN Navire ;
END Init ;
FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Tradeship IS
Navire : T_Tradeship ;
BEGIN
Navire.Nom := Nom ;
Navire.Coque.init(Stat(Coque)) ;
Navire.Equipage.init (Stat(Equipage)) ;
Navire.Puissance.init(Stat(Puissance)*70/100) ;
Navire.Attaque.init (Stat(Attaque)) ;
Navire.Cuirasse.init (Stat(Cuirasse)*110/100) ;
Navire.Defense.init (Stat(Defense)*110/100) ;
Navire.Vitesse.init (Stat(Vitesse)*90/100) ;
Navire.Playable := False ;
Navire.Gold := Stat(Gold) ;
Navire.stock := 15 ;
RETURN Navire ;
END Init ;
FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Corsair IS
Navire : T_Corsair ;
BEGIN
Navire.Nom := Nom ;
Navire.Coque.init(Stat(Coque)) ;
Navire.Equipage.init (Stat(Equipage)) ;
Navire.Puissance.init(Stat(Puissance)) ;
Navire.Attaque.init (Stat(Attaque)) ;
Navire.Cuirasse.init (Stat(Cuirasse)) ;
Navire.Defense.init (Stat(Defense)) ;
Navire.Vitesse.init (Stat(Vitesse)) ;
Navire.Playable := False ;
Navire.Gold := Stat(Gold) ;
RETURN Navire ;
END Init ;
FUNCTION Init (Nom : unbounded_string ; Stat : T_Stat) RETURN T_Pirate IS
Navire : T_Pirate ;
BEGIN
Navire.Nom := Nom ;
Navire.Coque.init(Stat(Coque)) ;
Navire.Equipage.init (Stat(Equipage)) ;
Navire.Puissance.init(Stat(Puissance)) ;
Navire.Attaque.init (Stat(Attaque)*120/100) ;
Navire.Cuirasse.init (Stat(Cuirasse)*70/100) ;
Navire.Defense.init (Stat(Defense)) ;
Navire.Vitesse.init (Stat(Vitesse)*130/100) ;
Navire.Playable := False ;
Navire.Gold := Stat(Gold) ;
RETURN Navire ;
END Init ;
------------------------
--CAPACITE DE DEFENSE --
------------------------
PROCEDURE Defend(Bateau : IN OUT T_Navire'Class) IS
BEGIN
Bateau.Defense.Bonus := Bateau.Defense.Current * 25 /100 ;
IF Bateau.Playable
THEN Put_Defense_Message(Green) ;
ELSE Put_Defense_Message(Light_Red) ;
END IF ;
END Defend ;
-------------------------
--CAPACITE DE MANOEUVRE--
-------------------------
PROCEDURE Manoeuvre(Bateau : IN OUT T_Navire'Class) IS
BEGIN
Bateau.Vitesse.Bonus := Bateau.Vitesse.Current * 25 /100 ;
IF Bateau.Playable
THEN Put_Manoeuvre_Message(Green) ;
ELSE Put_Manoeuvre_Message(Light_Red) ;
END IF ;
END Manoeuvre ;
------------------------------------------------
--FONCTION POUR SAVOIR SI UN BATEAU EST COULE --
------------------------------------------------
FUNCTION Est_Mort(Bateau : T_Navire'Class) RETURN Boolean IS
BEGIN
RETURN Bateau.Coque.current = 0 OR Bateau.Equipage.current = 0 ;
END Est_Mort ;
-----------------------------------
--REMISE A ZERO POUR DBT DE TOUR --
-----------------------------------
PROCEDURE Raz_Bonus(Bateau : OUT T_Navire'Class) IS
BEGIN
Bateau.Coque.raz ;
Bateau.Equipage.raz ;
Bateau.Puissance.raz ;
Bateau.Attaque.raz ;
Bateau.Cuirasse.raz ;
Bateau.Defense.raz ;
Bateau.Vitesse.raz ;
END Raz_Bonus ;
----------------------------
--METHODES POUR LE MARCHE --
----------------------------
PROCEDURE Reparer (Navire : IN OUT T_Navire'Class) IS
Cout : constant Natural := (Navire.Coque.Max - Navire.Coque.Current) * Repair_Cost ;
BEGIN
IF Cout <= Navire.Gold
THEN Navire.Coque.Init ;
Navire.Gold := Navire.Gold - Cout ;
ELSE Navire.Coque.Current := Navire.Coque.Current + (Navire.Gold / Repair_Cost) ;
Navire.Gold := Navire.Gold mod Repair_Cost ;
END IF ;
Bleep ;
END Reparer ;
PROCEDURE Recruter (Navire : IN OUT T_Navire'Class) IS
Cout : constant Natural := (Navire.Equipage.max - Navire.Equipage.current) * Recrute_cost ;
BEGIN
IF Cout <= Navire.Gold
THEN Navire.Equipage.Init ;
Navire.Gold := Navire.Gold - Cout ;
ELSE Navire.Equipage.Current := Navire.Equipage.Current + (Navire.Gold / Recrute_Cost) ;
Navire.Gold := Navire.Gold mod Recrute_Cost ;
END IF ;
Bleep ;
END Recruter ;
PROCEDURE Vendre (Navire : IN OUT T_Tradeship) IS
BEGIN
Navire.Gold := Navire.Gold + Navire.Stock * Goods_Cost ;
Navire.Stock := 0 ;
Bleep ;
END Vendre ;
PROCEDURE Ameliorer_Coque (Navire : IN OUT T_Navire'Class) IS
BEGIN
IF Coque_Cost <= Navire.Gold
THEN Navire.Gold := Navire.Gold - Coque_Cost ;
Navire.Coque.Max := Navire.Coque.Max + 2 ;
Navire.Coque.Current := Navire.Coque.Current + 2 ;
Coque_Cost := Coque_cost * 2 ;
END IF ;
Bleep ;
END Ameliorer_Coque ;
PROCEDURE Ameliorer_Equipage (Navire : IN OUT T_Navire'Class) IS
BEGIN
IF Equipage_Cost <= Navire.Gold
THEN Navire.Gold := Navire.Gold - Equipage_Cost ;
Navire.Equipage.Max := Navire.Equipage.Max + 2 ;
Navire.Equipage.Current := Navire.Equipage.Current + 2 ;
Equipage_Cost := Equipage_cost * 2 ;
END IF ;
Bleep ;
END Ameliorer_Equipage ;
PROCEDURE Ameliorer_Puissance(Navire : IN OUT T_Navire'Class) IS
BEGIN
IF Puissance_Cost <= Navire.Gold
THEN Navire.Gold := Navire.Gold - Puissance_Cost ;
Navire.Puissance.Max := Navire.Puissance.Max + 1 ;
Navire.Puissance.Current := Navire.Puissance.Current + 1 ;
Puissance_Cost := Puissance_cost * 2 ;
END IF ;
Bleep ;
END Ameliorer_Puissance ;
PROCEDURE Ameliorer_Attaque (Navire : IN OUT T_Navire'Class) IS
cout : constant natural := Attaque_Cost * Navire.Equipage.max ;
BEGIN
IF cout <= Navire.Gold
THEN Navire.Gold := Navire.Gold - cout ;
Navire.Attaque.Max := Navire.Attaque.Max + 1 ;
Navire.Attaque.Current := Navire.Attaque.Current + 1 ;
Attaque_Cost := Attaque_cost + 1 ;
END IF ;
Bleep ;
END Ameliorer_Attaque ;
PROCEDURE Ameliorer_Cuirasse (Navire : IN OUT T_Navire'Class) IS
BEGIN
IF Cuirasse_Cost <= Navire.Gold
THEN Navire.Gold := Navire.Gold - Cuirasse_Cost ;
Navire.Cuirasse.Max := Navire.Cuirasse.Max + 1 ;
Navire.Cuirasse.Current := Navire.Cuirasse.Current + 1 ;
Cuirasse_Cost := Cuirasse_cost * 2 ;
END IF ;
Bleep ;
END Ameliorer_Cuirasse ;
PROCEDURE Ameliorer_Defense (Navire : IN OUT T_Navire'Class) IS
cout : constant natural := Defense_Cost * Navire.Equipage.max ;
BEGIN
IF cout <= Navire.Gold
THEN Navire.Gold := Navire.Gold - cout ;
Navire.Defense.Max := Navire.Defense.Max + 1 ;
Navire.Defense.Current := Navire.Defense.Current + 1 ;
Defense_Cost := Defense_cost + 1 ;
END IF ;
Bleep ;
END Ameliorer_Defense ;
PROCEDURE Ameliorer_Vitesse (Navire : IN OUT T_Navire'Class) IS
BEGIN
IF Vitesse_Cost <= Navire.Gold
THEN Navire.Gold := Navire.Gold - Vitesse_Cost ;
Navire.Vitesse.Max := Navire.Vitesse.Max + 1 ;
Navire.Vitesse.Current := Navire.Vitesse.Current + 1 ;
Vitesse_Cost := Vitesse_cost * 2 ;
END IF ;
Bleep ;
END Ameliorer_Vitesse ;
-------------------------
--GAIN DE FIN DE COMBAT--
-------------------------
PROCEDURE Bat(Vainqueur : IN OUT T_Navire'Class ; Perdant : IN T_Navire'Class) IS
Gain_or, Gain_Stock : Natural := 0 ;
BEGIN
goto_xy(2,10) ;
set_foreground(green) ;
Put("VOUS AVEZ VAINCU VOTRE ADVERSAIRE !") ;
IF Vainqueur IN T_Pirate'Class
THEN Gain_Or := Perdant.Gold / 4 ;
ELSE Gain_Or := Perdant.Gold / 5 ;
END IF ;
Vainqueur.Gold := Vainqueur.Gold + Gain_Or ;
goto_xy(0,11) ;
set_foreground(green) ;
Put("Vous remportez " & integer'image(Gain_or) & " or") ;
IF Vainqueur IN T_Tradeship'Class
THEN Gain_stock := (Niveau-1) * 3 + 1 ;
T_Tradeship(Vainqueur).Stock := T_Tradeship(Vainqueur).Stock + Gain_Stock ;
Put(" et " & integer'image(Gain_Stock) & " stocks") ;
END IF ;
put(" !") ;
Set_Foreground(Black) ;
delay Message_time * 2.0 ;
END Bat ;
PROCEDURE Perd(Navire : IN T_Navire'Class) IS
BEGIN
goto_xy(2,10) ;
set_foreground(light_red) ;
Put("VOUS AVEZ PERDU CONTRE VOTRE ADVERSAIRE !") ;
goto_xy(0,11) ;
IF Navire.Coque.Current = 0
THEN Put("La coque de votre navire est d" & Character'Val(130) & "truite.") ;
ELSIF Navire.Equipage.Current = 0
then Put("Votre " & Character'Val(130) & "quipage est massacr" & Character'Val(130) & ".") ;
END IF ;
Set_Foreground(Black) ;
delay Message_time * 2.0 ;
END Perd ;
END P_Navire ;
P_Navire.list
Peu d'intérêt, c'est ici que sont écrits les statistiques des différents navires (frégate, trois-mâts, galion et corvette). Vous pouvez en ajouter autant que bon vous semble. Le seul inconvénient, c'est qu'il faudra recompiler le code source (les données sont hard-coded).
package P_Navire.List is
TYPE T_Navire_Id IS RECORD
Nom : Unbounded_String ;
Stat : T_Stat ;
END RECORD ;
type T_Liste_Navire is array(positive range <>) of T_Navire_Id ;
-------------
-- NAVIRES --
-------------
--EXEMPLE STATS Coque Equpg Puiss Att Cuir Defse Vits Gold
Stat_Fregate : T_Stat := (15, 10, 14, 8, 8, 6, 8, 200) ;
Stat_Gallion : T_Stat := (20, 14, 10, 10, 12, 8, 4, 500) ;
Stat_Corvette : T_Stat := (12, 7, 8, 8, 10, 4, 16, 150) ;
Stat_Trois_Mats : T_Stat := (16, 8, 12, 7, 10, 8, 10, 300) ;
Liste_Navire : T_Liste_Navire :=(
(To_Unbounded_String("Frégate"), Stat_Fregate),
(To_Unbounded_String("Gallion"), Stat_Gallion),
(To_Unbounded_String("Corvette"), Stat_Corvette),
(To_Unbounded_String("Trois-Mâts"), Stat_Trois_Mats)
);
------------------------------
-- GENERATION D'ADVERSAIRES --
------------------------------
PROCEDURE Mettre_Niveau(Navire : IN OUT T_Navire'Class ; Niveau : Positive) ;
FUNCTION Generer_Ennemi(Niveau : Natural := 1) RETURN T_Navire'Class ;
End P_Navire.List ;
WITH P_Variables ; USE P_Variables ;
package body P_Navire.List is
PROCEDURE Mettre_Niveau(Navire : IN OUT T_Navire'Class ; Niveau : Positive) IS
coef : float ;
BEGIN
Coef := 1.5**(Niveau-1) ;
Navire.Coque.Init(Integer(Float(Navire.Coque.Max) * Coef)) ;
Navire.Equipage.Init(Integer(Float(Navire.Equipage.Max) * Coef)) ;
Navire.Puissance.Init(Integer(Float(Navire.Puissance.Max) * Coef)) ;
Navire.Attaque.Init(Integer(Float(Navire.Attaque.Max) * Coef)) ;
Navire.Cuirasse.Init(Integer(Float(Navire.Cuirasse.Max) * Coef)) ;
Navire.Defense.Init(Integer(Float(Navire.Defense.Max) * Coef)) ;
Navire.Vitesse.Init(Integer(Float(Navire.Vitesse.Max) * Coef)) ;
Coef := 2.0**(Niveau-1) ;
Navire.Gold := integer(float(Navire.Gold) * coef) ;
END Mettre_Niveau ;
FUNCTION Generer_Ennemi(Niveau : Natural := 1) RETURN T_Navire'Class IS
Navire : ACCESS T_Navire'Class ;
N : Natural ;
BEGIN
N:= Random mod Liste_Navire'Length + 1 ;
CASE Random mod 4 IS
WHEN 0 => Navire := new T_Warship'(init(Liste_Navire(N).nom, Liste_Navire(N).stat)) ;
WHEN 1 => Navire := new T_Tradeship'(init(Liste_Navire(N).nom, Liste_Navire(N).stat)) ;
WHEN 2 => Navire := new T_Pirate'(init(Liste_Navire(N).nom, Liste_Navire(N).stat)) ;
WHEN others => Navire := new T_Corsair'(init(Liste_Navire(N).nom, Liste_Navire(N).stat)) ;
END CASE ;
Mettre_Niveau(Navire.All,Niveau) ;
RETURN Navire.all ;
END Generer_Ennemi ;
End P_Navire.List ;
P_Variables
Là encore peu d'intérêt, hormis si vous souhaitez modifier le temps d'affichage des message, le coût de base d'une amélioration ou des réparations.
PACKAGE body P_Variables IS
PROCEDURE Reset IS
BEGIN
Reset(Germe) ;
END Reset ;
FUNCTION Random RETURN T_Pourcentage IS
BEGIN
RETURN Random(Germe) ;
END Random ;
end P_Variables ;
P_Data
Comme dit précédemment, ce package sert à l'enregistrement et au chargement de parties enregistrées dans des fichiers texte. Bref, c'est du déjà-vu pour vous :
WITH P_Navire ; USE P_Navire ;
PACKAGE P_Data IS
FUNCTION Load_Navire(File_Name : String) RETURN T_Navire'Class ;
PROCEDURE Save_Navire(Navire : in T_Navire'class) ;
end P_Data ;
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Strings.Unbounded ; USE Ada.Strings.Unbounded ;
WITH P_Variables ; USE P_Variables ;
WITH P_Point ; USE P_Point ;
PACKAGE BODY P_Data IS
FUNCTION Load_Navire(File_Name : String) RETURN T_Navire'Class IS
FUNCTION Value(F : File_type) RETURN Integer IS
BEGIN
RETURN Integer'Value(Get_Line(F)) ;
END Value ;
Navire : ACCESS T_Navire'Class ;
F : File_Type ;
BEGIN
Open(F, In_File,"./data/" & File_Name & ".txt") ;
CASE Value(F) IS
WHEN 1 => Navire := NEW T_Warship ;
WHEN 2 => Navire := NEW T_Tradeship ;
WHEN 3 => Navire := NEW T_Pirate ;
WHEN others => Navire := NEW T_Corsair ;
END CASE ;
Navire.nom := to_unbounded_string(get_line(F)) ;
Navire.Coque := (Value(F),Value(F),0) ;
Navire.Equipage := (Value(F),Value(F),0) ;
Navire.Puissance := (Value(F),Value(F),0) ;
Navire.Attaque := (Value(F),Value(F),0) ;
Navire.Cuirasse := (Value(F),Value(F),0) ;
Navire.Defense := (Value(F),Value(F),0) ;
Navire.Vitesse := (Value(F),Value(F),0) ;
Navire.Gold := Value(F) ;
IF Navire.All IN T_Tradeship'Class
THEN T_Tradeship(Navire.All).Stock := Value(F) ;
END IF ;
Coque_Cost := value(F) ;
Equipage_Cost := value(F) ;
Puissance_Cost := value(F) ;
Attaque_Cost := value(F) ;
Cuirasse_Cost := value(F) ;
Defense_Cost := value(F) ;
Vitesse_Cost := value(F) ;
Close(F) ;
RETURN Navire.All ;
END Load_Navire ;
PROCEDURE Save_Navire(Navire : in T_Navire'class) IS
F : File_Type ;
PROCEDURE Save_Stat(F : File_Type ; P : T_Point) IS
BEGIN
Put_Line(F,Integer'Image(P.Max)) ;
Put_Line(F,Integer'Image(P.Current)) ;
END Save_Stat ;
BEGIN
Create(F,Out_File,"./data/" & to_string(Save_File_Name) & ".txt") ;
IF Navire IN T_Warship'Class
THEN Put_Line(F,"1") ;
ELSIF Navire IN T_Tradeship'Class
THEN Put_Line(F,"2") ;
ELSIF Navire IN T_Pirate'Class
THEN Put_Line(F,"3") ;
ELSIF Navire IN T_Corsair'Class
THEN Put_Line(F,"4") ;
END IF ;
Put_Line (F, To_String(Navire.Nom)) ;
Save_Stat(F, Navire.Coque) ;
Save_Stat(F, Navire.Equipage) ;
Save_Stat(F, Navire.Puissance) ;
Save_Stat(F, Navire.Attaque) ;
Save_Stat(F, Navire.Cuirasse) ;
Save_Stat(F, Navire.Defense) ;
Save_Stat(F, Navire.Vitesse) ;
Put_Line (F, Integer'Image(Navire.Gold)) ;
IF Navire IN T_Tradeship'Class
THEN Put_Line(F, Integer'Image(T_Tradeship(Navire).Stock)) ;
END IF ;
Put_Line (F, Integer'Image(Coque_Cost)) ;
Put_Line (F, Integer'Image(Equipage_Cost)) ;
Put_Line (F, Integer'Image(Puissance_Cost)) ;
Put_Line (F, Integer'Image(Attaque_Cost)) ;
Put_Line (F, Integer'Image(Cuirasse_Cost)) ;
Put_Line (F, Integer'Image(Defense_Cost)) ;
Put_Line (F, Integer'Image(Vitesse_Cost)) ;
Close(F) ;
END Save_Navire ;
END P_Data ;
P_Screen
Package important : c'est là que se font tous les affichages.
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH P_Variables ; USE P_Variables ;
with P_Navire.list ; use P_Navire.list ;
WITH Ada.Strings.Unbounded ; USE Ada.Strings.Unbounded ;
WITH Ada.Integer_Text_IO ;
PACKAGE BODY P_Screen IS
-----------------------------------------------------------
--AFFICHER UN ENTIER AVEC UNE COULEUR ET UN LIEU SPECIFIE--
-----------------------------------------------------------
PROCEDURE Put(N : Integer ; Color : Color_Type := black ; X,Y : Integer := -1) IS
BEGIN
IF X >= 0 AND Y >= 0
THEN Goto_Xy(X,Y) ;
END IF ;
Set_Foreground(Color) ; Set_BackGround(White) ;
Ada.Integer_Text_IO.put(n,0) ;
Set_Foreground(Black) ;
end put ;
----------------------------------------------------------
--AFFICHER UN TEXTE AVEC UNE COULEUR ET UN LIEU SPECIFIE--
----------------------------------------------------------
PROCEDURE Print(Text : String ; Color : Color_Type := Black ; X,Y : Integer := -1) IS
BEGIN
IF X >= 0 AND Y >= 0
THEN Goto_Xy(X,Y) ;
END IF ;
Set_Foreground(Color) ; Set_BackGround(White) ;
FOR I IN Text'RANGE LOOP
CASE Text(I) IS
WHEN 'é' => Put(Character'Val(130)) ;
WHEN 'â' => Put(Character'Val(131)) ;
WHEN 'è' => Put(Character'Val(138)) ;
WHEN OTHERS => Put(Text(I)) ;
END CASE ;
END LOOP ;
Set_Foreground(Black) ;
END Print ;
----------------------
--AFFICHAGE DU TITRE--
----------------------
PROCEDURE Put_Title IS
BEGIN
goto_xy(0,0) ;
set_background(white) ;
Set_Foreground(light_red) ;
Put_Line(" BATAILLE NAVALE") ; new_line ;
Set_Foreground(black) ;
END Put_Title;
-----------------------------
--AFFICHAGE DU PREMIER MENU--
-----------------------------
PROCEDURE Put_First_Menu(Indice : Natural := 1) IS
X : constant Natural := 9 ;
Y : CONSTANT Natural := 4 ;
color : color_type := blue ;
BEGIN
Print("Que souhaitez-vous faire ?",color,0,Y-1) ;
FOR I IN 1..2 LOOP
IF Indice=I
THEN Color := Light_Red ;
ELSE Color := Blue ;
END IF ;
CASE I IS
WHEN 1 => Print("NOUVELLE PARTIE",Color,X,Y) ;
WHEN 2 => Print("CHARGER UNE ANCIENNE PARTIE",Color,X+20,Y);
END CASE ;
END LOOP ;
Goto_Xy(X+20*(Indice-1) + 10,Y+1) ;
Set_Foreground(Light_Red) ;
Put(Character'Val(30)) ;
Set_Foreground(Black) ;
END Put_First_Menu ;
--------------------
--MENU DE BATAILLE--
--------------------
PROCEDURE Put_Fight_Menu(Navire : T_Navire'Class ; Indice : Natural:=1) IS
X : constant Natural := 9 ;
Y : constant Natural := 13 ;
blank_line : constant string(1..80) := (others => ' ') ;
BEGIN
Goto_Xy(0,Y) ;
put(blank_line) ;
Goto_Xy(X,Y) ;
IF Indice = 1 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
IF Navire IN T_Illegal'Class THEN Put("ABORDER ") ; END IF ;
Goto_Xy(X+12,Y) ;
IF Indice = 2 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
IF Navire IN T_Legal'Class THEN Put("BOMBARDER ") ; END IF ;
Goto_Xy(X+24,Y) ;
IF Indice = 3 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Put("DEFENDRE ") ;
IF Indice = 4 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Put("MANOEUVRER ") ;
IF Indice = 5 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Put("FUIR") ;
Goto_Xy(0,Y+1) ;
put(blank_line) ;
Goto_Xy(X+4+12*(Indice-1),Y+1) ;
Set_Foreground(Light_Red) ;
put(character'val(30)) ;
Set_Foreground(Black) ;
END Put_Fight_Menu ;
-------------------------
--MENU D'APRES BATAILLE--
-------------------------
PROCEDURE Put_NextFight_Menu(Indice : Natural := 1) IS
X : constant Natural := 9 ;
Y : CONSTANT Natural := 12 ;
color : color_type := blue ;
blank_line : constant string(1..80) := (others => ' ') ;
BEGIN
FOR I IN -2..+2 LOOP
Goto_Xy(0,Y+I) ; Put(Blank_Line) ;
END LOOP ;
Print("Que souhaitez-vous faire désormais ?",color,0,Y) ;
FOR I IN 1..3 LOOP
IF Indice=I
THEN Color := Light_Red ;
ELSE Color := Blue ;
END IF ;
CASE I IS
WHEN 1 => Print("DEBARQUER",Color,X,Y+1) ;
WHEN 2 => Print("FAIRE VOILE",Color,X+20,Y+1);
WHEN 3 => Print("PRENDRE LE LARGE",Color,X+40,Y+1) ;
END CASE ;
END LOOP ;
Goto_Xy(X+20*(Indice-1) + 3,Y+2) ;
Set_Foreground(Light_Red) ;
Put(Character'Val(30)) ;
set_foreground(black) ;
END Put_Nextfight_Menu ;
-----------------------------------
--AFFICHAGE DU STATUS D'UN BATEAU--
-----------------------------------
PROCEDURE Put_Status(Navire : T_Navire'class ; Pos : T_Position := Gauche) is
X : Natural ;
y : constant natural := 15 ;
BEGIN
IF Pos = Gauche
THEN X:= 0 ;
ELSE X:= 39 ;
END IF ;
set_background(white) ;
print(" " & to_string(Navire.nom), black, x, y) ;
Set_Foreground(Light_Red) ; Goto_Xy(X,Y+1) ;
Put(" " & Character'Val(2) & " ") ; put_point(Navire.coque) ;
Set_Foreground(Green) ; Goto_Xy(X,Y+2) ;
Put(" " & Character'Val(3) & " ") ; Put_Point(Navire.Equipage) ;
Goto_Xy(X,Y+3) ; Put("Psce:") ; Put_Point(Navire.Puissance) ;
Goto_Xy(X,Y+4) ; Put("Attq:") ; Put_Point(Navire.Attaque) ;
Goto_Xy(X,Y+5) ; Put("Cuir:") ; Put_Point(Navire.Cuirasse) ;
Goto_Xy(X,Y+6) ; Put("Dfns:") ; Put_Point(Navire.Defense) ;
Goto_Xy(X,Y+7) ; Put("Vits:") ; Put_Point(Navire.Vitesse) ;
END Put_Status ;
-------------------------
--AFFICHAGE DU TYPE X/Y--
-------------------------
PROCEDURE Put_Point(Point : T_Point) IS
BEGIN
IF Point.Current <= Point.Max / 4
THEN Put(Point.Current,Light_Red) ;
ELSE Put(Point.Current) ;
END IF ;
Put('/') ; Put(Point.Max) ;
IF Point.Bonus > 0
THEN Put('+') ; Put(Point.Bonus) ;
END IF ;
END Put_Point ;
---------------------------------
--AFFICHAGE DES MESSAGES DU JEU--
---------------------------------
PROCEDURE Put_Esquive_Message(color : color_type := green) IS
BEGIN
goto_xy(0,11) ;
IF Color = Green
THEN set_foreground(green) ;
Put("Vous avez esquiv"& character'val(130) &" l'attaque adverse !") ;
Set_Foreground(Black) ;
ELSE Set_Foreground(light_Red) ;
Put("L'adversaire a esquiv"& character'val(130) &" votre attaque !") ;
Set_Foreground(Black) ;
END IF ;
delay message_time ;
END Put_Esquive_Message ;
PROCEDURE Put_Bombard_Message(Degats : Integer ; Color : Color_Type := Green) IS
BEGIN
Goto_Xy(0,11) ;
set_foreground(black) ;
IF Color = Green
THEN Put("Votre bombardement a caus"& Character'Val(130) & " ") ;
Put(degats,green) ;
put(" points de d"& Character'Val(130) &"g"& Character'Val(131) &"ts") ;
ELSE Put("Le bombardement ennemi a caus"& Character'Val(130) & " ") ;
Put(degats,light_red) ;
put(" points de d"& Character'Val(130) &"g"& Character'Val(131) &"ts") ;
END IF ;
DELAY message_time ;
END Put_Bombard_Message ;
PROCEDURE Put_Abordage_Message(Degats : Integer ; Color : Color_Type := Green) IS
BEGIN
Goto_Xy(0,11) ;
set_foreground(black) ;
IF Color = Green
THEN Put("Votre abordage a tu"& Character'Val(130) & " ") ;
Put(degats,green) ;
put(" marins ennemis") ;
ELSE Put("L'abordage ennemi a tu"& Character'Val(130) & " ") ;
Put(degats,light_red) ;
put(" de vos marins") ;
END IF ;
DELAY message_time ;
END Put_Abordage_Message ;
PROCEDURE Put_Defense_Message(color : color_type := green) IS
BEGIN
goto_xy(0,11) ;
IF Color = Green
THEN set_foreground(green) ;
Put("Vos hommes se pr"& character'val(130) &"parent "& character'val(133) &" l'abordage !") ;
Set_Foreground(Black) ;
ELSE Set_Foreground(light_Red) ;
Put("L'ennemi se pr"& character'val(130) &"pare "& character'val(133) &" l'abordage !") ;
Set_Foreground(Black) ;
END IF ;
delay Message_time ;
END Put_Defense_Message ;
PROCEDURE Put_Manoeuvre_Message(color : color_type := green) IS
BEGIN
goto_xy(0,11) ;
IF Color = Green
THEN set_foreground(green) ;
Put("Votre navire se place sous le vent !") ;
Set_Foreground(Black) ;
ELSE Set_Foreground(light_Red) ;
Put("Le navire ennemi se place sous le vent !") ;
Set_Foreground(Black) ;
END IF ;
delay Message_time ;
END Put_Manoeuvre_Message ;
PROCEDURE Put_Fuite_Message IS
BEGIN
goto_xy(0,11) ;
Set_Foreground(light_Red) ;
Put("Vous fuyez devant l'adversit" & character'val(130) & " !") ;
Set_Foreground(Black) ;
delay Message_time ;
END Put_Fuite_Message ;
--------------------------------
--AFFICHAGE DES MENU DU MARCHE--
--------------------------------
PROCEDURE Put_Gold(Navire : T_Navire'class ; X : X_Pos := 40 ; Y : Y_Pos := 16) IS
blank_line : constant string(1..80 - X) := (others => ' ') ;
BEGIN
Goto_Xy(X,Y) ;
Put(Blank_Line) ;
Goto_Xy(X,Y) ;
set_foreground(black) ;
Put("Or : ") ;
IF Navire.Gold = 0
THEN Set_Foreground(Light_Red) ;
END IF ;
Put(Integer'Image(Navire.Gold)) ;
Set_Foreground(Black) ;
END Put_Gold ;
PROCEDURE Put_Market_Menu1(Navire : T_Navire'Class ; Indice : Natural := 1) IS
X : constant Natural := 9 ;
Y : constant Natural := 13 ;
blank_line : constant string(1..80) := (others => ' ') ;
BEGIN
Goto_Xy(0,Y-1) ;
Put(Blank_Line) ;
Goto_Xy(0,Y) ;
put(blank_line) ;
IF Indice = 1 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Goto_Xy(X,Y-1) ; Put("PRENDRE") ;
Goto_xy(X,Y) ; Put("LA MER") ;
IF Indice = 2 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Goto_Xy(X+12,Y-1) ; Put("REPARER") ;
Goto_xy(x+12,Y) ; Put("(" & integer'image((Navire.coque.max - Navire.coque.current) * Repair_cost) &")") ;
IF Indice = 3 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Goto_Xy(X+24,Y-1) ; Put("RECRUTER") ;
Goto_xy(x+24,Y) ; Put("(" & integer'image((Navire.Equipage.max - Navire.Equipage.current) * Recrute_cost) &")") ;
IF Indice = 4 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Goto_Xy(X+36,Y-1) ; Put("ACHETER ") ;
IF Indice = 5 THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
IF Navire IN T_Tradeship'Class
THEN Goto_Xy(X+48,Y-1) ; Put(" VENDRE") ;
Goto_xy(X+50,Y) ; Put("(" & integer'image(T_Tradeship(Navire).stock * Goods_cost) &")") ;
END IF ;
Goto_Xy(0,Y+1) ;
put(blank_line) ;
Goto_Xy(X+4+12*(Indice-1),Y+1) ;
Set_Foreground(Light_Red) ;
put(character'val(30)) ;
Set_Foreground(Black) ;
END Put_Market_Menu1 ;
PROCEDURE Put_Market_Menu2(Indice : Natural := 1) IS
X : constant Natural := 35 ;
Y : constant Natural := 12 ;
blank_line : constant string(1..80) := (others => ' ') ;
BEGIN
FOR I IN 1..7 LOOP
IF Indice = I THEN Set_Foreground(Light_Red) ; ELSE Set_Foreground(Blue) ; END IF ;
Goto_Xy(0,Y-I) ;
Put(Blank_Line) ;
Goto_Xy(X,Y-I) ;
CASE I IS
WHEN 1 => Put("Gouvernail (" & integer'image(Vitesse_cost) & ") + 1 Vitesse") ;
WHEN 2 => Put("Boucliers (" & integer'image(Defense_cost) & "/marin) + 1 Defense") ;
WHEN 3 => Put("Blindage (" & integer'image(Cuirasse_cost) & ") + 1 Cuirasse") ;
WHEN 4 => Put("Sabres (" & integer'image(Attaque_cost) & "/marin) + 1 Attaque") ;
WHEN 5 => Put("Cannons (" & integer'image(Puissance_cost) & ") + 1 Puissance") ;
WHEN 6 => Put("Couchettes (" & integer'image(Equipage_cost) & ") + 2 Equipage");
WHEN 7 => Put("Planches (" & integer'image(Coque_cost) & ") + 2 Coque") ;
END CASE ;
END LOOP ;
Goto_Xy(X-2,Y-Indice) ;
Set_Foreground(Light_Red) ;
put(character'val(26)) ;
Set_Foreground(Black) ;
END Put_Market_Menu2 ;
PROCEDURE Put_Select_Menu1(Indice : Natural := 1) IS
BEGIN
FOR I IN 1..4 LOOP
IF Indice = I
THEN set_foreground(Light_Red) ;
Goto_Xy(0,I+3) ;
put(character'val(26)) ;
ELSE set_foreground(Blue) ;
END IF ;
goto_xy(2,I+3) ;
CASE I IS
WHEN 1 => put("Navire de guerre") ;
WHEN 2 => put("Navire marchand") ;
WHEN 3 => put("Pirate") ;
WHEN 4 => Put("Corsaire") ;
END CASE ;
END LOOP ;
set_foreground(black) ;
END Put_Select_Menu1 ;
PROCEDURE Put_Select_Menu2(Indice : Natural := 1) IS
color : color_type ;
BEGIN
FOR I IN Liste_Navire'range LOOP
IF Indice = I
THEN color := Light_Red ;
print("" & character'val(26),color,20,I+3) ;
ELSE Color := Blue ;
print(" ",color,20,I+3) ;
END IF ;
print(to_string(Liste_navire(i).nom),color,22,i+3) ;
END LOOP ;
set_foreground(black) ;
END Put_Select_Menu2 ;
end P_Screen ;
P_Modes
Et enfin, le cœur du jeu : P_Mode. C'est dans ce dernier package que sont gérés les touches du clavier et la réaction à adopter.
WITH P_Navire ; USE P_Navire ;
PACKAGE P_Modes IS
FUNCTION First_Mode RETURN T_Navire'Class ;
PROCEDURE Fight_Mode (Joueur : IN OUT T_Navire'Class) ;
FUNCTION NextFight_Mode RETURN natural ;
PROCEDURE Market_Mode(Joueur : IN OUT T_Navire'Class) ;
PROCEDURE Buy_Mode(Joueur : IN OUT T_Navire'Class) ;
FUNCTION Select_Mode RETURN T_Navire'class ;
END P_Modes ;
Le nombre de procédures et fonctions est restreint : First_Mode gère le tout premier menu pour choisir entre une nouvelle ou une ancienne partie ; en cas de nouvelle partie, il lancera Select_Mode qui permet au joueur de choisir son navire et sa classe (marchand, pirate ...) ; puis il accède au menu du marché, Market_Mode qui est le principal menu (c'est de là que se font les sauvegardes en appuyant sur échap, les achats avec Buy_Mode, les ventes, les réparations ou le départ en mer avec Fight_Mode) ; enfin, NextFight_Mode gère un menu proposant au joueur de rentrer au port ou de continuer son aventure à la fin de chaque combat.
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Strings.Unbounded ; USE Ada.Strings.Unbounded ;
WITH Nt_Console ; USE Nt_Console ;
WITH P_Screen ; USE P_Screen ;
WITH P_Variables ; USE P_Variables ;
WITH P_Navire.List ; USE P_Navire.List ;
WITH P_Data ; USE P_Data ;
PACKAGE BODY P_Modes IS
FUNCTION First_Mode RETURN T_Navire'Class IS
Position : Natural := 1 ;
touche : character ;
BEGIN
Main_Loop : LOOP
Clear_Screen(White) ;
Put_Title ;
Put_First_Menu(Position) ;
Touche := Get_Key ;
IF Character'Pos(Touche) = 75 AND Position = 2 --TOUCHE GAUCHE
THEN Position := 1 ;
ELSIF Character'Pos(Touche) = 77 AND Position = 1 --TOUCHE DROITE
THEN Position := 2 ;
END IF ;
IF Character'Pos(Touche) = 13
THEN Print("Entrez le nom du fichier :",Blue,0,6) ;
Save_File_Name := To_Unbounded_String(Get_Line) ;
IF Position = 1
THEN RETURN Select_Mode ;
ELSIF Position = 2
THEN RETURN Load_Navire(To_string(save_file_name)) ;
END IF ;
END IF ;
END LOOP Main_loop ;
END First_Mode ;
PROCEDURE Fight_Mode(Joueur : IN OUT T_Navire'Class) IS
Touche : Character ;
Position : Natural := 4 ;
N : T_Pourcentage ;
Ordi : T_Navire'Class := generer_ennemi(Niveau) ;
BEGIN
Main_loop : LOOP
Raz_bonus(Joueur) ;
Clear_Screen(White) ;
Put_Title ;
Put_Status(Joueur,Gauche) ;
Put_Status(Ordi,Droite) ;
IF Joueur.Est_Mort
THEN Joueur.Perd ;
EXIT ;
END IF ;
------------------------
-- TOUR JOUEUR HUMAIN --
------------------------
LOOP
Put_Fight_Menu(Joueur,Position) ;
Touche := Get_Key ;
--touche gauche
IF Character'Pos(Touche) = 75
THEN IF Position = 1
OR (Position = 2 AND Joueur NOT IN T_Illegal'Class)
THEN NULL ;
ELSIF Position = 3 AND Joueur NOT IN T_Legal'Class
THEN Position := Position - 2 ;
ELSE Position := Position - 1 ;
END IF ;
END IF ;
--touche droite
IF Character'Pos(Touche) = 77 and position < 5
THEN IF Position = 1 AND Joueur NOT IN T_Legal'Class
THEN Position := Position + 2 ;
ELSE Position := Position + 1 ;
END IF ;
END IF ;
--touche entrée
IF Character'Pos(Touche) = 13
THEN CASE Position IS
WHEN 1 => Joueur.Aborde(Ordi) ;
WHEN 2 => joueur.bombarde(ordi) ;
WHEN 3 => joueur.defend ;
WHEN 4 => joueur.manoeuvre ;
WHEN OTHERS => put_fuite_message ; exit Main_loop ;
END CASE ;
EXIT ;
END IF ;
END LOOP ;
---------------------
-- TOUR ORDINATEUR --
---------------------
Raz_bonus(Ordi) ;
Clear_Screen(White) ;
Put_Title ;
Put_Status(Joueur,Gauche) ;
Put_Status(Ordi,Droite) ;
IF Ordi.Est_Mort
THEN Joueur.Bat(Ordi) ;
EXIT ;
END IF ;
N := Random ;
IF N >= 90
THEN Ordi.Manoeuvre ;
ELSIF N>=80
THEN Ordi.Defend ;
ELSIF Ordi IN T_Legal'Class AND Ordi IN T_Illegal'Class
THEN IF N mod 2 = 0
THEN Ordi.Bombarde(Joueur) ;
ELSE Ordi.Aborde(Joueur) ;
END IF ;
ELSIF Ordi IN T_Legal'Class
THEN Ordi.Bombarde(Joueur) ;
else ordi.aborde(joueur) ;
END IF ;
END LOOP Main_loop ;
END Fight_Mode ;
FUNCTION NextFight_Mode RETURN natural IS
Position : Natural := 1 ;
touche : character ;
BEGIN
LOOP
Put_NextFight_Menu(position) ;
Touche := Get_Key ;
--TOUCHE GAUCHE
IF Character'Pos(Touche) = 75 AND Position > 1
THEN Position := Position - 1 ;
END IF ;
--TOUCHE DROITE
IF Character'Pos(Touche) = 77 AND Position < 3
THEN Position := Position + 1 ;
END IF ;
IF Character'Pos(Touche) = 13 OR Character'Pos(Touche) = 72
THEN CASE Position IS
WHEN 1 => Niveau := 1 ;
WHEN 3 => Niveau := Niveau + 1 ;
WHEN OTHERS => null ;
END CASE ;
RETURN Position ;
END IF ;
END LOOP ;
END NextFight_Mode ;
PROCEDURE Market_Mode(Joueur : IN OUT T_Navire'Class) IS
Position : Natural := 1 ;
Touche : character ;
BEGIN
Main_Loop : LOOP
Raz_bonus(Joueur) ;
Clear_Screen(White) ;
Put_Title ;
Put_Status(Joueur,Gauche) ;
Put_Gold(joueur) ;
LOOP
Put_Market_Menu1(Joueur,Position) ;
Touche := Get_Key ;
--touche gauche
IF Character'Pos(Touche) = 75 and position > 1
THEN Position := Position - 1 ;
END IF ;
--touche droite
IF Character'Pos(Touche) = 77 and ((Joueur in T_Tradeship'class and position = 4) or position < 4)
THEN Position := Position + 1 ;
END IF ;
--touche echap
IF Character'Pos(Touche) = 27
THEN Save_Navire(Joueur) ;
Print("Fichier sauvegardé sous " & To_String(Save_File_Name) & ".txt",Red,0,24) ;
bleep ;
EXIT Main_Loop ;
END IF;
--touche entrée
IF Character'Pos(Touche) = 13 or Character'Pos(Touche) = 72
THEN CASE Position IS
WHEN 1 => Fight_loop : loop
Fight_Mode(Joueur) ;
IF Joueur.Est_Mort
THEN touche := get_key ;
EXIT Main_Loop ;
ELSE EXIT Fight_loop WHEN NextFight_Mode = 1 ;
END IF ;
END LOOP Fight_Loop ;
WHEN 2 => Joueur.reparer ;
WHEN 3 => Joueur.recruter ;
WHEN 4 => Buy_Mode(joueur) ;
WHEN OTHERS => T_Tradeship(Joueur).vendre ;
END CASE ;
EXIT ;
END IF ;
END LOOP ;
END LOOP Main_loop ;
END Market_Mode ;
PROCEDURE Buy_Mode(Joueur : IN OUT T_Navire'Class) IS
Position : Natural := 1 ;
Touche : character ;
BEGIN
while position > 0 LOOP
Put_Market_Menu2(Position) ;
Touche := Get_Key ;
--touche haut
IF Character'Pos(Touche) = 72 and position < 7
THEN Position := Position + 1 ;
END IF ;
--touche bas
IF Character'Pos(Touche) = 80 and position > 0
THEN Position := Position - 1 ;
END IF ;
--touche gauche ou droite
IF Character'Pos(Touche) = 75 or Character'Pos(Touche) = 77
THEN Position := 0 ;
END IF ;
--touche entrée
IF Character'Pos(Touche) = 13
THEN CASE Position IS
WHEN 1 => Joueur.Ameliorer_vitesse ;
WHEN 2 => Joueur.Ameliorer_defense ;
WHEN 3 => Joueur.Ameliorer_cuirasse ;
WHEN 4 => Joueur.Ameliorer_attaque ;
WHEN 5 => Joueur.Ameliorer_puissance ;
WHEN 6 => Joueur.Ameliorer_equipage ;
when 7 => Joueur.Ameliorer_coque ;
WHEN OTHERS => null ;
END CASE ;
Put_Gold(joueur) ;
Put_Status(Joueur,Gauche) ;
END IF ;
END LOOP ;
END Buy_Mode ;
FUNCTION Select_Mode RETURN T_Navire'Class IS
Navire : ACCESS T_Navire'Class ;
Pos1,Pos2 : Natural := 1 ;
touche : character ;
BEGIN
Main_Loop : LOOP
Menu1 : LOOP
Clear_Screen(White) ;
Put_Title ;
Put_Select_Menu1(Pos1) ;
Touche := Get_Key ;
--touche haut
IF Character'Pos(Touche) = 72 and pos1 > 1
THEN pos1 := pos1 - 1 ;
END IF ;
--touche bas
IF Character'Pos(Touche) = 80 and pos1 < 4
THEN pos1 := pos1 + 1 ;
END IF ;
--touche entrée ou droite
IF Character'Pos(Touche) = 13 or Character'Pos(Touche) = 77
THEN bleep ; EXIT Menu1 ;
END IF;
END LOOP Menu1 ;
Menu2 : LOOP
Put_Select_Menu2(Pos2) ;
Touche := Get_Key ;
--touche haut
IF Character'Pos(Touche) = 72 and pos2 > 1
THEN pos2 := pos2 - 1 ;
END IF ;
--touche bas
IF Character'Pos(Touche) = 80 and pos2 < Liste_Navire'length
THEN pos2 := pos2 + 1 ;
END IF ;
--touche entrée ou droite
IF Character'Pos(Touche) = 13 or Character'Pos(Touche) = 77
THEN bleep ; EXIT Main_Loop ;
END IF;
IF Character'Pos(Touche) = 75
THEN EXIT Menu2 ;
END IF;
END LOOP Menu2 ;
END LOOP Main_loop ;
CASE Pos1 IS
WHEN 1 => Navire := NEW T_Warship'(Init(Liste_Navire(Pos2).nom, Liste_Navire(Pos2).stat)) ;
WHEN 2 => Navire := NEW T_Tradeship'(Init(Liste_Navire(Pos2).nom, Liste_Navire(Pos2).stat)) ;
WHEN 3 => Navire := NEW T_Pirate'(Init(Liste_Navire(Pos2).nom, Liste_Navire(Pos2).stat)) ;
WHEN others => Navire := NEW T_Corsair'(Init(Liste_Navire(Pos2).nom, Liste_Navire(Pos2).stat)) ;
END CASE ;
Navire.Playable := True ;
Navire.Gold := 100 ;
return Navire.all ;
END Select_Mode ;
END P_Modes ;
Comme pour chaque TP, n'hésitez pas à perfectionner ce petit jeu de rôle, ce sera le meilleur des entraînements. Vous pouvez ajouter un écran des meilleurs scores, ajouter une nationalité à votre navire (Français, Anglais, Portugais, Hollandais, Espagnol, Pirate) ajoutant de nouveaux bonus/malus, vous pouvez également approfondir le système de jeu en proposant de personnaliser les armes (grappins, filets, sabres, lances, petits ou gros cannons ...) ou les manœuvres ...
Je me suis efforcé durant les derniers chapitres de vous apprendre à rédiger correctement vos algorithmes afin d'éviter toute erreur. Je vous ai régulièrement incité à penser aux cas particuliers, aux bornes des intervalles des tableaux, aux conditions de terminaison des boucles itératives ou récursives ... Malheureusement, il y a des choses que vous ne pouvez pas prévoir car elle ne dépendent pas du programmeur mais de l'utilisateur : un fichier nécessaire à votre logiciel qui aurait été malencontreusement supprimé, un utilisateur qui n'aurait pas compris que le nombre entier demandé par le programme ne peut pas avoir de virgule ou que 'A' n'est pas un nombre, la mémoire est saturée ...
Vos codes, pour l'heure, peuvent gérer certains de ces problèmes mais cela vous oblige généralement à les bidouiller et à les rendre illisibles (usage de boucles, saisie de texte converti ensuite en nombre...). Et qui plus est, vous ne pouvez gérer tous les cas de plantage. Heureusement, le langage Ada peut gérer ces erreurs grâces à ce que l'on appelle les exceptions. Les exceptions permettront de signaler le type d'erreur commis voire même de les traiter et de rétablir le fonctionnement normal du programme. Le langage Ada est même réputé pour la gestion des erreurs.
Vous avez du régulièrement vous retrouver face au message suivante : raised CONSTRAINT_ERROR : ###.abd:.... Je vous ai même parfois incité à écrire des programmes menant à ce genre d'erreur.
Ah oui ... le fameux plantage du Contraint_error ! Je ne sais même plus combien de fois il a accompagné le crash de mes programmes ... :D
C'est certainement l'une des exceptions les plus courantes au début. L'exception CONSTRAINT_ERROR, indique que vous tentez d'accéder à un élément inexistant (cible d'un pointeur nul, accès à la 11ème valeur d'un tableau à 10 éléments ...) ou qu'un calcul risque de générer un overflow (pour des rappels sur l'overflow, voire le premier exercice du chapitre sur la récursivité ou bien le chapitre traitant de la représentation des nombres entiers). Mais vous ne devez pas la voir comme un plantage de votre programme. En fait, Ada se rend compte à un moment donné qu'il y a une erreur et lève une exception afin d'éviter un véritable crash, c'est à dire le programme qui se ferme tout seul sans vous dire merci et votre système d'exploitation qui vous indique qu'il a rencontré un petit soucis.
Et ça nous avance à quoi que Ada s'en rende compte puisque de toutes façons le résultat est le même ? o_O
Que vous êtes défaitistes, c'est au contraire d'une grande aide :
Ada nous indique de quel type d'erreur il s'agit tout d'abord. Il nous indique également la ligne du code où le soucis est apparu et ajoute quelques informations supplémentaires. Ces indications sont très utiles à la fois pour la personne qui développe le programme, mais aussi pour celle qui sera chargée de sa maintenance.
Une fois l'exception connue, il sera possible d'effectuer un traitement particulier adapté au type d'erreur rencontrée, et parfois même de résoudre ce problème afin de rétablir un fonctionnement normal du programme.
Une exception n'est donc pas un simple plantage de votre programme mais plutôt une alerte concernant un évènement exceptionnel méritant un traitement approprié. Jusque là, aucun traitement n'étant proposé, Ada décidait de mettre lui-même fin au programme pour éviter tout problème.
Le fonctionnement par l'exemple
Testons par exemple le code suivant afin de comprendre ce qu'il se passe :
procedure test_exception is
type Tableau is array(1..10) of integer ;
procedure init(T : out Tableau ; dbt, fin : integer) is
begin
for i in dbt..fin loop
T(i) := 0 ;
end loop ;
end init ;
T : Tableau ;
begin
init(T,0,11) ; --Il y aura un gros soucis à ce moment là !
end test_exception ;
Vous devriez obtenir le doux message suivant : raised CONSTRAINT_ERROR : test_exception.adb:8 index check failed. Traduction : Ada a levé (raised) une exception de type CONSTRAINT_ERROR. Celle-ci a été déclenchée lors de l'exécution de l'instruction située à la ligne 8 de test_exception.adb. Information complémentaire : vous avez commis une erreur sur les indices du tableau.
Sauf que l'erreur dans ce code est à la ligne 15 et pas 8 ! Quelle idée d'initialiser 12 éléments dans un tableau de 10 ! o_O
Reprenons le cheminement tranquillement. Votre programme commence par effectuer ses déclarations de types, variables et procédures. Jusque là, rien de catastrophique. Puis il exécute l'instruction Init() durant laquelle une boucle est exécutée qui demande l'accès en écriture à l'élément n°0 de notre tableau. C'est cette demande qui lève une exception. Que fait le programme ? Il cherche, au sein de la procédure Init(), une proposition de traitement lié à ce type d'erreur. Puisqu'il n'en trouve pas, il met fin à la procédure et répercute l'exception dans la procédure principale et recommence. Il cherche à nouveau un traitement lié à cette exception et comme il n'y en a toujours pas, il met fin à cette nouvelle procédure. Et comme il s'agit de la procédure principale, le programme prend fin en affichant l'exception rencontrée.
Comme le montre le schéma ci-dessous, la levée d'une exception ne génère pas automatiquement l'arrêt brutal de votre programme, mais plutôt un arrêt en chaîne si aucun traitement approprié n'a été prévu. Votre programme cherchera un remède à l'exception rencontrée au sein même du sous-programme responsable avant de transmettre ses ennuis au sous-programme qui l'avait auparavant appelé.
Vous aurez également remarqué sur le schéma que les flèches indiquant la recherche d'un traitement des exceptions pointent toutes vers la fin des procédures. En effet, la levée d'une exception dans une procédure ou une fonction entraîne immédiatement son arrêt. Le programme "saute" alors à la fin de la procédure ou fonction pour y chercher un éventuel traitement. C'est donc à la toute fin de nos sous-programmes que nous allons tâcher de régler nos erreurs à l'aide du mot clé exception. Vous allez voir, ce nouveau mot-clé a un fonctionnement analogue à celui de case :
procedure init(T : out Tableau ; dbt, fin : integer) is
begin
for i in dbt..fin loop
T(i) := 0 ;
end loop ;
exception
when CONSTRAINT_ERROR => Put_line("Tu pouvais pas reflechir avant d'ecrire tes indices ?") ;
when others => Put_line("Qu'est-ce que t'as encore fait comme anerie ?") ;
end init ;
Nous nous contenterons pour l'instant d'un simple affichage. Si vous testez de nouveau votre code, vous devriez obtenir le compliment suivant : Tu pouvais pas reflechir avant d'ecrire tes indices ?. Cela ne règle toujours pas notre problème mais nous avons progressé : plus de vilains affichages agressifs et incompréhensibles. Une autre solution aurait consisté à gérer l'exception non pas dans la procédure init mais dans la procédure principale :
procedure test_exception is
type Tableau is array(1..10) of integer ;
procedure init(T : out Tableau ; dbt, fin : integer) is
begin
for i in dbt..fin loop
T(i) := 0 ;
end loop ;
end init ;
T : Tableau ;
begin
init(T,0,11) ;
exception
when CONSTRAINT_ERROR => Put_line("Tu pouvais pas reflechir avant d'ecrire tes indices ?") ;
when others => Put_line("Qu'est-ce que t'as encore fait comme anerie ?") ;
end test_exception ;
Où et quand gérer une exception
Mouais, bah ça c'est typiquement le genre d'exemple inutile que j'aurais pu trouver tout seul. Tu chercherais pas à meubler parce que tu n'as plus rien à dire ?
Vous croyez ? :p Eh bien non, je n'essaie pas de meubler mais bien de vous présenter deux cas différents. Alors oui, je sais : au final, le programme affiche toujours la même phrase. Alors pour comprendre la différence, ajoutez cette ligne juste après init(T,0,11) ; et avant la fin du programme et le bloc de gestion des exceptions :
put_line("Initialisation reussie !") ;
Testez ensuite les deux cas. Quand le bloc exception se trouve dans la procédure principale, rien ne change ! La procédure init échoue toujours entraînant l'affichage de cette fameuse phrase de congratulation. :( Mais lorsque le bloc exception se trouve au sein même de la procédure init, l'affichage obtenu est tout autre :
Tu pouvais pas reflechir avant d'ecrire tes indices ?
Initialisation reussie !
Eh oui ! Le programme principal reprend son cours, comme si de rien n'était. Victoire ! Il ne plante plus !
Wouhouh ! ! ! :soleil: Mais au fait, que vaut le tableau alors ? :o
C'est justement sur ce point que je souhaitais attirer votre attention. La levée de l'exception n'entraîne plus l'arrêt du programme grâce au traitement effectué, mais le problème n'a pas été résolu. Le programme principal continue donc comme si de rien était alors que le tableau qu'il était sensé initialiser n'a jamais vu la moindre affectation. Tentez un tri sur ce tableau ou la moindre lecture, et vous aurez droit de nouveau à une jolie exception. De ce simple exemple, nous devons tirer quelques enseignements :
Soit nous traitons cette erreur dans la procédure en cause (init), et alors nous traitons le problème à fond afin de retourner un tableau vraiment initialisé :
exception
when CONSTRAINT_ERROR => Put_line("Il y a eu un petit contre-temps, mais c'est fait.") ;
T := (others => 0) ;
Soit nous propageons l'exception au programme principal sciemment à l'aide du mot clé raise :
exception
when CONSTRAINT_ERROR => Put_line("Il y a eu un petit soucis.") ;
raise ;
Soit nous ne nous en préoccupons que dans le programme principal en considérant que le problème provient de là et qu'il doit donc être traité par la procédure test_exception.
Enfin, quel que soit le cas de figure que vous choisirez, gardez en mémoire le petit schéma vu précédemment : avant de traiter une exception vous devez réfléchir à sa propagation et au meilleur moment de la traiter.
Le langage Ada dispose nativement de nombreuses exceptions prédéfinies. Nous avons jusque là traité de l'exception CONSTRAINT_ERROR qui est levée lors d'une erreur sur l'indexation d'un tableau, lors de l'accès à un pointeur null, d'un overflow, d'une opération impossible (division par 0 par exemple). Mais d'autres existent et sont définies par le package Standard :
PROGRAM_ERROR : celle-là, vous ne l'avez probablement jamais vue. Elle est appelée lorsqu'un programme fait appel à un sous-programme dont le corps n'a pas encore été rédigé ou lorsqu'une fonction se termine sans être passée par la case return. Cela peut arriver notamment lors d'une erreur avec une fonction récursive (nous verrons un exemple juste après).
STORAGE_ERROR : cette exception est levée lorsqu'un programme exige plus de mémoire qu'il n'en a le droit. Cela arrive régulièrement avec des programmes récursifs mal ficelés : une boucle récursive infinie est engendrée, réquisitionnant plus de mémoire à chaque appel. L'ordinateur met fin à cette gabegie lorsque la mémoire demandée devient trop importante.
TASKING_ERROR : Celle-là non plus, vous n'avez pas du la voir beaucoup, et pour cause elle est levée lorsqu'un problème de communication apparaît entre deux tâches. Mais comme vous ne savez pas encore ce qu'est une tâche en Ada, cela ne vous avance pas à grand chose, patience. :p
Exceptions et fonctions récursives
Avant de présenter de nouvelles exceptions, attardons-nous sur le cas des fonctions récursives évoqué ci-dessus. Voici une fonction toute simple qui divise un nombre par 4, 3, 2, 1 puis 0. Bien entendu, la division par 0 engendrera une exception :
with ada.integer_text_io ; use ada.integer_Text_IO ;
procedure Test_exception_recursive is
function division(a : integer ; n : integer) return integer is
begin
put(a) ;
return division(a/n,n-1) ;
end division ;
begin
put(division(125, 4) ) ;
end test_exception_recursive ;
Comme attendu, nous nous retrouvons avec une belle exception :
125 31 10 5 5
raised CONSTRAINT_ERROR : test_exception_recursive.adb:8 divide by zero
Nous allons résoudre ce problème à l'aide de nos exceptions (oui, je sais, il y a plus simple mais c'est un exemple :-° ) :
with ada.Text_IO ; use ada.Text_IO ;
with ada.integer_text_io ; use ada.integer_Text_IO ;
procedure Test_exception_recursive is
function division(a : integer ; n : integer) return integer is
begin
put(a) ;
return division(a/n,n-1) ;
exception
when others => Put_line("Division par zero !") ;
end division ;
begin
put(division(125, 4) ) ;
end test_exception_recursive ;
Et que se passe-t-il désormais ?
125 31 10 5 5Division par zero !
Division par zero !
Division par zero !
Division par zero !
Division par zero !
raised PROGRAM_ERROR : test_exception_recursive.adb:8 missing return
Pourquoi Ada lève-t-il une exception ? On les avait toutes traitées avec exception et when others, non ?
Pas tout à fait. Nous avons réglé le cas des exceptions levées lors de la fonction. Notre fonction division n°1 (avec n valant 4) effectue quatre appels récursifs. Et l'appel division n°5 (avec n valant 0) lève une exception (la division par zéro) au lieu de renvoyer un integer. Du coup, le même phénomène se produit pour les division n°4, 3, 2 puis 1 ! Tout cela est très bien, mais il n'empêche que notre programme principal attend que la fonction lui renvoie un résultat, ce qu'elle ne peut pas faire puisque notre traitement des exceptions ne contient pas d'instruction return. Ce qui lève donc cette fameuse exception : PROGRAM_ERROR. Encore une fois, il est important de réfléchir à la propagation d'une exception avant de se lancer dans un traitement hasardeux.
Autres exceptions prédéfinies
D'autres exceptions sont définies par le langage dans divers packages. Mais vous avez du en rencontrer beaucoup lorsque vous avez travaillé sur les fichiers : lorsque le mode n'était pas bon, que vous n'aviez pas pensé à gérer les fins de fichiers, ou que le programme ne trouvait pas votre fichier pour une toute petite erreur d'haurtogaffe. Ces exceptions concernant les entrées-sorties sont définies dans le package Ada.IO_Exceptions (a-ioexce.ads) :
Status_Error : levée lorsque le status d'un fichier (ouvert/fermé) est erroné. Par exemple, fermer ou lire un fichier déjà fermé.
Mode_Error : levée lorsque le mode d'un fichier (in_file/out_file/append_file) est erroné. Par exemple, si vous tentez d'écrire dans un fichier en lecture seule.
Name_Error : levée lorsque le nom d'un fichier est erroné, c'est à dire quand il est introuvable.
Use_Error : levée lorsque l'usage d'un fichier ne correspond pas à son type. Pour rappel, nous avions vu trois types de fichiers : texte, séquentiel et à accès direct.
Device_Error : levée lors de problèmes liés au matériel.
End_Error : levée lorsque vous tentez de lire au delà de la fin du fichier (pensez à utiliser End_of_page, end_of_line et end_of_file).
Data_Error : levée lorsque l'utilisateur fournit des données du mauvais type. Par exemple, lorsque le programme demande un entier et que l'utilisateur lui renvoie un 'A'.
Layout_Error : levée lorsqu'un string est trop long pour être affiché.
Supposons que vous soyez en pleine conception d'un programme d'authentification. Votre programme doit saisir un identifiant composé de 5 lettres ainsi qu'un mot de passe comportant 6 lettres suivies de 2 chiffres et les enregistrer dans un fichier. La partie sensible se pose au moment de la saisie du mot de passe : on ne va pas enregistrer un mot de passe incorrect ! Vous avez donc rédigé pour cela une fonction mdp_correct qui renvoie false en cas d'erreur.
Et justement s'il y a erreur, votre programme devra lever une exception. Nous appellerons notre exception PWD_ERROR. Notez au passage que j'écrirai toujours mes exceptions en majuscules les nommerai toujours avec le suffixe _ERROR. Une autre solution consiste à les préfixer avec EXC_, de la même manière que nos types étaient préfixés par un T_ et nos packages par un P_.
La déclaration de l'exception se fait en même temps que les déclarations de types ou de variables de la façon suivante :
PWD_ERROR : exception ;
Lever sa propre exception
C'est bien gentil d'avoir ses propres exceptions, mais comment Ada peut-il savoir quand la lever ? Ce n'est pas une exception standard !
Cela se fera à l'aide du mot clé raise, déjà vu précédemment. Voici donc un exemple de programme :
procedure Authentification is
PWD_ERROR : exception ;
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
else raise PWD_ERROR ;
end if ;
exception
when PWD_ERROR => put_line("Mot de passe incorrect !") ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end Authentification ;
Et de la même manière qu'avec une exception standard, l'instruction raise va mettre fin à notre procédure et effectuer un bond vers le bloc de traitement pour trouver une réponse adaptée.
Il est également possible avec l'instruction with d'indiquer immédiatement à la levée de l'exception le message d'alerte qui sera affiché.
procedure Authentification is
PWD_ERROR : exception ;
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
else raise PWD_ERROR with "Mot de passe incorrect !" ;
end if ;
exception
when PWD_ERROR => null ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end Authentification ;
Propagation de l'exception
Mais si la procédure Authentification fait partie d'un programme plus vaste, que va-t-il se passer pour le programme principal ? L'authentification n'aura pas eu lieu et le programme principal ne connaîtra pas mon exception puisqu'elle est définie seulement dans la sous-procédure.
Une solution consiste à propager l'exception aux programmes appelants en écrivant :
when PWD_ERROR => put_line("Mot de passe incorrect !") ; raise ;
Mais le programme principal ne connaîtra pas PWD_ERROR, car sa portée est limitée à la procédure Authentification. Le programme principal devra donc comporter un bloc exception dans lequel PWD_ERROR sera récupéré par l'instruction when others.
Rectifier son code
Le retour du bloc declare
Tout cela c'est bien beau, mais ça ne répare pas les bêtises. :( Il vaudrait mieux demander à l'utilisateur de recommencer plutôt que de propager PWD_ERROR, mais le bloc exception est forcément à la fin de la procédure !
Attention, le bloc exception doit se trouver à la fin d'un autre bloc mais pas nécessairement à la fin du sous-programme. Il peut donc terminer une function, une procedure ou un declare. Et c'est ce dernier que nous allons utiliser :
procedure Authentification is
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
declare
PWD_ERROR : exception ;
begin
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
else raise PWD_ERROR ;
end if ;
exception
when PWD_ERROR => put_line("Mot de passe incorrect !") ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end ;
end Authentification ;
Une autre façon, plus élégante et moins lourde consiste à créer un simple bloc introduit par begin sans rien déclarer :
procedure Authentification is
PWD_ERROR : exception ;
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
TRY : begin
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
else raise PWD_ERROR ;
end if ;
exception
when PWD_ERROR => put_line("Mot de passe incorrect !") ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end TRY ;
end Authentification ;
Je conserverai cette seconde solution par la suite car elle a le mérite de ne rien déclarer en cours de route (pratique à bannir autant que possible) et de faire apparaître clairement un bloc de test (rappelons que try signifie essayer) dans lequel pourra être levé une exception. On parle alors de zone critique. Venons-en maintenant à la façon de rectifier notre code. Il y a deux grandes options.
Les boucles
La première option consiste à enfermer notre section critique dans une boucle dont on ne sort qu'en cas de réussite :
loop
TRY : begin
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
exit ; -- on peut même clarifier ce exit en nommant la boucle.
else raise PWD_ERROR ;
end if ;
exception
when PWD_ERROR => put_line("Mot de passe incorrect !") ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
raise ;
end TRY ;
end loop ;
La levée de l'exception empêche donc la sortie de boucle et la portion de code est ainsi répétée. Une variant pourrait consisté à proposer seulement trois essais et à clore le programme ensuite.
Goto is back !
Cette solution, si elle a ses adeptes, me semble plutôt lourde et oblige à ouvrir deux blocs : un bloc itératif et un bloc déclaratif ! Et par conséquent, cela nous oblige à fermer deux blocs. Question efficacité, on a déjà fait mieux. :( Ma solution privilégiée est de faire appel à une instruction que je vous avais jadis interdite : goto ! :ninja:
Son inconvénient majeur était qu'elle ne réalisait pas de blocs clairement identifiables et générait généralement du code dit "spaghetti" où les chemins suivis par le programme s'entremêlent au point que plus personne n'ose y mettre le nez. Mais dans le cas présent nous avons créé un bloc spécifique, alors profitons-en pour faire appel (proprement) à cette vieille instruction :
<<TRY>>
begin
if mdp_correct(pwd)
then Enregistrement(login, pwd) ;
else raise PWD_ERROR ;
end if ;
exception
when PWD_ERROR => put_line("Mot de passe incorrect !") ;
goto TRY ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
raise ;
end ;
Après les exceptions, les assertions ! Qu'est-ce que c'est encore que ça ?
Une assertion est simplement un test rapide permettant de contrôler certains paramètres de votre programme et de lever une exception particulière (ASSERTION_ERROR) si les conditions ne sont pas remplies. Mais avant de vous expliquer sa mise en oeuvre, je dois vous parler des pragma.
Peut-être avez-vous déjà vu cette instruction en feuilletant divers packages sans en comprendre le sens. Les pragma sont ce que l'on appelle en Français des directives de compilateur, c'est à dire des instructions qui s'adressent non pas au programme et à ses utilisateurs mais à votre bon vieux compilateur GNAT. Elle sont là pour lui donner des instructions sur la façon de compiler, de comprendre votre code, de le contrôler ...
Mais ces directives sont également là éprouver votre code, vous apporter des garanties de fiabilité. Elles peuvent s'écrire durant les déclaration ou le déroulement de vos programmes et s'utilisent de la manière suivante :
pragma Nom_de_directive(parametres_eventuels) ;
Il existe des dizaines et des dizaines de directives différentes. Certains compilateurs fournissent d'ailleurs leurs propres directives. Celle dont nous allons parler est heureusement utilisée par tous les compilateurs, il s'agit de la directive Assert (comme assertion, vous l'aurez compris). Reprenons le cas de notre mot de passe. Plutôt que de lever notre propre exception, il est possible de vérifier l'assertion (ou affirmation) suivante : "le mot de passe est correct". Si cette assertion est vérifiée, on continue notre bout de chemin. Sinon, l'exception ASSERTION_ERROR sera automatiquement levée. Exemple :
procedure Authentification is
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
pragma assert(mdp_correct(pwd)) ;
Enregistrement(login, pwd) ;
exception
when ASSERTION_ERROR => put_line("Mot de passe incorrect !") ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end Authentification ;
La directive Assert prend en paramètre une expression booléenne. Il est ainsi possible de vérifier la valeur d'un nombre ou d'effectuer un test d'appartenance en écrivant :
pragma Assert(x=0) ;
-- OU
pragma Assert(MonObjet in MonType'class) ;
Assert peut également prendre un second paramètre. On indique alors avec une chaîne de caractères le message à afficher en cas d'erreur :
procedure Authentification is
login : string(1..5) ;
pwd : string(1..8) ;
begin
login := saisie_login ;
pwd := saisie_pwd ;
pragma assert(mdp_correct(pwd),"Mot de passe incorrect !") ;
Enregistrement(login, pwd) ;
exception
when ASSERTION_ERROR => null ;
when others => put_line("Le programme a rencontré une erreur fatale !") ;
end Authentification ;
Supprimer les contrôles du compilateur
Tant que nous parlons de pragma, je vais vous en présenter une seconde directive de compilateur : suppress. Cette directive permet de lever le contrôle de certaines exceptions effectué par le compilateur. Par exemple :
pragma suppress(overflow_check) ;
Supprimera le test d'overflow lié à l'exception CONSTRAINT_ERROR sur le bloc entier. De même, si vous disposez d'un type T_tableau, vous pourrez supprimer le contrôle des indices sur tous les types tableaux de tout le bloc en écrivant :
pragma suppress(index_check) ;
ou bien ne supprimer ces tests que sur les variables composites de types T_Tableau en écrivant :
pragma suppress(overflow_check, T_Tableau) ;
Voici les tests de l'exception CONSTRAINT_ERROR que vous pourrez supprimer avec pragma suppress : access_check, discriminant_check, index_check, length_check, range_check, division_check, overflow_check. Mais comme je doute que vous ayez souvent l'occasion de les mettre en œuvre, je ne m'étendrai pas plus longtemps sur cette notion (la plupart de ces noms évoquant d'ailleurs clairement le test effectué).
Avec la norme Ada 2012, il est possible d'effectuer automatiquement des assertions à l'entrée et à la sortie d'une fonction ou d'une procédure. Ces conditions d'application de la fonction sont appelées contrats. Pour bien comprendre, changeons d'exemple. Prenons une fonction qui effectue la division de deux natural :
function division(a,b : natural) return natural ;
Cette fonction doit remplir quelques conditions. Une précondition tout d'abord : le nombre b ne doit pas valoir 0 (je rappelle qu'il est impossible de diviser par zéro :colere2: ). Nous allons donc affecter un contrat à notre fonction :
function division(a,b : natural) return natural
with Pre => (b /= 0) ;
Une exception sera donc levée ou GNAT vous avertira si jamais vous veniez à diviser par 0. Mais notre fonction doit également remplir une postcondition : le résultat obtenu doit être plus petit que le paramètre a (c'est une division entière). Nous allons donc affecter un second contrat :
function division(a,b : natural) return natural
with Pre => (b /= 0) ,
with Post => (dision(a,b) < a) ;
Cette programmation par contrat est une des grandes nouveautés de la norme Ada2012, empruntée à des languages tels Eiffel ou D. Elle peut également s'appliquer aux types. Prenons l'exemple d'un type T_Date dont vous souhaiteriez qu'il soit et demeure valide (pas de 35/87/1901 par exemple). Vous définirez alors un invariant de type :
type T_Date is record
jour,mois,annee : integer ;
end record
with Type_Invariant => (jour in 1..31 and mois in 1..12 and annee in 1900..2100) ;
Après la programmation orientée objet, nous en venons au second point essentiel de la partie IV : le multitasking. Si vous n'avez jamais entendu parler de multitasking, peut-être avez-vous déjà entendu parler de multithreading, de parallélisme, de programmation multi-tâche, de programmation concurrente ou de programmation temps réel ? Non ? Alors sachez que le but de ce chapitre est de réaliser un programme capable d'effectuer plusieurs tâches "en même temps" et non plus successivement, c'est à dire de réaliser ses tâches en parallèle et non en série.
Contrairement à la POO, qui consistait avant tout à changer l'organisation de notre code pour mieux le structurer, la programmation temps réel va vous obliger à changer votre façon de programmer et penser vos programmes en y faisant intervenir la notion de temps et en vous obligeant à anticiper les interactions possibles entre les différentes tâches. Il vous faudra également comprendre le fonctionnement du processeur. Attention, ce chapitre est très dense et complexe, ce qui nécessitera peut-être plusieurs lectures.
Multitasking ou l'art de faire plusieurs tâches à la fois
Quel est l'intérêt de ce multitasking ? J'ai jamais vu de programmes qui faisaient plusieurs choses différentes "en même temps". :(
Détrompez-vous ! En ce moment même, vous utilisez assurément un programme multitâche : votre système d'exploitation ! Que vous utilisiez Windows, MacOS ou une distribution Linux, votre système d'exploitation est bien obligé de pouvoir gérer plusieurs tâches en même temps : même si vous lancé un jeu, un navigateur internet et une messagerie mail, votre système d'exploitation n'arrête pas pour autant de fonctionner, de se mettre à jour ou de supporter votre antivirus. Et il effectue ces tâches "en même temps". Le multitasking est donc un composant essentiel de l'informatique moderne.
Bon, pour le système d'exploitation d'accord. Mais à mon niveau, je ne vais pas programmer un OS ! Quel intérêt de faire plusieurs choses en même temps ? Autant les faire successivement, ça reviendra au même. :euh:
Prenons comme exemple un domaine très friand de programmation temps réel : l'aérospatiale ! Vous devez rédiger un programme d'aide au pilotage pour la fameuse fusée Z123 pilotée par Zozor. Votre programme doit régulièrement contrôler les capteurs de pression, d'altitude, de température, de vitesse ... afficher les valeurs lues et permettre à Zozor de rectifier ces paramètres pour éviter le crash ou l'explosion en plein vol. Si nous procédons comme d'habitude nous aurons le schéma suivant :
Logique n'est-ce pas ? Sauf que le temps que votre programme vérifie la pression, l'altitude ou la vitesse peuvent chuter. Et Zozor devra de plus valider la pression alors que l'urgence serait plutôt de redresser la fusée et de mettre les gaz. Un schéma similaire à celui-ce serait préférable :
Le programme contrôle tous les capteurs en même temps, affiche les valeurs en temps réel et permet de rectifier certains paramètres sans bloquer le reste du système. C'est la réussite assurée pour la Z123.
Eh bien, dans ce cas, il n'y a qu'à réaliser plusieurs programmes, un pour la pression, un autre pour la vitesse, un autre pour l'altitude ...
Ce pourrait être une bonne idée, mais encore une fois, ce n'est pas réaliste : si Zozor rectifie sa trajectoire en augmentant l'altitude, cela impliquera une augmentation de la vitesse et surtout, le système ne devra pas s'affoler de voir la pression atmosphérique ou la température extérieure baisser. Bref, ces différentes tâches manipulent des variables communes et il est donc préférable de les rassembler dans un même programme plutôt que de les dissocier.
Les tâches en Ada
Créer une tâche
Vous avez compris le principe et l'objectif ? Bien, passons alors à la mise en œuvre. Une tâche se déclare en Ada avec le mot clé task et fonctionne un peu comme une procédure ou une fonction. Cependant, vous devrez préalablement définir sa spécification avant de rédiger son corps. Continuons avec l'exemple de la fusée Z123 :
with ada.text_io ; use ada.text_io ;
procedure Z123 is
altitude, vitesse : integer := 0 ;
--Nous déclarerons les tâches ici
begin --La procédure principale se chargera de simuler le décollage
put_line("3 ... 2 ... 1 ... Decollage !") ;
while altitude < 10_000 loop
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
end loop ;
put_line("Decollage reussi !") ;
end Z123 ;
La procédure Z123 est notre première tâche : la tâche principale. Nous allons déclarer également les deux tâches suivantes :
task Verif_Altitude ;
task body Verif_Altitude is
begin
loop
put_line("Altitude de" & integer'image(altitude) & " metres") ;
end loop ;
end Verif_Altitude ;
---------
task Verif_Vitesse ;
task body Verif_Vitesse is
begin
loop
put_line("Vitesse de" & integer'image(vitesse) & " km / H") ;
end loop ;
end Verif_Vitesse ;
Avorter une tâche
Compilez et exécutez ce code et là ... c'est le drame ! Les lignes d'affichage défilent à une vitesse ahurissante. Aucun moyen de savoir ce qui se passe et le programme n'en finit pas ! Le problème, c'est que la tâche principale ne prendra fin qu'à l'arrêt des deux tâches Verif_Altitude et Verif_Vitesse. Or ces deux tâches ont pour but de vérifier aussi longtemps que possible l'altitude et la vitesse. Il faudrait donc que la procédure principale mette fin à ces deux tâches. Pour cela, il suffit d'utiliser le mot clé abort : on dit alors que l'on fait avorter nos tâches :
with ada.text_io ; use ada.text_io ;
procedure Z123 is
altitude, vitesse : integer := 0 ;
task Verif_Altitude ;
task body Verif_Altitude is
begin
loop
put_line("Altitude de" & integer'image(altitude) & " metres") ;
end loop ;
end Verif_Altitude ;
task Verif_Vitesse ;
task body Verif_Vitesse is
begin
loop
put_line("Vitesse de" & integer'image(vitesse) & " km / H") ;
end loop ;
end Verif_Vitesse ;
begin
put_line("3 ... 2 ... 1 ... Decollage !") ;
while altitude < 10_000 loop
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
end loop ;
put_line("Decollage reussi !") ;
abort Verif_Altitude ;
abort Verif_Vitesse ;
end Z123 ;
Temporiser vos tâches
Bon, cette fois notre programme prend fin, le décollage de la fusée de Zozor a bien eu lieu mais on n'a le temps de rien voir. Quand le programme prend fin, on voit seulement que l'altitude est de 10 000 mètres et la vitesse de 1000 km/H
Et encore ! Ca ne fait jamais deux fois la même chose ! Des fois, la vitesse ou l'altitude (ou même les deux) valent 0 alors que le décollage est soit-disant réussi ! o_O
Je reviendrai sur ce problème plus tard lorsque nous évoquerons le fonctionnement du processeur. Commençons déjà par régler le problème de la vitesse. Nous allons faire patienter nos deux tâches quelques instants (un dixième de seconde pour être précis) avant de faire un affichage. Cela nous laissera le temps de lire les informations. Pour cela, nous allons utiliser l'instruction delay. Celle-ci prend en paramètre un nombre décimal à virgule fixe correspondant au nombre de secondes d'attente :
task Verif_Altitude ;
task body Verif_Altitude is
begin
loop
delay 0.1 ;
put_line("Altitude de" & integer'image(altitude) & " metres") ;
end loop ;
end Verif_Altitude ;
task Verif_Vitesse ;
task body Verif_Vitesse is
begin
loop
delay 0.1 ;
put_line("Vitesse de" & integer'image(vitesse) & " km / H") ;
end loop ;
end Verif_Vitesse ;
Et pour éviter que le décollage ne soit terminé avant que le moindre affichage n'ait eu lieu, nous allons également temporiser le décollage en attendant un centième de seconde avant l'incrémentation :
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
end loop ;
Cette fois, tout se passe comme prévu : la vitesse augmente jusqu'à stagner à 1000 km/H, l'altitude augmente jusqu'à atteindre 10 000 mètres, mettant alors fin au programme de décollage.
Temporiser jusqu'à ...
Une autre possibilité est d'utiliser la combinaison de deux instructions : delay until ### ; où ### est de type Time. Cela signifie "attendre jusqu'à une date précise". Vous aurez alors besoin soit du package Ada.calendar soit de Ada.Real_Time. Tous deux définissent un type Time et une fonction clock vous permettant d'obtenir la date actuelle.
Ainsi, vous pourrez définir une constante Delai_Attente de type duration et l'utiliser pour temporiser vos programmes. Reprenons par exemple la tâche Verif_Vitesse :
task body Verif_Vitesse is
Delai_Attente : Duration := 0.1 ;
begin
loop
delay until (clock + Delai_Attente) ;
put_line("Vitesse de" & integer'image(vitesse) & " km / H") ;
end loop ;
end Verif_Vitesse ;
Le principe est assez similaire. Au lieu d'attendre qu'un certain temps se soit écoulé, on attend un moment précis (une heure précise, un jour précis ...). Vue la structure actuelle de notre code, vous comprendrez que cette solution n'est pas la mieux adaptée à notre problème.
Le type tâche
C'est sympa, mais c'est pas un peu redondant d'écrire deux tâches aussi similaires ? Et puis tu n'as pas expliqué le problème d'affichage d'altitude. :o
Vous allez devoir attendre encore un peu pour comprendre cette bizarrerie. En revanche, je peux vous éviter ce problème de redondance. Nous allons pour cela définir un type tâche. Nous allons en profiter au passage pour essayer d'améliorer l'affichage et arriver à ceci :
3 ... 2 ... 1 ... Decollage !
Altitude (en m) Vitesse (en km/H)
8790 800
Ce sera le retour du package NT_Console que nous avions utilisé lors du TP n°3 sur le jeu du serpent (cliquez sur le lien pour retrouver le code source de ce package). Je vous préviens tout de suite : vous allez de nouveau être confronté à une bizarrerie que je n'expliquerai pas tout de suite (comment ça je fuis devant la difficulté ? :p ).
Nous n'allons donc définir qu'un seul type de tâche appelé Task_Verif. Celle-ci affichera le contenu d'une variable à un endroit précis. Il nous suffira ensuite de définir deux tâches Verif_altitude et Verif_vitesse de type Task_Verif. Voici à quoi ressemblera notre type tâche :
task type Task_Verif(var : integer ; x : X_Pos ; y : Y_Pos) ;
task body Task_Verif is
begin
loop
delay 0.1 ;
GOTO_XY(x,y) ;
put(var) ;
end loop ;
end Task_Verif ;
Notez bien deux choses : l'ajout du mot type lors de la spécification tout d'abord, l'absence de paramètres pour le corps ensuite. Et voici ce que devient notre programme Z123 :
with ada.text_io ; use ada.text_io ;
with ada.integer_text_io ; use ada.integer_text_io ;
with NT_Console ; use NT_Console ;
procedure Z123 is
-- Déclaration du type Task_Verif
altitude : integer := 0 ;
Verif_Altitude : Task_Verif(altitude,0,2) ;
vitesse : integer := 0 ;
Verif_Vitesse : Task_Verif(vitesse,25,2) ;
begin
GOTO_XY(0,0) ; put("3 ... 2 ... 1 ... Decollage !") ;
GOTO_XY(0,1) ; put("Altitude (en m) ") ;
GOTO_XY(25,1) ; put("Vitesse (en km/H) ") ;
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
end loop ;
GOTO_XY(0,3) ; put_line("Decollage reussi !") ;
abort Verif_Altitude ;
abort Verif_Vitesse ;
end Z123 ;
En procédant de la sorte, nous nous épargnons toute redondance et il est possible de créer, rapidement et facilement, une tâche pour contrôler la pression, la température ou tout autre paramètre.
Euh ... la vitesse et l'altitude n'augmentent plus, c'est normal ? :o
Oui, c'est normal ! Car j'ai rédigé ce code pour attirer votre attention sur un point particulier : une tâche n'est pas une procédure ou une fonction que l'on appellerait de manière régulière. Elle n'a pas de paramètres en modes in, out ou in out. Je sais, vous vous dites : "pourtant, on a bien initialiser Verif_Altitude avec la variable altitude !". Mais cette variable n'a servi qu'à l'initialisation : la variable altitude valait 0 lorsque l'on a initialisé Verif_Altitude, donc son paramètre val vaudra 0, un point c'est tout. La modification de altitude ne modifiera pas pour autant le paramètre val. Comment résoudre ce problème ? Eh bien, il y a toujours les pointeurs !
with ada.text_io ; use ada.text_io ;
with ada.integer_text_io ; use ada.integer_text_io ;
with NT_Console ; use NT_Console ;
procedure Z123 is
task type Verif(var : access integer ; x : X_Pos ; y : Y_Pos) ;
task body Verif is
begin
loop
delay 0.1 ;
GOTO_XY(x,y) ;
put(var.all) ;
end loop ;
end Verif ;
altitude : aliased integer := 0 ;
Verif_Altitude : Verif(altitude'access,0,2) ;
vitesse : aliased integer := 0 ;
Verif_Vitesse : Verif(vitesse'access,25,2) ;
begin
...
Le pointeur ne change jamais de valeur, il contient toujours l'adresse de sa cible. Ainsi nous réglons ce problème. Mais il en reste encore un : l'affichage de l'altitude et de la vitesse est plutôt ... bizarre. Au lieu d'afficher deux valeurs, le programme en affiche 4 ! Pourquoi ? C'est ce que nous allons expliquer dans la prochaine partie.
Pour comprendre d'où viennent les bizarreries rencontrées lors de ces quelques essais, vous devez comprendre qu'un ordinateur n'est pas plus intelligent que vous : il ne peut pas faire deux choses en même temps. Alors comment fait-il pour donner cette impression ? Eh bien, il va vite. ^^
Plus sérieusement, imaginez que votre ordinateur doive faire tourner votre système d'exploitation (OS), votre navigateur internet, un antivirus et un jeu de foot. Il ne peut tout faire en même temps, il va donc exécuter l'OS pendant un laps de temps très court, puis mettre cette tâche en mémoire pour s'occuper rapidement du navigateur qu'il placera à son tour en mémoire. Il fera de même avec l'antivirus et votre jeu de foot. Que se passe-t-il ensuite ? Eh bien il sort votre OS de la mémoire pour l'exécuter à nouveau durant un court instant avant de le remettre en mémoire et d'en sortir le navigateur internet etc ... Cette méthode est appelée tourniquet ou round-robin en Anglais, ou encore balayage cyclique. C'est le principe du dessin animé : en faisant défiler rapidement des images statiques, on fait croire à un mouvement. Nous avons donc l'impression, pauvres humains que nous sommes, que l'ordinateur effectue plusieurs tâches en même temps.
Mais comment l'ordinateur sait-il quelle tâche il doit retirer de la mémoire ?
Vous vous souvenez des TAD ? Vous vous souvenez des files et du système FIFO ? Eh bien notre processeur utilise lui-aussi une file : une file de processus. A chaque fois, il pioche dans la file (dequeue), en sort un processus, le traite durant un certain laps de temps puis l'enfile à nouveau (requeue). Nous apporterons des nuances un peu plus tard.
Sections critiques
Ah d'accord ... mais je ne vois pas le rapport avec nos problèmes d'affichage. :(
C'est simple. Nos tâches sont (mal)traitées par le processeur de la même manière que les processus. Elles peuvent être interrompues à n'importe quel moment pour être remises en fin de file d'attente. Et pendant qu'elles attendent dans leur file, une autre tâche est traitée qui, elle, reprend son travail là où elle s'était arrêtée. L'idéal serait que les tâches s'alternent de la manière suivante :
Programme principal
Tâche Verif_Altitude
Tâche Verif_Vitesse
v=10 ; a = 10
-
-
-
placement du curseur colonne 0 afficher a = 10
-
-
-
placement du curseur colonne 25 afficher v = 10
v=15 ; a = 20
-
-
-
placement du curseur colonne 0 afficher a = 20
-
-
-
placement du curseur colonne 25 afficher v = 15
Mais cela ne se passe pas toujours aussi bien et l'enchaînement peut alors ressembler à ça :
Programme principal
Tâche Verif_Altitude
Tâche Verif_Vitesse
v=10 ; a = 10
-
-
-
placement du curseur colonne 0
-
-
-
placement du curseur colonne 25 afficher v = 10
v=15 ; a = 20
-
-
-
afficher a = 20 placement du curseur colonne 0 afficher a = 20
-
-
-
placement du curseur colonne 25 afficher v = 15
Quelle importance me direz-vous ? Eh bien le soucis qu'il va se poser, c'est que lorsque Verif_Altitude va afficher que a vaut 20, le curseur sera au-delà de la colonne 25 ! Il aura été placé en colonne 25, puis déplacé pour afficher v, mais n'aura pas été remis en colonne 0 avant d'afficher a. D'où l'apparition d'un troisième nombre. Un quatrième apparaîtra si ce phénomène se produit avec Verif_Vitesse.
Ce problème ne semble pas si grave, ce n'est jamais que de l'affichage ! Et pourtant, c'est le problème majeur du multitasking : le partage et l'accès aux ressource (ici l'écran). Prenons un autre exemple. Supposons que nous ayons créé un type tâche Task_Pilotage permettant de régler vitesse et altitude de la fusée Z123. Nous créeons deux tâches : Pilote et Copilote. Que va-t-il se passer si le pilote et le copilote décident tous deux en même temps de réduire un peu la vitesse ? La Z123 risque fort de freiner en plein ciel. :p Et cela n'a rien d'illogique : supposons que le la tâche pilote lise la valeur de la vitesse avant d'être interrompue. La tâche copilote prend le relai et décide de baisser la vitesse avant d'être à son tour interrompue. La tâche pilote reprend les commandes et affiche la valeur-vitesse lue précédemment. Sauf que la vitesse a entre-temps diminué. Et le pilote ne le saura pas. Conclusion : le pilote va ralentir, pensant sa vitesse trop haute, alors que le copilote s'en est déjà chargé. Résultat : "Houston, we've had a problem".
Lorsque vous concevez une tâche, vous devez donc réfléchir à ce que l'on appelle les sections critiques (et comme c'est le problème principal, vous DEVEZ ABSOLUMENT y penser). Elles sont faciles à repérer, ce sont les zones de code faisant intervenir des ressources partagées avec d'autres tâches.
Une solution directe : le Rendez-vous
Une première solution pour régler ce problème consiste à faire communiquer nos tâches entre elles directement afin qu'elles se synchronisent. Ainsi, il suffirait que la procédure principale (qui est une tâche elle aussi, je le rappelle), indique aux deux autres à quel moment elles peuvent intervenir sans risquer d'engendrer des comportements erratiques. La procédure principale va donc fixer un rendez-vous à ses sous-tâches (le terme anglais est tout simplement Rendez-vous, mais avec l'accent british ^^ ) : "tu interviendras à tel moment et tu feras telle chose".
Comment cela se traduit-il au niveau du traitement par le processeur ? Deux cas de figures se posent :
soit la procédure principale est en avance sur les tâches auxquelles elle demande d'intervenir. Auquel cas, la procédure principale sera mise en attente, le temps que les tâches aient terminé leur propres instructions et aient exécuté les instruction demandées par la procédure principale. Après quoi, tout reprendra comme à l'accoutumée.
soit la procédure principale est en retard sur ses tâches. Ces dernières ayant effectué leurs instructions propres seront mises en attente d'un appel venant de la procédure principale.
Les entrées
Les rendez-vous permettent donc à une tâche de recevoir des ordres de l'extérieur. Nous allons pouvoir concevoir des tâches qui ne seront plus hermétiques mais qui seront dotées de points d'entrée. Ainsi, notre type Task_Verif étant chargé d'afficher une valeur, nous allons créer une entrée appelée Affichage. Cette entrée devra être spécifiée dans la spécification du type tâche et se déclare à l'aide du mot-clé entry :
task type Task_Verif(var : access integer ; x : X_Pos ; y : Y_Pos) is
entry affichage ;
end Task_Verif ;
Cette entrée ne sera en définitive qu'une sorte de sous-procédure attendant le rendez-vous. Attention toutefois, la syntaxe du corps est différente :
task body Task_Verif is
begin
loop
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
end loop ;
end Task_Verif ;
Comprenez cette syntaxe de la manière suivante : "lorsque la tâche (task) accepte (accept) l'entrée (entry) affichage, elle doit faire (do) ceci". Maintenant, si vous lancez votre programme, vous vous rendrez compte que vos deux tâches ne font plus rien, et pour cause, elles attendent qu'un rendez-vous leur soit fixé via l'entrée Affichage. Nous allons donc modifier la procédure principale à son tour :
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
Verif_Vitesse.affichage ;
Verif_Altitude.affichage ;
end loop ;
Compilez, testez : tout fonctionne à merveille ! Les tâches exécutent correctement l'affichage puisqu'elles sont appelées à un moment précis et ne rendent la main qu'après avoir achevé leur entrée. Une remarque toutefois, il aurait été possible de "déparamétrer" notre type tâche pour paramétrer son entrée. Ce qui aurait évité l'usage d'un pointeur mais nous aurait obligé à spécifier les paramètres au sein de la procédure principale (et en bon fainéant, j'ai préféré la première solution ^^ ) :
task type Task_Verif is
entry affichage(var : integer ; x : X_Pos ; y : Y_Pos) ;
end Task_Verif ;
task body Task_Verif is
begin
loop
accept affichage(var : integer ; x : X_Pos ; y : Y_Pos) do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var) ;
end affichage ;
end loop ;
end Task_Verif ;
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
Verif_Vitesse.affichage(vitesse,25,2) ;
Verif_Altitude.affichage(altitude,0,2) ;
end loop ;
Les synchronisations sélectives
Améliorons encore nos tâches. Nous allons proposer désormais deux affichages : un normal et un d'urgence qui sera activé lorsque la vitesse dépassera 800 km/H et l'altitude 6000 m. Cette nouvelle entrée appelée simplement Urgence affichera la valeur en rouge. La spécification du type tâche est évidente :
task type Task_Verif(var : access integer ; x : X_Pos ; y : Y_Pos) is
entry affichage ;
entry urgence ;
end Task_Verif ;
Je veux bien, mais comment appeler cette entrée ? Si notre tâche attend l'entrée affichage, elle n'acceptera pas l'entrée Urgence et tout le monde va rester bloqué !
C'est bien vrai, la pire solution serait d'écrire le corps suivant :
task body Task_Verif is
begin
loop
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
accept urgence do
delay 0.01 ;
set_foreground(light_red) ;
GOTO_XY(x,y) ;
put(var.all) ;
set_foreground(gray) ;
end urgence ;
end loop ;
end Task_Verif ;
Au premier affichage, tout irait bien, mais ensuite, la tâche attendrait nécessairement un affichage d'urgence, ce qui ne risque pas d'arriver au décollage de la fusée. Il faut donc que la tâche propose une alternative, qu'elle se mette en attente d'une ou plusieurs entrées. C'est le rôle de l'instruction de sélection. Nous allons donc écrire :
task body Task_Verif is
begin
loop
select
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
or
accept urgence do
delay 0.01 ;
set_foreground(light_red) ;
GOTO_XY(x,y) ;
put(var.all) ;
set_foreground(gray) ;
end urgence ;
end select ;
end loop ;
end Task_Verif ;
Il ne reste plus qu'à modifier notre procédure principale :
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 5 ;
altitude := altitude + 5 ;
else altitude := altitude + 10 ;
end if ;
if vitesse <= 800
then Verif_Vitesse.affichage ;
else Verif_Vitesse.urgence ;
end if ;
if altitude <= 6000
then Verif_Altitude.affichage ;
else Verif_Altitude.urgence ;
end if ;
end loop ;
Gardes et compléments
Si l'instruction select n'est pas une instruction if, elle peut toutefois imposer certaines conditions : cesser d'attendre ou lever une exception si l'attente devient trop longue, n'accepter une entrée que sous certaines conditions ... Le but recherché n'est pas alors de faire un tri parmi les entrées mais d'éviter des blocages (on parle plus exactement de famine), des levées d'exceptions ou des comportements non désirés. Ces conditions apportées à notre attente sélective sont appelées gardes.
Garde conditionnelle
Commençons par imposer une condition toute simple : l'entrée urgence ne pourra être activée que pour une valeur strictement positive : on ne va pas tirer la sonnette d'alarme pour un appareil à l'arrêt. Cela se fera tout simplement avec l'instruction when :
task body Task_Verif is
begin
loop
select
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
or when var.all > 0
accept urgence do
delay 0.01 ;
set_foreground(light_red) ;
GOTO_XY(x,y) ;
put(var.all) ;
set_foreground(gray) ;
end urgence ;
end select ;
end loop ;
end Task_Verif ;
Garde temporelle
Mais que se passera-t-il si la procédure principale demande à employer l'entrée urgence avec une variable nulle ? Ça ne risque pas de bloquer ?
Ce n'est pas que ça risque de bloquer ... ça VA bloquer à coup sûr. Pour éviter tout phénomène d'interblocage, il est possible d'ajouter une garde prenant en compte le temps d'attente : au delà de 3 secondes d'attente, on exécute une entrée particulière (par exemple, on arrête la tâche proprement). Pour définir le temps d'attente, nous allons réutiliser l'instruction delay.
task body Task_Verif is
begin
loop
select
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
or when var.all > 0
accept urgence do
delay 0.01 ;
set_foreground(light_red) ;
GOTO_XY(x,y) ;
put(var.all) ;
set_foreground(gray) ;
end urgence ;
or delay 3.0 ;
exit ;
end select ;
end loop ;
end Task_Verif ;
A ce sujet, il est possible d'utiliser l'instruction else plutôt que or. Par exemple si nous écrivons le code ci-dessous (qui déclenchera une exception TASKING_ERROR) :
Les tâches de type Task_Verif regarderons si une demande d'affichage ou d'affichage d'urgence a été demandé. Si tel n'est pas le cas, alors (else) elles sortiront de la boucle avec exit. Cela revient à écrire une instruction or delay 0.0 à la différence qu'avec else, le temps durant lequel la tâche est inactive en mémoire n'est pas décompté.
Instruction de terminaison
Plutôt que d'avorter les tâches durant notre programme principal, pourquoi ne pas faire en sorte que celles-ci mettent fin elle-même proprement à leur exécution ? Cela est rendu possible avec l'instruction terminate. Je vous conseille donc, à chaque attente sélective, d'ajouter une clause terminate, cela évitera que vos programmes n'aient pas de fin parce que vous avez négligé d'avorter toutes vos tâches :
task body Task_Verif is
begin
loop
select
accept affichage do
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
or when var.all > 0
accept urgence do
delay 0.01 ;
set_foreground(light_red) ;
GOTO_XY(x,y) ;
put(var.all) ;
set_foreground(gray) ;
end urgence ;
or
terminate ;
end select ;
end loop ;
end Task_Verif ;
Une seconde façon d'éviter tout problème sur les ressources lié au parallélisme est de s'assurer que l'accès à ces ressources soit protégé et que jamais deux tâches ne puissent y accéder en même temps. Avant de pouvoir lire ou écrire une ressource partagée, toute tâche devra demander une autorisation au programme principal. Une fois le travail d'écriture ou de lecture effectué, la tâche "rendra" son autorisation, libérant ainsi l'accès à la ressource pour d'autres tâches. Il s'agit du principe d'exclusion mutuelle, aussi appelé Mutex. La Mutex peut bien entendu être réalisée en Ada grâce aux types protégés ou protected.
Il s'agit d'un format de type particulier dans lequel il est possible de déclarer les variables protégées, mais aussi des entrées, des fonctions ou des procédures ainsi qu'une partie privée. Les fonctions, procédures et entrées déclarées dans un type protégé sont toutes en exclusion mutuelle. De plus, les entrées peuvent être bloquantes car elles doivent être munies d'une garde. Les fonctions seront généralement utilisées pour lire les données protégées, les procédures et entrées pour les écrire.
Pour mieux comprendre, reprenons l'exemple de notre affichage de fusée à la base. Plus d'entrées, plus de communication entre notre programme principal et les tâches. Notre procédure Z123 se résumera donc à ceci :
with ada.text_io ; use ada.text_io ;
with ada.integer_text_io ; use ada.integer_text_io ;
with NT_Console ; use NT_Console ;
procedure Z123 is
-------------------------------------------
--Nous déclarerons ici notre type protégé--
-------------------------------------------
-----------------------------------------
--Nous déclarerons ici notre type tâche--
-----------------------------------------
begin
GOTO_XY(0,0) ; put("3 ... 2 ... 1 ... Decollage !") ;
GOTO_XY(0,1) ; put("Altitude (en m) ") ;
GOTO_XY(25,1) ; put("Vitesse (en km/H) ") ;
while altitude < 10_000 loop
delay 0.01 ;
if altitude < 1000
then vitesse := vitesse + 10 ;
altitude := altitude + 10 ;
else altitude := altitude + 50 ;
end if ;
end loop ;
abort Verif_Vitesse ;
abort Verif_Altitude ;
GOTO_XY(0,3) ; put_line("Decollage reussi !") ;
end Z123 ;
Notre type tâche sera lui aussi simplifié : plus d'attente sélective, plus d'entrées, juste une affichage à un endroit précis :
--notre type tâche
task type Verif(var : access integer ; x : X_Pos ; y : Y_Pos) ;
task body Verif is
begin
loop
delay 0.01 ;
GOTO_XY(x,y) ;
put(var.all) ;
end loop ;
end Verif ;
--et nos variables
altitude : aliased integer := 0 ;
Verif_Altitude : Verif(altitude'access,0,2) ;
vitesse : aliased integer := 0 ;
Verif_Vitesse : Verif(vitesse'access,25,2) ;
Nous allons ensuite pouvoir déclarer un type protégé, que nous appellerons T_Ecran et une variable Ecran de type T_Ecran. Voici un schéma de ce fameux type :
--D'abord les spécifications
protected type T_Ecran(paramètres éventuels) is
entry truc ;
procedure bidule ;
function machin ;
private
MaVariable : UnTypeDeVariable ;
--autres déclarations privées
end T_Ecran ;
--Ensuite le corps du type
protected body T_Ecran is
entry truc when une_condition is
begin
...
end truc ;
procedure bidule is
begin
...
end bidule ;
function machin is
begin
...
return ...
end machin ;
end T_Ecran ;
--Enfin, notre objet protégé
Ecran : T_Ecran(paramètres) ;
Pourquoi tu n'as pas détaillé ton type T_Ecran ? Je dois tout compléter moi-même ?
Non, je compte bien détailler tout cela sans trop tarder, je me contentais juste de vous présenter un plan de la déclaration d'un type protégé. Car il y a plusieurs façons d'utiliser ces types protégés, chaque façon dispose de ses propres avantages et inconvénients, mais aucune n'est parfaite. Je ne compte pas détailler toutes les méthodes possibles et imaginables ; je préfère me concentrer sur deux méthodes parmi les plus connues : les sémaphores et les moniteurs. La programmation concurrente est un vaste pan de l'informatique, passionnant mais que ce tutoriel n'a pas vocation à couvrir. :)
Les sémaphores
Un peu d'Histoire
Le principe des sémaphores fut inventé par le mathématicien et informaticien néerlandais Edsger Wybe Dijkstra en 1968. Mort en 2002, Dijkstra aura auparavant marqué la seconde moitié du XXème siècle par le rôle qu'il a joué dans le développement de l'informatique en temps que science.
Inventeur des sémaphores, Dijkstra s'intéressa à la programmation concurrente (nous reviendrons plus tard sur son apport) ainsi qu'à l'algorithmique. Un célèbre algorithme publié en 1959 (notamment étudié en filière économique et social en France) porte son nom : l'algorithme de Dijkstra permet de déterminer un plus court chemin en théorie des graphes (si cela ne vous parle pas, dites-vous que son algorithme permet à votre GPS de connaître la route la plus courte ou la moins chère entre Paris et Lyon).
Il apporta également sa contribution au développement du langage de programmation Algol. Ce langage, très structuré en comparaison des langages de l'époque, permettant la récursivité, donnera par la suite naissance au langage Pascal, langage dont s'inspirera le Français Jean Ichbiah pour élaborer le langage Ada à la demande du département de la Défense américain. Le langage Ada est donc l'un des héritiers de ce grand Monsieur (ce qui explique en bonne partie sa structure claire et sa rigueur).
De quoi parle-t-on ?
Un sémaphore est, dans la vie courante, un avertisseur. Si je vous parle des feux de signalisation des trains, vous savez, ceux qui font ding-ding-ding ... eh bien ce sont des sémaphores. Ils avertissent de la présence ou non d'un train. De même, en Espagnol comme en Italien, un feu tricolore est appelé semáforo ou semaforo. Bref en informatique, le but d'un sémaphore sera de bloquer les tâches avant une section critique de manière à n'en laisser passer qu'un certain nombre à la fois. Les sémaphores se chargeront de compter le nombre d'accès restants à une ressource (pour notre écran, seule une tâche pourra y accéder) et de jouer le rôle de feu tricolore. Lorsqu'une tâche arrivera devant une section critique, le sémaphore regardera le nombre de places libres :
Si ce nombre vaut 0, alors la tâche est mise en attente.
Sinon, le sémaphore se contentera de décrémenter son compteur de places libres.
Une fois que la tâche aura effectué son travail en section critique, le sémaphore n'aura plus qu'à incrémenter son compteur de places libres afin de libérer l'accès à d'autres tâches en attente. La première opération est généralement notée P. C'est l'initiale du mot Proberen qui signifie tester en néerlandais. La seconde opération est généralement notée V pour VVerhogen (incrémenter). Comme je me doute que, hormis les tulipes et les moulins, vous ne connaissez pas grand chose aux Pays-Bas, voici une petite astuce pour retenir les noms de ces deux opérations : P est également l'initiale de "PPuis-je ? " ou de Prendre et V l'initiale de "VVas-y ! " ou Vendre. Compris ? Alors passons à la mise en œuvre.
Mise en œuvre en Ada
Si nous souhaitons réaliser un sémaphore, notre type protégé T_Ecran devra donc contenir une variable privée compteur (il serait inutile et dangereux que quelqu'un puisse y accéder sans employer les opérations P et V). Nous l'initialiserons automatiquement à 1 (car seulement une seule tâche à la fois pourra accéder à l'écran), mais il est bien sûr possible de l'initialiser via un paramètre. L'opération P devra être réalisée par une entrée pour permettre la mise en attente des tâches. Pour ne pas être mise en attente, il suffira que le compteur n'indique pas zéros places restantes. Il n'est toutefois pas nécessaire que V soit une entrée mais plutôt une simple procédure. En effet, il n'y a aucun besoin de mettre en attente une tâche qui souhaite libérer une ressource et l'opération V n'a besoin d'aucune précondition. Voici donc ce que donnerait notre type protégé :
--les spécifications
protected type T_Ecran is
entry P ;
procedure V ;
private
compteur : integer := 1 ;
end T_Ecran ;
--le corps
protected body T_Ecran is
entry P when compteur > 0 is --une condition DOIT être spécifiée
begin
compteur := compteur - 1 ;
end P ;
procedure V is
begin
compteur := compteur + 1 ;
end V ;
end T_Ecran ;
--la variable protégée
Ecran : T_Ecran ;
Désormais, nous n'avons plus qu'à revoir le corps de notre type tâche Task_Verif afin de positionner notre sémaphore autour de la section critique :
task body Verif is
begin
loop
delay 0.01 ;
Ecran.P ; --Puis-je accéder à la section critique ? Juste un petit moment, svp.
GOTO_XY(x,y) ;
put(var.all) ;
Ecran.V ; --Tu as fini ? Alors Vas-y, sors de la section critique et continue !
end loop ;
end Verif ;
Avantages et inconvénients
L'avantage des sémaphores est avant-tout leur simplicité : simple à comprendre et donc simple à mettre en œuvre. Et ce n'est pas un atout négligeable dans un domaine aussi compliqué que la programmation concurrente. Qui plus est, les sémaphores sont peu coûteux en ressources comme le temps processeur.
L'inconvénient est que si un programmeur oublie malencontreusement de libérer une ressource avec l'opération V, celle-ci deviendra inaccessible, conduisant à ce que l'on appelle un interblocage. De même, la ressource en elle-même n'est pas protégée, un mauvais programmeur oubliant d'utiliser l'entrée P réalisera un programme sans mutex qui amènera très certainement à de sacrées surprises. Autre inconvénient, la première tâche arrivant au sémaphore s'empare de la ressource partagée et bloque donc les autres : aucune priorité n'est prise en compte. Les sémaphores sont donc un outil simple, pratique mais qui ne répond pas à toutes les attentes. Venons-en donc aux moniteurs.
Les moniteurs
Encore un peu d'Histoire
Les moniteurs, autre outil de synchronisation, furent quant à eux inventés par le britannique Sir Charles Antony Richard Hoare en 1974. Vous avez déjà eu affaire à cet éminent professeur, car il est l'inventeur du fameux Quick Sort, l'algorithme de tri rapide que nous avions étudier en début de partie IV avec tant d'autres.
Mais ce n'est pas tout. Hoare a également élaboré toute une logique, la logique de Hoare, qui permet de raisonner sur les programmes et algorithmes d'une façon très mathématique, permettant ainsi de traquer d'éventuelles erreurs ou de prouver qu'un algorithme fait effectivement ce qu'il est attendu qu'il fasse.
Eh oui, l'informatique est une science, ne l'oubliez pas. Et comme le disait Hoare : "Il y a deux manières pour construire un logiciel : ou bien on le fait si simple qu’il n’y a à l’évidence pas de défauts, ou bien on le fait si compliqué qu’aucun défaut n’est évident. La première méthode est de loin la plus difficile."
Principe du moniteur
Le principe du moniteur est de protéger les ressources partagées en encapsulant les sections critiques de manière à ce que les tâches n'y aient plus accès. On rejoint l'idée de l'encapsulation : les données brutes ne sont plus accessibles, on fournit par contre les méthodes pour la manipuler. Mais, toujours pour éviter des accès multiples à cette ressource, on ajoute à ces méthodes quelques conditions, ce que l'on appelle un verrou de mutex.
Les moniteurs permettent ainsi une gestion de plus haut niveau que les sémaphores. D'autant plus que le langage Ada, via ses types protected gèrera lui-même les mises en attente ou les réveils de tâches. Notre type T_Ecran, s'il est conçu tel un moniteur, ressemblera à ceci :
protected type T_Ecran is
entry affichage(var : access integer ; x : X_Pos ; y : Y_Pos) ;
private
compteur : integer := 1 ;
end T_Ecran ;
protected body T_Ecran is
entry affichage(var : access integer ; x : X_Pos ; y : Y_Pos) when compteur > 0 is
begin
compteur := compteur - 1 ;
GOTO_XY(x,y) ;
put(var.all) ;
compteur := compteur + 1 ;
end affichage ;
end T_Ecran ;
Ecran : T_Ecran ;
Facile n'est-ce pas ? Et attendez de voir ce que devient notre type tâche :
task type Verif(var : access integer ; x : X_Pos ; y : Y_Pos) ;
task body Verif is
begin
loop
delay 0.01 ;
Ecran.affichage(var,x,y) ;
end loop ;
end Verif ;
Cela devient extrêmement simple, non ? Et pourtant les moniteurs sont normalement plus complexes à comprendre que les sémaphores car il faut gérer des signaux de mise en attente ou de réactivation de tâches. Heureusement pour nous, le type protected du langage Ada agit à la façon d'un moniteur ce qui nous décharge de bien des tracas en réglant bon nombre de soucis de sécurité. Et nous pouvons encore améliorer ce code en nous débarrassant de la variable compteur à incrémenter/décrémenter. Nous allons modifier la garde de l'entrée Affichage pour ne nous concentrer que sur le nombre de tâches en attente. Nous allons pour cela utiliser l'attribut 'count :
protected type T_Ecran is
entry affichage(var : access integer ; x : X_Pos ; y : Y_Pos) ;
end T_Ecran ;
protected body T_Ecran is
entry affichage(var : access integer ; x : X_Pos ; y : Y_Pos) when affichage'count = 0 is
begin
GOTO_XY(x,y) ;
put(var.all) ;
end affichage ;
end T_Ecran ;
Ecran : T_Ecran ;
Il est temps désormais de compléter ce que nous avons dit sur le tourniquet. Vous vous souvenez, je vous ai expliqué comment l'ordinateur faisait pour gérer soit-disant "en même temps" un système d'exploitation (OS), un navigateur internet, un antivirus et un jeu de foot. Je vous avais expliqué qu'il faisait tourner l'OS pendant quelques millisecondes avant de le placer dans une file d'attente en mémoire, file d'attente gérée sur le mode FIFO (First In First Out). Avant d'avoir de nouveau accès au processeur, votre OS devrait donc attendre que celui-ci ait traité le navigateur internet, puis l'antivirus et enfin le jeu de foot.
Eh bien je vous ai dit des bêtises (pour la bonne cause rassurez-vous). Car il est évident que tous ces logiciels ne fonctionneraient pas sans le système d'exploitation. Celui-ci est primordial au bon fonctionnement de l'ordinateur, contrairement à l'antivirus qui, la plupart du temps, n'a rien de particulier à faire. Il n'est donc pas judicieux que l'antivirus et l'OS aient le même temps d'accès au processeur alors qu'il n'ont pas la même charge de travail. On dit qu'ils n'ont pas la même priorité. C'est pourquoi nos ordinateurs utilisent plutôt un système de tourniquet à priorité.
Comment faire pour que le système d'exploitation soit prioritaire puisqu'on utilise une file et donc le principe FIFO ?
L'idée est en fait d'utiliser plusieurs tourniquets et non un seul. On attribue un tourniquet à chaque niveau de priorité. Reprenons notre exemple précédent avec trois niveaux de priorité : 0 pour l'antivirus, 1 pour le jeu de foot et le navigateur internet, 2 pour le système d'exploitation. Les processus de priorité 2 (en rouge sur le schéma) obtiendront 50% du temps processeur, ceux de priorité 1 (en orange) auront 30% et ceux de priorité 0 (en vert) auront 20%. Ce qui nous donne le schéma suivant :
Un nouveau pragma
La priorité d'une tâche peut être fixée de manière statique grâce à une directive de compilateur. Vous vous souvenez ? Les fameux pragma. Nous ferons appel ici le pragma priority. Celui-ci permet de fixer la priorité d'une tâche de manière statique : nous définirons la priorité lors des spécifications de la tâche une fois pour toute. Le langage Ada accepte des niveaux de priorités allant de 0 à 30, 30 étant le niveau de priorité maximal. Nous allons également faire appel à un nouveau package : System. Attention ! Pas Ada.system, mais System tout court ! Ce package nous permet d'utiliser un type Priority de type Integer, ainsi qu'une constante Default_Priority qui définit une priorité par défaut de 15.
WITH System ; USE System ;
...
TASK TYPE T_Tache(P : Priority) IS
PRAGMA Priority(P) ;
END T_Tache ;
TASK BODY T_Tache IS
...
END T_Tache ;
Le pragma priority peut également être utilisé avec la procédure principale. Par défaut, une tâche hérite de la priorité de la tâche qui l'a appelée. C'est à dire que si une tâche de priorité 10 déclare des sous-tâches, celles-ci auront une priorité de 10, à moins d'utiliser le pragma priority.
Et il n'est pas possible de modifier la priorité d'une tâche en cours d'exécution ?
Bien sûr que si. Prenez l'exemple dont nous parlions précédemment. L'antivirus n'est pas un processus prioritaire la plupart du temps ... sauf lorsque vous tentez d'accéder à une page web ou à un fichier. L'antivirus commence alors son analyse et il est préférable que cette analyse se fasse rapidement afin de ne pas bloquer ou ralentir les processus ayant besoin de ladite page web ou dudit fichier. Pour effectuer tout changement de priorité, vous devrez faire appel au package Ada.Dynamic_Priorities. Celui-ci définit deux méthodes dont voici les spécifications simplifiées (pour plus de précision, le package porte le nom a-dynpri.ads) :
procedure Set_Priority(P : Priority;
T : Task_Id := Current_Task);
function Get_Priority(T : Task_Id := Current_Task)
return Priority;
La procédure Set_priority permet de fixer dynamiquement la priorité de la tâche P (notez que si vous ne renseignez pas le paramètre P, alors Set_priority s'applique par défaut à la tâche qui l'appelle). La fonction Get_priority permet quant à elle de récupérer la priorité d'une tâche (là encore, si le paramètre n'est pas renseigné, c'est la tâche en cours qui est utilisée). Toutefois, n'abusez pas des changements de priorité : ce sont des opérations lourdes. Changer régulièrement la priorité d'une tâche pour l'accélérer peut ainsi avoir comme conséquence improbable de la ralentir.
Un dernier pragma pour la route
Tant que nous parlons des directives de compilateur, en voici une dernière : le pragma storage_size. Celui-ci permet de définir la taille (en octets) de l'espace mémoire alloué à une tâche. Exemple :
TASK TYPE T_Tache(P : Priority) IS
PRAGMA Storage_Size(500 * 2**10) ;
END T_Tache ;
Chaque tâche de type T_Tache aura ainsi droit à une taille de octets soit ko. Si votre ordinateur ne peut allouer 500 ko lors de la déclaration de la tâche, une exception STORAGE_ERROR sera levée.
Quand la programmation orientée objet rejoint la programmation concurrente
Interface, Task et Protected
Poussons le vice toujours plus loin. Vous avez remarqué que pour appeler l'entrée d'un type protégé, il fallait utiliser une écriture pointée : Objet_Protege.Entree. Cela rappelle la POO non ? ^^ Eh bien sachez qu'il est possible de concevoir vos tâches ou vos types protégés "façon objet". Ada nous permet ainsi de faire appel aux notions d'héritage ou d'abstraction comme nous le faisions avec des types étiquetés. Pour déclarer un type tâche ou protégé qui puisse être dérivé, nous devrons le définir comme interface, ce qui nous donnerait ainsi :
TYPE T_Tache_Mere IS TASK INTERFACE ;
TYPE T_Protege_Pere IS PROTECTED INTERFACE ;
L'implémentation se fait comme nous en avions l'habitude :
--------------------------
-- Types interfaces --
--------------------------
TYPE T_Tache_Mere1 IS TASK INTERFACE ;
TYPE T_Tache_Mere2 IS TASK INTERFACE ;
-----------------------
-- Types dérivés --
-----------------------
TYPE T_Tache_Fille1 IS NEW T_Tache_Mere1 AND T_Tache_Mere2 ;
-- OU
TYPE T_Tache_Fille2 IS NEW T_Tache_Mere1 AND T_Tache_Mere2 WITH
... --écrire ici les différentes entrées de la tâche fille
END T_Tache_Fille2 ;
Les types tâches filles (mais c'est également valables pour des types protégés fils) héritent ainsi de toutes les méthodes (abstraites nécessairement) s'appliquant aux types tâches mères.
Le type synchronized
Mais le langage Ada pousse le vice encore plus loin en termes d'abstraction ! Il est possible de créer un type racine interface sans savoir s'il sera implémenté par un type tâche ou un type protégé. Il s'agit du type syncronized ! Un type synchronisé peut soit être une tâche soit un type protégé. Il est donc nécessairement abstrait, et le mot syncronized ne s'utilisera donc jamais sans le mot interface :
TYPE T_Synchro IS SYNCHRONIZED INTERFACE ;
Il pourra donc être implémenté de différentes façons, permettant par polymorphisme d'utiliser une même méthode pour des tâches ou des types protégés :
TYPE T_Tache_Fille IS NEW T_Tache_Mere AND T_Synchro ;
TYPE T_Protege_Fils IS NEW T_Protege_Pere AND T_Synchro ;
Nous avons jusque là aborder le multitasking sous un angle ludique. Mais tous les cas de parallélisme ne sont pas aussi simples. Pour nous entraîner, nous allons maintenant résoudre trois problèmes classiques de programmation concurrente : le problème des producteurs et consommateurs, le problème des lecteurs et écrivains et le dîner des philosophes. Pour information, les deux derniers sont des problèmes qui furent à la fois posés et résolus par Edsger Dijkstra.
Modèle des producteurs et consommateurs
Énoncé
Le modèle producteur-consommateur, ou problème du buffer à capacité limitée, est un cas typique : certaines tâches créent des documents, des données qui sont stockées en mémoire en attendant que d'autres tâches viennent les utiliser. C'est typiquement ce qui se passe avec une imprimante : plusieurs utilisateurs peuvent lancer une impression, les documents sont alors placés dans une file d'attente appelée le spool jusqu'à ce que l'imprimante ait fini son travail en cours et puisse les traiter, les uns après les autres. Le problème qui se pose, c'est que l'espace-mémoire dédié à ce stockage temporaire que l'on nomme tampon ou buffer, a une capacité limitée et qu'il est en accès partagé.
Et qui dit ressource partagée dit problème de synchronisation. Voici typiquement ce qu'il faudrait éviter, on a indiqué par "Time Out" les coupures opérées par le tourniquet pour passer d'une tâche à l'autre :
Producteur
Consommateur
Accès au tampon Incrémentation de la taille du tampon (taille vaut 1) Time Out
-
-
Taille = 1 donc accès au tampon Décrémentation de la taille du tampon (taille vaut 0)
Sortie du tampon Time Out
Ajout de données Sortie du tampon
-
On voit apparaître une erreur grave : lorsque le consommateur accède au tampon, la taille de ce dernier vaut théoriquement 1, sauf que ce dernier est encore vide dans les faits. Le retrait de données entraînera automatiquement une erreur. Nous devrons donc protéger le tampon, et j'ai décidé que nous allions le faire grâce à un moniteur.
Donc votre mission, si vous l'accepter, :soleil: sera de créer un type tâche Producteur et un type tâche Consommateur. Le premier ajoutera dans un conteneur (doubly_linked_list, vector, file à vous de choisir) des caractères tirés au hasard. Attention, la taille de ce conteneur devra être limitée : imaginez un agriculteur qui rangerait 5000 bottes de foin dans un hangar prévu pour 2000, ce n'est pas possible. Le buffer est limité ! Le second type de tâche retirera les caractères de votre conteneur, à condition bien sûr qu'il ne soit pas vide. Pour être certain que les caractères ont bien été retirés, chaque consommateur enregistrera son caractère dans un fichier spécifique. Tout cela ne durera qu'un certain temps, disons quelques secondes. Compris ? Alors à vous de jouer.
Solution
Voici une solution possible au problème des producteurs-consommateurs :
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Calendar ; USE Ada.Calendar ;
with ada.Containers.Doubly_Linked_Lists ;
WITH Ada.Numerics.Discrete_Random ;
procedure prod_cons is
--PACKAGES
SUBTYPE Chara IS Character RANGE 'a'..'z' ;
PACKAGE P_Lists IS NEW Ada.Containers.Doubly_Linked_Lists(Chara) ;
USE P_Lists ;
PACKAGE P_Random IS NEW Ada.Numerics.Discrete_Random(Chara) ;
USE P_Random ;
--TYPE T_STOCK--
PROTECTED TYPE T_Stock(Stock_Max_Size : integer := 10) IS
ENTRY Deposer(C : Character) ;
ENTRY Retirer(name : string) ;
PRIVATE
Stock_Size : Integer := 0 ;
Stock : List ;
END T_Stock ;
PROTECTED BODY T_Stock IS
ENTRY Deposer(C : Character) WHEN Stock_Size < Stock_Max_Size IS
BEGIN
Stock_Size := Stock_Size +1 ;
Stock.append(C) ;
END Deposer ;
ENTRY Retirer(Name : String) WHEN Stock_Size >0 IS
F : File_Type ;
c : character ;
BEGIN
open(F,Append_File,name) ;
C := Stock.First_Element ;
Stock.delete_first ;
Stock_Size := Stock_Size - 1 ;
put(F,c) ;
close(F) ;
END Retirer ;
END T_Stock ;
Hangar : T_Stock ;
--TYPE PRODUCTEUR--
TASK TYPE T_Prod ;
TASK BODY T_Prod IS
G : Generator ;
c : character ;
BEGIN
reset(g) ;
LOOP
c := random(g) ;
Hangar.Deposer(C) ;
put(c) ;
END LOOP ;
END T_Prod ;
P1, P2 : T_Prod ;
--TYPE CONSOMMATEUR--
TASK TYPE T_Cons(nb: integer) ;
TASK BODY T_Cons IS
F : File_Type ;
name : string := "docs/conso" & integer'image(nb) & ".txt" ;
BEGIN
Create(F,In_File,name) ;
Close(F) ;
LOOP
Hangar.retirer(name) ;
END LOOP ;
END T_Cons ;
C1 : T_Cons(1) ;
C2 : T_Cons(2) ;
C3 : T_Cons(3) ;
--VARIABLES POUR PROGRAMME PRINCIPAL--
D : Duration := 4.0 ;
T : Time := clock ;
BEGIN
WHILE Clock < T + D LOOP
NULL ;
END LOOP ;
ABORT P1 ;
ABORT P2 ;
ABORT C1 ;
ABORT C2 ;
ABORT C3 ;
end prod_cons ;
Modèle des lecteurs et rédacteurs
Enoncé
Second cas typique, le modèle lecteurs/rédacteurs. Vous disposez d'un unique fichier (par exemple un annuaire contenant des numéros de téléphone à 10 chiffres) et plusieurs tâches tentent d'y accéder "en même temps". Certaines pour lire ce fichier (ce sont les lecteurs), d'autres pour y écrire de nouveaux numéros (ce sont les ... suspense ... rédacteurs). Imaginez les ennuis si un vendeur de téléphone tente de vous attribuer un numéro de portable alors même qu'un de ses collègues à l'autre bout du magasin (ou chez un concurrent) est en train de modifier la base de données. Votre vendeur pourrait vous attribuer un faux numéro composé à partir de deux numéros, ou vous attribuer un numéro que son collègue vient tout juste d'attribuer ! Bref, il faut protéger le fichier.
Les règles sont simples : il est possible à autant de personnes que possible de lire le fichier. En revanche, seule une personne à la fois peut y écrire et bien sûr il est impossible de lire et d'écrire en même temps. De plus, si deux tâches tentent d'accéder au fichier, un lecteur et un rédacteur, alors c'est le rédacteur qui aura la priorité ou, pour être plus clair, il ne devra pas être interrompu par un lecteur.
Ce problème avait été posé et résolu par E. Dijkstra. La solution qu'il proposait faisait appel aux sémaphores, et nous allons donc nous aussi faire appel aux sémaphores. Pour éviter tout problème sur l'accès au fichier, nous aurons besoin de deux entrées P (P_lecture et P_écriture), de deux procédures V (V_lecture et V_écriture) et donc de deux compteurs (Nb_lecteur et Nb_redacteur) . Cela nous fait ainsi quatre appels possibles. Pour centraliser et clarifier tout cela, je vous propose de ne plus avoir que deux appels (P et V) auxquels nous fournirons en paramètre le type d'accès désiré (lecture ou écriture). Nous utiliserons ainsi un nouveau mot-clé : requeue. Celui-ci a pour effet et ré-enfiler la tâche dans la liste d'attente d'une nouvelle tâche. Ainsi, l'entrée P, donnerait quelque-chose comme ceci :
entry P(acces : T_acces) is
begin
IF Acces = Lecture
THEN REQUEUE P_Lecture ;
ELSE REQUEUE P_Ecriture ;
END IF;
END P ;
Votre mission est donc de créer des tâches qui liront un fichier contenant une liste de numéros de téléphone pour en afficher une dizaine à l'écran. Vous créerez également des tâches qui enrichiront le fichier. Restera ensuite à créer un type protégé T_Fichier pour gérer les accès et les priorités. Le code fourni en solution propose un générateur de numéros de téléphone à 10 chiffres.
Solution
Le code proposé protège l'accès au fichier (ce qui était le but de l'exercice) mais pas l'accès à l'écran pour ne pas alourdir la solution.
WITH Ada.Text_IO ; USE Ada.Text_IO ;
with ada.Numerics.Discrete_Random ;
PROCEDURE Lecteur_Redacteur IS
SUBTYPE Chiffre IS Integer RANGE 0..9 ;
PACKAGE P_Random IS NEW Ada.Numerics.Discrete_Random(Chiffre) ;
USE P_Random ;
g : generator ;
-------------------------------
-- GENERATION DU FICHIER --
-------------------------------
procedure generate_file(name : string) is
F : File_Type ;
BEGIN
Create(F,out_File,"./docs/" & name & ".txt") ;
reset(g) ;
FOR J IN 1..20 LOOP
put(f,'0') ;
FOR I IN 1..9 LOOP
put(f,integer'image(Random(G))(2)) ;
END LOOP ;
new_line(f) ;
end loop ;
close(f) ;
END Generate_File ;
-------------------------------------
-- LECTURE-ECRITURE DU FICHIER --
-------------------------------------
PROCEDURE Read(Name : String ; line : integer := 1) IS
F : File_type ;
BEGIN
Open(F,In_File,"./docs/" & Name & ".txt") ;
IF Line > 1
THEN Skip_Line(F,Count(Line-1)) ;
END IF;
Put_Line(Get_Line(F)) ;
close(f) ;
END Read ;
PROCEDURE Write(Name : String) IS
F : File_Type ;
BEGIN
open(F,append_File,"./docs/" & name & ".txt") ;
put(f,'0') ;
FOR I IN 1..9 LOOP
put(f,integer'image(Random(G))(2)) ;
END LOOP ;
new_line(f) ;
close(f) ;
END Write ;
----------------------
-- TYPE PROTEGE --
----------------------
TYPE T_Acces IS (Lecture,Ecriture) ;
PROTECTED TYPE T_Fichier IS
ENTRY P(acces : T_acces) ;
PROCEDURE V(acces : T_acces) ;
PRIVATE
ENTRY P_Lecture ;
ENTRY P_Ecriture ;
PROCEDURE V_Lecture ;
PROCEDURE V_Ecriture ;
Nb_Lecteur, Nb_Redacteur : Integer := 0 ;
ecriture_en_cours : boolean := false ;
END T_Fichier ;
PROTECTED BODY T_Fichier IS
ENTRY P(acces : T_acces) WHEN not ecriture_en_cours IS
BEGIN
IF Acces = Lecture
THEN REQUEUE P_Lecture ;
ELSE Ecriture_En_Cours := True ;
REQUEUE P_Ecriture ;
END IF;
END P ;
PROCEDURE V(Acces : T_Acces) IS
BEGIN
IF Acces = Lecture
THEN V_Lecture ;
ELSE V_Ecriture ;
Ecriture_En_Cours := False ;
END IF;
END V ;
ENTRY P_Lecture WHEN Nb_Redacteur = 0 IS
BEGIN
Nb_Lecteur := Nb_Lecteur + 1 ;
END P_Lecture ;
ENTRY P_Ecriture WHEN Nb_Redacteur = 0 AND Nb_Lecteur = 0 IS
BEGIN
Nb_Redacteur := 1 ;
END P_Ecriture ;
PROCEDURE V_Lecture IS
BEGIN
Nb_Lecteur := Nb_Lecteur - 1 ;
END V_Lecture ;
PROCEDURE V_Ecriture IS
BEGIN
Nb_Redacteur := 0 ;
END V_Ecriture ;
END T_Fichier;
Fichier : T_Fichier ;
File_Name : String := "numeros" ;
----------------------
-- TYPES TACHES --
----------------------
TASK TYPE T_Lecteur ;
TASK BODY T_Lecteur IS
BEGIN
FOR I IN 1..10 LOOP
Fichier.P(lecture) ;
DELAY 0.5 ;
Read(File_Name,I) ;
Fichier.V(lecture) ;
END LOOP ;
END T_Lecteur ;
L1,L2 : T_Lecteur ;
TASK TYPE T_Redacteur ;
TASK BODY T_Redacteur IS
BEGIN
FOR I IN 1..10 LOOP
Fichier.P(ecriture) ;
Write(File_Name) ;
Fichier.V(ecriture) ;
END LOOP ;
END T_Redacteur ;
R1, R2 : T_Redacteur ;
BEGIN
--generate_file(File_Name) ;
null ;
END Lecteur_Redacteur ;
Le dîner des philosophes
Enoncé
Le dernier problème, le dîner des philosophes, est un grand classique de programmation concurrente. Inventé lui aussi par E.Dijkstra, ce problème d'algorithmique met en avant les problèmes d'interblocage et d'ordonnancement. Le problème est le suivant : cinq philosophes se réunissent autour d'une table ronde pour manger et disserter. Chacun dispose d'une assiette de spaghettis et d'une fourchette située à gauche de l'assiette. Mais pour manger, un philosophe doit disposer de deux fourchettes, il doit donc en emprunter une à son voisin de droite. La situation est problématique mais heureusement les philosophes ont également pour habitude de penser, laissant ainsi du temps aux autres pour manger. Un philosophe peut exécuter quatre actions :
Penser durant un temps indéterminé
Prendre une fourchette
Rendre une fourchette
Manger, là encore durant un temps indéterminé.
Le but du jeu est de faire en sorte que le maximum de philosophes puisse manger en même temps et qu'il n'y ait pas d'interblocage. Exemple simple d'interblocage : si chaque philosophe prend sa fourchette gauche, aucun ne pourra prendre de fourchette droite et tous mourront de faim. Ce genre de situation peut être révélé en insérant régulièrement des instructions delay dans votre algorithme.
Notre programme ne tournera que durant un temps imparti, disons 10 secondes. Et pour nous assurer que nos philosophes ne meurent pas de faim, nous enregistreront leurs temps de réflexion et de repas dans un fichier texte : un philosophe qui n'aurait réfléchi que 0,4 secondes et mangé 0,8 secondes a très certainement été confronté à un phénomène de famine : tous les couverts étaient pris et notre philosophe est mort précocement. D'ailleurs, il serait bon que les temps de réflexion ou de repas soient aléatoires mais ne dépassent pas la seconde.
Solution
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Ada.Calendar ; USE Ada.Calendar ;
WITH Ada.Numerics.Discrete_Random ;
PROCEDURE Diner_Des_Philosophes IS
-------------------------
-- ALEATOIRE --
-------------------------
SUBTYPE T_Duree IS integer RANGE 0..1000 ;
PACKAGE P_Random IS NEW Ada.Numerics.discrete_Random(T_Duree) ;
USE P_Random ;
g : generator ;
---------------------------------------
-- CONSTANTES DU PROGRAMME --
---------------------------------------
type Philosophe_Name is (PLATON, SOCRATE, ARISTOTE, EPICURE, PYTHAGORE) ; --les noms de nos philosophes
Nb_Philosophes : CONSTANT Natural := Philosophe_Name'Pos(Philosophe_Name'Last) +1 ; --le nombre de philosophes
--T_Index est l'intervalle 0..4 pour les différents indices
--il s'agit d'un type modulaire pour faciliter le calcul de l'indice suivant
type T_Index is mod Nb_Philosophes ;
Type T_Boolean_Array is array(T_Index) of Boolean ;
-------------------------------
-- TYPE FOURCHETTE --
-------------------------------
PROTECTED TYPE T_Fourchette IS
--P : prendre les fourchettes si possible
--Le paramètre est un type de sorte que
--P n'est pas une entrée mais une famille d'entrées
ENTRY P(T_Index) ;
--V : rendre les fourchettes
PROCEDURE V(gauche : T_Index) ;
PRIVATE
Libre : T_Boolean_Array := (OTHERS =>True) ;
END T_Fourchette ;
-----------------
PROTECTED BODY T_Fourchette IS
--Notez bien la notation particulière des paramètres ! ! !
ENTRY P(for gauche in T_Index) when Libre(Gauche) and libre(gauche+1) IS
BEGIN
Libre(Gauche) := False ;
Libre(Gauche+1) := False ;
END P ;
PROCEDURE V(gauche : T_Index) IS
BEGIN
Libre(Gauche) := True ;
Libre(Gauche + 1) := True ;
END V ;
END T_Fourchette ;
-----------------
Fourchette : T_Fourchette ;
-------------------------------
-- TYPE PHILOSOPHE --
-------------------------------
TASK TYPE T_Philosophe(Numero: T_Index) ;
-----------------
TASK BODY T_Philosophe IS
Name : constant String := Philosophe_Name'Image(Philosophe_Name'Val(Numero)) ; --On extrait le nom à partir du numéro
Duree : Duration ; --Durée aléatoire de la réflexion ou du repas
Temps : Duration := 0.0 ; --Temps d'activité total
F : File_Type ; --Tout sera enregsitré dans un fichier
BEGIN
--Préparatifs
create(F,out_file,"./docs/" & Name & ".txt") ;
--Boucle principale
LOOP
--Période de réflexion du philosophe
Duree := Duration(Random(G))/1000.0 ;
Temps := Temps + Duree ;
put_line(F,name & " pense pendant " & Duration'image(duree) & "s soit " & Duration'image(Temps) & "s d'activite.") ;
DELAY Duree ;
--Période où le philosophe mange
Fourchette.P(Numero) ;
Duree := Duration(Random(G))/1000.0 ;
Temps := Temps + Duree ;
Put_Line(F,Name & " mange pendant " & Duration'image(duree) & "s soit " & Duration'image(Temps) & "s d'activite.") ;
DELAY Duree ;
Fourchette.V(Numero) ;
END LOOP ;
END T_Philosophe ;
-----------------
--On utilisera un tableau pour gérer les philosophes
--Mais comme ceux-ci doivent être contraints par un numéro
--nous utiliserons un tableau de pointeurs sur philosophes
TYPE T_Philosophe_access is access T_Philosophe ;
TYPE T_Philosophe_Array IS ARRAY(T_Index) OF T_Philosophe_Access ;
Philosophe : T_Philosophe_Array ;
-----------------
T : CONSTANT Time := Clock + 10.0 ; --indique le temps d'execution du programme
-----------------------------------
-- PROGRAMME PRINCIPAL --
-----------------------------------
BEGIN
Reset(G) ;
--Création des tâches Philosophes (allocation dynamique)
FOR I IN T_Index LOOP
Philosophe(I) := NEW T_Philosophe(I) ;
END LOOP ;
--Boucle principale permettant de faire tourner le programme 10 secondes
WHILE Clock < T LOOP
null ;
END LOOP ;
--Avortement des tâches Philosophes
FOR I IN T_Index LOOP
abort philosophe(i).all ;
END LOOP ;
END Diner_Des_Philosophes ;
Commentaires concernant la solution proposée
La solution que je vous propose apporte plusieurs nouveautés. Tout d'abord, au lieu de créer cinq variables tâches distinctes elles ont toutes été réunies dans un tableau.
Mais pourquoi avoir utilisé un tableau de pointeurs sur philosophes au lieu d'un tableau de philosophes ? Tu te compliques la vie ! o_O
Vous avez du remarquer que mon type T_Philosophe n'est pas contraint, il dépend d'un paramètre (numéro). Or il est impossible de déclarer un tableau contenant des éléments d'un type non contraint. D'où l'usage des pointeurs (cela devrait vous rappeler les chapitres de POO). Ensuite, mes tâches ont besoin d'un générateur G pour s'exécuter. Or, il est préférable que G soit réinitialisé avec reset avant que les tâches ne débutent. En utilisant les pointeurs, mes tâches ne commencent qu'à partir du moment où j'écris Philosophe(I) := NEW T_Philosophe(I) et non à partir de begin ! Cela permet de retarder leur démarrage. Notez d'ailleurs que si vous utilisiez Ada.Unchecked_Deallocation sur l'un de ces pointeurs, cela mettre fin à la tâche pointée, un peu violemment d'ailleurs :-° .
Autre particularité, les fourchettes et les philosophes sont placés autour d'une table RONDE ! Et je rappelle qu'un cercle n'a ni début ni fin. Autrement dit, les numéros des fourchettes et philosophes sont 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1 ... d'où l'emploi d'un type modulaire pour les numéroter. C'est vrai que je n'ai pas beaucoup utilisé ces types jusque là, mais ils se justifiait totalement dans ce cas. Ainsi, il suffit de calculer gauche + 1 pour connaître l'indice de la fourchette de droite, même si la fourchette de gauche à le numéro 4 !
Troisième remarque : vous avez sûrement noté qu'il est impossible que la garde d'une entrée utilise un paramètre de la même entrée. Impossible d'écrire par exemple : ENTRY P(n : integer) WHEN n > 0 IS. Or nous n'allons pas rédiger une entrée P pour chaque fourchette ! La solution consiste à créer une famille d'entrées en inscrivant en paramètre non pas une variable mais un type :
--Spécifications : on n'inscrit que le type, à la manière des intervalles pour les tableaux
ENTRY P(Integer) WHEN n > 0 ;
--Corps, on indique l'intervalle dans lequel varie notre variable, à la manière des boucles
ENTRY P(for n in integer) WHEN n > 0 IS
C'est avec ces trois exercices fondamentaux que s'achève notre chapitre sur le multitasking. Il y aurait encore beaucoup à dire car la programmation multitâche est un vaste domaine côtoyant les avancées en matière de processeur. Mais je préfère cesser mes développements pour ne pas trop m'éloigner de notre sujet (le langage Ada) et ne pas alourdir davantage un chapitre déjà compliqué.
Retenez toutefois ceci :
Les task sont un atout majeur et ancien d'Ada dont d'autres langages se sont inspirés.
Qui dit parallélisme et ressources partagées, dit problème de synchronisation. J'espère que vous aurez compris que ces problèmes peuvent être sévères et exigent des algorithmes mûrement pensés.
Pour répondre aux problèmes de synchronisation, Ada propose un outil puissant : les types protected (voire synchronized) qui sont justement protégés des interruptions (Time Out).
A travers les types synchronized, il est possible de faire se rejoindre programmation concurrente et programmation orientée objet.
synchronized pragma priority
Ca y est ! Vous êtes venus à bout de cette quatrième et infâme partie ! Que de théorie. J'aperçois d'ici la fumée qui se dégage des neurones en surchauffe ! :p Vous pouvez désormais passer à la dernière partie (si ce n'est pas déjà fait :-° ) sur la programmation événementielle avec GTK. À vous les fenêtres et les boutons, enfin ! Cette cinquième partie sera à l'exact opposé de la quatrième : très pratique, avec des objectifs bien plus palpitants que de connaître le temps d'exécution d'un algorithme de tri, et surtout, c'est le couronnement de tous les efforts fournis pour parvenir jusque-là. Alors régalez-vous !
Ca y est, après des dizaines de cours théoriques faisant appel à une vieille console en noir et blanc, des heures passées à écrire des lignes de code pour n'aboutir qu'à un médiocre logiciel ne reconnaissant que le clavier, nous allons enfin pouvoir nous lancer dans la conception de logiciels plus modernes, avec des images, des boutons qui réagissent quand on clique dessus ... Pour faire cela, plusieurs choix s'offraient à nous, j'ai choisi de vous en proposer un : GTK et surtout sa version prévue pour Ada, GTKAda.
Avant de rentrer dans le vif du sujet, je vais prendre quelques unes de vos précieuses minutes pour vous exposer ce que sont GTK et GTKAda. Je vous expliquerai ce qu'est GTK et pourquoi j'ai fait ce choix. Nous verrons également comment l'installer et enfin comment l'utiliser.
GTK n'est pas un logiciel. Il s'agit d'un ensemble de bibliothèques permettant de créer des interfaces graphiques pour vos programmes. Il existe plusieurs bibliothèques de la sorte, elles permettent aux développeurs de créer rapidement des interfaces graphiques (aussi appelées GUI, pour Graphical Users Interface), c'est-à-dire des programmes fenêtrés, disposant de boutons, de textes, d'images ... et permettant à l'utilisateur d'agir via son clavier mais également via la souris ou d'autres périphériques. Ces bibliothèques fournissent aux programmeurs tout un ensemble de méthodes leur évitant de réinventer la roue : pas question de perdre du temps à dessiner les bords du bouton, à définir sa couleur principale, sa couleur lorsqu'il est survolé, sa couleur lorsqu'il est enfoncé ...
Et GTK dans tout cela ? :euh:
GTK est l'une de ces bibliothèques. C'est l'acronyme pour Gimp ToolKit, cette bibliothèque ayant été à l'origine créée pour le puissant logiciel de traitement d'images GIMP. Elle est depuis utilisée dans de nombreux logiciels :
Le logiciel de retouche d'image Gimp, bien sûr
L'environnement graphique Gnome, utilisé sur de nombreuses distribtions Linux, telle la célèbre Ubuntu
Le logiciel de virtualisation VmWare
Le logiciel de dessin vectoriel Inkscape
De nombreux logiciels ayant l'initiale G : GEdit, Gnumerics, GParted, GThumb ... et d'autres tels Nautilus ou Totem.
Vous pourrez trouver une liste de logiciels réalisés sous GTK en cliquant ici.
Gimp, Gnome, Inkscape et VmWare
GTK, GTKAda, GDK, Glib et toute la famille
C'est quoi la différence entre GTK et GTKAda ? J'ai aussi entendu parler de GDK et GTK+ : c'est mieux ou pas ?
Avant d'aller plus en avant, il faut clarifier tous ces logos. Le projet GTK (aussi appelé GTK+) est une bibliothèque écrite en C et pour le C. Elle est toutefois disponible dans de nombreux autres langages de programmation dont Ada. Mais pour cela, il aura fallu réaliser un interfaçage (ou binding), une sorte de traduction partielle de la bibliothèque. GTKAda est donc cette traduction de GTK du C vers l'Ada.
Comme de nombreux projets liés à l'univers Linux, GTK est composé de différentes couches (des sous-projets en quelques sortes) :
Cairo : il s'agit d'une bibliothèque graphique 2D. Absente des premières versions de GTK, Cairo prend de plus en plus de place dans le projet.
GLib : il s'agit d'une bibliothèque permettant d'étendre les possibilités du C, et notamment de manipuler diverses structures de données. Elle n'a rien à voir avec le rendu graphique mais est à la base du projet GTK+.
Au-dessus, viennent se greffer d'autres couches :
Pango : cette bibliothèque est en charge du texte. Elle permet l'utilisation de diverses polices, la mise en forme du texte ainsi l'écriture dans divers alphabets. Avec elle, plus de soucis avec les caractères accentués ! Vous pourrez même écrire en japonais si le cœur vous en dit.
GDK : pour GIMP Drawing Kit. Il s'agit de la couche graphique bas-niveau de GTK+. Elle était présente dès l'origine de GTK mais tend à céder la place à Cairo.
ATK : ou Accessibility Toolkit. Cette bibliothèque permet une meilleure accessibilité de logiciels aux personnes handicapées : forts contrastes, loupes, navigation au clavier seul ou à la souris seule ... nous ne nous servirons pas de cette bibliothèque, mais libre à vous d'y jeter un oeil.
GIO : de moindre importance, cette bibliothèque est désormais intégrée à Glib.
Le projet GTK+ fait appel à ces différentes couches. Ce que l'on peut résumer par le schéma ci-dessous :
Autre acronyme que vous pourriez voir : Glade
. Il s'agit d'un logiciel permettant la réalisation de votre interface graphique en quelques clics. Pour éviter de vous trouver face à des montagnes de lignes de code incompréhensibles, nous n'utiliserons Glade qu'à la toute fin de cette partie, lorsque vous maîtriserez un peu mieux GTKAda.
Pourquoi ce choix ?
Pourquoi avoir choisi une bibliothèque écrite en C ?
J'ai avant tout choisi l'une des bibliothèques graphiques les plus connues, non pas que ce soit un gage de qualité mais cela vous apporte l'assurance de trouver des ressources complémentaires (tutoriels, cours, forums ...) . Certes elle est écrite en C, mais elle a bénéficié d'un interfaçage vers Ada complet et de qualité. Pour tout vous dire, vous ne verrez presque jamais de C en vous baladant dans les packages. D'ailleurs, GTK n'est pas réservé au C, il est disponible dans de nombreux autres langages : C++, C#, Java, Javascript, Python, Vala et Perl pour les bindings officiels. Il est également supporté (tout ou partie) par Ruby, Pascal, R, Lua, Guile, OCaml, Haskell, FreeBasic, D, Go ou Fortran. Ouf ! Impressionnant non ? :o
J'ai plusieurs ordinateurs avec différents systèmes d'exploitation. Je suppose que ça ne marche que sous Windows ton GTK ? :colere2:
Pas du tout, GTK est multiplateforme, vos projets pourrons être développés sous Windows, Mac OS, Linus ou Unix. Bien sûr, il faudra recompiler sous chaque système d'exploitation, les .exe ne fonctionnant pas ailleurs que sous Windows (c'est un exemple).
Et ça va me coûter combien ?
Pas un centime ! GTK est un projet gratuit et libre. Il est placé sous la licence des logiciels libres LGPL. Cela vous permettra, si vous le souhaitez, de vendre votre programme sans pour autant en faire un logiciel sous licence LGPL. En revanche, si vous veniez à modifier le code source de GTK, alors la bibliothèque obtenue devrait absolument être sous licence LGPL.
J'ai regardé sur internet des logiciels faits avec GTK ... ils sont moches !
GTK a un aspect très ... Linux qui ne plaît pas à tous. Et pour cause, l'environnement de Bureau GNOME, utilisé par de nombreuses distributions est basé sur GTK. Mais rassurez-vous, si cet aspect ne vous plaît pas, GTK est personnalisable. Différents thèmes graphiques sont aisément téléchargeables sur ce site.
GTK est donc une bibliothèque libre, gratuite, multilangage et notamment bien adaptée à l'Ada, multiplateforme, personnalisable, très utilisée et pour laquelle vous trouverez donc aisément des informations sur le net. J'ajouterai encore un avantage à GTK : sa conception orientée objet. Pour vous qui venez tout juste de découvrir la POO, il me semblait intéressant que la bibliothèque que vous alliez étudier soit elle aussi orientée objet.
Autre atout de GTKAda : il est aisément téléchargeable sur le site d'Adacore, à l'adresse suivante : http://libre.adacore.com/download/configurations . Après avoir vérifié votre système d'exploitation (1), dans le menu GtkAda 2.24.2 (2) (la version en cours lorsque j'écris ces lignes), sélectionnez le bouton gtkada-gpl-2.24.2-nt.exe (3) puis cliquez sur le bouton Download select files (4). Sous Linux, vous aurez deux archives à télécharger : gtkada-gpl-2.24.2-src.tgz et gtk+-2.24.5-i686-pc-linux-gnu.tgz
Installer
Sous Windows
Sous Windows, l'installation est elle aussi simplissime. Ouvrez le fichier zip téléchargé ainsi que les sous-répertoires qu'il contient. Extrayez le fichier gtkada-gpl-2.24.2-nt.exe puis lancez-le et suivez les instructions.
Sous Linux
Ouvrez le répertoire /usr et créez un sous-répertoire gtkada. Dans l'archive téléchargée, vous trouverez deux sous-archives. Commencez par ouvrir gtk+-2.24.5-i686-pc-linux-gnu.tgz et décompresser son contenu dans le répertoire /usr/gtkada que vous venez de créer.
La seconde sous-archive pourra être décompressée dans un répertoire temporaire. A l'aide de la console, placez-vous dans ce répertoire temporaire et entrez les instructions suivantes :
configure --prefix=/usr/gtkada
make all
sudo make install
sudo ldconfig
Vous pourrez ensuite supprimer le répertoire temporaire.
Configurer votre IDE
Attention, ce n'est pas parce que GtkAda est installé que vous pouvez déjà l'utiliser. Vous devrez préalablement configurer votre IDE pour qu'il indique au compilateur où se trouvent les packages de Gtk.
Sous Adagide
Pour Adagide, il vous suffit d'aller dans le menu Compile > Select Target. Une fenêtre s'ouvre, cliquez alors sur l'onglet Debug settings. Dans la ligne Compiler Options, vous n'aurez qu'à écrire -I suivi immédiatement du chemin pour accéder au répertoire GtkAda/include/gtkada. Par exemple, voici ce que vous pourriez écrire (tout dépend du répertoire choisi pour installer GtkAda) :
-IC:\Program Files\GtkAda\include\gtkada
Sous GPS
Une manipulation similaire est nécessaire sous GPS. Rendez-vous dans le menu Build > Settings > Targets. Puis dans chacun des outils que vous utilisez (c'est à dire Compile File et Build <current file>), ajoutez à la ligne d'instruction située au bas de la fenêtre la commande indiquée précédemment.
Un premier essai
Pour s'assurer que tout fonctionne correctement, copiez le code ci-dessous. N'oubliez pas d'indiquer au compilateur l'emplacement des packages de GtkAda.
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
PROCEDURE Test01 IS
win : Gtk_window ;
BEGIN
Init ;
Gtk_New(Win) ;
Win.show_all ;
Main ;
END Test01 ;
Compilez, exécutez et vous devriez obtenir ceci :
Ce n'est pas extraordinaire, mais c'est bien une fenêtre tout ce qu'il y a de plus normale, pas une vilaine console ! Vous venez de réaliser votre tout premier programme fenêtré avec GTK !
A retenir :
GTK est un ensemble de bibliothèques graphiques codées en C, mais le projet GtkAda permet d'utiliser GTK tout en codant en Ada.
Avant tout projet utilisant GTK, vous devrez absolument indiquer au compilateur le chemin pour accéder aux packages de GTK.
Vous avez créé votre premier programme fenêtré lors du précédent chapitre ... mais sans rien comprendre à ce que vous faisiez. Nous allons donc prendre le temps cette fois de décortiquer et de comprendre ce premier bout de code GtkAda.
Pour commencer, nous allons édulcorer encore notre code. Voici donc le minimum requis pour tout programme GTK :
WITH Gtk.Main ; USE Gtk.Main ;
PROCEDURE MaFenetre IS
BEGIN
Init ;
Main ;
END MaFenetre ;
Vous pouvez compiler, vous vous apercevrez qu'il ne se passe pas grand chose : la console s'ouvre comme d'habitude mais plus de jolie fenêtre ! :'( Et pourtant, GTK a bien été lancé. En fait, comme bon nombre de bibliothèques, GTK nécessite d'être initialisée avant toute utilisation avec la procédure Init ou plus exactement Gtk.Main.Init. Je vous précise le chemin complet car vous serez très certainement amenés à un moment ou à un autre à le préciser.
Puis, votre code doit se terminer par l'instruction Main (ou Gtk.Main.Main). Pourquoi ? Nous expliquerons cela en détail lors du chapitre sur les signaux, mais sachez pour l'instant que cette instruction équivaut à ceci :
LOOP
Traiter_Les_Actions_De_L_Utilisateur ;
END LOOP ;
L'instruction Main empêche ainsi que votre fenêtre se ferme aussitôt après avoir été créée et se chargera de réagir aux différentes actions de l'utilisateur (comme cliquer sur un bouton, déplacer la souris, appuyer sur une touche du clavier ... ). Main n'est donc rien d'autre qu'une boucle infinie, laquelle peut toutefois être stoppée grâce à la procédure Main_Quit que nous verrons à la fin du chapitre et qui fait elle aussi partie du package Gtk.Main.
Créer une fenêtre
Une fenêtre sous GTK est un objet private de la classe GTK_Window_Record. Cette classe et les méthodes qui y sont associées sont accessibles via le package GTK.Window. Cependant, vous ne manipulerez jamais les objets de classe GTK_Window_Record, vous ne manipulerez que des pointeurs sur cette classe.
Argh ! :waw: Des pointeurs sur des classes privées. Il va falloir que je relise toute la partie IV pour comprendre la suite ?
Ne vous inquiétez pas, tout se fera le plus simplement du monde. Plutôt que de manipuler directement des objets GTK_Window_Record, vous utiliserez des GTK_Window. Le fait qu'il s'agisse d'un pointeur sur classe ne compliquera pas votre développement, mais il est bon que vous sachiez qu'une fenêtre GTK se définit ainsi :
type Gtk_Window is access all Gtk_Window_Record'Class;
A quoi bon savoir cela ? Eh bien si vous savez qu'il s'agit d'un pointeur, vous savez dès lors que déclarer une GTK_Window ne fait que réserver un espace mémoire pour y stocker des adresses. Il faudra en plus absolument créer un espace mémoire sur lequel pointera notre GTK_Window. Cela se faisait habituellement avec l'instruction new, avec GtkAda, vous utiliserez la procédure Gtk_New dont voici la spécification :
procedure Gtk_New(Window : out Gtk_Window;
The_Type : Gtk.Enums.Gtk_Window_Type := Gtk.Enums.Window_Toplevel);
Oublions pour l'instant le paramètre The_Type sur lequel nous reviendrons dans la prochaine partie. Lançons-nous ! Déclarons une Gtk_window et créons sa Gtk_Window_Record correspondante :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
PROCEDURE MaFenetre IS
win : Gtk_window ;
BEGIN
Init ;
gtk_new(win) ;
Main ;
END MaFenetre ;
Euh ... y se passe toujours rien lorsque je lance le programme :euh:
Normal, vous avez créer une Gtk_Window_Record ... en mémoire ! Elle existe donc bien, mais elle est tranquillement au chaud dans vos barettes de RAM. Il va falloir spécifier que vous souhaiter l'afficher en ajoutant l'instruction gtk.window.show :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
PROCEDURE MaFenetre IS
win : Gtk_window ;
BEGIN
Init ;
Gtk_New(Win) ;
show(win) ;
Main ;
END MaFenetre ;
Ooh la belle fenêtre !
Pourquoi la console reste-t-elle apparente lorsque je ferme la fenêtre ? o_O
Nous avons déjà en partie répondu à cette question : fermer la fenêtre revient à ne plus l'afficher, mais cela n'implique pas que vous sortiez de la boucle infinie du Main. Pour en sortir, il faut associer l'action "fermer la fenêtre" à la procédure Main_quit. Nous verrons cela plus tard, pour l'instant contentez-vous de fermer la fenêtre et la console.
Et cette console, on ne pourrait pas s'en passer ?
Oui on peut s'en passer, mais non nous ne nous en passerons pas pour l'instant car elle vous permettra lors de la phase de développement de connaître les exceptions levées par votre programme. Donc, là encore : patience.
C'est bien d'avoir créé une fenêtre mais elle est petite, vide et son titre n'est pas terrible. :(
C'est pourquoi nous allons désormais nous attacher à modifier notre fenêtre puis nous verrons dans la partie suivante comment la remplir. Je vous conseille pour mieux comprendre (ou pour aller plus loin) d'ouvrir le fichier gtk-window.ads situé dans le répertoire .../Gtkada/include/gtkada.
Changer de type de fenêtre
Souvenez-vous, nous avons négligé un paramètre lors de la création de notre fenêtre : le paramètre The_Type. Sa valeur par défaut était Gtk.Enums.window_toplevel. Plus clairement, sa valeur était window_toplevel mais les valeurs de ce paramètre sont listés dans le package Gtk.Enums (un package énumérant diverses valeurs comme les divers types d'ancrages, les tailles d'icônes, les positions dans une fenêtre ...). Deux valeurs sont possibles :
Window_Toplevel : fenêtre classique comme vous avez pu le voir tout à l'heure. Nous n'utiliserons quasiment que ce type de fenêtre.
Window_Popup : fenêtre sans barre d'état ni bords, ni possibilité d'être fermée, déplacée ou redimensionnée. Vous savez, c'est le genre de fenêtre qui s'ouvre au démarrage d'un logiciel le temps que celui-ci soit chargé (Libre Office par exemple).
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
PROCEDURE MaFenetre IS
win : Gtk_window ;
BEGIN
Init ;
Gtk_New(win,Window_Popup) ;
win.show ;
Main ;
END MaFenetre ;
Si vous testez le code ci-dessus, vous devriez voir apparaître un magnifique rectangle gris sans intérêt à l'écran. Génial non ? :D
Définir les paramètres avec Set_#
Fixer le titre
Avant toute chose, un peu d'Anglais : comment dites-vous "fixer" dans la langue de Shakespeare ? Réponse : "to set". Donc dès que vous aurez envie de fixer quelque chose (la taille, la position, l'apparence ...), vous devrez utiliser des méthodes commençant par "set". Ainsi, pour fixer le titre de votre fenêtre, nous utiliserons la méthode set_title() :
BEGIN
Init ;
Gtk_New(win,Window_Popup) ;
win.set_title("Super programme !") ;
win.show ;
Main ;
END MaFenetre ;
A l'inverse, si vous souhaitez connaître un paramètre, l'obtenir, il vous faudra utiliser des méthodes (plus exactement des fonctions) dont le nom commencera par le mot "get". Ainsi, Win.Get_Title vous renverra le titre de la fenêtre Win. Exemple (regardez la console) :
WITH Ada.Text_IO ; USE Ada.Text_IO ;
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
PROCEDURE MaFenetre IS
win : Gtk_window ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
win.set_title("Super programme !") ;
Win.Show ;
put_line(win.get_title) ;
Main ;
END MaFenetre ;
Fixer la taille de la fenêtre
Nous allons désormais nous focaliser sur les méthodes "set", les méthodes "get" ne nous servirons que lorsque nous pourrons interagir avec la fenêtre (et nous en sommes encore loin). Si vous avez compris ce qui a été dit juste avant, vous devriez avoir une idée du nom de la méthode permettant de fixer la taille par défaut de notre fenêtre : Set_default_size, bien sûr ! Elle prend deux paramètres : Width pour la largeur et Height pour la hauteur de la fenêtre. Exemple :
BEGIN
Init ;
Gtk_New(win,Window_Popup) ;
win.set_title("Super programme !") ;
Win.Set_Default_Size(600,400) ;
win.show ;
Main ;
END MaFenetre ;
Remarquez également que vous ne faites que définir une taille par défaut. Si vous souhaitez que votre fenêtre ne puisse pas être redimensionnée par l'utilisateur, vous allez devoir utiliser la méthode set_resizable.
win.set_resizable(false) ;
Cette ligne indiquera que votre fenêtre n'est pas "redimensionnable". En revanche, elle va automatiquement se contracter pour ne prendre que la place dont elle a besoin ; et vu que votre fenêtre ne contient rien pour l'instant, elle devient minuscule. Voici également quelques méthodes supplémentaires qui pourraient vous servir à l'avenir :
win.fullscreen ; --met la fenêtre en plein écran
win.unfullscreen ; --annule le plein écran
win.resize(60,40) : --redimensionne la fenêtre à la taille 60x40
win.Reshow_With_Initial_Size ; --fais disparaître la fenêtre pour la réafficher
--à la taille initiale
Pour l'instant, hormis fullscreen, les autres méthodes ne devraient pas encore vous concerner. Mais attention, si vous mettez votre fenêtre en plein écran, vous n'aurez plus accès à l'icône pour la fermer. Vous devrez appuyer sur Alt + F4 pour la fermer ou bien sur Alt + Tab pour accéder à une autre fenêtre.
Fixer la position
Il y a deux façons positionner votre fenêtre. La première méthode est la plus simple et la plus intuitive : set_position. Cette méthode ne prend qu'un seul paramètre de type Gtk.Enums.Gtk_Window_Position (encore le package Gtk.Enums). Voici les différentes valeurs :
type Gtk_Window_Position is
(Win_Pos_None, --Aucune position particulière
Win_Pos_Center, --La fenêtre est centrée à l'écran
Win_Pos_Mouse, --La fenêtre est centrée autour de la souris
Win_Pos_Center_Always, --La fenêtre est centrée à l'écran et le restera malgré
--les redimensionnements opérés par le programme
Win_Pos_Center_On_Parent); --La fenêtre est centrée par rapport à la fenêtre qui l'a créée
Pour centrer la fenêtre à l'écran, il suffira d'écrire :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Super programme !") ;
Win.Set_Default_Size(600,400) ;
win.set_position(win_pos_center) ;
Win.Show ;
Main ;
END MaFenetre ;
La seconde méthode pour positionner votre fenêtre est plus compliquée et consiste à la placer en comptant les pixels :
win.move(0,0) ;
Cette instruction aura pour conséquence de placer votre fenêtre en haut à gauche de l'écran, ou plus exactement de placer le pixel supérieur gauche de votre fenêtre (le pixel de la fenêtre de coordonnées ) dans le coin supérieur gauche de l'écran (sur le pixel de coordonnées de votre écran). Par défaut c'est le point de la fenêtre de coordonnées qui est le point de référence, appelé centre de gravité de la fenêtre.
Vous devez d'ailleurs savoir que chaque pixel de votre écran est repéré par des coordonnées . Plus est grand, plus le pixel est situé vers la droite. Plus est grand, plus le pixel est situé vers le bas :
Enfin, il est possible de faire en sorte que votre fenêtre reste au-dessus de toutes les autres, quoi que vous fassiez. Il vous suffit pour cela d'utiliser la méthode win.set_keep_above(true).
Fixer l'apparence
Venons-en maintenant à l'apparence de notre fenêtre. La première modification que nous pouvons apporter porte sur le bouton de fermeture de la fenêtre : actif ou non ? Par défaut, GTK crée des fenêtres supprimables, mais il est possible d'empêcher leur fermeture grâce à la méthode win.set_deletable(false). Pour rappel, "to delete" signifie "supprimer" en Anglais, donc "deletable" signifie "supprimable".
Seconde modification possible : l'opacité de la fenêtre. Il est possible avec Gtk de rendre une fenêtre complètement ou partiellement transparente :
Cela se fait le plus simplement du monde avec la méthode win.set_opacity(). Cette méthode prend en paramètre un Gdouble compris entre 0.0 et 1.0, c'est à dire un Glib Double ce qui correspond à un nombre en virgule flottante (double précision) disponible dans le package Glib. Comme pour les Gint, vous serez sûrement amener à effectuer quelques conversions entre les float d'Ada et les Gdouble de Gdk.
Enfin, troisième modification (la plus attendue, je pense) : l'icône du programme. Changeons ce vilain icône de programme par un icône bien à vous. Enregistrez l'image ci-dessous dans le répertoire de votre programme (prenez soin d'avoir une image carrée pour ne pas avoir de surprises à l'affichage) :
Nous allons utiliser la méthode set_icon_from_file qui permet de fixer l'icône à partir d'un fichier spécifique. Cependant, contrairement aux autres méthodes utilisées jusqu'ici, il s'agit d'une fonction et non d'une procédure. Elle renvoie un booléen : si le chargement de l'icône s'est bien passé, il vaudra true, si le fichier n'existe pas, est introuvable ou n'est pas dans un format compatible, il vaudra false. Cela vous permet de gérer ce genre d'erreur sans faire planter votre programme ou bien de lever une exception (ça fera un excellent rappel) :
...
LOADING_ERROR : EXCEPTION ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Super programme !") ;
Win.Set_Default_Size(160,180) ;
Win.Set_Position(Win_Pos_Center) ;
Win.Set_Keep_Above(True) ;
Win.Set_Opacity(0.8) ;
IF NOT win.Set_Icon_From_File("bug-icone.png")
THEN RAISE LOADING_ERROR ;
END IF ;
Win.Show ;
Main ;
EXCEPTION
WHEN LOADING_ERROR => Put_line("L'icone n'a pas pu etre charge") ;
END MaFenetre ;
Un Widget est l'acronyme de Windows, Icons, Dialog box, Graphics Extensions, Track ball, mais on considère plus souvent que c'est la contraction de Window's gadget. Cela ne vous avance pas davantage ? Eh bien un widget, est simplement un élément graphique composant votre interface. Les boutons, les cases à cocher, les barres de défilement, les images, les lignes de texte, les zones de frappe mais aussi les menus, les icônes ou votre fenêtre elle-même constituent autant de widgets.
Pour GTK tous ces widgets constituent des classes qui dérivent en plus ou moins droite ligne de la classe GTK_Widget_Record. Imaginez que vous ayez un widget appelé buzzer, alors la norme d'écriture de GTK imposera que :
il porte le nom de GTK_Buzzer_Record ;
ce soit un type tagged et private dérivé de GTK_Widget_Record ;
il soit définit, lui et ses méthodes, dans le package GTK.Buzzer et que les fichiers correspondant portent les noms gtk-buzzer.ads et gtk-buzzer.adb ;
un type GTK_Buzzer soit défini de la manière suivante : type GTK_Buzzer is access all GTK_Buzzer'class ;
Ces quelques remarques devraient vous rappeler quelque chose non ? C'est exactement ce que nous avons vu avec les fenêtres ! Ces conventions d'écriture et la conception orientée objet de la bibliothèque vont grandement nous simplifier la tâche, vous verrez.
Ajouter un bouton
Cessons ces généralités et ajoutons un bouton à notre fenêtre. Le widget-bouton se nomme tout simplement GTK_Button ! Enfin, GTK_Button_Record plus précisément mais vous aurez compris que c'est le pointeur GTK_Button qui nous intéresse réellement. Et il se trouve évidemment dans le package Gtk.Button. Vous commencez à comprendre le principe ? Très bien. ;)
Reprenons notre programme (que j'ai édulcoré pour ne nous concentrer que sur l'essentiel) :
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gdk.Window ; USE Gdk.Window ;
WITH Gtk.Button ; USE Gtk.Button ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Bouton : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Super programme !") ;
win.set_default_size(150,180) ;
Win.Set_Position(Win_Pos_Center) ;
IF NOT Win.Set_Icon_From_File("bug-icone.png")
THEN NULL ;
END IF ;
Gtk_New(Bouton) ;
win.add(Bouton) ;
Win.Show ;
Bouton.show ;
Main ;
END MaFenetre ;
Vous remarquerez que la procédure Gtk_New est toujours nécessaire pour créer notre bouton. Puis nous devons l'ajouter à notre fenêtre avec l'instruction win.add(Bouton) sans quoi nous aurons un bouton sans trop savoir quoi en faire. Enfin, dernière étape, on affiche le bouton avec la méthode Bouton.show.
Dis-moi : c'est vraiment nécessaire d'utiliser show autant de fois qu'il y a de widgets ? Parce que ça risque d'être un peu long quand on aura plein de bouton et de menus. :-°
En effet, c'est pourquoi à partir de maintenant nous n'utiliserons plus win.show mais win.show_all. Cette méthode affichera non seulement la fenêtre Win mais également tout ce qu'elle contient.
Personnaliser le bouton
Bon c'est pas tout ça mais mon bouton est particulièrement moche. On peut pas faire mieux que ça :
Nous pourrions commencer par lui donner un nom ou plus exactement une étiquette ("label" en anglais) :
A noter que les lignes 20 et 21 peuvent être remplacées par une seule : GTK_New(Bouton,"Ok !") ;. Bien plus rapide non ? Un autre possibilité, pour l'affichage du texte, est de souligner l'une des lettres afin d'indiquer le raccourci clavier. Mais ne vous emballez pas, nous n'allons pour l'instant que souligner une lettre. Deux méthodes s'offrent à vous :
GTK_New(Bouton,"_Ok !") ;
Bouton.set_use_underline(true) ; --on indique que l'on utilise le soulignage
-- OU PLUS DIRECTEMENT
GTK_New_With_Mnemonic(Bouton,"_Ok !") ; --on crée directement le bouton comme tel
L'underscore devant la lettre O indiquera qu'il faut souligner cette lettre. Si jamais vous aviez besoin d'écrire un underscore, il vous suffirait d'en écrire deux d'affilée.
On peut placer une image dans le bouton ? :p
Bien sûr, mais pour cela il faudrait utiliser des GTK_Image et je garde cela pour le chapitre 4. En revanche, nous pourrions changer le relief du bouton, son épaisseur. On utilise alors la méthode Set_Relief() qui prend comme paramètre un Gtk.Enums.Gtk_Relief_Style (eh oui, encore ce package Gtk.Enums, il liste divers styles, donc mieux vaut garder un œil dessus) :
Bouton.Set_Relief(Relief_Normal) ; --le relief auquel vous étiez habitué
Bouton.Set_Relief(Relief_Half) ; --un bouton un peu plus plat
Bouton.Set_Relief(Relief_None) ; --un bouton complètement plat
Ajouter un second bouton ?
Allez, je vais m'entraîner en ajoutant un second bouton à ma fenêtre :
Si jamais vous compilez ce code, vous vous apercevrez que :
GNAT ne bronche pas. Pour lui, tout est syntaxiquement juste.
votre fenêtre ne comporte toujours qu'un seul bouton.
une belle exception semble avoir été levée car votre console vous affiche : Gtk-WARNING **: Attempting to add a widget with type GtkButton to a GtkWindow, but as a GtkBin subclass a GtkWindow can only contain one widget at a time ; it already contains a widget of type GtkButton
Tout est dit dans la console (d'où son utilité) : les fenêtres ne peuvent contenir qu'un seul widget à la fois. Alors si vous voulez absolument placer de nouveaux boutons (car oui c'est possible), vous n'avez plus qu'à lire le chapitre 3.
Eh bien ! Tout ce code pour seulement une fenêtre et un bouton !
C'est effectivement le problème des interfaces graphiques : elles génèrent énormément de code. Mais heureusement, nous avons déjà vu une solution idéale pour limiter tout ce code. Une solution orientée objet, adaptée aux pointeurs (et notamment aux pointeurs sur classe), qui permet d'initialiser automatiquement nos objets ... ça ne vous rappelle rien ? Les types contrôlés bien sûr ! C'est vrai que nous ne les avons pas beaucoup utilisés, même durant le TP car je savais pertinemment que nous serions amenés à les revoir.
Méthode brutale
Nous allons donc créer un package P_Fenetre, dans lequel nous déclarerons un type contrôlé T_Fenetre ainsi que sa méthode Initialize. Pas besoin de Adjust et Finalize. Notre type T_Fenetre aura deux composantes : win de type GTK_Window et btn de type GTK_Button :
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Ada.Finalization ; USE Ada.Finalization ;
PACKAGE P_Fenetre IS
TYPE T_Fenetre IS NEW Controlled WITH RECORD
Win : GTK_Window ;
Btn : GTK_Button ;
END RECORD ;
PROCEDURE Initialize(F : IN OUT T_Fenetre) ;
end P_Fenetre ;
Que fera Initialize ? Eh bien c'est simple : tout ce que faisait notre programme précédemment. Initialize va initialiser GTK, créer et paramétrer notre fenêtre et notre bouton et lancer le Main :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gdk.Window ; USE Gdk.Window ;
PACKAGE BODY P_Fenetre IS
PROCEDURE Initialize(F : IN OUT T_Fenetre) IS
BEGIN
Init ;
--Création de la fenêtre
Gtk_New(F.Win,Window_Toplevel) ;
F.Win.Set_Title("Super programme !") ;
F.win.set_default_size(150,180) ;
F.Win.Set_Position(Win_Pos_Center) ;
IF NOT F.Win.Set_Icon_From_File("bug-icone.png")
THEN NULL ;
END IF ;
--Création du bouton
Gtk_New_With_Mnemonic(F.Btn, "_Ok !") ;
F.Win.Add(F.Btn) ;
--Affichage
F.Win.Show_All ;
Main ;
END Initialize ;
END P_Fenetre ;
Notre procédure principale devient alors extrêmement simple puisqu'il ne reste plus qu'à déclarer un objet de type T_Fenetre. Génial, non ?
WITH P_Fenetre ; USE P_Fenetre ;
PROCEDURE MaFenetre IS
Mon_Programme : T_Fenetre ;
BEGIN
NULL ;
END MaFenetre ;
Méthode subtile
Une seconde possibilité existe, plus nuancée : créer deux packages (P_Window et P_Button) pour deux types contrôlés (T_Window et T_Button). Cette méthode évite de créer un package fourre-tout et laisse la main au programmeur de la procédure principale. Il n'aura simplement plus à se soucier de la mise en forme. Ce qui nous donnerait les spécifications suivantes :
WITH Gtk.Button ; USE Gtk.Button ;
WITH Ada.Finalization ; USE Ada.Finalization ;
PACKAGE P_Button IS
TYPE T_Button IS NEW Controlled WITH RECORD
Btn : GTK_Button ;
END RECORD ;
PROCEDURE Initialize(B : IN OUT T_Button) ;
end P_Button ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Ada.Finalization ; USE Ada.Finalization ;
WITH P_Button ; USE P_Button ;
PACKAGE P_Window IS
TYPE T_Window IS NEW Controlled WITH RECORD
Win : GTK_Window ;
END RECORD ;
PROCEDURE Initialize(F : IN OUT T_Window) ;
PROCEDURE Add(W : IN OUT T_Window ; B : IN T_Button) ;
PROCEDURE Show_All(W : IN T_Window) ;
end P_Window ;
Et voici le corps de nos packages :
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gdk.Window ; USE Gdk.Window ;
PACKAGE BODY P_Button IS
PROCEDURE Initialize(B : IN OUT T_Button ) IS
BEGIN
Gtk_New_With_Mnemonic(B.Btn, "_Ok !") ;
B.Btn.set_relief(Relief_None) ;
END Initialize ;
end P_Button ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gdk.Window ; USE Gdk.Window ;
PACKAGE BODY P_Window IS
PROCEDURE Initialize(F : IN OUT T_Window) IS
BEGIN
--Création de la fenêtre
Gtk_New(F.Win,Window_Toplevel) ;
F.Win.Set_Title("Super programme !") ;
F.win.set_default_size(150,180) ;
F.Win.Set_Position(Win_Pos_Center) ;
IF NOT F.Win.Set_Icon_From_File("bug-icone.png")
THEN NULL ;
END IF ;
END Initialize ;
PROCEDURE Add(W : IN OUT T_Window ; B : IN T_Button) IS
BEGIN
W.Win.Add(B.Btn) ;
END Add ;
PROCEDURE Show_all(W : IN T_Window) IS
BEGIN
W.Win.Show_all ;
END Show_all ;
end P_Window ;
Et enfin notre procédure principale :
WITH Gtk.Main ; USE Gtk.Main ;
WITH P_Window ; USE P_Window ;
WITH P_Button ; USE P_Button ;
PROCEDURE MaFenetre IS
BEGIN
Init ;
DECLARE
Win : T_Window ;
Btn : T_Button ;
BEGIN
Win.Add(Btn) ;
Win.Show_all ;
Main ;
END ;
END MaFenetre ;
En résumé :
Un programme GTK commence par Init et se termine par Main.
Un widget GTK commence par GTK_ suivi de son nom. Le package correspondant commence Gtk. suivi lui aussi du nom du widget.
Avant de manipuler les widgets, pensez à les initialiser avec Gtk_New(). Avant le Main, pensez à les afficher avec les méthodes show ou show_all.
Pour définir les paramètres d'un widget, on utilise les méthodes dont le nom commence par set_ suivi de l'élément à paramétrer.
Pour clarifier le code de la procédure principale, pensez à créer des types contrôlés.
Nous nous sommes arrêtés au dernier chapitre sur une déception de taille : Notre fenêtre ne comporte qu'un seul gros bouton qui occupe la totalité de la place et qui est redimensionné en même temps que la fenêtre. De plus, il est impossible d'ajouter un second bouton à notre fenêtre. Alors pour avoir plusieurs boutons dans votre application, il y a une solution : les conteneurs. Ces widgets un peu particuliers font l'objet d'un chapitre à part entière.
Non, quand je parle de conteneur je ne parle pas de ça :
Il s'agit de widgets très particuliers, pas nécessairement visibles mais dont le seul rôle est de contenir d'autres widgets. Les fenêtres ou les boutons dérivent de la classe GTK_Container_Record puisqu'une fenêtre peut contenir un bouton et qu'un bouton peut contenir une étiquette (du texte) et une image. Mais, quand je parlerai de conteneurs, je sous-entendrai désormais des conteneurs conçus pour organiser nos fenêtres.
L'idée est simple : une fenêtre ne peut contenir qu'un seul widget. Mais il est possible de créer des widgets appelés conteneurs pouvant contenir plusieurs autres widgets. Alors pourquoi ne pas placer tous nos widgets dans un seul conteneur que l'on placera quant à lui dans la fenêtre. Nous obtiendrions quelque chose comme cela :
Présentation de différents conteneurs
Je vais vous présenter succinctement les quelques conteneurs que nous verrons dans ce chapitre. Il en existe d'autres que nous verrons plus tard, nous allons pour l'instant nous concentrer sur les conteneurs principaux.
Les alignements
Il s'agit d'un conteneur prévu pour un seul sous-widget (on parle de widget enfant). Mais il permet, comme son nom l'indique, d'aligner un bouton selon des critères précis, par exemple : "je veux que le bouton reste en bas à gauche de la fenêtre". Cela évite d'avoir un gros bouton tout moche qui se déforme en même temps que la fenêtre. Je sais, c'est pas folichon, mais il est essentiel de comprendre son fonctionnement avant de s'attaquer à des conteneurs plus complexes.
Les boîtes
Les boîtes peuvent quant à elles plusieurs widgets alignés verticalement ou horizontalement.
Les tables
Les tables ressemblent peu ou prou aux boîtes mais proposent d'afficher plusieurs lignes ou colonnes de widgets.
Les conteneurs à position fixée
Ces conteneurs permettent de fixer une widget selon des coordonnées. Plus simples d'emploi, il est en revanche plus compliqué d'arriver à des interfaces agréables, sans bugs et portables aisément sur d'autres ordinateurs avec ces conteneurs.
Nous allons voir désormais de nombreux widgets, alors afin de ne pas me répéter, je vous présenterai désormais ces nouveautés par une rapide fiche d'identité.
Widget : GTK_Alignment
Package : Gtk.Alignment
Descendance : GTK_Widget >> GTK_Container >> GTK_Bin (conteneurs pour un unique widget)
Description : Conteneur permettant d'aligner de façon fine un unique widget dans une fenêtre.
Créer un GTK_Alignment
Repartons sur un code relativement épuré pour ne pas nous mélanger les pinceaux :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Btn : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Alignement") ;
win.set_default_size(250,200) ;
Gtk_New(Btn, "Bouton") ;
Win.add(Btn) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Si, comme je vous l'avais conseillé, vous avez ouvert les spécifications de ce package, vous pourrez vous rendre compte que la procédure GTK_New() a subi quelques modifications pour les GTK_Alignment :
Je passe sur le type GFloat, chacun aura compris qu'il s'agit d'un type virgule flottante défini très certainement par Glib. La question est surtout : que sont tous ces paramètres ?
Le paramètre Xalign permet de positionner votre conteneur horizontalement : si Xalign = 0.0 alors le widget est complètement à gauche. Si Xalign = 1.0, le conteneur sera le plus à droite possible. Si Xalign = 0.5, le conteneur sera situé au milieu (horizontalement).
Le paramètre Yalign permet de positionner votre conteneur verticalement. Si Yalign = 0.0, votre conteneur sera tout en haut ; si Yalign = 1.0, votre conteneur sera tout en bas.
Ces deux premiers paramètres ont des valeurs entre 0.0 et 1.0 et doivent être vus comme des pourcentages : Xalign = 0.50 et Yalign = 1.00, signifie que le conteneur est aligné à 50% selon l'horizontale et à 100% selon la verticale. Autrement dit, il se trouve au milieu en bas.
Le paramètre Xscale signifie littéralement "échelle horizontale". Il correspond à "l'étalement" du conteneur horizontalement. Les images ci-dessus ont été faites avec un Xscale valant 0.0, c'est à dire que le conteneur ne s'étale pas, il prend le moins de place possible, la seule limite étant la place nécessaire à l'affichage du texte du bouton. Si Xscale = 1.0 (sa valeur maximale), alors le conteneur prendra 100% de la place disponible horizontalement.
Le paramètre Yscale a lui le même rôle mais verticalement, vous l'aurez compris.
Mieux vaut une petite image pour bien comprendre. Je vais placer mon conteneur au centre (Xalign = 0.50 et Yalign = 0.50) et faire varier Xscale et Yscale :
Sachant cela, nous allons créer un Alignement contenant un bouton, situé en haut au milieu et s'étalant de 10% horizontalement et 0% verticalement. Il faudra penser à ajouter l'alignement à la fenêtre puis à ajouter le bouton à l'alignement (ou l'inverse) :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Alignment ; USE Gtk.Alignment ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Conteneur : Gtk_Alignment ;
Btn : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Alignement") ;
win.set_default_size(250,200) ;
Gtk_New(Conteneur,0.5,0.0,0.1,0.0) ;
Win.Add(Conteneur) ;
Gtk_New(Btn, "Bouton") ;
Conteneur.add(Btn) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Le padding
Le padding correspond à l'écart séparant le bord du conteneur du bord du bouton. Pour l'instant, le padding est de 0 pixels, ce qui veut dire que le conteneur enserre parfaitement le bouton. Pour créer un peu d'air (et éviter à terme que d'autres widgets viennent se coller à votre conteneur) nous pouvons utiliser cette méthode :
procedure Set_Padding
(Alignment : access Gtk_Alignment_Record;
Padding_Top : Guint; --espace au dessus du bouton
Padding_Bottom : Guint; --espace en dessous du bouton
Padding_Left : Guint; --espace à gauche du bouton
Padding_Right : Guint); --espace à droite du bouton
Je vous conseille d'avoir un padding de seulement quelques pixels (3 par exemple) : conteneur.set_padding(3,3,3,3) ;
Description : Conteneurs permettant d'aligner plusieurs widgets horizontalement (HBox) ou verticalement (VBox).
Créer des boîtes
Si vous regardez en détail le début des spécifications du package, vous remarquerez qu'il y a trois widgets : GTK_Box et deux sous-types GTK_HBox et GTK_VBox. Ce sont ces deux derniers que nous allons utiliser : GTK_HBox est une boîte horizontale et GTK_VBox est une boîte verticale. Il existe donc un constructeur pour chacun de ces widgets : GTK_New_HBox() et GTK_New_VBox().
Si le paramètre Homogeneous vaut true, alors les widgets auront des tailles similaires, homogènes. Le paramètre Spacing est similaire au paramètre Padding des alignements : il indique le nombre de pixels (l'espace) qui séparera les widgets enfants. Ces deux paramètres pourront être modifiés plus tard grâce aux méthodes Set_Homogeneous() et Set_Spacing(). Créons par exemple une boîte verticale homogène avec un espacement de 3 pixels.
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Box ; USE Gtk.Box ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Boite : Gtk_VBox ;
Btn1, Btn2, Btn3 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Boite verticale") ;
win.set_default_size(250,200) ;
Gtk_New_VBox(Boite,
homogeneous => true,
spacing => 3) ;
Win.Add(Boite) ;
Gtk_New(Btn1, "Bouton 1") ;
Gtk_New(Btn2, "Bouton 2") ;
Gtk_New(Btn3, "Bouton 3") ;
-- Ici, nous ajouterons les trois boutons dans notre boite
Win.Show_all ;
Main ;
END MaFenetre ;
Ajout de widgets
Reste maintenant à intégrer nos trois boutons à notre boîte verticale. La méthode add() est inopérante avec les boîtes : ajouter des widgets, c'est bien gentil, mais où et comment les ajouter ? Pour cela, imaginez une grande boîte en carton étalée devant vous. Vous posez un objet au centre puis, pour gagner de la place, vous le poussez soit vers le haut du carton, soit vers le bas. C'est exactement ce que nous allons faire avec nos widgets en les "poussant autant que possible" soit vers le début (le haut pour les VBox, la gauche pour les HBox), soit vers la fin (le bas ou la droite). Pour ajouter un widget par le haut de notre GTK_VBox, vous utiliserez la méthode Pack_start(). Pour ajouter un widget par le bas, vous utiliserez la méthode Pack_end().
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Box ; USE Gtk.Box ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Boite : Gtk_VBox ;
Btn1, Btn2, Btn3 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Boite verticale") ;
win.set_default_size(250,200) ;
Gtk_New_VBox(Boite,
homogeneous => true,
spacing => 3) ;
Win.Add(Boite) ;
Gtk_New(Btn1, "Bouton 1") ; Boite.Pack_End(Btn1) ;
Gtk_New(Btn2, "Bouton 2") ; Boite.Pack_End(Btn2) ;
Gtk_New(Btn3, "Bouton 3") ; Boite.Pack_End(Btn3) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Si vous testez le code ci-dessus, vous remarquerez que Btn1 est le premier bouton placé à la fin : ce sera donc le bouton le plus en bas.
Paramétrez vos widgets enfants
Maintenant, si vous avez regardé les spécifications de ces méthodes, vous aurez remarqué qu'elles comportent trois autres paramètres : Expand, Fill et Padding.
Vous savez désormais ce qu'est le padding, les méthodes Pack_End() et Pack_Start() vous proposent un Padding supplémentaire pour certains widget, Padding qui s'ajoute au Spacing de la boîte.
Le paramètre Expand, s'il vaut true, indique que l'encart contenant votre widget va pouvoir "prendre ses aises" et s'étendre autant qu'il le peut, même au détriment de ses camarades. Si la fenêtre est redimensionnée, l'encartle sera aussi. Ce paramètre n'a aucun intérêt si vous avez paramétré Homogeneous à true.
Le paramètre Fill, s'il vaut true, indique que le widget doit occuper tout l'espace disponible dans son encart. S'il vaut false, le widget se limitera à l'espace dont il a réellement besoin. Ce paramètre n'a d'intérêt que si Expand vaut true.
Cette fois, Expand = true et Fill = true, donc son encart prend toute la place disponible et le bouton remplit l'encart.
Avec plusieurs types de widgets
Un avantage des boîtes, c'est qu'elles peuvent contenir divers widgets, pas nécessairement de même type. Par exemple, nous allons remplacer le troisième bouton par un GTK_Label, c'est-à-dire une étiquette (du texte quoi) :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.Label ; USE Gtk.Label ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Boite : Gtk_VBox ;
Btn1, Btn2 : Gtk_Button ;
Lbl : GTK_Label ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Boite verticale") ;
win.set_default_size(250,200) ;
Gtk_New_VBox(Boite,
homogeneous => false,
spacing => 3) ;
Win.Add(Boite) ;
Gtk_New(Btn1, "Bouton 1") ; Boite.Pack_End(Btn1, Expand => false, Fill => false) ;
Gtk_New(Btn2, "Bouton 2") ; Boite.Pack_End(Btn2, Expand => true, Fill => true) ;
Gtk_New(Lbl, "Ceci est du texte") ; Boite.Pack_End(Lbl, Expand => False, Fill => False) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Avoir tous ces différents widgets ne posera pas de soucis à GTK ni à notre boîte.
Mélanger le tout
Ça veut dire que mes widgets seront soit à l'horizontale, soit à la verticale, mais qu'il n'y a pas moyen de panacher ... c'est un peu limité quand même. :(
Allons, soyez imaginatifs. Les conteneurs sont des widgets faits pour contenir d'autres widgets. Il n'est donc as interdit qu'un conteneur contienne un autre conteneur ! Par exemple, notre GTK_VBox, pourrait contenir une GTK_HBox à l'emplacement du bouton 2 !
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH GTK.Label ; USE Gtk.Label ;
WITH Gtk.Box ; USE Gtk.Box ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
VBoite : Gtk_HBox ;
HBoite : Gtk_HBox ;
Btn1, Btn2, Btn3 : Gtk_Button ;
lbl : Gtk_Label ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Boite horizontale") ;
win.set_default_size(250,200) ;
Gtk_New_VBox(VBoite,
homogeneous => false,
spacing => 3) ;
Win.Add(VBoite) ;
--On remplit la boite verticale
Gtk_New(Btn1, "Bouton 1") ;
Gtk_New_HBox(HBoite, homogeneous => false, Spacing => 3) ;
Gtk_New(Btn3, "Bouton 3") ;
VBoite.Pack_End(Btn1) ;
VBoite.Pack_End(HBoite) ;
VBoite.Pack_End(Btn3) ;
--On remplit la boite horizontale
Gtk_New(Btn2, "Bouton 2") ;
Gtk_New(Lbl, "Ceci est toujours du texte") ;
HBoite.Pack_Start(Btn2) ;
HBoite.Pack_Start(Lbl) ;
Win.Show_all ;
Main ;
END MaFenetre ;
La GTK_VBox rouge comprend deux boutons et une GTK_HBox bleue, laquelle contient une étiquette et un bouton.
Boîtes à boutons
Fiche d'identité
Widgets : GTK_HButton_Box et GTK_VButton_Box
Package : GTK.Button_Box, GTK.HButton_Box et GTK.VButton_Box
Description : Conteneurs spécifiquement prévu pour organiser les boutons de façon harmonieuse, horizontalement ou verticalement.
Créer et remplir une boîte à boutons
Nos boîtes, si elles sont très pratiques, ne sont malheureusement pas très esthétiques. Nos boutons sont soit écrasés soit énormes. Et cela ne s'arrange pas si l'on agrandit la fenêtre. Pour pallier à ce problème existe un deuxième type de boîte : les boîtes à boutons. Comme pour les boîtes classiques, il existe un modèle vertical et un modèle horizontal. Toutefois, chacun a son package spécifique. Celles-ci dérivant du type GTK_Button_Box, lui-même dérivant du type GTK_Box, les méthodes pack_end() et pack_start() vues précédemment restent valides :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.HButton_Box ; USE Gtk.HButton_Box ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Boite : Gtk_HButton_Box ;
Btn1, Btn2, Btn3 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Boite a boutons horizontale") ;
win.set_default_size(350,200) ;
Gtk_New(Boite) ;
Win.Add(Boite) ;
Gtk_New(Btn1, "Bouton 1") ; Boite.Pack_End(Btn1) ;
Gtk_New(Btn2, "Bouton 2") ; Boite.Pack_End(Btn2) ;
Gtk_New(Btn3, "Bouton 3") ; Boite.Pack_End(Btn3) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Malgré l'agrandissement de la fenêtre, les boutons gardent un aspect normal.
Paramétrages spécifiques à la boîte à boutons
Les boîtes à boutons présentent de nouveaux paramètres pour affiner la présentation. Tout d'abord avec la méthode Set_Layout() (package GTK.Button_Box) ou la méthode Set_Layout_Default() (packages GTK.HButton_Box et GTK.VButton_Box). Celles-ci proposent différents placements par défaut pour vos boutons. Ces placements sont de type Gtk.Enums.Gtk_Button_Box_Style (encore Gtk.Enums !) :
Gtk_Button_Box_Style
Aperçu
Buttonbox_Spread : les boutons sont placés de manière régulière dans la boîte.
Buttonbox_Edge : les boutons sont placés de manière régulière, mais le premier et le dernier boutons sont collés aux bords de la boîte.
Buttonbox_Start : les boutons sont placés le plus près possible du début de la boîte (le haut pour les boîtes verticales, la gauche pour les boîtes horizontales).
Buttonbox_End : les boutons sont placés le plus près possible de la fin de la boîte (le bas pour les boîtes verticales, la droite pour les boîtes horizontales).
Autre personnalisation possible : rendre secondaire certains boutons. Cela est souvent utiliser pour les boutons "Aide" ou "Options". Ces derniers sont mis à l'écart des autres. Les GTK_Button_Box permettent cela grâce à la méthode Set_Child_Secondary(). Par exemple, si nous modifions notre code pour que les boutons soient alignés sur la gauche et que le bouton n°3 soit secondaire, cela nous donnera :
En créant votre table, vous devrez indiquer le nombre de lignes (rows), de colonnes (columns) et indiquer si la table sera homogène (relire la partie sur les boîtes si vous avez déjà oublier ce que cela signifie). Pour information, les types Guint sont encore des types entiers comme les Gint et signifient "Glib Universal Integer". En cas d'erreur, vous pourrez toujours revoir ces paramètres à l'aide des deux méthodes suivantes :
Vous pouvez également régler l'écart entre les colonnes ou entre les lignes avec les deux méthodes ci-dessous. L'écart correspond bien entendu au nombre de pixels.
procedure Set_Col_Spacings --définit l'espace entre toutes les colonnes
(Table : access Gtk_Table_Record;
Spacing : Guint);
procedure Set_Col_Spacing --définit l'espace entre deux colonnes spécifiques
(Table : access Gtk_Table_Record;
Column : Guint;
Spacing : Guint);
procedure Set_Row_Spacings --définit l'espace entre toutes les lignes
(Table : access Gtk_Table_Record;
Spacing : Guint);
procedure Set_Row_Spacing --définit l'espace entre deux lignes spécifiques
(Table : access Gtk_Table_Record;
Row : Guint;
Spacing : Guint);
Voici le code initial de notre fenêtre :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Table ; USE Gtk.Table ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Tableau : Gtk_Table ;
Btn1, Btn2, Btn3 : Gtk_Button ;
Btn4, Btn5, Btn6 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Table a widgets") ;
win.set_default_size(350,200) ;
Gtk_New(Tableau,3,2,True) ;
Tableau.Set_Row_Spacings(1) ;
Tableau.Set_Col_Spacings(2) ;
Win.Add(Tableau) ;
--Nous ajouterons ici les boutons à notre table
Win.Show_all ;
Main ;
END MaFenetre ;
Ajouter des widgets
Avant de commencer à ajouter des boutons à notre table, vous devez savoir qu'un widget peut occuper plusieurs cases alors que son voisin n'en occupera qu'une seule. Cette liberté offerte au programmeur va quelque peu alourdir notre code car nous devrons renseigner où se situe les bords gauche, droite, haut et bas du widget. Pour comprendre de quoi je parle, regardez la spécification (allégée) de la méthode pour ajouter des widgets :
Vous devez vous imaginer que chaque bordure ou séparation de la table porte un numéro. La première bordure, celle du haut ou de gauche, porte le numéro 0. La bordure de droite porte le numéro du nombre de colonnes ; la bordure du bas porte le numéro du nombre de lignes :
Ainsi, on peut affirmer que le bouton n°2 s'étend de 0 à 1 horizontalement et de 1 à 2 verticalement, ce qui se traduit en langage Ada par :
Malheureusement, je vous ai bien dit que le constructeur que je vous avais transmis était allégé. Le véritable constructeur a plutôt cette spécification-là :
Vous vous souvenez du padding ? Nous l'avions vu avec les alignements. Il s'agit du nombre de pixels séparant le bord de l'encart et le widget qui s'y trouve. Xpadding indique donc l'écart horizontal, Ypadding l'écart vertical. Attention, le padding n'influe pas sur le conteneur (sauf si la fenêtre est trop petite) mais sur la taille du widget enfant.
Les paramètres Xoptions et Yoptions correspondent au comportement du widget à l'horizontale et à la verticale : notre bouton doit-il prendre le maximum ou le minimum de place ? Les valeurs possibles sont les suivantes (disponibles avec Gtk.Enums, encore et toujours) :
Expand : déjà vu avec les boîtes. Le widget tente de maximiser la place occupée par son encart. N'a vraiment de sens que pour une table non homogène.
Fill : déjà vu avec les boîtes. Le widget remplit entièrement l'encart qui lui est réservé.
Expand or fill : permet de combiner les deux caractéristiques précédentes. D'ailleurs, c'est la valeur par défaut du paramètre.
Shrink : indique que le widget ne prendra que la place strictement nécessaire.
Dans les faits, soit vous ne modifierez pas ces paramètres et votre bouton occupera tout l'espace alloué, soit vous utiliserez la valeur shrink pour restreindre la taille du widget au maximum. Modifions notre code pour y voir plus clair et supprimons l'un des boutons :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Table ; USE Gtk.Table ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Tableau : Gtk_Table ;
Btn1, Btn2, Btn3 : Gtk_Button ;
Btn4, Btn5 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Table a widgets") ;
win.set_default_size(350,200) ;
Gtk_New(Tableau,3,2,false) ;
Tableau.Set_Row_Spacings(1) ;
Tableau.Set_Col_Spacings(2) ;
Win.Add(Tableau) ;
Gtk_New(Btn1, "Bouton 1") ; Tableau.attach(Btn1,0,1,0,1, Xoptions => shrink,
Yoptions => fill) ;
Gtk_New(Btn2, "Bouton 2") ; Tableau.attach(Btn2,0,1,1,2, Xoptions => shrink,
Yoptions => shrink) ;
Gtk_New(Btn3, "Bouton 3") ; Tableau.attach(Btn3,0,1,2,3, Xoptions => fill,
Yoptions => fill) ;
Gtk_New(Btn4, "Bouton 4") ; Tableau.Attach(Btn4,1,2,0,1, Xpadding => 25,
Xoptions => fill,
Yoptions => shrink) ;
Gtk_New(Btn5, "Bouton 5") ; Tableau.Attach(Btn5,1,2,1,3, Xoptions => expand or fill,
Yoptions => expand or fill) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Je vous laisse comparer les effets des différents paramètres sur les boutons de ma nouvelle fenêtre :
Description : Conteneur de taille infinie permettant de positionner divers widgets à partir de coordonnées.
Utilisation des GTK_Fixed
Ce sera certainement le widget le plus simple de ce chapitre. Son constructeur se nomme simplement Gtk_New() et n'a aucun paramètre particulier. Pour positionner un widget à l'intérieur d'un GTK_Fixed, la méthode à employer s'appelle simplement put(). Ses paramètres sont simplement les coordonnées du coin supérieur gauche de votre widget. Exemple :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Fixed ; USE Gtk.Fixed ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Couche : Gtk_Fixed ;
Btn1, Btn2, Btn3 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Fixes") ;
win.set_default_size(150,100) ;
Gtk_New(Couche) ;
Win.Add(Couche) ;
Gtk_New(Btn1, "Bouton 1") ; Couche.put(Btn1,20,50) ;
Gtk_New(Btn2, "Bouton 2") ; Couche.put(Btn2,30,60) ;
Gtk_New(Btn3, "Bouton 3") ; Couche.put(Btn3,200,150) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Vous remarquerez deux choses : ce conteneur autorise le chevauchements de widgets. C'est à vous de faire en sorte qu'il n'y ait pas de souci d'affichage, ce qui est plus contraignant qu'avec les boîtes ou les tables. Ensuite, le Bouton n°3 aurait du être en dehors de la fenêtre, mais le GTK_Fixed a agrandi automatiquement la fenêtre pour pouvoir l'afficher. Nous verrons plus tard les GTK_Layout, un conteneur similaire qui, lui, ne s'embêtera pas avec cela.
Enfin, si l'un de vos widgets devait être déplacé, il suffirait d'utiliser la méthode move() qui fonctionne comme put().
En résumé :
Utilisez les GTK_Alignment pour positionner finement un unique widget.
Pour positionner plusieurs widgets, utilisez les GTK_Box, GTK_Button_Box ou GTK_Table.
Si vous avez besoin de positionner manuellement vos widgets (au pixel près) optez pour les GTK_Fixed mais pensez que le rendu ne sera pas forcément le même sur un autre ordinateur.
N'hésitez pas à imbriquer divers conteneurs les uns dans les autres pour obtenir la présentation souhaitée.
Maintenant que vous savez créer des fenêtres, les organiser, y ajouter des boutons ou des étiquettes, il est temps que tout cela agisse un petit peu. A quoi bon cliquer sur des boutons si rien ne se passe ? Nous allons devoir tout d'abord nous intéresser à la gestion bas niveau des évènements pour comprendre le fonctionnement de GTK. Puis nous retournerons au haut niveau et à la programmation évènementielle à proprement parler.
Ce chapitre est fondamental pour la suite, mais il est ardu. N'hésitez pas à le relire ou à revenir piocher dedans à l'avenir car il faut être précis sur les types ou sous-packages employés (et ils sont nombreux). GNAT sera impitoyable si vous ne respectez pas scrupuleusement mes conseils.
Le titre de cette partie commençait par "la programmation évènementielle", je crois. Eh bien on peut pas dire qu'il y ait beaucoup d'évènements dans nos programmes dernièrement. Comment je fais pour lancer mes procédures et fonctions ?
On serait tenté d'écrire ce genre de chose :
Le souci, c'est que tout notre code consiste à créer et paramétrer des widgets, les afficher et enfin lancer une boucle infinie (Main). Où écrire ces quelques lignes ? Le programme ne met que quelques millisecondes à créer les widgets et à les afficher, cela ne laisse pas vraiment le temps à l'utilisateur d'aller cliquer sur un bouton. Et puis un clic ne dure pas plus d'une seconde, comment faire pour que le programme exécute cette ligne de test durant cette fraction de seconde ? C'est impossible.
Le problème est même plus profond que cela. Nous codions jusqu'ici de manière linéaire. Certes, nous avions les conditions pour exécuter telle ou telle instruction, les boucles pour répéter ou pas certaines portions de code, les tâches pour exécuter plusieurs programmes en même temps. Mais tout cela restait très prévisible : l'utilisateur ne pouvait sortir du cadre très fermé que vous lui aviez concocté à grands coups de IF, CASE, LOOP, TASK ... Avec nos programmes fenêtrés, nous ne pouvons savoir quand l'utilisateur cliquera sur notre bouton, ni si il le fera, ni même s'il aura cliqué sur d'autres widgets auparavant. Vous êtes en réalité dans l'inconnu.
Et si on créait une grande boucle infinie qui testerait en continu les différentes actions possibles, comme nous l'avions fait au TP 4 ?
Une boucle infinie ? C'est une idée. Mais nous disposons déjà de ce genre de boucle : Main ! Main contrôle en permanence les différents widgets créés et vérifie s'ils ne sont pas cliqués, déplacés, survolés ... bref, Main attend le moindre évènement pour réagir.
Le principe Signal-Procédure de rappel
Pour comprendre comment faire agir nos widgets, vous devez comprendre le principe de fonctionnement bas-niveau de GTK. Lorsqu'un évènement se produit, par exemple lorsque l'utilisateur clique sur un bouton, un signal est émis.
Aussitôt, ce signal est intercepté par le Main qui va associer le widget et le type de signal émis à une procédure particulière, appelée procédure de rappel ou callback.
Mais comment Main peut-il savoir quelle procédure il doit appeler lorsque l'on clique sur un bouton ?
Pour que votre programme puisse faire le lien, il faut que vous ayez préalablement connecté le widget en question et son signal à cette fameuse procédure de rappel. C'est ce à quoi nous allons nous attacher maintenant.
Notre premier projet est simple : créer une fenêtre avec un unique bouton. Lorsque l'utilisateur cliquera sur le bouton ou sur le bouton de fermeture de la fenêtre, cela mettra fin au programme. Pour cela nous n'aurons pas à créer de procédure de rappel, nous ferons appel à des procédures préexistantes. Voici donc notre code de base (que vous devriez pouvoir déchiffrer seul désormais) :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
PROCEDURE MaFenetre IS
Win : Gtk_Window ;
Btn1 : Gtk_Button ;
BEGIN
Init ; --Initialisation de GTK
Gtk_New(Win,Window_Toplevel) ; --Création et paramétrage de la fenêtre
Win.Set_Title("Fenetre") ;
win.set_default_size(200,150) ;
Gtk_New_With_Mnemonic(Btn1, "_Exit") ; --Création d'un bouton et ajout à la fenêtre
win.add(Btn1) ;
Win.Show_all ; --Affichage et lancement de la boucle d'évènements
Main ;
END MaFenetre ;
Pour manipuler nos divers widget, nous aurons besoin du package Gtk.Handlers (le verbe anglais To handle signifiant manipuler). Attention ce package en lui-même ne contient presque rien d'utilisable. Si vous ouvrez ses spécifications vous vous rendrez compte qu'il contient en fait tout un ensemble d'autres sous-packages génériques. Je vous expliquerai les détails plus tard. Sachez pour l'instant que nous avons besoin du sous-package générique Gtk.Handlers.Callback. Il n'a qu'un seul paramètre de généricité : le type Widget_Type dont le nom me semble assez clair.
Nous devons donc l'instancier en créant un nouveau package P_Callback. Pour l'instant, nous n'allons fournir en paramètre que le type GTK_Window_Record et nous verrons pour le bouton un peu plus tard :
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Window_Record) ;
USE P_Callback ;
La procédure de connexion
Vous devriez trouver à la ligne 847 de Gtk.Handlers les spécifications d'une procédure essentielle :
procedure Connect
( Widget : access Widget_Type'Class;
Name : Glib.Signal_Name;
Cb : Simple_Handler;
After : Boolean := False);
C'est cette procédure qui va connecter le widget et le signal qu'il émet à une procédure. Il est important de bien regarder sa spécification si vous ne voulez pas que GNAT soit désagréable avec vous. ;) Tout d'abord le widget : on attend un pointeur sur une classe de widget. Autrement dit, dans notre cas présent, un objet de type GTK_Window (et pas GTK_Window_Record). Ensuite, le paramètre Name correspond au nom du signal émis. Ce nom est en fait un simple string que je vous donnerai. Le dernier paramètre (After) ne nous servira que si vous voulez imposer que la connexion ne se fasse qu'une fois toutes les connexions par défaut effectuées. Bref, aucun intérêt à notre niveau. Enfin, nous arrivons au paramètre Cb de type Simple_Handler. Ce type correspond à un pointeur sur une procédure prenant en paramètre un pointeur sur une classe de widget (le widget grâce auquel vous avez instancié Gtk.Handlers.Callback). C'est donc ce paramètre qui enregistrera la procédure à connecter.
La procédure de rappel
Nous allons créer une procédure pour sortir de la boucle d'évènements : Stop_Program. Cette procédure utilisera l'instruction Main_Quit qui met fin au Main. La logique voudrait que cette procédure n'ait aucun paramètre. Pourtant, si j'ai préalablement attiré votre attention sur la procédure connect(), c'est pour que vous compreniez comment définir votre callback. connect() va non seulement connecter un signal à une procédure, mais il transmettra également le widget appelant à ladite procédure si ce signal est détecté. Nous voilà donc obligé d'ajouter un paramètre à notre callback. Quant à son type, il suffit de regarder les spécifications de connect() pour le connaître : access Widget_Type'Class ! Ce qui nous donnera :
PROCEDURE Stop_Program(Emetteur : access Gtk_Window_Record'class) IS
BEGIN
Main_Quit;
END Stop_Program ;
Si vous compiler, GNAT ne cessera de vous dire : "warning : formal parameter "Emetteur" is not referenced". Alors pour lui indiquer que le paramètre Emetteur est sciemment inutilisé, vous pourrez ajouter le pragma unreferenced :
PROCEDURE Stop_Program(Emetteur : access Gtk_Window_Record'class) IS
PRAGMA Unreferenced (Emetteur);
BEGIN
Main_Quit;
END Stop_Program ;
La connexion, enfin !
Le package est instancié et le callback rédigé. Il ne reste plus qu'à effectuer la connexion à l'aide de la procédure vue plus haut. Pour cela, vous devez connaître le nom du signal de fermeture de la fenêtre : "destroy". Ce signal est envoyé par n'importe quel widget lorsqu'il est détruit. Notre code donne donc :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Handlers ;
PROCEDURE MaFenetre IS
--Instanciation du package pour la connexion
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Window_Record) ;
USE P_Callback ;
--Notre callback
PROCEDURE Stop_Program(Emetteur : access Gtk_Window_Record'class) IS
PRAGMA Unreferenced (Emetteur);
BEGIN
Main_Quit;
END Stop_Program ;
Win : Gtk_Window ;
Btn1 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Fenetre") ;
win.set_default_size(200,150) ;
Gtk_New_With_Mnemonic(Btn1, "_Exit") ;
win.add(Btn1) ;
--Connexion du signal "destroy" avec le callback Stop_program
--Pensez que le signal est un string, non un type énuméré
--N'oubliez pas que le 3° paramètre doit être un pointeur
connect(win, "destroy", Stop_Program'access) ;
--en cas de souci, essayez ceci :
--connect(win, "destroy", to_Marshaller(Stop_Program'access)) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Utiliser le bouton
Nous voudrions maintenant pouvoir faire de même avec notre bouton. Le souci, c'est que la procédure connect() a pour nom complet P_Callback.connect() et que le package P_Callback a été instancié pour les objets de la classe GTK_Window_Record'class. Deux solutions s'offrent à nous : soit créer un second package P_Callback_Button, soit améliorer le premier.
J'opte pour la deuxième méthode. Il suffit d'utiliser une classe commune aux GTK_Window_Record et aux GTK_Button_Record. Vous savez désormais que fenêtres et boutons sont deux widgets. Nous pourrions donc utiliser la classe GTK_Widget_Record'class et citer le package Gtk.Widget. Mais nous savons également que ce sont deux conteneurs (GTK_Container_Record'class) et même des conteneurs pour un seul élément (GTK_Bin_Record'class). Nous pouvons donc généraliser notre package de trois façons différentes. Les voici, de la plus restrictive à la plus large :
WITH Gtk.Bin ; USE Gtk.Bin ;
...
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Bin_Record) ;
USE P_Callback ;
PROCEDURE Stop_Program(Emetteur : access Gtk_Bin_Record'class) IS ...
-- OU
WITH Gtk.Container ; USE Gtk.Container ;
...
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Container_Record) ;
USE P_Callback ;
PROCEDURE Stop_Program(Emetteur : access Gtk_Container_Record'class) IS ...
-- OU
WITH Gtk.Widget ; USE Gtk.Widget ;
...
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Widget_Record) ;
USE P_Callback ;
PROCEDURE Stop_Program(Emetteur : access Gtk_Widget_Record'class) IS ...
Ne reste plus qu'à effectuer la connexion. Si peu de signaux sont intéressants pour l'instant avec les fenêtres, avec les boutons, nous avons davantage de choix. Voici quelques signaux :
"clicked" : le bouton a été cliqué, c'est à dire enfoncé puis relâché.
"pressed" : le bouton a été enfoncé
"released" : le bouton a été relâché
"enter" : la souris survole le bouton
"leave" : la souris ne survole plus le bouton
Voici ce que donnerait notre programme :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Bin ; USE Gtk.Bin ;
WITH Gtk.Handlers ;
PROCEDURE MaFenetre IS
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Bin_Record) ;
USE P_Callback ;
PROCEDURE Stop_Program(Emetteur : access Gtk_Bin_Record'class) IS
PRAGMA Unreferenced (Emetteur);
BEGIN
Main_Quit;
END Stop_Program ;
Win : Gtk_Window ;
Btn1 : Gtk_Button ;
BEGIN
Init ;
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Fenetre") ;
win.set_default_size(200,150) ;
Gtk_New_With_Mnemonic(Btn1, "_Exit") ;
Win.Add(Btn1) ;
Connect(Win, "destroy", To_Marshaller(Stop_Program'ACCESS)) ;
Connect(Btn1, "clicked", To_Marshaller(Stop_Program'ACCESS)) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Fermer le programme, c'est facile : il suffit d'une seule instruction. Mais comment je fais si je veux créer des callbacks modifiant d'autres widgets ?
Pour y voir clair, nous allons créer un programme "Hello world". L'idée est simple : notre fenêtre affichera une étiquette nous saluant uniquement si nous appuyons sur un bouton. Nous avons donc besoin de créer une fenêtre contenant une étiquette, un bouton et bien-sûr un conteneur :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Label ; USE Gtk.Label ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.widget ; USE Gtk.widget ;
WITH Gtk.Handlers ;
PROCEDURE MaFenetre IS
--SOUS PACKAGES POUR MANIPULER LES CALLBACKS
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Widget_Record) ;
USE P_Callback ;
--CALLBACKS
PROCEDURE Stop_Program(Emetteur : access Gtk_widget_Record'class) IS
PRAGMA Unreferenced (Emetteur );
BEGIN
Main_Quit;
END Stop_Program ;
--WIDGETS
Win : Gtk_Window ;
Btn : Gtk_Button ;
Lbl : Gtk_Label ;
Box : Gtk_Vbox ;
BEGIN
Init ;
--CREATION DE LA FENETRE
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Fenetre") ;
win.set_default_size(200,150) ;
--CREATION DU BOUTON ET DE L'ETIQUETTE
Gtk_New_With_Mnemonic(Btn, "Dis _bonjour !") ;
Gtk_New(Lbl,"") ;
--CREATION DE LA BOITE
Gtk_New_Vbox(Box) ;
Box.Pack_Start(Lbl) ;
Box.Pack_Start(Btn) ;
Win.Add(Box) ;
--CONNEXION AVEC LE CALLBACK DE FERMETURE
Connect(Win, "destroy", Stop_Program'ACCESS) ;
Win.Show_all ;
Main ;
END MaFenetre ;
Ce code n'est pas très compliqué, vous devriez pouvoir le comprendre seuls. Maintenant, nous allons créer un callback supplémentaire appelé Dis_Bonjour() qui modifiera une étiquette (ne nous préoccupons pas de la connexion pour l'instant) :
PROCEDURE Dis_Bonjour(Emetteur : ACCESS GTK_Widget_Record'Class ;
Label : Gtk_Label) IS
PRAGMA Unreferenced(Emetteur) ;
BEGIN
IF Label.Get_Text'Length = 0
THEN Label.Set_Text("Hello world !") ;
else Label.Set_Text("Ouais, ouais ... salut !") ;
END IF ;
END Dis_Bonjour;
J'utilise deux méthodes de la classe GTK_Label_Record : Set_text() qui modifie le texte de l'étiquette et Get_Text() qui renvoie le contenu. Rien de bien compliqué mais un souci toutefois : nous avons besoin de deux paramètres !
Un nouveau package de callbacks
Or, pour l'instant notre package P_Callback n'est instancié qu'avec un seul type : la classe GTK_Widget_Record du widget émetteur. Cela signifie que nos callbacks ne peuvent avoir qu'un unique paramètre de ce même type. Comment faire pour accéder à un second widget ? Plusieurs solutions s'offrent à vous. L'une d'elles consiste à placer nos widgets dans un package spécifique pour en faire des variables globales et ainsi ne plus avoir à les déclarer comme paramètre formel de nos méthodes. Vous pourrez ainsi facilement accéder à votre GTK_Label. Toutefois, vous savez que je n'aime pas abuser des variables globales. D'autant plus que les GTK_Widget, GTK_Button ou GTK_Label sont, vous le savez des pointeurs généralisés : nous multiplions les prises de risque.
Pour résoudre ce dilemne, GtkAda fournit toute une série de package pour nos callbacks. L'un d'entre eux, Gtk.Handlers.User_Callback permet de passer une paramètre supplémentaire à nos procédures de connexion (il faut donc l'instancier à l'aide de deux types). Ces deux paramètres sont simplement ceux fournis à notre callback : GTK_Widget_Record pour l'émetteur (le premier paramètre de notre callback est un pointeur vers ce type) ; GTK_Label pour le second paramètre. D'où la définition :
PACKAGE P_UCallback IS NEW Gtk.Handlers.User_Callback(Gtk_Widget_Record,Gtk_Label) ;
USE P_Ucallback ;
La connexion
La connexion se fait de la même manière que précédemment : en utilisant la procédure connect(). Toutefois celle-ci admettra un paramètre supplémentaire :
procedure Connect(
Widget : access Widget_Type'Class;
Name : Glib.Signal_Name;
Marsh : Marshallers.Marshaller;
User_Data : User_Type;
After : Boolean := False);
On retrouve les paramètres habituels, sauf User_Data qui ici correspond au type GTK_Label employé par votre callback. Voici ce que donne notre code :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Label ; USE Gtk.Label ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.widget ; USE Gtk.widget ;
WITH Gtk.Handlers ;
PROCEDURE MaFenetre IS
--SOUS PACKAGES POUR MANIPULER LES CALLBACKS
PACKAGE P_Callback IS NEW Gtk.Handlers.Callback(Gtk_Widget_Record) ;
USE P_Callback ;
PACKAGE P_UCallback IS NEW Gtk.Handlers.User_Callback(Gtk_Widget_Record, Gtk_Label) ;
USE P_Ucallback ;
--CALLBACKS
PROCEDURE Stop_Program(Emetteur : access Gtk_widget_Record'class) IS
PRAGMA Unreferenced (Emetteur );
BEGIN
Main_Quit;
END Stop_Program ;
PROCEDURE Dis_Bonjour(Emetteur : ACCESS GTK_Widget_Record'Class ;
Label : GTK_Label) IS
PRAGMA Unreferenced(Emetteur ) ;
BEGIN
IF String(Label.Get_Text)'Length = 0
THEN Label.Set_Text("Hello world !") ;
else Label.Set_Text("Ouais, ouais ... salut !") ;
END IF ;
END Dis_Bonjour;
--WIDGETS
Win : Gtk_Window ;
Btn : Gtk_Button ;
Lbl : Gtk_Label ;
Box : Gtk_Vbox ;
BEGIN
Init ;
--CREATION DE LA FENETRE
Gtk_New(Win,Window_Toplevel) ;
Win.Set_Title("Fenetre") ;
win.set_default_size(200,150) ;
--CREATION DU BOUTON ET DE L'ETIQUETTE
Gtk_New_With_Mnemonic(Btn, "Dis _bonjour !") ;
Gtk_New(Lbl,"") ;
--CREATION DE LA BOITE
Gtk_New_Vbox(Box) ;
Box.Pack_Start(Lbl) ;
Box.Pack_Start(Btn) ;
Win.Add(Box) ;
--CONNEXION AVEC LES CALLBACKS
Connect(Win, "destroy", Stop_Program'ACCESS) ;
Connect(Btn, "clicked", Dis_Bonjour'ACCESS, Lbl);
Win.Show_all ;
Main ;
END MaFenetre ;
Perfectionner encore notre code
Mais ... ça veut dire que si je voulais ajouter un deuxième bouton qui modifierait un autre widget (une image par exemple), il faudrait créer un nouveau sous package du genre : PACKAGE P_UCallback2 IS NEW Gtk.Handlers.User_Callback(Gtk_Widget_Record, Un_Autre_Type_De_Widget) ; ! Ça va devenir encombrant à la longue tous ces packages. :(
Vous avez raison, nous devons optimiser notre code pour ne pas créer plusieurs instances d'un même package. Et pour cela, nous allons réutiliser les types contrôlés ! Si, comme je vous l'avais conseillé, vous placez tous vos widgets dans un type contrôlé, accompagné d'un méthode Initialize(), vous n'aurez dès lors plus qu'une seule instanciation à effectuer :
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Label ; USE Gtk.Label ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.Widget ; USE Gtk.Widget ;
WITH Ada.Finalization ; USE Ada.Finalization ;
WITH Gtk.Handlers ;
PACKAGE P_Fenetre IS
TYPE T_Fenetre IS NEW Controlled WITH RECORD
Win : Gtk_Window ;
Btn : Gtk_Button ;
Lbl : Gtk_Label ;
Box : Gtk_Vbox ;
END RECORD ;
PROCEDURE Initialize(F : IN OUT T_Fenetre) ;
PACKAGE P_Handlers IS NEW Gtk.Handlers.Callback(Gtk_Widget_Record) ;
USE P_Handlers ;
PACKAGE P_UHandlers IS NEW Gtk.Handlers.User_Callback(Gtk_Widget_Record,T_Fenetre) ;
use P_UHandlers ;
END P_Fenetre ;
WITH Gtk.Main ; USE Gtk.Main ;
WITH P_Callbacks ; USE P_Callbacks ;
PACKAGE BODY P_Fenetre IS
PROCEDURE Initialize(F : IN OUT T_Fenetre) IS
BEGIN
Init ;
Gtk_New(GTK_Window(F.Win),Window_Toplevel) ;
F.Win.Set_Title("Fenetre") ;
F.win.set_default_size(200,150) ;
Gtk_New_With_Mnemonic(F.Btn, "Dis _bonjour !") ;
Gtk_New(F.Lbl,"") ;
Gtk_New_Vbox(F.Box) ;
F.Box.Pack_Start(F.Lbl) ;
F.Box.Pack_Start(F.Btn) ;
F.Win.Add(F.Box) ;
Connect(F.Win, "destroy", Stop_Program'ACCESS) ;
Connect(F.Btn, "clicked", Dis_Bonjour'ACCESS, F) ;
F.Win.Show_all ;
END Initialize ;
END P_Fenetre ;
WITH Gtk.Widget ; USE Gtk.Widget ;
with P_Fenetre ; use P_Fenetre ;
PACKAGE P_Callbacks IS
PROCEDURE Stop_Program(Emetteur : access Gtk_widget_Record'class) ;
PROCEDURE Dis_Bonjour(Emetteur : ACCESS GTK_Widget_Record'Class ;
F : T_Fenetre) ;
END P_Callbacks ;
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Label ; USE Gtk.Label ;
PACKAGE BODY P_Callbacks IS
PROCEDURE Stop_Program(Emetteur : access Gtk_widget_Record'class) IS
PRAGMA Unreferenced (Emetteur );
BEGIN
Main_Quit;
END Stop_Program ;
PROCEDURE Dis_Bonjour(Emetteur : ACCESS GTK_Widget_Record'Class ;
F : T_Fenetre) IS
PRAGMA Unreferenced(Emetteur ) ;
BEGIN
IF F.Lbl.Get_Text'Length = 0
THEN F.Lbl.Set_Text("Hello world !") ;
else F.Lbl.Set_Text("Ouais, ouais ... salut !") ;
END IF ;
END Dis_Bonjour;
END P_Callbacks ;
WITH Gtk.Main ; USE Gtk.Main ;
WITH P_Fenetre ; USE P_Fenetre ;
PROCEDURE MaFenetre IS
F : T_Fenetre ;
pragma Unreferenced(F) ;
BEGIN
Main ;
END MaFenetre ;
Autres packages de callback
A quoi servent les autres sous-packages de Gtk.Handlers ?
Le package Gtk.Handlers comprend 6 sous-packages de callback :
Return_Callback : ce package permet d'employer des fonctions comme callbacks et pas des procédures. Elle prend en paramètre le type de widget émetteur, bien entendu, ainsi que le type des résultats retournés par les fonctions.
User_Return_Callback : similaire au package User_Callback utilisé dans cette sous-partie, mais pour des fonctions de rappel, il prend en paramètre la classe du widget émetteur, le type des résultats retournés par les fonctions de rappel, ainsi que le type User_Type du paramètre supplémentaire (notre GTK_Label dans l'exemple ci-dessus).
User_Return_Callback_With_Setup : similaire au package précédent, il permet toutefois de fournir une procédure d'initialisation des objets de type User_Type.
Callback : vu dans la sous-partie n°2.
User_Callback : vu dans la sous-partie n°3.
User_Callback_With_Setup : similaire au package User_Callback mais fournissant une procédure d'initialisation des objets de type User_Type.
En résumé :
Tout évènement sur un widget, aussi anodin soit-il, déclenche l'émission d'un signal.C'est la capture de ce signal qui va permettre le déclenchement d'une procédure de rappel ou callback.
Tout callback doit être connecté à un widget et un signal. Cela se fait grâce aux procédures connect() disponibles dans les sous-packages de Gtk.Handlers.
Pour obtenir des interactions entre les différents widgets, vous pouvez utiliser le package Gtk.Handlers.User_Callback.
Faites appel aux types contrôlés et à vos connaissances en POO pour simplifier votre développement.
Nous avons dors et déjà découvert de nombreux widgets : fenêtres, boutons, étiquettes ainsi que quatre conteneurs. Mais nous sommes loin d'avoir tout vu. Si je n'ai pas la prétention de vous faire découvrir toutes les possibilités de Gtk, je ne peux tout de même pas vous abandonner avec si peu de widgets dans votre sac. ;) Je vous propose de faire le tour des widgets suivants :
Les étiquettes (nous allons approfondir ce que nous avons déjà vu)
Les images
Les zones de saisie : à une ligne, à plusieurs lignes, numériques
De nouveaux boutons : à bascule, à cocher, liens, radios
Les boîtes de dialogue
Les séparateurs, les flèches, le calendrier et la barre de progression
Ce chapitre sera, j'en suis désolé, un véritable catalogue. Pour ne pas le rendre indigeste, j'ai tenté de l'organiser pour que vous puissiez facilement venir y piocher ce dont vous aurez besoin. Cette liste de widgets sera complétée ultérieurement par un second chapitre sur les widgets, un second sur les conteneurs et enfin par un dernier chapitre sur les barres et menus.
On connaît déjà les étiquettes. Pourquoi en reparler ?
Nous en reparlons pour deuxraisons :
Nous n'avons vu que peu de méthodes applicables aux GTK_Label.
Il est possible d'utiliser des caractères accentués dans vos GTK_Label mais si vous avez tenté, vous avez du remarquer la levée d'une exception. Il est également possible de mettre le texte en forme.
Fiche d'identité
Widget : GTK_Label
Package : Gtk.Label
Descendance : GTK_Widget >> GTK_Misc
Description : L'étiquette est une zone texte que l'utilisateur ne peut pas modifier. Cette zone peut être mise en forme à volonté.
Quelques méthodes des GTK_Label
Constructeurs
Pour l'instant, tout ce que nous avons vu à propos des étiquettes, c'est le constructeur GTK_New(). Vous aurez remarqué qu'il prend deux paramètres : le GTK_Label, bien évidemment, suivi d'un string correspondant à la phrase à afficher. Il est également possible de souligner un caractère avec la méthode GTK_New_With_Mnemonic() :
GTK_New_With_Mnemonic(Lbl,"Cliquez sur _A.") ;
La ligne de code ci-dessus affichera le texte : Cliquez sur A. La règle est la même que pour les boutons. Voyons maintenant quelques-unes des méthodes de base des étiquettes :
La méthode Set_Label() permet de redéfinir le contenu de l'étiquette, tandis que Get_Label() permet d'accéder à son contenu. L'ancien contenu est alors écrasé. Set_Selectable() autorise (ou non) l'utilisateur à sélectionner le texte du label. Par défaut, le texte n'est pas sélectionnable. La méthode Set_Use_Underline() permet, si cela n'a pas été fait, de souligner les lettres précédées d'un underscore. Enfin, la méthode Set_Angle() permet de définir l'orientation du texte de 0° à 360° (position normales). La mesure de l'angle est donnée en degrés et non en radians.
Une première mise en forme
Il est possible d'afficher un texte sur plusieurs lignes. Pour cela, je vous conseille de vous créer une constante : newline : constant character := character'val(10) ;. Si votre texte doit comporter plusieurs lignes, il serait bon de déclarer préalablement votre texte dans une variable de type string pour plus de clarté, en utilisant le symbole de concaténation. Exemple :
Txt : string := "Ceci est du texte" & newline &
"avec un retour a la ligne" & newline &
"pour la mise en forme."
Dès lors que votre texte s'étend sur plusieurs lignes, il est possible de régler l'alignement du texte : aligné à gauche, à droite, centré ou justifié. Cela se fait à l'aide de la méthode procedure Set_Justify (Label : access Gtk_Label_Record; Jtype : Gtk.Enums.Gtk_Justification);. Le paramètre Jtype (dont le type GTK_Justification est, encore une fois, accessible via le package Gtk.Enums) peut prendre les valeurs suivantes :
Justify_Left : le texte sera ligné à gauche
Justify_Right : le texte sera ligné à droite
Justify_Center : le texte sera centré
Justify_Fill : le texte sera justifié, c'est à dire aligné à gauche et à droite.
Pour une mise en forme plus poussée
Les accents
J'en ai marre de voir plein d'erreurs levées dès que j'écris un 'é' ou un 'à' ! Il n'y aurait pas un moyen simple d'écrire normalement ?
Bien sûr que si. Gtk gère de très nombreux caractères et notamment les caractères latins accentués. Pour cela il utilise la norme Unicode et plus notamment l'encodage UTF-8. Pour faire simple (et réducteur, mais ce n'est pas le sujet de ce chapitre), il s'agit d'une façon de coder les caractères à la manière du code ASCII vu durant la partie IV. Si vous vous souvenez bien, le code ASCII utilisait 7 bits, les codes ASCII étendus utilisant eux 8 bits soit un octet. L'ASCII avait le gros inconvénient de ne proposer que des caractères anglo-saxons. Les ASCII étendus avaient eux l'inconvénient de ne pas être transposables d'un pays à l'autre (les caractères d'Europe de l'ouest ne convenant pas à l'Europe orientale). Le codage UTF-8 utilise quant à lui jusqu'à 4 octets (soit 32 bits, ce qui fait caractères possibles) réglant ainsi la plupart de ces inconvénients et permettant même l'usage de caractères arabes, tibétains, arméniens ...
Pour convertir proprement nos string en UTF-8, nous allons utiliser le package Glib.Convert et la fonction Locale_To_UTF8() qui convertit un string encodé dans le format "local" en string encodé en UTF-8 :
function Locale_To_UTF8(OS_String : String) return String;
Voici un exemple simplissime de code permettant l'emploi de caractères "bien de chez nous" :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Label ; USE Gtk.Label ;
WITH Glib.Convert ; USE Glib.Convert ;
WITH Gtk.Enums ; USE Gtk.Enums ;
PROCEDURE Texte IS
Win : Gtk_Window;
Lbl : Gtk_Label ;
newline : constant character := character'val(10) ;
Txt : CONSTANT String := Locale_To_Utf8(
"Ça c'est une chaîne de" & Newline &
"caractères encodée en UTF-8" & Newline &
"grâce à Locale_To_UTF8") ;
BEGIN
Init ;
Gtk_New(Win) ;
Win.Set_Default_Size(100,100) ;
win.set_title("Du texte !") ;
Gtk_New(Lbl,txt) ;
Lbl.Set_Justify(Justify_center) ;
win.add(lbl) ;
Win.show_all ;
Main ;
END Texte ;
La mise en forme avec Pango
Venons-en maintenant à la "vraie" mise en forme : gras, italique, souligné, barré, taille 5 ou 40, police personnalisée ... car oui ! Tout cela est possible avec Gtk ! Pour cela, une seule méthode sera utile : procedure Set_Use_Markup(Label : access Gtk_Label_Record ; Setting : Boolean). Il suffit que le paramètre Setting vaille true pour pouvoir appliquer ces mises en forme.
Reste maintenant à appliquer ces mises en forme. Pour cela, Gtk fait appel à la librairie Pango et à son langage à balise (Pango Markup Language).
Houlà ! Je ne comprenais déjà pas ce que voulait dire Set_Use_Markup mais là j'avoue que je me sens dépassé. :(
Le langage à balise de Pango, est un langage proche du HTML. Il consiste à placer des mots clés dans votre texte afin d'encadrer les zones bénéficiant d'une mise en forme particulière. Par exemple : "Ceci est un texte avec BALISE_DEBUT mise en forme BALISE_FIN". Les balises répondent toutefois à quelques règles. La balise ouvrante (celle du début) se note plus exactement entre deux chevrons : <NOM_DE_BALISE>. La balise fermante se note elle aussi entre deux chevrons mais est également précédée d'un slash : </NOM_DE_BALISE>. L'exemple ci-dessus donnerait donc : "Ceci est un texte avec <NOM_DE_BALISE>mise en forme</NOM_DE_BALISE>". Ainsi, les trois derniers mots bénéficieront des atouts apportés par la balise. Le principe du langage à balise est notamment utilisé en HTML ou XML.
Balises simples
Mais que dois-je écrire dans ces fameuses balise ?
Balise
Signification
Exemple
<b>
Gras (bold)
<i>
Italique (italic)
<u>
souligné (underlined)
<s>
barré (strikened)
<sub>
en indice
<sup>
en exposant
<small>
petite taille
<big>
grande taille
<tt>
télétype
Balise <span>
Une dernière balise existe, à savoir <span>. Mais son utilisation est particulière. Seule, elle ne sert à rein, il faut y ajouter des attributs. Les attributs sont écrits à l'intérieur des chevrons de la balise ouvrante. Ils constituent des paramètres que l'on peut renseigner. Exemple : <span attribut1='valeur n°1' attribut2='valeur n°2' ...></span>. Le nombre d'attributs n'est pas limité, vous pouvez tout autant n'en écrire qu'un seul qu'en écrire une dizaine. Vous remarquerez également que la valeur assignée à un attribut doit être écrite entre apostrophes.
Voici quelques-uns des attributs utilisables avec la balise <span> :
Attribut
Valeurs possibles
Signification
Exemple
font_family, face
'Times new Roman', 'Arial', 'Comic sans ms' ...
Indique la police utilisée
size
Valeurs absolues : 'xx-small', 'x-small', 'small', 'medium', 'large', 'x-large', 'xx-large' Valeurs relatives : 'smaller', 'larger' (plus petit et plus grand)
Indique la taille d'écriture
font_desc
Exemples : 'Arial 15', 'Comic sans ms 25' ...
Indique la police et la taille d'écriture
style
'normal', 'oblique', 'italic'
Indique l'obliquité du texte
weight
'ultralight', 'light', 'normal', 'bold', 'ultrabold', 'heavy' ou une valeur numérique
Indique le niveau de gras du texte
underline
'single', 'double', 'low', 'error'
Indique le type de soulignement (simple, double, bas ou ondulé façon faute d'orthographe)
foreground
Vous pouvez soit entrer la valeur RGB en hexadécimal (exemple :'#6600FF' pour un violet) soit utilisé des noms de couleur préenregistrés (exemple : 'red'). Pour trouver des valeurs hexadécimales de couleur, utilisez soit un logiciel de graphisme soit le lien wikipedia suivant.
Description : Ce widget, comme son nom l'indique, affiche une image. Ce peut être un icône, un gif animé comme une photo de vacances au format JPEG.
Méthodes
Avec vos propres images
Comme pour tous les widgets nous disposons d'une méthode GTK_New pour initialiser notre GTK_Image. Plus exactement, nous disposons de deux méthodes :
procedure Gtk_New(Image : out Gtk_Image) ;
procedure Gtk_New(Image : out Gtk_Image;
Filename : UTF8_String) ;
La première ne fait que créer le widget sans y affecter de fichier image. Nous utiliserons de préférence la seconde méthode afin d'indiquer immédiatement l'adresse (relative ou absolue) du fichier image. Exemple avec l'image ci-dessous :
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Image ; USE Gtk.Image ;
PROCEDURE Image IS
Win : Gtk_Window;
Img : Gtk_Image ;
BEGIN
Init ;
Gtk_New(Win) ;
Win.Set_Default_Size(400,300) ;
win.set_title("Une image ! ") ;
Gtk_New(Img,"./picture.png") ;
win.add(Img) ;
Win.show_all ;
Main ;
END Image ;
Si vous optez pour la première méthode ou si vous souhaitez changer l'image, il vous faudra tout de même spécifier le chemin d'accès à l'image désirée grâce à la méthode set() :
De même, si vous souhaitez modifier une image, il sera préférable de l'effacer auparavant grâce à la méthode clear() :
procedure Clear(Image : access Gtk_Image_Record);
A partir d'icônes pré-stockés
Il existe plusieurs autres façons de charger une image : à partir d'une Gdk_Pixmap, d'un Gdk_Pixbuf_Record'class, d'une Gdk_Image, d'un GIcon ... vous n'étudierez la plupart de ces solutions que dans des cas bien précis. Mais il est une façon qui pourrait vous être utile. Gtk étant personnalisable, il dispose de thèmes graphiques ; lesquels thèmes comprennent également des thèmes d'icônes préenregistrés : les GTK_Stock_Item, disponibles via le package Gtk.Stock. Ce package fournit également tout un lot de chaînes de caractères constantes. Et cela tombe bien car Gtk.Image nous propose une autre méthode Gtk_New :
Comme vous pouvez le constater, cette dernière attend comme paramètre une chaîne de caractères (UTF8_String) appelée Stock_Id. Cette méthode se chargera d'utiliser les sous-programmes fournis par le package Gtk.Stock afin de convertir cette chaîne de caractères en un GTK_Stock_Item. Ainsi, en écrivant :
Gtk_New(Img,Stock_Cancel,...) ;
Vous obtiendrez l'icône suivant :
.
C'est bien gentil, mais tu n'as pas renseigné le dernier paramètre : Size. Je mets quoi comme taille, moi ?
Le type Gtk_Icon_Size, n'est rien d'autre qu'un nombre entier naturel. Mais si vous jetez un coup d’œil au package Gtk.Enums vous y découvrirez les tailles suivantes, classées de la plus petite à la plus grande :
Icon_Size_Invalid : taille utilisée par Gtk pour indiquer qu'une taille n'est pas valide. Inutile pour vous.
Icon_Size_Menu : taille utilisée pour les menus déroulants.
Icon_Size_Small_Toolbar : taille utilisée pour les barres d'icônes.
Icon_Size_Large_Toolbar : idem mais pour des barres utilisant de grands icônes.
Icon_Size_Button : taille utilisée pour les boutons.
Icon_Size_Dnd : taille utilisée pour le drag & drop, c'est à dire le glisser-déposer.
Icon_Size_Dialog : taille utilisée pour les boîtes de dialogue.
Enfin, je vous livre les images de quelques icônes, mais je vous invite bien sûr à les essayer par vous-mêmes en lisant le package Gtk.Stock :
Nom de l'icône
Image
Stock_Apply
Stock_Cancel
Stock_Dialog_Info
Stock_Directory
Stock_Floppy
Stock_Ok
Exercice : créer un bouton avec icône
Pour égayer ce cours, voici un petit exercice : comment créer un bouton comportant à la fois du texte, mais également un icône comme celui ci-dessous :
Un indice ? Rappelez-vous d'une petite phrase prononcée au début du chapitre sur les conteneurs. Je vous avais alors dit que les fenêtres et les boutons étaient des GTK_Container. Autrement dit, un bouton peut, tout autant qu'une boîte ou un alignement, contenir du texte, des images, d'autres conteneurs ou widgets. A vous de jouer.
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Gtk.Image ; USE Gtk.Image ;
WITH Gtk.Label ; USE Gtk.Label ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.Enums ; USE Gtk.Enums ;
with gtk.fixed ; use gtk.fixed ;
PROCEDURE Bouton_A_Image IS
--On crée un type T_Button contenant tous les widgets nécessaires
--Vous pouvez également en faire un type contrôlé
TYPE T_Button IS RECORD
Btn : Gtk_Button ;
Box : Gtk_HBox ;
Lbl : Gtk_Label ;
Img : Gtk_Image ;
END RECORD ;
--Procédure d'initialisation du type T_Button
PROCEDURE GTK_New(B : IN OUT T_Button ; Texte : String ; Adresse : String) IS
BEGIN
Gtk_New(B.Btn) ;
Gtk_New_HBox(B.Box) ;
Gtk_New(B.Lbl, Texte) ;
Gtk_New(B.Img, Adresse) ;
B.Btn.Add(B.Box) ;
B.Box.Pack_Start(B.Img) ;
B.Box.pack_start(B.Lbl) ;
END GTK_New ;
B : T_Button ;
F : Gtk_Fixed ;
Win : Gtk_Window;
BEGIN
Init ;
Gtk_New(Win) ;
Win.Set_Default_Size(400,300) ;
Win.Set_Title("Un bouton perso ! ") ;
--on crée ici un conteneur de type GTK_Fixed pour mettre le bouton en évidence.
Gtk_New(F) ;
Win.Add(F) ;
GTK_New(B,"Mon texte","./picture.png") ;
F.put(B.Btn,100,80) ;
Win.show_all ;
Main ;
END Bouton_A_Image ;
Widget : GTK_Entry ou GTK_GEntry (qui n'est qu'un sous-type).
Package : Gtk.GEntry
Descendance : GTK_Widget >> GTK_Editable
Description : Ce widget se présente sous la forme d'une zone de texte d'une seule ligne. Ce texte est tout à fait éditable par l'utilisateur et pourra servir, par exemple, à entrer un mot de passe.
Méthodes
Je ne compte pas m'appesantir encore une fois sur le constructeur GTK_New(), celui-ci ne prend qu'un seul paramètre : votre widget. Vous serez donc capable de l'utiliser sans moi et je n'attirerai plus votre attention sur les constructeurs que lorsqu'ils nécessiteront des paramètres spécifiques.
Commençons donc par les méthodes concernant ... le texte ! Comme les entrées sont faites pour cela, rien de plus logique :
procedure Set_Text(The_Entry : access Gtk_Entry_Record;
Text : UTF8_String);
function Get_Text(The_Entry : access Gtk_Entry_Record) return UTF8_String ;
function Get_Text_Length(The_Entry : access Gtk_Entry_Record) return Guint16 ;
--METHODES OBSOLETES
Append_text(The_Entry : access Gtk_Entry_Record ; Text : UTF8_String);
Prepend_text(The_Entry : access Gtk_Entry_Record ; Text : UTF8_String);
Tout d'abord, Set_Text() vous permet de fixer vous-même le texte de l'entrée ; utile pour définir un texte par défaut du genre "tapez votre mot de passe ici". Puis, nous avons deux fonctions qui vous seront utiles dans vos callbacks : Get_Text() qui renvoie le texte tapé par l'utilisateur et Get_Text_Length() qui renvoie la longueur de la chaîne de caractères (utile pour indiquer à l'utilisateur que le mot de passe choisi est trop court par exemple). A noter que des méthodes obsolètes, mais toujours accessibles, pourraient vous faire gagner un peu de temps : Append_text() pour ajouter des caractères à la fin du texte contenu dans l'entrée et Prepend_text() pour l'ajouter au début (souvenez-vous les TAD, nous avions déjà utilisé les mots Append et Prepend). Ne vous inquiétez pas si le compilateur vous indique que ces méthodes sont obsolètes, elles fonctionnent tout de même. Venons-en maintenant à la taille de l'entrée :
Les méthodes Set_Max_Length() et Get_Max_Length() permettent de définir ou de lire la longueur de l'entrée et donc le nombre de caractères visibles. Si votre entrée a une taille de 8, elle ne pourra afficher que 8 caractères en même temps, ce qui n'empêchera pas l'utilisateur d'entrer un texte de 15 ou 20 caractères, l'affichage suivant le curseur. En revanche, si vous souhaitez limiter ou connaître le nombre de caractères inscriptibles, utilisez Set_Width_Chars() et Get_Width_Chars() (rappel : length signifie longueur, width signifie largeur). Passons maintenant à l'usage de l'entrée : celle-ci pouvant servir pour des mots de passe, il faudrait pouvoir masquer (ou non) son contenu.
Pour masquer le texte par des ronds noirs (●●●), il faudra utiliser Set_Visibility() et que le paramètre Visible vaille false. Il vous est possible de ne rien afficher du tout en utilisant Set_Invisible_Char() avec char := 0, ou de remplacer les ● par d'autre caractères. Pour ce faire, il faudra utiliser le package glib.unicode afin de convertir nos caractères en Gunichar :
Les méthodes Set_Alignment() et Get_Alignment() permettent de définir ou de connaître la position du texte au sein de l'entrée. Xalign est un simple nombre en virgule flottante : quand il vaut 0.0, le texte est aligné à gauche, quand il vaut 1.0 il est aligné à droite. Pour centrer le texte, il faudra donc que Xalign vaille 0.5.
Avec Set_Icon_From_Stock et le package Gtk.Stock, il est possible d'ajouter des icônes à votre entrée, comme nous le faisions avec nos images. Toutefois, vous devez préciser la position de l'icône. Deux valeurs sont possibles pour Icon_Pos :
Gtk_Entry_Icon_Primary : icône à gauche
Gtk_Entry_Icon_Secondary : icône à droite
Une entrée avec texte centré et icône. Vous remarquerez que le curseur est centré par rapport à la place laissée disponible pour le texte.
Faire de votre entrée une barre de progression
Enfin, il est également possible de transformer votre GTK_Entry en une sorte de barre de progression :
La méthode Set_Progress_Fraction() permet de définir le pourcentage d'avancement de la barre de progression (Fraction vaudra 1.0 pour 100% d'avancement et 0.0 pour 0%).
Mais si vous souhaitez que vos callbacks fassent progresser la barre de manière régulière, vous devrez définir le pas, c'est à dire de quel pourcentage la barre progressera à chaque avancement. Pour définir ce pas, vous utiliserez Set_Progress_Pulse_Step(), puis il vous suffira d'utiliser Progress_pulse() pour faire faire progresser la barre de la valeur du pas que vous venez de définir.
Quelques signaux
Enfin, pour que vous puissiez utiliser toutes ces méthodes, voici quelques signaux qui vous serons utiles. Notez que vous pouvez les appelez soit via une chaîne de caractères, soit via le nom de la variable signal :
Signal_Activate / "activate" : émis lorsque vous appuyez sur la touche Entrée.
Signal_Backspace / "backspace" : émis lorsque vous appuyez sur la touche Retour Arrière.
Signal_Copy_Clipboard / "copy_clipboard" : émis lorsque vous copier du texte.
Signal_Cut_Clipboard / "cut_clipboard" : émis lorsque vous couper du texte.
Signal_Delete_From_Cursor / "delete_from_cursor" : émis lorsque vous appuyez sur la touche Suppr.
Signal_Move_Cursor / "move_cursor" : émis lorsque vous déplacez le curseur avec les touches fléchées.
Signal_Paste_Clipboard / "paste_clipboard" : émis lorsque vous coller du texte.
Signal_Toggle_Overwrite / "toggle_overwrite" : émis lorsque vous appuyez sur la touche Inser.
Saisie de texte multiligne
Fiche d'identité
Widget : Gtk_Text_view.
Package : Gtk.Text_view
Descendance : GTK_Widget >> GTK_Container
Description : Ce widget se présente sous la forme d'une page blanche sur laquelle l'utilisateur peut écrire tout ce qu'il souhaite.
Quelques méthodes
Je vais vous présenter maintenant quelques méthodes pour contrôler votre GTK_Text_View.
La méthode Set_Accepts_Tab() vous permettra de définir le comportement de votre widget lorsque l'utilisateur appuiera sur la touche de tabulation. Si le paramètre Accepts_Tab vaut true, appuyer sur Tab créera une tabulation dans le GTK_Text_View. Si le paramètre Accepts_Tab vaut false, appuyer sur la touche Tab permettra seulement de passer le focus d'un widget à un autre. La méthode Set_Wrap_Mode() indique quant à elle comment gérer les fins de ligne. Le paramètre Wrap_Mode peut valoir :
Wrap_None : lorsque vous atteignez la fin de la ligne, le widget s'agrandit de manière à afficher les nouveaux caractères.
Wrap_Char : lorsque vous atteignez la fin de la ligne, les nouveaux caractères sont écrits sur la ligne suivante, pouvant ainsi couper les mots en plein milieu.
Wrap_Word : lorsque vous atteignez la fin de la ligne, le mot en cours d'écriture est placé sur la ligne suivante. En revanche, si le mot que vous écrivez est plus long que la ligne, le widget s'agrandira afin de loger le mot entier.
Wrap_Word_Char : c'est le mode utilisé habituellement par les traitements de texte : en fin de ligne, le mot en cours d'écriture est placé tout entier sur la ligne suivante, à moins qu'il soit trop long, auquel cas il est coupé pour afficher les caractères suivants à la ligne.
Enfin, comme son nom l'indique, la méthode Set_Cursor_Visible() indique au widget si le curseur sera visible ou non. Venons-en maintenant à la mise en forme du widget.
Tout d'abord, la méthode Set_Justification() : celle-ci permet d'aligner le texte à gauche (Justify_Left), à droite(Justify_Right), au centre (Justify_Center) ou bien de le justifier, c'est à dire faire en sorte qu'il soit aussi bien aligné à gauche qu'à droite (Justify_Fill).
Les méthodes Set_Margin_Left() et Set_Margin_Right() permettent quant à elles de définir les marges du texte à gauche et à droite. Ainsi, l'instruction Mon_Text_View.Set_Margin_Left(25) réservera 25 pixels à gauche sur lesquels il sera impossible d'écrire.
Enfin, la méthode Set_Indent() permet de définir l'indentation du texte ou, pour laisser de côté le vocabulaire informatique, de définir la taille des alinéas. Vous savez, c'est une règle de typographie. Tout nouveau paragraphe commence par un léger retrait du texte de la première ligne (l'équivalent d'une tabulation très souvent). Très utile pour avoir des paragraphes facilement distinguables et un texte clair. De même, nous avons les méthodes suivantes :
Les méthodes Set_Pixels_Above_Lines() et Set_Pixels_Below_Lines() permettent de définir le nombre de pixels au-dessus et au-dessous de chaque paragraphe. Pour bien comprendre le vocabulaire employé par GTK, vous devez avoir en tête que lorsque vous voyez un paragraphe composé de plusieurs lignes, pour GTK, il ne s'agit que d'une seule ligne d'une chaîne de caractère, c'est à dire d'un texte compris entre deux retours à la ligne. La méthode Set_Pixels_Inside_Wrap() définit quant à elle l'interligne au sein d'un même paragraphe. Enfin, voici une dernière méthode :
Elle permet de définir les bords de la zone de texte. Le paramètre The_Type peut valoir Text_Window_Left (bordure gauche), Text_Window_Right (bordure droite), Text_Window_Top (bordure haute) ou Text_Window_Bottom (bordure basse). Le paramètre Size correspond là encore au nombre de pixels.
Et pour quelques méthodes de plus
Mais comment je fais si je veux écrire un texte justifié avec un titre centré ?
Eh bien le package Gtk.Text_View ne permet de manipuler que le widget GTK_Text_View, et pas d'affiner la présentation du texte. Si vous souhaitez entrer dans les détails, nous allons devoir utiliser les Gtk_Text_Buffer. Il ne s'agit plus d'un widget mais d'un GObject (un objet définit par la bibliothèque GLib). Un buffer est une mémoire tampon dans laquelle sont enregistrées diverses informations comme le texte ou les styles et polices utilisés. Tout GTK_Text_View dispose d'un Gtk_Text_Buffer. Vous allez donc devoir :
Déclarer un GTK_Buffer
Déclarer un GTK_Text_View
Récupérer dans votre GTK_Buffer, le texte de votre GTK_Text_View
Une fois l'adresse du texte récupérée dans votre buffer, vous allez pouvoir effectuer quelques recherches ou modifications. Par exemple, les méthodes Get_Line_Count() et Get_Char_Count() vous permettront de connaître le nombre de paragraphes et de caractères dans votre buffer :
function Get_Line_Count(Buffer : access Gtk_Text_Buffer_Record) return Gint;
function Get_Char_Count(Buffer : access Gtk_Text_Buffer_Record) return Gint;
procedure Set_Text(Buffer : access Gtk_Text_Buffer_Record;
Text : UTF8_String);
procedure Insert_At_Cursor(Buffer : access Gtk_Text_Buffer_Record;
Text : UTF8_String);
La méthode Set_Text() vous permettra de modifier le texte. Attention toutefois, cela effacera tout le contenu précédent ! Si vous souhaitez seulement ajouter du texte à l'emplacement du curseur, utilisez plutôt Insert_At_Cursor(). Maintenant, nous allons voir comment obtenir du texte contenu dans le buffer ou insérer du texte à un endroit donné :
function Get_Text (Buffer : access Gtk_Text_Buffer_Record;
Start : Gtk.Text_Iter.Gtk_Text_Iter;
The_End : Gtk.Text_Iter.Gtk_Text_Iter;
Include_Hidden_Chars : Boolean := False) return UTF8_String;
procedure Insert (Buffer : access Gtk_Text_Buffer_Record;
Iter : in out Gtk.Text_Iter.Gtk_Text_Iter;
Text : UTF8_String);
Get_Text() permettra d'obtenir le texte compris entre les paramètres Start et The_End, tandis que Insert() insèrera du texte à l'emplacement Iter. Facile non ?
Facile, facile ... c'est quoi ces Gtk_Text_Iter ?
Ah oui, je vais un peu vite en besogne. Les GTK_Iter sont des itérateurs, c'est à dire des emplacements dans le texte. Ces objets sont accessibles via le package Gtk.Text_Iter. Vous pouvez les contrôler de manière très précise en les déplaçant d'un ou plusieurs caractères. Cependant, je ne vois pour nous que quatre positions vraiment utiles :
Le début du texte :
procedure Get_Start_Iter(Buffer : access Gtk_Text_Buffer_Record;
Iter : out Gtk.Text_Iter.Gtk_Text_Iter);
La fin du texte :
procedure Get_End_Iter(Buffer : access Gtk_Text_Buffer_Record;
Iter : out Gtk.Text_Iter.Gtk_Text_Iter);
Le début et la fin d'une sélection :
procedure Get_Selection_Bounds(Buffer : access Gtk_Text_Buffer_Record;
Start : out Gtk.Text_Iter.Gtk_Text_Iter;
The_End : out Gtk.Text_Iter.Gtk_Text_Iter;
Result : out Boolean);
Voici un exemple d'utilisation :
...
Txt : GTK_Text_View ; --Le widget GTK_Text_View
Tampon : GTK_Buffer ; --Son Buffer
Debut,
Fin : Gtk_Iter ; --Les itérateurs de début et de fin de sélection
Ca_Marche : Boolean ; --Un booléen pour savoir si la sélection marche ou pas
BEGIN
...
GTK_New(Tampon) ;
Tampon := Txt.Get_Buffer ;
--On effectue un affichage dans la console de l'intégralité du texte
Tampon.Get_Start_Iter(Debut) ;
Tampon.Get_End_Iter(Fin) ;
Put_line("Le GTK_Text_View contient : ") ;
Put_line(Tampon.Get_Text(Debut,Fin)) ;
--On effectue un affichage dans la console du texte sélectionné
Tampon.Get_selection_Bounds(Debut,Fin,Ca_Marche) ;
Put_line("Vous avez selectionne : ") ;
Put_line(Tampon.Get_Text(Debut,Fin)) ;
...
Venons-en maintenant à la mise en forme de notre texte. Malheureusement, la mise en forme du texte est plus complexe que pour les GTK_Entry. L'utilisateur ne vas pas écrire de balise dans son texte, ce serait trop : un utilisateur qui serait programmeur en GTK. :ange: Nous allons donc devoir créer des balises nous-même. Ces balises s'appellent des GTK_Text_Tag et leur usage est complexe. Vous devrez :
Créer votre GTK_Text_Tag grâce à GTK_New.
L'ajouter à la table des balises contenue dans le buffer en lui donnant un nom. Les tables de balises se nomment des GTK_Text_Tag_Table, mais nous ferons en sorte de ne pas y avoir recours.
Paramétrer votre Tag.
Le constructeur GTK_New() est disponible dans le package Gtk.Text_Tag et ne prend comme seul paramètre que votre Gtk_Text_Tag. Le premier soucis est d'ajouter votre tag à la table des tags du buffer. Pour faire cela, vous trouverez dans le package Gtk.Text_Buffer la fonction suivante :
Elle permet d'affecter votre tag à un tampon tout en lui attribuant un nom. Attention, la table des tags d'un buffer ne peut contenir deux tag portant le même nom. Nous verrons un exemple d'utilisation ci-dessous, rassurez-vous. Reste maintenant à paramétrer notre tag pour, par exemple, mettre du texte en gras. Pour cela, vous aurez besoin du package Pango.Enums (pas de Gtk !). Celui-ci comporte toutes sortes de types énumérés correspondant à différents styles mais surtout, il implémente le package générique Glib.Generic_Properties. Vous me suivez ? Plus simplement, c'est comme si notre package Pango.Enums disposait de la méthode suivante pour définir les propriétés d'un GTK_Text_Tag (je simplifie pour y voir clair) :
procedure Set_Property(Object : access GTK_Text_Tag_Record'Class;
Name : Property ;
Value : Property_Type);
Le paramètre Name est le nom d'une propriété, cela permet d'indiquer ce que vous souhaitez modifier (gras, italique, barré ... ). Vous trouverez les valeurs possibles dans le package GTK.Text_Tag. Par exemple, la propriété Gras se nomme Weight_Property. Le paramètre Value permet de préciser la propriété (gras léger, gras épais ... ) et vous trouverez les valeurs possibles dans Pango.Enums :
type Weight is
(Pango_Weight_Ultralight,
Pango_Weight_Light,
Pango_Weight_Normal,
Pango_Weight_Medium,
Pango_Weight_Semi_Bold,
Pango_Weight_Bold,
Pango_Weight_Ultrabold,
Pango_Weight_Heavy);
Excuse-moi, mais j'ai beau te relire, j'ai vraiment du mal à comprendre. Je me perds dans les packages et les méthodes. :'(
Résumons : dans GTK.Text_Tag nous trouverons le type GTK_Text_Tag, son constructeur GTK_New() ainsi que des noms de propriétés (Style_Property, Underline_Property, Strikethrough_Property, Weight_Property...). Dans Pango.Enums nous trouverons plus de précisions pour différentes propriétés (type de gras, d'italique ...) ainsi que la méthode Set_Property() (implicitement). La méthode Create_Tag() permettant d'ajouter le tag à la table des tags est disponible dans GTK.Text_Buffer. Un exemple résumerait tout cela encore mieux :
...
tag : GTK_Text_Tag ;
tampon : GTK_Text_Buffer ;
BEGIN
...
--création du tag
gtk_new(tag) ;
--Définition du tag : propriété gras et plus exactement Ultragras.
Set_Property(Tag, Weight_Property, Pango_Weight_Ultrabold) ;
--ajout du tag dans la table du buffer sous le nom "gras"
Tag := Tampon.Create_Tag("gras") ;
Maintenant, il ne vous restera plus qu'à insérer du texte déjà formaté à l'aide de votre tag ou simplement d'appliquer votre tag à une partie du buffer à l'aide des méthodes suivantes :
--INSERER DU TEXTE FORMATE
procedure Insert_With_Tags --A l'aide de votre variable : Tag
(Buffer : access Gtk_Text_Buffer_Record;
Iter : in out Gtk.Text_Iter.Gtk_Text_Iter;
Text : UTF8_String;
Tag : Gtk.Text_Tag.Gtk_Text_Tag);
procedure Insert_With_Tags_By_Name --A l'aide du nom de votre Tag : "gras"
(Buffer : access Gtk_Text_Buffer_Record;
Iter : in out Gtk.Text_Iter.Gtk_Text_Iter;
Text : UTF8_String;
Tag_Name : String);
--APPLIQUER UN FORMAT
procedure Apply_Tag --A l'aide de votre variable : Tag
(Buffer : access Gtk_Text_Buffer_Record;
Tag : access Gtk.Text_Tag.Gtk_Text_Tag_Record'Class;
Start : Gtk.Text_Iter.Gtk_Text_Iter;
The_End : Gtk.Text_Iter.Gtk_Text_Iter);
procedure Apply_Tag_By_Name --A l'aide du nom de votre Tag : "gras"
(Buffer : access Gtk_Text_Buffer_Record;
Name : String;
Start : Gtk.Text_Iter.Gtk_Text_Iter;
The_End : Gtk.Text_Iter.Gtk_Text_Iter);
Un exemple (ou un exercice)
Voici un exemple de code utilisant les GTK_Text_View, avec les buffers et les tags. Il s'agit d'un mini éditeur de texte : il suffit de sélectionner du texte puis de cliquer sur les boutons Gras ou Italique pour appliquer la mise en forme.
WITH Gtk.Main ; USE Gtk.Main ;
WITH Gtk.Window ; USE Gtk.Window ;
WITH Gtk.Text_View ; USE Gtk.Text_View ;
WITH Gtk.Enums ; USE Gtk.Enums ;
WITH Gtk.Handlers ; USE Gtk.Handlers ;
WITH Gtk.Box ; USE Gtk.Box ;
WITH Gtk.Button ; USE Gtk.Button ;
WITH Glib.Convert ; USE Glib.Convert ;
WITH Gtk.Text_Buffer ; USE Gtk.Text_Buffer ;
WITH Gtk.Text_Iter ; USE Gtk.Text_Iter ;
WITH Gtk.Text_Tag ; USE Gtk.Text_Tag ;
WITH Pango.Enums ; USE Pango.Enums ;
PROCEDURE Texte IS
TYPE T_Fenetre IS RECORD
Win : Gtk_Window;
Txt : Gtk_Text_View ;
Btn_Gras, Btn_Ital : Gtk_Button ;
VBox : GTK_VBox ;
HBox : GTK_HBox ;
END RECORD ;
--INITIALISATION D'UN OBJET T_FENETRE
PROCEDURE Init(F : IN OUT T_Fenetre) IS
Tag : Gtk_Text_Tag ;
Tampon : GTK_Text_Buffer ;
BEGIN
Init ;
--Création de la fenêtre
Gtk_New(F.Win) ;
F.Win.Set_Default_Size(250,200) ;
F.Win.Set_Title(Locale_To_Utf8("Mini éditeur de texte")) ;
--Création des boutons
Gtk_New(F.Btn_Gras,"Gras") ;
Gtk_New(F.Btn_Ital,"Italique") ;
--Création du GTK_Text_View
Gtk_New(F.Txt) ;
F.Txt.Set_Wrap_Mode(Wrap_Word_char) ;
F.Txt.Set_Justification(Justify_Fill) ;
F.Txt.Set_Pixels_Above_Lines(10) ;
F.Txt.Set_Indent(15) ;
--Création des boîtes et organisation de la fenêtre
GTK_New_VBox(F.VBox) ;
GTK_New_HBox(F.HBox) ;
F.VBox.Pack_Start(F.Txt) ;
F.VBox.Pack_Start(F.HBox, Expand=> False, Fill => False) ;
F.HBox.Pack_Start(F.Btn_Gras, Expand=> False, Fill => False) ;
F.HBox.Pack_Start(F.Btn_Ital, expand=> false, fill => false) ;
F.Win.Add(F.VBox) ;
F.Win.Show_All ;
--Création des tags et ajout à la table du buffer
gtk_new(tag) ;
Tampon := F.Txt.Get_Buffer ;
Tag := Tampon.Create_Tag("gras") ;
Set_Property(Tag, Weight_Property, Pango_Weight_Ultrabold) ; --
Tag := Tampon.Create_Tag("italique") ;
set_property(Tag, Style_Property, Pango_Style_Italic) ;
END Init ;
--LES CALLBACKS
PACKAGE Callback IS NEW Gtk.Handlers.User_Callback(GTK_Button_Record, T_Fenetre) ;
USE Callback ;
PROCEDURE To_Bold(Emetteur : ACCESS GTK_Button_Record'Class ; F : T_Fenetre) IS
PRAGMA Unreferenced(Emetteur) ;
Tampon : GTK_Text_Buffer ;
Debut,Fin : GTK_Text_Iter ;
Resultat : Boolean ;
BEGIN
Gtk_New(Tampon) ;
Tampon := F.Txt.Get_Buffer ;
Tampon.Get_Selection_Bounds(debut,fin,resultat) ; --Initialisation des Iter
Tampon.apply_tag_by_name("gras",debut,fin) ; --Application du format Gras
END To_Bold ;
PROCEDURE To_Italic(Emetteur : ACCESS GTK_Button_Record'Class ; F : T_Fenetre) IS
PRAGMA Unreferenced(Emetteur) ;
Tampon : GTK_Text_Buffer ;
Debut,Fin : GTK_Text_Iter ;
Resultat : Boolean ;
BEGIN
Gtk_New(Tampon) ;
Tampon := F.Txt.Get_Buffer ;
Tampon.Get_Selection_Bounds(debut,fin,resultat) ; --Initialisation des Iter
Tampon.apply_tag_by_name("italique",debut,fin) ; --Application du format Italique
END To_Italic ;
F : T_Fenetre ;
BEGIN
Init(F) ;
Connect(F.Btn_Gras,"clicked",To_Bold'ACCESS, F) ;
connect(F.Btn_Ital,"clicked",To_Italic'access, F) ;
Main ;
END Texte ;
Quelques signaux
Les GTK_Text_View aussi peuvent émettre des signaux. Vous retrouverez la plupart des signaux vus pour les GTK_Entry :
Description : Ce widget présente une zone d'affichage d'un nombre, accompagnée de deux petits boutons pour augmenter ou diminuer ce nombre.
Méthodes
Le constructeur est cette fois plus exigent :
procedure Gtk_New(Spin_Button : out Gtk_Spin_Button;
Min : Gdouble;
Max : Gdouble;
Step : Gdouble);
procedure Set_Increments(Spin_Button : access Gtk_Spin_Button_Record;
Step : Gdouble;
Page : Gdouble);
procedure Get_Increments(Spin_Button : access Gtk_Spin_Button_Record;
Step : out Gdouble;
Page : out Gdouble);
procedure Set_Range(Spin_Button : access Gtk_Spin_Button_Record;
Min : Gdouble;
Max : Gdouble);
procedure Get_Range(Spin_Button : access Gtk_Spin_Button_Record;
Min : out Gdouble;
Max : out Gdouble);
Vous devrez lui indiquer la valeur minimale, la valeur maximale ainsi que le pas (Step), c'est à dire la valeur de l'augmentation ou de la diminution qui aura lieu à chaque fois que l'utilisateur appuiera sur les boutons correspondants. Attention, ces valeurs sont des GDouble, c'est à dire des nombres flottants double précision. Rassurez-vous, si vous souhaitez un compteur entier, GTK n'affichera de ",0" à la fin de vos nombres. De plus, vous pouvez modifier ces valeurs grâce aux méthodes Set_Increments() et Set_Range(). Si Set_Range() se contente de redéfinir le minimum et le maximum, la méthode Set_Increments() permet de redéfinir deux types de pas : le "pas simple" (Step) et le "pas large" (Page). Le pas large correspond à l'augmentation obtenue lorsque vous appuierez sur les touches Page Haut ou Page Bas de votre clavier (les deux touches à côté de Fin et Début) ou lorsque vous cliquerez sur les boutons d'augmentation/diminution avec le bouton n°2 de la souris (la molette centrale pour une souris trois boutons). Si vous cliquez à l'aide du bouton n°3 (bouton droit) vous atteindrez la plus petite ou plus grande valeur.
procedure Set_Digits(Spin_Button : access Gtk_Spin_Button_Record;
The_Digits : Guint);
function Get_Digits(Spin_Button : access Gtk_Spin_Button_Record) return Guint;
procedure Set_Value(Spin_Button : access Gtk_Spin_Button_Record;
Value : Gdouble);
function Get_Value(Spin_Button : access Gtk_Spin_Button_Record) return Gdouble;
Vous pouvez également préciser à l'aide de Set_Digits() le nombre de chiffres que vous désirez après la virgule. Enfin, pour vos callbacks, vous pourrez utiliser les méthodes Set_Value() et Get_Value() qui vous permettront de définir ou d'obtenir la valeur du GTK_Spin_Button.
Signal
Un signal devrait vous servir ici. Il s'agit du signal Signal_Value_Changed / "value_changed" qui est émis dès lors que la valeur du GTK_Spin_Button est modifiée (soit en cliquant sur les boutons d'augmentation/réduction soit en tapant la valeur manuellement et en appuyant sur Entrée.
Saisie numérique par curseurs
Fiche d'identité
Widget : Gtk_Scale, Gtk_HScale et Gtk_VScale.
Package : Gtk.Scale
Descendance : GTK_Widget >> GTK_Range
Description : Ce widget permet de saisir un nnombre en déplaçant un curseur.
Méthodes
Les curseurs (appelés échelles par GTK) ont deux orientations possibles : à la verticale ou à l'horizontale). Il existe donc un constructeur pour chacun d'eux (en fait il y en a même deux pour chacun, mais nous n'en verrons qu'un seul) :
procedure Gtk_New_Hscale(Scale : out Gtk_Hscale;
Min : Gdouble;
Max : Gdouble;
Step : Gdouble);
procedure Gtk_New_Vscale(Scale : out Gtk_Vscale;
Min : Gdouble;
Max : Gdouble;
Step : Gdouble);
function Get_Orientation(Self : access Gtk_Scale_Record) return Gtk.Enums.Gtk_Orientation;
procedure Set_Orientation(Self : access Gtk_Scale_Record;
Orientation : Gtk.Enums.Gtk_Orientation);
Je ne reviens pas sur les paramètres Min, Max et Step, ce sont les mêmes que pour les GTK_Spin_Button. Si jamais vous vouliez modifier ou connaître l'orientation de votre curseur, vous pouvez utiliser Get_Orientation() et Set_Orientation(). Deux types d'orientations sont disponibles : Orientation_Horizontal et Orientation_Vertical. Ai-je besoin de traduire ? :D
Comme précédemment, pour connaître ou modifier le nombre de chiffres après la virgule à afficher (Number_Of_Digits), utilisez les méthodes Get_Digits() et Set_Digits(). Attention, cette dernière peut modifier votre pas, s'il n'est pas suffisamment précis. Vous pouvez ne pas afficher la valeur correspondant à votre curseur en utilisant la méthode Mon_Gtk_Scale.Set_Draw_Value(false).
Autres méthodes : Add_mark() qui ajoute une marque à votre curseur et Clear_Marks() qui les effacent toutes. Qu'est-ce qu'une marque me direz-vous ? Eh bien, c'est simplement un petit trait sur le bord de l'échelle permettant d'indiquer une position précise (le milieu, une ancienne valeur ...) comme sur l'exemple ci-dessous :
Le paramètre Value indique simplement le lieu où doit se trouver la marque. Le paramètre Position indique s'il doit se situer au-dessus ou en-dessous (Pos_Top ou Pos_Bottom, valable seulement pour les GTK_HScale), à gauche ou à droite (Pos_Left ou Pos_Right, valable seulement pour les GTK_VScale). Enfin, Markup est le texte qui sera inscrit à côté de la marque.
Dans le même esprit, Get_Value_Pos() et Set_Value_Pos() permettent de connaître ou de définir la position de la valeur du curseur : est-elle affichée au-dessus, au-dessous, à gauche ou à droite du curseur ?
function Get_Value (The_Range : access Gtk_Range_Record) return Gdouble;
procedure Set_Value(The_Range : access Gtk_Range_Record;
Value : Gdouble);
procedure Set_Increments(The_Range : access Gtk_Range_Record;
Step : Gdouble;
Page : Gdouble);
procedure Set_Range(The_Range : access Gtk_Range_Record;
Min : Gdouble;
Max : Gdouble);
Par héritage, les GTK_Scale bénéficient également des méthodes ci-dessus. Elles jouent le même rôle que pour les GTK_Spin_Button, je ne vais donc pas vous les réexpliquer.
Vous venez de terminer la partie la plus complexe de ce chapitre. Nous allons maintenant nous détendre en découvrant quatre nouveaux boutons plus spécifiques : les boutons à bascule, les boutons-liens, les boutons à cocher et les boutons radios.
Description : Il s'agit d'un bouton d'apparence classique, mais qui ne peut en réalité être que dans l'un des deux états suivants : actif (enfoncé) ou inactif(relevé).
Méthodes
Les Toggle_Button se créent comme des boutons classiques avec GTK_New() ou Gtk_New_With_Mnemonic(). La nouveauté est de pouvoir activer ou non le bouton à bascule :
Pour que le bouton soit activé, il suffit que Is_Active vaille true. Enfin, il est également possible de "bloquer" le bouton si par exemple des paramètres renseignés par l'utilisateur étaient incompatibles avec son activation (dans un jeu, un bouton "partie rapide" serait bloqué si le joueur demandait à jouer contre 30 adversaires). Pour cela il suffit d'utiliser les méthodes suivantes avec Setting à true :
Les Toggle_Button apportent un nouveau signal : Signal_Toggled ou "toggled" qui signifie que le bouton a basculé d'un état à un autre (actif vers inactif ou réciproquement).
Description : Ce bouton se présente comme un lien internet, gardant en mémoire s'il a été cliqué ou non.
Méthodes
procedure Gtk_New (Widget : out Gtk_Link_Button;
Uri : String);
procedure Gtk_New_With_Label(Widget : out Gtk_Link_Button;
Uri : String;
Label : String);
Lors de la création d'un GTK_Link_Button, vous devrez renseigner l'URI vers laquelle il est sensé pointé, c'est à dire l'adresse internet ou le fichier visé. Exemple : "http://siteduzero.com". Si vous souhaitez que le bouton affiche un texte spécifique plutôt que l'adresse du fichier ou de la page ciblé, utilisez la méthode Gtk_New_With_Label().
Avec les méthodes précédentes vous pourrez obtenir ou modifier l'adresse URI du bouton. Vous pourrez également savoir si le lien a été visité ou le réinitialiser. Enfin, les GTK_Link_Button ne présentent pas de signaux particuliers (pas davantage que les boutons classiques).
Description : Ce widget est généralement utilisé en groupe, pour choisir entre diverses options s'excluant les unes les autres.
image2
Méthodes
Lorsque vous créez un Gtk_Radio_Button, vous créez également une GSList (plus exactement une Gtk.Widget.Widget_SList.GSlist). Cette liste permet à votre programme de lier plusieurs boutons radios entre eux : lorsque l'utilisateur cliquera sur l'un d'entre eux, cela décochera tous les autres de la liste. Heureusement, GTKAda nous simplifie la vie. Pour ne pas créer de GSList en plus de nos Gtk_Radio_Button, il existe un constructeur liant les Gtk_Radio_Button entre eux :
procedure Gtk_New (Radio_Button : out Gtk_Radio_Button;
Group : Gtk_Radio_Button;
Label : UTF8_String := "");
Le paramètre Radio_Button est bien sûr le bouton radio que vous souhaitez créer. Le paramètre Group est l'un des boutons radio de la liste et Label est bien entendu l'étiquette du bouton. Voici un exemple d'utilisation des boutons radio ; il s'agit de proposer à l'utilisateur de payer par carte ou par chèque, en euros ou en dollars :
...
BtnA1, BtnA2 : GTK_Radio_Button ;
BtnB1, BtnB2 : GTK_Radio_Button ;
BEGIN
--Première liste de boutons
GTK_New(BtnA1,NULL, "Par carte") ;
GTK_New(BtnA2, BtnA1, "Par cheque") ;
--Deuxième liste de boutons
GTK_New(BtnB1,NULL, "En euros") ;
GTK_New(BtnB2, BtnB1, "En dollars") ;
Vous aurez remarqué que pour le premier bouton de chaque liste, il suffit d'indiquer NULL pour qu'il ne soit lié à aucun autre bouton (bah oui, les GTK_Radio_Button sont des pointeurs sur des GTK_Radio_Button_Record, vous vous souvenez).
Enfin, ne cherchez pas davantage de méthodes : les boutons radio sont des boutons à cocher, qui eux-mêmes sont des boutons à bascule, qui eux-mêmes sont des boutons ... Ouf ! Les histoires de famille c'est compliqué, mais l'avantage c'est qu'il n'y aura pas de nouvelles méthodes ou de nouveaux signaux à apprendre. :p
Nous allons désormais voir quelques types de fenêtres plus spécifiques : les boîtes de dialogue. En effet, pour beaucoup de logiciels, une seule fenêtre ne suffit pas, il est souvent nécessaire d'ouvrir des fenêtres secondaires pour demander à l'utilisateur s'il souhaite enregistrer son document avant de quitter ou pour lui permettre de paramétrer les options du logiciel ... ces fenêtres sont appelées boîtes de dialogue.
Une procédure Gtk_New_With_Markup() identique existe si jamais vous souhaitez utiliser des balises pour la mise en forme. Le paramètre Dialog est bien entendu votre boîte de dialogue. Le paramètre Parent correspond à la fenêtre principale, la fenêtre mère. Le paramètre Message correspond au message indiqué dans la boîte de dialogue. Venons-en maintenant aux trois autres paramètre. Flags peut prendre les valeurs suivantes :
Modal : Si vous souhaitez désactiver la fenêtre mère le temps que votre boîte de dialogue est active. (la plus utile)
Destroy_With_Parent : Pour indiquer que la fermeture de la fenêtre mère détruira la boîte de dialogue. Mais par défaut, ce paramètre devrait être actif quoi que vous fassiez.
0 : si vous ne voulez indiquer aucun paramètre.
Le paramètre Typ indique le type de boîte de dialogue et donc l'image qui sera affichée (les valeurs possibles sont Message_Info, Message_Warning, Message_Question, Message_Error) ; le paramètres Buttons indique quant à lui le type et le nombre de boutons de la boîte (Buttons_None, Buttons_Ok, Buttons_Close, Buttons_Cancel, Buttons_Yes_No, Buttons_Ok_Cancel)Pour y voir plus clair, voici quelques exemples :
N'oubliez pas d'afficher votre boîte de dialogue grâce à show_all ! Enfin, pour personnaliser davantage votre boîte de dialogue, vous pouvez modifier le titre de la fenêtre grâce à la méthode set_title() disponible pour les GTK_Window, modifier l'image grâce à set_image() ou ajouter un texte secondaire grâce à Format_Secondary_Text() et Format_Secondary_Markup() :
Pour utiliser une boîte de dialogue, nous n'allons pas utiliser de signaux. Nous allons utiliser la fonction run() présente dans le package GTK.Dialog :
function Run(Dialog : access Gtk_Dialog_Record) return Gtk_Response_Type;
Cette fonction affiche la boîte de dialogue (comme show ou show_all), crée une sorte de "mini-boucle infinie" et renvoie la réponse de l'utilisateur (a-t-il cliqué sur OK ou Annuler ?). Voici un exemple d'utilisation :
...
Win : GTK_Window ;
Msg : GTK_Message_Dialog ;
BEGIN
...
--Création de la boîte de dialogue Msg
Gtk_New(Msg, Win, 0, Message_Error, Buttons_Ok_Cancel, "Ceci est un message d'erreur") ;
--Affichage de la fenêtre prinicpale
Win.Show_All ;
--Affichage et attente d'une réponse de la boîte de dialogue
IF Msg.Run = Gtk_Response_OK
THEN --écrire ici les instructions
END IF ;
...
Le code ci-dessus crée une boîte de dialogue de type Erreur. L'utilisateur a deux boutons accessibles : OK et Cancel. S'il clique sur OK, run() renvoie comme Gtk_Response_Type la valeur suivante : Gtk_Response_OK. Le programme n'a alors plus qu'à gérer cette réponse. Voici une liste de réponses possibles :
Gtk_Response_Delete_Event : si l'utilisateur clique sur l'icône de fermeture de la barre de titre.
Gtk_Response_OK : si l'utilisateur appuie sur le bouton Buttons_Ok
Gtk_Response_Cancel : si l'utilisateur appuie sur le bouton Buttons_Cancel
Gtk_Response_Close : si l'utilisateur appuie sur le bouton Buttons_Close
Gtk_Response_Yes : si l'utilisateur appuie sur le bouton Yes de Buttons_Yes_No
Gtk_Response_No : si l'utilisateur appuie sur le bouton No de Buttons_Yes_No
Mais ... ma boîte de dialogue ne se ferme pas toute seule ! o_O
Vous devrez donc, lorsque vous traitez les réponses possibles, pensez à ajouter une instruction pour détruire la boîte de dialogue. Cette instruction est présente dans le package GTK.Widget (et est donc disponible pour n'importe quel widget, même les boutons, images ou conteneurs) :
Description : Ce widget est souvent utilisé lorsque l'utilisateur clique sur le menu "A propos" afin d'afficher le nom du logiciel , sa version, son auteur, son logo ...
Méthodes
Le constructeur des GTK_About_Dialog est simplissime et ne prend qu'un seul paramètre. Concentrons nous donc sur l'apparence de cette boîte de dialogue :
Les méthodes ci-dessus permettent d'obtenir ou de définir les commentaires (description succincte du logiciel), le copyright, la licence, le nom du programme, sa version actuelle, l'adresse du site web correspondant ainsi que le nom du site web (qui sera affiché à la place de l'adresse). Toutes ces méthodes manipulent des UTF8_String et il est possible de les mettre en forme comme nous l'avons vu avec les étiquettes. A noter que la création d'une licence engendre automatiquement la création du bouton du même nom. Si vous cliquez sur celui-ci, une seconde fenêtre de dialogue s'ouvrira. Il est également possible d'ajouter un troisième bouton, en plus des boutons License et Close : le bouton Credits.
Les méthodes ci-dessus permettront de définir les artistes, les auteurs, les personnes ayant documenté le logiciel ainsi que les éventuels traducteurs. Les trois premières méthodes utilisent des GNAT.Strings.String_List qui ne sont rien de plus que des tableaux de pointeurs vers des strings. Voici par exemple comment renseigner la liste des artistes :
...
List : String_List(1..2) ;
BEGIN
...
List(1) := NEW String'("Picasso") ;
List(2) := NEW String'("Rembrandt") ;
Ma_Boite_De_Dialogue.Set_Artists(List) ;
...
Si vous souhaitez consulter les spécifications du type String_List, ouvrez le package System.String (s-string.ads) car GNAT.String n'est qu'un surnommage. Enfin, vous pouvez également définir un logo à votre boîte de dialogue (en général, le logo du logiciel) :
function Get_Logo (About : access Gtk_About_Dialog_Record) return Gdk.Pixbuf.Gdk_Pixbuf;
procedure Set_Logo(About : access Gtk_About_Dialog_Record;
Logo : access Gdk.Pixbuf.Gdk_Pixbuf_Record'Class);
C'est quoi ces pixbuf ?
Les Gdk_Pixbuf_Record sont en fait des images (gérées de façon bas niveau par Gdk). Comme je ne souhaite pas perdre de temps supplémentaire sur les images, nous nous contenterons donc d'utiliser une des méthodes Get prévues pour les GTK_Image. Celle-ci extrait un Gdk_Pixbuf d'une Gtk_Image :
Description : Ce widget permet de sélectionner un fichier ou un répertoire pour l'ouvrir ou l'enregistrer.
Méthodes des GTK_File_Chooser_Dialog
Les GTK_File_Chooser_Dialog ne sont pas compliqués à créer :
procedure Gtk_New (Dialog : out Gtk_File_Chooser_Dialog;
Title : String;
Parent : access Gtk.Window.Gtk_Window_Record'Class;
Action : Gtk.File_Chooser.File_Chooser_Action);
Le paramètre Title est bien entendu le titre de votre boîte de dialogue ("ouverture du fichier de sauvegarde" par exemple), Parent est le nom de la fenêtre parente, la fenêtre principale. Quant au paramètre Action, il indique le type de fenêtre désiré. Il peut prendre l'une des valeurs suivantes :
Action_Open : fenêtre pour ouvrir un fichier.
Action_Save : fenêtre pour sauvegarder un fichier. Elle comporte une ligne pour indiquer le nom du fichier à créer ainsi qu'un bouton pour créer un sous-répertoire.
Action_Select_Folder : fenêtre pour ouvrir un répertoire. Les fichiers sont automatiquement grisés.
Action_Create_Folder : fenêtre pour créer un répertoire.
Et c'est à peu près tout ce que vous pouvez faire avec une GTK_File_Chooser_Dialog.
Les GTK_File_Chooser (sans le Dialog)
Mais ... il n'y a aucun bouton Ouvrir, Annuler ou Enregistrer ! A quoi ça sert ?
Les méthodes des GTK_File_Chooser_Dialog sont quelque peu limitées. Pour la personnaliser un peu (notamment en ajoutant quelques boutons), vous devrez récupérer le GTK_File_Chooser de votre GTK_File_Chooser_Dialog, car c'est lui que vous pourrez personnaliser. Pour effectuer la récupération, une méthode "+" est disponible dans le package GTK.File_Chooser_Dialog. Exemple :
...
Chooser : GTK_File_Chooser ;
Dialog : GTK_File_Chooser_Dialog ;
BEGIN
...
Chooser := + Dialog ; --Chooser pointera vers le GTK_File_Chooser contenu dans Dialog
...
Passons maintenant aux méthodes liées aux GTK_File_Chooser. Pour commencer, nous voudrions ajouter au moins un bouton à notre boîte de dialogue.
La méthode Set_Extra_Widget() permet d'ajouter n'importe quel type de widget au bas de votre fenêtre : un bouton ou mieux ! Une boîte à boutons ! Maintenant voyons comment paramétrer notre boîte de dialogue :
La méthode Set_Action() vous permet de redéfinir le type de fenêtre (sauvegarde, ouverture de fichier ou de répertoire) si jamais vous ne l'aviez pas déjà fait. La méthode Set_Select_Multiple() permet de définir si l'utilisateur peut sélectionner un unique fichier (le paramètre select_multiple valant false) ou bien plusieurs (select_multiple valant true). De la même manière, Set_Show_Hidden() permet d'afficher les fichiers cachés (si Show_Hidden = true) ou pas. La méthode Set_Current_Name() n'est utile que pour des boîtes de dialogue de sauvegarde car elle permet de définir un nom par défaut à votre sauvegarde. Cette méthode peut vous être très utile pour des sauvegardes de partie en fournissant un titre par défaut, par exemple du genre "Nomdujoueur-jour-mois-annee.sav". De la même manière, Set_Current_Folder() permet de définir un répertoire par défaut à l'ouverture de la boîte de dialogue ; très utile notamment si vous souhaitez que l'utilisateur enregistre ses sauvegardes dans un même répertoire prévu à cet effet. Enfin, la méthode Get_Filename() permettra à vos callbacks d'obtenir l'adresse du fichier sélectionné afin de pouvoir l'ouvrir. Attention, il s'agit de l'adresse absolue et non relative du fichier, c'est à dire du chemin complet.
Et si je veux ouvrir plusieurs fichiers en même temps ?
Là, les choses se compliquent un petit peu. Vous utiliserez la méthode suivante :
function Get_Filenames(Chooser : Gtk_File_Chooser) return Gtk.Enums.String_SList.GSlist;
Vous aurez sûrement remarqué le S supplémentaire dans le nom de la méthode ainsi que le type du résultat : Gtk.Enums.String_SList.GSlist. Cela signifie que vous devrez utiliser le package Gtk.Enums et ajouter une clause USE Gtk.Enums.String_SList (car il s'agit d'un sous-package interne à Gtk.Enums) pour utiliser ces GSList. Qu'est-ce qu'une GSList ? C'est la contraction de "generic single-linked list", soit "liste générique simplement chaînée" (vous devriez comprendre ce que cela signifie désormais).
Vous trouverez les méthodes associées dans le package Glib.GSlist. Notamment, vous aurez besoin des méthodes ci-dessous. La première, Length() renvoie la longueur de la chaîne (celles-ci étant indexées de 0 à "Longueur-1") tandis que la seconde renvoie la donnée numéro N de la GSList.
function Length (List : in GSlist)
return Guint;
function Nth_Data (List : in GSlist;
N : in Guint)
return Gpointer;
Voici un exemple d'utilisation de ces méthodes avec un callback appelé lorsque l'utilisateur appuie sur le bouton OK :
PROCEDURE Ok_Action(Emetteur : ACCESS GTK_Button_Record'Class ;
F : Gtk_File_Chooser_Dialog) IS
PRAGMA Unreferenced(Emetteur) ;
USE Gtk.Enums.String_SList ;
L : Gslist ;
BEGIN
L := Get_Filenames(+F); --On récupère les noms de fichiers du File_chooser de F
FOR I IN 0..Length(L)-1 LOOP --On affiche les noms de la liste.
Put_Line(Nth_data(L,I)) ; --Attention, elle est indexée à partir de 0 ! Il y a donc
END LOOP ; --un décalage dans les indices
F.destroy ; --Enfin on détruit la boîte de dialogue
END Ok_Action ;
Deux widgets supplémentaires
Enfin, il est possible d'ajouter deux derniers widgets : un prévisualiseur de fichier et un filtre. Le prévisualiseur est un widget de votre cru affichant une miniature du contenu du fichier sélectionné. Par exemple, certains logiciels de graphisme affichent une miniature de vos photos avant que vous ne les ouvriez pour de bon. Cela peut facilement s'ajouter à l'aide des méthodes :
Les filtres, quant à eux permettent de filtrer les fichiers, de n'en afficher qu'une partie seulement selon des critères :
Pour cela vous devrez créer un filtre, c'est à dire un widget de type Gtk_File_Filter disponible via le package Gtk.File_Filter. Vous y trouverez les méthodes ci-dessous :
--le constructeur, sans commentaires
procedure Gtk_New(Filter : out Gtk_File_Filter);
--pour définir le texte à afficher
procedure Set_Name(Filter : access Gtk_File_Filter_Record; Name : String);
--pour définir les critères, nous allons voir celui-ci plus en détail
procedure Add_Pattern(Filter : access Gtk_File_Filter_Record;
Pattern : String);
Je ne m'attarde pas sur les deux premières méthodes, plutôt évidentes. En revanche, la troisième est importante : c'est elle qui fixe la règle d'affichage. Ces règles correspondent aux règles utilisées sous la console. Exemple :
Filtre1.Add_Pattern("*") ; --affiche tous les fichiers (* signifie n'importe quels caractères)
Filtre2.Add_Pattern("*.txt") ; --n'affiche que les fichiers se finissant par ".txt"
Une fois vos filtres créés, vous pourrez les ajouter ou les supprimer de vos Gtk_File_Chooser grâce aux méthodes :
Description : Cette boîte de dialogue permet de sélectionner une police, une taille et un style. Elle affiche également un aperçu de la mise en forme obtenue.
Méthodes
Les Gtk_Font_Selection_Dialog présentent assez peu de méthodes. Elles peuvent se résumer à ceci :
procedure Gtk_New(Widget : out Gtk_Font_Selection_Dialog;
Title : UTF8_String);
function Set_Font_Name(Fsd : access Gtk_Font_Selection_Dialog_Record;
Fontname : String) return Boolean;
function Get_Font_Name(Fsd : access Gtk_Font_Selection_Dialog_Record) return String;
Le constructeur n'exige rien de plus qu'un titre pour votre fenêtre. Ensuite, la méthode Get_Font_Name() vous permet de récupérer une chaîne de caractères contenant le nom de la police suivi éventuellement du style (gras, italique ...) puis de la taille.
Les boîtes de dialogue de sélection de couleur
Fiche d'identité
Widget : Gtk_Color_Selection_Dialog et Gtk_Color_Selection.
Package : Gtk.Color_Selection_Dialog et Gtk.Color_Selection
Description : Cette boîte de dialogue permet de sélectionner une couleur.
Méthodes
Là encore, les méthodes sont très limitées. Le constructeur ne demande qu'un titre pour votre boîte de dialogue. En revanche, pour manipuler ce widget, vous devrez récupérer son Gtk_Color_Selection à l'aide de la méthode Get_Colorsel() :
function Get_Colorsel(Color_Selection_Dialog : access Gtk_Color_Selection_Dialog_Record)
return Gtk.Color_Selection.Gtk_Color_Selection;
Une fois le Gtk_Color_Selection récupérer, vous pourrez connaître ou fixer la couleur actuelle à l'aide des deux méthodes suivantes :
--Fixer ou obtenir la couleur actuelle
procedure Set_Current_Color(Colorsel : access Gtk_Color_Selection_Record;
Color : Gdk.Color.Gdk_Color);
procedure Get_Current_Color(Colorsel : access Gtk_Color_Selection_Record;
Color : out Gdk.Color.Gdk_Color);
--Fixer ou obtenir l'ancienne couleur
procedure Set_Previous_Color(Colorsel : access Gtk_Color_Selection_Record;
Color : Gdk.Color.Gdk_Color);
procedure Get_Previous_Color(Colorsel : access Gtk_Color_Selection_Record;
Color : out Gdk.Color.Gdk_Color);
La couleur obtenue se présente sous la forme d'une variable composite Gdk_Color (oui je sais, c'est notre première variable Gdk ^^ ). Pour la manipuler, utilisez le package Gdk.Color et les méthodes suivantes :
procedure Set_Rgb (Color : out Gdk_Color; Red, Green, Blue : Guint16);
function Red (Color : Gdk_Color) return Guint16;
function Green (Color : Gdk_Color) return Guint16;
function Blue (Color : Gdk_Color) return Guint16;
function To_String (Color : Gdk_Color) return String;
Set_Rgb() vous permettra de définir votre propre couleur à partir de ses valeurs RGB (Rouge Vert et Bleu). Attention, celles-ci sont définies de 0 à 65535 et pas de 0 à 255. A l'inverse, les fonctions Red(), Green(), Blue() vous permettront de connaître chacune des composantes de votre couleur, tandis que To_String() vous renverra le code hexadécimal HTML de votre couleur Gtk.Assistant (#92D06C dans l'exemple ci-dessus).
Signaux
Le seul signal nouveau apporté par les Gtk_Color_Selection est le signal Signal_Color_Changed / "color_changed" indiquant que l'utilisateur a changé la couleur.
Description : Il s'agit là de la boîte de dialogue mère, personnalisable à volonté. Par défaut, Gtk considère qu'une boîte de dialogue est une fenêtre coupée en deux. La partie haute comprend divers widgets, tandis que la partie basse, appelée Zone d'actions, comprend des boutons rangés horizontalement.
Méthodes
Nous avons déjà vu bon nombre de méthodes des GTK_Dialog comme les constructeurs ou la méthode run(), mais en voici quelques-unes qui pourraient vous être utile pour personnaliser vos boîtes de dialogue (y compris celles vues précédemment) :
function Get_Action_Area (Dialog : access Gtk_Dialog_Record) return Gtk.Box.Gtk_Box;
function Get_Content_Area(Dialog : access Gtk_Dialog_Record) return Gtk.Box.Gtk_Box;
function Get_Vbox (Dialog: access Gtk_Dialog_Record) return Gtk.Box.Gtk_Box;
function Add_Button(Dialog : access Gtk_Dialog_Record;
Text : UTF8_String;
Response_Id : Gtk_Response_Type) return Gtk.Widget.Gtk_Widget;
Les trois premières méthodes permettent respectivement de récupérer la zone d'action, la zone de contenu et le conteneur principal de votre boîte de dialogue afin de les personnaliser. La fonction Add_Button() crée un bouton, tout en l'ajoutant à la zone d'action de votre boîte de dialogue (pas besoin de set_extra_widget() par exemple). Le paramètre Text est bien entendu le texte du bouton, Responde_Id est quant à lui le type de réponse qu'il renverra (ce sont les fameux Gtk_Response_# vus au début de cette partie).
Signaux
Enfin, voici deux signaux généraux aux boîtes de dialogue :
Signal_Close / "close" : émis lorsque l'utilisateur appuie sur la touche Echap.
Signal_Response / "response" : émis lorsque l'utilisateur clique sur l'un des widgets de la zone d'action (en général sur un bouton).
Description : Ce widget est une simple ligne séparant différentes zones d'une même fenêtre.
Méthodes
Il existe deux sortes de séparateurs : les séparateurs horizontaux (GTK_HSeparator_Record) et les séparateurs verticaux (GTK_VSeparator_Record). Ce qui implique donc deux constructeurs d'une simplicité enfantine :
procedure Gtk_New_Vseparator (Separator : out Gtk_Vseparator);
procedure Gtk_New_Hseparator (Separator : out Gtk_Hseparator);
Mais comme il ne s'agit que de deux sous-types finalement très semblables, on peut aisément transformé un GTK_HSeparator en GTK_VSeparator, il suffit de modifier leur orientation avec :
--Pour connaître l'orientation du séparateur
function Get_Orientation(Self : access Gtk_Separator_Record) return Gtk.Enums.Gtk_Orientation;
--Pour modifier l'orientation du séparateur
procedure Set_Orientation(Self : access Gtk_Separator_Record;
Orientation : Gtk.Enums.Gtk_Orientation);
Les deux orientations possibles étant Orientation_Horizontal et Orientation_Vertical.
Les flèches
Fiche d'identité
Widget : Gtk_Arrow.
Package : Gtk.Arrow
Descendance : GTK_Widget >> GTK_Misc
Description : Ce widget est une simple flèche triangulaire.
Méthodes
Il y a fort peu de méthode pour ce type de widget. Voici le constructeur et le modifieur :
Le paramètre Arrow_Type indique l'orientation de la flèche (haut, bas, gauche, droite). Il peut prendre l'une des valeurs suivantes : Arrow_Up, Arrow_Down, Arrow_Left, Arrow_Right. Quant au paramètre Shadow_Type il indique le type d'ombrage et peut prendre les valeurs suivantes : Shadow_None, Shadow_In, Shadow_Out, Shadow_Etched_In, Shadow_Etched_Out.
Le calendrier
Fiche d'identité
Widget : Gtk_Calndar.
Package : Gtk.Calendar
Descendance : GTK_Widget
Description : Ce widget affiche une grille des jours du mois et de l'année en cours.
Méthodes
Le constructeur est simplissime donc je ne l'évoque pas. Toutefois, vous pouvez personnaliser votre calendrier :
Lorsque vous utilisez la méthode Set_Display_Options(), vous devez indiquer toutes les options désirées en les additionnant. Par exemple, Set_Display_Options(option1 + option3) configurera le calendrier avec les options 1 et 3 mais pas avec la 2, même si celle-ci existait par défaut. Il existe ## options différentes :
Show_Heading : affiche le mois et l'année
Show_Day_Names : affiche les trois premières lettres du jour
No_Month_Change : empêche l'utilisateur de changer de mois et donc d'année.
Show_Week_Numbers : affiche le numéro de la semaine sur la gauche du calendrier
Week_Start_Monday : commence la semaine le lundi au lieu du dimanche (ne semble pas marcher chez moi ^^ )
D'autres méthodes sont disponibles :
procedure Get_Date(Calendar : access Gtk_Calendar_Record;
Year : out Guint;
Month : out Guint;
Day : out Guint);
function Mark_Day (Calendar : access Gtk_Calendar_Record;
Day : Guint) return Boolean;
procedure Select_Day (Calendar : access Gtk_Calendar_Record; Day : Guint);
function Select_Month(Calendar : access Gtk_Calendar_Record;
Month : Guint;
Year : Guint) return Boolean;
La méthode Get_Date() vous permet de récupérer le jour, le mois et l'année sélectionnée par l'utilisateur. Mark_Day() vous permet de marquer en gras certains jours du mois, indiqués par leur numéro (0 signifiant aucun jour). Enfin, les méthodes Select_Day() et Select_Month() vous permettent comme leur nom l'indique de sélectionner un jour ou un mois et une année particuliers.
Signaux
Les signaux disponibles sont les suivants :
Signal_Day_Selected / "day-selected" : émis lorsque l'utilisateur clique sur un jour
Signal_Day_Selected_Double_Click / "day-selected-double-click" : émis lorsque l'utilisateur double-clique sur un jour
Signal_Month_Changed / "month-changed" : émis lorsque l'utilisateur change le mois
Signal_Next_Month / "next-month" : émis lorsque l'utilisateur augmente le mois
Signal_Next_Year / "next-year" : émis lorsque l'utilisateur augmente l'année
Signal_Prev_Month / "prev-month" : émis lorsque l'utilisateur diminue le mois
Signal_Prev_Year / "prev-year" : émis lorsque l'utilisateur diminue l'année.
Les barres de progression
Fiche d'identité
Widget : Gtk_Progress_Bar.
Package : Gtk.Progress_Bar
Descendance : GTK_Widget >> GTK_Progress
Description : Ce widget est une barre affichant la progression d'un téléchargement, d'une installation ...
Méthodes
Le constructeur des GTK_Progress_Bar est sans intérêt. Passons directement aux autres méthodes que vous devriez déjà connaître puisque nous les avons déjà vu avec les GTK_Entry :
La méthode set_text() permet de définir le texte affiché sur la barre de progression (en général, il s'agit du pourcentage de progression). Les GTK_Progress_Bar ne fonctionnent pas à l'aide d'un minimum et d'un maximum, mais à l'aide d'un pourcentage de progression appelé Fraction et de type GDouble. Pour rappel, Set_Fraction() fixe ce pourcentage de progression tandis que Pulse() l'augmente de la valeur du pas (Step). Ce pas peut être défini avec Set_Pulse_Step().
Enfin, il est possible d'orienter la barre de progression : horizontale ou verticale ; progressant de gauche à droite ou de droite à gauche, de bas en haut ou de haut en bas. Les valeurs possibles des Gtk_Progress_Bar_Orientation sont : Progress_Left_To_Right, Progress_Right_To_Left, Progress_Bottom_To_Top, Progress_Top_To_Bottom.
curseurs H/VScale
En résumé :
Pour afficher du texte, utilisez les GTK_Label
Pour afficher une image, utilisez les GTK_Image
Pour saisir du texte, utilisez les GTK_GEntry ou les GTK_Text_View
Pour saisir un nombre, utilisez les GTK_Spin_Button ou les GTK_Scale
Pour afficher messages, options ou informations sur votre logiciel, ne créez pas de nouvelles GTK_Window, mais utilisez plutôt les diverses boîtes de dialogue mises à votre disposition.
N'hésitez pas à fouiner dans les divers packages de GTKAda pour découvrir votre bonheur ou allez sur le site d'Adacore pour consulter le manuel de référence.
Voilà, nous avons fait un tour d'horizon très large de ce que le langage Ada pouvait permettre. J'espère vous avoir donné goût à ce langage ou, tout du moins, vous avoir fourni les bases pour programmer correctement, que vous continuiez votre chemin avec Ada ou que vous partiez vers d'autres cieux : C, C++, Java, Python ...
Il n'est pas mauvais d'ailleurs de se frotter à d'autres langages, à leurs spécificités ou à leurs ressemblances. "La Terre est le berceau de l'humanité, mais on ne passe pas sa vie entière dans un berceau" disait Constantin Tsiolkovski, père de l'astronautique russe. Il en est de même en programmation, quel que soit votre langage favori, vous serez amenés à en utiliser d'autres. Il n'y a qu'ainsi que vous connaîtrez celui qui est fait pour vous.
Ce tutoriel est en cours de création. Il s'enrichira peu à peu de nouveaux chapitres pour vous offrir un apprentissage complet du langage. En attendant, vous pouvez retrouver l'avancement du cours sur le forum.
Merci de votre soutien, bonne lecture et n'hésitez pas à poser des questions sur les forums.

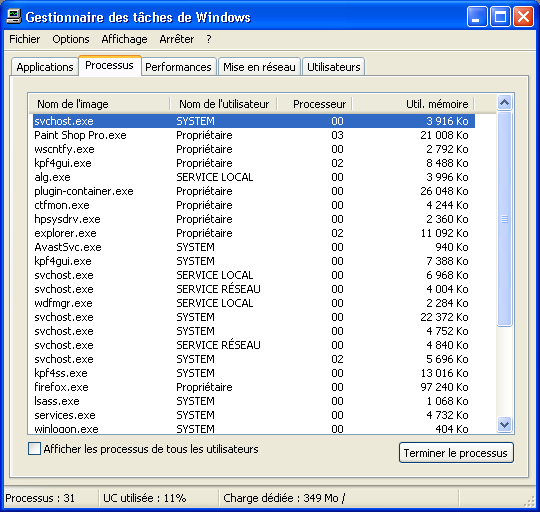
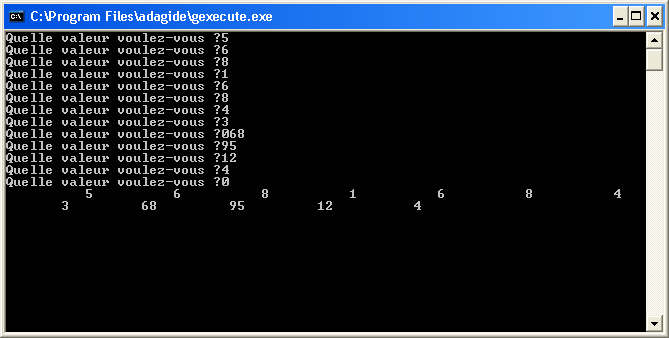
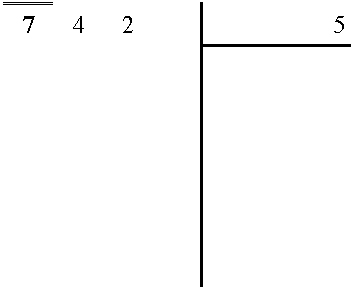
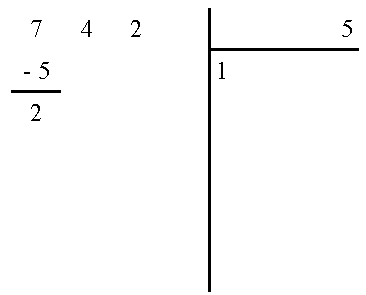

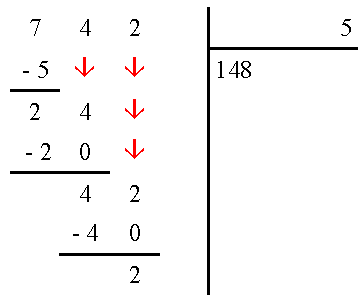
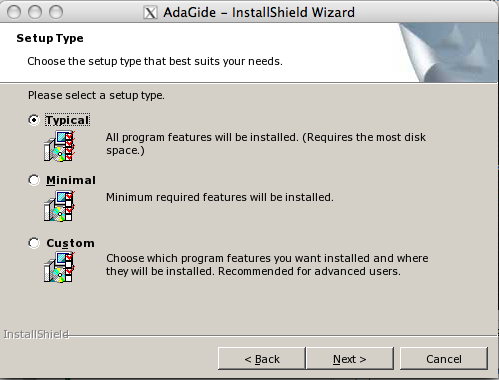
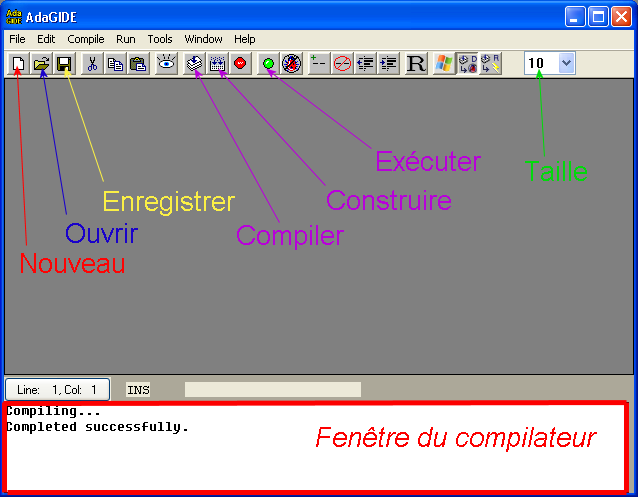
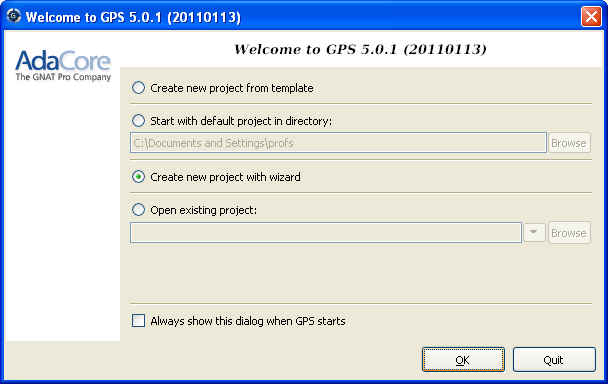
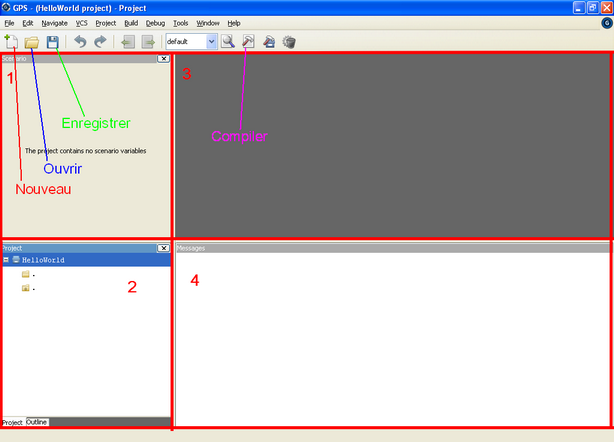
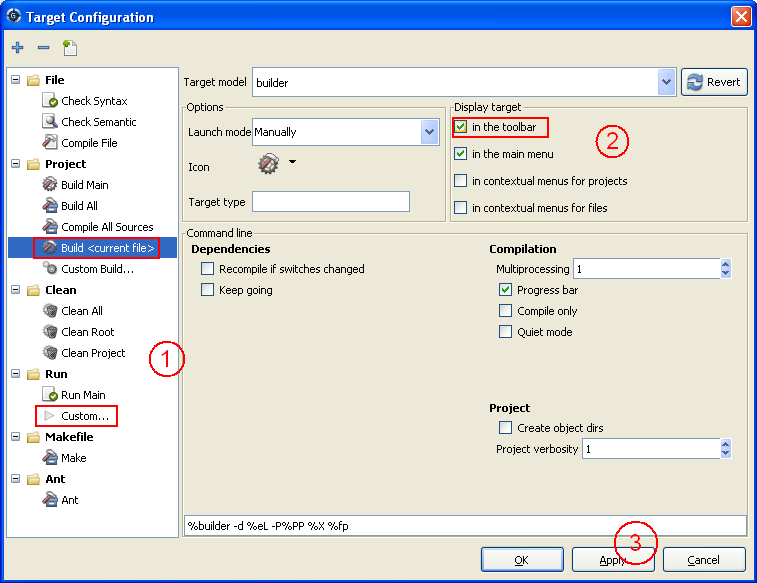


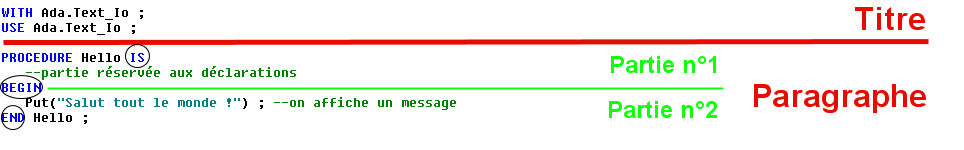

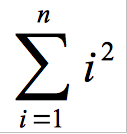
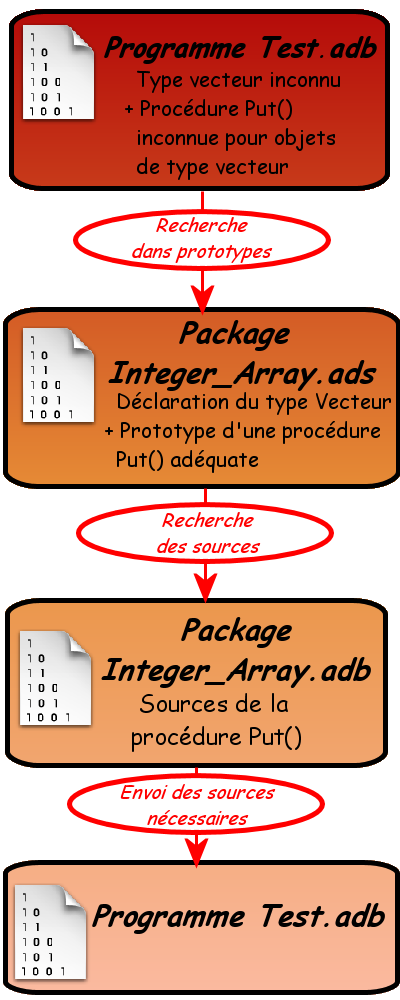

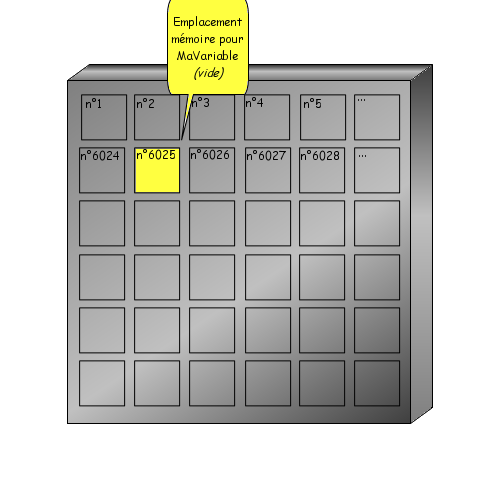
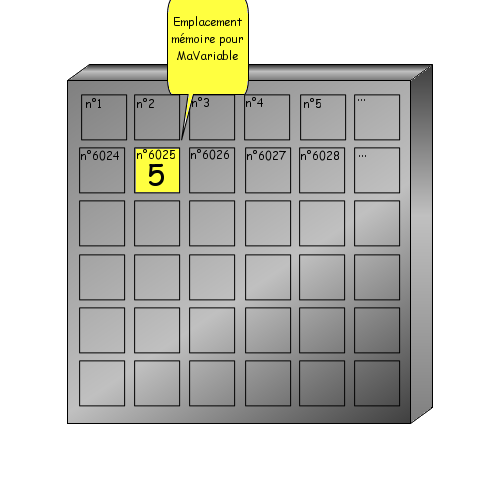
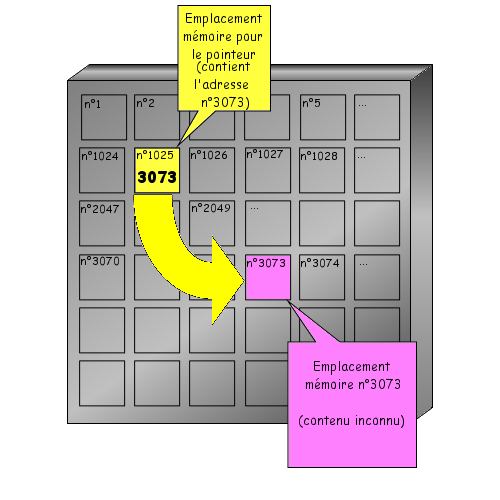
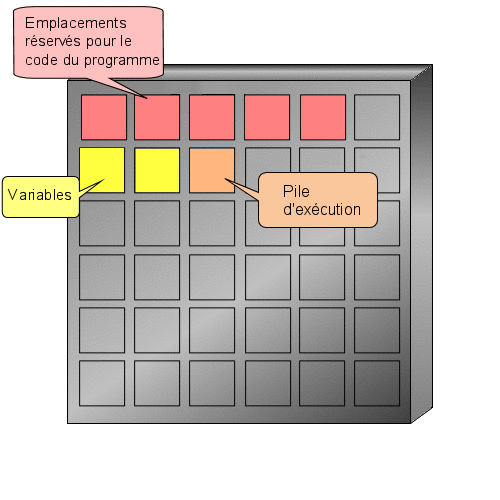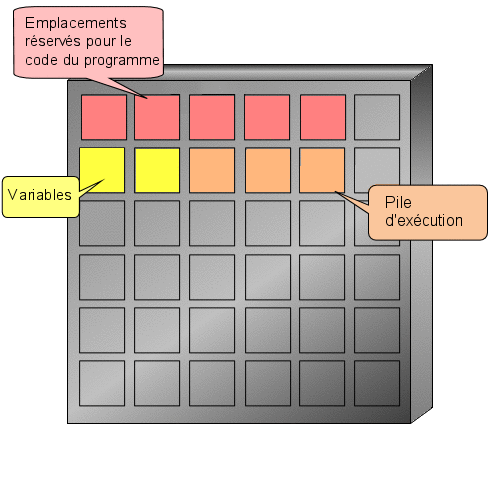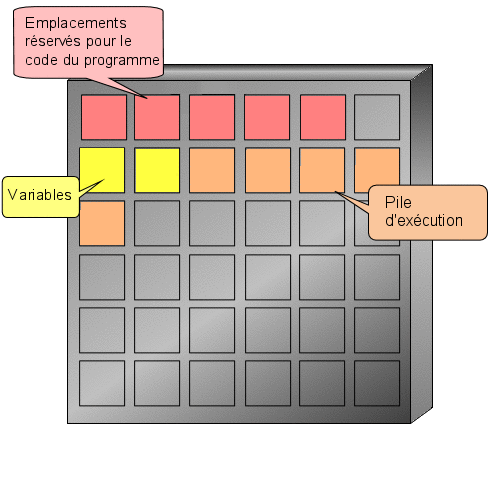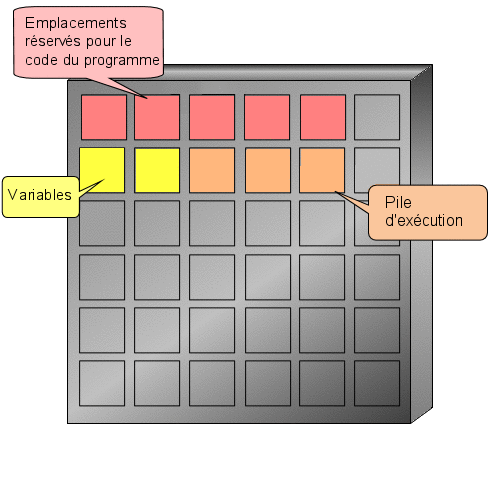
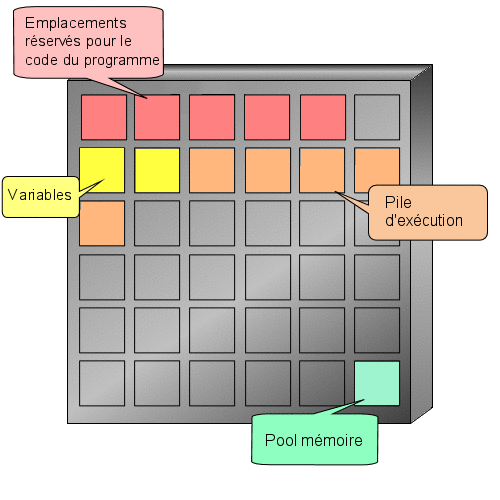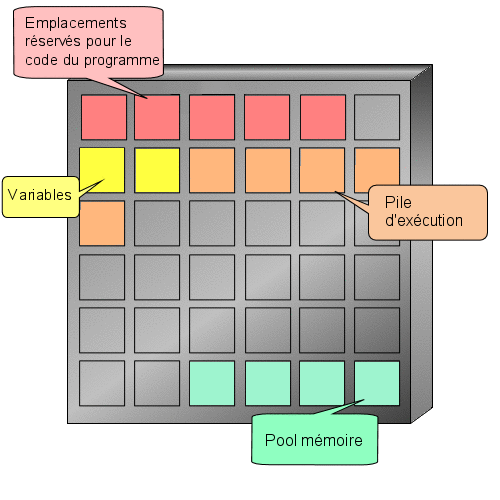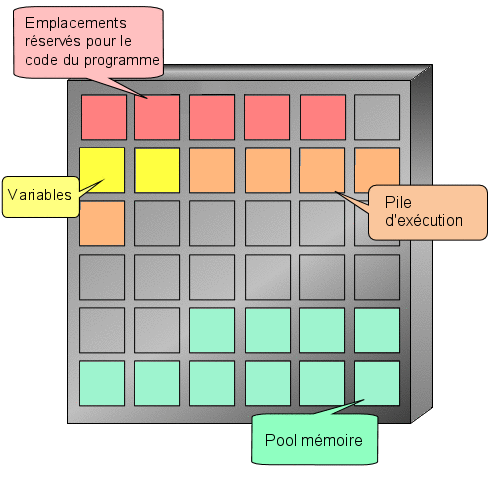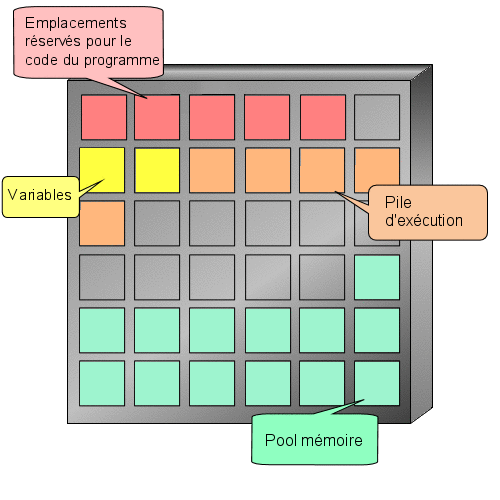


.jpg)





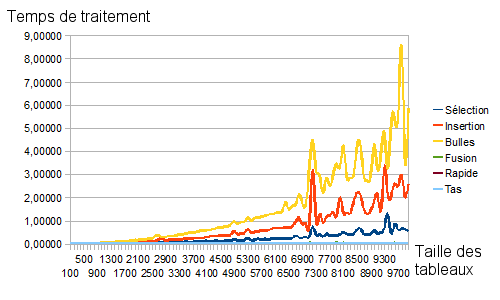
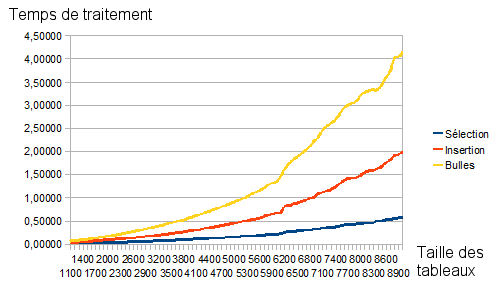
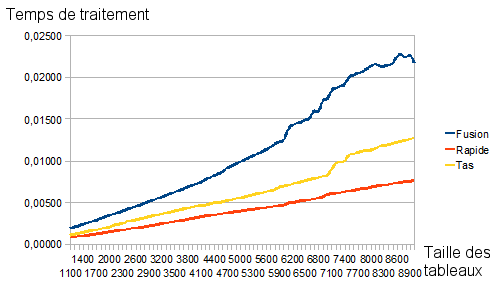

 Caractères en Ada
Caractères en Ada