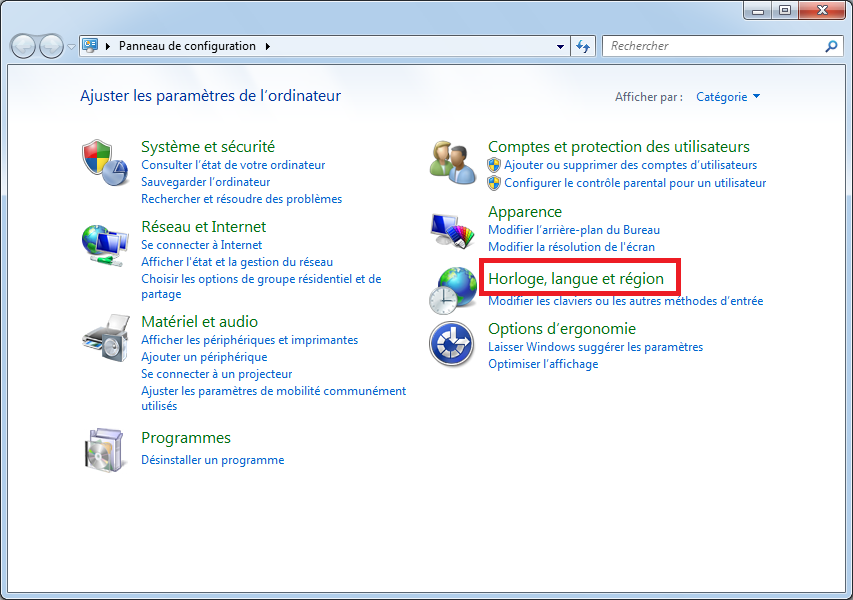
Vous avez entendu parler du langage C, du C++, et voilà qu'on vous présente maintenant le C# ! Encore un langage me direz-vous ? Oui, mais pas n'importe lequel !
Il existe beaucoup de langages de programmation, comme le C, le C++, Python, Java... Chacun a ses avantages, ses inconvénients et ses domaines d'applications.
Le C# (Prononcez "Cé charpe" ou "ci charpe" à l'anglaise), vous en avez peut-être entendu parler autour d’un café, ou bien rencontré un développeur qui en vantait les mérites ou peut-être vu une offre d’emploi intéressante sur le sujet… qui sait ?
Bref, vous avez envie de découvrir et d'apprendre le C#.
C’est justement l’objectif que se donne ce tutoriel. Il est réservé aux débutants dans la mesure où nous allons aborder ce sujet comme si nous n’en avions jamais entendu parler mais il conviendra aussi aux personnes souhaitant approfondir leurs connaissances sur ce sujet.
En lisant les chapitres les uns après les autres, vous :
commencerez à découvrir ce qu'est vraiment le C#
verrez les applications informatiques que nous pouvons réaliser avec et comment ce langage s'intègre dans un ensemble plus important
apprendrez réellement la syntaxe du C#
découvrirez comment travailler avec des données afin de manipuler des fichiers ou de lire et écrire dans une base de données
L’étude ne sera pas exhaustive tellement il y a des sujets différents rattachés mais elle fournira un point d’entrée complet pour pouvoir être efficace avec le C#. Mais plus important encore, lorsque vous aurez lu et pratiqué l’ensemble de ce tutoriel, vous serez capable de créer des applications informatiques de plusieurs sortes en utilisant le C#.
Joli programme n’est-ce pas ? :) Alors, enfilez votre tenue de combat et attaquons tout de suite le tutoriel !
Ce cours vous plaît ?
Si vous avez aimé ce cours, vous pouvez retrouver le livre "Apprenez à développer en C#" en vente sur le Site du Zéro, en librairie et dans les boutiques en ligne. Vous y trouverez ce cours adapté au format papier avec un chapitre et une préface inédits.
Vous pouvez également obtenir cet ouvrage au format eBook sur Amazon ou sur iTunes.
Dans ce tout premier chapitre, nous allons découvrir ce qu'est le C#, son histoire et son rapport avec le framework .NET. D'ailleurs, vous ne savez pas ce qu'est un framework ? Ce n'est pas grave, tout ceci sera expliqué ! :) Nous verrons dans ce chapitre ce que sont les applications informatiques et comment des langages de programmation évolués comme le C# nous permettent de réaliser de telles applications.
Et ce n'est que le début… alors ouvrez grands vos yeux, chaussez vos lunettes et explorons ce monde merveilleux !
Aux débutants ! Pas besoin d'avoir fait du développement avant pour suivre ce tutoriel ! Je vais donc faire de mon mieux pour détailler au maximum mes explications, c'est promis. Mon but est réellement de rendre ce tutoriel accessible pour les débutants.
Bien sûr, il y en a peut-être parmi vous qui ont déjà fait du C, du C++, du Java... Evidemment, si vous avez déjà fait du développement informatique, ce sera plus facile pour vous (surtout pour la première partie qui présente les bases du langage). Attention néanmoins de ne pas vouloir aller trop vite : le C# ressemble à d'autres langages mais il a quand même ses spécificités !
Esprit du tutoriel
Nous allons découvrir ensemble de nombreuses choses en apprenant à développer en C#. Il y aura bien entendu des TP pour vous faire pratiquer, afin que vous puissiez vous rendre compte de ce que vous êtes capables de faire après avoir lu plusieurs chapitres plus théoriques.
Néanmoins, je veux que vous soyez actifs ! Ne vous contentez pas de lire passivement mes explications, même lorsque les chapitres sont plutôt théoriques ! Testez les codes et les manipulations au fur et à mesure. Essayez les petites idées que vous avez pour améliorer ou adapter légèrement le code. Sortez un peu des sentiers battus du tutoriel : cela vous fera pratiquer et vous permettra de découvrir rapidement si vous avez compris ou non le chapitre. Pas d'inquiétude, si jamais vous bloquez sur quoi que ce soit qui n'est pas expliqué dans ce cours, la communauté qui sillonne les forums saura vous apporter son aide précieuse.
Durée d’apprentissage
Il faut compter plusieurs semaines pour lire, comprendre et assimiler ce tutoriel. Une fois assimilées toutes les notions présentées, il vous faudra plusieurs mois pour atteindre un niveau solide en C#. Après tout, c'est en forgeant qu'on devient forgeron.
D'ailleurs merci de m'informer du temps que vous a pris la lecture de ce cours pour que je puisse indiquer aux autres lecteurs une durée moyenne de lecture.
C'est tout ?
Non rassurez-vous, le tutoriel est loin d'être fini, vous ne voyez donc pas toutes les parties. Vous découvrirez dans ce tutoriel le début des rudiments du développement en C#. Petit à petit je compléterai le tutoriel pour ajouter la suite des rudiments du langage. Ensuite, je présenterai la programmation orientée objet et comment en faire avec le C#. Enfin, pour aller plus loin, nous étudierons l'accès aux données et d'autres surprises encore.
Le début de ce cours sera plutôt théorique. Pour savoir coder, il faut commencer par apprendre les bases du langage, c'est un passage obligé. Petit à petit j'introduirai la pratique pour illustrer certains points importants ; cela vous permettra de mieux comprendre des fonctionnements et surtout de bien mémoriser le cours.
Allez plus loin !
N'hésitez pas à regarder d'autres tutoriels portant sur le sujet. Il est toujours bon de diversifier ses sources pour avoir différentes approches du sujet.
De manière générale, je vous recommande de ne pas hésiter à tester les codes que je présenterai au fur et à mesure. Surtout, si vous avez des idées pour les améliorer un peu, faites-le ! Ca ne marchera pas à tous les coups, mais cela vous fera beaucoup plus progresser que vous ne le pensez ! Ne comptez donc pas uniquement sur les TP pour pratiquer, ce serait dommage.
Sachez aussi que je suis ouvert à toutes remarques, critiques, questions, ... portant sur ce tutoriel. N'hésitez donc pas à poster des commentaires, surtout si votre message peut être utile pour d'autres personnes. Par contre, veuillez ne pas m'envoyer de MP, sauf en cas de force majeure, parce que je n'aurai pas le temps de vous répondre individuellement, et que s'il s'agit d'une demande d'aide, les forums sont là pour ça et on vous y répondra plus rapidement que moi.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Le C# est un langage de programmation créé par Microsoft en 2002.
Ces applications informatiques peuvent être de beaucoup de sortes, par exemple une application Windows, comme un logiciel de traitement de texte ou une calculatrice ou encore un jeu de cartes. On les appelle également des clients lourds. Il est également possible de développer des applications web, comme un site d’e-commerce, un intranet, … Nous pourrons accéder à ces applications grâce à un navigateur internet que l’on appelle un client léger. Toujours grâce à un navigateur internet, nous pourrons développer des clients riches. Ce sont des applications qui se rapprochent d’une application Windows mais qui fonctionnent dans un navigateur. Bien d’autres types d'applications peuvent être écrites avec le C#, citons encore le développement d’applications mobiles sous Windows phone 7, de jeux ou encore le développement de web services …
Nous verrons un peu plus en détail en fin de tutoriel comment réaliser de telles applications. Chacun de ces domaines nécessite un tutoriel entier pour être complètement traité, aussi nous nous initierons à ces domaines sans aller trop loin non plus.
Le C# est un langage dont la syntaxe ressemble un peu au C++ ou au Java qui sont d’autres langages de programmation très populaires. Le C# est le langage phare de Microsoft. Il fait partie d’un ensemble plus important. Il est en fait une brique de ce qu’on appelle le « Framework .NET ». Gardons encore un peu de suspens sur ce qu'est le framework .NET, nous découvrirons ce que c'est un peu plus loin dans le tutoriel.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une application informatique : qu'est-ce que c'est ?
Comme vous le savez, votre ordinateur exécute des applications informatiques pour effectuer des tâches. Ce sont des logiciels comme :
Un traitement de texte
Un navigateur internet
Un jeu vidéo
...
Votre ordinateur ne peut exécuter ces applications informatiques que si elles sont écrites dans le seul langage qu'il comprend, le binaire. Techniquement, le binaire est représenté par une suite de 0 et de 1.
Il n'est bien sûr pas raisonnablement possible de réaliser une grosse application en binaire, c'est pour ça qu'il existe des langages de programmation qui permettent de simplifier l'écriture d'une application informatique.
Comment créer des programmes "simplement" ?
Je vais vous expliquer rapidement le principe de fonctionnement des langages "traditionnels" comme le C et le C++, puis je vous présenterai le fonctionnement du C#. Comme le C# est plus récent, il a été possible d'améliorer son fonctionnement par rapport au C et au C++ comme nous allons le voir.
Langages traditionnels : la compilation
Avec des langages traditionnels comme le C et le C++, on écrit des instructions simplifiées, lisibles par un humain comme :
printf("Bonjour");
Ce n'est pas vraiment du français, mais c'est quand même beaucoup plus simple que le binaire et on comprend globalement avec cet exemple que l'on va afficher le mot Bonjour.
Bien entendu, l'ordinateur ne comprend pas ces instructions. Lui, il veut du binaire, du vrai. :pirate: Pour obtenir du binaire à partir d'un code écrit en C ou C++, on doit effectuer ce qu'on appelle une compilation. Le compilateur est un programme qui traduit le code source en binaire exécutable :
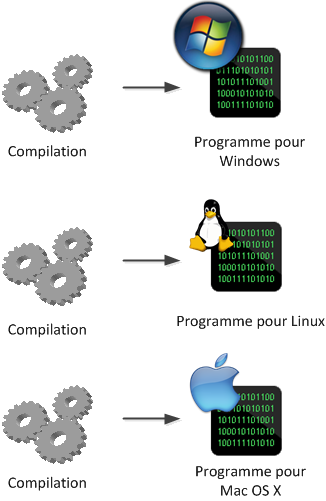
Cette méthode est efficace et a fait ses preuves. De nombreuses personnes développent toujours en C et C++ aujourd'hui. Néanmoins, ces langages ont aussi un certain nombre de défauts dus à leur ancienneté. Par exemple, un programme compilé (binaire) ne fonctionne que sur la plateforme pour laquelle il a été compilé. Cela veut dire que si vous compilez sous Windows, vous obtenez un programme qui fonctionne sous Windows uniquement (et sur un type de processeur particulier). Impossible de le faire tourner sous Mac OS X ou Linux simplement, à moins de le recompiler sous ces systèmes d'exploitation (et d'effectuer au passage quelques modifications).
Les programmes binaires ont ce défaut : ils ne fonctionnent que pour un type de machine. Pour les développeurs qui écrivent le code, c'est assez fastidieux à gérer.
Langages récents : le code managé
Les langages récents, comme le C# et le Java, résolvent ce problème de compatibilité tout en ajoutant de nombreuses fonctionnalités appréciables au langage, ce qui permet de réaliser des programmes beaucoup plus efficacement.
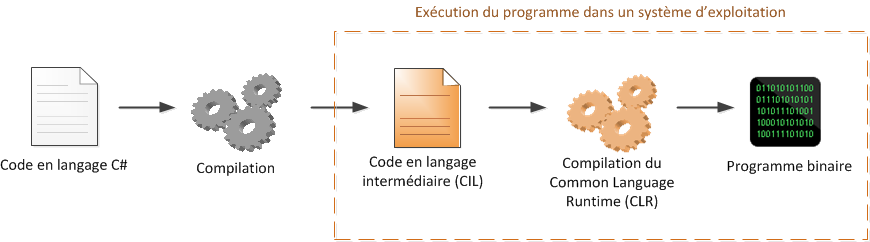
La compilation en C# ne donne pas un programme binaire, contrairement au C et au C++. Le code C# est en fait transformé dans un langage intermédiaire (appelé CIL ou MSIL) que l'on peut ensuite distribuer à tout le monde. Ce code, bien sûr, n'est pas exécutable lui-même, car l'ordinateur ne comprend que le binaire.
Regardez bien ce schéma pour comprendre comment cela fonctionne :
Le code en langage intermédiaire (CIL) correspond au programme que vous allez distribuer. Sous Windows, il prend l'apparence d'un .exe comme les programmes habituels, mais il ne contient en revanche pas de binaire.
Lorsqu'on exécute le programme CIL, celui-ci est lu par un autre programme (une machine à analyser les programmes, appelée CLR) qui le compile cette fois en vrai programme binaire. Cette fois, le programme peut s'exécuter, ouf !
Ca complique bien les choses quand même ! Est-ce bien utile ?
Cela offre beaucoup de souplesse au développeur. Le code en langage intermédiaire (CIL) peut être distribué à tout le monde. Il suffit d'avoir installé la machine CLR sur son ordinateur, qui peut alors lire les programmes en C# et les compiler "à la volée" en binaire. Avantage : le programme est toujours adapté à l'ordinateur sur lequel il tourne.
Cette complexité ralentit légèrement la vitesse d'exécution des programmes (par rapport au C ou au C++), mais la différence est aujourd'hui vraiment négligeable par rapport aux gains que cela apporte.
Donc, en théorie, il est possible d'utiliser n'importe quelle application compilée en langage intermédiaire à partir du moment où il y a une implémentation du CLR disponible. En réalité, il n'y a que sous Windows qu'il existe une implémentation complète du CLR. Il existe cependant une implémentation partielle sous Linux : Mono. Cela veut dire que si votre programme utilise des fonctionnalités qui ne sont pas couvertes par Mono, il ne fonctionnera pas.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
J'ai dit juste au dessus que le C# était compilé en langage intermédiaire et qu'on le retrouve sous la forme d'un .exe comme les programmes habituels.
Par contre, c'est un peu incomplet.
Il est possible de créer des programmes (.exe) qui pourront directement être exécuté par le CLR, mais il est également possible de créer des bibliothèques sous la forme d'un fichier possédant l'extension « .dll ».
On appelle ces deux formes de programmes des assemblages, mais on utilise globalement toujours le mot anglais « assembly ».
Les fichiers .exe sont des assemblys de processus
Les fichiers .dll sont des assemblys de bibliothèques
Concrètement, cela signifie que le fichier .exe servira à lancer une application et qu'une dll pourra être partagée entre plusieurs applications .exe afin de réutiliser du code déjà écrit.
Nous verrons un peu plus loin comment ceci est possible.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
J'ai commencé à vous parler du C# qui était une brique du framework .NET. Il est temps d'en savoir un peu plus sur ce fameux framework.
Commençons par le commencement : comment cela se prononce ?
Citation : Shakespeare
DOTTE NETTE
Citation : maitre Capello
POINT NETTE
Je vous accorde que le nom est bizarre, point trop net pourrions-nous dire … Surtout que le nom peut être trompeur. Avec l’omniprésence d’internet, son abréviation (net) ou encore des noms de domaines (.net), on pourrait penser que le framework .NET est un truc dédié à internet. Que nenni.
Nous allons donc préciser un peu ce qu’est le framework .NET pour éviter les ambigüités.
Première chose à savoir, qu’est-ce qu’un framework ?
Pour simplifier, on peut dire qu’un framework est une espèce de grosse boite à fonctionnalités qui va nous permettre de réaliser des applications informatiques de toutes sortes.
Le framework .NET est un framework créé par Microsoft en 2002, en même temps que le C#, qui est principalement dédié à la réalisation d’applications fonctionnant dans des environnements Microsoft. Nous pourrons par exemple réaliser des programmes qui fonctionnent sous Windows, ou bien des sites web ou encore des applications qui fonctionnent sur téléphone mobile, etc.
Disons que la réalisation d’une application informatique, c’est un peu comme un chantier (je dis pas ça parce que c'est toujours en retard, même si c'est vrai :) ). Il est possible de construire différentes choses, comme une maison, une piscine, une terrasse, etc. Pour réaliser ces constructions, nous allons avoir besoin de matériaux, comme des briques, de la ferraille, etc. Certains matériaux sont communs à toutes les constructions (fer, vis, …) et d’autres sont spécifiques à certains domaines (pour construire une piscine, je vais avoir besoin d’un liner par exemple).
On peut voir le framework .NET comme ces matériaux, c’est un ensemble de composants que l’on devra assembler pour réaliser notre application. Certains sont spécifiques pour la réalisation d’applications web, d’autres pour la réalisation d’applications Windows, etc.
Pour réaliser un chantier, nous allons avoir besoin d’outils pour manipuler les matériaux. Qui envisagerait de visser une vis avec les doigts ou de poser des parpaings sans les coller avec du mortier ? C’est la même chose pour une application informatique, pour assembler notre application, nous allons utiliser un langage de programmation : le C#.
A l’heure où j’écris ces lignes, le C# est en version 4 ainsi que le framework .NET. Ce sont des versions stables et utilisées par beaucoup de personnes. Chaque version intermédiaire a apporté son lot d’évolutions. Le framework .NET et le C# sont en perpétuelle évolution preuve de la dynamique apportée par Microsoft.
C’est tout ce qu’il y a à savoir pour l’instant, nous reviendrons un peu plus en détail sur le framework .NET dans les chapitres suivants. Pour l’heure, il est important de retenir que c’est grâce au langage de programmation C# et grâce aux composants du framework .NET que nous allons pouvoir développer des applications informatiques.
En résumé
Le C# est un langage de programmation permettant d’utiliser le framework .NET. C’est le langage phare de Microsoft.
Le framework .NET est une énorme boîte à fonctionnalités permettant la création d’applications.
Le C# permet de développer des applications de toutes sortes, exécutables par le CLR qui traduit le MSIL en binaire.
Il est possible de créer des assemblys de deux sortes : des assemblys de processus exécutables par le CLR et des assemblys de bibliothèques.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre nous allons faire nos premiers pas avec le C#. Nous allons dans un premier temps installer et découvrir les outils qui nous seront nécessaires pour réaliser des applications informatiques avec le C#. Nous verrons comment démarrer avec ces outils et à la fin de ce chapitre, nous serons capables de créer un petit programme qui affiche du texte simple et nous aurons commencé à nous familiariser avec l’environnement de développement.
Il faut bien commencer par les bases, mais vous verrez comme cela peut être gratifiant d’arriver enfin à faire un petit quelque chose. Allez, c’est parti ! :)
J’espère vous avoir donné envie de démarrer l’apprentissage du C#, cependant, il nous manque encore quelque chose pour pouvoir sereinement attaquer cet apprentissage.
Bien sûr, vous allez avoir besoin d’un ordinateur, mais a priori, vous l’avez déjà … S’il n’est pas sous Windows, mais sous linux, vous pouvez utiliser Mono qui va permettre d’utiliser le C# sous linux. Cependant, Mono n’est pas aussi complet que le C# et le framework .NET sous Windows, en l’utilisant vous risquez de passer à côté de certaines parties du tutoriel.
Pour reprendre la métaphore du chantier, on peut dire qu’il va également nous manquer un chef de chantier. Il n’est pas forcément nécessaire en théorie, mais dans la pratique il se révèle indispensable pour mener à bien son chantier.
Ce chef de chantier c’est en fait l’outil de développement. Il va nous fournir les outils pour orchestrer nos développements.
C’est entre autres :
Un puissant éditeur
Un compilateur
Un environnement d’exécution
L’éditeur de texte va nous servir à créer des fichiers contenant des instructions en langage C#. Le compilateur va servir à transformer ces fichiers en une suite d'instructions compréhensibles par l'ordinateur, comme nous l'avons déjà vu. Le moteur d’exécution va permettre de faire les actions informatiques correspondantes (afficher une phrase, réagir au clic de la souris, etc.), c'est le CLR dont on a déjà parlé.
Enfin, nous aurons besoin d’une base de données. Nous y reviendrons plus en détail ultérieurement, mais la base de données est un endroit où seront stockées les données de notre application. C’est un élément indispensable à mesure que l’application grandit.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons donc besoin de notre chef de chantier, l’outil de développement. C’est un logiciel qui va nous permettre de créer des applications et qui va nous fournir les outils pour orchestrer nos développements. La gamme de Microsoft est riche en outils professionnels de qualité pour le développement, notamment grâce à Visual Studio.
Nous aurons recours au terme IDE régulièrement.
Pour apprendre et commencer à découvrir l'environnement de développement, Microsoft propose gratuitement Visual Studio dans sa version express. C’est une version allégée de l’environnement de développement qui permet de faire plein de choses, mais avec des outils en moins par rapport aux versions payantes. Rassurez-vous, ces versions gratuites sont très fournies et permettent de faire tout ce dont on a besoin pour apprendre le C# et suivre ce tutoriel.
Pour réaliser des applications d'envergure, il pourra cependant être judicieux d'investir dans l'outil complet et ainsi bénéficier de fonctionnalités complémentaires qui permettent d'améliorer, de faciliter et d'industrialiser les développements.
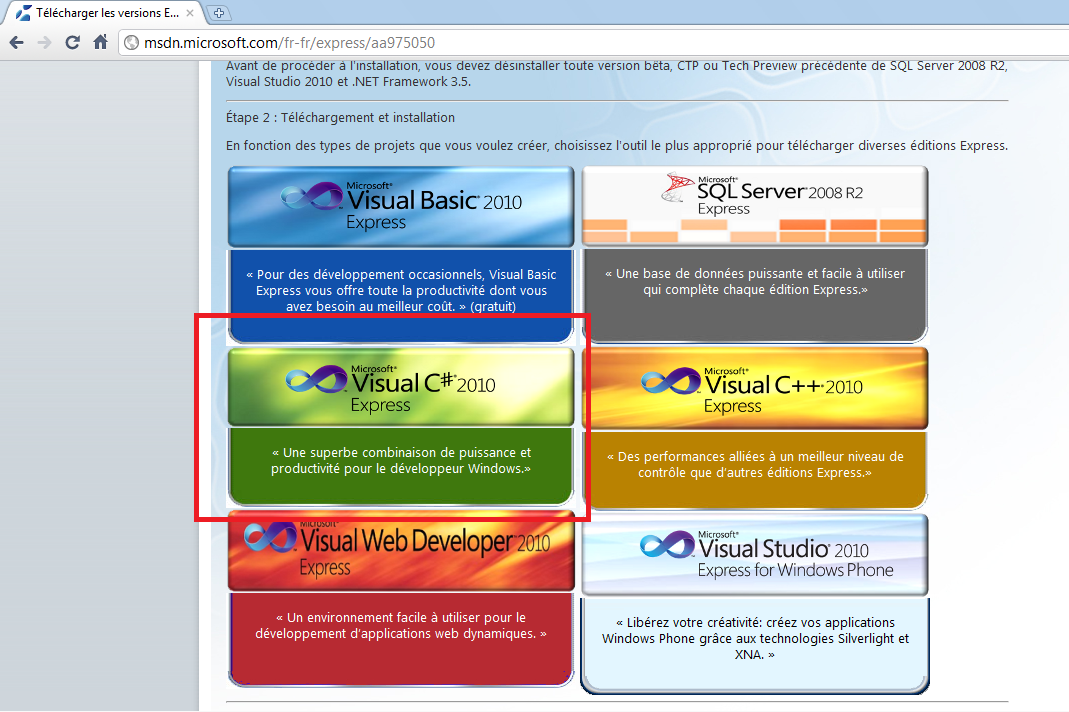
Pour développer en C# gratuitement et créer des applications Windows, nous allons avoir besoin de Microsoft Visual C# 2010 Express que vous pouvez télécharger en vous rendant sur cette page.
Pour résumer :
Visual Studio est la version payante de l'outil de développement.
Microsoft Visual C# 2010 Express est une version allégée et gratuite de Visual Studio, dédiée au développement en C#. Exactement ce qu'il nous faut :)
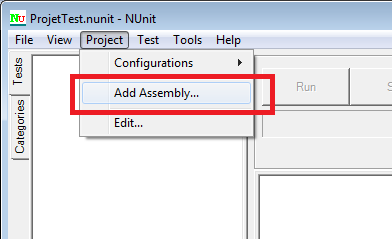
Cliquez sur Visual C# 2010 Express et choisissez la langue qui vous convient. Puis cliquez sur Téléchargez.
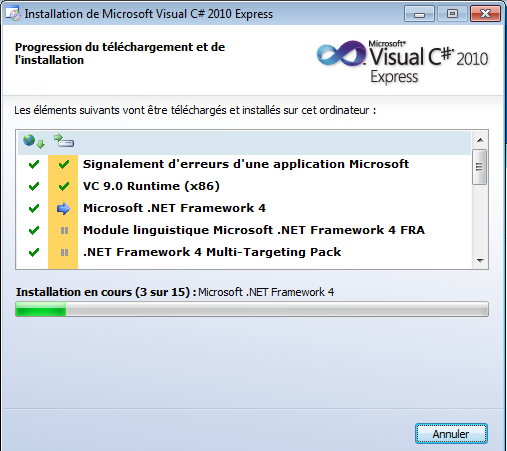
Une fois l’exécutable téléchargé, il ne reste plus qu’à le lancer et l’installation démarre :
Cliquez sur Suivant pour démarrer l’installation :
Vous devez à présent lire la licence d'utilisation du logiciel et l'accepter pour pouvoir continuer l'installation :
Une application sans données, c'est plutôt rare. C'est un peu comme un site d'e-commerce sans produits, un traitement de texte sans fichiers ou le site du zéro sans tutoriel. On risque de vite s'ennuyer :) .
Heureusement, le programme d’installation nous propose d’installer « Microsoft SQL Server 2008 express Service Pack 1 ».
Microsoft propose en version gratuite un serveur de base de données allégé. Il va nous permettre de créer facilement une base de données et de l’utiliser depuis nos applications en C#.
Nous avons également évoqué dans l'introduction qu'il était possible de réaliser des applications qui ressemblent à des applications Windows mais dans un navigateur, que nous avons appelé « clients riches ». Silverlight va justement permettre de créer ce genre d'application.
Cochez donc tout pour installer Silverlight et Sql Server et cliquez sur suivant :
Cliquez sur Installer en changeant éventuellement le dossier d'installation :
L'installation démarre (vous devez être connecté à Internet) :
Une fois l'installation terminée cliquez sur Quitter.
A l’heure où j’écris ces lignes, il existe un service pack pour visual studio, le service pack 1. C’est un ensemble de corrections qui permettent d’améliorer la stabilité du logiciel. Je vous invite à télécharger et installer ce service pack.
Vous voilà avec votre copie de Visual C# express qui va vous permettre de créer des programmes en C# gratuitement et facilement. L'installation de l'outil de développement est terminée.
En résumé, nous avons installé un outil de développement, Visual C# 2010 dans sa version express et une base de données, SQL Server express 2008. Nous avons tous les outils nécessaires et nous allons pouvoir démarrer (enfin !) l'apprentissage et la pratique du C#.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous allons vérifier que l'installation de Visual C# express a bien fonctionné. Et pour ce faire, nous allons le démarrer et commencer à prendre en main ce formidable outil de développement.
Il vous semblera surement très complexe au début mais vous allez voir, si vous suivez ce tutoriel pas à pas, vous allez apprendre les fonctionnalités indispensables. Elles seront illustrées par des copies d'écrans vous permettant de plus facilement vous y retrouver. A force d’utiliser Visual C# express, vous verrez que vous vous sentirez de plus en plus à l’aise et peut-être oserez-vous aller fouiller dans les menus ? :D
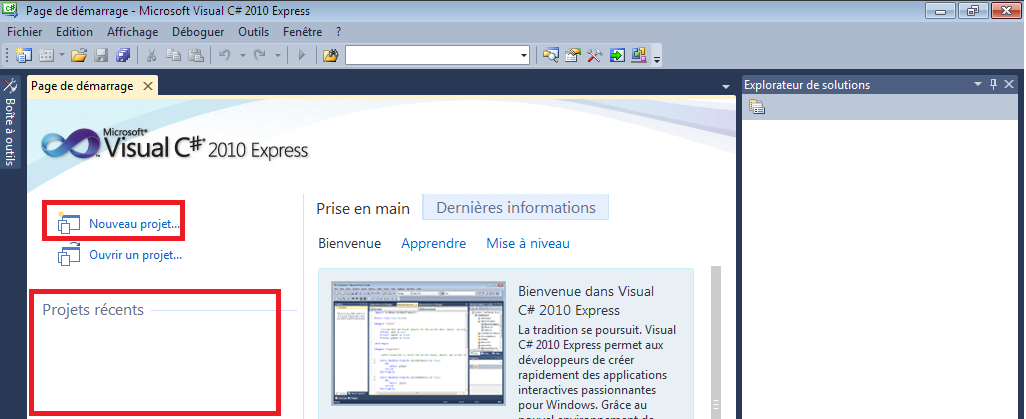
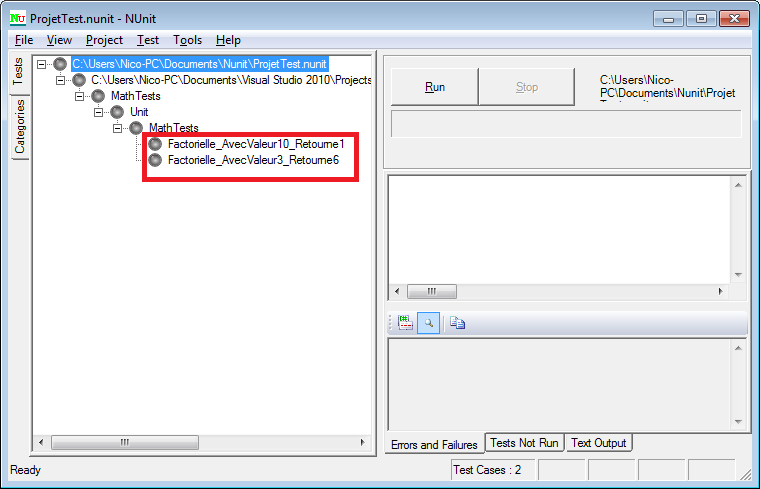
Commencez par démarrer Visual C# 2010 Express. Le logiciel s’ouvre sur la page de démarrage de Visual C# 2010 Express :
Les deux zones entourées de rouge permettent respectivement de créer un nouveau projet et d’accéder aux anciens projets déjà créés. Dans ce deuxième cas, comme je viens d’installer le logiciel, la liste est vide.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
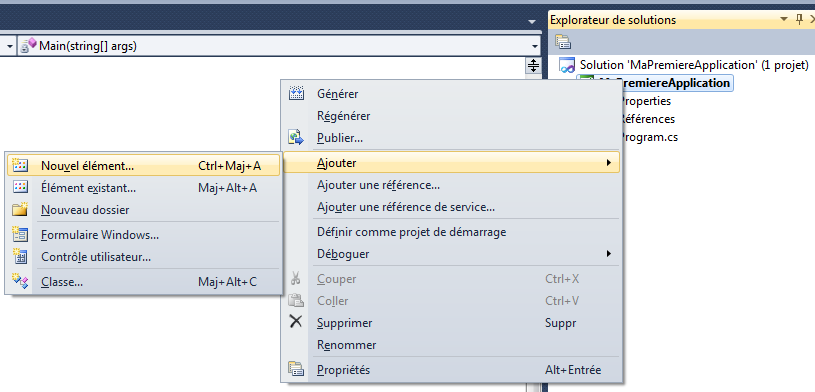
Commençons par créer un nouveau projet en cliquant dans la zone rouge. Cette commande est également accessible via le menu Fichier > Nouveau > Projet
Un projet va contenir les éléments de ce que l’on souhaite réaliser. Cela peut être par exemple une application web, une application Windows, etc …
Le projet est aussi un container de fichiers et notamment dans notre cas de fichiers en langage C# qui vont permettre de construire ce que l’on souhaite réaliser. Le projet est en fait représenté par un fichier dont l’extension est .csproj. Son contenu décrit les paramètres de configuration correspondant à ce que l’on souhaite réaliser et les fichiers qui composent le projet.
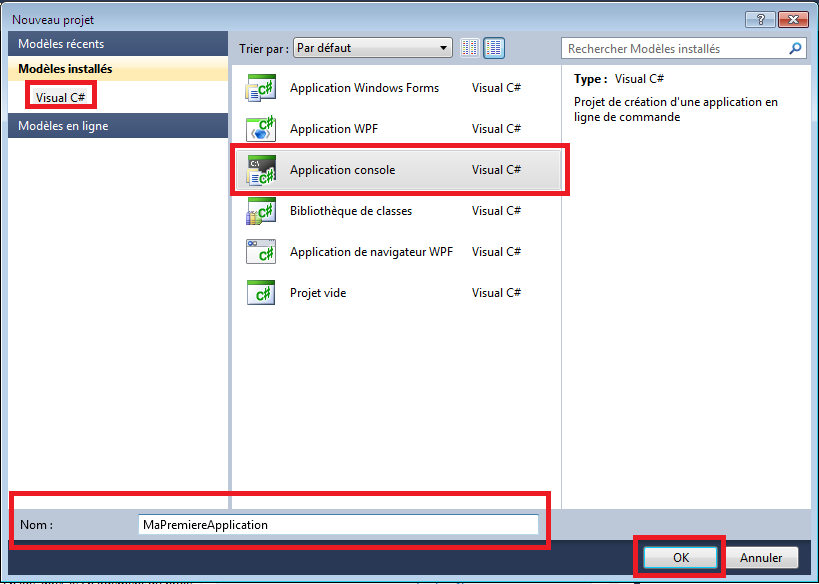
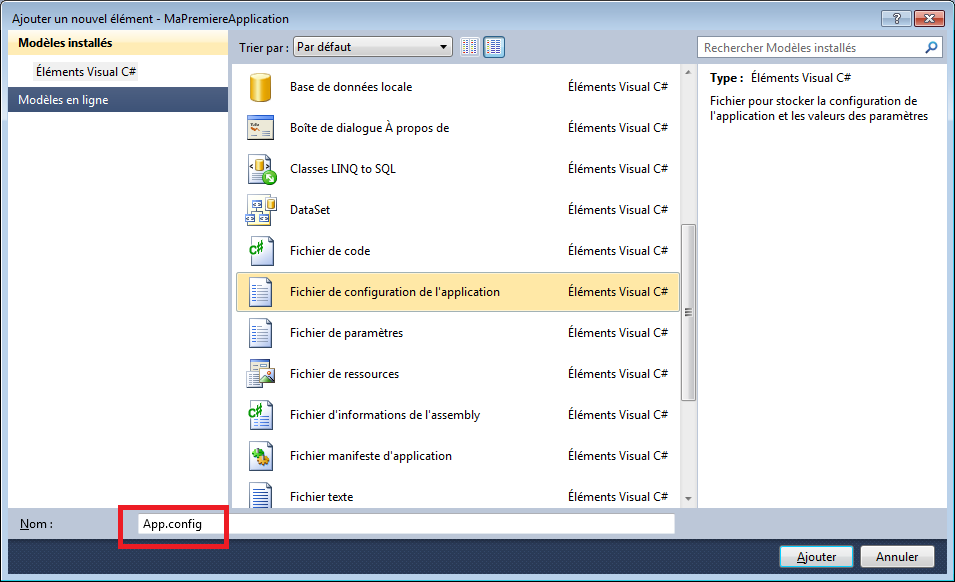
Créons donc un nouveau projet. La fenêtre de création de nouveau projet s’ouvre et nous avons plusieurs possibilités de choix. Nous allons dans un premier temps aller dans Visual C# pour choisir de créer une Application console.
Ce que nous faisons ici, c’est utiliser ce qu’on appelle un « modèle » (plus couramment appelé par son équivalent anglais : « template ») de création de projet.
Si vous naviguez à l’intérieur des différents modèles, vous pourrez constater que Visual C# nous propose des modèles de projets plus ou moins compliqués. Ces modèles sont très utiles pour démarrer un projet car toute la configuration du projet est déjà faite. Le nombre de modèles peut être différent en fonction de votre version de Visual Studio ou du nombre de versions express installées.
L’application Console est la forme de projet pouvant produire une application exécutable la plus simple. Elle permet de réaliser un programme qui va s’exécuter dans la console noire qui ressemble à une fenêtre ms-dos, pour les dinosaures comme moi qui ont connu cette époque … A noter que les projets de type « Bibliothèque de classes » permettent de générer des assemblys de bibliothèques (.dll).
Dans cette console, nous allons pouvoir notamment afficher du texte simple. Ce type de projet est parfait pour démarrer l’apprentissage du C# car il n’y a besoin que de savoir comment afficher du texte pour commencer alors que pour réaliser une application graphique par exemple, il y a beaucoup d’autres choses à savoir.
En bas de la fenêtre de création de projet, nous avons la possibilité de choisir un nom pour le projet, ici ConsoleApplication1. Changeons le nom de notre application, par exemple "MaPremiereApplication", dans la zone correspondante.
Cliquons sur OK pour valider la création de notre projet.
Visual C# Express crée alors pour nous les fichiers composant une application console vide, qui utilise le C# comme langage et que nous avons nommé MaPremiereApplication.
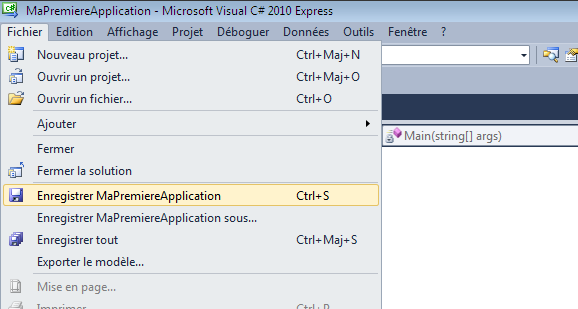
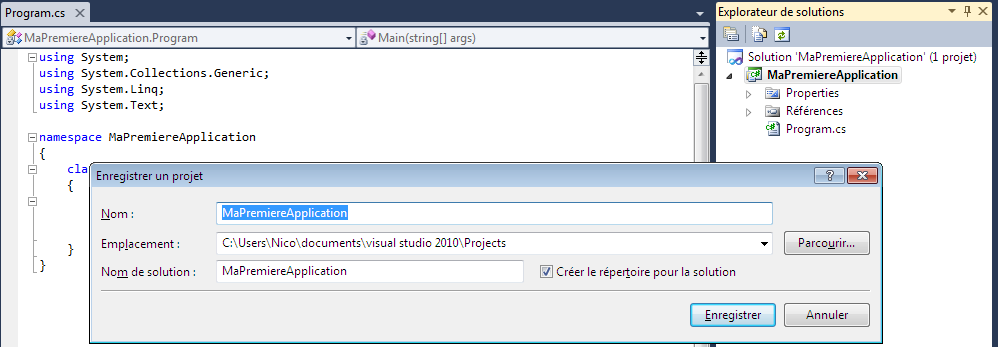
Avant toute chose, nous allons enregistrer le projet. Allons dans le menu Fichier > Enregistrer (ou utiliser le raccourci bien connu ctrl+s) :
Visual C# Express nous ouvre la fenêtre d’enregistrement de projet :
Nous pouvons donner un nom, préciser un emplacement où nous souhaitons que les fichiers soient enregistrés et un nom de solution. Une case à cocher pré-cochée nous propose de créer un répertoire pour la solution. C’est ce que nous allons faire et cliquons sur Enregistrer.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Allons dans l’emplacement renseigné (ici c:\users ico\documents\visual studio 2010\Projects), nous pouvons constater que Visual C# Express a créé un répertoire MaPremiereApplication, c’est le fameux répertoire pour la solution qu’il nous a proposé de créer.
Dans ce répertoire, nous remarquons notamment un fichier MaPremiereApplication.sln.
C’est ce qu'on appelle le fichier de solution ; il s’agit juste d’un container de projets qui va nous permettre de visualiser nos projets dans visual C# express.
En l’occurrence, pour l’instant, nous avons un seul projet dans la solution: l’application MaPremiereApplication, que nous retrouvons dans le sous répertoire MaPremiereApplication et qui contient notamment le fichier de projet : MaPremiereApplication.csproj.
Il y a encore un fichier digne d’intérêt (pour l’instant) dans ce répertoire, il s’agit du fichier Program.cs. Les fichiers dont l’extension est .cs contiennent du code C#, c’est dans ce fichier que nous allons commencer à taper nos premières lignes de code …
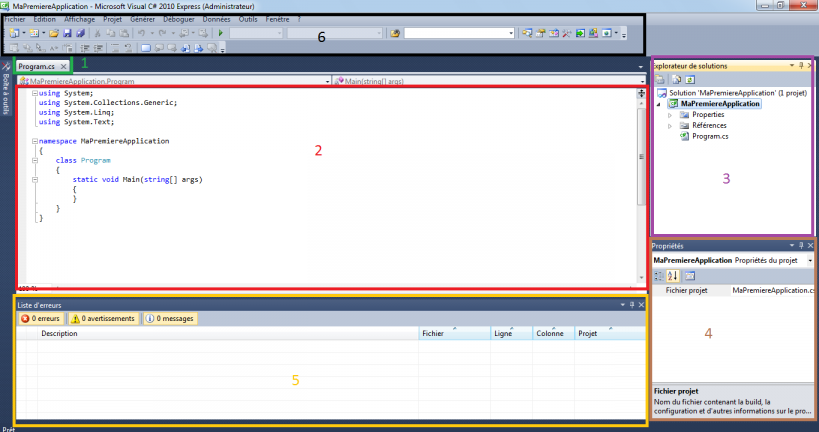
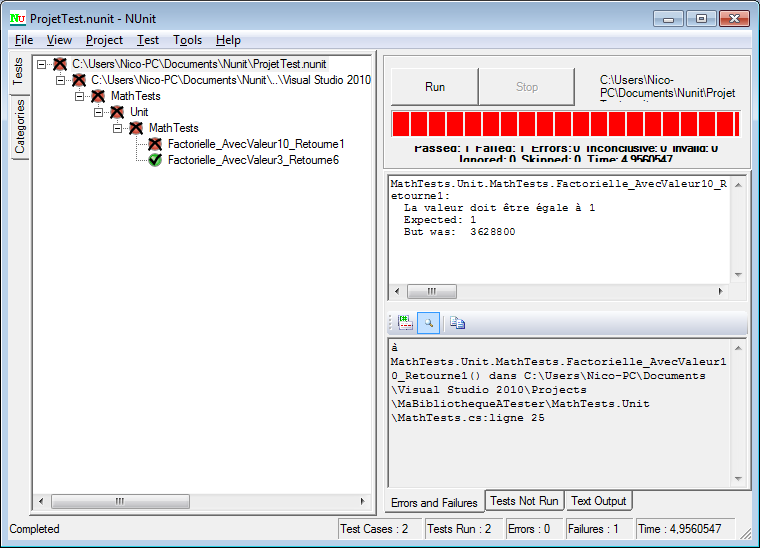
Si nous retournons dans l’interface de Visual C# express, nous pouvons retrouver quelque chose comme ça :
La zone verte numéro 1 contient les différents fichiers ouverts sous la forme d’un onglet. On voit que par défaut, Visual C# nous a créé et ouvert le fichier Program.cs.
Dans la zone rouge numéro 2, c’est l’éditeur de code. Il affiche le contenu du fichier ouvert. Nous voyons des mots que nous ne comprenons pas encore. C’est du code qui a été automatiquement généré par Visual C#. Nous pouvons observer que les mots sont de différentes couleurs. En effet, l’éditeur Visual C# express possède ce qu’on appelle une coloration syntaxique, c'est-à-dire que certains mots clés sont colorés d’une couleur différente en fonction de leur signification ou de leur contexte afin de nous permettre de nous y retrouver plus facilement.
La zone numéro 3 en violet est l’explorateur de solutions, c’est ici que l’on voit le contenu de la solution sur laquelle nous travaillons en ce moment. En l’occurrence, il s’agit de la solution « MaPremiereApplication » qui contient un unique projet « MaPremiereApplication ». Ce projet contient plusieurs sous éléments :
Properties : contient des propriétés de l’application, on ne s’en occupe pas pour l’instant
Références : contient les références de l’application, on ne s’en occupe pas pour l’instant
Program.cs est le fichier qui a été généré par Visual C# et qui contient le code C#. Il nous intéresse fortement !!
La zone 4 en brun est la zone contenant les propriétés de ce sur quoi nous travaillons en ce moment. Ici, nous avons le curseur positionné sur le projet, il n’y a pas beaucoup d’informations excepté le nom du fichier de projet. Nous aurons l’occasion de revenir sur cette fenêtre plus tard.
La zone 5 en jaune n’est pas affichée au premier lancement, elle contient la liste des erreurs, des avertissements et des messages de notre application. Nous verrons comment l’afficher un peu plus bas.
La zone 6 en noir est la barre d'outils, elle possède plusieurs boutons que nous pourrons utiliser, notamment pour exécuter notre application.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Allons donc dans la zone 2 réservée à l’édition de notre fichier Program.cs qui est le fichier contenant le code C# de notre application.
Les mots présents dans cette zone sont ce qu’on appelle des instructions de langage. Elles vont nous permettre d’écrire notre programme. Nous reviendrons plus loin sur ce que veulent dire les instructions qui ont été générées par Visual C#, pour l’instant, rajoutons simplement l’instruction suivante après l'accolade ouvrante :
Console.WriteLine("Hello World !!");
de manière à avoir :
static void Main(string[] args)
{
Console.WriteLine("Hello World !!");
}
Nous venons d’écrire une instruction qui va afficher la phrase “Hello World !!”, pour l’instant vous avez juste besoin de savoir ça. Nous étudierons plus en détail ultérieurement à quoi cela correspond exactement.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ca y est ! Nous avons écrit notre premier code qui affiche un message très populaire. Mais pour le moment, ça ne fait rien. On veut voir ce que ça donne !!!
Comme je vous comprends.
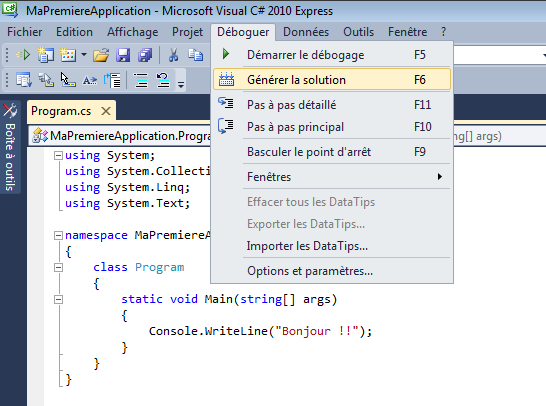
La première chose à faire est de transformer le langage C# que nous venons d’écrire en programme exécutable. Cette phase s’appelle la « génération de la solution » sous Visual C#. On l’appelle souvent la « compilation » ou en anglais le « build ».
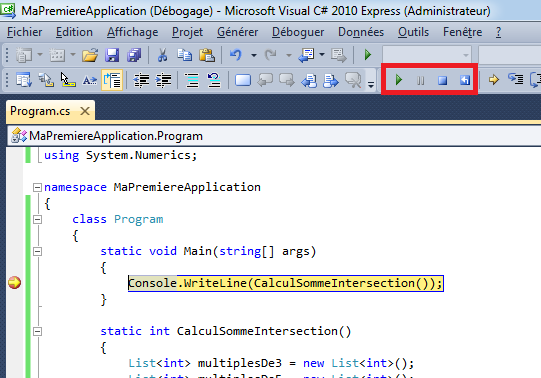
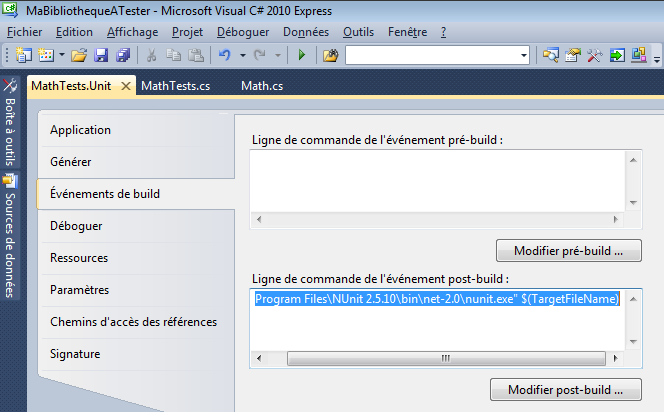
Allez dans le menu Déboguer et cliquez sur « Générer la solution » :
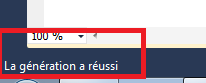
Visual C# lance alors la génération de la solution et on voit dans la barre des taches en bas à gauche qu’il travaille jusqu’à nous indiquer que la génération a réussi :
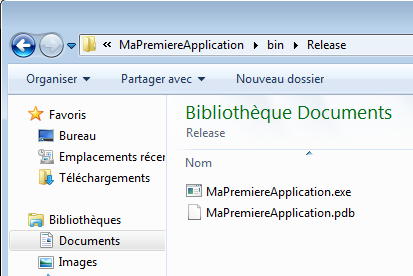
Si nous allons dans le répertoire contenant la solution, nous pouvons voir dans le répertoire MaPremiereApplication\MaPremiereApplication\bin\Release qu’il y a deux fichiers :
MaPremiereApplication.exe
MaPremiereApplication.pdb
Le premier est le fichier exécutable, possédant l’extension .exe, qui est le résultat du processus de génération. Il s’agit bien de notre application.
Le second est un fichier particulier qu’il n’est pas utile de connaitre pour l’instant, nous allons l’ignorer.
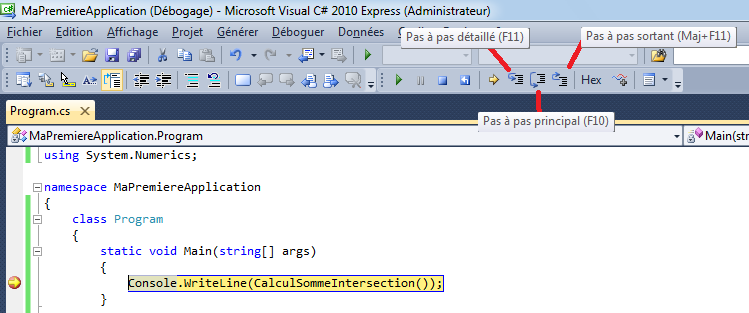
Exécutons notre application en lançant le fichier exécutable depuis l’explorateur de fichiers. Déception, nous voyons à peine un truc noirâtre qui s’affiche et qui se referme immédiatement. Que s’est-il passé ? En fait, l’application s’est lancée, a affiché notre message et s’est terminée immédiatement. Et tout ça un brin trop rapidement … ça ne va pas être pratique tout ça. Heureusement, Visual C# express arrive à la rescousse. Retournons dans notre IDE préféré. Nous allons ajouter un bouton dans la barre d’outils. J’avoue ne pas comprendre pourquoi ce bouton est manquant dans l’installation par défaut. Nous allons remédier à ce problème en cliquant sur la petite flèche qui est à côté de la barre d’outils tout à droite et qui nous ouvre le menu déroulant permettant d’ajouter ou supprimer des boutons et cliquez sur « Personnaliser » :
Cliquez sur « Ajouter une commande » :
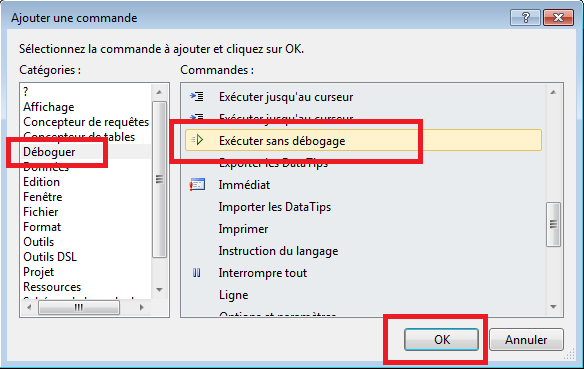
Allez dans la catégorie « déboguer » et choisissez « Exécuter sans débogage » puis cliquez sur « OK » :
Enfin, fermez la fenêtre. Vous avez désormais un nouveau bouton dans la barre d’outils :
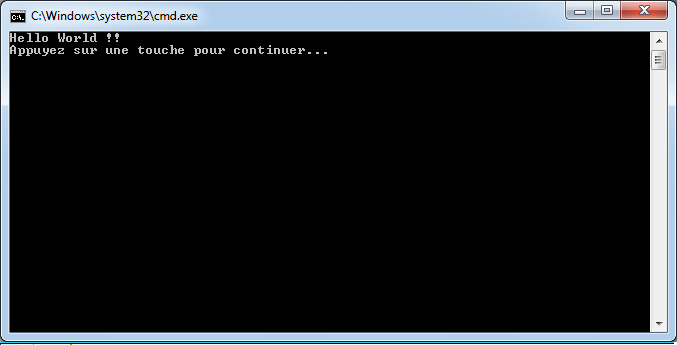
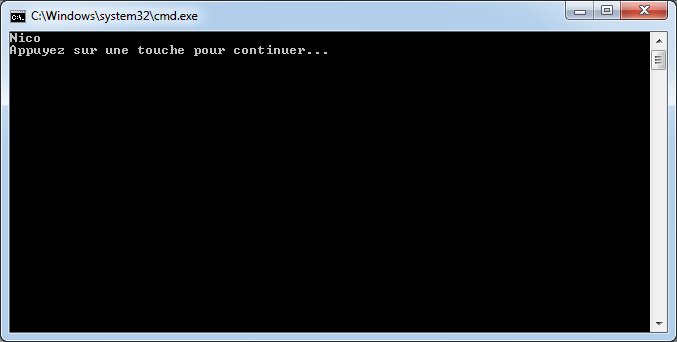
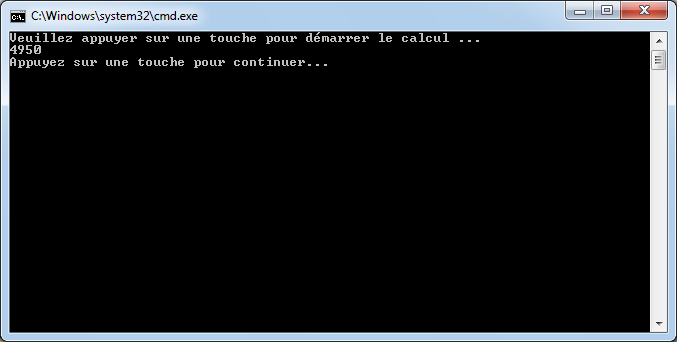
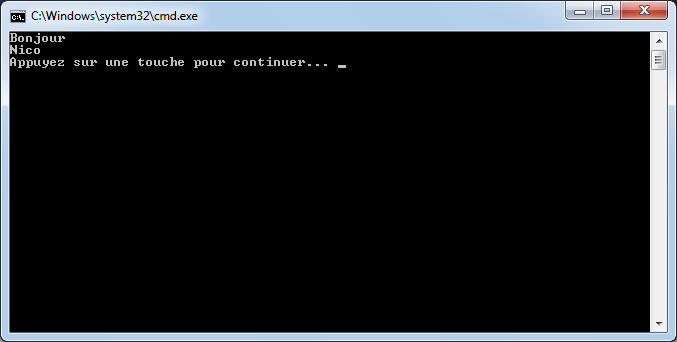
Si vous avez eu la flemme d’ajouter le bouton précédemment, vous pouvez utiliser le raccourci ctrl+F5 ou bien cliquer sur ce nouveau bouton pour exécuter l’application depuis Visual c#. La console s’ouvre nous délivrant le message tant attendu :
Le message est désormais visible car Visual C# nous demande d’appuyer sur une touche pour que l’application se termine, ce qui nous laisse donc le temps d’apprécier l’exécution de notre superbe programme.
Wahouu, ça y est, notre première application en C# !!! :)
Je suis fier de nous, mais nous n’allons pas en rester là, nous sommes désormais fin parés pour apprendre le C#.
En résumé
Visual C# Express est l’outil de développement gratuit de Microsoft permettant de démarrer avec le C#.
Visual Studio est l’outil de développement payant de Microsoft permettant d’être efficace dans le développement d’applications .NET.
Microsoft SQL Server Express est le moteur de base de données utilisable facilement avec Visual C# Express.
L’environnement de développement nous permet de créer du code C# qui sera contenu dans des projets, qui peuvent être réunis dans une solution.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous allons aborder ici la syntaxe générale du langage de programmation C# dans le cadre d’une application console. Il est en effet possible de créer plein de choses différentes avec le C# comme une application web, des jeux, etc.
Dans cette optique, nous allons utiliser très souvent l’instruction : Console.WriteLine("…"); que nous avons vue au chapitre précédent et qui est une instruction dédiée à l’affichage sur la console. C’est une instruction qui va s’avérer très pratique pour notre apprentissage car nous pourrons avoir une représentation visuelle de ce que nous allons apprendre. Il est globalement rare qu’une application ne doive afficher que du texte, sans aucune mise en forme. Vous verrez en fin de tutoriel comment réaliser des applications un peu plus évoluées graphiquement.
Préparez vous, nous plongeons petit à petit dans l'univers du C#. Dans ce chapitre, nous allons nous attaquer à la syntaxe générale du C# et nous serons capable de reconnaître les lignes de code et de quoi elles se composent.
Les lignes de code écrites avec le langage de développement C# doivent s’écrire dans des fichiers dont l’extension est .cs. Nous avons vu dans le chapitre précédent que nous avons écrit dans le fichier Program.cs qui est le fichier qui a été généré par Visual C# lors de la création du projet. Nous y avons notamment rajouté une instruction permettant d’afficher du texte. Les lignes de code C# se lisent et s’écrivent de haut en bas et de gauche à droite, comme un livre normal. Aussi, une instruction écrite avant une autre sera en général exécutée avant celle-ci.
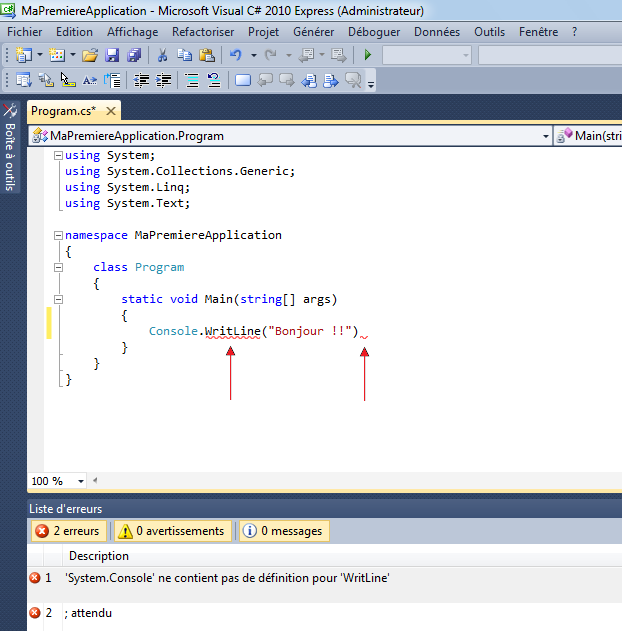
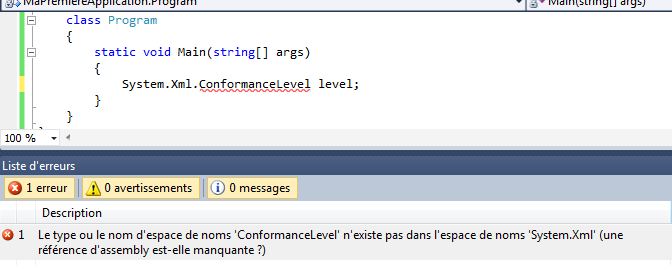
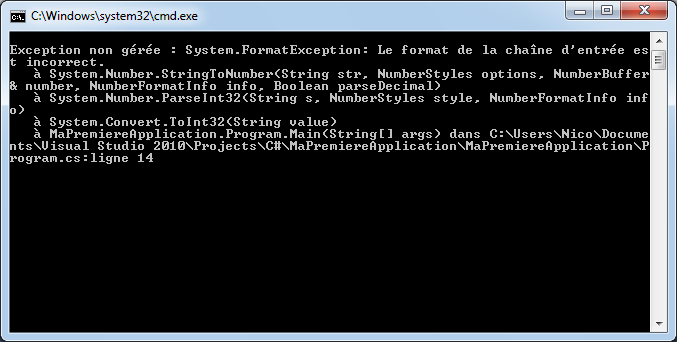
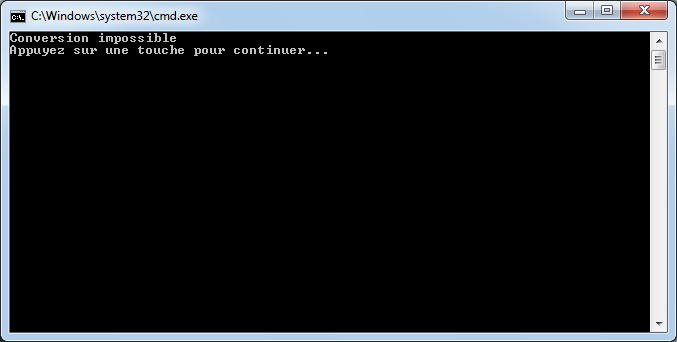
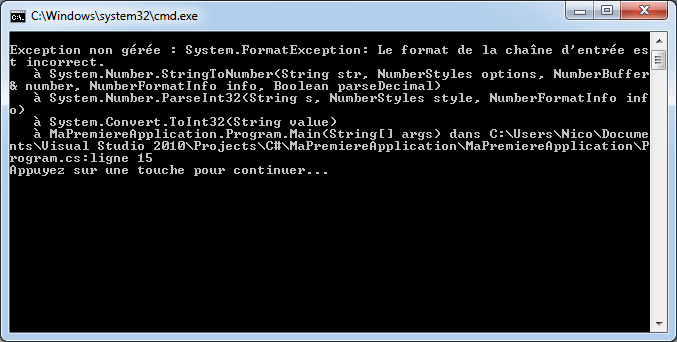
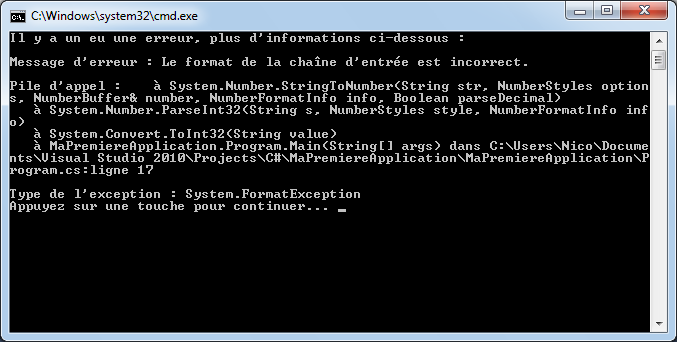
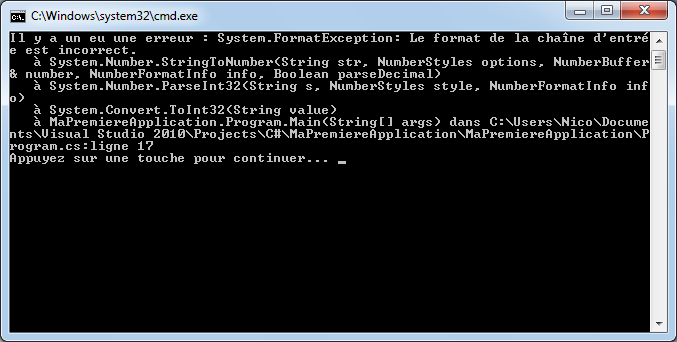
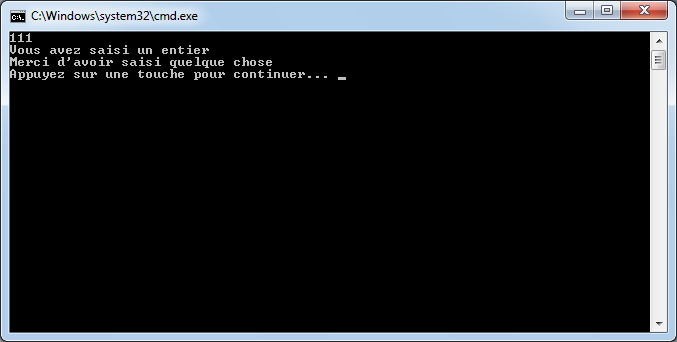
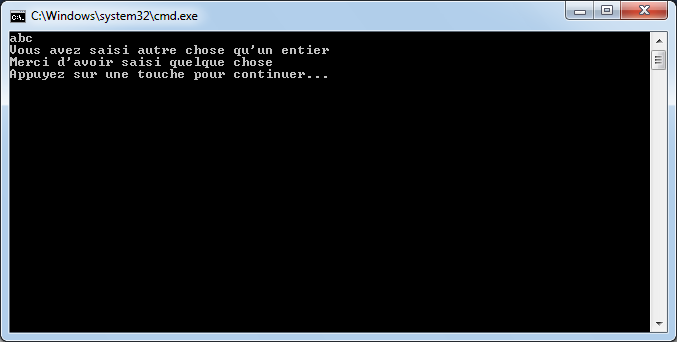
Par exemple, si à la fin de mon instruction, je retire le point-virgule ou si j’orthographie mal le mot WriteLine, j’aurai :
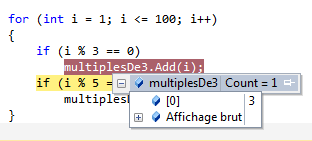
Visual C# Express me signale qu’il y a un problème en mettant en valeur un manque au niveau de la fin de l’instruction et il me souligne également le mot « WritLine ». Dans la fenêtre du bas, il m’indique qu’il a deux erreurs et me donne des précisions sur celles-ci avec éventuellement des pistes pour résoudre ces erreurs.
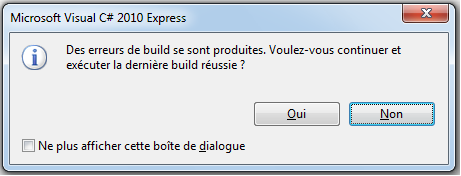
Si je tente de lancer mon application (raccourci ctrl+F5), Visual C# Express va tenter de compiler et d’exécuter l’application. Ceci n’étant pas possible, il m’affichera un message indiquant qu’il y a des erreurs.
Ce sont des erreurs de compilation qu’il va falloir résoudre si l’on souhaite que l’application console puisse s’exécuter.
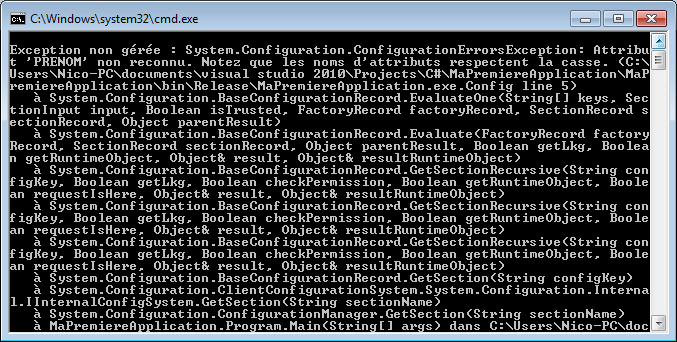
Nous allons voir dans les chapitres suivant comment écrire correctement des instructions en C#. Mais il est important de noter à l’heure actuelle que le C# est sensible à la casse, ce qui veut dire que les majuscules comptent ! Ainsi le mot « WriteLine » et le mot « WriTEline » sont deux mots bien distincts et peuvent potentiellement représenter deux instructions différentes. Ici, le deuxième mot est incorrect car il n’existe pas.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
En général, une instruction en code C# s’écrit sur une ligne et se termine par un point-virgule. Ainsi, l’instruction que nous avons vue plus haut :
Console.WriteLine("Hello World !!");
se termine au niveau du point-virgule. Il aurait été possible de remplacer le code écrit :
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World !!");
}
}
par :
class Program {static void Main(string[] args) {Console.WriteLine("Hello World !!");}}
ou encore :
class Program
{
static void Main(string[] args)
{
Console
.WriteLine("Hello World !!"
);
}
}
En général, pour que le code soit le plus lisible possible, on écrit une instruction par ligne et on indente le code de façon à ce que les blocs soient lisibles.
Visual C# express nous aide pour faire correctement cette indentation quand nous écrivons du code. Il peut également remettre toute la page en forme avec la combinaison de touche : ctrl+k+ctrl+d.
Décortiquons à présent cette ligne de code :
Console.WriteLine("Hello World !!");
Pour simplifier, nous dirons que nous appelons la méthode WriteLine qui permet d’écrire une chaine de caractères sur la Console.
L’instruction "Hello World !!" représente une chaine de caractères et est passée en paramètre de la méthode Console.WriteLine à l’aide des parenthèses. La chaine de caractères est délimitée par les guillemets. Enfin, le point-virgule permet d’indiquer que l’instruction est terminée et qu’on peut enchainer sur la suivante.
Certains points ne sont peut-être pas encore tout à fait clairs, comme ce qu’est vraiment une méthode, ou comment utiliser des chaines de caractères, mais ne vous inquiétez pas, nous allons y revenir plus en détail dans les chapitres suivants et découvrir au fur et à mesure les arcanes du C#.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour faciliter la compréhension du code ou pour se rappeler un point précis, il est possible de mettre des commentaires dans son code. Les commentaires sont ignorés par le compilateur et n’ont qu’une valeur informative pour le développeur. Dans un fichier de code C# (.cs), on peut écrire des commentaires de 2 façons différentes :
Soit en commençant son commentaire par /* et en le terminant par */ ce qui permet d’écrire un commentaire sur plusieurs lignes.
Soit en utilisant // et tout ce qui se trouve après sur la même ligne est alors un commentaire.
Visual C# express colore les commentaires en vert pour faciliter leurs identifications.
/* permet d'afficher du texte
sur la console */
Console.WriteLine("Hello World !!"); // ne pas oublier le point virgule
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
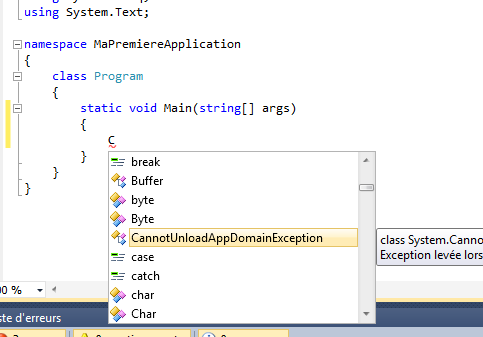
Visual C# express est un formidable outil qui nous facilite à tout moment la tâche, notamment grâce à la complétion automatique. La complétion automatique est le fait de proposer de compléter automatiquement ce que nous sommes en train d’écrire en se basant sur ce que nous avons le droit de faire. Par exemple, si vous avez cherché à écrire l’instruction :
Console.WriteLine("Hello World !!");
vous avez pu constater que lors de l’appui sur la touche C, Visual C# express nous affiche une fenêtre avec tout ce qui commence par « C » :
Au fur et à mesure de la saisie, il affine les propositions pour se positionner sur la plus pertinente. Il est possible de valider la proposition en appuyant sur la touche Entrée. Non seulement cela nous économise des appuis de touches, paresseux comme nous sommes, mais cela nous permet également de vérifier la syntaxe de ce que nous écrivons et d’obtenir également une mini-aide sur ce que nous essayons d’utiliser.
Ainsi, finies les fautes de frappe qui résultent en une erreur de compilation ou les listes de mots clés dont il faut absolument retenir l’écriture.
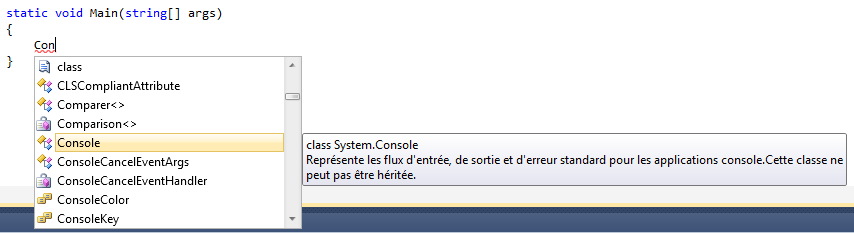
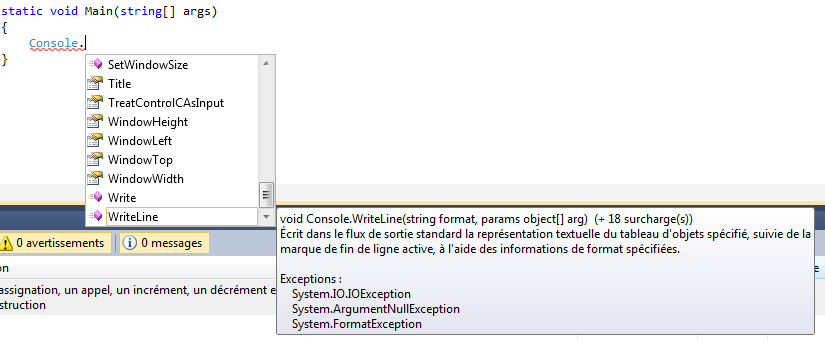
De la même façon, une fois que vous avez fini de saisir « Console » vous allez saisir le point « . » et Visual C# express va nous proposer toute une série d’instruction en rapport avec le début de l’instruction :
Nous pourrons ainsi facilement finir de saisir « WriteLine » et ceci sans erreur d’écriture, ni problème de majuscule.
En résumé
Le code C# est composé d’une suite d’instructions qui se terminent par un point virgule.
La syntaxe d’un code C# doit être correcte sinon nous aurons des erreurs de compilation.
Il est possible de commenter son code grâce aux caractères « // », « /* » et « */ ».
Visual C# Express dispose d’un outil puissant qui permet d’aider à compléter ses instructions : la complétion automatique.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre nous allons apprendre ce que sont les variables et comment ces éléments indispensables vont nous rendre bien des services pour traiter de l'information susceptible de changer dans nos programmes informatiques. Nous continuerons en découvrant les différents types de variables et nous ferons nos premières manipulations avec elles.
Soyez attentifs à ce chapitre, il est vraiment fondamental de bien comprendre à quoi servent les variables lors du développement d'une application informatique.
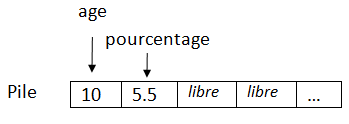
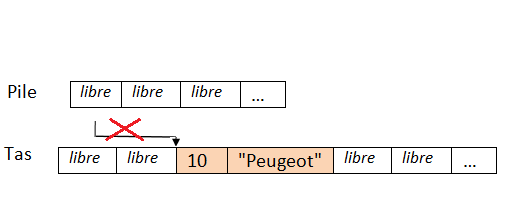
Comme tous les langages de programmations, le C# va pouvoir conserver des données grâce à des variables. Ce sont en fait des blocs de mémoire qui vont contenir des nombres, des chaines de caractères, des dates ou plein d’autres choses. Les variables vont nous permettre d’effectuer des calculs mathématiques, d’enregistrer l’âge du visiteur, de comparer des valeurs, etc. On peut les comparer à des petits classeurs possédant une étiquette. On va pouvoir mettre des choses dans ces classeurs, par exemple, je mets 30 dans le classeur étiqueté « âge de Nicolas » et 20 dans le classeur « âge de Jérémie ». Si je veux connaitre l’âge de Nicolas, je n’ai qu’à regarder dans ce classeur pour obtenir 30. Je peux également remplacer ce qu’il y a dans mon classeur par autre chose, par exemple changer 30 en 25. Je ne peux par contre pas mettre deux choses dans mon classeur, il n’a qu’un seul emplacement.
Une variable est représentée par son nom, caractérisée par son type et contient une valeur.
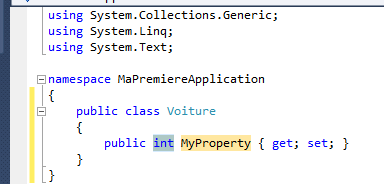
Par exemple, l’âge d’une personne pourrait être stockée sous la forme d’un entier et accessible par la variable « age », ce qui s’écrit en C# :
int age;
On appelle ceci « la déclaration de la variable age ».
Le mot clé int permet d’indiquer au compilateur que la variable « age » est un entier numérique. int correspond au début d’ « integer » qui veut dire « entier » en anglais.
Ici, la variable « age » n’a pas été initialisée, elle ne pourra pas être utilisée car le compilateur ne sait pas quelle valeur il y a dans la variable age.
Pour l’initialiser (on parle également « d’affecter une valeur ») on utilisera l’opérateur égal (« = »).
int age;
age = 30;
Notre variable « age » possède désormais l’entier numérique « 30 » comme valeur.
L’initialisation d’une variable peut également se faire au même moment que sa déclaration. Ainsi, on pourra remplacer le code précédent par :
int age = 30;
Pour déclarer une variable en C#, on commence toujours par indiquer son type (int, ici un entier) et son nom (age). Il faudra impérativement affecter une valeur à cette variable avec l’opérateur « = », soit sur la même instruction que la déclaration, soit un peu plus loin dans le code, mais dans tous les cas, avant l’utilisation de cette variable.
Nous pouvons à tout moment demander la valeur contenue dans la variable age, par exemple :
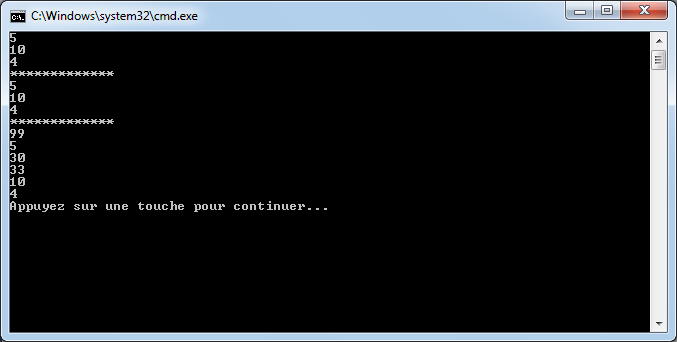
int age = 30;
Console.WriteLine(age); // affiche 30
Il est possible de modifier la valeur de la variable à n’importe quel moment grâce à l’emploi de l’opérateur = que nous avons aperçu :
int age = 30;
Console.WriteLine(age); // affiche 30
age = 20;
Console.WriteLine(age); // affiche 20
Vous pouvez nommer vos variables à peu près n’importe comment, à quelques détails près. Les noms de variables ne peuvent pas avoir le même nom qu’un type. Il sera alors impossible d’appeler une variable int. Il est également impossible d’utiliser des caractères spéciaux, comme des espaces ou des caractères de ponctuation. De même, on ne pourra pas nommer une variable en commençant par des chiffres.
En général, une variable commence par une minuscule et si son nom représente plusieurs mots, on démarrera un nouveau mot par une majuscule. Par exemple :
int ageDuVisiteur;
C’est ce qu’on appelle le camel case.
Attention, suivant le principe de sensibilité à la casse, il faut faire attention car ageduvisiteur et ageDuVisiteur seront deux variables différentes :
int ageduvisiteur = 30;
int ageDuVisiteur = 20;
Console.WriteLine(ageduvisiteur); // affiche 30
Console.WriteLine(ageDuVisiteur); // affiche 20
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu juste au-dessus que la variable « age » pouvait être un entier numérique grâce au mot clé int. Le framework .NET dispose de beaucoup de types permettant de représenter beaucoup de choses différentes.
Par exemple, nous pouvons stocker une chaine de caractères grâce au type string.
string prenom = "nicolas";
ou encore un décimal avec :
decimal soldeCompteBancaire = 100;
ou encore un boolean (qui représente une valeur vraie ou fausse) avec
bool estVrai = true;
On ne peut par exemple pas stocker le prénom "Nicolas" dans un entier.
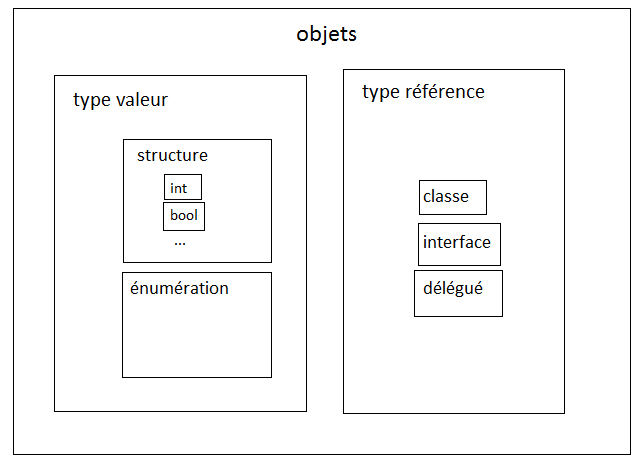
Les principaux types de base du framework .NET sont :
Type
Description
byte
Entier de 0 à 255
short
Entier de -32768 à 32767
int
Entier de -2147483648 à 2147483647
long
Entier de -9223372036854775808 à 9223372036854775807
float
Nombre simple précision de -3,402823e38 à 3,402823e38
double
Nombre double précision de -1,79769313486232e308 à 1,79769313486232e308
decimal
Nombre décimal convenant particulièrement aux calculs financiers (en raison de ses nombres significatifs après la virgule)
char
Représente un caractère
string
Une chaine de caractère
bool
Une valeur booléenne (vrai ou faux)
Vous verrez plus loin qu'il existe encore d'autres types dans le framework .NET et qu'on peut également construire les siens.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est possible d’effectuer des opérations sur les variables et entre les variables. Nous avons déjà vu comment affecter une valeur à une variable grâce à l’opérateur =.
int age = 30;
string prenom = "nicolas";
En plus de la simple affectation, nous pouvons également faire des opérations, par exemple :
int resultat = 2 * 3;
ou encore
int age1 = 20;
int age2 = 30;
int moyenne = (age1 + age2) / 2;
Les opérateurs « + », « * », « / » ou encore « - » (que nous n’avons pas encore utilisé) servent bien évidemment à faire les opérations mathématiques qui leur correspondent, à savoir respectivement l’addition, la multiplication, la division et la soustraction. Vous aurez donc surement deviné que la variable « resultat » contient 6 et que la moyenne vaut 25.
Il est à noter que les variables contiennent une valeur qui ne peut évoluer qu’en affectant une nouvelle valeur à cette variable. Ainsi, si j’ai le code suivant :
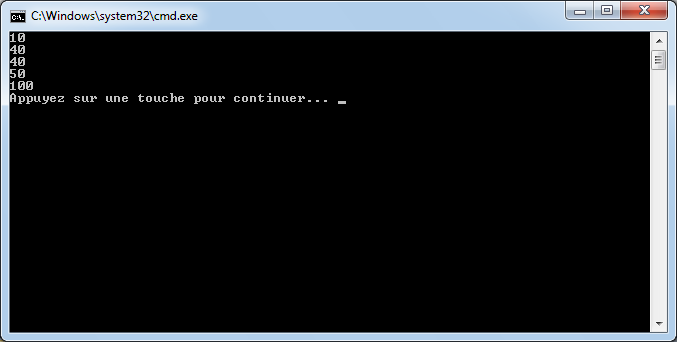
int age1 = 20;
int age2 = 30;
int moyenne = (age1 + age2) / 2;
age2 = 40;
la variable moyenne vaudra toujours 25 même si j’ai changé la valeur de la variable « age2 ». En effet, lors du calcul de la moyenne, j’ai rangé dans mon classeur la valeur 25 grâce à l’opérateur d’affectation « = » et j’ai refermé mon classeur. Le fait de changer la valeur du classeur « age2 » n’influence en rien le classeur « moyenne » dans la mesure où il est fermé. Pour le modifier, il faudrait ré-exécuter l’opération d’affectation de la variable moyenne, en écrivant à nouveau l’instruction de calcul, c’est-à-dire :
int age1 = 20;
int age2 = 30;
int moyenne = (age1 + age2) / 2;
age2 = 40;
moyenne = (age1 + age2) / 2;
L’opérateur « + » peut également servir à concaténer des chaines de caractères, par exemple :
D’autres opérateurs particuliers existent que nous ne trouvons pas dans les cours de mathématiques. Par exemple, l’opérateur ++ qui permet de réaliser une incrémentation de 1, ou l’opérateur -- qui permet de faire une décrémentation de 1. De même, les opérateurs que nous avons déjà vus peuvent se cumuler à l’opérateur = pour simplifier une opération qui prend une variable comme opérande et cette même variable comme résultat. Par exemple :
int age = 20;
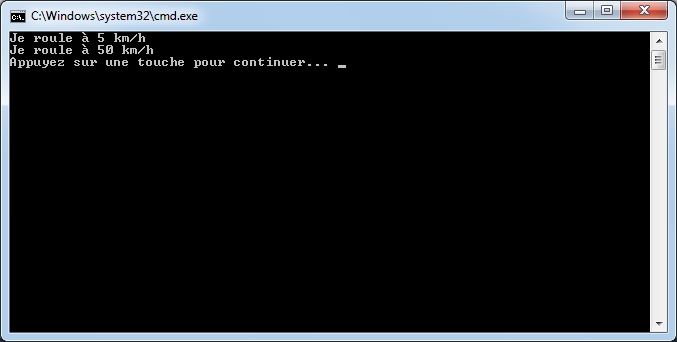
age = age + 10; // age contient 30 (addition)
age++; // age contient 31 (incrémentation de 1)
age--; // age contient 30 (décrémentation de 1)
age += 10; // équivalent à age = age + 10 (age contient 40)
age /= 2; // équivalent à age = age / 2 => (age contient 20)
Comme nous avons pu le voir dans nos cours de mathématiques, il est possible de grouper des opérations avec des parenthèses pour agir sur leurs priorités.
Ainsi, l’instruction précédemment vue :
int moyenne = (age1 + age2) / 2;
effectue bien la somme des deux âges avant de les diviser par 2, car les parenthèses sont prioritaires.
Cependant, l’instruction suivante :
int moyenne = age1 + age2 / 2;
aurait commencé par diviser l’age2 par 2 et aurait ajouté l’age1, ce qui n’aurait plus rien à voir avec une moyenne. En effet, la division est prioritaire par rapport à l’addition.
Prenons cet exemple :
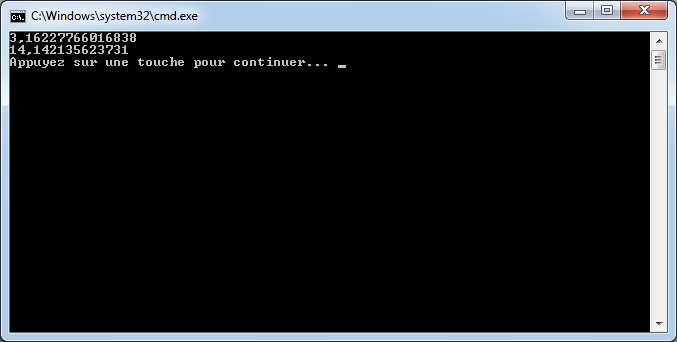
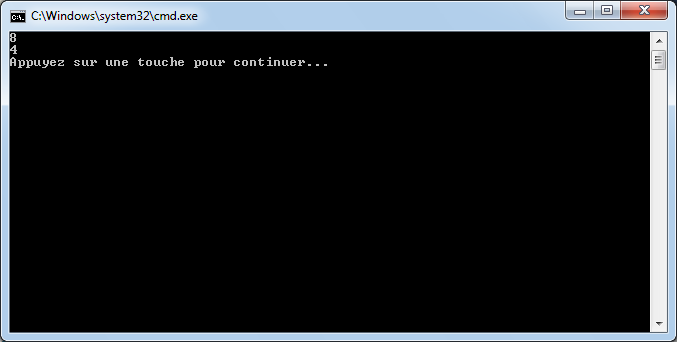
int moyenne = 5 / 2;
Console.WriteLine(moyenne);
Si nous l'exécutons, nous voyons que moyenne vaut 2.
2 ? Si je me rappelle bien de mes cours de math ... c'est pas plutôt 2.5 ?
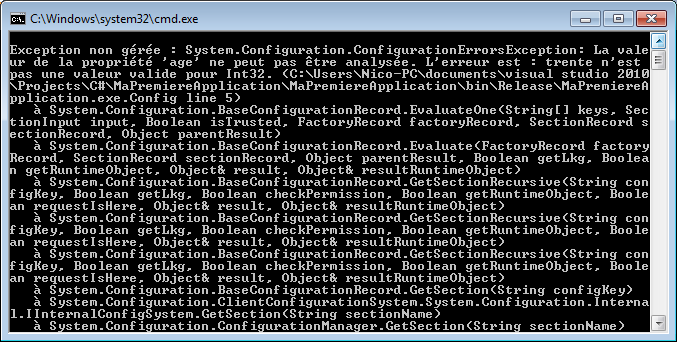
Oui et non. Si nous divisions 5 par 2, nous obtenons bien 2.5. Par contre, ici nous divisons l'entier 5 par l'entier 2 et nous stockons le résultat dans l'entier moyenne. Le C# réalise en fait une division entière, c'est-à-dire qu'il prend la partie entière de 2.5, c'est-à-dire 2.
De plus, l'entier moyenne est incapable de stocker une valeur contenant des chiffres après la virgule. Il ne prendrait que la partie entière.
Pour avoir 2.5, il faudrait utiliser le code suivant :
Ici, nous divisons deux « doubles » entre eux et nous stockons le résultat dans un « double ». (Rappelez-vous, le type de données « double » permet de stocker des nombres à virgule.)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
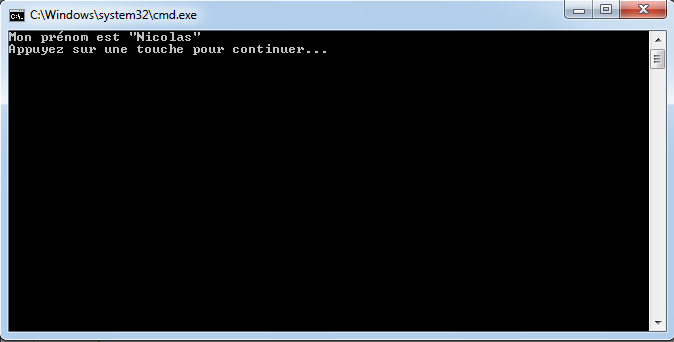
En ce qui concerne l’affectation de chaines de caractères, vous risquez d’avoir des surprises si vous tentez de mettre des caractères spéciaux dans des variables de type string. En effet, une chaine de caractères étant délimitée par des guillemets " ", comment faire pour que notre chaine de caractères puisse contenir des guillemets ?
C’est là qu’intervient le caractère spécial \ qui sera à mettre juste devant le guillemet, par exemple le code suivant :
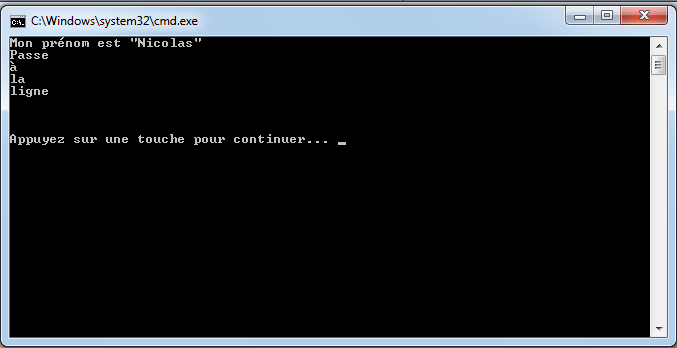
string phrase = "Mon prénom est \"Nicolas\"";
Console.WriteLine(phrase);
affichera :
Si vous avez testé par vous-même l’instruction Console.WriteLine et enchainé plusieurs instructions qui écrivent des lignes, vous avez pu remarquer que nous passions à la ligne à chaque fois. C’est le rôle de l’instruction WriteLine qui affiche la chaine de caractères et passe à la ligne à la fin de la chaîne de caractères.
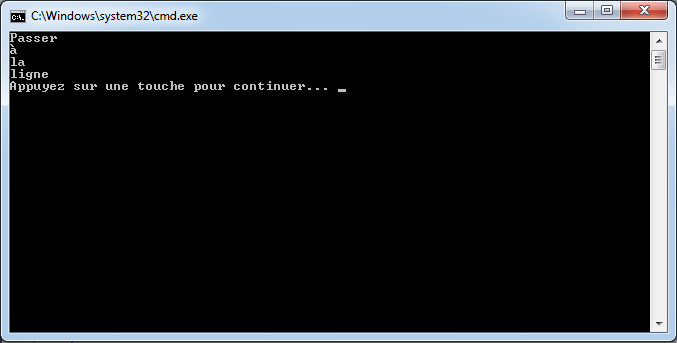
Nous pouvons faire la même chose en utilisant le caractère spécial « ». Il permet de passer à la ligne à chaque fois qu’il est rencontré. Ainsi, le code suivant :
string phrase = "Mon prénom est \"Nicolas\"";
Console.WriteLine(phrase);
Console.WriteLine("Passe\nà\nla\nligne\n\n\n");
affichera :
où nous remarquons bien les divers passages à la ligne. Vous me diriez qu’on pourrait enchaîner les Console.WriteLine et vous auriez raison.
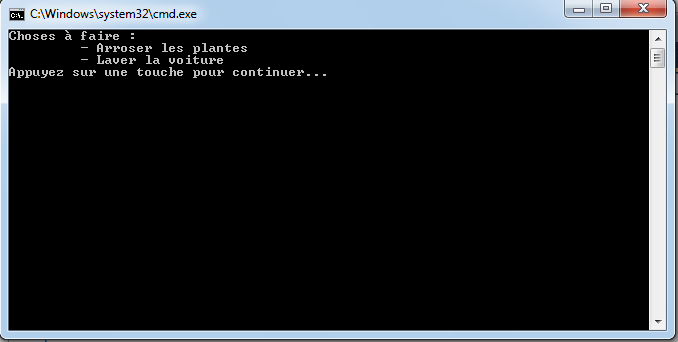
Mais les caractères spéciaux nous permettent de faire d’autres choses comme une tabulation par exemple grâce au caractère spécial « ». Le code suivant :
Console.WriteLine("Choses à faire :");
Console.WriteLine("\t - Arroser les plantes");
Console.WriteLine("\t - Laver la voiture");
permettra d’afficher des tabulations, comme illustré ci-dessous :
Nous avons vu que le caractère \ était un caractère spécial et qu’il permettait de dire au compilateur que nous voulions l’utiliser combiné à la valeur qui le suit, permettant d’ avoir une tabulation ou un retour à la ligne. Comment pourrons-nous avoir une chaine de caractères qui contienne ce fameux caractère ?
Le principe est le même, il suffira de faire suivre ce fameux caractère spécial de lui-même :
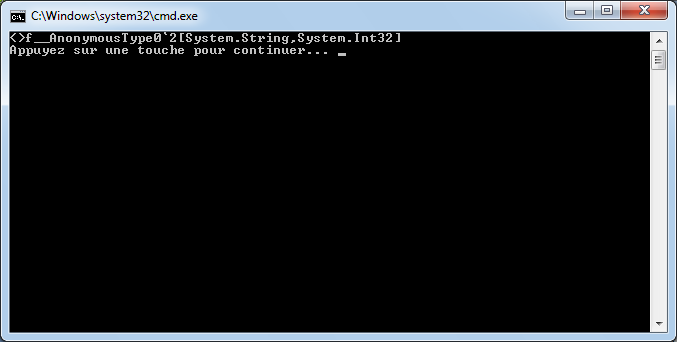
Environment.NewLine ? Une espèce de variable ? Qu’est-ce que c’est que cette chose là ?
En fait, je triche un peu sur les mots. Pour faciliter la compréhension, on peut considérer que Environment.NewLine est une variable, au même titre que la variable « sautDeLigne » que nous avons défini. En réalité, c’est un peu plus complexe qu’une variable. Nous découvrirons plus loin de quoi il s’agit vraiment.
En résumé
Une variable est une zone mémoire permettant de stocker une valeur d'un type particulier.
Le C# possède plein de types prédéfinis, comme les entiers (int), les chaînes de caractères (string), etc.
On utilise l'opérateur = pour affecter une valeur à une variable.
Il est possible de faire des opérations entre les variables.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans nos programmes C#, nous allons régulièrement avoir besoin de faire des opérations en fonction d'un résultat précédent. Par exemple, lors d'un processus de connexion à une application, si le login et le mot de passe sont bons, alors nous pouvons nous connecter, sinon nous afficherons une erreur.
Il s'agit de ce que l'on appelle une condition. Elle est évaluée lors de l'exécution et en fonction de son résultat (vrai ou faux) nous ferons telle ou telle chose.
Bien que relativement court, ce chapitre est très important. N'hésitez pas à le relire et à vous entraîner.
L’instruction if permet d’exécuter du code si une condition est vraie (if = si en anglais). Par exemple :
decimal compteEnBanque = 300;
if (compteEnBanque >= 0)
Console.WriteLine("Votre compte est créditeur");
Ici, nous avons une variable contenant le solde de notre compte en banque. Si notre solde est supérieur ou égal à 0 alors nous affichons que le compte est créditeur.
Pour afficher que le compte est débiteur, on pourrait tester si la valeur de la variable est inférieure à 0 et afficher que le compte est débiteur :
decimal compteEnBanque = 300;
if (compteEnBanque >= 0)
Console.WriteLine("Votre compte est créditeur");
if (compteEnBanque < 0)
Console.WriteLine("Votre compte est débiteur");
Une autre solution est d’utiliser le mot clé else, qui veut dire « sinon » en anglais.
« Si la valeur est vraie, alors on fait quelque chose, sinon, on fait autre chose », ce qui se traduit en C# par :
decimal compteEnBanque = 300;
if (compteEnBanque >= 0)
Console.WriteLine("Votre compte est créditeur");
else
Console.WriteLine("Votre compte est débiteur");
Il faut bien se rendre compte que l’instruction if teste si une valeur est vraie (dans l’exemple précédent la comparaison compteEnBanque >= 0).
On a vu rapidement dans les chapitres précédents qu’il existait un type de variable qui permettait de stocker une valeur vraie ou fausse : le type bool, autrement appelé booléen (boolean en anglais). Ainsi, il sera également possible de tester la valeur d’un booléen. L’exemple précédent peut aussi s’écrire :
decimal compteEnBanque = 300;
bool estCrediteur = (compteEnBanque >= 0);
if (estCrediteur)
Console.WriteLine("Votre compte est créditeur");
else
Console.WriteLine("Votre compte est débiteur");
À noter que les parenthèses autour de l’instruction de comparaison sont facultatives, je les ai écrites ici pour clairement identifier que la variable « estCrediteur » va contenir une valeur qui est le résultat de l’opération de comparaison « compte en banque est supérieur ou égal à 0 », en l’occurrence vrai.
Voici d’autres exemples pour vous permettre d’appréhender plus précisément le fonctionnement du type bool :
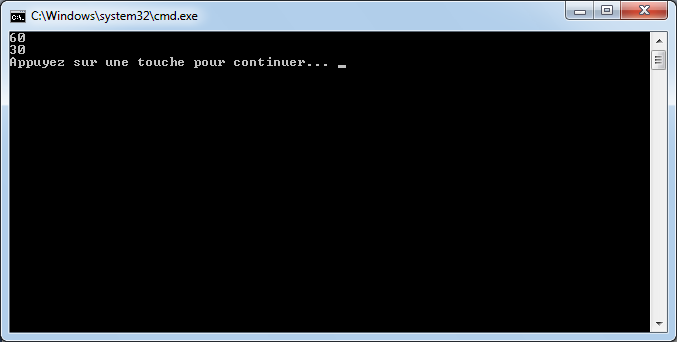
int age = 30;
bool estAgeDe30Ans = age == 30;
Console.WriteLine(estAgeDe30Ans); // affiche True
bool estSuperieurA10 = age > 10;
Console.WriteLine(estSuperieurA10); // affiche True
bool estDifferentDe30 = age != 30;
Console.WriteLine(estDifferentDe30); // affiche False
Un type bool peut prendre deux valeurs, vrai ou faux, qui s’écrivent avec les mots clés true et false.
Il est également possible de combiner les tests grâce aux opérateurs de logique conditionnelle, par exemple && qui correspond à l’opérateur ET.
Dans l’exemple qui suit, nous affichons le message de bienvenue uniquement si le login est « Nicolas » ET que le mot de passe est « test ». Si l’un des deux ne correspond pas, nous irons dans l’instruction else.
D’autres opérateurs de logiques existent, nous avons notamment l’opérateur || qui correspond au OU logique :
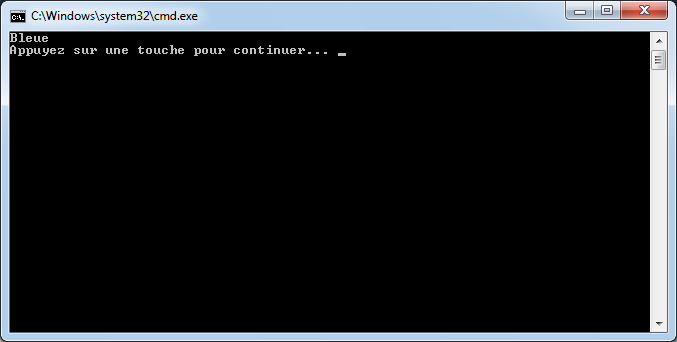
if (civilite == "Mme" || civilite == "Mlle")
Console.WriteLine("Vous êtes une femme");
else
Console.WriteLine("Vous êtes un homme");
L’exemple parle de lui-même ; si la civilité de la personne est Mme ou Mlle, alors nous avons à faire avec une femme.
A noter ici que si la première condition du if est vraie alors la deuxième ne sera pas évaluée. C’est un détail ici, mais cela peut s’avérer important dans certaines situations dont une que nous verrons un peu plus loin.
Un autre opérateur très courant est la négation que l’on utilise avec l’opérateur « ! ». Par exemple :
Ce test pourrait se lire ainsi : « Si la négation de la variable estVrai est vraie, alors on écrira c’est faux ». La variable « estVrai » étant égale à true, sa négation vaut false. Dans cet exemple, le programme nous affichera donc l’instruction correspondant au else, à savoir « C’est vrai ! ».
Rappelez-vous, nous avons dit qu’une instruction se finissait en général par un point-virgule. Comment cela se fait-il alors qu’il n’y ait pas de point-virgule à la fin du if ou du else ? Et si nous écrivions l’exemple précédent de cette façon ?
Ceci est tout à fait valable et permet de voir où s’arrête vraiment l’instruction grâce au point-virgule. Cependant, nous écrivons en général ces instructions de la première façon afin que celles-ci soient plus lisibles. Vous aurez l’occasion de rencontrer dans les chapitres suivants d’autres instructions qui ne se terminent pas obligatoirement par un point-virgule.
Remarquons enfin qu'il est possible d’enchaîner les tests de manière à traiter plusieurs conditions en utilisant la combinaison else-if. Cela donne :
if (civilite == "Mme")
Console.WriteLine("Vous êtes une femme");
else if (civilite == "Mlle")
Console.WriteLine("Vous êtes une femme non mariée");
else if (civilite == "M.")
Console.WriteLine("Vous êtes un homme");
else
Console.WriteLine("Je n'ai pas pu déterminer votre civilité");
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
L’instruction switch peut être utilisée lorsqu’une variable peut prendre beaucoup de valeurs. Elle permet de simplifier l’écriture. Ainsi, l’instruction suivante :
string civilite = "M.";
if (civilite == "M.")
Console.WriteLine("Bonjour monsieur");
if (civilite == "Mme")
Console.WriteLine("Bonjour madame");
if (civilite == "Mlle")
Console.WriteLine("Bonjour mademoiselle");
pourra s’écrire :
string civilite = "M.";
switch (civilite)
{
case "M." :
Console.WriteLine("Bonjour monsieur");
break;
case "Mme":
Console.WriteLine("Bonjour madame");
break;
case "Mlle":
Console.WriteLine("Bonjour mademoiselle");
break;
}
Switch commence par évaluer la variable qui lui est passée entre parenthèses. Avec le mot clé case on énumère les différents cas possible pour la variable et on exécute les instructions correspondante jusqu’au mot clé break qui signifie que l’on sort du switch.
Nous pouvons également indiquer une valeur par défaut en utilisant le mot clé default, ainsi dans l’exemple suivant tout ce qui n’est pas « M. » ou « Mme » ou « Mlle » donnera l’affichage d’un « Bonjour inconnu » :
switch (civilite)
{
case "M." :
Console.WriteLine("Bonjour monsieur");
break;
case "Mme":
Console.WriteLine("Bonjour madame");
break;
case "Mlle":
Console.WriteLine("Bonjour mademoiselle");
break;
default:
Console.WriteLine("Bonjour inconnu");
break;
}
Nous pouvons également enchainer plusieurs cas pour qu’ils fassent la même chose, ce qui reproduit le fonctionnement de l’opérateur logique OU (« || »). Par exemple, on pourra remplacer l’exemple suivant :
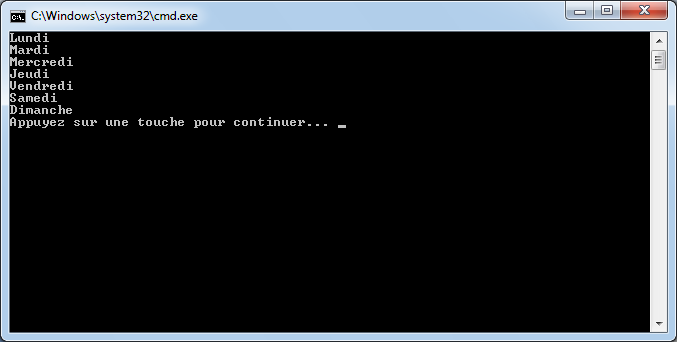
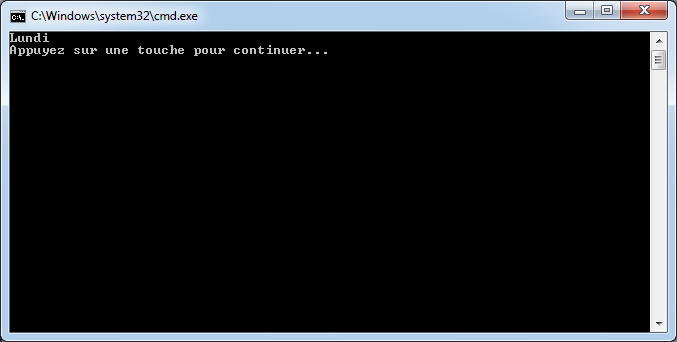
string mois = "Janvier";
if (mois == "Mars" || mois == "Avril" || mois == "Mai")
Console.WriteLine("C'est le printemps");
if (mois == "Juin" || mois == "Juillet" || mois == "Aout")
Console.WriteLine("C'est l'été");
if (mois == "Septembre" || mois == "Octobre" || mois == "Novembre")
Console.WriteLine("C'est l'automne");
if (mois == "Decembre" || mois == "Janvier" || mois == "Février")
Console.WriteLine("C'est l'hiver");
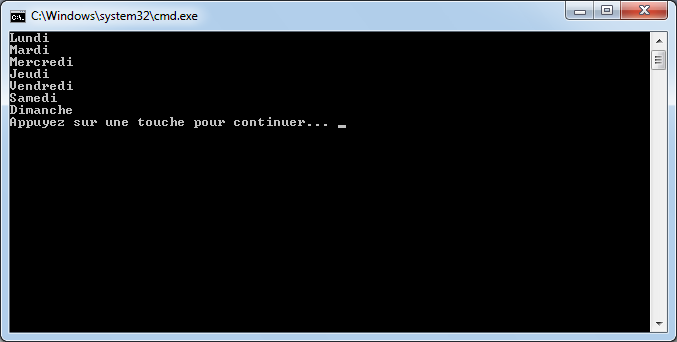
par :
switch (mois)
{
case "Mars":
case "Avril":
case "Mai":
Console.WriteLine("C'est le printemps");
break;
case "Juin":
case "Juillet":
case "Aout":
Console.WriteLine("C'est l'été");
break;
case "Septembre":
case "Octobre":
case "Novembre":
Console.WriteLine("C'est l'automne");
break;
case "Décembre":
case "Janvier":
case "Février":
Console.WriteLine("C'est l'hiver");
break;
}
Qui allège quand même l’écriture et la rend beaucoup plus lisible.
En résumé
Les instructions conditionnelles permettent d'exécuter des instructions seulement si une condition est vérifiée.
On utilise en général le résultat d'une comparaison dans une instruction conditionnelle.
Le C# possède beaucoup d'opérateurs de comparaison, comme l'opérateur d'égalité ==, l'opérateur de supériorité >, d'infériorité <, etc.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons régulièrement utilisé dans le chapitre précédent les accolades ouvrantes et fermantes : \{ et \}. Nous avons rapidement dit que ces accolades servaient à créer des blocs de code.
L'utilisation d'accolades implique également une autre subtilité. Vous l'avez vu dans le titre du chapitre, il s'agit de la portée d'une variable.
Les blocs de code permettent de grouper plusieurs instructions qui vont s’exécuter dans le même contexte. Cela peut être le cas par exemple après un if, nous pourrions souhaiter effectuer plusieurs instructions. Par exemple :
decimal compteEnBanque = 300;
if (compteEnBanque >= 0)
{
Console.WriteLine("Votre compte est créditeur");
Console.WriteLine("Voici comment ouvrir un livret …");
}
else
{
Console.WriteLine("Votre compte est débiteur");
Console.WriteLine("N’oubliez pas que les frais de découverts sont de …");
}
Ici, nous enchaînons deux Console.WriteLine en fonction du résultat de la comparaison de compteEnBanque avec 0.
Les blocs de code seront utiles dès qu’on voudra regrouper plusieurs instructions. C’est le cas pour les instructions conditionnelles mais nous verrons beaucoup d’autres utilisations, comme le switch que nous avons vu juste au-dessus, les boucles ou les méthodes que nous allons aborder dans le chapitre suivant.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
C# … portée … on se croirait au cours de musique …
En fait, la « portée d’une variable » est la zone de code dans laquelle une variable est utilisable. Elle correspond en général au bloc de code dans lequel est définie la variable.
Ainsi, le code suivant :
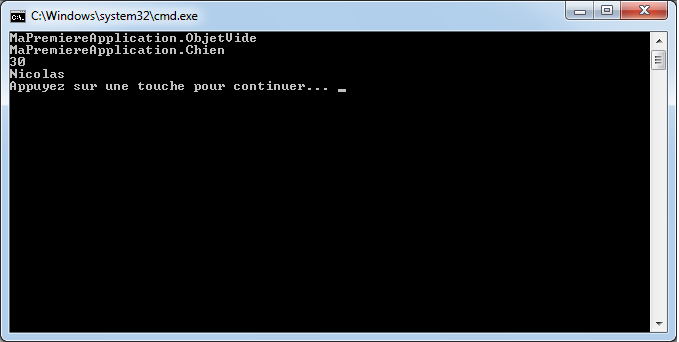
static void Main(string[] args)
{
string prenom = "Nicolas";
string civilite = "M.";
if (prenom == "Nicolas")
{
int age = 30;
Console.WriteLine("Votre age est : " + age);
switch (civilite)
{
case "M.":
Console.WriteLine("Vous êtes un homme de " + age + " ans");
break;
case "Mme":
Console.WriteLine("Vous êtes une femme de " + age + " ans");
break;
}
}
if (age >= 18)
{
Console.WriteLine(prenom + ", vous êtes majeur");
}
}
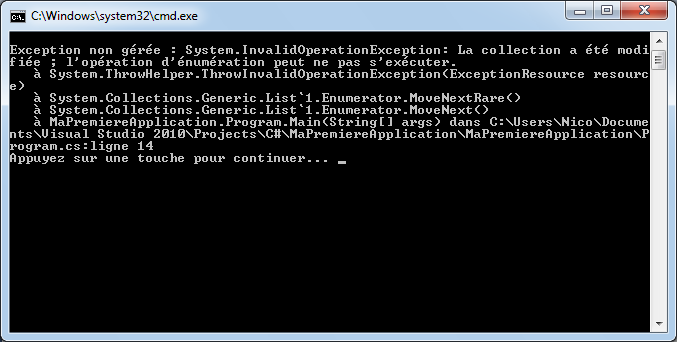
est incorrect et provoquera une erreur de compilation. En effet, nous essayons d’accéder à la variable « age » en dehors du bloc de code où elle est définie. Nous voyons que cette variable est définie dans le bloc qui est exécuté lorsque le test d’égalité du prénom avec la chaine « Nicolas » est vrai alors que nous essayons de la comparer à 18 dans un endroit où elle n’existe plus.
Nous pouvons utiliser « age » sans aucun problème dans tout le premier if, et même dans les sous blocs de code, comme c’est le cas dans le sous bloc du switch, mais pas en dehors du bloc de code dans lequel la variable est définie. Ainsi, la variable « prenom » est accessible dans le dernier if car elle a été définie dans un bloc père.
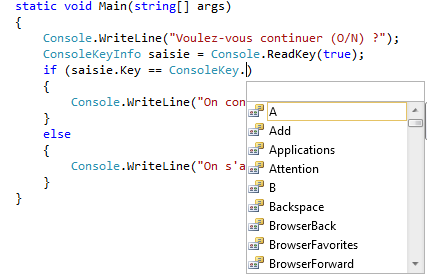
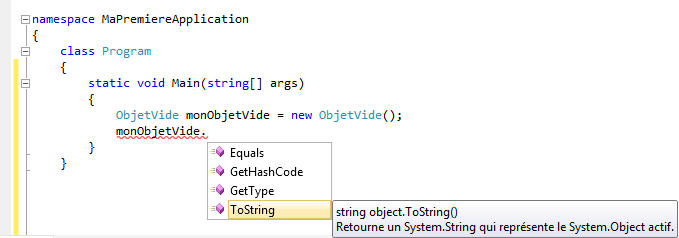
Vous noterez qu’ici, la complétion nous est utile. En effet, Visual C# express propose de nous compléter le nom de la variable dans un bloc où elle est accessible. Dans un bloc où elle ne l’est pas, la complétion automatique ne nous la propose pas. Comme Visual C# express est malin comme une machine, si la complétion ne propose pas ce que vous souhaitez, c’est probablement que vous n’y avez pas le droit. Une des explications peut être que la portée ne vous l’autorise pas.
Pour corriger l’exemple précédent, il faut déclarer la variable « age » au même niveau que la variable prénom.
Ok, mais alors, pourquoi on ne déclarerait pas tout au début une bonne fois pour toute ? Cela éviterait ces erreurs … non ?
Evidemment non, vous verrez qu’il n’est pas possible de faire cela. Généralement, l’utilisation de variables accessibles de partout est une mauvaise pratique de développement (c’est ce qu’on appelle des variables « globales »). Même si on peut avoir un équivalent en C#, il faut se rappeler que plus une variable est utilisée dans la plus petite portée possible, mieux elle sera utilisée et plus elle sera pertinente. Je vous conseille donc d’essayer de déterminer le bloc de code minimal où l’utilisation de la variable est adaptée.
En résumé
Un bloc de code permet de regrouper des instructions qui commencent par \{ et qui finissent par \}.
Une variable définie à l'intérieur d'un bloc de code aura pour portée ce bloc de code.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Élément indispensable de tout programme informatique, une méthode regroupe un ensemble d'instructions, pouvant prendre des paramètres et pouvant renvoyer une valeur. Lors de vos développements, vous allez avoir besoin de créer beaucoup de méthodes.
Nous allons découvrir les méthodes dans ce chapitre mais nous y reviendrons petit à petit tout au long de ce cours et vous aurez ainsi l'occasion d'approfondir vos connaissances.
Vous pourrez trouver de temps en temps le mot « fonction » à la place du mot « méthode ». Cela signifie la même chose. C'est une relique du passé correspondant à un ancien mode de développement qui s'utilise de moins en moins, de même que le terme « procédure » qui est encore plus vieux !
Le but de la méthode est de factoriser du code afin d’éviter d’avoir à répéter sans arrêt le même code et ceci pour deux raisons essentielles :
Déjà parce que l’homme est un être paresseux qui utilise son intelligence pour éviter le travail inutile.
Ensuite parce que si jamais il y a quelque chose à corriger dans ce bout de code et s’il est dupliqué à plusieurs endroits, alors nous allons devoir faire une correction dans tous ces endroits. Si le code est factorisé à un unique endroit, nous ferons une unique correction. (Oui oui, encore la paresse mais aussi cela permet d’éviter d’oublier un bout de code dans un endroit caché).
Ce souci de factorisation est connu comme le principe « DRY » qui est l’acronyme des mots anglais « Don’t Repeat Yourself », ce qui veut bien sûr dire : « Ne vous répétez pas ». Le but de ce principe est de ne jamais (à quelques exceptions près bien sûr …) avoir à réécrire la même ligne de code.
Par exemple, imaginons quelques instructions qui s’occupent d’écrire un message de bienvenue avec le nom de l’utilisateur. Le code C# pourrait être :
Console.WriteLine("Bonjour Nicolas");
Console.WriteLine("-------" + Environment.NewLine);
Console.WriteLine("\tBienvenue dans le monde merveilleux du C#");
Si plus tard, on veut ré-afficher le message de bienvenue, il faudra réécrire ces 4 lignes de codes. Sauf si nous utilisons une méthode :
static void AffichageBienvenue()
{
Console.WriteLine("Bonjour Nicolas");
Console.WriteLine("-------" + Environment.NewLine);
Console.WriteLine("\tBienvenue dans le monde merveilleux du C#");
}
Dans l’exemple précédent, je définis une méthode qui s’appelle AffichageBienvenue.
L’instruction :
static void AffichageBienvenue()
est ce qu’on appelle la signature de la méthode. Elle nous renseigne sur les paramètres de la méthode et sur ce qu’elle va renvoyer. Le mot clé void signifie que la méthode ne renvoie rien. Les parenthèses vides à la fin de la signature indiquent que la méthode n’a pas de paramètres.
Le mot clé static ne nous intéresse pas pour l’instant, mais sachez qu’il sert à indiquer que la méthode est toujours disponible et prête à être utilisée. Dans ce contexte, il est obligatoire. Nous y reviendrons.
En-dessous de la signature de la méthode, nous retrouvons les accolades. Elles permettent de délimiter la méthode. Le bloc de code ainsi formé constitue ce qu’on appelle le « corps de la méthode ».
En résumé, pour déclarer une méthode, nous aurons :
Signature de la méthode
{
Bloc de code de la méthode
}
Nous pouvons désormais appeler (c'est-à-dire : exécuter) cette méthode dans notre programme grâce à son nom. Par exemple, ici je l’appelle très facilement 2 fois de suite :
static void Main(string[] args)
{
AffichageBienvenue();
AffichageBienvenue();
}
static void AffichageBienvenue()
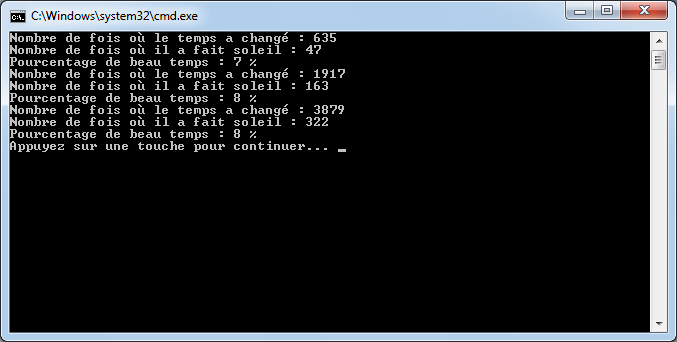
{
Console.WriteLine("Bonjour Nicolas");
Console.WriteLine("-------" + Environment.NewLine);
Console.WriteLine("\tBienvenue dans le monde merveilleux du C#");
}
Et tout ça, sans efforts ! C’est quand même plus simple et plus clair, non ?
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
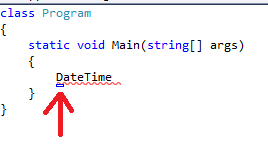
La signature de la méthode que l’on vient de créer ne vous rappelle rien ? Mais si, l’autre bloc au-dessus de notre méthode, qui ressemble lui aussi à une méthode.
Elle a été générée par Visual C# express lorsque nous avons créé le projet Console.
Cette méthode est en fait le point d’entrée de l’application, c’est-à-dire que quand le CLR tente d’exécuter notre application, il recherche cette méthode afin de pouvoir commencer à exécuter des instructions à partir d’elle. S’il ne la trouve pas, alors, il ne pourra pas exécuter notre application. C’est pour cela qu’il est important que cette méthode soit accessible de partout ; rappelez-vous, c’est grâce au mot clé static que nous aurons l’occasion d’étudier plus en détail ultérieurement. Visual C# express nous garde bien de cette erreur. En effet, si vous supprimez cette méthode (ou que vous enlevez le mot clé static) et que vous tentez de compiler notre application, vous aurez le message d’erreur suivant :
Citation : Compilateur
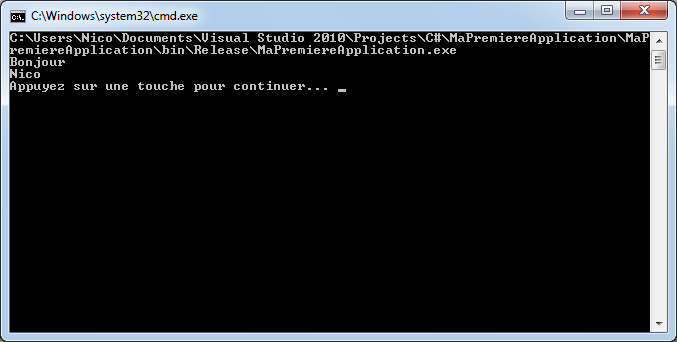
Erreur 1 Le programme 'C:\Users\Nico\Documents\Visual Studio 2010\Projects\C#\MaPremiereApplication\MaPremiereApplication\obj\x86\Release\MaPremiereApplication.exe' ne contient pas une méthode 'Main' statique appropriée pour un point d'entrée
Le message d’erreur est clair. Il a besoin d’une méthode Main() pour démarrer.
Les lecteurs attentifs auront remarqué que cette méthode possède des choses dans la signature, entre les parenthèses … Des paramètres ! Découvrons-les dans le prochain chapitre…
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
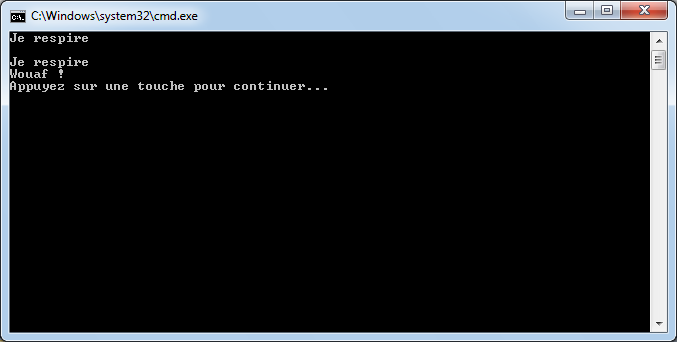
Super, nous savons créer des méthodes. Nous allons pouvoir créer une méthode qui permet de souhaiter la bienvenue à la personne qui vient de se connecter à notre application par exemple. Si c’est Nicolas qui vient de se connecter, nous allons pouvoir appeler la méthode AffichageBienvenueNicolas(). Si c’est Jérémie, nous appellerons la méthode AffichageBienvenueJeremie(), etc …
static void AffichageBienvenueNicolas()
{
Console.WriteLine("Bonjour Nicolas");
Console.WriteLine("-------" + Environment.NewLine);
Console.WriteLine("\tBienvenue dans le monde merveilleux du C#");
}
static void AffichageBienvenueJeremie()
{
Console.WriteLine("Bonjour Jérémie");
Console.WriteLine("-------" + Environment.NewLine);
Console.WriteLine("\tBienvenue dans le monde merveilleux du C#");
}
Bof… finalement, ce n’est pas si super que ça en fait. Alors que nous venions juste d’évoquer le principe DRY, nous nous retrouvons avec deux méthodes quasiment identiques qui ne diffèrent que d’une toute petite chose.
C’est là qu’interviennent les paramètres de méthodes. Nous l’avons évoqué au paragraphe précédent, il est possible de passer des paramètres à une méthode. Ainsi, nous pourrons utiliser les valeurs de ces paramètres dans le corps de nos méthodes, les méthodes en deviendront d’autant plus génériques.
Dans notre exemple d’affichage de message de bienvenue, il est évident que le nom de l’utilisateur sera un paramètre de la méthode.
Les paramètres s’écrivent à l’intérieur des parenthèses qui suivent le nom de la méthode. Nous devons indiquer le type du paramètre ainsi que le nom de la variable qui le représentera au sein de la méthode.
Il est possible de passer plusieurs paramètres à une méthode, on les séparera avec une virgule. Par exemple :
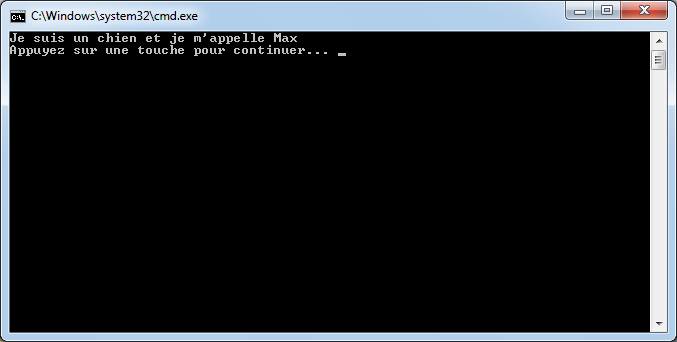
static void DireBonjour(string prenom, int age)
{
Console.WriteLine("Bonjour " + prenom);
Console.WriteLine("Vous avez " + age + " ans");
}
Ici, la méthode DireBonjour prend en paramètres une chaine de caractères prenom et un entier age. La méthode affiche « Bonjour » ainsi que le contenu de la variable prenom. De même, juste en dessous, elle affiche l’âge qui a été passé en paramètres.
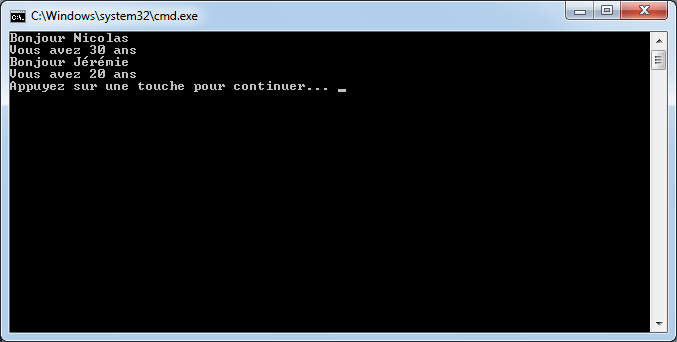
Nous pourrons appeler cette méthode de cette façon, depuis la méthode Main() :
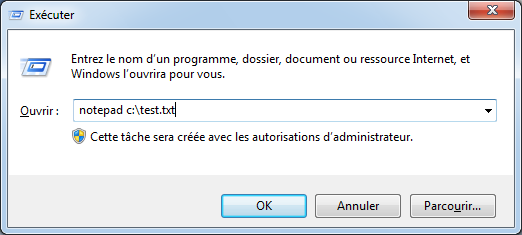
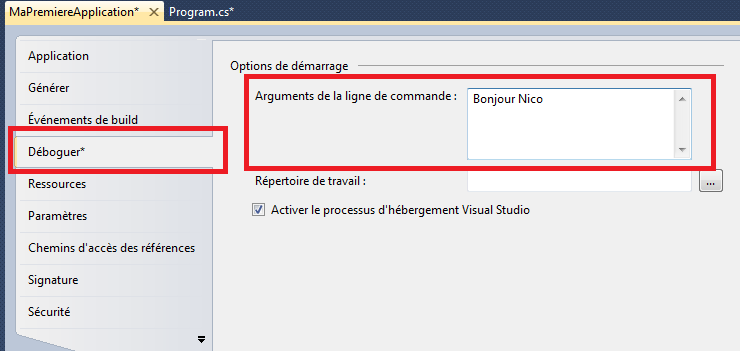
Bien sûr, il est obligatoire de fournir en paramètres d’une méthode une variable du même type que le paramètre. Sinon, le compilateur sera incapable de mettre la donnée qui a été passée dans le paramètre. D’ailleurs, si vous ne fournissez pas le bon paramètre, vous aurez droit à une erreur de compilation.
Par exemple, si vous appelez la méthode avec les paramètres suivants :
DireBonjour(10, 10);
Vous aurez l’erreur de compilation suivante :
Citation : Compilateur
impossible de convertir de 'int' en 'string'
Il est évidemment possible de passer des variables à une méthode, cela fonctionne de la même façon :
Nous allons revenir plus en détail sur ce qu’il se passe exactement ici dans le chapitre sur le mode de passage des paramètres.
Vous voyez, cela ressemble beaucoup à ce que nous avons déjà fait avec la méthode Console.WriteLine(). Facile, non ? :)
La méthode Console.WriteLine fait partie de la bibliothèque du framework .NET et est utilisée pour écrire des chaines de caractères, des nombres ou plein d’autres choses sur la console. Le framework .NET contient énormément de méthodes utilitaires de toutes sortes, nous y reviendrons.
Vous aurez peut-être remarqué un détail, nous avons préfixé toutes nos méthodes du mot clé static. J’ai dit que c’était obligatoire dans notre contexte, pour être plus précis, c’est parce que la méthode Main() est statique que nous sommes obligés de créer des méthodes statiques. On a dit que la méthode Main() était obligatoirement statique parce qu’elle devait être accessible de partout afin que le CLR puisse trouver le point d’entrée de notre programme. Or, une méthode statique ne peut appeler que des méthodes statiques, c’est pour cela que nous sommes obligés (pour l’instant) de préfixer nos méthodes par le mot clé static. Nous décrirons ce que recouvre exactement le mot clé static dans la partie suivante.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une méthode peut aussi renvoyer une valeur, par exemple un calcul. C’est souvent d’ailleurs son utilité première.
On pourrait imaginer par exemple une méthode qui calcule la longueur de l’hypoténuse à partir des 2 côtés d’un triangle. Sachant que a² + b² = c², nous pouvons imaginer une méthode qui prend en paramètres la longueur des 2 cotés, fait la somme de leur carrés et renvoie la racine carré du résultat. C’est ce que fait la méthode suivante :
static double LongueurHypotenuse(double a, double b)
{
double sommeDesCarres = a * a + b * b;
double resultat = Math.Sqrt(sommeDesCarres);
return resultat;
}
Continuons à ignorer le mot clé static. Vous aurez remarqué que la signature de la méthode commence par le mot clé double, qui indique que la méthode va nous renvoyer une valeur du type double. Comme on l’a vu, double a et double b sont deux paramètres de la méthode et sont du type double.
La méthode Math.Sqrt est une méthode du framework .NET, au même titre que la méthode Console.WriteLine, qui permet de renvoyer la racine carrée d’un nombre. Elle prend en paramètre un double et nous retourne une valeur de type double également qui correspond à la racine carrée du paramètre. C’est tout naturellement que nous stockons ce résultat dans une variable grâce à l’opérateur d’affectation « = ».
À la fin de la méthode, le mot clé return indique que la méthode renvoie la valeur à la méthode qui l’a appelée. Ici, nous renvoyons le résultat.
Comme précédemment, nous utilisons une variable pour stocker le résultat de l’exécution de la méthode.
Ce qui produira comme résultat :
À noter qu’il est également possible de se passer d’une variable intermédiaire pour stocker le résultat. Ainsi, nous pourrons par exemple faire :
Console.WriteLine("Le résultat est : " + LongueurHypotenuse(1, 3));
Avec cette écriture le résultat renvoyé par la méthode LongueurHypotenuse est directement concaténé à la chaine "Le résultat est : " et est passé en paramètre à la méthode Console.WriteLine.
Remarquez qu’on a fait l’opération a*a pour mettre « a » au carré. On aurait également pu faire Math.Pow(a, 2) qui permet de faire la même chose, la différence est que Pow permet de mettre à la puissance que l’on souhaite. Ainsi, Math.Pow(a, 3) permet de mettre « a » au cube.
Il faut savoir que le mot clé return peut apparaitre à n’importe quel endroit de la méthode. Il interrompt alors l’exécution de celle-ci et renvoie la valeur passée. Ce mot-clé est obligatoire, sans cela la méthode ne compilera pas.
Il est également primordial que tous les chemins possibles d’une méthode renvoient quelque chose. Les chemins sont déterminés par les instructions conditionnelles que nous avons vues précédemment.
Nous avons vu dans le chapitre précédent qu’il était possible de créer des méthodes qui ne retournent rien. Dans ce cas, on peut utiliser le mot clé return sans valeur qui le suit pour stopper l’exécution de la méthode. Par exemple :
Dans les chapitres précédents, nous avons pu utiliser les types de base du framework .NET, comme int, string, double, etc. Nous allons découvrir ici d'autres types qui vont s'avérer très utiles dans la construction de nos applications informatiques.
Une fois bien maîtrisés, vous ne pourrez plus vous en passer ! :p
Voici le premier nouveau type que nous allons étudier, le type « tableau ». En déclarant une variable de type tableau, nous allons en fait utiliser une variable qui contient une suite de variables du même type. Prenons cet exemple :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
Nous définissons ici un tableau de chaine de caractères qui contient 7 chaines de caractères, à savoir les jours de la semaine. Ne faites pas trop attention à l’opérateur new pour l’instant, nous y reviendrons plus tard ; il permet simplement de créer le tableau. Les crochets « [] » qui suivent le nom du type permettent de signaler au compilateur que nous souhaitons utiliser un tableau de ce type-là, ici le type string.
Un tableau, c’est un peu comme une armoire dans laquelle on range des variables. Chaque variable est posée sur une étagère. Pour accéder à la variable qui est posée sur une étagère, on utilise le nom de l’armoire et on indique l’indice de l’étagère où est stockée la variable, en utilisant des crochets [] :
Console.WriteLine(jours[3]); // affiche Jeudi
Console.WriteLine(jours[0]); // affiche Lundi
Console.WriteLine(jours[10]); // provoque une erreur d'exécution car l'indice n'existe pas
Sans anticiper sur le chapitre sur les boucles, il est possible de parcourir l’ensemble d’un tableau avec l’instruction suivante :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
for (int i = 0; i < jours.Length; i++)
{
Console.WriteLine(jours[i]);
}
Nous y reviendrons plus tard mais pour comprendre, ici nous parcourons les éléments de 0 à taille-1 et nous affichons l’élément du tableau correspondant à l’indice en cours.
Ce qui nous donne :
Revenons à présent sur la déclaration du tableau :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
Cette écriture permet de créer un tableau qui contient 7 éléments et d’affecter une valeur à chaque élément du tableau. Il s’agit en fait ici d’une écriture simplifiée. Cette écriture est équivalente à celle-ci :
qui est beaucoup plus verbeuse, mais d’un autre côté, plus explicite.
La première instruction crée un tableau qui peut contenir 7 éléments. 7 indique la taille du tableau, elle ne peut pas changer. Chaque instruction suivante affecte une valeur à un indice du tableau. Rappelez-vous, un tableau commence à l’indice 0 et va jusqu’à l’indice taille – 1.
Il est possible facilement de faire des opérations sur un tableau, comme un tri. On pourra utiliser la méthode Array.Sort(). Par exemple :
Array.Sort(jours);
Avec cette instruction, le tableau sera classé par ordre alphabétique. Vous aurez l’occasion de voir d’autres méthodes dans des chapitres ultérieurs. Ainsi, le code suivant :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
Array.Sort(jours);
for (int i = 0; i < jours.Length; i++)
{
Console.WriteLine(jours[i]);
}
produira :
Ce qui est très inutile :) .
Le tableau « jours » est ce que l’on appelle un tableau à une dimension. Il est également possible de créer des tableaux à N dimensions, il est cependant assez rare de dépasser 2 dimensions. Cela est utile lorsque l’on manipule des matrices.
Nous n'étudierons pas les tableaux à plus d'une dimension dans ce tutoriel car ils risquent de vraiment peu vous servir dans vos premières applications. Par contre, le type suivant vous servira abondamment.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Un autre type que nous allons utiliser à foison est la liste. Nous allons voir comment ce type fonctionne mais sans en faire une étude exhaustive car elle pourrait être bien longue et ennuyeuse. Regardons cet exemple :
List<int> chiffres = new List<int>(); // création de la liste
chiffres.Add(8); // chiffres contient 8
chiffres.Add(9); // chiffres contient 8, 9
chiffres.Add(4); // chiffres contient 8, 9, 4
chiffres.RemoveAt(1); // chiffres contient 8, 4
foreach (int chiffre in chiffres)
{
Console.WriteLine(chiffre);
}
La première ligne permet de créer la liste. Nous reviendrons sur cette instruction un peu plus bas dans le chapitre. Il s’agit d’une liste d’entiers.
Nous ajoutons des entiers à la liste grâce à la méthode Add(). Nous ajoutons en l’occurrence les entiers 8, 9 et 4.
La méthode RemoveAt() permet de supprimer un élément en utilisant son indice, ici nous supprimons le deuxième entier, c’est-à-dire 9.
Après cette instruction, la liste contient les entiers 8 et 4.
Enfin, nous parcourons les éléments de la liste grâce à l’instruction foreach. Nous y reviendrons en détail lors du chapitre sur les boucles. Pour l’instant, nous avons juste besoin de comprendre que nous affichons tous les éléments de la liste.
Ce qui donne :
Les lecteurs assidus auront remarqués que la construction de la liste est un peu particulière. Passons sur le mot clé new qui permet de créer la liste, nous y reviendrons plus en détail dans un prochain chapitre. Par contre, on observe l’utilisation de chevrons <> pour indiquer le type de la liste. Pour avoir une liste d’entier, il suffit d’indiquer le type int à l’intérieur des chevrons. Ainsi, il ne sera pas possible d’ajouter autre chose qu’un entier dans cette liste. Par exemple, l’instruction suivante provoque une erreur de compilation :
List<int> chiffres = new List<int>(); // création de la liste
chiffres.Add("chaine"); // ne compile pas
Evidemment, on ne peut pas ajouter des choux à une liste de carottes !
De la même façon, si l’on souhaite créer une liste de chaine de caractères, nous pourrons utiliser le type string à l’intérieur des chevrons :
List<string> chaines = new List<string>(); // création de la liste
chaines.Add("chaine"); // compilation OK
chaines.Add(1); // compilation KO, on ne peut pas ajouter un entier dans une liste de chaines de caractères
Les listes possèdent des méthodes bien pratiques qui permettent toutes sortes d’opérations sur la liste. Par exemple, la méthode IndexOf() permet de rechercher un élément dans la liste et de renvoyer son indice.
List<string> jours = new List<string>();
jours.Add("Lundi");
jours.Add("Mardi");
jours.Add("Mercredi");
jours.Add("Jeudi");
jours.Add("Vendredi");
jours.Add("Samedi");
jours.Add("Dimanche");
int indice = jours.IndexOf("Mercredi"); // indice vaut 2
Nous aurons l’occasion de voir d’autres utilisations de méthodes de la liste dans les chapitres suivants.
La liste que nous venons de voir (List<>) est en fait ce que l’on appelle un type générique. Nous n’allons pas rentrer dans le détail de ce qu’est un type générique pour l’instant, mais il faut juste savoir qu’un type générique permet d’être spécialisé par un type concret. Pour notre liste, cette généricité permet d’indiquer de quel type est la liste, une liste d’entiers ou une liste de chaines de caractères, etc …
Ne vous inquiétez pas si tout ceci n’est pas parfaitement clair, nous reviendrons plus en détail sur les génériques dans un chapitre ultérieur. Le but ici est de commencer à se familiariser avec le type List<> que nous utiliserons régulièrement et les exemples que nous verrons permettront d’appréhender les subtilités de ce type.
À noter qu’il existe également une écriture simplifiée des listes. En effet, il est possible de remplacer :
List<string> jours = new List<string>();
jours.Add("Lundi");
jours.Add("Mardi");
jours.Add("Mercredi");
jours.Add("Jeudi");
jours.Add("Vendredi");
jours.Add("Samedi");
jours.Add("Dimanche");
par
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
un peu comme pour les tableaux.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous aurez remarqué que les deux types, tableau et liste, se ressemblent beaucoup. Essayons de voir ce qui les différencie afin de savoir quel type choisir entre les deux.
En fait, une des grosses différences est que le tableau peut être multidimensionnel. C’est un point important mais dans le cadre de vos premières applications, il est relativement rare d’avoir à s’en servir. Ils serviront globalement plus souvent dans le développement de jeux ou lorsque l’on souhaite faire des calculs 3D.
Par contre, le plus important pour nous est que le type tableau est de taille fixe alors que la liste est de taille variable. On peut ajouter sans problèmes un nouvel élément grâce à la méthode Add(). De même, on peut supprimer des éléments avec les méthodes Remove alors qu’avec un tableau, on peut seulement remplacer les valeurs existantes et il n’est pas possible d’augmenter sa capacité.
Globalement, vous verrez que dans vos applications, vous utiliserez plutôt les listes pour par exemple afficher une liste de produits, une liste de clients, etc …
Gardez quand même dans un coin de l’esprit les tableaux, ils pourront vous aider dans des situations précises.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
À noter qu’on ne peut pas définir cette énumération n’importe où, pour l’instant, contentons-nous de la définir en dehors de la méthode Main().
Pour être tout à fait précis, une énumération est un type dont toutes les valeurs définies sont des entiers. La première vaut 0, et chaque valeur suivante prend la valeur précédente augmentée de 1. C'est-à-dire que Lundi vaut 0, Mardi vaut 1, etc …
Il est possible de forcer des valeurs à toutes ou certaines valeurs de l’énumération, les valeurs non forcées prendront la valeur précédente augmentée de 1 :
Mais, à part pour enregistrer une valeur dans une base de données, il est rare de manipuler les énumérations comme des entiers car le but de l’énumération est justement d’avoir une liste exhaustive et fixée de valeurs constantes. Le code s’en trouve plus clair, plus simple et plus lisible.
Le fait de définir une telle énumération revient en fait à enrichir les types que nous avons à notre disposition, comme les entiers ou les chaines de caractères (int ou string). Ce nouveau type s’appelle « Jours ».
Nous pourrons définir une variable du type « Jours » de la même façon qu’avec un autre type :
Jours jourDeLaSemaine;
La seule différence c’est que les valeurs qu’il est possible d’affecter à notre variable sont figées et font partie des valeurs définies dans l’énumération.
Pour pouvoir accéder à un élément de l’énumération, il faudra utiliser le nom de l’énumération suivi de l’opérateur point « . » suivi encore de la valeur de l’énumération choisie. Par exemple :
Jours lundi = Jours.Lundi;
Console.WriteLine(lundi);
soit dans notre programme :
class Program
{
enum Jours
{
Lundi,
Mardi,
Mercredi,
Jeudi,
Vendredi,
Samedi,
Dimanche
}
static void Main(string[] args)
{
Jours lundi = Jours.Lundi;
Console.WriteLine(lundi);
}
}
Ce qui nous donne :
Nous pourrons également nous servir des énumérations pour faire des tests de comparaisons, comme par exemple :
Comme on l'a déjà évoqué, le framework .NET est une énorme boîte à outils qui contient beaucoup de méthodes permettant de construire toutes sortes d'applications. Nous allons avoir besoin régulièrement d'utiliser les éléments du framework .NET pour réaliser nos applications. Il est donc grand temps d'apprendre à savoir le manipuler !
Nous allons sans arrêt solliciter la puissance du framework .NET. Par exemple, nous pouvons lui demander de nous donner la date courante.
Pour ce faire, on utilisera l’instruction :
Console.WriteLine(DateTime.Now);
Ce qu’il se passe ici, c’est que nous demandons à notre application l’affichage de la propriété Now de l’objet DateTime. Nous allons revenir en détail sur ce que sont des propriétés et des objets, considérez pour l’instant qu’ils correspondent simplement à une instruction qui nous fournit la date du moment.
Ce qui donne :
En fait, pour accéder à la date courante, on devrait normalement écrire :
System.Console.WriteLine(System.DateTime.Now);
Car les objets DateTime et Console se situent dans l’espace de nom « System ».
Un espace de nom (en anglais namespace) correspond à un endroit où l’on range des méthodes et des objets. Il est caractérisé par des mots séparés par des points (.).
C’est un peu comme des répertoires, nous pouvons dire que le fichier « DateTime » est rangé dans le répertoire « System » et quand nous souhaitons y accéder nous devons fournir l’emplacement complet du fichier, à savoir System.DateTime.
Cependant, plutôt que d’écrire le chemin complet à chaque fois, il est possible de dire : « ok, maintenant, à chaque fois que je vais avoir besoin d’accéder à une fonctionnalité, va la chercher dans l’espace de nom « System ». Si elle s’y trouve, utilise la ».
C’est ce qu’il se passe grâce à l’instruction
using System;
qui a été générée par Visual C# express au début du fichier.
Elle indique au compilateur que nous allons « utiliser » (using) le namespace System dans notre page. Ainsi, il n’est plus obligatoire de préfixer l’accès à DateTime par « System. ». C’est une espèce de raccourci. Pour conserver l’analogie avec les répertoires et les fichiers, on peut dire que nous avons ajouté le répertoire « System » dans le path.
Pour résumer, l’instruction :
System.Console.WriteLine(System.DateTime.Now);
est équivalente aux deux instructions :
using System;
et
Console.WriteLine(DateTime.Now);
Sachant qu’elles ne s’écrivent pas côte à côte. En général, on met l’instruction using en entête du fichier .cs, comme ce qu’a fait Visual C# express lorsqu’il a généré le fichier. L’autre instruction étant à positionner à l’endroit adéquat où nous souhaitons qu’elle soit exécutée.
À noter que dans ce cas-là, si Visual C# express reconnait l’instruction mais que l’espace de nom n’est pas inclus, il le propose en soulignant le début du mot « DateTime » d’un petit trait bleu et blanc.
Un clic droit sur le mot permettra d’ouvrir un menu déroulant, de choisir « Résoudre » et d’importer le using correspondant automatiquement.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous aurez l’occasion de découvrir que le framework .NET fourmille d’espace de noms contenant plein de méthodes de toutes sortes permettant de faire un peu tout et n’importe quoi. Une vraie caverne d’ali-baba.
Parmi les nombreuses fonctionnalités du framework .NET, nous avons une méthode qui nous permet de récupérer l’utilisateur courant (au sens « utilisateur windows »), on pourra par exemple utiliser l’instruction suivante :
Ou, comme vous le savez désormais, on pourra utiliser conjointement :
using System;
et
Console.WriteLine(Environment.UserName);
Pour produire le même résultat.
Petit à petit vous allez retenir beaucoup d’instructions et d’espaces de nom du framework .NET mais il est inimaginable de tout retenir. Il existe une documentation répertoriant tout ce qui compose le framework .NET, c’est ce qu’on appelle la MSDN library. Elle est accessible à cette adresse : http://msdn.microsoft.com/fr-fr/library/.
Nous avons désigné la caverne d’ali-baba par le mot « framework .NET ». Pour être plus précis, la désignation exacte de cette caverne est : « la bibliothèque de classe .NET ». Le mot « framework .NET » est en général utilisé par abus de langage (et vous avez remarqué que j’ai moi-même abusé du langage !) et représente également cette bibliothèque de classe. Nous reviendrons plus tard sur ce qu’est exactement une classe, pour l’instant, vous pouvez voir ça comme des composants ; une bibliothèque de composants.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Mais d’ailleurs, comment se fait-il que nous puissions accéder aux méthodes du framework .NET sans nous poser de question ? Il est magique ce framework ? Où se trouve le code qui permet de récupérer la date du jour ?
Judicieuse question. Si on y réfléchit, il doit falloir beaucoup de code pour renvoyer la date du jour ! Déjà, il faut aller la lire dans l’horloge système, il faut peut-être l’adapter au fuseau horaire, la formater d’une façon particulière en fonction de la langue, etc. Tout ça est déjà fait, heureusement, dans la bibliothèque de méthodes du framework .NET.
Alors, où est-elle cette bibliothèque ? Et le reste ?
Dans des assemblys bien sûr. Comme on a vu, les assemblys possèdent des fragments de code compilés en langage intermédiaire. S’ils sont réutilisables, ils se trouvent dans des fichiers dont l’extension est .dll.
Le framework .NET est composé d’une multitude d’assemblys qui sont installés sur votre système d’exploitation, dans le GAC (global assembly cache) qui est un endroit où sont stockées ces assemblys afin de les rendre accessible depuis nos programmes. Pour pouvoir utiliser ces assemblys dans notre programme, nous devons indiquer que nous voulons les utiliser. Pour ça, il faut les référencer dans le projet. Si l’on déplie les références dans notre explorateur de solutions, nous pouvons voir que nous avons déjà pas mal de références qui ont été ajoutées par Visual C# express :
Ce sont des assemblys qui sont très souvent utilisées, c’est pour ça que Visual C# express nous les a automatiquement référencées. Toujours ce souci de nous simplifier le travail, qu’il est sympa !
Prenons par exemple la référence System.Xml. Son nom nous suggère que dedans est réuni tout ce qu’il nous faut pour manipuler le XML. Commençons à taper System.Xml., la complétion automatique nous propose plusieurs choses.
On ne sait pas du tout à quoi elle sert, mais déclarons par exemple une variable de l’énumération ConformanceLevel :
System.Xml.ConformanceLevel level;
et compilons. Pas d’erreur de compilation. Si vous supprimez la référence à System.Xml. (bouton droit, Supprimer),
et que vous compilez à nouveau, vous pouvez voir que ConformanceLevel est désormais souligné en rouge, signe qu’il y a un problème.
Par ailleurs, la compilation provoque l’erreur suivante :
Citation : Compilateur
Le type ou le nom d'espace de noms 'ConformanceLevel' n'existe pas dans l'espace de noms 'System.Xml' (une référence d'assembly est-elle manquante ?)
Loin d’être bête, Visual C# express nous affiche un message d’erreur plutôt explicite.
En effet, cette énumération est introuvable car elle est définie dans une assembly qui n’est pas référencée. C’est comme si on nous demandait de prendre le marteau pour enfoncer un clou, mais que le marteau n’est pas à coté de nous, mais au garage bien rangé ! Il faut donc référencer le marteau afin de pouvoir l’utiliser. Pour ce faire, faisons un clic sur Références et ajoutons une référence.
Ici, nous avons plusieurs onglets (selon la version de Visual Studio que vous possédez, vous aurez peut-être une présentation légèrement différente).
Chaque onglet permet d’ajouter une référence à une assemblys.
L’onglet .NET permet de référencer une assembly présente dans le GAC, c’est ici que nous viendrons chercher les assemblys du framework .NET
L’onglet COM permet de référencer une dll COM. Vous ne savez pas ce qu’est COM ? On peut dire que c’est l’ancêtre de l’assembly. Techniquement, on ne référence pas directement une dll COM, mais Visual C# express génère ce qu’on appelle un wrapper permettant d’utiliser la dll COM. Un wrapper est en fait une espèce de traducteur permettant d’utiliser la dll COM comme si c’était une assembly. Mais ne nous attardons pas sur ce point qui ne va pas nous servir, nous qui sommes débutants.
L’onglet Projets permet de référencer des assemblys qui se trouvent dans notre solution. Dans la mesure où notre solution ne contient qu’un seul projet, l’onglet sera vide. Nous verrons plus tard comment utiliser cet onglet lorsque nous ajouterons des assemblys à nos solutions.
L’onglet Parcourir va permettre de référencer une assembly depuis un emplacement sur le disque dur. Cela peut-être une assembly tierce fournie par un collègue, ou par un revendeur, etc …
Enfin, l’onglet Récent, comme son nom le suggère, permet de référencer des assemblys récemment référencées.
Retournons à nos moutons, repartons sur l’onglet .NET et recherchons l’assembly que nous avons supprimée, à savoir System.Xml.
Une fois trouvée, appuyez sur OK. Maintenant que la référence est ajoutée, nous pouvons à nouveau utiliser cette énumération…
Ouf ! :-°
Je ne comprends pas, j’ai supprimé toutes les références, mais j’arrive quand même à utiliser la date, le nom de l’utilisateur ou la méthode Console.WriteLine. Si j’ai bien compris, je ne devrais pas pouvoir utiliser des méthodes dont les assemblys ne sont pas référencées… C’est normal ?
Eh oui, il existe une assembly qui n’apparait pas dans les références et qui contient tout le cœur du framework .NET. Cette assembly doit obligatoirement être référencée, il s’agit de mscorlib.dll. Comme elle est obligatoire, elle est référencée par défaut dès que l’on crée un projet.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il arrivera souvent que vous ayez besoin d’une fonctionnalité trouvée dans la documentation ou sur internet et qu’il faille ajouter une référence. Ce sera peut-être une référence au framework .NET, à des bibliothèques tierces ou à vous. Nous verrons plus loin comment créer nos propres bibliothèques.
Dans la documentation MSDN, il est toujours indiqué quelle assembly il faut référencer pour utiliser une fonctionnalité. Prenons par exemple la propriété DateTime.Now, la documentation nous dit :
Citation : MSDN
Espace de noms : System Assembly : mscorlib (dans mscorlib.dll)
Cela veut donc dire qu’on utilise la date du jour en utilisant l’assembly obligatoire mscorlib et la fonctionnalité se trouve dans l’espace de nom « System », comme déjà vu.
Il n’y a donc rien à faire pour pouvoir utiliser DateTime.Now. En imaginant que nous ayons besoin de faire un programme qui utilise des nombres complexes, vous allez surement avoir besoin du type Complex, trouvé dans la documentation.
Pour l’utiliser, comme indiqué, il va falloir référencer l’assembly System.Numerics.dll. Rien de plus simple, répétons la procédure pour référencer une assembly et allons trouver System.Numerics.dll :
Ensuite, nous pourrons utiliser par exemple le code suivant :
permettant d’avoir à éviter de préfixer Complex par System.Numerics. Mais ça, vous aviez trouvé tout seul, n’est-ce pas ? :) Ce qui nous donnera :
En résumé
Le framework .NET est un ensemble d'assemblys qu'il faut référencer dans son projet afin d'avoir accès à leurs fonctionnalités.
On utilise le mot-clé using pour inclure un espace de nom comme raccourci dans son programme, ce qui permet de ne pas avoir à préfixer les types de leurs espaces de noms complets.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Bienvenue dans ce premier TP ! Vous avez pu découvrir dans les chapitres précédents les premières bases du langage C# permettant la construction d'applications. Il est grand temps de mettre en pratique ce que nous avons appris. C'est ici l'occasion pour vous de tester vos connaissances et de valider ce que vous appris en réalisant cet exercice.
Le but est de créer une petite application qui affiche un message différent en fonction du nom de l’utilisateur et du moment de la journée :
Bonjour XXX pour la tranche horaire 9h <-> 18h, les lundi, mardi, mercredi, jeudi et vendredi
Bonsoir XXX pour la tranche horaire 18h <-> 9h, les lundi, mardi, mercredi, jeudi
Bon week-end XXX pour la tranche horaire vendredi 18h <-> lundi 9h
Peut-être cela vous parait simple, dans ce cas, foncez et réalisez cette première application tout seul :) . Sinon, décortiquons un peu l’énoncé de ce TP pour éviter d’être perdu.
Pour réaliser ce premier TP, vous allez avoir besoin de plusieurs choses. Dans un premier temps, il faut afficher le nom de l’utilisateur, c’est une chose que nous avons déjà faite en allant puiser dans les fonctionnalités du framework .NET.
Vous aurez besoin également de récupérer l’heure courante pour la comparer aux tranches horaires souhaitées. Vous avez déjà vu comment récupérer la date courante. Pour pouvoir récupérer l’heure de la date courante, il vous faudra utiliser l’instruction DateTime.Now.Hour qui renvoie un entier représentant l’heure du jour.
Pour comparer l’heure avec des valeurs entières il vous faudra utiliser les opérateurs de comparaisons et les instructions conditionnelles que nous avons vus précédemment.
Pour traiter le cas spécial du jour de la semaine, vous aurez besoin que le framework .NET vous indique quel jour nous sommes. C’est le rôle de l’instruction DateTime.Now.DayOfWeek qui est une énumération indiquant le jour de la semaine. Les différentes valeurs sont consultables à cette adresse.
Pour plus de clarté, nous les reprenons ici :
Valeur
Traduction
Sunday
Dimanche
Monday
Lundi
Tuesday
Mardi
Wednesday
Mercredi
Thursday
Jeudi
Friday
Vendredi
Saturday
Samedi
Il ne restera plus qu’à comparer deux valeurs d’énumération, comme on l’a vu au chapitre sur les énumérations.
Voilà, vous avez tous les outils en main pour réaliser ce premier TP. N’hésitez pas à revenir sur les chapitres précédents si vous avez un doute sur la syntaxe ou sur les instructions à réaliser. On ne peut pas apprendre un langage par cœur du premier coup.
À vous de jouer !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous êtes autorisés à lire cette correction uniquement si vous vous êtes arraché les cheveux sur ce TP ! Je vois qu'il vous en reste, encore un effort ! :lol: Quoique, si vous avez réussi avec brio le TP, vous pourrez également comparer votre travail au mien.
Quoi qu’il en soit, voici la correction que je propose. Bien évidemment, il peut y en avoir plusieurs, mais elle contient les informations nécessaires pour la réalisation de ce TP.
Première chose à faire : créer un projet de type console. J’ai ensuite ajouté le code suivant :
static void Main(string[] args)
{
if (DateTime.Now.DayOfWeek == DayOfWeek.Saturday || DateTime.Now.DayOfWeek == DayOfWeek.Sunday)
{
// nous sommes le week-end
AfficherBonWeekEnd();
}
else
{
// nous sommes en semaine
if (DateTime.Now.DayOfWeek == DayOfWeek.Monday && DateTime.Now.Hour < 9)
{
// nous sommes le lundi matin
AfficherBonWeekEnd();
}
else
{
if (DateTime.Now.Hour >= 9 && DateTime.Now.Hour < 18)
{
// nous sommes dans la journée
AfficherBonjour();
}
else
{
// nous sommes en soirée
if (DateTime.Now.DayOfWeek == DayOfWeek.Friday && DateTime.Now.Hour >= 18)
{
// nous sommes le vendredi soir
AfficherBonWeekEnd();
}
else
{
AfficherBonsoir();
}
}
}
}
}
static void AfficherBonWeekEnd()
{
Console.WriteLine("Bon week-end " + Environment.UserName);
}
static void AfficherBonjour()
{
Console.WriteLine("Bonjour " + Environment.UserName);
}
static void AfficherBonsoir()
{
Console.WriteLine("Bonsoir " + Environment.UserName);
}
Détaillons un peu ce code :
Au chargement du programme (méthode Main) nous faisons les comparaisons adéquates. Dans un premier temps, nous testons le jour de la semaine de la date courante (DateTime.Now.DayOfWeek) et nous la comparons aux valeurs représentant Samedi et Dimanche. Si c’est le cas, alors nous appelons une méthode qui affiche le message « Bon week-end » avec le nom de l’utilisateur courant que nous pouvons récupérer avec Enrivonment.UserName.
Si nous ne sommes pas le week-end, alors nous testons l’heure de la date courante avec DateTime.Now.Hour. Si nous sommes le lundi matin avant 9h, alors nous continuons à afficher « Bon week-end ». Sinon, si nous sommes dans la tranche horaire 9h – 18h alors nous pouvons appeler la méthode qui affiche Bonjour. Si non, il reste juste à vérifier que nous ne sommes pas vendredi soir, qui fait partie du week-end, sinon on peut afficher le message de « Bonsoir ».
Et voilà, un bon exercice pour manipuler les conditions et les énumérations…
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ce TP n’était pas très compliqué, il nous a permis de vérifier que nous avions bien compris le principe des if et que nous sachions appeler des éléments du framework .NET.
Nous aurions pu simplifier l’écriture de l’application en compliquant en peu les tests avec une combinaison de conditions. Par exemple, on pourrait avoir :
if (DateTime.Now.DayOfWeek == DayOfWeek.Saturday ||
DateTime.Now.DayOfWeek == DayOfWeek.Sunday ||
(DateTime.Now.DayOfWeek == DayOfWeek.Monday && DateTime.Now.Hour < 9) ||
(DateTime.Now.DayOfWeek == DayOfWeek.Friday && DateTime.Now.Hour >= 18))
{
// nous sommes le week-end
AfficherBonWeekEnd();
}
else
{
// nous sommes en semaine
if (DateTime.Now.Hour >= 9 && DateTime.Now.Hour < 18)
{
// nous sommes dans la journée
AfficherBonjour();
}
else
{
AfficherBonsoir();
}
}
Le premier test permet de vérifier que nous sommes soit samedi, soit dimanche, soit que nous sommes lundi et que l’heure est inférieure à 9, soit que nous sommes vendredi et que l’heure est supérieure à 18. Nous avons, pour ce faire, combiné les tests avec l’opérateur logique OU : ||. Remarquons que les parenthèses nous permettent d’agir sur l’ordre d’évaluation des conditions. Pour que ce soit le week-end, il faut bien sûr être « vendredi et que l’heure soit supérieure à 18 » ou « lundi et que l’heure soit inférieure à 9 » ou samedi ou dimanche.
On pourrait encore simplifier en évitant de solliciter à chaque fois le framework .NET pour obtenir la date courante. Il suffit de stocker la date courante dans une variable de type DateTime. Ce qui donnerait :
DateTime dateCourante = DateTime.Now;
if (dateCourante.DayOfWeek == DayOfWeek.Saturday ||
dateCourante.DayOfWeek == DayOfWeek.Sunday ||
(dateCourante.DayOfWeek == DayOfWeek.Monday && dateCourante.Hour < 9) ||
(dateCourante.DayOfWeek == DayOfWeek.Friday && dateCourante.Hour >= 18))
{
// nous sommes le week-end
AfficherBonWeekEnd();
}
else
{
// nous sommes en semaine
if (dateCourante.Hour >= 9 && dateCourante.Hour < 18)
{
// nous sommes dans la journée
AfficherBonjour();
}
else
{
AfficherBonsoir();
}
}
On utilise ici le type DateTime comme le type string ou int. Il sert à gérer les dates et l’heure. Il est légèrement différent des types que nous avons vus pour l’instant, nous ne nous attarderons pas dessus. Nous aurons l’occasion de découvrir de quoi il s’agit dans la partie suivante. Cette optimisation n’a rien d’extraordinaire, mais cela nous évite un appel à chaque fois au framework .NET.
Voilà pour ce TP. J’espère que vous aurez réussi avec brio l’exercice. Vous avez pu remarquer que ce TP n'était pas trop difficile. Il a simplement fallu réfléchir à comment imbriquer correctement nos conditions.
N'hésitez pas à pratiquer et à vous entraîner avec d'autres problèmes de votre cru. Si vous avez le moindre problème, vous pouvez relire les chapitres précédents. Vous verrez que nous aurons l'occasion d'énormément utiliser ces instructions conditionnelles dans tous les programmes que nous allons écrire.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous les avons évoquées rapidement un peu plus tôt en parlant des tableaux et des listes. Dans ce chapitre nous allons décrire plus précisément les boucles.
Elles sont souvent utilisées pour parcourir des éléments énumérables, comme le sont les tableaux ou les listes. Elles peuvent également être utilisées pour effectuer la même action tant qu'une condition n'est pas réalisée.
La première instruction que nous avons aperçue est la boucle for. Elle permet de répéter un bout de code tant qu’une condition est vraie. Souvent cette condition est un compteur. Nous pouvons par exemple afficher un message 50 fois avec le code suivant :
int compteur;
for (compteur = 0; compteur < 50; compteur++)
{
Console.WriteLine("Bonjour C#");
}
Ce qui donne :
Nous définissons ici un entier « compteur ». Il est initialisé à 0 en début de boucle (compteur = 0). Après chaque exécution du bloc de code du for, c’est-à-dire à chaque itération, il va afficher « Bonjour C# ». À la fin de chaque itération, la variable compteur est incrémentée (compteur++) et nous recommençons l’opération tant que la condition « compteur < 50 » est vraie.
Bien sûr, la variable compteur est accessible dans la boucle et change de valeur à chaque itération.
int compteur;
for (compteur = 0; compteur < 50; compteur++)
{
Console.WriteLine("Bonjour C# " + compteur);
}
Ce qui donne :
Ce précédent code affichera la valeur de la variable après chaque bonjour, donc de 0 à 49. En effet, quand compteur passe à 50, la condition n’est plus vraie et on passe aux instructions suivantes.
En général, on utilise la boucle for pour parcourir un tableau. Ainsi, nous pourrons utiliser le compteur comme indice pour accéder aux éléments du tableau :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
int indice;
for (indice = 0; indice < 7; indice++)
{
Console.WriteLine(jours[indice]);
}
Dans cette boucle, comme à la première itération indice vaut 0, nous afficherons l’élément du tableau à la position 0, à savoir « Lundi ». À l’itération suivante, indice passe à 1, nous affichons l’élément du tableau à la position 1, à savoir « Mardi », et ainsi de suite.
Ce qui donne :
Attention à ce que l’indice ne dépasse pas la taille du tableau, sinon l’accès à un indice en dehors des limites du tableau provoquera une erreur à l’exécution. Pour éviter ceci, on utilise en général la taille du tableau comme condition de fin :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
int indice;
for (indice = 0; indice < jours.Length; indice++)
{
Console.WriteLine(jours[indice]);
}
Ici jours.Length renvoie la taille du tableau, à savoir 7.
Il est très courant de boucler sur un tableau en passant tous les éléments un par un, mais il est possible de changer les conditions de départ, les conditions de fin, et l’élément qui influe sur la condition de fin.
Ainsi, l’exemple suivant :
int[] chiffres = new int[] { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
for (int i = 9; i > 0; i -= 2)
{
Console.WriteLine(chiffres[i]);
}
Permet de parcourir le tableau de 2 en 2 en commençant par la fin.
Ce qui nous donne :
Vous avez pu voir que dans cet exemple, nous avons défini l’entier i directement dans l’instruction for, c’est une commodité qui nous permet d’avoir la variable i qui n’existe qu’à l’intérieur de la boucle, car sa portée correspond aux accolades qui délimitent le for.
Attention, il est possible de faire un peu tout et n’importe quoi dans ces boucles. Aussi il peut arriver que l’on se retrouve avec des bugs, comme des boucles infinies.
est une boucle infinie. En effet, on modifie la variable indice en la décrémentant. Sauf que la condition de sortie de la boucle est valable pour un indice qui dépasse ou égale la valeur 7, ce qui n’arrivera jamais.
Si on exécute l’application avec ce code, la console va afficher à l’infini le mot « Test » avec son indice. La seule solution pour quitter le programme sera de fermer brutalement l’application.
L’autre solution est d’attendre que le programme se termine...
Mais tu viens de dire que la boucle était infinie ?
Oui c’est vrai, mais en fait, ici on se heurte à un cas limite du C#. C’est à cause de la variable indice. indice est un entier que l’on décrémente. Au début il vaut zéro, puis -1, puis -2, etc … Lorsque la variable indice arrive à la limite inférieure que le type int est capable de gérer, c’est-à-dire -2147483648 alors il y a ce qu’on appelle un dépassement de capacité. Sans rentrer dans les détails, il ne peut pas stocker un entier plus petit et donc il boucle et repart à l’entier le plus grand, c’est-à-dire 2147483647.
Donc pour résumer, l’indice fait :
0
-1
-2
...
-2147483647
-2147483648
+2147483647
Et comme là, il se retrouve supérieur à 7, la boucle se termine.
Donc, techniquement, ce n’est pas une boucle infinie, mais bon, on a attendu tellement longtemps pour atteindre ce cas limite que c’est tout comme.
Et surtout, nous tombons sur un cas imprévu. Ici, ça se termine « plutôt bien », mais ça aurait pu finir en crash de l’application.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Comme il est très courant d’utiliser les boucles pour parcourir un tableau ou une liste, le C# dispose d’un opérateur particulier : foreach que l’on peut traduire par « pour chaque » : pour chaque élément du tableau faire …
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
foreach (string jour in jours)
{
Console.WriteLine(jour);
}
Cette boucle va nous permettre de parcourir tous les éléments du tableau « jours ». À chaque itération, la boucle va créer une chaine de caractères « jour » qui contiendra l’élément courant du tableau. À noter que la variable « jour » aura une portée égale au bloc foreach. Nous pourrons ainsi utiliser cette valeur dans le corps de la boucle et pourquoi pas l’afficher comme dans l’exemple précédent.
Ce qui produira :
L’instruction foreach fonctionne aussi avec les listes, par exemple le code suivant :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
foreach (string jour in jours)
{
Console.WriteLine(jour);
}
nous permettra d’afficher tous les jours de la semaine contenus dans la liste des jours.
Attention, la boucle foreach est une boucle en lecture seule. Cela veut dire qu'il n'est pas possible de modifier l'élément de l'itération en cours.
Par exemple, le code suivant :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
foreach (string jour in jours)
{
jour = "pas de jour !";
}
provoquera l'erreur de compilation suivante :
Citation : Compilateur
Impossible d'assigner à 'jour', car il s'agit d'un 'variable d'itération foreach'
Notez d'ailleurs que l'équipe de traduction de Visual C# express a quelques progrès à faire :D ...
Si nous souhaitons utiliser une boucle pour changer la valeur de notre liste ou de notre tableau, il faudra passer par une boucle for :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
for (int i = 0; i < jours.Count; i++ )
{
jours[i] = "pas de jour !";
}
Il vous arrivera aussi surement un jour (ça arrive à tous les développeurs) de vouloir modifier une liste en elle même lors d'une boucle foreach. C'est-à-dire lui rajouter un élément, le supprimer, etc ... C'est également impossible car à partir du moment où l'on rentre dans la boucle foreach, la liste devient non-modifiable.
Prenons l'exemple ô combien classique de la recherche d'une valeur dans une liste pour la supprimer. Nous serions tenté de faire :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
foreach (string jour in jours)
{
if (jour == "Mercredi")
jours.Remove(jour);
}
ce qui semblerait tout à fait correct et en plus, ne provoque pas d'erreur de compilation.
Sauf que si vous exécutez l'application, vous aurez l'erreur suivante :
qui nous plante notre application. Le programme nous indique que « la collection a été modifiée » et que « l'opération d'énumération peut ne pas s'exécuter ».
Il est donc impossible de faire notre suppression ainsi.
Comment tu ferais toi ?
Et bien, plusieurs solutions existent. Celle qui vient en premier à l'esprit est d'utiliser une boucle for par exemple :
for (int i = 0 ; i < jours.Count ; i++)
{
if (jours[i]== "Mercredi")
jours.Remove(jours[i]);
}
Cette solution est intéressante ici, mais elle peut poser un problème dans d'autres situations. En effet, vu que nous supprimons un élément de la liste, nous allons nous retrouver avec une incohérence entre l'indice en cours et l'élément que nous essayons d'atteindre. En effet, lorsque le jour courant est Mercredi, l'indice i vaut 2. Si l'on supprime cet élément, c'est Jeudi qui va se retrouver en position 2. Et nous allons rater son analyse car la boucle va continuer à l'indice 3, qui sera Vendredi. On peut éviter ce problème en parcourant la boucle à l'envers :
for (int i = jours.Count - 1; i >= 0; i--)
{
if (jours[i] == "Mercredi")
jours.Remove(jours[i]);
}
Nous n'étudierons pas les autres solutions car elles font appels à des notions que nous verrons en détail plus tard.
Après avoir lu ceci, vous pourriez avoir l'impression que la boucle foreach n'est pas souple et difficilement exploitable, autant utiliser autre chose ... Vous verrez à l'utilisation que non, elle est en fait très pratique. Il faut simplement connaître ses limites. Voilà qui est chose faite. ^^
Nous avons vu que l’instruction foreach permettait de boucler sur tous les éléments d’un tableau ou d’une liste. En fait, il est possible de parcourir tous les types qui sont énumérables. Nous verrons plus loin ce qui caractérise un type énumérable, car pour l’instant, c’est un secret ! Chuuut ;) .
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
La boucle while est en général moins utilisée que for ou foreach. C’est la boucle qui va nous permettre de faire quelque chose tant qu’une condition n’est pas vérifiée. Elle ressemble de loin à la boucle for, mais la boucle for se spécialise dans le parcours de tableau tandis que la boucle while est plus générique.
Par exemple :
int i = 0;
while (i < 50)
{
Console.WriteLine("Bonjour C#");
i++;
}
Permet d’écrire « Bonjour C# » 50 fois de suite. Ici, la condition du while est évaluée en début de boucle.
Dans l’exemple suivant :
int i = 0;
do
{
Console.WriteLine("Bonjour C#");
i++;
}
while (i < 50);
La condition de sortie de boucle est évaluée à la fin de la boucle. L’utilisation du mot clé do permet d’indiquer le début de la boucle.
Concrètement cela veut dire que dans le premier exemple, le code à l’intérieur de la boucle peut ne jamais être exécuté, si par exemple l’entier i est initialisé à 50. A contrario, on passera au moins une fois dans le corps de la boucle du second exemple, même si l’entier i est initialisé à 50 car la condition de sortie de boucle est évaluée à la fin.
Les conditions de sorties de boucles ne portent pas forcément sur un compteur ou un indice, n’importe quelle expression peut être évaluée. Par exemple :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
int i = 0;
bool trouve = false;
while (!trouve)
{
string valeur = jours[i];
if (valeur == "Jeudi")
{
trouve = true;
}
else
{
i++;
}
}
Console.WriteLine("Trouvé à l'indice " + i);
Le code précédant va répéter les instructions contenues dans la boucle while tant que le booléen « trouve » sera faux (c'est-à-dire qu’on va s’arrêter dès que le booléen sera vrai). Nous analysons la valeur à l’indice i, si la valeur est celle cherchée, alors nous passons le booléen à vrai et nous pourrons sortir de la boucle. Sinon, nous incrémentons l’indice pour passer au suivant.
Attention encore aux valeurs de sorties de la boucle. Si nous ne trouvons pas la chaine recherchée, alors i continuera à s’incrémenter ; le booléen ne passera jamais à vrai, nous resterons bloqué dans la boucle et nous risquons d’atteindre un indice qui n’existe pas dans le tableau. Il serait plus prudent que la condition porte également sur la taille du tableau, par exemple :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
int i = 0;
bool trouve = false;
while (i < jours.Length && !trouve)
{
string valeur = jours[i];
if (valeur == "Jeudi")
{
trouve = true;
}
else
{
i++;
}
}
if (!trouve)
Console.WriteLine("Valeur non trouvée");
else
Console.WriteLine("Trouvé à l'indice " + i);
Ainsi, si l’indice est supérieur à la taille du tableau, nous sortons de la boucle et nous éliminons le risque de boucle infinie.
Une erreur classique est que la condition ne devienne jamais vraie à cause d’une erreur de programmation. Par exemple, si j’oublie d’incrémenter la variable i, alors à chaque passage de la boucle j’analyserai toujours la première valeur du tableau et je n’atteindrai jamais la taille maximale du tableau, condition qui me permettrait de sortir de la boucle.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est possible de sortir prématurément d’une boucle grâce à l’instruction break. Dès qu’elle est rencontrée, elle sort du bloc de code de la boucle. L’exécution du programme continue alors avec les instructions situées après la boucle. Par exemple :
int i = 0;
while (true)
{
if (i >= 50)
{
break;
}
Console.WriteLine("Bonjour C#");
i++;
}
Le code précédent pourrait potentiellement produire une boucle infinie. En effet, la condition de sortie du while est toujours vraie. Mais l’utilisation du mot clé break nous permettra de sortir de la boucle dès que i atteindra la valeur 50. Certes ici, il suffirait que la condition de sortie porte sur l’évaluation de l’entier i. Mais il peut arriver des cas où il pourra être judicieux d’utiliser un break (surtout lors d'un déménagement !).
C’est le cas pour l’exemple suivant. Imaginons que nous voulions vérifier la présence d’une valeur dans une liste. Pour la trouver, on peut parcourir les éléments de la liste et une fois trouvée, on peut s’arrêter. En effet, il sera inutile de continuer à parcourir le reste des éléments :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
bool trouve = false;
foreach (string jour in jours)
{
if (jour == "Jeudi")
{
trouve = true;
break;
}
}
Nous nous économisons ici d’analyser les 3 derniers éléments de la liste.
Il est également possible de passer à l’itération suivante d’une boucle grâce à l’utilisation du mot-clé continue. Prenons l’exemple suivant :
for (int i = 0; i < 20; i++)
{
if (i % 2 == 0)
{
continue;
}
Console.WriteLine(i);
}
Ici, l’opérateur % est appelé « modulo ». Il permet d’obtenir le reste de la division. L’opération i % 2 renverra donc 0 quand i sera pair. Ainsi, dès qu’un nombre pair est trouvé, nous passons à l’itération suivante grâce au mot clé continue. Ce qui fait que nous n'allons afficher que les nombres impairs.
Ce qui donne :
Bien sûr, il aurait été possible d’inverser la condition du if pour ne faire le Console.WriteLine() que dans le cas où i % 2 != 0. À vous de choisir l’écriture que vous préférez en fonction des cas que vous rencontrerez.
En résumé
On utilise la boucle for pour répéter des instructions tant qu'une condition n'est pas vérifiée, les éléments de la condition changeant à chaque itération.
On utilise en général la boucle for pour parcourir un tableau, avec un indice qui s'incrémente à chaque itération.
La boucle foreach est utilisée pour simplifier le parcours des tableaux ou des listes.
La boucle while permet de répéter des instructions tant qu'une condition n'est pas vérifiée. C'est la boucle la plus souple.
Il faut faire attention aux conditions de sortie d'une boucle afin d'éviter les boucles infinies qui font planter l'application.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ça y est, grâce au chapitre précédent, vous devez avoir une bonne idée de ce que sont les boucles. Par contre, vous ne voyez peut-être pas encore complètement qu'elles vont vous servir tout le temps. C'est un élément qu'il est primordial de maîtriser. Il vous faut donc vous entrainer pour être bien sûr d’avoir tout compris.
C’est justement l’objectif de ce deuxième TP. Finie la théorie des boucles, place à la pratique en boucle ! Notre but est de réaliser des calculs qui vont avoir besoin des for et des foreach.
La première va servir à calculer la sommes d'entiers consécutifs. Si par exemple je veux calculer la somme des entiers de 1 à 10, c'est à dire 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10, je vais appeler cette méthode en lui passant en paramètres 1 et 10, c'est-à-dire les bornes des entiers dont il faut faire la somme.
Sachant que le premier résultat de cet exemple vaut 55 (1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 = 55) et le deuxième 5050.
La deuxième méthode acceptera une liste de double en paramètres et devra renvoyer la moyenne des doubles de la liste. Par exemple :
List<double> liste = new List<double> { 1.0, 5.5, 9.9, 2.8, 9.6};
Console.WriteLine(CalculMoyenne(liste));
Le résultat de cet exemple vaut 5.76.
Enfin, la dernière méthode devra dans un premier temps construire une liste d’entiers de 1 à 100 qui sont des multiples de 3 (3, 6, 9, 12, …). Dans un second temps, construire une autre liste d’entiers de 1 à 100 qui sont des multiples de 5 (5, 10, 15, 20, …). Et dans un dernier temps, il faudra calculer la somme des entiers qui sont communs aux deux listes … vous devez bien sur trouver 315 comme résultat :)
Voilà, c’est à vous de jouer …
Bon, allez, je vais quand même vous donner quelques conseils pour démarrer. Vous n’êtes pas obligé de les lire si vous vous sentez capables de réaliser cet exercice tout seul.
Vous l’aurez évidemment compris, il va falloir utiliser des boucles. Je ne donnerai pas de conseils pour la première méthode, c’est juste pour vous échauffer :) .
Pour la deuxième méthode, vous allez avoir besoin de diviser la somme de tous les doubles par la taille de la liste. Vous ne savez sans doute pas comment obtenir cette taille. Le principe est le même que pour la taille d’un tableau et vous l’aurez sans doute trouvé si vous fouillez un peu dans les méthodes de la liste. Toujours est-il que pour obtenir la taille d’une liste, on va utiliser liste.Count, avec par exemple :
int taille = liste.Count;
Enfin, pour la dernière méthode, vous allez devoir trouver tous les multiples de 3 et de 5. Le plus simple, à mon avis, pour calculer tous les multiples de 3, est de faire une boucle qui démarre à 3 et d’avancer de 3 en 3 jusqu’à la valeur souhaitée. Et pareil pour les multiples de 5.
Ensuite, il sera nécessaire de faire deux boucles imbriquées afin de déterminer les intersections. C’est-à-dire parcourir la liste de multiple de 3 et à l’intérieur de cette boucle, parcourir la liste des multiples de 5. On compare les deux éléments, s’ils sont égaux, c’est qu’ils sont communs aux deux listes.
Voilà, vous devriez avoir tous les éléments en main pour réussir ce TP, c'est à vous ^^
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
J’imagine que vous avez réussi ce TP, non pas sans difficultés, mais à force de tâtonnements, vous avez sans doute réussi. Bravo. Si vous n’avez même pas essayé, pas bravo :pirate: . Quoi qu’il en soit, voici la correction que je propose.
Première méthode :
static int CalculSommeEntiers(int borneMin, int borneMax)
{
int resulat = 0;
for (int i = borneMin; i <= borneMax ; i++)
{
resulat += i;
}
return resulat;
}
Ce n’était pas très compliqué, il faut dans un premier temps construire une méthode qui renvoie un entier et qui accepte deux entiers en paramètres. Ensuite, on boucle grâce à l’instruction for de la borne inférieure à la borne supérieure (incluse, donc il faut utiliser l’opérateur de comparaison <= ) en incrémentant un compteur de 1 à chaque itération. Nous ajoutons la valeur du compteur à un résultat, que nous retournons en fin de boucle.
Ici, le principe est grosso modo le même, la différence est que la méthode retourne un double et accepte une liste de double en paramètres. Ici, nous utilisons la boucle foreach pour parcourir tous les éléments que nous ajoutons à un résultat. Enfin, nous retournons ce résultat divisé par la taille de la liste.
Troisième méthode :
static int CalculSommeIntersection()
{
List<int> multiplesDe3 = new List<int>();
List<int> multiplesDe5 = new List<int>();
for (int i = 3; i <= 100; i += 3)
{
multiplesDe3.Add(i);
}
for (int i = 5; i <= 100; i += 5)
{
multiplesDe5.Add(i);
}
int somme = 0;
foreach (int m3 in multiplesDe3)
{
foreach (int m5 in multiplesDe5)
{
if (m3 == m5)
somme += m3;
}
}
return somme;
}
Peut-être la plus compliquée... :)
On commence par créer nos deux listes de multiples. Comme je vous avais conseillé, j’utilise une boucle for qui commence à trois avec un incrément de 3. Comme ça, je suis sûr d’avoir tous les multiples de 3 dans ma liste. C’est le même principe pour les multiples de 5, sachant que dans les deux cas, la condition de sortie est quand l’indice est supérieur à 100.
Ensuite, j’ai mes deux boucles imbriquées où je compare les deux valeurs et si elles sont égales, je rajoute la valeur à la somme globale que je renvoie en fin de méthode. Pour bien comprendre ce qu’il se passe dans les boucles imbriquées, il faut comprendre que nous allons parcourir une unique fois la liste multiplesDe3 mais que nous allons parcourir autant de fois la liste multipleDe5 qu’il y a d’éléments dans la liste multipleDe3, c’est-à-dire 33 fois. Ce n’est sans doute pas facile de le concevoir dès le début, mais pour vous aider, vous pouvez essayer de vous faire l’algorithme dans la tête :
On rentre dans la boucle qui parcoure la liste multiplesDe3
m3 vaut 3
On rentre dans la boucle qui parcoure la liste multiplesDe5
m5 vaut 5
On compare 3 à 5, ils sont différents
On passe à l’itération suivante de la liste multiplesDe5
m5 vaut 10
On compare 3 à 10, ils sont différents
Etc … jusqu’à ce qu’on ait fini de parcourir la liste des multiplesDe5
On passe à l’itération suivante de la liste multiplesDe3
m3 vaut 6
On rentre dans la boucle qui parcoure la liste multiplesDe5
m5 vaut 5
On compare 6 à 5, ils sont différents
On passe à l’itération suivante de la liste multiplesDe5
Etc …
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est aussi possible de parcourir les listes avec un for et d’accéder aux éléments de la liste avec un indice, comme on le fait pour un tableau. Ce qui donnerait :
static double CalculMoyenne(List<double> liste)
{
double somme = 0;
for (int i = 0; i < liste.Count; i++)
{
somme += liste[i];
}
return somme / liste.Count;
}
Notez qu’on se sert de liste.Count pour obtenir la taille de la liste et qu’on accède à l’élément courant avec liste[i]. Je reconnais que la boucle foreach est plus explicite, mais cela peut être utile de connaitre le parcours d’une liste avec la boucle for. A vous de voir.
Vous aurez également noté ma technique pour avoir des multiples de 3 et de 5. Il y en a plein d’autres. Je pense à une en particulier et qui fait appel à des notions que nous avons vu auparavant : la division entière et la division de double.
Pour savoir si un nombre est un multiple d’un autre, il suffit de les diviser entre eux et de voir s’il y a un reste à la division. Pour ce faire, on peut le faire de deux façons. Soit en comparant la division entière avec la division « double » et en vérifiant que le résultat est le même. Si le résultat est le même, c’est qu’il n’y a pas de chiffres après la virgule :
for (int i = 1; i <= 100; i++)
{
if (i / 3 == i / 3.0)
multiplesDe3.Add(i);
if (i / 5 == i / 5.0)
multiplesDe5.Add(i);
}
L'autre solution est d'utiliser l’opérateur modulo que nous avons vu précédemment qui fait justement ça :
for (int i = 1; i <= 100; i++)
{
if (i % 3 == 0)
multiplesDe3.Add(i);
if (i % 5 == 0)
multiplesDe5.Add(i);
}
L’avantage de ces deux techniques est qu’on peut construire les deux listes de multiples en une seule boucle.
Voilà, c’est fini pour ce TP. N’hésitez pas à vous faire la main sur ces boucles car il est fondamental que vous les maitrisiez. Faites-vous plaisir, tentez de les repousser dans leurs limites, essayez de résoudre d’autres problèmes, ... L’important, c’est de pratiquer.
Cette première partie touche désormais à sa fin.
Nous avons commencé l'étude du C# en définissant exactement ce que nous allions faire dans ce tutoriel, ce qu'est le C# et comment créer des applications avec.
Vous avez pu découvrir tout au long des différents chapitres les bases de la programmation en C#. Vous devriez commencer à être capables de vous amuser à faire quelques petits programmes.
Dans le prochain chapitre, nous allons aller encore un peu plus loin dans l'étude des bases du C#.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu que le C# est un langage qui possède plein de types de données différents : entier, décimal, chaîne de caractères, etc.
Dans nos programmes, nous allons très souvent avoir besoin de manipuler des données entre elles alors qu'elles ne sont pas forcément du même type. Lorsque cela sera possible, nous aurons besoin de convertir un type de données en un autre.
C’est l’heure de faire la sélection des types les plus performants, place au casting ! Le jury est en place, à vos SMS pour voter.
Ah, on me fait signe qu’il ne s’agirait pas de ce casting là … :) .
Plus précisément, cela fonctionne pour les types qui sont compatibles entre eux, entendez par là « qui se ressemblent ».
Par exemple, l'entier et le petit entier se ressemblent. Pour rappel, nous avons :
Type
Description
short
Entier de -32768 à 32767
int
Entier de -2147483648 à 2147483647
Ils ne diffèrent que par leur capacité. Le short ne pourra pas contenir le nombre 100000 par exemple, alors que l'int le pourra.
Nous ne l'avons pas encore fait, mais le C# nous autorise à faire :
short s = 200;
int i = s;
Car il est toujours possible de stocker un petit entier dans un grand. Peu importe la valeur de s, i sera toujours à même de contenir sa valeur. C'est comme dans une voiture, si nous arrivons à tenir à 5 dans un monospace, nous pourrons facilement tenir à 5 dans un bus.
L'inverse n'est pas vrai bien sûr, si nous tenons à 100 dans un bus, ce n'est pas certain que nous pourrons tenir dans le monospace, même en se serrant bien.
Ce qui fait que si nous faisons :
int i = 100000;
short s = i;
nous aurons l'erreur de compilation suivante :
Impossible de convertir implicitement le type 'int' en 'short'. Une conversion explicite existe (un cast est-il manquant ?)
Et oui, comment pouvons-nous faire rentrer 100000 dans un type qui ne peut aller que jusqu'à 32767 ? Le compilateur le sait bien.
Vous remarquerez que nous aurons cependant la même erreur si nous tentons de faire :
int i = 200;
short s = i;
Mais pourquoi ? Le short est bien capable de stocker la valeur 200 ?
Oui tout à fait, mais le compilateur nous avertit quand même. Il nous dit :
Nous avons envie de lui répondre :
(on se parle souvent avec mon compilateur !)
Et bien, ceci s'écrit en C# de la manière suivante :
int i = 200;
short s = (short)i;
Pour faire un tel cast, il suffit de précéder la variable à convertir du nom du type souhaité entre parenthèses. Ce qui permet d'indiquer à notre compilateur que nous savons ce que nous faisons, et que l'entier tiendra correctement dans le petit entier.
Mais attention, le compilateur nous fait confiance. Nous sommes le boss ! Cela implique une certaine responsabilité, il ne faut pas faire n'importe quoi.
Si nous faisons :
int i = 40000;
short s = (short)i;
Console.WriteLine(s);
Console.WriteLine(i);
nous tentons de faire rentrer un trop gros entier dans ce qu'est capable de stocker le petit entier.
Si nous exécutons notre application, nous aurons :
Le résultat n'est pas du tout celui attendu. Nous avons fait n'importe quoi, le C# nous a punis. :diable:
En fait, plus précisément, il s'est passé ce qu'on appelle un dépassement de capacité. Nous l'avons déjà vu lors du chapitre sur les boucles. Ici, il s'est produit la même chose. Le petit entier est allé à sa valeur maximale puis a bouclé en repartant de sa valeur minimale.
Bref, tout ça pour dire que nous obtenons un résultat inattendu. Il faut donc faire attention à ce que l'on fait et honorer la confiance que nous porte le compilateur. Bien faire attention à ce que l'on caste.
D'une façon similaire à l'entier et au petit entier, l'entier et le double se ressemblent un peu. Ce sont tous les deux des types permettant de contenir des nombres. Le premier permet de contenir des nombres entiers, le deuxième pouvant contenir des nombres à virgules.
Ainsi, nous pouvons faire le code C# suivant :
int i = 20;
double d = i;
En effet, un double est plus précis qu’un entier. Il est capable d’avoir des chiffres après la virgule alors que l’entier ne le peut pas. Ce qui fait que le double est entièrement capable de stocker toute la valeur d’un entier sans perdre d’information dans cette affectation.
Par contre, comme on peut s'y attendre, l’inverse n’est pas possible. Le code suivant :
double prix = 125.55;
int valeur = prix;
produira l’erreur de compilation suivante :
Impossible de convertir implicitement le type 'double' en 'int'. Une conversion explicite existe (un cast est-il manquant ?)
En effet, un double étant plus précis qu’un entier, si nous mettons ce double dans l’entier nous allons perdre notamment les chiffres après la virgule.
Il restera encore une fois à demander au compilateur de nous faire confiance !
Ce qui s’écrit en C# de cette manière, comme nous l'avons vu :
double prix = 125.55;
int valeur = (int)prix; // valeur vaut 125
Nous faisons précéder la variable prix du type dans lequel nous voulons la convertir en utilisant les parenthèses.
C'est plutôt sympa comme instruction. Mais n'oubliez-pas que cette opération est possible uniquement avec les types qui se ressemblent entre eux.
Par exemple, le cast suivant est impossible :
string nombre = "123";
int valeur = (int)nombre;
car les deux types sont trop différents et sont incompatibles entre eux. Même si la chaine de caractères représente un nombre.
Nous verrons plus loin comment convertir une chaîne en entier. Pour l’instant, Visual C# Express nous génère une erreur de compilation :
Impossible de convertir le type 'string' en 'int'
Nous avons vu précédemment que les énumérations représentaient des valeurs entières. Il est donc possible de récupérer l’entier correspondant à une valeur de l’énumération grâce à un cast.
Par exemple, en considérant l’énumération suivante :
Nous verrons dans la prochaine partie que le cast est beaucoup plus puissant que ça, mais pour l’instant, nous n’avons pas assez de connaissances pour tout étudier. Nous y reviendrons dans la partie suivante.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu qu’il était facile de convertir des types qui se ressemblent grâce au cast. Il est parfois possible de convertir des types qui ne se ressemblent pas mais qui ont le même sens.
Par exemple, il est possible de convertir une chaine de caractères qui contient uniquement des chiffres en un nombre (entier, décimal, …). Cette conversion va nous servir énormément car dès qu’un utilisateur va saisir une information par le clavier, elle sera représentée par une chaine de caractères. Donc si on lui demande de saisir un nombre, il faut être capable d’utiliser sa saisie comme un nombre afin de le transformer, de le stocker, etc …
Pour ce faire, il existe plusieurs solutions. La plus simple est d’utiliser la méthode Convert.ToInt32() disponible dans le framework .NET. Par exemple :
string chaineAge = "20";
int age = Convert.ToInt32(chaineAge); // age vaut 20
Cette méthode, bien que simple d’utilisation, pose un inconvénient dans le cas où la chaine ne représente pas un entier. À ce moment-là, la conversion va échouer et le C# va renvoyer une erreur au moment de l’exécution.
Par exemple :
string chaineAge = "vingt ans";
int age = Convert.ToInt32(chaineAge);
Si vous exécutez ce bout de code, vous verrez :
La console nous affiche ce que l’on appelle une exception. Il s’agit tout simplement d’une erreur. Nous aurons l’occasion d’étudier plus en détail les exceptions dans les chapitres ultérieurs. Pour l’instant, on a juste besoin de voir que ceci ne nous convient pas. L’erreur est explicite « Le format de la chaine d’entrée est incorrect », mais cela se passe au moment de l’exécution et notre programme « plante » lamentablement. Nous verrons dans le chapitre sur les exceptions comment gérer les erreurs.
En interne, la méthode Convert.ToInt32() utilise une autre méthode pour faire la conversion, il s’agit de la méthode int.Parse(). Donc plutôt que d’utiliser une méthode qui en appelle une autre, nous pouvons nous en servir directement, par exemple :
string chaineAge = "20";
int age = int.Parse(chaineAge); // age vaut 20
Bien sûr, il se passera exactement la même chose que précédemment quand la chaine ne représentera pas un entier correct.
Il existe par contre une autre façon de convertir une chaine en entier qui ne provoque pas d’erreur quand le format n’est pas correct et qui nous informe si la conversion s’est bien passée ou non, c’est la méthode int.TryParse() qui s’utilise ainsi :
string chaineAge = "ab20cd";
int age;
if (int.TryParse(chaineAge, out age))
{
Console.WriteLine("La conversion est possible, age vaut " + age);
}
else
{
Console.WriteLine("Conversion impossible");
}
Et nous aurons :
La méthode int.TryParse nous renvoie vrai si la conversion est bonne, faux sinon. Nous pouvons donc effectuer une action en fonction du résultat grâce aux if/else. On passe en paramètres la chaine à convertir et la variable où l’on veut stocker le résultat de la conversion. Le mot clé « out» signifie juste que la variable est modifiée par la méthode, nous verrons exactement de quoi il s’agit dans un chapitre ultérieur.
Les méthodes que nous venons de voir Convert.ToString() ou int.TryParse() se déclinent en général pour tous les types de bases, par exemple double.TryParse() ou Convert.ToDecimal(), etc …
En résumé
Il est possible, avec le casting, de convertir la valeur d’un type dans un autre lorsqu’ils sont compatibles entre eux.
Le casting explicite s’utilise en préfixant une variable par un type précisé entre parenthèses.
Le framework .NET possède des méthodes permettant de convertir des types incompatibles entre eux s’ils sont sémantiquement proches.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons beaucoup écrit avec Console.WriteLine(), maintenant il est temps de savoir lire. En l'occurrence, il faut être capable de récupérer ce que l'utilisateur a saisi au clavier. En effet, un programme qui n'a pas d'interaction avec l'utilisateur, ce n'est pas vraiment intéressant. Vous imaginez un jeu où on ne fait que regarder ? Ça s'appelle une vidéo, c'est intéressant aussi, mais ce n'est pas pareil !
Aujourd'hui, il existe beaucoup d'interfaces de communication que l'on peut utiliser sur un ordinateur (clavier, souris, doigts, manettes,…). Dans ce chapitre nous allons regarder comment savoir ce que l'utilisateur a saisi au clavier dans une application console.
Lorsque nous lui en donnerons la possibilité, l'utilisateur de notre programme pourra saisir des choses grâce à son clavier. Nous pouvons lui demander son âge, s'il veut terminer notre application, lui permettre de saisir un mail, etc ...
Il nous faut donc un moyen lui permettant de saisir des caractères en tapant sur son clavier. Nous pourrons faire cela grâce à la méthode Console.ReadLine:
string saisie = Console.ReadLine();
Lorsque notre application rencontre cette instruction, elle se met en pause et attend une saisie de la part de l’utilisateur. La saisie s’arrête lorsque l’utilisateur valide ce qu’il a écrit avec la touche entrée. Ainsi les instructions suivantes :
Console.WriteLine("Veuillez saisir une phrase et valider avec la touche \"Entrée\"");
string saisie = Console.ReadLine();
Console.WriteLine("Vous avez saisi : " + saisie);
produiront :
Vous aurez remarqué que nous stockons le résultat de la saisie dans une variable de type chaine de caractères. C’est bien souvent le seul type que nous aurons à notre disposition lors des saisies utilisateurs. Cela veut bien sûr dire que si vous avez besoin de manipuler l’âge de la personne, il faudra la convertir en entier. Par exemple :
bool ageIsValid = false;
int age = -1;
while (!ageIsValid)
{
Console.WriteLine("Veuillez saisir votre age");
string saisie = Console.ReadLine();
if (int.TryParse(saisie, out age))
ageIsValid = true;
else
{
ageIsValid = false;
Console.WriteLine("L'age que vous avez saisi est incorrect ...");
}
}
Console.WriteLine("Votre âge est de : " + age);
Et nous aurons :
Ce code est facile à comprendre maintenant que vous maitrisez les boucles et les conditions. Nous commençons par initialiser nos variables. Ensuite, nous demandons à l’utilisateur de saisir son âge. Nous tentons de le convertir en entier, si cela fonctionne on pourra passer à la suite, sinon, tant que l’âge n’est pas valide, nous recommençons la boucle.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il peut arriver que nous ayons besoin de ne saisir qu’un seul caractère, pour cela nous allons pouvoir utiliser la méthode Console.ReadKey(). Nous pourrons nous en servir par exemple pour faire une pause dans notre application. Le code suivant réclame l’attention de l’utilisateur avant de démarrer un calcul hautement important :
Console.WriteLine("Veuillez appuyer sur une touche pour démarrer le calcul ...");
Console.ReadKey(true);
int somme = 0;
for (int i = 0; i < 100; i++)
{
somme += i;
}
Console.WriteLine(somme);
Ce qui nous donnera :
À noter que nous avons passé true en paramètre de la méthode afin d’indiquer au C# que nous ne souhaitions pas que notre saisie apparaisse à l’écran. Si le paramètre avait été false et que j’avais par exemple appuyé sur h pour démarrer le calcul, le résultat se serait vu précédé d’un disgracieux « h » …
D’ailleurs, comment faire pour savoir quelle touche a été saisie ?
Il suffit d’observer le contenu de la variable renvoyée par la méthode Console.ReadKey. Elle renvoie en l’occurrence une variable du type ConsoleKeyInfo. Nous pourrons comparer la valeur « Key » de cette variable qui est une énumération du type ConsoleKey. Par exemple :
Nous remarquons grâce à la complétion automatique que l’énumération ConsoleKey possède plein de valeur :
Nous comparons donc à la valeur ConsoleKey.O qui représente la touche o.
À noter que le type « ConsoleKeyInfo» est ce qu’on appelle une structure et que Key est une propriété de la structure. Nous reviendrons dans la partie suivante sur ce que cela veut vraiment dire. Pour l’instant, considérez juste qu’il s’agit d’une variable évoluée qui permet de contenir plusieurs choses…
En résumé
La méthode Console.ReadLine nous permet de lire des informations saisies par l'utilisateur au clavier.
Il est possible de lire toute une phrase terminée par la touche Entrée ou seulement un unique caractère.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous allons maintenant faire une petite pause. Le C# c'est bien, mais notre environnement de développement, Visual C# Express, peut faire beaucoup plus que sa fonction basique d'éditeur de fichiers. Il possède un outil formidable qui va nous permettre d'être très efficaces dans le débogage de nos applications et dans la compréhension de leur fonctionnement.
Il s'agit du débogueur. Découvrons vite à quoi il sert et comment il fonctionne
Fidèle à son habitude de nous simplifier la vie, Visual C# express possède un débogueur. C’est un outil très pratique qui va permettre d’obtenir plein d’informations sur le déroulement de son programme.
Il va permettre d'exécuter les instructions les unes après les autres, de pouvoir observer le contenu des variables, de revenir en arrière, bref, de pouvoir savoir exactement ce qu’il se passe et surtout pourquoi tel bout de code ne fonctionne pas.
Pour l’utiliser, il faut que Visual C# express soit en mode « débogage ». Je n’en ai pas encore parlé. Pour ce faire, il faut exécuter l’application en appuyant sur F5 ou en passant par le menu Déboguer > Démarrer le débogage ou en cliquant sur le petit triangle vert dont l’icône rappelle un bouton de lecture.
Pour étudier le débogueur, reprenons la dernière méthode du précédent TP :
static void Main(string[] args)
{
Console.WriteLine(CalculSommeIntersection());
}
static int CalculSommeIntersection()
{
List<int> multiplesDe3 = new List<int>();
List<int> multiplesDe5 = new List<int>();
for (int i = 1; i <= 100; i++)
{
if (i % 3 == 0)
multiplesDe3.Add(i);
if (i % 5 == 0)
multiplesDe5.Add(i);
}
int somme = 0;
foreach (int m3 in multiplesDe3)
{
foreach (int m5 in multiplesDe5)
{
if (m3 == m5)
somme += m3;
}
}
return somme;
}
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour que le programme s’arrête sur un endroit précis et qu’il nous permette de voir ce qu’il se passe, il va falloir mettre des points d’arrêts dans notre code.
Pour mettre un point d’arrêt, il faut se positionner sur la ligne où nous souhaitons nous arrêter, par exemple la première ligne où nous appelons Console.WriteLine et appuyer sur F9. Nous pouvons également cliquer dans la marge à gauche pour produire le même résultat. Un point rouge s’affiche et indique qu’il y a un point d’arrêt à cet endroit.
Il est possible de mettre autant de points d’arrêts que nous le souhaitons, à n’importe quel endroit de notre code.
Lançons l’application avec F5, nous pouvons voir que Visual C# express s’arrête sur la ligne prévue en la surlignant en jaune :
Nous en profitons pour remarquer au niveau du carré rouge que le débogueur est en pause et qu’il est possible soit de continuer l’exécution (triangle) soit de l’arrêter (carré) soit de redémarrer le programme depuis le début (carré avec une flèche blanche dedans).
Nous pouvons désormais exécuter notre code pas à pas, en nous servant des icônes à coté ou des raccourcis claviers suivants :
Utilisons la touche F10 pour continuer l’exécution du code pas à pas. La ligne suivante se trouve surlignée à son tour. Appuyons à nouveau sur la touche F10 pour aller à l’instruction suivante, il n’y en a plus le programme se termine.
Vous me direz, « c’est bien beau, mais, nous ne sommes pas passés dans la méthode CalculSommeIntersection() ». Et oui, c’est parce que nous avons utilisé la touche F10 qui est le pas à pas principal. Pour rentrer dans la méthode, il aurait fallu utiliser la touche F11 qui est le pas à pas détaillé.
Si nous souhaitons que le programme se poursuive pour aller jusqu’au prochain point d’arrêt, il suffit d’appuyer sur le triangle (play) ou sur F5.
Relançons notre programme en mode débogage, et cette fois-ci, lorsque le débogueur s’arrête sur notre point d’arrêt, appuyons sur F11 pour rentrer dans le corps de la méthode. Voilà, nous sommes dans la méthode CalculSommeIntersection(). Continuons à appuyer plusieurs fois sur F10 afin de rentrer dans le corps de la boucle for.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
À ce moment-là du débogage, si nous passons la souris sur la variable i, qui est l’indice de la boucle, Visual C# express va nous afficher une mini-information :
Il nous indique que i vaut 1, ce qui est normal, nous sommes dans la première itération de la boucle. Si nous continuons le parcours en appuyant sur F10 plusieurs fois, nous voyons que la valeur de i augmente, conformément à ce qui est attendu. Maintenant, mettons un point d’arrêt - F9 - sur la ligne :
multiplesDe3.Add(i);
et poursuivons l’exécution en appuyant sur F5. Il s’arrête au moment où i vaut 3. Appuyons sur F10 pour exécuter l’ajout de i à la liste et passons la souris sur la liste :
Visual C# express nous indique que la liste multiplesDe3 a son « Count » qui vaut 1. Si nous cliquons sur le + pour déplier la liste :
nous pouvons voir que 3 a été ajouté dans le premier emplacement de la liste (indice 0). Si nous continuons l’exécution plusieurs fois, nous voyons que les listes se remplissent au fur et à mesure.
Enlevez le point d’arrêt sur la ligne en appuyant à nouveau sur F9 et mettez un nouveau point d’arrêt sur la ligne :
int somme = 0;
Poursuivez l’exécution avec F5, la boucle est terminée, nous pouvons voir que les listes sont complètement remplies :
Grâce au débogueur, nous pouvons voir vraiment tout ce qui nous intéresse, c’est une des grandes forces du débogueur et c’est un atout vraiment très utile pour comprendre ce qu’il se passe dans un programme (en général, ça se passe mal !).
Il est également possible de voir les variables locales en regardant en bas dans la fenêtre « Variables locales ». Dans cette fenêtre, vous pourrez observer les variables qui sont dans la portée courante. Il existe également une fenêtre « Espion » qui permet de la même façon de surveiller une ou plusieurs variables précises.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nom de Zeus, Marty ! On peut revenir dans le passé ?
C’est presque ça Doc ! Si pour une raison, vous souhaitez ré-exécuter un bout de code, parce que vous n’avez pas bien vu ou que vous avez raté l’information qu’il vous fallait, vous pouvez forcer le débogueur à revenir en arrière dans le programme. Pour cela, vous avez deux solutions, soit vous faites un clic droit à l’endroit souhaité et vous choisissez l’élément de menu Définir l’instruction suivante :
soit vous déplacez avec la souris la petite flèche jaune sur la gauche qui indique l’endroit où nous en sommes.
Il faut faire attention car ce retour en arrière n’en est pas complètement un. En effet, si vous revenez au début de la boucle qui calcule les multiples et que vous continuez l’exécution, vous verrez que la liste continue à se remplir. À la fin de la boucle, au lieu de contenir 33 éléments, la liste des multiples de 3 en contiendra 66. En effet, à aucun moment nous n'avons vidé la liste et donc le fait de ré-exécuter cette partie de code risque de provoquer des comportements inattendus. Ici, il vaudrait mieux revenir au début de la méthode afin que la liste soit de nouveau créée.
Même si ça ne vous saute pas aux yeux pour l’instant, vous verrez à l’usage que cette possibilité est bien pratique. D’autant plus quand vous aurez bien assimilé toutes les notions de portée de variable.
Mais rassurez-vous, celui-ci est quand même déjà bien avancé et permet de faire beaucoup de choses.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une autre fenêtre importante à regarder est la pile des appels, elle permet d’indiquer où nous nous trouvons et par où nous sommes passés pour arriver à cet endroit-là.
Par exemple si vous appuyez sur F11 et que vous rentrez dans la méthode CalculSommeIntersection() vous pourrez voir dans la pile des appels que vous êtes dans la méthode CalculSommeIntersection() qui a été appelée depuis la méthode Main() :
Si vous cliquez sur la ligne du Main(), Visual C# express vous ramène automatiquement à l’endroit où a été fait l’appel. Cette ligne est alors surlignée en vert pour bien faire la différence avec le surlignage en jaune qui est vraiment l’endroit où se trouve le débogueur. C’est très pratique quand on a beaucoup de méthodes qui s’appellent les unes à la suite des autres.
En tous cas, le débogueur est vraiment un outil à forte valeur ajoutée. Je ne vous ai présenté que le strict minimum nécessaire et indispensable. Mais croyez-moi, vous aurez l’occasion d’y revenir :) .
En résumé
Le débogueur est un outil très puissant permettant d'inspecter le contenu des variables lors de l'exécution d'un programme.
On peut s'arrêter à un endroit de notre application grâce à un point d'arrêt.
Le débogueur permet d'exécuter son application pas à pas et de suivre son évolution.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Wahou, nous augmentons régulièrement le nombre de choses que nous savons. C'est super. Nous commençons à être capables d'écrire des applications qui ont un peu plus de panache !
Enfin… moi, j'y arrive ! Et vous ? C'est ce que nous allons vérifier avec ce TP.
Savoir interagir avec son utilisateur est important. Voici donc un petit TP sous forme de création d'un jeu simple qui va vous permettre de vous entraîner. L'idée est de réaliser le jeu classique du plus ou du moins…
Je vous rappelle les règles. L’ordinateur nous calcule un nombre aléatoire et nous devons le deviner. À chaque saisie, il nous indique si le nombre saisi est plus grand ou plus petit que le nombre à trouver. Une fois trouvé, il nous indique en combien de coups nous avons réussi à trouver le nombre secret.
Pour ce TP, vous savez presque tout faire. Il ne vous manque que l’instruction pour obtenir un nombre aléatoire. La voici, cette instruction permet de renvoyer un nombre compris entre 0 et 100 (exclu). Ne vous attardez pas trop sur sa syntaxe, nous aurons l’occasion de comprendre exactement de quoi il s’agit dans le chapitre suivant :
int valeurATrouver = new Random().Next(0, 100);
Le principe est grosso modo le suivant : tant qu’on n’a pas trouvé la bonne valeur, nous devons en saisir une nouvelle. Dans ce cas, la console nous indique si la valeur est trop grande ou trop petite. Il faudra bien sur incrémenter un compteur de coups à chaque essai.
N’oubliez pas de gérer le cas où l’utilisateur saisit n’importe quoi. Nous ne voudrions pas que notre premier jeu ait un bug qui fasse planter l’application !
Allez, je vous en ai trop dit. C’est à vous de jouer. Bon courage.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Bien sûr, il existe beaucoup de façon de réaliser ce petit jeu. S’il fonctionne, c’est que votre solution est bonne. Ma solution fonctionne, la voici :
static void Main(string[] args)
{
int valeurATrouver = new Random().Next(0, 100);
int nombreDeCoups = 0;
bool trouve = false;
Console.WriteLine("Veuillez saisir un nombre compris entre 0 et 100 (exclu)");
while (!trouve)
{
string saisie = Console.ReadLine();
int valeurSaisie;
if (int.TryParse(saisie, out valeurSaisie))
{
if (valeurSaisie == valeurATrouver)
trouve = true;
else
{
if (valeurSaisie < valeurATrouver)
Console.WriteLine("Trop petit ...");
else
Console.WriteLine("Trop grand ...");
}
nombreDeCoups++;
}
else
Console.WriteLine("La valeur saisie est incorrecte, veuillez recommencer ...");
}
Console.WriteLine("Vous avez trouvé en " + nombreDeCoups + " coup(s)");
}
On commence par obtenir un nombre aléatoire avec l’instruction que j’ai fournie dans l’énoncé. Nous avons ensuite les initialisations de variables. L’entier nombreDeCoups va permettre de stocker le nombre d’essai et le booléen « trouve » va permettre d’avoir une condition de sortie de boucle.
Notre boucle démarre et ne se terminera qu’une fois que le booléen « trouve » sera passé à vrai (true). Dans le corps de la boucle, nous demandons à l’utilisateur de saisir une valeur que nous essayons de convertir en entier. Si la conversion échoue, nous l’indiquons à l’utilisateur et nous recommençons notre boucle. Notez ici que je n’incrémente pas le nombre de coups, jugeant qu’il n’y a pas lieu de pénaliser le joueur parce qu’il a mal saisi ou qu’il a renversé quelque chose sur son clavier juste avant de valider la saisie.
Si par contre la conversion se passe bien, nous pouvons commencer à comparer la valeur saisie avec la valeur à trouver. Si la valeur est la bonne, nous passons le booléen à vrai, ce qui nous permettra de sortir de la boucle et de passer à la suite. Sinon, nous afficherons un message pour indiquer si la saisie est trop grande ou trop petite en fonction du résultat de la comparaison. Dans tous les cas, nous incrémenterons le nombre de coups.
Enfin, en sortie de boucle, nous indiquerons sa victoire au joueur ainsi que le nombre de coups utilisés pour trouver le nombre secret. Une partie de jeu pourra être :
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est bien sûr toujours possible d’améliorer le jeu. Nous pourrions par exemple ajouter un contrôle sur les bornes de la saisie. Ainsi, si l’utilisateur saisit un nombre supérieur ou égal à 100 ou inférieur à 0, nous pourrions lui rappeler les bornes du nombre aléatoire.
De même, à la fin, plutôt que d’afficher « coup(s) », nous pourrions tester la valeur du nombre de coups. S’il est égal à 1, on affiche « coup » au singulier, sinon « coups » au pluriel.
La boucle pourrait également être légèrement différente. Plutôt que de tester la condition de sortie sur un booléen, nous pourrions utiliser le mot clé break. De même, nous pourrions alléger l’écriture avec le mot clé continue.
Par exemple :
static void Main(string[] args)
{
int valeurATrouver = new Random().Next(0, 100);
int nombreDeCoups = 0;
Console.WriteLine("Veuillez saisir un nombre compris entre 0 et 100 (exclu)");
while (true)
{
string saisie = Console.ReadLine();
int valeurSaisie;
if (!int.TryParse(saisie, out valeurSaisie))
{
Console.WriteLine("La valeur saisie est incorrecte, veuillez recommencer ...");
continue;
}
if (valeurSaisie < 0 || valeurSaisie >= 100)
{
Console.WriteLine("Vous devez saisir un nombre entre 0 et 100 exclu ...");
continue;
}
nombreDeCoups++;
if (valeurSaisie == valeurATrouver)
break;
if (valeurSaisie < valeurATrouver)
Console.WriteLine("Trop petit ...");
else
Console.WriteLine("Trop grand ...");
}
if (nombreDeCoups == 1)
Console.WriteLine("Vous avez trouvé en " + nombreDeCoups + " coup");
else
Console.WriteLine("Vous avez trouvé en " + nombreDeCoups + " coups");
}
Tout ceci est une question de goût. Je préfère personnellement la version précédente n’aimant pas trop les break et les continue. Mais après tout, chacun fait comme il préfère, l’important est que nous amusions à écrire le programme et à y jouer. :D
Voilà, ce TP est terminé.
Vous avez pu voir finalement que nous étions tout à fait capables de réaliser des petites applications récréatives. Personnellement, j'ai commencé à m'amuser à faire de la programmation en réalisant toute sorte de petits programmes de ce genre.
Je vous encourage fortement à essayer de créer d'autres programmes vous-mêmes, pourquoi pas à proposer aux autres vos idées. Plus vous vous entraînerez à faire des petits programmes simples et plus vous réussirez à appréhender les subtilités de ce que nous avons appris.
Bien sûr, plus tard, nous serons capables de réaliser des applications plus compliquées ... Cela vous tente ? Alors continuons la lecture. :)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Sous ce nom un peu barbare se cache une fonctionnalité très présente dans nos usages quotidiens mais qui a tendance à être masquée à l'utilisateur lambda. Nous allons, dans un premier temps, voir ce qu'est exactement la ligne de commande et à quoi elle sert. Ensuite, nous verrons comment l'exploiter dans notre application avec le C#.
Notez que ce chapitre n'est pas essentiel mais qu'il pourra sûrement vous servir plus tard dans la création de vos applications.
La ligne de commande, c’est ce qui nous permet d’exécuter nos programmes. Très présente à l’époque où Windows existait peu, elle a tendance à disparaitre de nos utilisations. Mais pas le fond de son fonctionnement.
En général, la ligne de commande sert à passer des arguments à un programme. Par exemple, pour ouvrir un fichier texte avec le bloc-notes (notepad.exe), on peut le faire de deux façons différentes. Soit on ouvre le bloc-notes et on va dans le menu Fichier > Ouvrir puis on va chercher le fichier pour l’ouvrir. Soit on utilise la ligne de commande pour l’ouvrir directement.
Pour ce faire, il suffit d’utiliser la commande :
notepad c:\test.txt
et le fichier c: est.txt s’ouvre directement dans le bloc-notes.
Ce qu’il s’est passé derrière, c’est que nous avons demandé d’exécuter le programme notepad.exe avec le paramètre c: est.txt. Le programme notepad a analysé sa ligne de commande, il y a trouvé un paramètre et il a ouvert le fichier correspondant.
Superbe ! Nous allons apprendre à faire pareil !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
La première chose à faire est de savoir comment faire pour passer des paramètres en ligne de commande. Plusieurs solutions existent. On peut par exemple exécuter la commande que j’ai écrite plus haut depuis le menu Démarrer > Exécuter (ou la combinaison windows + r).
On peut également le faire depuis une invite de commande (Menu Démarrer > Accessoires > Invite de commande) :
Ceci nous ouvre une console noire, comme celle que l’on connait bien et dans laquelle nous pouvons taper des instructions :
Mais nous, ce qui nous intéresse surtout, c’est de pouvoir le faire depuis Visual C# Express afin de pouvoir passer des arguments à notre programme. Pour ce faire, on va aller dans les propriétés de notre projet (bouton droit sur le projet, Propriétés) puis nous allons dans l’onglet Déboguer et nous voyons une zone de texte permettant de mettre des arguments à la ligne de commande. Rajoutons par exemple « Bonjour Nico » :
Voilà, maintenant lorsque nous exécuterons notre application, Visual C# express lui passera les arguments que nous avons définis en paramètre de la ligne de commande.
A noter que dans ce cas, les arguments « Bonjour Nico » ne seront valables que lorsque nous exécuterons l’application à travers Visual C# express. Evidemment, si nous exécutons notre application par l’invite de commande, nous aurons besoin de repasser les arguments au programme pour qu’il puisse les exploiter.
C’est bien ! Sauf que pour l’instant, ça ne nous change pas la vie ! Il faut apprendre à traiter ces paramètres …
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
On peut lire le contenu de la ligne de commande de deux façons différentes. Vous vous rappelez de la méthode Main() ? On a vu que Visual C# express générait cette méthode avec des paramètres. Et bien ces paramètres, vous ne devinerez jamais ! Ce sont les paramètres de la ligne de commande. Oh joie !
static void Main(string[] args)
{
}
La variable args est un tableau de chaine de caractères. Sachant que chaque paramètre est délimité par des espaces, nous retrouverons chacun des paramètres à un indice du tableau différent.
Ce qui fait que si j’utilise le code suivant :
foreach (string parametre in args)
{
Console.WriteLine(parametre);
}
et que je lance mon application avec les paramètres définis précédemment, je vais obtenir :
Et voilà, nous avons récupéré les paramètres de la ligne de commande, il ne nous restera plus qu’à les traiter dans notre programme. Comme prévu, nous obtenons deux paramètres. Le premier est la chaine de caractères « Bonjour », le deuxième est la chaine de caractères « Nico ». N’oubliez pas que c’est le caractère d’espacement qui sert de délimiteur entre les paramètres.
L’autre façon de récupérer la ligne de commande est d’utiliser la méthode Environment.GetCommandLineArgs(). Elle renvoie un tableau contenant les paramètres, comme ce qui est passé en paramètres à la méthode Main. La seule différence, c’est que dans le premier élément du tableau, nous trouverons le chemin complet de notre programme. Ceci peut être utile dans certains cas. Si cela n’a aucun intérêt pour vous, il suffira de commencer la lecture à partir de l’indice numéro 1.
L’exemple suivant affiche toutes les valeurs du tableau :
foreach (string parametre in Environment.GetCommandLineArgs())
{
Console.WriteLine(parametre);
}
Ce qui donne :
Tu as dit que c’était le caractère d’espacement qui permettait de délimiter les paramètres. J’ai essayé de rajouter le paramètre C:\Program Files est.txt à ma ligne de commande afin de changer l’emplacement du fichier, mais je me retrouve avec deux paramètres au lieu d’un seul, c'est normal ?
Eh oui, il y a un espace entre Program et Files. L’astuce est de passer le paramètre entre guillemets, de cette façon : "C:\Program Files est.txt". Nous aurons un seul paramètre dans la ligne de commande à la place de 2.
Comme par exemple :
En résumé
On peut passer des paramètres à une application en utilisant la ligne de commande.
Le programme C# peut lire et interpréter ces paramètres.
Ces paramètres sont séparés par des espaces.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Et voici un nouveau TP qui va nous permettre de récapituler un peu tout ce que nous avons vu. Au programme, des if, des switch, des méthodes, des boucles et... de la ligne de commande bien sûr !
Grâce à nos connaissances grandissantes, nous arrivons à augmenter la difficulté de nos exercices et c'est une bonne chose. Vous verrez que dans le moindre petit programme, vous aurez besoin de toutes les notions que nous avons apprises.
Allez, ne traînons pas trop et à vous de jouer travailler.
L’objectif de ce TP est de réaliser un petit programme qui permet d’effectuer une opération mathématique à partir de la ligne de commande.
Il va donc falloir écrire un programme que l'on pourra appeler avec des paramètres. En imaginant que le programme s'appelle « MonProgramme », on pourrait l'utiliser ainsi pour faire la somme de deux nombres :
MonProgramme somme 2 5 Ce qui renverra bien sûr 7.
Pour effectuer une multiplication, nous pourrons faire :
MonProgramme multiplication 2 5 et nous obtiendrons 10.
Enfin, pour calculer une moyenne, nous pourrons faire :
MonProgramme moyenne 1 2 3 4 5 ce qui renverra 3.
Les règles sont les suivantes :
Il doit y avoir 2 et seulement 2 nombres composant l’addition et la multiplication
La moyenne peut contenir autant de nombres que souhaité
Si le nombre de paramètres est incorrect, alors le programme affichera un message d’aide explicite
Si le nombre attendu n’est pas un double correct, on affichera le message d’aide
Plutôt simple non ? Alors, à vous de jouer, il n’y a pas de subtilité.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
J’ai dit qu’il n’y avait pas de subtilité, mais j’ai un peu menti en fait. J’avoue, c’était pour que vous alliez au bout du développement sans aide. ^^
Pour vérifier que vous avez trouvé la subtilité, essayez votre programme avec les paramètres suivants : MonProgramme addition 5,5 2,5
Obtenez-vous 8 ?
C’était à peu près la seule subtilité, il fallait juste savoir qu’un nombre à virgule s’écrivait avec une virgule plutôt qu’avec un point. Si nous écrivons 2.5, alors le C# ne sait pas faire la conversion.
Quoiqu'il en soit, voici ma correction du TP :
static void Main(string[] args)
{
if (args.Length == 0)
{
AfficherAide();
}
else
{
string operateur = args[0];
switch (operateur)
{
case "addition":
Addition(args);
break;
case "multiplication":
Multiplication(args);
break;
case "moyenne":
Moyenne(args);
break;
default:
AfficherAide();
break;
}
}
}
static void AfficherAide()
{
Console.WriteLine("Utilisez l'application de la manière suivante :");
Console.WriteLine("MonProgamme addition 2 5");
Console.WriteLine("MonProgamme multiplication 2 5");
Console.WriteLine("MonProgamme moyenne 2 5 10 11");
}
static void Addition(string[] args)
{
if (args.Length != 3)
{
AfficherAide();
}
else
{
double somme = 0;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
{
AfficherAide();
return;
}
somme += valeur;
}
Console.WriteLine("Résultat de l'addition : " + somme);
}
}
static void Multiplication(string[] args)
{
if (args.Length != 3)
{
AfficherAide();
}
else
{
double resultat = 1;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
{
AfficherAide();
return;
}
resultat *= valeur;
}
Console.WriteLine("Résultat de la multiplication : " + resultat);
}
}
static void Moyenne(string[] args)
{
double total = 0;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
{
AfficherAide();
return;
}
total += valeur;
}
total = total / (args.Length - 1);
Console.WriteLine("Résultat de la moyenne : " + total);
}
Disons que c’est plus long que difficile...
Oui je sais, lors de l’addition et de la multiplication, j’ai parcouru l’ensemble des paramètres alors que j’aurais pu utiliser uniquement args[1] et args[2]. L’avantage c’est que si je supprime la condition sur le nombre de paramètres, alors mon addition pourra fonctionner avec autant de nombres que je le souhaite… Vous aurez remarqué que je commence mon parcours à l’indice 1, d’où la pertinence de l’utilisation de la boucle for plutôt que la boucle foreach.
Notez quand même l’utilisation du mot clé return afin de sortir prématurément de la méthode en cas de problème.
Évidemment, il y a plein de façons de réaliser ce TP, la mienne en est une, il y en a d'autres.
J’espère que vous aurez fait attention au calcul de la moyenne. Nous retirons 1 à la longueur du tableau pour obtenir le nombre de paramètres. Il faut donc faire attention à l’ordre des parenthèses afin que le C# fasse d'abord la soustraction avant la division, alors que sans ça, la division est prioritaire à la soustraction.
Sinon, c'est l'erreur de calcul assurée, indigne de notre superbe application. :-°
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ce code est très bien. Sisi, c'est moi qui l'ai fait :p .
Sauf qu'il y a quand même un petit problème ... d'ordre architectural.
Il a été plutôt simple à écrire en suivant l'énoncé du TP mais on peut faire encore mieux. On peut le rendre plus facilement maintenable en le ré-architecturant différemment.
Observez le code suivant :
static void Main(string[] args)
{
bool ok = false;
if (args.Length > 0)
{
string operateur = args[0];
switch (operateur)
{
case "addition":
ok = Addition(args);
break;
case "multiplication":
ok = Multiplication(args);
break;
case "moyenne":
ok = Moyenne(args);
break;
}
}
if (!ok)
AfficherAide();
}
static void AfficherAide()
{
Console.WriteLine("Utilisez l'application de la manière suivante :");
Console.WriteLine("MonProgamme addition 2 5");
Console.WriteLine("MonProgamme multiplication 2 5");
Console.WriteLine("MonProgamme moyenne 2 5 10 11");
}
static bool Addition(string[] args)
{
if (args.Length != 3)
return false;
double somme = 0;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
return false;
somme += valeur;
}
Console.WriteLine("Résultat de l'addition : " + somme);
return true;
}
static bool Multiplication(string[] args)
{
if (args.Length != 3)
return false;
double resultat = 1;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
return false;
resultat *= valeur;
}
Console.WriteLine("Résultat de la multiplication : " + resultat);
return true;
}
static bool Moyenne(string[] args)
{
double total = 0;
for (int i = 1; i < args.Length; i++)
{
double valeur;
if (!double.TryParse(args[i], out valeur))
return false;
total += valeur;
}
total = total / (args.Length - 1);
Console.WriteLine("Résultat de la moyenne : " + total);
return true;
}
Nous n'affichons l'aide plus qu'à un seul endroit en utilisant le fait que les méthodes renvoient un booléen indiquant si l'opération a été possible ou pas.
D'une manière générale, il est important d'essayer de rendre son code le plus maintenable possible, comme nous l'avons fait ici.
Voilà, j'espère que vous aurez réussi ce TP.
Vous pouvez bien sûr compléter notre calculatrice élémentaire en y rajoutant des notions plus compliquées, comme la racine carrée ou la mise à la puissance. À ce propos, comme les méthodes Math.Sqrt() ou Math.Pow(), il existe de nombreuses méthodes permettant de faire des opérations de toutes sortes. Vous pouvez les consulter à cette adresse dans la documentation en ligne. (oui, je suis d'accord, ce n'est pas tous les jours que nous aurons envie de calculer la tangente hyperbolique d'un angle ... mais sait-on jamais :p ).
En tous cas, n'hésitez pas à faire des variations sur les différents TP que je vous ai proposés, il est toujours intéressant de sortir des sentiers battus.
Voilà pour cette partie.
Nous avons simplement continué à plonger dans les bases du C#. Grâce à cette partie, vous avez pu commencer à faire des programmes un peu plus rigolos en lisant les saisies utilisateurs à partir du clavier. Vous avez également pu mettre un premier pas dans le monde très important des conversions entre les types.
Bien sûr, vous devez impérativement essayer d'en créer d'autres. Plus vous pratiquerez et plus vous deviendrez à l'aise avec les différents concepts.
N'hésitez pas à chercher des informations dans la documentation en ligne si besoin. Il y a beaucoup de ressources sur internet, votre curiosité pourrait vous amener à découvrir des bonnes surprises...
Dans la prochaine partie, nous continuerons à étudier la syntaxe du C# et nous découvrirons le C# comme un langage orienté objet.
C'est une très vaste partie avec pas mal de théorie.
Alors dès à présent, armez vous de courage et n’oubliez pas de faire des pauses :D .
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre, nous allons essayer de décrire ce qu'est la programmation orientée objet (abrégée souvent en POO). Je dis bien « essayer », car pour être complètement traitée, la POO nécessiterait qu'on lui dédie un ouvrage entier !
Nous allons tâcher d'aller à l'essentiel et de rester proche de la pratique. Ce n'est pas très grave si tous les concepts abstraits ne sont pas parfaitement appréhendés : il est impossible d'apprendre la POO en deux heures. Cela nécessite une longue pratique, beaucoup d'empirisme et des approfondissements théoriques.
Ce qui est important ici, c'est de comprendre les notions de base et de pouvoir les utiliser dans de petits programmes. Après cette mise au point, attaquons sans plus tarder la programmation orientée objet !
Vous avez pu voir précédemment que j’ai utilisé de temps en temps le mot « objet » et que le mot-clé « new » est apparu comme par magie… Il a été difficile de ne pas trop en parler et il est temps d’en savoir un peu plus.
Alors qu’est-ce qu’un objet ?
Si on prend le monde réel (si si, vous allez voir, vous connaissez…), nous sommes entourés d’objets : une chaise, une table, une voiture, etc. Ces objets forment un tout.
Ils possèdent des propriétés (la chaise possède 4 pieds, elle est de couleur bleue, etc.).
Ces objets peuvent faire des actions (la voiture peut rouler, klaxonner, etc.).
Ils peuvent également interagir entre eux (l’objet conducteur démarre la voiture, l’objet voiture fait tourner l’objet volant, etc.).
Il faut bien faire attention à distinguer ce qu’est l’objet et ce qu'est la définition d’un objet
La définition de l’objet (ou structure de l’objet) permet d’indiquer ce qui compose un objet, c'est-à-dire quelles sont ses propriétés, ses actions etc. Comme par exemple le fait qu’une chaise ait des pieds ou qu’on puisse s’asseoir dessus. Par contre, l’objet chaise est bien concret. On peut donc avoir plusieurs objets chaises : on parle également d’instances. Les objets chaises, ce sont bien celles concrètes que l’on voit devant nous autour de l’objet table pour démarrer une partie de belote.
On peut faire l’analogie avec notre dictionnaire qui nous décrit ce qu’est une chaise. Le dictionnaire décrit en quoi consiste l’objet, et l’instance de l’objet représente le concret associé à cette définition. Chaque objet a sa propre vie et est différent d’un autre. Nous pouvons avoir une chaise bleue, une autre rouge, une autre avec des roulettes, une cassée …
Bon, finalement la notion d’objet est plutôt simple quand on la ramène à ce qu’on connait déjà :D .
Sachant qu’un objet en programmation c’est comme un objet du monde réel mais ce n’est pas forcément restreint au matériel. Un chien est un objet. Des concepts comme l’amour ou une idée sont également des objets, tandis qu’on ne dirait pas cela dans le monde réel.
En conclusion :
La définition (ou structure) d’un objet est un concept abstrait, comme une définition dans le dictionnaire. Cette définition décrit les caractéristiques d’un objet (la chaise a des pieds, l’homme a des jambes, etc.). Cette définition est unique comme une définition dans le dictionnaire.
Un objet ou une instance est la réalisation concrète de la structure de l’objet. On peut avoir de multiples instances, comme les 100 voitures sur le parking devant chez moi. Elles peuvent avoir des caractéristiques différentes (une voiture bleue, une voiture électrique, une voiture à 5 portes, etc.)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Le fait de concevoir une application comme un système d’objets interagissant entre eux apporte une certaine souplesse et une forte abstraction.
Prenons un exemple tout simple : la machine à café du bureau. Nous insérons nos pièces dans le monnayeur, choisissons la boisson et nous nous retrouvons avec un gobelet de la boisson commandée. Nous nous moquons complètement de savoir comment cela fonctionne à l’intérieur et nous pouvons complètement ignorer si le café est en poudre, en grain, comment l’eau est ajoutée, chauffée, comment le sucre est distribué, etc. Tout ce qui nous importe c’est que le fait de mettre des sous dans la machine nous permet d’obtenir un café qui va nous permettre d’attaquer la journée.
Voilà un bel exemple de programmation orientée objet. Nous manipulons un objet MachineACafe qui a des propriétés (Allumée/éteinte, présence de café, présence de gobelet, …) et qui sait faire des actions (AccepterMonnaie, DonnerCafe, …). Et c’est tout ce que nous avons besoin de savoir. On se moque du fonctionnement interne, peu importe ce qu’il se passe à l’intérieur, notre objet nous donne du café, point !
C’est ce qu’on appelle l’encapsulation. Cela permet de protéger l’information contenue dans notre objet et de le rendre manipulable uniquement par ses actions ou propriétés. Ainsi, l’utilisateur ne peut pas accéder au café ni au sucre ou encore moins à la monnaie. Notre objet est ainsi protégé et fonctionne un peu comme une boite noire. L’intérêt est que si la personne qui entretient la machine met du café en grain à la place du café soluble, c’est invisible pour l’utilisateur qui se soucie simplement de mettre ses pièces dans la machine.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Un autre élément important dans la programmation orientée objet que nous allons aborder est l’héritage.
Ah bon ? Les objets aussi peuvent mourir et transmettre leur patrimoine ?
Eh bien c’est presque comme en droit, à part que l’objet ne meurt pas et qu’il n’y pas de taxe sur l’héritage. C’est-à-dire qu’un objet dit « père » peut transmettre certaines de ses caractéristiques à un autre objet dit « fils ».
Pour cela, on pourra définir une relation d’héritage entre eux. S’il y a une relation d’héritage entre un objet père et un objet fils, alors l’objet fils hérite de l’objet père. On dit également que l’objet fils est une spécialisation de l’objet père ou qu’il dérive de l’objet père.
En langage plus courant on peut également dire que l’objet fils est « une sorte » d’objet père.
Des exemples !!
On dit souvent qu’un petit exemple vaut bien un long discours, alors prenons par exemple l’objet « chien » et imaginons ses caractéristiques tirées du monde réel en utilisant l’héritage :
L’objet « chien » est une sorte d’objet « mammifère »
L’objet « mammifère » est une sorte d’objet « animal »
L’objet « animal » est une sorte d’objet « être vivant »
Chaque père est un peu plus général que son fils. Et inversement, chaque fils est un peu plus spécialisé que son père. Avec l’exemple du dessus, un mammifère est un peu plus général qu’un chien, l’être vivant étant encore plus général qu’un mammifère.
Il est possible pour un père d’avoir plusieurs fils, par contre, l’inverse est impossible, un fils ne peut pas avoir plusieurs pères. Et oui, c’est triste mais c’est comme ça, c’est le règne du père célibataire avec plusieurs enfants à charge !
Ainsi, un objet « chat » peut également être un fils de l’objet « mammifère ». Un objet « végétal » peut également être fils de l’objet « être vivant ».
Ce qu’on peut reproduire sur le schéma suivant. Chaque bulle représentant un objet et chaque flèche représente l’héritage entre les objets.
On peut définir une sorte de hiérarchie entre les objets, un peu comme on le ferait avec un arbre généalogique. La différence est qu’un objet héritant d’un autre peut obtenir certains ou tous les comportements de l’objet qu’il spécialise, alors qu’un petit enfant n’hérite pas forcément des yeux bleus de sa mère ou du côté bougon de son grand-père, le hasard de la nature faisant le reste.
Pour bien comprendre cet héritage de comportement, empruntons à nouveau les exemples du monde réel.
L’être vivant peut par exemple faire l’action « vivre ».
Le mammifère possède des yeux.
Le chien, qui est une sorte d’être vivant et une sorte de mammifère, peut également faire l’action « vivre » et aura des yeux.
Le chat qui est une autre sorte d’être vivant peut lui aussi faire l’action « vivre » et aura également des yeux.
On voit bien ici que le chat et le chien héritent des comportements de leurs parents et grands-parents en étant capables de vivre et d’avoir des yeux. Par contre, l’action « aboyer » est spécifique au chien. Ce qui veut dire que ni le chat, ni le dauphin ne seront capables d’aboyer. Il n’y a que dans les dessins animés de Tex Avery que ceci est possible ! Évidemment, il n’y a pas de notion d’héritage entre le chien et le chat et l’action aboyer est définie au niveau du comportement du chien. Ceci implique également que seul un objet qui est une sorte de chien, par exemple l’objet Labrador ou l’objet Chihuahua, pourra hériter du comportement « aboyer », car il y a une relation d’héritage entre eux. Finalement, c'est plutôt logique. :D Rappelons juste avant de terminer ce paragraphe qu’un objet ne peut pas hériter de plusieurs objets. Il ne peut hériter que d’un seul objet. Le C# ne permet pas ce qu’on appelle l’héritage multiple, a contrario d’autres langages comme le C++ par exemple.
Voilà globalement pour la notion d’héritage. Je dis globalement car il y a certaines subtilités que je n’ai pas abordées mais ce n’est pas trop grave, vous verrez dans les chapitres suivants comment le C# utilise la notion d’héritage et ce qu’il y a vraiment besoin de savoir. Ne vous inquiétez pas si certaines notions sont encore un peu floues, vous comprendrez surement mieux grâce à la pratique.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Le mot polymorphisme suggère qu’une chose peut prendre plusieurs formes. Sous ce terme un peu barbare se cachent plusieurs notions de l’orienté objet qui sont souvent sources d’erreurs. Je vais volontairement passer rapidement sur certains points qui ne vont pas nous servir pour me concentrer sur ceux qui sont importants pour ce tutoriel. J’espère que vous ne m’en voudrez pas et que vous m’accorderez quelques dérogations qui pourraient déplaire aux puristes.
En fait, on peut dire qu’une manifestation du polymorphisme est la capacité pour un objet de faire une même action avec différents types d’intervenants. C’est ce qu’on appelle le polymorphisme « ad hoc » ou le polymorphisme « paramétré ». Par exemple, notre objet voiture peut rouler sur la route, rouler sur l’autoroute, rouler sur la terre si elle est équipée de pneus adéquats, rouler au fond de l’eau si elle est amphibie, etc … Concrètement ici, je fais interagir un objet « voiture » avec un objet « autoroute » ou un objet « terre »… par l’action qui consiste à « rouler ». Cela peut paraitre anodin décrit ainsi, mais nous verrons ce que cela implique avec le C#.
Substitution
La substitution est une autre manifestation du polymorphisme. Pas de régime ou de balance dans ce terme-là, il s’agit simplement de la capacité d’un objet fils à redéfinir des caractéristiques ou des actions d’un objet père.
Prenons par exemple un objet mammifère qui sait faire l’action « se déplacer ». Les objets qui dérivent du mammifère peuvent potentiellement avoir à se déplacer d’une manière différente. Par exemple, l’objet homme va se déplacer sur ses deux jambes et donc différemment de l’objet dauphin qui se déplacera grâce à ses nageoires ou bien encore différemment de l’objet « homme accidenté » qui va avoir besoin de béquilles pour s’aider dans son déplacement. Tous ces mammifères sont capables de se déplacer, mais chacun va le faire d’une manière différente. Ceci est donc possible grâce à la substitution qui permet de redéfinir un comportement hérité. Ainsi, chaque fils sera libre de réécrire son propre comportement, si celui de son père ne lui convient pas.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Un autre concept important de la programmation orientée objet est la notion d’interface.
Prenons un exemple dans notre monde réel et connu : les prises de courant. Elles fournissent de l’électricité à 220V avec deux trous et (souvent) une prise de terre. Peu importe ce qu’il y a derrière, du courant alternatif de la centrale du coin, un transformateur, quelqu'un qui pédale,... nous saurons à coup sûr que nous pouvons brancher nos appareils électriques car ces prises s’engagent à nous fournir du courant alternatif avec le branchement adéquat. Elles respectent le contrat ; elles sont « branchables ». Ce dernier terme est un peu barbare et peut faire mal aux oreilles. Mais vous verrez que suffixer des interfaces par un « able » est très courant ( :) ) et permet d’être plus précis sur la sémantique de l’interface. « Able » est également un suffixe qui fonctionne en anglais et les interfaces du framework .NET finissent pour la plupart par « able ».
À noter que les interfaces ne fournissent qu’un contrat, elles ne fournissent pas d’implémentation c'est-à-dire pas de code C#. Les interfaces indiquent que les objets qui choisissent de respecter ce contrat auront forcément telle action ou telle caractéristique mais elles n’indiquent pas comment faire, c'est-à-dire qu’elles n’ont pas de code C# associé. Chaque objet respectant cette interface (on parle d’objet implémentant une interface) sera responsable de coder la fonctionnalité associée au contrat.
Pour manipuler ces prises, nous pourrons utiliser cette interface en disant : « allez hop, tous les branchables, venez par ici, on a besoin de votre courant ». Peu importe que l’objet implémentant cette interface soit une prise murale, une prise reliée à une dynamo ou autre, nous pourrons manipuler ces objets par leur interface et donc brancher nos prises permettant d’alimenter nos appareils.
Contrairement à l’héritage, un objet est capable d’implémenter plusieurs interfaces. Par exemple, une pompe à chaleur peut être « Chauffante » et « Refroidissante ». Notez qu’en français, nous pourrons également utiliser le suffixe « ante ». En anglais, nous aurons plus souvent « able ».
Nous en avons terminé avec la théorie sur les interfaces. Il est fort probable que vous ne saisissiez pas encore tout l’intérêt des interfaces ou ce qu’elles sont exactement. Nous allons y revenir avec des exemples concrets et vous verrez des utilisations des interfaces dans le cadre du framework .NET qui vous éclaireront d'avantage.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons décrit plusieurs concepts de la programmation orientée objet mais nous n’avons pas encore dit à quoi elle allait nous servir.
En fait, on peut dire que la POO est une façon de développer une application qui consiste à représenter (on dit également « modéliser ») une application informatique sous la forme d’objets, ayant des propriétés et pouvant interagir entre eux. La modélisation orientée objet est proche de la réalité ce qui fait qu’il sera relativement facile de modéliser une application de cette façon. De plus, les personnes non-techniques pourront comprendre et éventuellement participer à cette modélisation.
Cette façon de modéliser les choses permet également de découper une grosse application, généralement floue, en une multitude d’objets interagissant entre eux. Cela permet de découper un gros problème en plus petits afin de le résoudre plus facilement.
Utiliser une approche orientée objet améliore également la maintenabilité. Plus le temps passe et plus une application est difficile à maintenir. Il devient difficile de corriger des choses sans tout casser ou d’ajouter des fonctionnalités sans provoquer une régression par ailleurs. L’orienté objet nous aide ici à limiter la casse en proposant une approche où les modifications internes à un objet n’affectent pas tout le reste du code, grâce notamment à l’encapsulation.
Un autre avantage de la POO est la réutilisabilité. Des objets peuvent être réutilisés ou même étendus grâce à l’héritage. C’est le cas par exemple de la bibliothèque de classes du framework .NET que nous avons déjà utilisée. Cette bibliothèque nous fournit par exemple tous les objets permettant de construire des applications graphiques. Pas besoin de réinventer toute la mécanique pour gérer des fenêtres dans une application, le framework .NET sait déjà faire tout ça. Nous avons juste besoin d’utiliser un objet « fenêtre », dans lequel nous pourrons mettre un objet « bouton » et un objet « zone de texte ». Ces objets héritent tous des mêmes comportements, comme le fait d’être cliquable ou sélectionnable, etc. De même, des composants tout faits et prêts à l’emploi peuvent être vendus par des entreprises tierces (système de log, contrôles utilisateurs améliorés, etc …).
Il faut savoir que la POO, c’est beaucoup plus que ça et nous en verrons des subtilités plus loin, mais comprendre ce qu’est un objet est globalement suffisant pour une grande partie du tutoriel.
En résumé
L’approche orientée objet permet de modéliser son application sous la forme d’interactions entre objets.
Les objets ont des propriétés et peuvent faire des actions.
Ils masquent la complexité d'une implémentation grâce à l'encapsulation.
Les objets peuvent hériter de fonctionnalités d'autres objets s'il y a une relation d'héritage entre eux.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ah, enfin un peu de concret et surtout de code. Dans ce chapitre, nous allons appliquer les notions que nous avons vues sur la programmation orientée objet pour continuer notre apprentissage du C#.
Même si vous n'avez pas encore appréhendé exactement où la POO pouvait nous mener, ce n'est pas grave. Les notions s'affineront au fur et à mesure de la lecture du tutoriel. Il est temps pour nous de commencer à créer des objets, à les faire hériter entre eux, etc. Bref, à jouer, grâce à ces concepts, avec le C#.
Vous verrez qu'avec un peu de pratique tout s'éclaircira ; vous saisirez l'intérêt de la POO et comment être efficace avec le C#.
Ça y est, il a fini avec son baratin qui donne mal à la tête ? Pourquoi tout ce blabla sur les objets ?
Parce que tout dans le C# est un objet. Comme déjà dit, une fenêtre Windows est un objet. Une chaîne de caractères est un objet. La liste que nous avons vue plus haut est un objet. Nous avons vu que les objets possédaient des caractéristiques, il s’agit de propriétés. Un objet peut également faire des actions, ce sont des méthodes.
Suivant ce principe, une chaîne de caractères est un objet et possède des propriétés (par exemple sa longueur). De la même façon, il sera possible que les chaînes de caractères fassent des actions (par exemple se mettre en majuscules). Nous allons voir plus bas qu’il est évidemment possible de créer nos propres objets (chat, chien, etc.) et que grâce à eux, nous allons enrichir les types qui sont à notre disposition. Un peu comme nous avons déjà fait avec les énumérations.
Voyons dès à présent comment faire, grâce aux classes.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans le chapitre précédent, nous avons parlé des objets mais nous avons également parlé de la définition de l’objet, de sa structure. Eh bien, c’est exactement ça, une classe.
Nous avons déjà pu voir une classe dans le code que nous avons utilisé précédemment et qui a été généré par Visual C# Express, la classe Program. Nous n’y avons pas fait trop attention, mais voilà à peu près à quoi elle ressemblait :
class Program
{
static void Main(string[] args)
{
}
}
C’est elle qui contenait la méthode spéciale Main() qui sert de point d’entrée à l’application. Nous pouvons découvrir avec des yeux neufs le mot clé class qui comme son nom le suggère permet de définir une classe, c'est-à-dire la structure d’un objet.
Rappelez-vous, les objets peuvent avoir des caractéristiques et faire des actions.
Ici, c’est exactement ce qu’il se passe. Nous avons défini la structure d’un objet Program qui contient une action : la méthode Main(). Vous aurez remarqué au passage que pour définir une classe, nous utilisons à nouveau les accolades permettant de créer un bloc de code qui délimite la classe.
Passons sur cette classe particulière et lançons-nous dans la création d’une classe qui nous servira à créer des objets. Par exemple, une classe Voiture. À noter qu’il est possible de créer une classe à plusieurs endroits dans le code, mais en général, nous utiliserons un nouveau fichier, du même nom que la classe, qui lui sera entièrement dédié. Une règle d’écriture commune à beaucoup de langage de programmation est que chaque fichier doit avoir une seule classe.
Faisons un clic droit sur notre projet pour ajouter une nouvelle classe :
Visual C# express nous ouvre sa fenêtre permettant de faire l’ajout d’un élément en se positionnant sur l’élément Classe. Nous pourrons donner un nom à cette classe : Voiture.
Vous remarquerez que les classes commencent en général par une majuscule. Visual C# Express nous génère le code suivant :
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace MaPremiereApplication
{
class Voiture
{
}
}
Nous retrouvons le mot-clé class suivi du nom de notre classe Voiture et les accolades ouvrantes et fermantes permettant de délimiter notre classe. Notons également que cette classe fait partie de l’espace de nom MaPremièreApplication qui est l’espace de nom par défaut de notre projet. Pour nous simplifier le travail, Visual C# Express nous a également inclus quelques espaces de noms souvent utilisés.
Mais pour l’instant cette classe ne fait pas grand-chose.
Comme cette classe est vide, elle ne possède ni propriétés, ni actions. Nous ne pouvons absolument rien faire avec à part en créer une instance, c'est-à-dire un objet. Cela se fait grâce à l’utilisation du mot-clé new. Nous y reviendrons plus en détail plus tard, mais cela donne :
static void Main(string[] args)
{
Voiture voitureNicolas = new Voiture();
Voiture voitureJeremie = new Voiture();
}
Nous avons créé deux instances de l’objet Voiture et nous les stockons dans les variable voitureNicolas et voitureJeremie.
Si vous vous rappelez bien, nous aurions logiquement dû écrire :
MaPremiereApplication.Voiture voitureNicolas = new MaPremiereApplication.Voiture();
Ou alors positionner le using qui allait bien, permettant d’inclure l’espace de nom MaPremiereApplication.
En fait, ici c’est superflu vu que nous créons les objets depuis la méthode Main() qui fait partie de la classe Program faisant partie du même espace de nom que notre classe.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous venons de créer notre objet Voiture mais nous ne pouvons pas en faire grand-chose. Ce qui est bien dommage. Ça serait bien que notre voiture puisse klaxonner par exemple si nous sommes bloqués dans des embouteillages. Bref, que notre voiture soit capable de faire des actions. Qui dit « action » dit « méthode ».
Nous allons pouvoir définir des méthodes faisant partie de notre objet Voiture. Pour ce faire, il suffit de créer une méthode, comme nous l’avons déjà vu, directement dans le corps de la classe :
class Voiture
{
void Klaxonner()
{
Console.WriteLine("Pouet !");
}
}
Notez quand même l’absence du mot-clé static que nous étions obligés de mettre avant. Je vous expliquerai un peu plus loin pourquoi.
Ce qui fait que si nous voulons faire klaxonner notre voiture, nous aurons juste besoin d’invoquer la méthode Klaxonner() depuis l’objet Voiture, ce qui s’écrit :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Klaxonner();
Cela ressemble beaucoup à ce que nous avons déjà fait. En fait, nous avons déjà utilisé des méthodes sur des objets. Rappelez-vous, nous avons utilisé la méthode Add() permettant d’ajouter une valeur à une liste :
List<int> maListe = new List<int>();
maListe.Add(1);
Comme nous avons un peu plus de notions désormais, nous pouvons remarquer que nous instancions un objet List (plus précisément, une liste d’entier) grâce au mot clé new et que nous invoquons la méthode Add de notre liste pour lui ajouter l’entier 1.
Nous avons fait pareil pour obtenir un nombre aléatoire, dans une écriture un peu plus concise. Nous avions écrit :
int valeurATrouver = new Random().Next(0, 100);
Ce qui peut en fait s’écrire :
Random random = new Random();
int valeurATrouver = random.Next(0, 100);
Nous créons un objet du type Random grâce à new puis nous appelons la méthode Next() qui prend en paramètres les bornes du nombre aléatoire que nous souhaitons obtenir (0 étant inclus et 100 exclu). Puis nous stockons le résultat dans un entier.
Et oui, nous avons manipulé quelques objets sans le savoir …
Revenons à notre embouteillage et compilons le code nous permettant de faire klaxonner notre voiture :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Klaxonner();
Impossible de compiler, le compilateur nous indique l’erreur suivante :
MaPremiereApplication.Voiture.Klaxonner()' est inaccessible en raison de son niveau de protection
Diantre ! Déjà un premier échec dans notre apprentissage de l’objet !
Vous aurez deviné grâce au message d’erreur que la méthode Klaxonner() semble inaccessible. Nous expliquerons un peu plus bas de quoi il s’agit. Pour l’instant, nous allons juste préfixer notre méthode du mot-clé public, comme ceci :
class Voiture
{
public void Klaxonner()
{
Console.WriteLine("Pouet !");
}
}
Nous allons y revenir juste en-dessous, mais le mot-clé public permet d’indiquer que la méthode est accessible depuis n’importe où.
Exécutons notre application et nous obtenons :
Wahou, notre première action d’un objet. :)
Bien sûr, ces méthodes peuvent également avoir des paramètres et renvoyer un résultat. Par exemple :
class Voiture
{
public bool VitesseAutorisee(int vitesse)
{
if (vitesse > 90)
return false;
else
return true;
}
}
Cette méthode accepte une vitesse en paramètre et si elle est supérieure à 90, alors la vitesse n’est pas autorisée. Cette méthode pourrait également s’écrire :
class Voiture
{
public bool VitesseAutorisee(int vitesse)
{
return vitesse <= 90;
}
}
En effet, nous souhaitons renvoyer faux si la vitesse est supérieure à 90 et vrai si la vitesse est inférieure ou égale.
Donc en fait, nous souhaitons renvoyer la valeur du résultat de la comparaison d’infériorité ou d’égalité de la vitesse à 90, c'est-à-dire :
class Voiture
{
public bool VitesseAutorisee(int vitesse)
{
bool estVitesseAutorisee = vitesse <= 90;
return estVitesseAutorisee;
}
}
Ce que nous pouvons écrire finalement en une seule ligne comme précédemment.
Il est bien sûr possible d’avoir plusieurs méthodes dans une même classe et elles peuvent s’appeler entre elles, par exemple :
class Voiture
{
public bool VitesseAutorisee(int vitesse)
{
return vitesse <= 90;
}
public void Klaxonner()
{
if (!VitesseAutorisee(180))
Console.WriteLine("Pouet !");
}
}
Quitte à rouler à une vitesse non autorisée, autant faire du bruit !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ok, le mot-clé public nous a bien sauvé la vie, mais… qu’est-ce donc ?
En fait, je l’ai rapidement évoqué et nous nous sommes bien rendu compte que sans ce mot-clé, c'est impossible de compiler car la méthode n’est pas accessible.
Le mot-clé public sert à indiquer que notre méthode peut être accessible depuis d’autres classes ; en l’occurrence dans notre exemple depuis la classe Program. C’est-à-dire que sans ce mot-clé, il est impossible à d’autres objets d’utiliser cette méthode.
Pour faire en sorte qu’une méthode soit inaccessible, nous pouvons utiliser le mot-clé private. Ce mot-clé permet d’avoir une méthode qui n’est accessible que depuis la classe dans laquelle elle est définie. Prenons l’exemple suivant :
class Voiture
{
public bool Demarrer()
{
if (ClesSurLeContact())
{
DemarrerLeMoteur();
return true;
}
return false;
}
public void SortirDeLaVoiture()
{
if (ClesSurLeContact())
PrevenirLUtilisateur();
}
private bool ClesSurLeContact()
{
// faire quelque chose pour vérifier
return true;
}
private void DemarrerLeMoteur()
{
// faire quelque chose pour démarrer le moteur
}
private void PrevenirLUtilisateur()
{
Console.WriteLine("Bip bip bip");
}
}
Ici seules les méthodes Demarrer() et SortirDeLaVoiture() sont utilisables depuis une autre classe, c'est-à-dire que ce sont les seules méthodes que nous pourrons invoquer, car elles sont publiques. Les autres méthodes sont privées à la classe et ne pourront être utilisées qu’à l’intérieur de la classe elle-même. Les autres classes n’ont pas besoin de savoir comment démarrer le moteur ou comment vérifier que les clés sont sur le contact, elles n’ont besoin que de pouvoir démarrer ou sortir de la voiture. Les méthodes privées sont exclusivement réservées à l’usage interne de la classe.
Il existe d’autres indicateurs de visibilité que nous allons rapidement décrire :
Visibilité
Description
public
Accès non restreint
protected
Accès depuis la même classe ou depuis une classe dérivée
private
Accès uniquement depuis la même classe
internal
Accès restreint à la même assembly
protected internal
Accès restreint à la même assembly ou depuis une classe dérivée
Les visibilités qui vont le plus vous servir sont représentées par les mots-clés public et private. Nous verrons que le mot-clé protected va servir un peu plus tard quand nous parlerons d’héritage. Notez qu’internal pourra être utilisé une fois que nous aurons bien maitrisé toutes les notions.
Ces mots-clés sont utilisables avec beaucoup d’autres concepts. Nous avons utilisé les méthodes pour les illustrer mais ceci est également valable pour les classes ou les propriétés que nous allons découvrir juste après.
Oui mais, au début, nous avons pu déclarer une classe sans préciser de visibilité… et pareil pour la première méthode qui ne compilait pas… c’est normal ?
Oui, il existe des visibilités par défaut suivant les types déclarés. Vous aurez compris par exemple que la visibilité par défaut d’une méthode est privée si l’on ne spécifie pas le mot clé.
Pour éviter tout risque et toute ambigüité, il est recommandé de toujours indiquer la visibilité. Ce que nous ferons désormais dans ce tutoriel, maintenant que nous savons de quoi il s’agit.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Des objets c’est bien. Des actions sur ces objets, c’est encore mieux. Il nous manque encore les caractéristiques des objets. C’est là qu’interviennent les propriétés.
Sans le savoir, vous avez déjà utilisé des propriétés, par exemple dans le code suivant :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
for (int i = 0; i < jours.Length; i++)
{
Console.WriteLine(jours[i]);
}
Dans la boucle, nous utilisons jours.Length. Nous utilisons en fait la propriété Length du tableau « jours », un tableau étant bien sûr un objet.
Nous avons pu utiliser d’autres propriétés, par exemple dans l’instruction suivante :
List<string> jours = new List<string> { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
for (int i = 0; i < jours.Count; i++)
{
Console.WriteLine(jours[i]);
}
Ici, Count est la propriété de la liste « jours ».
De la même façon, nous avons la possibilité de créer des propriétés sur nos classes pour permettre d’ajouter des caractéristiques à nos objets.
Par exemple, nous pouvons rajouter les propriétés suivantes à notre voiture : une couleur, une marque, une vitesse. Il y a plusieurs façons de rajouter des caractéristiques à un objet. La première est d’utiliser des variables membres.
Les variables membres :
Ici en fait, un objet peut avoir une caractéristique sous la forme d’une variable publique qui fait partie de la classe. Pour ce faire, il suffit de définir simplement la variable à l’intérieur des blocs de code délimitant la classe et de lui donner la visibilité public.
Rajoutons par exemple une chaine de caractères permettant de stocker la couleur de la voiture :
public class Voiture
{
public string Couleur;
}
Notez que j’ai rajouté les visibilités pour la classe et pour la variable.
Grâce à ce code, la chaine de caractères Couleur est désormais une caractéristique de la classe Voiture. Nous pourrons l’utiliser en faisant suivre notre objet de l’opérateur « . » suivi du nom de la variable. Ce qui donne :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Couleur = "rouge";
Voiture voitureJeremie = new Voiture();
voitureJeremie.Couleur = "verte";
Cela ressemble beaucoup à ce que nous avons déjà fait. Nous utilisons le « . » pour accéder aux propriétés d’un objet. Comme d’habitude, les variables vont pouvoir stocker des valeurs. Ainsi, nous pourrons avoir une voiture rouge pour Nicolas et une voiture verte pour Jérémie.
Les propriétés :
Les propriétés sont en fait des variables évoluées. Elles sont à mi-chemin entre une variable et une méthode.
Prenons cet exemple :
public class Voiture
{
private int vitessePrivee;
public int Vitesse
{
get
{
return vitessePrivee;
}
set
{
vitessePrivee = value;
}
}
}
Nous pouvons voir que nous définissons dans un premier temps une variable privée, « vitessePrivee » de type entier. Comme prévu, cette variable est masquée pour les utilisateurs d’objets Voiture. Ainsi, le code suivant :
Voiture voitureNicolas = new Voiture();
voitureNicolas.vitessePrivee = 50;
provoquera l’erreur de compilation désormais bien connue :
MaPremiereApplication.Voiture.vitessePrivee' est inaccessible en raison de son niveau de protection
Par contre, nous en avons profité pour définir la propriété Vitesse, de type int. Pour ceci, nous avons défini une partie de la propriété avec le mot clé get suivi d’un return vitessePrivee. Et juste en dessous, nous avons utilisé le mot clé set, suivi de vitessePrivee = value.
Ce que nous avons fait, c’est définir la possibilité de lire la propriété grâce au mot clé get. Ici, la lecture de la propriété nous renvoie la valeur de la variable privée. De la même façon, nous avons défini la possibilité d’affecter une valeur à la propriété en utilisant le mot clé set et en affectant la valeur à la variable privée.
Les blocs de code délimités par get et set se comportent un peu comme des méthodes, elles ont un corps qui est délimité par des accolades et dans le cas du get, elle doit renvoyer une valeur du même type que la propriété.
À noter que dans le cas du set, « value » est un mot clé qui permet de dire : « la valeur que nous avons affectée à la propriété ».
Prenons l’exemple suivant :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Vitesse = 50;
Console.WriteLine(voitureNicolas.Vitesse);
La première instruction instancie bien sûr une voiture.
La deuxième instruction consiste à appeler le bloc de code set de Vitesse qui met la valeur 50 dans la pseudo-variable value qui est stockée ensuite dans la variable privée.
Lorsque nous appelons la troisième instruction, nous lisons la valeur de la propriété et pour ce faire, nous passons par le get qui nous renvoie la valeur de la variable privée.
Ok, c’est super, mais dans ce cas, pourquoi passer par une propriété et pas par une variable ? Même s'il parait que les variables ne doivent jamais être publiques …
Eh bien parce que dans ce cas-là, la propriété peut faire un peu plus que simplement renvoyer une valeur. Et aussi parce que nous masquons la structure interne de notre classe à ceux qui veulent l’utiliser. Nous pourrions très bien envisager d’aller lire la vitesse dans les structures internes du moteur, ou en faisant un calcul poussé par rapport au coefficient du vent et de l’âge du capitaine (ou plus vraisemblablement en allant lire la valeur en base de données). Et ici, nous pouvons tirer parti de la puissance des propriétés pour masquer tout ça à l’appelant qui lui n’a besoin que d’une vitesse.
Par exemple :
private int vitessePrivee;
public int Vitesse
{
get
{
int v = vitesseDesRoues * rayon * coefficient; // ce calcul est complètement farfelu !
MettreAJourLeCompteur();
AdapterLaVitesseDesEssuieGlaces();
return v;
}
set
{
// faire la mise à jour des variables internes
MettreAJourLeCompteur();
AdapterLaVitesseDesEssuieGlaces();
}
}
En faisant tout ça dans le bloc de code get, nous masquons les rouages de notre classe à l’utilisateur. Lui, il n’a besoin que d’obtenir la vitesse, sans s’encombrer du compteur ou des essuie-glaces.
Bien sûr, la même logique peut s’adapter au bloc de code qui permet d’affecter une valeur à la propriété, set.
Il est également possible de rendre une propriété en lecture seule, c’est-à-dire non modifiable par les autres objets. Il pourra par exemple sembler bizarre de positionner une valeur à la vitesse alors qu’en fait, pour mettre à jour la vitesse, il faut appeler la méthode AppuyerPedale(double forceAppui).
Pour empêcher les autres objets de pouvoir directement mettre à jour la propriété Vitesse, il suffit de ne pas déclarer le bloc de code set et de ne garder qu’un get. Par exemple :
public class Voiture
{
private int vitessePrivee;
public int Vitesse
{
get
{
// faire des calculs ...
return vitessePrivee;
}
}
}
Ce qui fait que si nous tentons d’affecter une valeur à la propriété Vitesse depuis une autre classe, par exemple :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Vitesse = 50;
Nous aurons l’erreur de compilation suivante :
La propriété ou l'indexeur 'MaPremiereApplication.Voiture.Vitesse' ne peut pas être assigné -- il est en lecture seule
Le compilateur nous indique donc très justement qu’il est impossible de faire cette affectation car la propriété est en lecture seule. Il devient donc impossible pour un utilisateur de cette classe de modifier la vitesse de cette façon.
De même, il est possible de définir une propriété pour qu’elle soit accessible en écriture seule. Il suffit de définir uniquement le bloc de code set :
private double acceleration;
public double Acceleration
{
set
{
acceleration = value;
}
}
Ainsi, si nous tentons d’utiliser la propriété en lecture, avec par exemple :
Console.WriteLine(voitureNicolas.Acceleration);
Nous aurons l’erreur de compilation attendue :
La propriété ou l'indexeur 'MaPremiereApplication.Voiture.Acceleration' ne peut pas être utilisé dans ce contexte, car il lui manque l'accesseur get
Ce bridage d’accès à des propriétés prend tout son sens quand nous souhaitons exposer nos objets à d’autres consommateurs qui n’ont aucun intérêt à connaitre la structure interne de notre classe. C’est un des principes de l’encapsulation.
Les propriétés auto-implémentées :
Les propriétés auto-implémentées sont une fonctionnalité que nous allons beaucoup utiliser. Il s’agit de la définition d’une propriété de manière très simplifiée qui va nous servir dans la grande majorité des cas où nous aurons besoin d’écrire des propriétés. Dans ce tutoriel, nous l’utiliserons très souvent.
Ainsi, le code suivant que nous avons déjà vu :
private int vitesse;
public int Vitesse
{
get
{
return vitesse;
}
set
{
vitesse = value;
}
}
est un cas très fréquent d’utilisation de propriétés. Nous exposons ici une variable privée à travers les propriétés get et set. L’écriture du dessus est équivalente à la suivante :
public int Vitesse { get; set; }
Dans ce cas, le compilateur fait le boulot lui-même, il génère (dans le code compilé) une variable membre qui va servir à stocker la valeur de la propriété.
C’est exactement pareil, sauf que cela nous simplifie grandement l’écriture.
En plus, nous pouvons encore accélérer son écriture en utilisant ce qu’on appelle des « snippets » qui sont des extraits de code. Pour les utiliser, il suffit de commencer à écrire un mot et Visual C# nous complète le reste. Un peu comme la complétion automatique sauf que cela fonctionne pour des bouts de code très répétitifs et très classiques à écrire.
Commencez par exemple à taper « prop », Visual C# nous propose plusieurs extraits de code :
Appuyez sur tab ou entrée pour sélectionner cet extrait de code et appuyez ensuite sur tab pour que Visual C# génère l’extrait de code correspondant à la propriété auto-implémentée. Vous aurez :
Ici, int est surligné et vous pouvez, si vous le souhaitez, changer le type de la propriété, par exemple string. Appuyez à nouveau sur tab et Visual C# surligne le nom de la propriété, que vous pouvez à nouveau changer. Appuyez enfin sur entrée pour terminer la saisie et vous aurez une belle propriété auto-implémentée :
Vous avez pu remarquer qu’en commençant à taper « prop », Visual C# express vous a proposé d’autres extraits de code, par exemple « propfull » qui va générer la propriété complète telle qu’on l’a vue un peu plus haut.
D’autres extraits de code existent, comme « propg » qui permet de définir une propriété en lecture seule.
En effet, comme au chapitre précédent, il est possible de définir des propriétés auto-implémentées en lecture seule ou en écriture seule avec une écriture simplifiée. Dans le cas des propriétés auto-implémentées, il y a cependant une subtilité.
Pour avoir de la lecture seule, nous devons indiquer que l'affectation est privée, comme on peut le voir en utilisant l’extrait de code « propg ». Visual C# express nous génère le bout de code suivant :
public int Vitesse { get; private set; }
En positionnant une propriété d’écriture en privée, Visual C# express autorise la classe Voiture à modifier la valeur de Vitesse, que ce soit par une méthode ou par une propriété.
A noter que si nous n'avions pas mis private set et que nous avions simplement supprimé le set, alors la compilation aurait été impossible. En effet, il s’avère difficile d’exploiter une propriété auto-implémentée en lecture alors que nous n’avons pas la possibilité de lui donner une valeur. Ou inversement.
Alors, pourquoi nous avoir parlé de la possibilité de complètement supprimer la lecture ou l’écriture ? Ce n’est pas plus intéressant de toujours mettre la propriété en private ?
Si c’est une propriété auto-implémentée, évidemment que si. Par contre, si nous n’utilisons pas une propriété auto-implémentée et que nous utilisons une variable membre pour sauvegarder la valeur de la propriété, nous pourrons éventuellement modifier ou lire la valeur de la variable à partir d’une méthode ou d’une autre propriété.
Bref, maintenant que vous connaissez les deux syntaxes, vous pourrez utiliser la plus adaptée à votre besoin.
Voilà pour les propriétés.
À noter que quand nous avons beaucoup de propriétés à initialiser sur un objet, nous pouvons utiliser une syntaxe plus concise. Par exemple, les instructions suivantes :
Maintenant que nous avons bien vu comment définir des objets, il est temps de savoir les utiliser.
Nous allons voir dans ce chapitre quelles sont les subtilités de l'instanciation des objets. Vous verrez notamment ce qu'est un constructeur et qu'on peut avoir des valeurs nulles pour des objets.
N'hésitez pas à jouer avec tous ces concepts, il est important d'être à l'aise avec les bases pour pouvoir être efficace avec les concepts avancés.
Le constructeur est une méthode particulière de l’objet qui permet de faire des choses au moment de la création d’un objet, c’est-à-dire au moment où nous utilisons le mot-clé new. Il est en général utilisé pour initialiser des valeurs par défaut d’un objet. Par exemple, si nous voulons que lors de la création d’une voiture, elle ait automatiquement une vitesse, nous pouvons faire :
public class Voiture
{
public int Vitesse { get; set; }
public Voiture()
{
Vitesse = 5;
}
}
Le constructeur est en fait une méthode spéciale qui a le même nom que la classe et qui ne possède pas de type de retour. Elle est appelée lors de la création de l’objet, avec new.
Pour illustrer le comportement du constructeur, ajoutons une méthode Rouler à notre classe, de cette façon :
public class Voiture
{
public int Vitesse { get; set; }
public Voiture()
{
Vitesse = 5;
}
public void Rouler()
{
Console.WriteLine("Je roule à " + Vitesse + " km/h");
}
}
Que nous pourrons appeler ainsi :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Rouler();
voitureNicolas.Vitesse = 50;
voitureNicolas.Rouler();
Au moment de l’instanciation de l’objet avec new, la vitesse va être égale à 5. Nous faisons rouler la voiture. Puis nous changeons la vitesse pour la passer à 50 et nous faisons à nouveau rouler la voiture. Nous aurons :
Le constructeur est la première « méthode » à être appelée lors de la création d’un objet. C’est l’endroit approprié pour faire des initialisations, ou pour charger des valeurs, etc.
Le constructeur que nous avons vu est ce qu’on appelle le constructeur par défaut, car il ne possède pas de paramètres. Il est possible de passer des paramètres à un constructeur, pour initialiser des variables de notre classe avec des valeurs. Pour ce faire, nous devons déclarer un constructeur avec un paramètre ; par exemple :
public class Voiture
{
public int Vitesse { get; set; }
public Voiture()
{
Vitesse = 5;
}
public Voiture(int vitesse)
{
Vitesse = vitesse;
}
public void Rouler()
{
Console.WriteLine("Je roule à " + Vitesse + " km/h");
}
}
Ainsi, nous pourrons créer un objet voiture en lui précisant une vitesse par défaut de cette façon :
Voiture voitureNicolas = new Voiture(20);
Après ceci, la variable voitureNicolas aura une vitesse de 20.
Bien sûr, nous pourrions faire la même chose sans utiliser de constructeur, en affectant une valeur à la propriété après avoir instancié l’objet. Ce qui fonctionnerait tout à fait. Sauf qu’il ne se passe pas exactement la même chose. Le constructeur est vraiment appelé en premier, dès qu’on utilise new pour créer un objet. Les propriétés sont affectées fatalement après, donc tout dépend de ce que l’on veut faire.
Donc, oui, on pourrait affecter une valeur à des propriétés pour faire ce genre d’initialisation juste après avoir instancié notre objet mais cela nous oblige à écrire une instruction supplémentaire qui pourrait ne pas paraitre évidente ou obligatoire.
Une chose est sûre avec le constructeur, c’est que nous sommes obligés d’y passer et ceci, peu importe la façon dont on utilise la classe. L’initialisation devient donc obligatoire, on évite le risque qu’une propriété soit nulle.
À noter qu’il est possible de cumuler les constructeurs tant qu’ils ont chacun des paramètres différents. Dans notre exemple, nous pourrons donc créer des voitures de deux façons différentes :
Voiture voitureNicolas = new Voiture(); // vitesse vaut 5
Voiture voitureJeremie = new Voiture(20); // vitesse vaut 20
Il est aussi possible de ne pas définir de constructeur par défaut et d’avoir uniquement un constructeur possédant des paramètres. Dans ce cas, il devient impossible d’instancier un objet sans lui passer de paramètres.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous allons revenir à présent sur l’instanciation d’un objet. Comme nous venons de le voir, nous utilisons le mot clé new pour créer une instance d’un objet. C’est lui qui permet la création d’un objet. Il appelle le constructeur correspondant. Si aucun constructeur n’existe, il ne se passera rien de plus qu’une création de base. Par exemple :
Voiture voitureNicolas = new Voiture();
Pour rentrer un peu dans la technique, au moment de l’instanciation d’un objet, l’opérateur new crée l’objet et le met à une place disponible en mémoire. Cette adresse mémoire est conservée dans la variable voitureNicolas. On dit que voitureNicolas contient une référence vers l’objet. Nous verrons un peu plus tard ce que cela implique.
Comme pour les types que nous avons vus plus haut, nous sommes obligés d’initialiser un objet avant de l’utiliser. Sinon, Visual C# Express nous génèrera une erreur de compilation. Par exemple, les instructions suivantes :
Utilisation d'une variable locale non assignée 'voitureNicolas'
En effet, Visual C# Express est assez intelligent pour se rendre compte que l’on va essayer d’accéder à un objet qui n’a pas été initialisé.
Il faut toujours initialiser une variable avant de pouvoir l’utiliser. Comme pour les types précédents, il est possible de dissocier la déclaration d’un objet de son instanciation, en écrivant les instructions sur plusieurs lignes, par exemple :
Voiture voitureNicolas;
// des choses
voitureNicolas = new Voiture();
ceci est possible tant que nous n’utilisons pas la variable voitureNicolas avant de l’avoir instanciée.
Les objets peuvent également avoir une valeur nulle. Ceci est différent de l’absence d’initialisation car la variable est bien initialisée et sa valeur vaut « nul ». Ceci est possible grâce à l’emploi du mot-clé null.
Voiture voitureNicolas = null;
Attention, il est par contre impossible d’accéder à un objet qui vaut null. Eh oui, comment voulez-vous vous asseoir sur une chaise qui n’existe pas ? Eh bien vous vous retrouverez avec les fesses par terre, personne ne vous a indiqué que la chaise n’existait pas. ;)
C’est pareil pour notre application, si nous tentons d’utiliser une voiture qui n’existe pas, nous aurons droit à un beau plantage.
vous n’aurez pas d’erreur à la compilation, par contre vous aurez :
Comme nous l’avons déjà vu, le programme nous affiche une exception ; nous avons dit que c’était simplement une erreur qui faisait planter notre programme. Pas bien ! Surtout que cela se passe au moment de l’exécution. Nous perdons toute crédibilité !
Ici, le programme nous dit que la référence d’un objet n’est pas définie à une instance d’un objet. Concrètement, cela veut dire que nous essayons de travailler sur un objet null.
Pour éviter ce genre d’erreur à l’exécution, il faut impérativement instancier ses objets, en utilisant l’opérateur new, comme nous l’avons déjà vu. Il n’est cependant pas toujours pertinent d’instancier un objet dont on pourrait ne pas avoir besoin. Le C# nous offre donc la possibilité de tester la nullité d’un objet. Il suffit d’utiliser l’opérateur de comparaison « == » en comparant un objet au mot-clé null, par exemple :
string prenom = "Nicolas";
Voiture voiture = null;
if (prenom == "Nicolas")
voiture = new Voiture { Vitesse = 50 };
if (voiture == null)
{
Console.WriteLine("Vous n'avez pas de voiture");
}
else
{
voiture.Rouler();
}
Ainsi, seul Nicolas possédera une voiture et le test de nullité sur l’objet permet d’éviter une erreur d’exécution si le prénom est différent.
Maintenant que vous connaissez le mot-clé null et que vous savez qu’un objet peut prendre une valeur nulle, nous allons revenir sur un point que j’ai rapidement abordé auparavant. Je ne sais pas si vous vous en rappelez, mais lors de l’étude des opérateurs logiques j’ai parlé du fait que l’opérateur OU ( || ) évaluait la première condition et si elle était vraie alors il n’évaluait pas la suivante, considérant que de toutes façons, le résultat allait être vrai.
Ce détail prend toute son importance dans le cas suivant :
if (voiture == null || voiture.Couleur == "Bleue")
{
// faire quelque chose
}
Dans ce cas, si la voiture est effectivement nulle, alors le fait d’évaluer la propriété Couleur de la voiture devrait renvoyer une erreur. Heureusement, le C# avait prévu le coup, si la première condition est vraie alors la seconde ne sera pas évaluée, ce qui évitera l’erreur. Ainsi, nous sommes sûrs de n’avoir aucune voiture bleue.
Il est par contre évident qu’une telle condition utilisant l’opérateur ET (&&) est une hérésie car pour que la condition soit vraie, le C# a besoin d’évaluer les deux opérandes. Et donc si la voiture est nulle, l’utilisation d’une propriété sur une valeur nulle renverra une erreur.
Notons également que lorsque nous utilisons l’opérateur ET (&&) si la première opérande est fausse, alors de la même façon, il n’évalue pas la seconde, car pour que la condition soit vraie il faut que les deux le soient. Ce qui fait qu’il est également possible d’écrire ce code :
if (voiture != null && voiture.Couleur == "Rouge")
{
// faire autre chose
}
qui ne provoquera pas d’erreur à l’exécution, même si voiture vaut null car dans ce cas, le fait que le premier test soit faux évitera le test de l’autre partie de l’expression.
Vous verrez que vous aurez l’occasion d’utiliser le mot-clé null régulièrement.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Lorsque nous écrivons le code d’une classe, le mot-clé this représente l’objet dans lequel nous nous trouvons. Il permet de clarifier éventuellement le code, mais Il est généralement facultatif. Ainsi, pour accéder à une variable de la classe ou éventuellement une méthode, nous pouvons les préfixer par « this. ». Par exemple, nous pourrions écrire notre classe de cette façon :
public class Voiture
{
public int Vitesse { get; set; }
public string Couleur { get; set; }
public Voiture()
{
this.Vitesse = 5;
}
public void Rouler()
{
Console.WriteLine("Je roule à " + this.Vitesse + " km/h");
}
public void Accelerer(int acceleration)
{
this.Vitesse += acceleration;
this.Rouler();
}
}
Ici, dans le constructeur, nous utilisons le mot-clé this pour accéder à la propriété Vitesse. C’est la même chose dans la méthode Rouler. De la même façon, on peut utiliser this.Rouler() pour appeler la méthode Rouler depuis la méthode Accelerer().
C’est une façon pour la classe de dire : « Regardez, avec this, c’est "ma variable à moi" ».
Notez bien sûr que sans le mot-clé this, notre classe compilera quand même et sera tout à fait fonctionnelle. Ce mot-clé est facultatif mais il peut aider à bien faire la différence entre ce qui appartient à la classe et ce qui fait partie des paramètres des méthodes ou d’autres objets utilisés.
Suivant les personnes, le mot-clé this est soit systématiquement utilisé, soit jamais. Je fais plutôt partie des personnes qui ne l’utilisent jamais. Il arrive par contre certaines situations où il est absolument indispensable, comme celle-ci, mais en général, j’essaie d’éviter ce genre de construction :
public void ChangerVitesse(int Vitesse)
{
this.Vitesse = Vitesse;
}
Vous remarquerez que le paramètre de la méthode ChangerVitesse() et la propriété ou variable membre de la classe ont exactement le même nom. Ceci est possible ici mais source d’erreurs, les variables ayant des portées différentes. Il s’avère que dans ce cas, le mot-clé this est indispensable. On pourra donc éviter l’ambigüité en préfixant la propriété membre avec le mot-clé this.
Je recommande plutôt de changer le nom du paramètre, quitte à utiliser une minuscule, ce qui augmentera la lisibilité et évitera des erreurs potentielles.
En général, des conventions de nommage pourront nous éviter de nous retrouver dans ce genre de situation.
Ça y est, nous savons instancier et utiliser des objets.
Savoir créer et utiliser ses propres objets est très important dans un programme orienté objet.
Vous allez également avoir besoin très régulièrement d’utiliser des objets tout fait, comme ceux venant de la bibliothèque de classe du framework .NET. Nous comprenons d’ailleurs mieux pourquoi elle s’appelle « bibliothèque de classes ». Il s’agit bien d’un ensemble de classes utilisables dans notre application et nous pourrons instancier les objets relatifs à ces classes pour nos besoins. Comme ce que nous avions déjà fait auparavant sans trop le savoir, avec l’objet Random par exemple…
N’hésitez pas à relire ce chapitre ainsi que le précédent si vous n’avez pas parfaitement compris toutes les subtilités de la création d’objet. C’est un point important du tutoriel.
Cependant, nous n’avons pas encore tout vu sur le C# et la POO. Alors ne nous arrêtons pas en si bon chemin et attaquons des concepts un peu plus avancés.
En résumé
Les classes possèdent une méthode particulière, appelée à l'instanciation de l'objet : le constructeur.
Une instance d'une classe peut être initialisée avec une valeur nulle grâce au mot-clé null.
Le mot-clé this représente l'objet en cours de la classe.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre, vous allez vous immerger un peu plus dans les subtilités de la POO en utilisant le C#. Il est temps un peu de tourmenter nos objets et de voir ce qu'ils ont dans le ventre. Ainsi, nous allons voir comment les objets héritent les uns des autres ou comment fonctionnent les différents polymorphismes.
Nous allons également voir comment tous ces concepts se retrouvent dans le quotidien d'un développeur C#.
Des types, des objets, type valeur et type référence
Ok, je sais maintenant créer des objets, mais je me rappelle qu’au début du tutoriel, nous avons manipulé des int et des string et que tu as appelé ça des « types » ; et après, tu nous dis que tout est objet … Tu serais pas en train de raconter n’importe quoi ?
Eh bien non, ô perspicace lecteur !
Précisons un peu maintenant que vous avez de meilleures connaissances. J’ai bien dit que tout était objet, je le maintiens, même sous la torture. :-° C'est-à-dire que même les types simples comme les entiers int ou les chaînes de caractères sont des objets.
J’en veux pour preuve ce simple exemple :
int a = 10;
string chaine = a.ToString();
chaine = "abc" + chaine;
string chaineEnMajuscule = chaine.ToUpper();
Console.WriteLine(chaineEnMajuscule);
Console.WriteLine(chaineEnMajuscule.Length);
La variable a est un entier. Nous appelons la méthode ToString() sur cet entier. Même si nous n’avons pas encore vu à quoi elle servait, nous pouvons supposer qu’elle effectue une action qui consiste à transformer l’entier en chaîne de caractères. Nous concaténons ensuite la chaîne abc à cette chaîne et nous effectuons une action qui, à travers la méthode ToUpper(), met la chaine en majuscule. Enfin, la méthode Console.WriteLine nous affiche « ABC10 » puis nous affiche la propriété Length de la chaîne de caractères qui correspond bien sûr à sa taille.
Pour créer une chaîne de caractères, nous utilisons le mot-clé string. Sachez que ce mot-clé est équivalent à la classe String (notez la différence de casse). En créant une chaîne de caractères, nous avons instancié un objet défini par la classe String.
Mais alors, pourquoi utiliser string et non pas String ?
En fait, le mot-clé string est ce qu’on appelle un alias de la classe String qui se situe dans l’espace de nom System. De même, le mot-clé int est un alias de la structure Int32 qui se situe également dans l’espace de nom System (nous verrons un peu plus loin ce qu'est vraiment une structure).
Ce qui fait que les instructions suivantes :
int a = 10;
string chaine = "abc";
sont équivalentes à celles-ci :
System.Int32 a = 10;
System.String chaine = "abc";
Cependant, les entiers, les booléens et autres types « simples » sont ce qu’on appelle des types intégrés. Et même si ce sont des objets à part entière (méthodes, propriétés,… ), ils ont des particularités, notamment dans la façon dont ils sont gérés par le framework .NET. On les appelle des types valeur, car les variables de ce type possèdent la vraie valeur de ce qu’on leur affecte a contrario des classes qui sont des types référence dont les variables possèdent simplement un lien vers un objet en mémoire.
Par exemple :
int entier = 5;
Ici, la variable contient vraiment l’entier 5. Alors que pour l’instanciation suivante :
Voiture voitureNicolas = new Voiture();
La variable voitureNicolas contient une référence vers l’objet en mémoire.
On peut imaginer que le type référence est un peu comme si on disait que ma maison se situe « 9 rue des bois ». L’adresse a été écrite sur un bout de papier et référence ma maison qui ne se situe bien sûr pas au même endroit que le bout de papier. Si je veux vraiment voir l’objet maison, il va falloir que j’aille voir où c’est indiqué sur le bout de papier. C’est ce que fait le type référence, il va voir en mémoire ce qu’il y a vraiment dans l’objet.
Alors que le type valeur pourrait ressembler à un billet de banque par exemple. Je peux me balader avec, c’est marqué 500€ dessus (oui, je suis riche !) et je peux payer directement avec sans que le fait de donner le billet implique d’aller chercher le contenu à la banque.
Le type valeur contient la vraie valeur qui en général est assez petite et facile à stocker.
Le type référence ne contient qu’un lien vers un plus gros objet stocké ailleurs.
Cette manière différente de gérer les types et les objets implique plusieurs choses. Dans la mesure où les types valeur possèdent vraiment la valeur de ce qu’on y stocke, une copie de la valeur est effectuée à chaque fois que l’on fait une affectation. Cela est possible car ces types sont relativement petits et optimisés. Cela s’avère impossible pour un objet qui est trop gros et trop complexe. C’est un peu compliqué de copier toute ma maison alors que c’est un peu plus simple de recopier ce qu’il y a sur le bout de papier :) .
Ainsi, l’exemple suivant :
int a = 5;
int b = a;
b = 6;
Console.WriteLine(a);
Console.WriteLine(b);
affichera les valeurs 5 puis 6. Ce qui est le résultat que l’on attend.
En effet, la variable « a » a été initialisée à 5.
On a ensuite affecté « a » à « b ». La valeur 5 s’est copiée (dupliquée) dans la variable « b ».
Quoi ? Nous indiquons que la voiture de Nicolas est bleue. Puis nous disons que celle de Jérémie est verte et quand on demande d’afficher la couleur des deux voitures, on nous dit qu’elles sont vertes toutes les deux alors qu’on croyait que celle de Nicolas était bleue ? Tout à l’heure, le fait de changer b n’avait pas changé la valeur de a …
Eh oui, ceci illustre le fait que les classes (comme Voiture) sont des types référence et ne possèdent qu’une référence vers une instance de Voiture. Quand nous affectons voitureNicolas à voitureJeremie, nous disons en fait que la voiture de Jérémie référence la même chose que celle de Nicolas. Concrètement, le C# copie la référence de l'objet Voiture qui est contenue dans la variable voitureNicolas dans la variable voitureJeremie. Ce sont donc deux variables différentes qui possèdent tous les deux une référence vers l'objet Voiture, qui est la voiture de Nicolas. C'est-à-dire que les deux variables référencent le même objet. Ainsi, la modification des propriétés de l’un affectera forcément l’autre.
Inattendu au premier abord, mais finalement, c’est très logique. Comprendre cette différence entre les types valeur et les types référence est important, nous verrons dans les chapitres suivants quels sont les autres impacts de cette différence. À noter également qu’il est impossible de dériver d’un type intégré alors que c’est possible de dériver facilement d’une classe.
D’ailleurs, si nous parlions un peu d’héritage ?
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu pour l’instant la théorie de l’héritage. Que les objets chiens héritaient des comportements des objets Animaux, que les labradors héritaient des comportements des chiens, etc.
Passons maintenant à la pratique et créons une classe Animal et une classe Chien qui en hérite. Nous allons créer des classes relativement courtes et nous nous limiterons dans le nombre d’actions ou de propriétés de celles-ci. Par exemple, nous pourrions imaginer que la classe Animal possède une propriété NombreDePattes qui est un entier et une méthode Respirer qui affiche le détail de l’action. Ce qui donne :
public class Animal
{
public int NombreDePattes { get; set; }
public void Respirer()
{
Console.WriteLine("Je respire");
}
}
La classe Chien dérive de la classe Animal et peut donc hériter de certains de ses comportements. En l’occurrence, la classe Chien héritera de tout ce qui est public ou protégé, identifiés comme vous le savez désormais par les mots clés public et protected. Le chien sait également faire quelque chose qui lui est propre, à savoir aboyer. Il possèdera donc une méthode supplémentaire. Ce qui donne :
public class Chien : Animal
{
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
On représente la notion d’héritage en ajoutant après la classe le caractère « : » suivi de la classe mère. Ici, nous avons défini une classe publique Chien qui hérite de la classe Animal.
Nous pouvons dès à présent créer des objets Animal et des objets Chien, par exemple :
Nous nous rendons bien compte que l’objet Chien, bien que n’ayant pas défini la propriété NombreDePattes ou la méthode Respirer() dans le corps de sa classe, est capable d’avoir des pattes et de faire l’action respirer.
Il a hérité ces comportements de l’objet Animal, en tous cas, ceux qui sont publiques. Rajoutons deux variables membres de la classe Animal :
public class Animal
{
private bool estVivant;
public int age;
public int NombreDePattes { get; set; }
public void Respirer()
{
Console.WriteLine("Je respire");
}
}
L’entier age est public alors que le booléen estVivant est privé. Si nous tentons de les utiliser depuis la classe fille Chien, comme ci-dessous :
public class Chien : Animal
{
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
public void Vieillir()
{
age++;
}
public void Naissance()
{
age = 0;
estVivant = true; // Erreur > 'MaPremiereApplication.Animal.estVivant'
// est inaccessible en raison de son niveau de protection
}
}
Nous voyons qu’il est tout à fait possible d’utiliser la variable age depuis la méthode Vieillir() alors que l’utilisation du booléen estVivant provoque une erreur de compilation. Vous avez bien compris que celui-ci était inaccessible car il est défini comme membre privé. Pour l’utiliser, on pourra le rendre public par exemple.
Il existe par contre un autre mot clé qui permet de rentre des variables/propriétés/méthodes inaccessibles depuis un autre objet tout en le rendant accessible depuis des classes filles. Il s’agit du mot clé protected. Si nous l’utilisons à la place de private pour définir la visibilité du booléen estVivant, nous pourrons nous rendre compte que la classe Chien peut désormais compiler :
public class Animal
{
protected bool estVivant;
[… Extrait de code supprimé …]
}
public class Chien : Animal
{
[… Extrait de code supprimé …]
public void Naissance()
{
age = 0;
estVivant = true; // compilation OK
}
}
Par contre, cette variable est toujours inaccessible depuis d’autres classes, comme l’est également une variable privée. Dans notre classe Program, l’instruction suivante :
chien.estVivant = true;
provoquera l’erreur de compilation que nous connaissons désormais bien :
'MaPremiereApplication.Animal.estVivant' est inaccessible en raison de son niveau de protection
Le mot clé protected prend tout son intérêt dès que nous avons à faire avec l’héritage. Nous verrons un peu plus bas d’autres exemples de ce mot clé.
Nous avons dit dans l’introduction qu’un objet B qui dérive de l’objet A est « une sorte » d’objet A. Dans notre exemple du dessus, le Chien est une sorte d’Animal. Cela veut dire que nous pouvons utiliser un chien en tant qu’animal. Par exemple, le code suivant :
Animal animal = new Chien { NombreDePattes = 4 };
est tout à fait correct. Nous disons que notre variable animal, de type Animal est une instance de Chien.
Avec cette façon d’écrire, nous avons réellement instancié un objet Chien mais celui-ci sera traité en tant qu’Animal. Cela veut dire qu’il sera capable de Respirer() et d’avoir des pattes. Par contre, même si en vrai, notre objet serait capable d’aboyer, le fait qu’il soit manipulé en tant qu’Animal nous empêche de pouvoir le faire Aboyer. Cela veut dire que le code suivant :
Animal animal = new Chien { NombreDePattes = 4 };
animal.Respirer();
animal.Aboyer(); // erreur de compilation
provoquera une erreur de compilation pour indiquer que la classe Animal ne contient aucune définition pour la méthode Aboyer(). Ce qui est normal, un animal ne sait pas forcément aboyer...
Quel est l’intérêt alors d’utiliser le chien en tant qu’animal ?
Bonne question.
Pour y répondre, nous allons enrichir notre classe Animal, garder notre classe Chien et créer une classe Chat qui hérite également d’Animal. Ce pourrait être :
public class Animal
{
protected string prenom;
public void Respirer()
{
Console.WriteLine("Je suis " + prenom + " et je respire");
}
}
public class Chien : Animal
{
public Chien(string prenomDuChien)
{
prenom = prenomDuChien;
}
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class Chat : Animal
{
public Chat(string prenomDuChat)
{
prenom = prenomDuChat;
}
public void Miauler()
{
Console.WriteLine("Miaou");
}
}
Nous forçons les chiens et les chats à avoir un nom, hérité de la classe Animal, grâce au constructeur afin de pouvoir les identifier facilement. Le chat garde le même principe que le chien, sauf que nous avons une méthode Miauler() à la place de la méthode Aboyer() … Ce qui est somme toute logique. L’idée est de pouvoir utiliser nos chiens et nos chats ensemble comme des animaux, par exemple en utilisant une liste.
Pour illustrer ce fonctionnement, donnons vie à quelques chiens et à quelques chats grâce à nos pouvoirs de développeur et mettons-les dans une liste :
List<Animal> animaux = new List<Animal>();
Animal milou = new Chien("Milou");
Animal dingo = new Chien("Dingo");
Animal idefix = new Chien("Idéfix");
Animal tom = new Chat("Tom");
Animal felix = new Chat("Félix");
animaux.Add(milou);
animaux.Add(dingo);
animaux.Add(idefix);
animaux.Add(tom);
animaux.Add(felix);
Nous avons dans un premier temps instancié une liste d’animaux à laquelle nous avons rajouté 3 chiens et 2 chats, chacun étant considéré comme un animal puisqu’ils sont tous des sortes d’animaux, grâce à l’héritage. Maintenant, nous n’avons plus que des animaux dans la liste. Il sera donc possible de les faire tous respirer en une simple boucle :
foreach (Animal animal in animaux)
{
animal.Respirer();
}
ce qui donnera :
Et voilà, c’est super simple. Imaginez le bonheur de Noé sur son arche quand il a compris que grâce à la POO, il pouvait faire respirer tous les animaux en une seule boucle ! Quel travail économisé. :p Peu importe ce qu’il y a dans la liste, des chiens, des chats, des hamsters, nous savons que ce sont tous des animaux et qu’ils savent tous respirer.
Vous avez sans doute remarqué que nous faisons la même chose dans le constructeur de la classe Chien et dans celui de la classe Chat. Deux fois la même chose… Ce n’est pas terrible. Peut-être y a-t-il un moyen de factoriser tout ça ? Effectivement, il est possible également d’écrire nos classes de cette façon :
public class Animal
{
protected string prenom;
public Animal(string prenomAnimal)
{
prenom = prenomAnimal;
}
public void Respirer()
{
Console.WriteLine("Je suis " + prenom + " et je respire");
}
}
public class Chien : Animal
{
public Chien(string prenomDuChien) : base(prenomDuChien)
{
}
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class Chat : Animal
{
public Chat(string prenomDuChat) : base(prenomDuChat)
{
}
public void Miauler()
{
Console.WriteLine("Miaou");
}
}
Qu’est-ce qui change ?
Eh bien la classe Animal possède un constructeur qui prend en paramètre un prénom et qui le stocke dans sa variable privée. C’est elle qui fait le travail d’initialisation. Il devient alors possible pour les constructeurs des classes filles d’appeler le constructeur de la classe mère afin de faire l’affectation du prénom. Pour cela, on utilise les deux points suivis du mot clé base qui signifie « appelle-moi le constructeur de la classe du dessus » auquel nous passons la variable en paramètres. Avec cette écriture un peu barbare, il devient possible de factoriser des initialisations qui ont un sens pour toutes les classes filles. Dans notre cas, je veux que tous les objets qui dérivent d’Animal puissent facilement définir un prénom.
Il faut aussi savoir que si nous appelons le constructeur par défaut d’une classe qui n'appelle pas explicitement un constructeur spécialisé d'une classe mère, alors celui-ci appellera automatiquement le constructeur par défaut de la classe dont il hérite. Modifions à nouveau nos classes pour avoir :
public class Animal
{
protected string prenom;
public Animal()
{
prenom = "Marcel";
}
public void Respirer()
{
Console.WriteLine("Je suis " + prenom + " et je respire");
}
}
public class Chien : Animal
{
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class Chat : Animal
{
public Chat(string prenomDuChat)
{
prenom = prenomDuChat;
}
public void Miauler()
{
Console.WriteLine("Miaou");
}
}
Ici, la classe Animal met un prénom par défaut dans son constructeur. Le chien n’a pas de constructeur et le chat en a un qui accepte un paramètre.
Il est donc possible de créer un Chien sans qu’il ait de prénom mais il est obligatoire d’en définir un pour le chat. Sauf que lorsque nous instancierons notre objet chien, il appellera automatiquement le constructeur de la classe mère et tous nos chiens s’appelleront Marcel :
static void Main(string[] args)
{
List<Animal> animaux = new List<Animal>();
Animal chien = new Chien();
Animal tom = new Chat("Tom");
Animal felix = new Chat("Félix");
animaux.Add(chien);
animaux.Add(tom);
animaux.Add(felix);
foreach (Animal animal in animaux)
{
animal.Respirer();
}
}
Ce qui donne :
Il est également possible d’appeler un constructeur à partir d’un autre constructeur. Prenons l’exemple suivant :
public class Voiture
{
private int vitesse;
public Voiture(int vitesseVoiture)
{
vitesse = vitesseVoiture;
}
}
Si nous souhaitons rajouter un constructeur par défaut qui initialise la vitesse à 10 par exemple, nous pourrons faire :
public class Voiture
{
private int vitesse;
public Voiture()
{
vitesse = 10;
}
public Voiture(int vitesseVoiture)
{
vitesse = vitesseVoiture;
}
}
Ou encore :
public class Voiture
{
private int vitesse;
public Voiture() : this(10)
{
}
public Voiture(int vitesseVoiture)
{
vitesse = vitesseVoiture;
}
}
Ici, l’utilisation du mot clé this, suivi d’un entier permet d’appeler le constructeur qui possède un paramètre entier au début du constructeur par défaut. Inversement, nous pouvons appeler le constructeur par défaut d’une classe depuis un constructeur possédant des paramètres afin de pouvoir bénéficier des initialisations de celui-ci :
public class Voiture
{
private int vitesse;
private string couleur;
public Voiture()
{
vitesse = 10;
}
public Voiture(string couleurVoiture) : this()
{
couleur = couleurVoiture;
}
}
Puisque nous sommes à parler d’héritage, il faut savoir que tous les objets que nous créons ou qui sont disponibles dans le framework .NET héritent d’un objet de base. On parle en général d’un « super objet ». L’intérêt de dériver d’un tel objet est de permettre à tous les objets d’avoir certains comportements en commun, mais également de pouvoir éventuellement tous les traiter en tant qu’objet. Notre super objet est représenté par la classe Object qui définit plusieurs méthodes. Vous les avez déjà vues si vous avez regardé dans la complétion automatique après avoir créé un objet. Prenons une classe toute vide, par exemple :
public class ObjetVide
{
}
Si nous instancions cet objet et que nous souhaitons l’utiliser, nous verrons que la complétion automatique nous propose des méthodes que nous n’avons jamais créées :
Nous voyons plusieurs méthodes, comme la méthode Equals ou GetHashCode ou GetType ou encore ToString. Comme vous l’avez compris, ce sont des méthodes qui sont définies dans la classe Object. La méthode ToString par exemple permet d’obtenir une représentation de l’objet sous la forme d’une chaine de caractères. C’est une méthode qui va souvent nous servir, nous y reviendrons un peu plus tard. Ce super-objet est du type Object, mais on utilise généralement son alias object.
Ainsi, il est possible d’utiliser tous nos objets comme des object et ainsi utiliser les méthodes qui sont définies sur la classe Object. Ce qui nous permet de faire :
static void Main(string[] args)
{
ObjetVide monObjetVide = new ObjetVide();
Chien chien = new Chien();
int age = 30;
string prenom = "Nicolas";
AfficherRepresentation(monObjetVide);
AfficherRepresentation(chien);
AfficherRepresentation(age);
AfficherRepresentation(prenom);
}
private static void AfficherRepresentation(object monObjetVide)
{
Console.WriteLine(monObjetVide.ToString());
}
Ce qui donne :
Comme indiqué, la méthode ToString() permet d’afficher la représentation par défaut d’un objet. Vous aurez remarqué qu’il y a une différence suivant ce que nous passons. En effet, la représentation par défaut des types référence correspond au nom du type, à savoir son espace de nom suivi du nom de sa classe. Pour ce qui est des types valeur, il contient en général la valeur du type, à l’exception des structures que nous n’avons pas encore vues et que nous aborderons un peu plus loin.
L’intérêt dans cet exemple de code est de voir que nous pouvons manipuler tout comme un object. D’une manière générale, vous aurez peu l’occasion de traiter vos objets en tant qu’object car il est vraiment plus intéressant de profiter pleinement du type, l’object étant peu utilisable.
J’en profite maintenant que vous connaissez la méthode ToString() pour parler d’un point qui a peut-être titillé vos cerveaux. Dans la première partie, nous avions fait quelque chose du genre :
int vitesse = 20;
string chaine = "La vitesse est " + vitesse + " km/h";
La variable vitesse est un entier. La chaîne La vitesse est est une chaine de caractères. Nous essayons d’ajouter un entier à une chaîne alors que j’ai dit qu’ils n’étaient pas compatibles entre eux ! Et pourtant cela fonctionne. Effectivement, c’est bizarre. o_O Nous concaténons une chaîne à un entier avec l’opérateur + et nous concaténons encore une chaîne.
Et si je fais l’inverse :
int vitesse = 20 + "40";
cela provoque une erreur de compilation. C’est logique, on ne peut pas ajouter un entier et une chaîne de caractères. Alors pourquoi cela fonctionne dans l’autre sens ? Ce qu’il se passe en fait dans l’instruction :
string chaine = "La vitesse est " + vitesse + " km/h";
c’est que le compilateur se rend compte que nous concaténons une chaîne avec un autre objet, peu importe que ce soit un entier ou un objet complexe. Alors pour que ça fonctionne, il demande une représentation de l’objet sous la forme d’une chaîne de caractères. Nous avons vu que ceci se faisait en appelant la méthode ToString() qui est héritée de l’objet racine Object.
L’instruction est donc équivalente à :
string chaine = "La vitesse est " + vitesse.ToString() + " km/h";
Dans le cas d’un type valeur comme un entier, la méthode ToString() renvoie la représentation interne de la valeur, à savoir "20". Dans le cas d’un objet complexe, elle aurait renvoyé le nom du type de l’objet.
Avant de terminer, il est important d’indiquer que le C# n’autorise pas l’héritage multiple. Ainsi, si nous possédons une classe Carnivore et une classe EtreVivant, il ne sera pas possible de faire hériter directement un objet Homme de l’objet Carnivore et de l’objet EtreVivant. Ainsi, le code suivant :
public class Carnivore
{
}
public class EtreVivant
{
}
public class Homme : Carnivore, EtreVivant
{
}
provoquera l’erreur de compilation suivante :
La classe 'MaPremiereApplication.Homme' ne peut pas avoir plusieurs classes de base : 'MaPremiereApplication.Carnivore' et 'EtreVivant'
Si par contre, cela est pertinent, nous pourrons faire un héritage en cascade afin que Carnivore dérive de EtreVivant et que Homme dérive de Carnivore :
public class Carnivore : EtreVivant
{
}
public class EtreVivant
{
}
public class Homme : Carnivore
{
}
Cependant, il n’est pas toujours pertinent d'opérer de la sorte. Notre Homme pourrait être à la fois Carnivore et Frugivore, cependant cela n’a pas de sens qu’un carnivore soit également frugivore, ou l’inverse.
Oui mais tu as dit que chaque objet dérivait du super objet Object, s’il dérive d’une autre classe comme un chien dérive d’un animal, ça fait bien deux classes dont il dérive…
Effectivement, mais dans ce cas-là, ce n’est pas pareil. Comme il est automatique de dériver de object, c’est comme si on avait le chien qui hérite de animal qui hérite lui-même de object. Le C# est assez malin pour ça. ^^
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu juste avant l’utilisation de la méthode ToString() qui permet d’obtenir la représentation d’un objet sous forme de chaine de caractères. En l’occurrence, vous conviendrez avec moi que la représentation de notre classe Chien n’est pas particulièrement exploitable. Le nom du type c’est bien, mais ce n’est pas très parlant.
Ça serait pas mal que quand nous demandons d’afficher un chien, nous obtenions le nom du chien, vous ne trouvez pas ? C’est là qu’intervient la substitution. Nous en avons parlé dans l’introduction à la POO, la substitution permet de redéfinir un comportement dont l’objet a hérité afin qu’il corresponde aux besoins de l’objet fils. Typiquement, ici, la méthode ToString() du super-objet ne nous convient pas et dans le cas de notre chien, nous souhaitons la redéfinir, en écrire une nouvelle version.
Pour cet exemple, simplifions notre classe Chien afin qu’elle n’ait qu’une propriété pour stocker son prénom :
public class Chien
{
public string Prenom { get; set; }
}
Pour redéfinir la méthode ToString() nous allons devoir utiliser le mot clé override qui signifie que nous souhaitons substituer la méthode existante afin de remplacer son comportement, ce que nous pourrons écrire en C# avec :
public class Chien
{
public string Prenom { get; set; }
public override string ToString()
{
return "Je suis un chien et je m'appelle " + Prenom;
}
}
Le mot clé override se met avant le type de retour de la méthode, comme on peut le voir ci-dessus. Si nous appelons désormais la méthode ToString de notre objet Chien :
notre programme va utiliser la nouvelle version de la méthode ToString() et nous aurons :
Et voilà un bon moyen d’utiliser la substitution, la représentation de notre objet est quand même plus parlante. Adaptons désormais cet exemple à nos classes. Pour montrer comment faire, reprenons notre classe Chien qui possède une méthode Aboyer() :
public class Chien
{
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
Nous pourrions imaginer créer une classe ChienMuet qui dérive de la classe Chien et qui hérite donc de ses comportements. Mais, que penser d’un chien muet qui serait capable d’aboyer ? Cela n’a pas de sens ! Il faut donc redéfinir cette fichue méthode.
Utilisons alors le mot clé override comme nous l’avons vu pour obtenir :
public class ChienMuet : Chien
{
public override void Aboyer()
{
Console.WriteLine("...");
}
}
Créons un chien muet puis faisons-le aboyer, cela donne :
ChienMuet pauvreChien = new ChienMuet();
pauvreChien.Aboyer();
Sauf que nous rencontrons un problème. Si nous tentons de compiler ce code, Visual C# express nous génère une erreur de compilation :
'MaPremiereApplication.Program.ChienMuet.Aboyer()' : ne peut pas substituer le membre hérité 'MaPremiereApplication.Program.Chien.Aboyer()', car il n'est pas marqué comme virtual, abstract ou override.
En réalité, pour pouvoir créer une méthode qui remplace une autre, il faut qu’une condition supplémentaire soit vérifiée : il faut que la méthode à remplacer s’annonce comme candidate à la substitution. Cela veut dire que l’on ne peut pas substituer n’importe quelle méthode, mais seulement celles qui acceptent de l’être. C’est le cas pour la méthode ToString que nous avons vue précédemment. Les concepteurs du framework .NET ont autorisé cette éventualité. Heureusement, sinon, nous serions bien embêtés :) .
Pour marquer notre méthode Aboyer de la classe Chien comme candidate éventuelle à la substitution, il faut la préfixer du mot clé virtual. Ainsi, elle annonce à ses futures filles que si elles le souhaitent, elles peuvent redéfinir cette méthode.
Cela se traduit ainsi dans le code :
public class Chien
{
public virtual void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class ChienMuet : Chien
{
public override void Aboyer()
{
Console.WriteLine("...");
}
}
Désormais, l’instanciation de l’objet est possible et nous pourrons avoir notre code :
ChienMuet pauvreChien = new ChienMuet();
pauvreChien.Aboyer();
qui affichera :
Parfait !
Tout est rentré dans l’ordre.
Le message d’erreur, quoique peu explicite, nous mettait quand même sur la bonne voie. Visual C# express nous disait qu’il fallait que la méthode soit marquée comme virtual, ce que nous avons fait. Il proposait également qu’elle soit marquée abstract, nous verrons un peu plus loin ce que ça veut dire. Visual C# express indiquait enfin que la méthode pouvait être marquée override. Cela veut dire qu’une classe fille de ChienMuet peut également redéfinir la méthode Aboyer() afin qu’elle colle à ses besoins. Elle n’est pas marquée virtual mais elle est marquée override. Par exemple :
public class ChienMuetAvecSyntheseVocale : ChienMuet
{
public override void Aboyer()
{
Console.WriteLine("bwarf !");
}
}
Il y a encore un dernier point que nous n’avons pas abordé. Il s’agit de la capacité pour une classe fille de redéfinir une méthode tout en conservant la fonctionnalité de la méthode de la classe mère. Imaginons notre classe Animal qui possède une méthode Manger() :
public class Animal
{
public virtual void Manger()
{
Console.WriteLine("Mettre les aliments dans la bouche");
Console.WriteLine("Mastiquer");
Console.WriteLine("Avaler");
Console.WriteLine("...");
}
}
Notre classe Chien pourra s’appuyer sur le comportement de la méthode Manger() de la classe Animal pour créer sa propre action personnelle. Cela se passe en utilisant à nouveau le mot clé base qui représente la classe mère. Nous pourrons par exemple appeler la méthode Manger() de la classe mère afin de réutiliser son fonctionnement. Cela donne :
public class Chien : Animal
{
public override void Manger()
{
Console.WriteLine("Réclamer à manger au maître");
base.Manger();
Console.WriteLine("Remuer la queue");
}
}
Dans cet exemple, je fais quelque chose avant d’appeler la méthode de la classe mère, puis je fais quelque chose d’autre après. Maintenant, si nous faisons manger notre chien :
Chien chien = new Chien();
chien.Manger();
nous aurons :
Nous voyons bien avec cet exemple comment la classe fille peut réutiliser les méthodes de sa classe mère.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons dit qu’une manifestation du polymorphisme était la capacité d'une classe à effectuer la même action sur différents types d’intervenants. Il s'agit de la surcharge, appelé aussi polymorphisme ad hoc.
Concrètement, cela veut dire qu’il est possible de définir la même méthode avec des paramètres en entrée différents. Si vous vous rappelez bien, c’est quelque chose que nous avons déjà fait sans le savoir. Devinez … Oui, c’est ça, avec la méthode Console.WriteLine.
Nous avons pu afficher des chaines de caractères, mais aussi des entiers, même des types double, et plus récemment des objets. Comment est-ce possible alors que nous avons déjà vu qu’il était impossible de passer des types en paramètres d’une méthode qui ne correspondent pas à sa signature ?
Ainsi, l’exemple suivant :
public class Program
{
static void Main(string[] args)
{
Math math = new Math();
int a = 5;
int b = 6;
int resultat = math.Addition(a, b);
double c = 1.5;
double d = 5.0;
resultat = math.Addition(c, d); // erreur de compilation
}
}
public class Math
{
public int Addition(int a, int b)
{
return a + b;
}
}
provoquera une erreur de compilation lorsque nous allons essayer de passer des variables du type double à notre méthode qui prend des entiers en paramètres. Pour que ceci fonctionne, nous allons rendre polymorphe cette méthode en définissant à nouveau cette même méthode mais en lui faisant prendre des paramètres d’entrées différents :
public class Program
{
static void Main(string[] args)
{
Math math = new Math();
int a = 5;
int b = 6;
int resultat = math.Addition(a, b);
double c = 1.5;
double d = 5.0;
double resultatDouble = math.Addition(c, d); // ca compile, youpi
}
}
public class Math
{
public int Addition(int a, int b)
{
return a + b;
}
public double Addition(double a, double b)
{
return a + b;
}
}
Nous avons ainsi écrit deux formes différentes de la même méthode. Une qui accepte des entiers et l’autre qui accepte des double. Ce code fonctionne désormais correctement.
Il est bien sûr possible d’écrire cette méthode avec beaucoup de paramètres de types différents, même une classe Chien, en imaginant que le fait d’additionner 2 chiens corresponde au fait d’additionner leur nombre de pattes :
public class Math
{
public int Addition(int a, int b)
{
return a + b;
}
public double Addition(double a, double b)
{
return a + b;
}
public int Addition(Chien c1, Chien c2)
{
return c1.NombreDePattes + c2.NombreDePattes;
}
}
Attention, j’ai toujours indiqué qu’il était possible d’ajouter une nouvelle forme à la même méthode en changeant les paramètres d’entrée. Vous ne pourrez pas le faire en changeant uniquement le paramètre de retour. Ce qui fait que cet exemple ne pourra pas compiler :
public class Math
{
public int Addition(int a, int b)
{
return a + b;
}
public double Addition(int a, int b)
{
return a + b;
}
}
Les deux méthodes acceptent deux entiers en paramètres et renvoient soit un entier, soit un double. Le compilateur ne sera pas capable de choisir quelle méthode utiliser lorsque nous essayerons d’appeler cette méthode. Les méthodes doivent se différencier avec les paramètres d’entrée. Lorsque nous avons plusieurs signatures possibles pour la même méthode, vous remarquerez que la complétion automatique nous propose alors plusieurs alternatives :
Visual C# Express nous indique qu’il a trois méthodes possibles qui s’appellent Math.Addition. Pour voir la signature des autres méthodes, il suffit de cliquer sur les flèches, ou d’utiliser les flèches du clavier :
C’est ce qu’il se passe dans la méthode Console.WriteLine :
Nous voyons ici qu’il existe 19 écritures de la méthode WriteLine, la cinquième prenant en paramètres un décimal. Notez que pour écrire plusieurs formes de cette méthode, nous pouvons également jouer sur le nombre de paramètres. La méthode :
public int Addition(int a, int b, int c)
{
return a + b + c;
}
sera bien une nouvelle forme de la méthode Addition.
Nous avons également vu dans le chapitre sur les constructeurs d’une classe qu’il était possible de cumuler les constructeurs avec des paramètres différents. Il s’agit à nouveau du polymorphisme. Il nous permet de définir différents constructeurs sur nos objets.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons déjà vu dans la partie précédente qu’il était possible de convertir les types qui se ressemblent entre eux. Cela fonctionne également avec les objets. Plus précisément, cela veut dire que nous pouvons convertir un objet en un autre seulement s’il est une sorte de l’autre objet. Nous avons vu dans les chapitres précédents qu’il s’agissait de la notion d’héritage.
Ainsi, si nous avons défini une classe Animal et que nous définissons une classe Chien qui hérite de cette classe Animal :
public class Animal
{
}
public class Chien : Animal
{
}
nous pourrons alors convertir le chien en animal dans la mesure où le chien est une sorte d’animal :
Chien medor = new Chien();
Animal animal = (Animal)medor;
Nous utilisons pour ce faire un cast, comme nous l’avons déjà fait pour les types intégrés (int, bool, etc.). Il suffit de préfixer la variable à convertir du type entre parenthèses dans lequel nous souhaitons le convertir. Ici, nous pouvons convertir facilement notre Chien en Animal.
Par contre, il est impossible de convertir un chien en voiture, car il n’y a pas de relation d’héritage entre les deux. Ainsi les instructions suivantes :
Chien medor = new Chien();
Voiture voiture = (Voiture)medor;
provoqueront une erreur de compilation. Nous avons précédemment utilisé l’héritage afin de mettre des chiens et des chats dans une liste d’animaux. Nous avions fait quelque chose du genre :
List<Animal> animaux = new List<Animal>();
Animal chien = new Chien();
Animal chat = new Chat();
animaux.Add(chien);
animaux.Add(chat);
Il serait plus logique en fait d’écrire les instructions suivantes :
List<Animal> animaux = new List<Animal>();
Chien chien = new Chien();
Chat chat = new Chat();
animaux.Add((Animal)chien);
animaux.Add((Animal)chat);
Dans ce cas, nous créons un objet Chien et un objet Chat que nous mettons dans une liste d’objets Animal grâce à une conversion utilisant un cast. En fait, ce cast est inutile et nous pouvons simplement écrire :
List<Animal> animaux = new List<Animal>();
Chien chien = new Chien();
Chat chat = new Chat();
animaux.Add(chien);
animaux.Add(chat);
La conversion est implicite, comme lorsque nous avions utilisé un object en paramètres d’une méthode et que nous pouvions lui passer tous les types qui dérivent d’ object. Nous avions également vu que nous ne pouvions traiter les chiens et les chats que comme des animaux à partir du moment où nous les mettions dans une liste. Avec les objets suivants :
public class Animal
{
public void Respirer()
{
Console.WriteLine("Je respire");
}
}
public class Chien : Animal
{
public void Aboyer()
{
Console.WriteLine("Waouf");
}
}
public class Chat : Animal
{
public void Miauler()
{
Console.WriteLine("Miaou");
}
}
Nous pouvions utiliser une boucle pour faire respirer tous nos animaux :
List<Animal> animaux = new List<Animal>();
Chien chien = new Chien();
Chat chat = new Chat();
animaux.Add(chien);
animaux.Add(chat);
foreach (Animal animal in animaux)
{
animal.Respirer();
}
Mais impossible de faire aboyer le chien, ni miauler le chat. Si vous tentez de remplacer dans la boucle Animal par Chien, avec :
foreach (Chien c in animaux)
{
c.Aboyer();
}
Vous pourrez faire aboyer le premier élément de la liste qui est effectivement un chien, par contre il y aura un plantage au deuxième élément de la liste car il s’agit d’un chat :
Lorsque notre programme a tenté de convertir un animal qui est un chat en chien, il nous a fait comprendre qu’il n’appréciait que moyennement. Les chiens n’aiment pas trop les chats d’une manière générale, alors en plus, un chat qui essaie de se faire passer pour un chien : c’est une déclaration de guerre ! Voilà pourquoi notre programme a levé une exception. Il lui était impossible de convertir un Chat en Chien.
Il est cependant possible de tester si une variable correspond à un objet grâce au mot-clé is. Ce qui nous permettra de faire la conversion adéquate et de nous éviter une erreur à l’exécution :
foreach (Animal animal in animaux)
{
if (animal is Chien)
{
Chien c = (Chien)animal;
c.Aboyer();
}
if (animal is Chat)
{
Chat c = (Chat)animal;
c.Miauler();
}
}
Nous testons avec le mot-clé is si l’animal est une instance d’un Chien ou d’un chat. Le code du dessus nous permettra d’utiliser dans la boucle l’animal courant comme un chien ou un chat en fonction de ce qu’il est vraiment, grâce au test.
Ce qui produira :
Le fait de tester ce qu’est vraiment l’animal avant de le convertir est une sécurité indispensable pour éviter le genre d’erreur du dessus. C’est l’inconvénient du cast explicite. Il convient très bien si nous sommes certains du type dans lequel nous souhaitons en convertir un autre. Par contre, si la conversion n’est pas possible, alors nous aurons une erreur. Lorsque nous ne sommes pas certains du résultat du cast, mieux vaut tester si l’instance d’un objet correspond bien à l’objet lui-même.
Cela peut se faire comme nous l’avons vu avec le mot-clé is, mais également avec un autre cast qui s’appelle le cast dynamique. Il se fait en employant le mot-clé as. Ce cast dynamique vérifie que l’objet est bien convertible. Si c’est le cas, alors il fait un cast explicite pour renvoyer le résultat de la conversion, sinon, il renvoie une référence nulle. Le code du dessus peut donc s’écrire :
foreach (Animal animal in animaux)
{
Chien c1 = animal as Chien;
if (c1 != null)
{
c1.Aboyer();
}
Chat c2 = animal as Chat;
if (c2 != null)
{
c2.Miauler();
}
}
On utilise le mot-clé as en le faisant précéder de la valeur à tenter de convertir et en le faisant suivre du type dans lequel nous souhaitons la convertir.
Fonctionnellement, nous faisons la même chose dans les deux codes. Vous pouvez choisir l’écriture que vous préférez, mais sachez que c’est ce dernier qui est en général utilisé car il est préconisé par Microsoft et est un tout petit peu plus performant.
Un petit détail encore. Il est possible de convertir un type valeur, comme un int ou un string en type référence en utilisant ce qu’on appelle le boxing. Rien à voir avec le fait de taper sur les types valeur. Comme nous l’avons vu, les types valeur et les types référence sont gérés différemment par .NET. Aussi, si nous convertissons un type valeur en type référence, .NET fait une opération spéciale automatiquement. Ainsi le code suivant :
int i = 5;
object o = i; // boxing
effectue un boxing automatique de l’entier en type référence. C’est ce boxing automatique qui nous permet de manipuler les types valeur comme des object. C’est aussi ce qui nous a permis plus haut de passer un entier en paramètre à une méthode qui acceptait un object. En interne, ce qu’il se passe c’est que object se voit attribuer une référence vers une copie de la valeur de i. Ainsi, modifier o ne modifiera pas i. Ce code :
int i = 5;
object o = i; // boxing
o = 6;
Console.WriteLine(i);
Console.WriteLine(o);
affiche 5 puis 6. Le contraire est également possible, ce qu’on appelle l’unboxing. Seulement, celui-ci a besoin d’un cast explicite afin de pouvoir compiler. C'est-à-dire :
int i = 5;
object o = i; // boxing
int j = (int)o; // unboxing
ici nous reconvertissons la référence vers la valeur de o en entier et nous effectuons à nouveau une copie de cette valeur pour la mettre dans j. Ainsi le code suivant :
int i = 5;
object o = i; // boxing
o = 6;
int j = (int)o; // unboxing
j = 7;
Console.WriteLine(i);
Console.WriteLine(o);
Console.WriteLine(j);
affichera en toute logique 5 puis 6 puis 7.
En résumé
Les objets peuvent être des types valeur ou des types référence. Les variables de type valeur possèdent la valeur de l'objet, comme un entier. Les variables de type référence possèdent une référence vers l'objet en mémoire.
Tous les objets dérivent de la classe de base Object.
On peut substituer une méthode grâce au mot-clé override si elle s'est déclarée candidate à la substitution grâce au mot-clé virtual.
La surcharge est le polymorphisme permettant de faire varier les types des paramètres d'une même méthode ou leurs nombres.
Il est possible grâce au cast de convertir un type en un autre type, s'ils ont une relation d'héritage.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre, nous allons continuer à découvrir comment nous pouvons faire de l'orienté objet avec le C#. Nous allons pousser un peu plus loin en découvrant les interfaces et en manipulant les classes statiques et abstraites.
À la fin de ce chapitre, vous serez capables de faire des objets encore plus évolués et vous devriez être capables de créer un vrai petit programme orienté objet… !
Nous avons vu dans la première partie qu’il était possible de comparer facilement des types valeur grâce aux opérateurs de comparaison. En effet, vu que des variables de ces types possèdent directement la valeur que nous lui affectons, on peut facilement comparer un entier avec la valeur 5, ou un entier avec un autre entier. Par contre, cela ne fonctionne pas avec les objets. En effet, nous avons vu que les variables qui représentent des instances d’objet contiennent en fait une référence vers l’instance.
Cela n’a pas vraiment de sens de comparer des références. De plus, en imaginant que je veuille vraiment comparer deux voitures, sur quels critères puis-je déterminer qu’elles sont égales ? La couleur ? La vitesse ?
Sans rien faire, la comparaison en utilisant par exemple l’opérateur d’égalité « == » permet simplement de vérifier si les références pointent vers le même objet.
Pour les exemples suivants, nous nous baserons sur la classe Voiture suivante :
public class Voiture
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
}
Ainsi, si nous écrivons :
Voiture voitureNicolas = new Voiture();
voitureNicolas.Couleur = "Bleue";
Voiture voitureJeremie = voitureNicolas;
voitureJeremie.Couleur = "Verte";
if (voitureJeremie == voitureNicolas)
{
Console.WriteLine("Les objets référencent la même instance");
}
Ce code affichera la chaine « Les objets référencent la même instance » car effectivement, nous avons affecté la référence de voitureNicolas à voitureJeremie. (Ce qui implique également que la modification de la voiture de Jérémie affecte également la voiture de Nicolas, comme nous l’avons déjà vu).
Par contre, le code suivant :
Voiture voitureNicolas = new Voiture();
Voiture voitureJeremie = new Voiture();
if (voitureJeremie == voitureNicolas)
{
Console.WriteLine("Les objets référencent la même instance");
}
n'affichera évidemment rien car ce sont deux instances différentes.
S’il s’avère qu’il est vraiment pertinent de pouvoir comparer deux voitures entre elles, il faut savoir que c’est quand même possible. La première chose à faire est de définir les critères de comparaison. Par exemple, nous n’avons qu’à dire que deux voitures sont identiques quand la couleur, la marque et la vitesse sont égales. Je sais, c’est un peu irréel, mais c’est pour l’exemple.
Ainsi, nous pourrons par exemple vérifier que deux voitures sont égales avec l’instruction suivante :
if (voitureNicolas.Couleur == voitureJeremie.Couleur && voitureNicolas.Marque == voitureJeremie.Marque && voitureNicolas.Vitesse == voitureJeremie.Vitesse)
{
Console.WriteLine("Les deux voitures sont identiques");
}
La comparaison d’égalité entre deux objets, c’est en fait le rôle de la méthode Equals() dont chaque objet hérite de la classe mère Object. A part pour les types valeur, le comportement par défaut de la méthode Equals() est de comparer les références des objets. Seulement, il est possible de définir un comportement plus approprié pour notre classe Voiture, grâce à la fameuse spécialisation.
Comme on l’a déjà vu, on utilise le mot clé override. Ceci est possible dans la mesure où la classe « Object » a défini la méthode Equals comme virtuelle, avec le mot clé virtual. Ce qui donne :
public class Voiture
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
public override bool Equals(object obj)
{
Voiture v = obj as Voiture;
if (v == null)
return false;
return Vitesse == v.Vitesse && Couleur == v.Couleur && Marque == v.Marque;
}
}
Remarquons que la méthode Equals prend en paramètre un object. La première chose à faire est donc de vérifier que nous avons réellement une voiture, grâce au cast dynamique. Ensuite, il ne reste qu’à comparer les propriétés de l’instance courante et de l’objet passé en paramètre.
Pour faire une comparaison entre deux voitures, nous pourrons utiliser le code suivant :
Voiture voitureNicolas = new Voiture { Vitesse = 10, Marque = "Peugeot", Couleur = "Grise"};
Voiture voitureJeremie = new Voiture { Vitesse = 10, Marque = "Peugeot", Couleur = "Grise" };
if (voitureNicolas.Equals(voitureJeremie))
{
Console.WriteLine("Les objets ont les mêmes valeurs dans leurs propriétés");
}
Nos deux voitures sont identiques car leurs marques, leurs couleurs et leurs vitesses sont identiques :
Facile de comparer :) . Sauf que vous aurez peut-être remarqué que la compilation de ce code provoque un avertissement. Il ne s’agit pas d’une erreur, mais Visual C# express nous informe qu’il faut faire attention :
Il nous dit que nous avons substitué la méthode Equals() sans avoir redéfini la méthode GetHashCode(). Nous n'avons pas besoin ici de savoir à quoi sert vraiment la méthode GetHashCode(), mais si vous voulez en savoir plus, n'hésitez pas à consulter la documentation.
Toujours est-il que nous devons rajouter une spécialisation de la méthode GetHashCode(), dont le but est de renvoyer un identifiant plus ou moins unique représentant l'objet, ce qui donnera :
public class Voiture
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
public override bool Equals(object obj)
{
Voiture v = obj as Voiture;
if (v == null)
return false;
return Vitesse == v.Vitesse && Couleur == v.Couleur && Marque == v.Marque;
}
public override int GetHashCode()
{
return Couleur.GetHashCode() * Marque.GetHashCode() * Vitesse.GetHashCode();
}
}
Nous nous servons du fait que chaque variable de la classe possède déjà un identifiant obtenu avec la méthode GetHashCode(). En combinant chaque identifiant de chaque propriété nous pouvons en créer un nouveau.
Ici, la classe est complète et prête à être comparée. Elle pourra donc fonctionner correctement avec tous les algorithmes d’égalité du framework .NET. Notez quand même que devoir substituer ces deux méthodes est une opération relativement rare, nous l’avons étudié pour la culture.
Ce qui est important à retenir c’est ce fameux warning. La conclusion à tirer est que notre façon de comparer, bien que fonctionnelle pour notre voiture, n’est pas parfaite.
Pourquoi ? Parce qu’en ayant substitué la méthode Equals(), nous croyons que la comparaison est bonne sauf que le compilateur nous apprend que ce n’est pas le cas. Heureusement qu’il était là ce compilateur. Comme c’est une erreur classique, il est capable de la détecter. Mais si c’est autre chose et qu’il ne le détecte pas ?
Cela manque d’une uniformisation tout ça, vous ne trouvez pas ? Il faudrait quelque chose qui nous assure que la classe est correctement comparable. Une espèce de contrat que l’objet s’engagerait à respecter pour être sûr que toutes les comparaisons soient valides.
Un contrat ? Un truc qui finit par « able » ? Ça me rappelle quelque chose ça. Mais oui, les interfaces.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une fois n’est pas coutume, plutôt que de commencer par étudier le plus simple, nous allons étudier le plus logique puis nous reviendrons sur le plus simple. C’est-à-dire que nous allons pousser un peu plus loin la comparaison en nous servant des interfaces et nous reviendrons ensuite sur comment créer une interface.
Nous avons donc dit que les interfaces étaient un contrat que s’engageait à respecter un objet. C’est tout à fait ce dont on a besoin ici. Notre objet doit s’engager à fonctionner pour tous les types de comparaison. Il doit être comparable. Mais comparable ne veut pas forcément dire « égal », nous devrions être aussi capables d’indiquer si un objet est supérieur à un autre.
Pourquoi ? Imaginons que nous possédions un tableau de voitures et que nous souhaitions le trier comme on a vu dans un chapitre précédent. Pour les entiers c’était une opération plutôt simple, avec la méthode Array.Sort() ils étaient automatiquement triés par ordre croissant. Mais dans notre cas, comment un tableau sera capable de trier nos voitures ?
Nous voici donc en présence d’un cas concret d’utilisation des interfaces. L’interface IComparable permet de définir un contrat de méthodes destinées à la prise en charge de la comparaison entre deux instances d’un objet. Une fois ces méthodes implémentées, nous serons certains que nos objets seront comparables correctement.
Pour cela, nous allons faire en sorte que notre classe « implémente » l’interface.
Reprenons notre classe Voiture avec uniquement ses propriétés et faisons lui implémenter l’interface IComparable. Pour implémenter une interface, on utilisera la même syntaxe que pour hériter d’une classe, c'est-à-dire qu’on utilisera les deux points suivis du type de l’interface. Ce qui donne :
public class Voiture : IComparable
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
}
Si vous tentez de compiler ce code, vous aurez le message d’erreur suivant :
Le compilateur nous rappelle à l’ordre : nous annonçons que nous souhaitons respecter le contrat de comparaison, sauf que nous n’avons pas la méthode adéquate ! Eh oui, le contrat indique ce que nous nous engageons à faire mais pas la façon de le faire. L’implémentation de la méthode est à notre charge.
Toujours dans l’optique de simplifier la tâche du développeur, Visual C# Express nous aide pour implémenter les méthodes d’un contrat. Faites un clic droit sur l’interface et choisissez dans le menu contextuel « Implémenter l’interface » et « Implémenter l’interface » :
Visual C# Express nous génère le code suivant :
public class Voiture : IComparable
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
public int CompareTo(object obj)
{
throw new NotImplementedException();
}
}
C'est-à-dire la signature de la méthode qu’il nous manque pour respecter le contrat de l’interface et un contenu que nous ne comprenons pas pour l’instant. Nous y reviendrons plus tard, pour l’instant, vous n’avez qu’à supprimer la ligne :
throw new NotImplementedException();
Il ne reste plus qu’à écrire le code de la méthode. Pour ce faire, il faut définir un critère de tri. Trier des voitures n’a pas trop de sens, aussi nous dirons que nous souhaitons les trier suivant leurs vitesses.
Pour respecter correctement le contrat, nous devons respecter la règle suivante qui se trouve dans la documentation de la méthode de l’interface :
Si une voiture est inférieure à une autre, alors nous devons renvoyer une valeur inférieure à 0, disons -1.
Si elle est égale, alors nous devons renvoyer 0.
Enfin, si elle est supérieure, nous devons renvoyer une valeur supérieure à 0, disons 1.
Ce qui donne :
public int CompareTo(object obj)
{
Voiture voiture = (Voiture)obj;
if (this.Vitesse < voiture.Vitesse)
return -1;
if (this.Vitesse > voiture.Vitesse)
return 1;
return 0;
}
À noter que la comparaison s’effectue entre l’objet courant et un objet qui lui est passé en paramètres. Pour que ce soit un peu plus clair, j’ai utilisé le mot-clé this qui permet de bien identifier l’objet courant et l’objet passé en paramètres. Comme il est facultatif, nous pouvons le supprimer.
Vous aurez également remarqué que j’utilise un cast explicite avant de comparer. Ceci permet de renvoyer une erreur si jamais l’objet à comparer n’est pas du bon type. En effet, que devrais-je renvoyer si jamais l’objet qu’on me passe n’est pas une voiture ? Une erreur, c’est très bien. :)
Le code est suffisamment explicite pour que nous comprenions facilement ce que l’on doit faire : comparer les vitesses.
Il est possible de simplifier grandement le code car pour comparer nos deux voitures, nous effectuons la comparaison sur la valeur d’un entier, ce qui est plutôt trivial. D’autant plus que l’entier, en bon objet comparable, possède également la méthode CompareTo(). Ce qui fait qu’il est possible d’écrire notre méthode de comparaison de cette façon :
public int CompareTo(object obj)
{
Voiture voiture = (Voiture)obj;
return Vitesse.CompareTo(voiture.Vitesse);
}
En effet, Vitesse étant un type intégré, il implémente déjà correctement la comparaison. C’est d’ailleurs pour ça que le tableau d’entier que nous avons vu précédemment a été capable de se trier facilement.
En ayant implémenté cette interface, nous pouvons désormais trier des tableaux de Voiture :
Voiture[] voitures = new Voiture[] { new Voiture { Vitesse = 100 }, new Voiture { Vitesse = 40 }, new Voiture { Vitesse = 10 }, new Voiture { Vitesse = 40 }, new Voiture { Vitesse = 50 } };
Array.Sort(voitures);
foreach (Voiture v in voitures)
{
Console.WriteLine(v.Vitesse);
}
Ce qui donne :
Voilà pour le tri, mais si je peux me permettre, je trouve que ce code-là est un peu moche. J’y reviendrai un peu plus tard.
Nous avons donc implémenté notre première interface. Finalement, ce n’était pas si compliqué. Voyons à présent comment créer nos propres interfaces. Une interface se définit en C# comme une classe, sauf qu’on utilise le mot-clé interface à la place de class. En tant que débutant, vous aurez rarement besoin de créer des interfaces. Cependant, il est utile de savoir le faire. Par contre, il sera beaucoup plus fréquent que vos classes implémentent des interfaces existantes du framework .NET, comme nous venons de le faire.
Voyons à présent comment créer une interface et examinons le code suivant :
public interface IVolant
{
int NombrePropulseurs { get; set; }
void Voler();
}
Nous définissons ici une interface IVolant qui possède une propriété de type int et une méthode Voler() qui ne renvoie rien. Voilà, c’est tout simple. :)
Nous avons créé une interface. Les objets qui choisiront d’implémenter cette interface seront obligés d’avoir une propriété entière NombrePropulseurs et une méthode Voler() qui ne renvoie rien. Rappelez-vous que l'interface ne contient que le contrat et aucune implémentation. C'est-à-dire que nous ne verrons jamais de corps de méthode dans une interface ni de variables membres ; uniquement des méthodes et des propriétés. Un contrat.
Notez quand même qu’il ne faut pas définir de visibilité sur les membres d’une interface. Nous serons obligés de définir les visibilités en public sur les objets implémentant l’interface.
Créons désormais deux objets Avion et Oiseau qui implémentent cette interface, ce qui donne :
public class Oiseau : IVolant
{
public int NombrePropulseurs { get; set; }
public void Voler()
{
Console.WriteLine("Je vole grâce à " + NombrePropulseurs + " ailes");
}
}
public class Avion : IVolant
{
public int NombrePropulseurs { get; set; }
public void Voler()
{
Console.WriteLine("Je vole grâce à " + NombrePropulseurs + " moteurs");
}
}
Grâce à ce contrat, nous savons maintenant que n’importe lequel de ces objets saura voler.
Il est possible de traiter ces objets comme des objets volants, un peu comme ce que nous avions fait avec les classes mères, en utilisant l’interface comme type pour la variable. Par exemple :
Nous instancions vraiment un objet Oiseau, mais nous le manipulons en tant que IVolant. Un des intérêts dans ce cas sera de pouvoir manipuler des objets qui partagent un comportement de la même façon :
Oiseau oiseau = new Oiseau { NombrePropulseurs = 2 };
Avion avion = new Avion { NombrePropulseurs = 4 };
List<IVolant> volants = new List<IVolant> { oiseau, avion };
foreach (IVolant volant in volants)
{
volant.Voler();
}
Ce qui produira :
Grâce à l’interface, nous avons pu mettre dans une même liste des objets différents, qui n’héritent pas entre eux mais qui partagent une même interface, c'est-à-dire un même comportement : IVolant. Pour accéder à ces objets, nous devrons utiliser leurs interfaces.
Il sera possible quand même de caster nos IVolant en Avion ou en Oiseau, si jamais nous souhaitons rajouter une propriété propre à l’avion. Par exemple je rajoute une propriété NomDuCommandant à mon avion mais qui ne fait pas partie de l’interface :
public class Avion : IVolant
{
public int NombrePropulseurs { get; set; }
public string NomDuCommandant { get; set; }
public void Voler()
{
Console.WriteLine("Je vole grâce à " + NombrePropulseurs + " moteurs");
}
}
Cela veut dire que l’objet Avion pourra affecter un nom de commandant mais qu’il ne sera pas possible d’y accéder par l’interface :
IVolant avion = new Avion { NombrePropulseurs = 4, NomDuCommandant = "Nico" };
Console.WriteLine(avion.NomDuCommandant); // erreur de compilation
L’erreur de compilation nous indique que IVolant ne possède pas de définition pour NomDuCommandant. Ce qui est vrai !
Pour accéder au nom du commandant, nous pourrons tenter de caster nos IVolant en Avion. Si le cast est valide, alors nous pourrons accéder à notre propriété :
Oiseau oiseau = new Oiseau { NombrePropulseurs = 2 };
Avion avion = new Avion { NombrePropulseurs = 4, NomDuCommandant = "Nico" };
List<IVolant> volants = new List<IVolant> { oiseau, avion };
foreach (IVolant volant in volants)
{
volant.Voler();
Avion a = volant as Avion;
if (a != null)
{
Console.WriteLine(a.NomDuCommandant);
}
}
Voilà, c’est tout simple et ça ressemble un peu à ce qu’on a déjà vu.
Il faut également noter que les interfaces peuvent hériter entre elles, comme c'est le cas avec les objets. C'est-à-dire que je vais pouvoir déclarer une interface IVolantMotorise qui hérite de l'interface IVolant.
public interface IVolant
{
int NombrePropulseurs { get; set; }
void Voler();
}
public interface IVolantMotorise : IVolant
{
void DemarrerLeMoteur();
}
Ainsi, ma classe Avion qui implémentera IVolantMotorise devra obligatoirement implémenter les méthodes/propriétés de IVolant ainsi que la méthode de IVolantMotorise :
public class Avion : IVolantMotorise
{
public void DemarrerLeMoteur()
{
}
public int NombrePropulseurs { get; set;}
public void Voler()
{
}
}
Enfin, et nous nous arrêterons là pour les interfaces, il est possible pour une classe d'implémenter plusieurs interfaces. Il suffira pour cela de séparer les interfaces par une virgule et d'implémenter bien sûr tout ce qu'il faut derrière. Par exemple :
public interface IVolant
{
void Voler();
}
public interface IRoulant
{
void Rouler();
}
public class Avion : IVolant, IRoulant
{
public void Voler()
{
Console.WriteLine("Je vole");
}
public void Rouler()
{
Console.WriteLine("Je Roule");
}
}
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une classe abstraite est une classe particulière qui ne peut pas être instanciée. Concrètement, cela veut dire que nous ne pourrons pas utiliser l’opérateur new. De la même façon, une méthode abstraite est une méthode qui ne contient pas d’implémentation, c’est-à-dire pas de code.
Pour être utilisables, les classes abstraites doivent être héritées et les méthodes redéfinies. En général, les classes abstraites sont utilisées comme classe de base pour d’autres classes. Ces classes fournissent des comportements mais n’ont pas vraiment d’utilité à avoir une vie propre. Ainsi, les classes filles qui en héritent pourront bénéficier de leurs comportements et devront éventuellement en remplacer d’autres.
C’est comme une classe incomplète qui ne demande qu’à être complétée.
Si une classe possède une méthode abstraite, alors la classe doit absolument être abstraite. L’inverse n’est pas vrai, une classe abstraite peut posséder des méthodes non abstraites. Vous aurez rarement besoin d’utiliser les classes abstraites en tant que débutant mais elles pourront vous servir pour combiner la puissance des interfaces à l’héritage.
Bon, voilà pour la théorie, passons un peu à la pratique.
Rappelez-vous nos chiens et nos chats qui dérivent d’une classe mère Animal. Nous savons qu’un Animal est capable de se déplacer. C’est un comportement qu’ont en commun tous les animaux. Il est tout à fait logique de définir une méthode SeDeplacer() au niveau de la classe Animal. Sauf qu’un chien ne se déplace pas forcément comme un dauphin. L’un a des pattes, l’autre des nageoires. Et même si le chien et le chat semblent avoir un déplacement relativement proche, ils ont chacun des subtilités. Le chat a un mouvement plus gracieux, plus félin.
Bref, on se rend compte que nous sommes obligés de redéfinir la méthode SeDeplacer() dans chaque classe fille de la classe Animal. Et puis de toute façon, sommes-nous vraiment capables de dire comment se déplace un animal dans l’absolu ?
La méthode SeDeplacer est une candidate parfaite pour être une méthode abstraite. Rappelez-vous, la méthode abstraite ne possède pas d’implémentation et chaque classe fille de la classe possédant cette méthode abstraite devra la spécialiser. C’est exactement ce qu’il nous faut.
Pour déclarer une méthode comme étant abstraite, il faut utiliser le mot-clé abstract et ne fournir aucune implémentation de la méthode, c'est-à-dire que la déclaration de la méthode doit se terminer par un point-virgule :
public class Animal
{
public abstract void SeDeplacer();
}
Si nous tentons de compiler cette classe, nous aurons l’erreur suivante :
'MaPremiereApplication.Animal.SeDeplacer()' est abstrait, mais est contenu dans la classe non abstraite 'MaPremiereApplication.Animal'
Ah oui c’est vrai, on a dit qu’une classe qui contient au moins une méthode abstraite était forcément abstraite. C’est le même principe que pour la méthode, il suffit d’utiliser le mot-clé abstract devant le mot-clé class :
public abstract class Animal
{
public abstract void SeDeplacer();
}
Voilà, notre classe peut compiler tranquillement.
Nous avons également dit qu’une classe abstraite pouvait contenir des méthodes concrètes et que c’était d’ailleurs une des grandes forces de ce genre de classes. En effet, il est tout à fait pertinent que des animaux puissent mourir. Et là, ça se passe pour tout le monde de la même façon, le cœur arrête de battre et on ne peut plus rien faire. C’est triste, mais c’est ainsi.
Cela veut dire que nous pouvons créer une méthode Mourir() dans notre classe abstraite qui possède une implémentation.
Cela donne :
public abstract class Animal
{
private Coeur coeur;
public Animal()
{
coeur = new Coeur();
}
public abstract void SeDeplacer();
public void Mourir()
{
coeur.Stop();
}
}
Avec une classe Cœur qui ne fait pas grand-chose :
public class Coeur
{
public void Battre()
{
Console.WriteLine("Boom boom");
}
public void Stop()
{
Console.WriteLine("Mon coeur s'arrête de battre");
}
}
Comme prévu, il n’est pas possible d’instancier un objet Animal. Si nous tentons l’opération :
Animal animal = new Animal();
nous aurons l’erreur de compilation suivante :
Impossible de créer une instance de la classe abstraite ou de l'interface 'MaPremiereApplication.Animal'
Par contre, il est possible de créer une classe Chien qui dérive de la classe Animal :
public class Chien : Animal
{
}
Cette classe ne pourra pas compiler dans cet état car il faut obligatoirement redéfinir la méthode abstraite SeDeplacer(). Cela se fait en utilisant le mot-clé override, comme on l’a déjà vu.
Vous aurez sûrement remarqué que la méthode abstraite n’utilise pas le mot-clé virtual comme cela doit absolument être le cas lors de la substitution d’une méthode dans une classe non-abstraite. Il est ici implicite et ne doit pas être utilisé, sinon nous aurons une erreur de compilation. Et puis cela nous arrange, un seul mot-clé, c’est largement suffisant !
Nous devons donc spécialiser la méthode SeDeplacer, soit en écrivant la méthode à la main, soit en utilisant encore une fois notre ami Visual C# Express. Il suffit de faire un clic droit sur la classe dont hérite Chien (en l’occurrence Animal) et de cliquer sur « Implémenter une classe abstraite » :
Visual C# Express nous génère donc la signature de la méthode à substituer :
public class Chien : Animal
{
public override void SeDeplacer()
{
throw new NotImplementedException();
}
}
Il ne reste plus qu’à écrire le corps de la méthode SeDeplacer, par exemple :
public class Chien : Animal
{
public override void SeDeplacer()
{
Console.WriteLine("Waouf ! Je me déplace avec mes 4 pattes");
}
}
Ainsi, nous pourrons créer un objet Chien et le faire se déplacer puis le faire mourir car il hérite des comportements de la classe Animal. Paix à son âme.
Chien max = new Chien();
max.SeDeplacer();
max.Mourir();
ce qui donnera :
Vous pouvez désormais vous rendre compte de la réalité de la phrase que j’ai écrite en introduction :
« [Les classes abstraites] pourront vous servir pour combiner la puissance des interfaces à l’héritage ».
En effet, la classe abstraite peut fournir des implémentations alors que l’interface ne propose qu’un contrat. Cependant, une classe concrète ne peut hériter que d’une seule classe mais peut implémenter plusieurs interfaces.
La classe abstraite est un peu à mi-chemin entre l’héritage et l’interface.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les classes partielles offrent la possibilité de définir une classe en plusieurs fois. En général, ceci est utilisé pour définir une classe sur plusieurs fichiers, si par exemple la classe devient très longue. Il pourra éventuellement être judicieux de découper la classe en plusieurs fichiers pour regrouper des fonctionnalités qui se ressemblent. On utilise pour cela le mot-clé partial.
Par exemple, si nous avons un fichier qui contient la classe Voiture suivante :
public partial class Voiture
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
}
Nous pourrons compléter sa définition dans un autre fichier pour lui rajouter par exemple des méthodes :
public partial class Voiture
{
public string Rouler()
{
return "Je roule à " + Vitesse + " km/h";
}
}
À la compilation, Visual C# Express réunit les deux classes en une seule et l’objet fonctionne comme toute autre classe qui ne serait pas forcément partielle.
À noter qu’il faut impérativement que les deux classes possèdent le mot-clé partial pour que cela soit possible, sinon Visual C# Express génèrera une erreur de compilation :
Modificateur partiel manquant sur la déclaration de type 'MaPremiereApplication.Voiture' ; une autre déclaration partielle de ce type existe
Vous allez me dire que ce n’est pas super utile comme fonctionnalité. Et je vous dirais que vous avez raison. Sauf dans un cas particulier.
Les classes partielles prennent de l’intérêt quand une partie du code de la classe est généré par Visual C# Express. C’est le cas pour la plupart des plateformes qui servent à développer des vraies applications. Par exemple ASP.NET pour un site internet, WPF pour une application Windows, Silverlight pour un client riche, etc. C’est aussi le cas lorsque nous générons de quoi permettre d’accéder à une base de données.
Dans ce cas-là, disons pour simplifier que Visual C# Express va nous générer tout un tas d’instructions pour nous connecter à la base de données ou pour récupérer des données. Toutes ces instructions seront mises dans une classe partielle que nous pourrons enrichir avec nos besoins.
L’intérêt est que si nous re-générons une nouvelle version de notre classe, seul le fichier généré sera impacté. Si nous avions modifié le fichier pour enrichir la classe avec nos besoins, nous aurions perdu tout notre travail. Vu que grâce aux classes partielles, ce code est situé dans un autre fichier, il n’est donc pas perdu. Pour notre plus grand bonheur !
À noter que le mot-clé partial peut se combiner sans problèmes avec d’autres mots-clés, comme abstract par exemple que nous venons de voir. Il est fréquent aussi de voir des classes partielles utilisées quand plusieurs développeurs travaillent sur la même classe. Le fait de séparer la classe en deux fichiers permet de travailler sans se marcher dessus.
Nous aurons l’occasion de voir des classes partielles générés plus tard dans le tutoriel.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons déjà vu le mot-clé static en première partie de ce tutoriel. Il nous a bien encombrés. Nous nous le sommes trimballé pendant un moment, puis il a disparu ! Il est temps de revenir sur ce mot-clé afin de comprendre exactement de quoi il s’agit, maintenant que nous avons plus de notions et que nous connaissons les objets et les classes.
Jusqu’à présent, nous avons utilisé le mot-clé static uniquement sur les méthodes et j’ai vaguement expliqué qu’il servait à indiquer que la méthode est toujours disponible et prête à être utilisée. Pas très convaincant, comme explication… mais comme vous êtes polis, vous ne m’aviez rien dit. ;)
En fait, le mot-clé static permet d’indiquer que la méthode d’une classe n’appartient pas à une instance de la classe. Nous avons vu que jusqu’à présent, nous devions instancier nos classes avec le mot-clé new pour avoir des objets.
Ici, static permet de ne pas instancier l’objet mais d’avoir accès à cette méthode en dehors de tout objet. Nous avons déjà utilisé beaucoup de méthodes statiques, je ne sais pas si vous avez fait attention, mais maintenant que vous connaissez les objets, la méthode suivante ne vous paraît pas bizarre ?
Console.WriteLine("Bonjour");
Nous utilisons la méthode WriteLine de la classe Console sans avoir créé d’objet Console. Étrange. o_O
Il s’agit, vous l’aurez deviné, d’une méthode statique qui est accessible en dehors de toute instance de Console. D’ailleurs, la classe entière est une classe statique. Si nous essayons d’instancier la classe Console avec :
Console c = new Console();
Nous aurons les messages d’erreurs suivant :
Impossible de déclarer une variable de type static 'System.Console'
Impossible de créer une instance de la classe static 'System.Console'
Nous avons dit que la méthode spéciale Main() est obligatoirement statique. Cela permet au CLR, qui va exécuter notre application, de ne pas avoir besoin d’instancier la classe Program pour démarrer notre application. Il a juste à appeler la méthode Program.Main() afin de démarrer notre programme.
Comme la méthode Main() est utilisable en dehors de toute instance de classe, elle ne peut appeler que des méthodes statiques. En effet, comment pourrait-elle appeler des méthodes d’un objet alors qu’elle n’en a même pas conscience ? C’est pour cela que nous avons été obligés de préfixer chacune de nos premières méthodes par le mot-clé static.
Revenons à nos objets. Ils peuvent contenir des méthodes statiques ou des variables statiques. Si une classe ne contient que des choses statiques alors elle peut devenir également statique.
Une méthode statique est donc une méthode qui ne travaille pas avec les membres (variables ou autres) non statiques de sa propre classe. Rappelez-vous un peu plus haut, nous avions créé une classe Math qui servait à faire des additions, afin d’illustrer le polymorphisme :
public class Math
{
public int Addition(int a, int b)
{
return a + b;
}
}
que nous utilisions de cette façon :
Math math = new Math();
int resultat = math.Addition(5, 6);
Ici, la méthode addition sert à additionner 2 entiers. Elle est complètement indépendante de la classe Math et donc des instances de l’objet Math. Nous pouvons donc en faire une méthode statique, pour cela il suffira de préfixer du mot-clé static son type de retour :
public class Math
{
public static int Addition(int a, int b)
{
return a + b;
}
}
Et nous pourrons alors utiliser l’addition sans créer d’instance de la classe Math, mais simplement en utilisant le nom de la classe suivi du nom de la méthode statique :
int resultat = Math.Addition(5, 6);
Exactement comme nous avons fait pour Console.WriteLine. De la même façon, nous pouvons rajouter d’autres méthodes, comme la multiplication :
public class Math
{
public static int Addition(int a, int b)
{
return a + b;
}
public static long Multiplication(int a, int b)
{
return a * b;
}
}
Que nous appellerons de la même façon :
long resultat = Math.Multiplication(5, 6);
À noter que la classe Mathest toujours instanciable mais qu’il n’est pas possible d’appeler les méthodes qui sont statiques depuis un objet Math. Le code suivant :
Math math = new Math();
long resultat = math.Multiplication(5, 6);
provoquera l’erreur de compilation :
Le membre 'MaPremiereApplication.Math.Multiplication(int, int)' est inaccessible avec une référence d'instance ; qualifiez-le avec un nom de type
Ok, mais à quoi ça sert de pouvoir instancier un objet Math si nous ne pouvons accéder à aucune de ses méthodes, vu qu’elles sont statiques ?
Absolument à rien ! Si une classe ne possède que des membres statiques, alors il est possible de rendre cette classe statique grâce au même mot-clé. Celle-ci deviendra non-instanciable, comme la classe Console :
public static class Math
{
public static int Addition(int a, int b)
{
return a + b;
}
}
Ainsi, si nous tentons d’instancier l’objet Math, nous aurons une erreur de compilation. En général, les classes statiques servent à regrouper des méthodes utilitaires qui partagent une même fonctionnalité. Ici, la classe Math permettrait d’y ranger toutes les méthodes du style addition, multiplication, racine carrée, etc …
Ah, on me fait signe que cette classe existe déjà dans le framework .NET et qu’elle s’appelle également Math. Elle est rangée dans l’espace de nom System. Souvenez-vous, nous l’avons utilisée pour calculer la racine carrée. Cette classe est statique, c’est la version aboutie de la classe que nous avons commencé à écrire.
Par contre, ce n’est pas parce qu’une classe possède des méthodes statiques qu’elle est obligatoirement statique. Il est aussi possible d’avoir des membres statiques dans une classe qui possède des membres non statiques.
Par exemple notre classe Chien, qui possède un prénom et qui sait aboyer :
public class Chien
{
private string prenom;
public Chien(string prenomDuChien)
{
prenom = prenomDuChien;
}
public void Aboyer()
{
Console.WriteLine("Wouaf ! Je suis " + prenom);
}
}
pourrait posséder une méthode permettant de calculer l’âge d’un chien dans le référentiel des humains. Comme beaucoup le savent, il suffit de multiplier l’âge du chien par 7.
public class Chien
{
private string prenom;
public Chien(string prenomDuChien)
{
prenom = prenomDuChien;
}
public void Aboyer()
{
Console.WriteLine("Wouaf ! Je suis " + prenom);
}
public static int CalculerAge(int ageDuChien)
{
return ageDuChien * 7;
}
}
Ici, la méthode CalculerAge() est statique car elle ne travaille pas directement avec une instance d’un chien. Nous pouvons l’appeler ainsi :
Chien hina = new Chien("Hina");
hina.Aboyer();
int ageReferentielHomme = Chien.CalculerAge(4);
Console.WriteLine(ageReferentielHomme);
Ce qui donne :
Vous me direz qu’il est possible de faire en sorte que la méthode travaille sur une instance d’un objet Chien, ce qui serait peut-être plus judicieux ici. Il suffirait de rajouter une propriété Age au Chien et de transformer la méthode pour qu’elle ne soit plus statique. Ce qui donnerait :
public class Chien
{
private string prenom;
public int Age { get; set; }
public Chien(string prenomDuChien)
{
prenom = prenomDuChien;
}
public void Aboyer()
{
Console.WriteLine("Wouaf ! Je suis " + prenom);
}
public int CalculerAge()
{
return Age * 7;
}
}
Que l’on pourrait appeler de cette façon :
Chien hina = new Chien("Hina") { Age = 5 };
int ageReferentielHomme = hina.CalculerAge();
Console.WriteLine(ageReferentielHomme);
Ici, c’est plus une histoire de conception. C’est à vous de décider, mais sachez que c’est possible. Il est également possible d’utiliser le mot-clé static avec des propriétés. Imaginions que nous souhaitions avoir un compteur sur le nombre d’instances de la classe Chien. Nous pourrions créer une propriété statique de type entier qui s’incrémente à chaque fois que l’on crée un nouveau chien :
public class Chien
{
public static int NombreDeChiens { get; set; }
private string prenom;
public Chien(string prenomDuChien)
{
prenom = prenomDuChien;
NombreDeChiens++;
}
public void Aboyer()
{
Console.WriteLine("Wouaf ! Je suis " + prenom);
}
}
Ici, la propriété NombreDeChiens est statique et est incrémentée à chaque passage dans le constructeur. Ainsi, si nous créons plusieurs chiens :
Chien chien1 = new Chien("Max");
Chien chien2 = new Chien("Hina");
Chien chien3 = new Chien("Laika");
Console.WriteLine(Chien.NombreDeChiens);
Nous pourrons voir combien de fois nous sommes passés dans le constructeur :
Pour une variable statique, cela se passe de la même façon qu'avec les propriétés statiques.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les classes internes (nested class en anglais) sont un mécanisme qui permet d’avoir des classes définies à l’intérieur d’autres classes. Cela peut être utile si vous souhaitez restreindre l’accès d’une classe uniquement à sa classe mère.
Par exemple :
public class Chien
{
private Coeur coeur = new Coeur();
public void Mourir()
{
coeur.Stop();
}
private class Coeur
{
public void Stop()
{
Console.WriteLine("The end");
}
}
}
Ici, la classe Cœur ne peut être utilisée que par la classe Chien car elle est privée. Nous pourrions également mettre la classe en protected afin qu’une classe dérivée de la classe Chien puisse également utiliser la classe Cœur :
public class ChienSamois : Chien
{
private Coeur autreCoeur = new Coeur();
}
Avec ces niveaux de visibilité, une autre classe comme la classe Chat ne pourra pas se servir de ce cœur. Si nous mettons la classe Cœur en public ou internal, elle sera utilisable par tout le monde ; comme une classe normale. Dans ce cas, nos chats pourront avoir :
public class Chat
{
private Chien.Coeur coeur = new Chien.Coeur();
public void Mourir()
{
coeur.Stop();
}
}
Notez que nous préfixons la classe par le nom de la classe qui contient la classe Cœur. Dans ce cas, l’intérêt d’utiliser une classe interne est moindre. Cela permet éventuellement de regrouper les classes de manière sémantique, et encore, c’est plutôt le but des espaces de noms. Voilà pour les classes internes. C’est une fonctionnalité souvent peu utilisée, mais voilà, vous la connaissez désormais :D .
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Le mot-clé var est un truc de feignant ! :D Il permet de demander au compilateur de déduire le type d’une variable au moment où nous la déclarons.
Par exemple le code suivant :
var prenom = "Nicolas";
var age = 30;
est équivalent au code suivant :
string prenom = "Nicolas";
int age = 30;
Le mot-clé var sert à indiquer que nous ne voulons pas nous préoccuper de ce qu’est le type et que c’est au compilateur de le trouver.
Cela implique qu’il faut que la variable soit initialisée (et non nulle) au moment où elle est déclarée afin que le compilateur puisse déduire le type de la variable, en l’occurrence, il devine qu’en lui affectant « Nicolas », il s’agit d’une chaîne de caractères.
Je ne recommande pas l’utilisation de ce mot-clé, car le fait de ne pas mettre le type de la variable fait perdre de la clarté au code. Ici, c’est facile. On déduit facilement nous aussi que le type de prenom est string et que le type de age est int. Mais c’est aussi parce qu’on est trop fort ! :p
Par contre, si jamais la variable est initialisée grâce à une méthode :
var calcul = GetCalcul();
il va falloir aller regarder la définition de la méthode afin de savoir le type de retour et connaitre ainsi le type de la variable. Des contraintes dont on n’a pas besoin alors qu’il est aussi simple d’indiquer le vrai type et que c’est d’autant plus lisible.
Mais alors, pourquoi en parler ?
Parce que ce mot-clé peut servir dans un cas précis, celui des types anonymes. Lorsqu’il est conjointement utilisé avec l’opérateur new, il permet de créer des types anonymes, c'est-à-dire des types dont on n’a pas défini la classe au préalable. Une classe sans nom.
Cette classe est déduite grâce à son initialisation :
var unePersonneAnonyme = new { Prenom = "Nico", Age = 30 };
Ici nous créons une variable qui contient une propriété Prenom et une propriété Age. Forcément, il est impossible de donner un type à cette variable vu qu’elle n’a pas de définition. C’est pour cela qu’on utilise le mot-clé var. On sait juste que la variable unePersonneAnonyme possède deux propriétés, un prénom et un âge. En interne, le compilateur va générer un nom de classe pour ce type anonyme, mais il n’a pas de sens pour nous.
En l’occurrence, si nous écrivons le code suivant où GetType() (hérité de la classe object) renvoie le nom du type :
var unePersonneAnonyme = new { Prenom = "Nico", Age = 30 };
Console.WriteLine(unePersonneAnonyme.GetType());
nous aurons :
Ce qui est effectivement sans intérêt pour nous !
Jusqu’ici, les types anonymes peuvent sembler ne pas apporter d’intérêt, tant il est simple de définir une classe Personne possédant une propriété Prenom et une propriété Age. Mais cela permet d’utiliser ces classes comme des classes à usage unique lorsque nous ne souhaitons pas nous encombrer d’un fichier possédant une classe qui va nous servir uniquement à un seul endroit.
Paresse, souci de clarté du code, … tout ceci est un peu mêlé dans la création d’un type anonyme. À vous de l’utiliser quand bon vous semble. Vous verrez plus tard que les types anonymes sont souvent utilisés dans les méthodes d’extensions Linq. Nous en reparlerons.
À noter que lorsque nous créons un tableau, par exemple :
string[] jours = new string[] { "Lundi", "Mardi", "Mercredi", "Jeudi", "Vendredi", "Samedi", "Dimanche" };
c'est-à-dire sans préciser le type du tableau après le new. Le compilateur déduit le type à partir de l'initialisation. Ce n'est pas un type anonyme en soit, mais le principe de déduction est le même.
En résumé
Une interface est un contrat que s'engage à respecter un objet.
Il est possible d'implémenter plusieurs interfaces dans une classe.
Une classe abstraite est une classe qui possède au moins une méthode ou propriété abstraite. Elle ne peut pas être instanciée.
Une classe concrète dérivant d'une classe abstraite est obligée de substituer les membres abstraits.
Il est possible de créer des types anonymes grâce à l'opérateur new suivi de la description des propriétés de ce type. Les instances sont manipulées grâce au mot-clé var.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce TP, nous allons essayer de mettre en pratique ce que nous avons appris en programmation orientée objet avec le C#.
Difficile d’avoir un exercice qui nécessite toutes les notions que nous avons apprises. Aussi, certaines sont laissées de côté. Avec ce TP, vous aurez l'occasion de vous entraîner à créer des classes, à manipuler l’héritage et vous pourrez vous confronter à des situations un peu différentes de la théorie !
Le but du TP est de créer une mini application de gestion bancaire où nous pourrons gérer des comptes qui peuvent faire des opérations bancaires entre eux. Ne vous attendez pas non plus à refaire les applications de la banque de France, on est là pour s'entrainer. ;) Ce TP sera décomposé en deux parties.
Dans notre mini application bancaire tous les montants utilisés seront des décimaux. Nous allons devoir gérer des comptes bancaires. Un compte est composé :
D’un Solde (calculé, mais non modifiable) ;
D’un Propriétaire (nom du propriétaire du compte) ;
D’une liste d’opérations interne permettant de garder l’historique du compte, non accessible par les autres objets ;
D’une méthode permettant de Crediter() le compte, prenant une somme en paramètre ;
D’une méthode permettant de Crediter() le compte, prenant une somme et un compte en paramètres, créditant le compte et débitant le compte passé en paramètres ;
D’une méthode permettant de Debiter() le compte, prenant une somme en paramètre ;
D’une méthode permettant de Débiter() le compte, prenant une somme et un compte bancaire en paramètres, débitant le compte et créditant le compte passé en paramètres ;
D’une méthode qui permet d’afficher le résumé d’un compte.
Un compte courant est une sorte de compte et est composé :
De tout ce qui compose un compte ;
D’un découvert autorisé, non modifiable, défini à l’ouverture du compte ;
Le résumé d’un compte courant affiche le solde, le propriétaire, le découvert autorisé ainsi que les opérations sur le compte.
Un compte épargne entreprise est une sorte de compte et est composé :
De tout ce qui compose un compte ;
D’un taux d’abondement, défini à l’ouverture du compte en fonction de l’ancienneté du salarié. Un taux est un double compris entre 0 et 1. (5% = 0.05) ;
Une opération bancaire est composée :
D’un montant ;
D’un type de mouvement, crédit ou débit.
Créer une telle application avec les informations suivantes :
Le compte courant de Nicolas a un découvert autorisé de 2000€
Le compte épargne entreprise de Nicolas a un taux de 2%
Le compte courant de Jérémie a un découvert autorisé de 500€
Nicolas touche son salaire de 100€, pas cher payé !
Il fait le plein de sa voiture : 50€
Il met de côté sur son compte épargne entreprise la coquette somme de 20€
Puis il reçoit un cadeau de la banque de 100€ car il a ouvert son compte pendant la période promotionnelle
Il remet ses 20€ sur son compte bancaire car finalement, il ne se sent pas méga en sécurité
Jérémie achète un nouveau PC : 500€
Puis il rembourse ses dettes à Nicolas : 200€
L’application doit indiquer les soldes de chacun de ces comptes :
Solde compte courant de Nicolas : 250
Solde compte épargne de Nicolas : 102,00
Solde compte courant de Jérémie : -700
Ensuite, nous afficherons le résumé du compte courant de Nicolas et de son compte épargne entreprise. Ce qui nous donnera :
Résumé du compte de Nicolas
*******************************************
Compte courant de Nicolas
Solde : 250
Découvert autorisé : 2000
Opérations :
+100
-50
-20
+20
+200
*******************************************
Résumé du compte épargne de Nicolas
########################################################
Compte épargne entreprise de Nicolas
Solde : 102,00
Taux : 0,02
Opérations :
+20
+100
-20
########################################################
Bon, j’ai bien expliqué, ce n’est pas si compliqué, sauf si bien sûr vous n’avez pas lu ou pas compris les chapitres précédents. Dans ce cas, n’hésitez pas à y rejeter un coup d’œil. Sinon, il suffit de bien décomposer tout en créant les classes les unes après les autres.
Bon courage ! :)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ne regardez pas tout de suite la correction. Faites le TP. Il est important de manipuler les classes. Vous allez faire ça très régulièrement. Cela doit devenir un réflexe et pour que cela le devienne, il faut pratiquer !
Toujours est-il que voici ma correction. Peut-être que le plus dur est de modéliser correctement l’application ? Il y a plusieurs solutions bien sûr pour créer ce petit programme, voici celle que je propose.
Tout d’abord, nous devons manipuler des comptes courant et des comptes épargne entreprise, qui sont des sortes de comptes. On en déduit qu’un compte courant hérite d’un compte. De même, un compte épargne entreprise hérite également d’un compte. D’ailleurs, un compte a-t-il vraiment une raison d’être à part entière ? Nous ne créons jamais de compte « généraliste », seulement des comptes spécialisés. Nous allons donc créer la classe compte en tant que classe abstraite.
Ce qui nous donnera les classes suivantes :
public abstract class Compte
{
}
public class CompteCourant : Compte
{
}
public class CompteEpargneEntreprise : Compte
{
}
Nous avons également dit qu’un compte était composé d’une liste d’opérations qui possèdent un montant et un type de mouvement. Le type de mouvement pouvant prendre 2 valeurs, il parait logique d’utiliser une énumération :
public enum Mouvement
{
Credit,
Debit
}
La classe d’opération étant :
public class Operation
{
public Mouvement TypeDeMouvement { get; set; }
public decimal Montant { get; set; }
}
Voilà pour la base.
Ensuite, la classe Compte doit posséder un nom de propriétaire et un solde qui peut être redéfini dans la classe CompteEpargneEntreprise. Ce solde est calculé à partir d’une liste d’opérations. Le solde est donc une propriété en lecture seule, virtuelle car nécessitant d’être redéfinie :
public abstract class Compte
{
protected List<Operation> listeOperations;
public string Proprietaire { get; set; }
public virtual decimal Solde
{
get
{
decimal total = 0;
foreach (Operation operation in listeOperations)
{
if (operation.TypeDeMouvement == Mouvement.Credit)
total += operation.Montant;
else
total -= operation.Montant;
}
return total;
}
}
}
La liste des opérations est une variable membre, déclarée en protected car nous allons en avoir besoin dans la classe CompteCourant qui en hérite, afin d’afficher un résumé des opérations.
La propriété Solde n’est pas très compliquée en soit, il suffit de parcourir la liste des opérations et en fonction du type de mouvement, ajouter ou retrancher le montant. Comme c’est une propriété en lecture seule, seul le get est défini.
N’oubliez pas que la liste doit être initialisée avant d’être utilisée, sinon nous aurons une erreur. Le constructeur est un endroit approprié pour le faire :
public abstract class Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public Compte()
{
listeOperations = new List<Operation>();
}
}
La classe doit ensuite posséder des méthodes permettant de créditer ou de débiter le compte, ce qui donne :
public abstract class Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public void Crediter(decimal montant)
{
Operation operation = new Operation { Montant = montant, TypeDeMouvement = Mouvement.Credit};
listeOperations.Add(operation);
}
public void Crediter(decimal montant, Compte compte)
{
Crediter(montant);
compte.Debiter(montant);
}
public void Debiter(decimal montant)
{
Operation operation = new Operation { Montant = montant, TypeDeMouvement = Mouvement.Debit };
listeOperations.Add(operation);
}
public void Debiter(decimal montant, Compte compte)
{
Debiter(montant);
compte.Crediter(montant);
}
}
Le principe est de créer une opération et de l’ajouter à la liste des opérations. L’astuce ici consiste à réutiliser les méthodes de la classe pour écrire les autres formes des méthodes, ce qui simplifie le travail et facilitera les éventuelles futures opérations de maintenance.
Enfin, chaque classe dérivée de la classe Compte doit afficher un résumé du compte. Nous pouvons donc forcer ces classes à devoir implémenter cette méthode en utilisant une méthode abstraite :
public abstract class Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public abstract void AfficherResume();
}
Voilà pour la classe Compte. En toute logique, c’est elle qui contient le plus de méthodes afin de factoriser le maximum de code commun dans la classe mère.
Passons à la classe CompteEpargneEntreprise, qui hérite de la classe Compte. Elle possède un taux d’abondement qui est défini à la création du compte. Il est donc ici intéressant de forcer le positionnement de ce taux lors de la création de la classe, c'est-à-dire en utilisant un constructeur avec un paramètre :
public class CompteEpargneEntreprise : Compte
{
private double tauxAbondement;
public CompteEpargneEntreprise(double taux)
{
tauxAbondement = taux;
}
}
Ce taux est utilisé pour calculer le solde du compte en faisant la somme de toutes les opérations et en appliquant le taux. Ce qui revient à appeler le calcul du solde de la classe mère et à lui appliquer le taux. Nous substituons donc la propriété Solde et utilisons le calcul fait dans la classe Compte:
public class CompteEpargneEntreprise : Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public override decimal Solde
{
get
{
return base.Solde * (decimal)(1 + tauxAbondement);
}
}
}
Rien de plus simple, en utilisant le mot-clé base pour appeler le solde de la classe mère. Vous noterez également que nous avons eu besoin de caster le taux qui est un double afin de pouvoir le multiplier à un décimal.
Enfin, cette classe se doit de fournir une implémentation de la méthode AfficherResume() :
public class CompteEpargneEntreprise : Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public override void AfficherResume()
{
Console.WriteLine("########################################################");
Console.WriteLine("Compte épargne entreprise de " + Proprietaire);
Console.WriteLine("\tSolde : " + Solde);
Console.WriteLine("\tTaux : " + tauxAbondement);
Console.WriteLine("\n\nOpérations :");
foreach (Operation operation in listeOperations)
{
if (operation.TypeDeMouvement == Mouvement.Credit)
Console.Write("\t+");
else
Console.Write("\t-");
Console.WriteLine(operation.Montant);
}
Console.WriteLine("########################################################");
}
}
Il s’agit d’une banale méthode d’affichage où nous parcourons la liste contenant les opérations et affichons le montant en fonction du type de mouvement. Voilà pour la classe CompteEpargneEntreprise.
Il ne reste plus que la classe CompteCourant qui doit également dériver de Compte :
public class CompteCourant : Compte
{
}
Un compte courant doit posséder un découvert autorisé, défini à la création du compte courant. Nous utilisons comme avant un constructeur avec un paramètre :
public class CompteCourant : Compte
{
private decimal decouvertAutorise;
public CompteCourant(decimal decouvert)
{
decouvertAutorise = decouvert;
}
}
Il ne restera plus qu’à fournir une implémentation de la méthode d’affichage du résumé :
public class CompteCourant : Compte
{
// [...]
// [Code précédent enlevé pour plus de lisibilité]
// [...]
public override void AfficherResume()
{
Console.WriteLine("*******************************************");
Console.WriteLine("Compte courant de " + Proprietaire);
Console.WriteLine("\tSolde : " + Solde);
Console.WriteLine("\tDécouvert autorisé : " + decouvertAutorise);
Console.WriteLine("\n\nOpérations :");
foreach (Operation operation in listeOperations)
{
if (operation.TypeDeMouvement == Mouvement.Credit)
Console.Write("\t+");
else
Console.Write("\t-");
Console.WriteLine(operation.Montant);
}
Console.WriteLine("*******************************************");
}
}
Voilà pour nos objets. Cela en fait un petit paquet. Mais ce n’est pas fini, il faut maintenant créer des comptes et faire des opérations.
L’énoncé consiste à faire les instanciations suivantes, depuis notre méthode Main() :
CompteCourant compteNicolas = new CompteCourant(2000) { Proprietaire = "Nicolas" };
CompteEpargneEntreprise compteEpargneNicolas = new CompteEpargneEntreprise(0.02) { Proprietaire = "Nicolas" };
CompteCourant compteJeremie = new CompteCourant(500) { Proprietaire = "Jérémie" };
compteNicolas.Crediter(100);
compteNicolas.Debiter(50);
compteEpargneNicolas.Crediter(20, compteNicolas);
compteEpargneNicolas.Crediter(100);
compteEpargneNicolas.Debiter(20, compteNicolas);
compteJeremie.Debiter(500);
compteJeremie.Debiter(200, compteNicolas);
Console.WriteLine("Solde compte courant de " + compteNicolas.Proprietaire + " : " + compteNicolas.Solde);
Console.WriteLine("Solde compte épargne de " + compteEpargneNicolas.Proprietaire + " : " + compteEpargneNicolas.Solde);
Console.WriteLine("Solde compte courant de " + compteJeremie.Proprietaire + " : " + compteJeremie.Solde);
Console.WriteLine("\n");
Rien d’extraordinaire.
Il ne reste plus qu’à afficher le résumé des deux comptes demandés :
Console.WriteLine("Résumé du compte de Nicolas");
compteNicolas.AfficherResume();
Console.WriteLine("\n");
Console.WriteLine("Résumé du compte épargne de Nicolas");
compteEpargneNicolas.AfficherResume();
Console.WriteLine("\n");
Nous en avons fini avec la première partie du TP ! Si vous avez bien compris comment construire des classes, comment les faire hériter entre elles et les interfaces, ce TP n’a pas dû vous poser trop de problèmes. :)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il y a plusieurs choses que je n’aime pas dans ce code. La première est la répétition. Dans les deux méthodes AfficherResume() des classes CompteCourant et CompteEpargneEntreprise on affiche les opérations de la même façon. Si jamais je dois modifier ce code (bug ou évolution), je devrais le faire dans les deux classes, au risque d’en oublier une. Il faut donc factoriser ce code. Il existe pour cela plusieurs solutions simples.
La première est d’utiliser une méthode statique pour afficher la liste des opérations. Cette méthode pourrait être située dans une classe utilitaire qui prend en paramètre la liste des opérations :
public static class Helper
{
public static void AfficheOperations(List<Operation> operations)
{
Console.WriteLine("\n\nOpérations :");
foreach (Operation operation in operations)
{
if (operation.TypeDeMouvement == Mouvement.Credit)
Console.Write("\t+");
else
Console.Write("\t-");
Console.WriteLine(operation.Montant);
}
}
}
Il ne reste plus qu’à utiliser cette méthode statique depuis nos méthodes AfficherResume(), par exemple pour le compte épargne entreprise :
La deuxième solution est de créer la méthode AfficheOperations() dans la classe abstraite Compte, ce qui permet de s’affranchir de passer la liste en paramètres vu que la classe Compte la connait déjà :
La méthode a tout intérêt à être déclarée en protected, afin qu’elle puisse servir aux classes filles mais pas à l’extérieur. Elle s’utilisera de cette façon, par exemple dans la classe CompteEpargneEntreprise :
Dès que l’on peut factoriser du code, il ne faut pas hésiter. Si nous avons demain besoin de créer un nouveau type de compte, nous serons ravis de pouvoir nous servir de méthodes toutes prêtes nous simplifiant le travail.
Il pourrait être intéressant également d'encapsuler l'enregistrement d'une opération dans une méthode. Ce qui permet de moins se répéter (même si ici, le code est vraiment petit) mais qui permet surtout de séparer la logique d'enregistrement d'une opération afin que cela soit plus facile ultérieurement à modifier, maintenir ou complexifier. Par exemple, via une méthode :
Nous voici maintenant dans la deuxième partie du TP. La banque souhaite proposer un nouveau type de compte, le livret ToutBénef. Dans cette banque, le livret ToutBénéf fonctionne comme le compte épargne entreprise. C’est-à-dire qu’il accepte un taux en paramètres et applique ce taux au moment de la restitution du solde.
La première idée qui vient à l’esprit est créer une classe LivretToutBenef qui hérite de CompteEpargneEntreprise. Mais ceci pose un problème si jamais le compte épargne entreprise doit évoluer, et c’est justement ce que le directeur de la banque vient de me confier. Donc, il vous interdit à juste titre d’hériter de ses fonctionnalités.
Ce que vous allez donc faire ici, c’est de considérer que le fait qu’un compte puisse faire des bénéfices soit en fait un comportement qui est fourni au moment où on instancie un compte. Il existe plusieurs comportements dont on doit fournir les implémentations :
Le comportement de bénéfice à taux fixe
Le comportement de bénéfice aléatoire
Le comportement où il n’y a aucun bénéfice
Chaque comportement est une classe qui respecte le contrat suivant :
Écrivez donc ces trois classes de comportement ainsi que le livret ToutBénéf qui possède un taux fixe de 2.75% et qui a été crédité une première fois de 800€ et une seconde fois de 200€. Affichez enfin son résumé qui devra tenir compte du taux du calculateur de bénéfice. Réécrivez ensuite la classe CompteCourant de manière à ce qu’elle ait un comportement où il n’y a pas de bénéfice. Enfin, la classe CompteEpargneEntreprise subira une évolution pour fonctionner avec un comportement de bénéfice aléatoire (tiré entre 0 et 1).
C’est parti.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ici c’est un peu plus compliqué. Vous n’êtes sans doute pas complètement familiers avec les notions d’interfaces, aussi avant de vous livrer la correction, je vais vous donner quelques pistes. Le fait d’avoir un comportement est finalement très simple. Il suffit d’avoir un membre privé dans la classe LivretToutBenef du type de l’interface. Ce membre privé sera affecté à la valeur passée en paramètre du constructeur. C’est-à-dire :
public class LivretToutBenef : Compte
{
private ICalculateurDeBenefice calculateurDeBenefice;
public LivretToutBenef(ICalculateurDeBenefice calculateur)
{
calculateurDeBenefice = calculateur;
}
}
Désormais, les opérations devront se faire avec cette variable, calculateurDeBenefice. On aura également besoin d’instancier au préalable le comportement voulu et de le passer en paramètres du constructeur. Retournez donc tenter de réaliser ce TP avant de voir la suite de la correction ;) .
C’est fait ? Alors voici ma correction. Nous avions donc cette interface imposée :
Nous avons besoin d’écrire plusieurs classes qui implémentent cette interface. La première est la classe de bénéfice à taux fixe :
public class BeneficeATauxFixe : ICalculateurDeBenefice
{
private double taux;
public BeneficeATauxFixe(double tauxFixe)
{
taux = tauxFixe;
}
public decimal CalculeBenefice(decimal solde)
{
return solde * (decimal)(1 + taux);
}
public double Taux
{
get
{
return taux;
}
}
}
Nous avons dit qu’elle devait prendre un taux en paramètres, le constructeur est l’endroit indiqué pour cela. Ensuite, la méthode de calcul est très simple, il suffit d’appliquer la formule au solde. Enfin, la propriété retourne le taux.
La classe suivante est la classe de bénéfice aléatoire. Là, pas besoin de paramètres, il suffit de tirer le nombre aléatoire dans le constructeur grâce à la méthode NextDouble(), ce qui donne :
public class BeneficeAleatoire : ICalculateurDeBenefice
{
private double taux;
private Random random;
public BeneficeAleatoire()
{
random = new Random();
taux = random.NextDouble();
}
public decimal CalculeBenefice(decimal solde)
{
return solde * (decimal)(1 + taux);
}
public double Taux
{
get
{
return taux;
}
}
}
Enfin, il faudra créer la classe avec aucun bénéfice :
public class AucunBenefice : ICalculateurDeBenefice
{
public decimal CalculeBenefice(decimal solde)
{
return solde;
}
public double Taux
{
get
{
return 0;
}
}
}
Rien de sorcier ! Là où cela se complique un peu, c’est pour la classe LivretToutBenef. Elle doit bien sûr dériver de la classe de base Compte et posséder un membre privé de type ICalculateurDeBenefice :
public class LivretToutBenef : Compte
{
private ICalculateurDeBenefice calculateurDeBenefice;
public LivretToutBenef(ICalculateurDeBenefice calculateur)
{
calculateurDeBenefice = calculateur;
}
public override decimal Solde
{
get
{
return calculateurDeBenefice.CalculeBenefice(base.Solde);
}
}
public override void AfficherResume()
{
Console.WriteLine("^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^");
Console.WriteLine("Livret ToutBénéf de " + Proprietaire);
Console.WriteLine("\tSolde : " + Solde);
Console.WriteLine("\tTaux : " + calculateurDeBenefice.Taux);
AfficheOperations();
Console.WriteLine("^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^");
}
}
Dans le constructeur, la variable est initialisée avec un objet de type ICalculateurDeBenefice. Ensuite, pour calculer le solde, il suffit d’appeler la méthode CalculeBenefice avec le solde de base en paramètres. De même, pour faire apparaître le taux dans le résumé, on pourra utiliser la propriété Taux de l’interface.
Il ne reste qu’à souscrire à un Livret ToutBénéf en lui passant un objet de bénéfice à taux fixe en paramètre du constructeur, et de faire les opérations bancaires demandées. Ce qui donne :
ICalculateurDeBenefice beneficeATauxFixe = new BeneficeATauxFixe(0.275);
LivretToutBenef livretToutBenefNicolas = new LivretToutBenef(beneficeATauxFixe);
livretToutBenefNicolas.Crediter(800);
livretToutBenefNicolas.Crediter(200);
Console.WriteLine("Résumé du livret Toutbénef");
livretToutBenefNicolas.AfficherResume();
Console.WriteLine("\n");
Ce qui donne :
Résumé du livret Toutbénef
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Livret ToutBénéf de
Solde : 1275,000
Taux : 0,275
Opérations :
+800
+200
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Maintenant, nous devons adapter la classe CompteEpargneEntreprise pour qu’elle puisse fonctionner avec un comportement. Cela devient tout simple et se rapproche beaucoup du livret ToutBénéf :
public class CompteEpargneEntreprise : Compte
{
private ICalculateurDeBenefice calculateurDeBenefice;
public CompteEpargneEntreprise(ICalculateurDeBenefice calculateur)
{
calculateurDeBenefice = calculateur;
}
public override decimal Solde
{
get
{
return calculateurDeBenefice.CalculeBenefice(base.Solde);
}
}
public override void AfficherResume()
{
Console.WriteLine("########################################################");
Console.WriteLine("Compte épargne entreprise de " + Proprietaire);
Console.WriteLine("\tSolde : " + Solde);
Console.WriteLine("\tTaux : " + calculateurDeBenefice.Taux);
AfficheOperations();
Console.WriteLine("########################################################");
}
}
Il faut maintenant changer l’instanciation de l’objet CompteEpargneEntreprise en lui passant en paramètres un objet de type bénéfice aléatoire :
ICalculateurDeBenefice beneficeAleatoire = new BeneficeAleatoire();
CompteEpargneEntreprise compteEpargneNicolas = new CompteEpargneEntreprise(beneficeAleatoire) { Proprietaire = "Nicolas" };
Reste le compte courant qui suit le même principe :
public class CompteCourant : Compte
{
private decimal decouvertAutorise;
private ICalculateurDeBenefice calculateurDeBenefice;
public CompteCourant(decimal decouvert, ICalculateurDeBenefice calculateur)
{
decouvertAutorise = decouvert;
calculateurDeBenefice = calculateur;
}
public override decimal Solde
{
get
{
return calculateurDeBenefice.CalculeBenefice(base.Solde);
}
}
public override void AfficherResume()
{
Console.WriteLine("*******************************************");
Console.WriteLine("Compte courant de " + Proprietaire);
Console.WriteLine("\tSolde : " + Solde);
Console.WriteLine("\tDécouvert autorisé : " + decouvertAutorise);
Console.WriteLine("\tTaux : " + calculateurDeBenefice.Taux);
AfficheOperations();
Console.WriteLine("*******************************************");
}
}
Que l’on pourra instancier avec un objet de type aucun bénéfice :
ICalculateurDeBenefice aucunBenefice = new AucunBenefice();
CompteCourant compteNicolas = new CompteCourant(2000, aucunBenefice) { Proprietaire = "Nicolas" };
Et voilà. L’avantage ici est d’avoir séparé les responsabilités dans différentes classes. Si jamais nous créons un nouveau compte qui est rémunéré grâce à un bénéfice à taux fixe, il suffira de réutiliser ce comportement et le tour est joué.
À noter que les trois calculs de la propriété Solde sont identiques, il pourrait être judicieux de le factoriser dans la classe mère Compte. Ceci implique que la classe mère possède elle-même le membre protégé du type de l’interface.
Voilà pour ce TP. J’espère que vous aurez réussi avec brio toutes les créations de classes et que vous ne vous êtes pas mélangés dans les mots-clés. Vous verrez que vous aurez très souvent besoin d’écrire des classes dans ce genre afin de créer une application. C’est un élément indispensable du C# qu’il est primordial de maîtriser.
N’hésitez pas à faire des variations sur ce TP ou à créer d’autres petits programmes simples vous permettant de vous entrainer.
Voilà pour ce TP. J’espère que vous aurez réussi avec brio toutes les créations de classes et que vous ne vous êtes pas mélangés dans les mots-clés. Vous verrez que vous aurez très souvent besoin d’écrire des classes de ce genre afin de créer une application. C’est un élément indispensable du C# qu’il est primordial de maîtriser.
N’hésitez pas à faire des variations sur ce TP ou à créer d’autres petits programmes simples vous permettant de vous entrainer.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans les chapitres précédents, nous avons décrit comment on pouvait passer des paramètres à une méthode. Nous avons également vu que les types du framework .NET pouvaient être des types valeur ou des types référence. Ceci influence la façon dont sont traités les paramètres d'une méthode. Nous allons ici préciser un peu ce fonctionnement.
Dans ce chapitre, je vais illustrer mes propos en utilisant des méthodes statiques écrites dans la classe Program, générée par Visual C# Express. Le but est de simplifier l'écriture et de ne pas s'encombrer d'objets inutiles. Évidemment, tout ce que nous allons voir fonctionne également de la même façon avec les méthodes non statiques présentes dans des objets.
Tout au début du tutoriel, nous avons appelé des méthodes en passant des types simples (int, string, etc.). Nous avons vu qu’il s’agissait de types valeur qui possèdent directement la valeur dans la variable.
Lorsque nous passons des types valeur en paramètre d’une méthode, nous utilisons un passage de paramètre par valeur.
Décortiquons l’exemple suivant :
static void Main(string[] args)
{
int age = 30;
Doubler(age);
Console.WriteLine(age);
}
public static void Doubler(int valeur)
{
valeur = valeur * 2;
Console.WriteLine(valeur);
}
Nous déclarons dans la méthode Main() une variable age, de type entier, à laquelle nous affectons la valeur 30. Nous appelons ensuite la méthode Doubler() en lui passant cette variable en paramètre.
Ce qu’il se passe c’est que le compilateur fait une copie de la valeur de la variable age pour la mettre dans la variable valeur de la méthode Doubler(). La variable valeur a une portée égale au corps de la méthode Doubler().
Nous modifions ensuite la valeur de la variable valeur en la multipliant par deux. Étant donné que la variable valeur a reçu une copie de la variable age, c'est-à-dire que le compilateur a dupliqué la valeur 30, le fait de modifier la variable valeur ne change en rien la valeur de la variable age.
En effet, si nous exécutons le code du dessus, nous allons avoir :
Nous passons 30 à la méthode Doubler() qui calcule le double de la variable valeur. On affiche 60. Lorsqu’on revient dans la méthode Main(), nous retrouvons la valeur initiale de la variable age. Elle n’a bien sûr pas été modifiée car la méthode Doubler() a travaillé sur une copie.
Rappelez-vous que ceci est possible car les types intégrés sont facilement copiables, car peu évolués.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour pouvoir modifier la valeur du paramètre passé, il faut indiquer que la variable est en mode « mise à jour ». Cela se fait grâce au mot-clé « ref » que nous pourrons utiliser ainsi :
static void Main(string[] args)
{
int age = 30;
Doubler(ref age);
Console.WriteLine(age);
}
public static void Doubler(ref int valeur)
{
valeur = valeur * 2;
}
Comme on peut s’en douter, ce code affiche 60.
Le mot-clé ref s’utilise avant la définition du paramètre dans la méthode. Cela implique qu’il soit également utilisé au moment d’appeler la méthode.
Vous aurez remarqué que le mot-clé utilisé est ref et qu'il ressemble beaucoup au mot « référence ». Ce n’est évidemment pas un hasard. En fait, avec ce mot-clé nous demandons au compilateur de passer en paramètre une référence vers la variable age plutôt que d’en faire une copie. Ainsi, la méthode Doubler() récupère une référence et la variable valeur référence alors la même valeur que la variable age. Ceci implique que toute modification de la valeur référencée provoque un changement sur la variable source puisque les variables référencent la même valeur.
Voilà pourquoi la variable est modifiée après le passage dans la méthode Doubler(). Bien sûr, il aurait tout à fait été possible de faire en sorte que la méthode Doubler() renvoie un entier contenant la valeur passée en paramètre multipliée par 2 :
static void Main(string[] args)
{
int age = 30;
age = Doubler(age);
Console.WriteLine(age);
}
public static int Doubler(int valeur)
{
return valeur * 2;
}
C’est ce que nous avons toujours fait auparavant. Voici donc une autre façon de faire qui peut être bien utile quand il y a plus d’une valeur à renvoyer.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
C’est aussi comme ça que cela fonctionne pour les objets. Nous avons vu que les variables qui stockent des objets possèdent en fait la référence de l’objet. Le fait de passer un objet à une méthode équivaut à passer la référence de l’objet en paramètres. Ainsi, c’est comme si on utilisait le mot-clé ref implicitement.
va donc créer un objet Voiture et le passer en paramètres à la méthode Repeindre(). Comme Voiture est un type référence, il n’y a pas de duplication de l’objet et une référence est passée à la méthode. Lorsque nous modifions la propriété Couleur de la voiture, nous modifions bien le même objet que celui présent dans la méthode Main().
Nous aurons donc :
Il est à noter quand même que la variable voiture de la méthode Repeindre est une copie de la variable voiture de la méthode Main() qui contiennent toutes les deux une référence vers l'objet de type Voiture. Cela veut dire que l'on accède bien au même objet, d'où le résultat, mais que les deux variables sont indépendantes. Si nous modifions directement la variable, avec par exemple :
Alors, ce code continuera à fonctionner, car la variable voiture de la méthode Main() ne vaut pas null. Le fait de modifier la variable de la méthode Repeindre, qui est une copie, n'affecte en rien la variable de la méthode Main().
Par contre, elle est affectée si nous utilisons le mot-clé ref. Par exemple le code suivant :
provoquera une erreur. En effet, cette fois-ci, c'est bien la référence qui est passée à nulle et pas une copie de la variable contenant la référence...
Une subtile différence. :-°
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Enfin, le dernier mode de passage est le passage de paramètres en sortie. Il permet de faire en sorte qu’une méthode force l’initialisation d’une variable et que l’appelant récupère la valeur initialisée. Nous avons déjà vu ce mode de passage quand nous avons étudié les conversions. Souvenez-vous de ce code :
string chaine = "1234";
int nombre;
if (int.TryParse(chaine, out nombre))
Console.WriteLine(nombre);
else
Console.WriteLine("Conversion impossible");
La méthode TryParse permet de tester la conversion d’une chaîne. Elle renvoie vrai ou faux en fonction du résultat de la conversion et met à jour l’entier qui est passé en paramètre en utilisant le mot-clé « out ». Si la conversion réussit, alors l’entier nombre est initialisé avec la valeur de la conversion, calculée dans la méthode TryParse. Nous pouvons utiliser ensuite la variable nombre car le mot-clé out garantit que la variable sera initialisée dans la méthode.
En effet, si nous prenons l’exemple suivant :
static void Main(string[] args)
{
int age = 30;
int ageDouble;
Doubler(age, out ageDouble);
}
public static void Doubler(int age, out int resultat)
{
}
Nous aurons une erreur de compilation :
Le paramètre de sortie 'resultat' doit être assigné avant que le contrôle quitte la méthode actuelle
En effet, il faut absolument que la variable resultat qui est marquée en sortie ait une valeur avant de pouvoir sortir de la méthode. Nous pourrons corriger cet exemple avec :
static void Main(string[] args)
{
int age = 30;
int ageDouble;
Doubler(age, out ageDouble);
}
public static void Doubler(int age, out int resultat)
{
resultat = age * 2;
}
Après l’appel de la méthode Doubler(), ageDouble vaudra donc 60.
Oui, mais quel intérêt par rapport à un return normal ?
Ici, aucun. Cela est pertinent quand nous souhaitons renvoyer plusieurs valeurs, comme c’est le cas pour la méthode TryParse qui renvoie le résultat de la conversion et si la conversion s’est bien passée. Bien sûr, si l’on n’aime pas trop le mot-clé out, il est toujours possible de créer un objet contenant deux valeurs que l’on retournera à l’appelant, par exemple :
public class Program
{
static void Main(string[] args)
{
string nombre = "1234";
Resultat resultat = TryParse(nombre);
if (resultat.ConversionOk)
Console.WriteLine(resultat.Valeur);
}
public static Resultat TryParse(string chaine)
{
Resultat resultat = new Resultat();
int valeur;
resultat.ConversionOk = int.TryParse(chaine, out valeur);
resultat.Valeur = valeur;
return resultat;
}
}
public class Resultat
{
public bool ConversionOk { get; set; }
public int Valeur { get; set; }
}
Ici, notre méthode TryParse renvoie un objet Resultat qui contient les deux valeurs résultantes de la conversion.
En résumé
Le type d'une variable passée en paramètres d'une méthode influence la façon dont elle est traitée.
Un passage par valeur effectue une copie de la valeur de la variable et la met dans la variable de la méthode.
Un passage par référence effectue une copie de la référence mais continue de pointer sur le même objet.
On utilise le mot-clé ref pour passer une variable de type valeur à une méthode afin de la modifier.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous allons aborder dans ce chapitre les structures qui sont une nouvelle sorte d’objets que nous pouvons créer dans des applications C#. Les structures sont presque comme des classes. Elles permettent également de créer des objets, possèdent des variables ou propriétés, des méthodes et même un constructeur, mais avec quelques subtiles différences …
Une des premières différences est la façon dont .NET gère ces deux objets. Nous avons vu que les classes étaient des types référence. Les variables de type référence ne possèdent donc pas la valeur de l’objet mais une référence vers cet objet en mémoire. La structure quant à elle est un type valeur et contient donc directement la valeur de l’objet.
Une autre différence est que la structure, bien qu’étant un objet, ne peut pas utiliser les principes d’héritage. On ne peut donc pas hériter d’une structure et une structure ne peut pas hériter des comportements d’un objet.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les structures vont être utiles pour stocker des petits objets qui vont avoir tendance à être souvent manipulés, comme les int ou les bool que nous avons déjà vus.
La raison tient dans un seul mot : performance.
Étant gérées en mémoire différemment, les structures sont optimisées pour améliorer les performances des petits objets. Comme il n’y a pas de référence, on utilisera directement l’objet sans aller le chercher via sa référence. On gagne donc un peu de temps lorsqu’on a besoin de manipuler ces données. C’est tout à fait pertinent pour des programmes où la vitesse est déterminante, comme les jeux vidéo.
Donc dans ce cas, autant utiliser tout le temps des structures, non ?
Eh bien non, déjà vous vous priveriez de tous les mécanismes d’héritage que nous avons vus. Ensuite, si nous surchargeons trop la mémoire avec des structures, l’optimisation prévue par .NET risque de se retourner contre nous et notre application pourrait être plus lente que si nous avions utilisé des classes.
D’une manière générale, et à moins de savoir exactement ce que vous faites ou d’avoir mesuré les performances, vous allez utiliser plus généralement les classes que les structures. Vous pouvez à ce sujet aller lire les recommandations de Microsoft.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour créer une structure, nous utiliserons le mot-clé struct, comme nous avions utilisé le mot-clé class pour créer une classe :
public struct Personne
{
public string Prenom { get; set; }
public int Age { get; set; }
}
Pour instancier cette structure, nous pourrons utiliser le mot-clé new, comme pour les classes. La différence est que la variable sera un type valeur, avec les conséquences que ce type impose en matière de gestion en mémoire ou de passages par paramètres :
Personne nicolas = new Personne() { Prenom = "Nicolas", Age = 30 };
Console.WriteLine(nicolas.Prenom + " a " + nicolas.Age + " ans");
Comme nous avons dit, il est impossible qu’une structure hérite d’une autre structure ou d’un objet. Sauf bien sûr du fameux type de base object, pour qui c’est automatique. Une structure hérite donc des quelques méthodes d’Object (comme ToString()) que nous pouvons éventuellement spécialiser :
public struct Personne
{
public string Prenom { get; set; }
public int Age { get; set; }
public override string ToString()
{
return Prenom + " a " + Age + " ans";
}
}
Et nous pourrons avoir :
Personne nicolas = new Personne() { Prenom = "Nicolas", Age = 30 };
Console.WriteLine(nicolas.ToString());
Qui renverra :
Nicolas a 30 ans
Comme pour les classes, il est possible d’avoir des constructeurs sur une structure à l’exception du constructeur par défaut qui est interdit.
Aussi le code suivant :
public struct Personne
{
public Personne()
{
}
}
provoquera l’erreur de compilation suivante :
Les structures ne peuvent pas contenir de constructeurs exempts de paramètres explicites
Par contre, les autres formes des constructeurs sont possibles, comme :
public struct Personne
{
private int age;
public Personne(int agePersonne)
{
age = agePersonne;
}
}
Qui s’utilisera comme pour une classe :
Personne nicolas = new Personne(30);
Attention, si vous tentez d’utiliser des propriétés ou des méthodes dans le constructeur d’une structure, vous allez avoir un problème. Par exemple le code suivant :
public struct Personne
{
private int age;
public Personne(int agePersonne)
{
AffecteAge(agePersonne);
}
private void AffecteAge(int agePersonne)
{
age = agePersonne;
}
}
provoquera les erreurs de compilation suivantes :
L'objet 'this' ne peut pas être utilisé avant que tous ses champs soient assignés
Le champ 'MaPremiereApplication.Personne.age' doit être totalement assigné avant que le contrôle soit retourné à l'appelant
Alors qu’avec une classe, ce code serait tout à fait correct. Pour corriger ceci, il faut absolument initialiser tous les champs avant de faire quoi que ce soit avec l’objet, comme l’indique l’erreur.
Nous pourrons par exemple faire :
public struct Personne
{
private int age;
public Personne(int agePersonne)
{
age = 0;
AffecteAge(agePersonne);
}
private void AffecteAge(int agePersonne)
{
age = agePersonne;
}
}
Ce qui peut sembler tout à fait inutile dans ce cas-là. Mais comme le compilateur fait certaines vérifications, il sera impossible de compiler un code de ce genre sans que toutes les variables soient initialisées explicitement.
Par contre, vous aurez un souci si vous utilisez des propriétés automatiques. Si nous tentons de faire :
public struct Personne
{
public int Age { get; set; }
public Personne(int agePersonne)
{
Age = agePersonne;
}
}
nous nous retrouverons avec la même erreur de compilation. Pour la corriger, il faudra appeler le constructeur par défaut de la structure qui va permettre d’initialiser toutes les variables de la classe :
public struct Personne
{
public int Age { get; set; }
public Personne(int agePersonne) : this()
{
Age = agePersonne;
}
}
Cela se fait comme pour les classes, en utilisant le mot-clé this suivi de parenthèses qui permettront d’appeler le constructeur par défaut.
Rappelez-vous que le constructeur par défaut s’occupe d’initialiser toutes les variables d’une classe ou d’une structure.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Comme il s’agit d’un type valeur, à chaque fois que nous passerons une structure en paramètres d’une méthode, une copie de l’objet sera faite. Ainsi, tout à fait logiquement, le code suivant :
static void Main(string[] args)
{
Personne nicolas = new Personne() { Age = 30 };
FaitVieillir(nicolas);
Console.WriteLine(nicolas.Age);
}
private static void FaitVieillir(Personne personne)
{
personne.Age++;
}
affichera 30 bien que nous modifions l’âge de la personne dans la méthode.
Comme nous l’avons déjà vu, la méthode travaille sur une copie de la structure. Cela veut bien sûr dire que si nous souhaitons modifier une structure à partir d’une méthode, nous devrons utiliser le mot-clé ref :
static void Main(string[] args)
{
Personne nicolas = new Personne() { Age = 30 };
FaitVieillir(ref nicolas);
Console.WriteLine(nicolas.Age);
}
private static void FaitVieillir(ref Personne personne)
{
personne.Age++;
}
Cela vaut pour tous les types valeur.
Prenez quand même garde. Si la structure est très grosse, le fait d’en faire une copie à chaque utilisation de méthode risque d’être particulièrement chronophage et pourra perturber les performances de votre application.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous l’aurez peut-être deviné, mais les entiers que nous avons déjà vus et que nous utilisions grâce au mot-clé int sont en fait des structures.
Étant très souvent utilisés et n’ayant pas non plus énormément de choses à stocker, ils sont créés en tant que structures et sont optimisés par .NET pour que nos applications s’exécutent de façon optimale. Ce qui est un choix tout à fait pertinent. C'est le cas également pour les bool, les double, etc ...
Toutefois, d’autres objets, comme la classe String, sont bel et bien des classes.
D’une manière générale, vous allez créer peu de structures en tant que débutant. Il sera plus judicieux de créer des classes dès que vous en avez besoin. En effet, plus vos objets sont gros et plus ils auront intérêt à être des classes pour éviter d’être recopiés à chaque utilisation. L’utilisation de structures pourra se révéler pertinente dans des situations bien précises, mais en général, il faut bien maitriser les rouages du framework .NET pour que les bénéfices de leurs utilisations se fassent ressentir.
Dans tous les cas, il sera important de mesurer (avec par exemple des outils de profilage) le gain de temps avant de mettre des structures partout.
En résumé
Les structures sont des types valeur qui sont optimisés par le framework .NET.
Une structure est un objet qui ressemble beaucoup à une classe, mais qui possède des restrictions.
Les structures possèdent des propriétés, des méthodes, des constructeurs, etc.
Il n'est pas possible d'utiliser l'héritage avec les structures.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les génériques sont une fonctionnalité du framework .NET apparus avec la version 2. Vous vous en souvenez peut-être, nous avons cité le mot dans le chapitre sur les tableaux et les listes. Ils permettent de créer des méthodes ou des classes qui sont indépendantes d'un type. Il est très important de connaître leur fonctionnement car c'est un mécanisme clé qui permet de faire beaucoup de choses, notamment en termes de réutilisabilité et d'amélioration des performances.
N'oubliez pas vos tubes d'aspirine et voyons à présent de quoi il retourne !
Avec les génériques, vous pouvez créer des méthodes ou des classes qui sont indépendantes d’un type. On les appellera des méthodes génériques et des types génériques.
Nous en avons déjà utilisé, rappelez-vous, avec la liste. La liste est une classe comme nous en avons déjà vu plein, sauf qu’elle a la capacité d’être utilisée avec n’importe quel autre type, comme les entiers, les chaînes de caractères, les voitures …
Cela permet d’éviter de devoir créer une classe ListeInt, une classe ListeString, une classe ListeVoiture, etc … On pourra utiliser cette classe avec tous les types grâce aux chevrons :
List<string> listeChaine = new List<string>();
List<int> listeEntier = new List<int>();
List<Voiture> listeVoiture = new List<Voiture>();
Nous indiquons entre les chevrons le type qui sera utilisé avec le type générique.
Oui mais, si nous voulons pouvoir mettre n’importe quel type d’objet dans une liste, il suffirait de créer une ListeObject ? Puisque tous les objets dérivent d'object…
En fait, c’est le choix qui avait été fait dans la toute première version de .NET. On utilisait l’objet ArrayList qui possède une méthode Add prenant en paramètre un object. Cela fonctionne. Sauf que nous nous trouvions faces à des limitations :
Premièrement, nous pouvions mélanger n’importe quel type d’objet dans la liste, des entiers, des voitures, des chiens, etc. Cela devenait une classe fourre-tout et nous ne savions jamais ce qu’il y avait dans la liste.
Deuxièmement, même si nous savions qu’il n’y avait que des entiers dans la liste, nous étions obligés de le traiter en tant qu’object et donc d’utiliser le boxing et l’unboxing pour mettre les objets dans la liste ou pour les récupérer.
Cela engendrait donc confusion et perte de performance. Grâce aux génériques, il devenait donc possible de créer des listes de n’importe quel type et nous étions certains du type que nous allions récupérer dans la liste.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Le framework .NET possède beaucoup de classes et d’interfaces génériques, notamment dans l’espace de nom System.Collections.Generic.
La liste est la classe générique que vous utiliserez sûrement le plus. Mais beaucoup d’autres sont à votre disposition. Citons par exemple la classe Queue<> qui permet de gérer une file d’attente style FIFO (first in, first out : premier entré, premier sorti) :
Citons encore le dictionnaire d’élément qui est une espèce d’annuaire où l’on accède aux éléments grâce à une clé :
Dictionary<string, Personne> annuaire = new Dictionary<string, Personne>();
annuaire.Add("06 01 02 03 04", new Personne { Prenom = "Nicolas"});
annuaire.Add("06 06 06 06 06", new Personne { Prenom = "Jeremie" });
Personne p = annuaire["06 06 06 06 06"]; // p contient la propriété Prenom valant Jeremie
Loin de moi l’idée de vous énumérer toutes les collections génériques du framework .NET, le but est de vous montrer rapidement qu’il existe beaucoup de classes génériques dans le framework .NET.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous commençons à cerner l’intérêt des génériques. Sachez qu’il est bien sûr possible de créer vos propres classes génériques ou vos propres méthodes. Commençons par les méthodes, cela sera plus simple.
Il est globalement intéressant d’utiliser un type générique partout où nous pourrions avoir un object. Nous avions créé une classe AfficheRepresentation() qui prenait un objet en paramètres, ce qui pourrait être :
public static class Afficheur
{
public static void Affiche(object o)
{
Console.WriteLine("Afficheur d'objet :");
Console.WriteLine("\tType : " + o.GetType());
Console.WriteLine("\tReprésentation : " + o.ToString());
}
}
Nous avons ici utilisé une classe statique permettant d’afficher le type d’un objet et sa représentation. Nous pouvons l’utiliser ainsi :
int i = 5;
double d = 9.5;
string s = "abcd";
Voiture v = new Voiture();
Afficheur.Affiche(i);
Afficheur.Affiche(d);
Afficheur.Affiche(s);
Afficheur.Affiche(v);
Rappelez-vous, à chaque fois qu’on passe dans cette méthode, l’objet est boxé en type object quand il s’agit d’un type valeur. Nous pouvons améliorer cette méthode en créant une méthode générique. Regardons ce code :
public static class Afficheur
{
public static void Affiche<T>(T a)
{
Console.WriteLine("Afficheur d'objet :");
Console.WriteLine("\tType : " + a.GetType());
Console.WriteLine("\tReprésentation : " + a.ToString());
}
}
Cette méthode fait exactement la même chose mais avec les génériques. Dans un premier temps, la méthode annonce qu’elle va utiliser un type générique représenté par la lettre T entre chevrons.
Cela veut dire que tout type utilisé dans cette méthode déclaré avec T sera du type passé à la méthode. Ainsi, la variable a est du type générique qui sera précisé lors de l’appel à cette méthode. Comme a est un objet, nous pouvons appeler la méthode GetType() et la méthode ToString() sur cet objet.
Pour afficher un objet, nous pourrons faire :
int i = 5;
double d = 9.5;
string s = "abcd";
Voiture v = new Voiture();
Afficheur.Affiche<int>(i);
Afficheur.Affiche<double>(d);
Afficheur.Affiche<string>(s);
Afficheur.Affiche<Voiture>(v);
Dans le premier appel, nous indiquons que nous souhaitons afficher i dont le type générique est int. Ce qu’il se passe, c’est comme si le CLR créait la surcharge de la méthode Affiche, prenant un entier en paramètre :
public static void Affiche(int a)
{
Console.WriteLine("Afficheur d'objet :");
Console.WriteLine("\tType : " + a.GetType());
Console.WriteLine("\tReprésentation : " + a.ToString());
}
De même pour l’affichage suivant, où l’on indique le type double entre les chevrons. C’est comme si le CLR créait la surcharge prenant un double en paramètre :
public static void Affiche(double a)
{
Console.WriteLine("Afficheur d'objet :");
Console.WriteLine("\tType : " + a.GetType());
Console.WriteLine("\tReprésentation : " + a.ToString());
}
Et ceci pour tous les types utilisés, à savoir ici int, double, string et Voiture.
À noter que dans cet exemple, nous pouvons remplacer les quatre lignes suivantes :
En effet, nul besoin de préciser quel type nous souhaitons traiter ici, le compilateur est assez malin pour le déduire du type de la variable. La variable i étant un entier, il est obligatoire que le type générique soit un entier. Il est donc facultatif ici de le préciser.
Une fois qu’il est précisé entre les chevrons, le type générique s’utilise dans la méthode comme n’importe quel autre type. Nous pouvons avoir autant de paramètres génériques que nous le voulons dans les paramètres et utiliser le type générique dans le corps de la méthode. Par exemple la méthode suivante :
public static void Echanger<T>(ref T t1, ref T t2)
{
T temp = t1;
t1 = t2;
t2 = temp;
}
permet d’échanger le contenu de deux variables entre elles. C’est donc une méthode générique puisqu’elle précise entre les chevrons que nous pourrons utiliser le type T.
En paramètres de la méthode, nous passons deux variables de types génériques.
Dans le corps de la méthode, nous créons une variable du type générique qui sert de mémoire temporaire puis nous échangeons les références des deux variables. Nous pourrons utiliser cette méthode ainsi :
int i = 5;
int j = 10;
Echanger(ref i, ref j);
Console.WriteLine(i);
Console.WriteLine(j);
Voiture v1 = new Voiture { Couleur = "Rouge" };
Voiture v2 = new Voiture { Couleur = "Verte" };
Echanger(ref v1, ref v2);
Console.WriteLine(v1.Couleur);
Console.WriteLine(v2.Couleur);
Qui donnera :
10
5
Verte
Rouge
Il est bien sûr possible de créer des méthodes prenant en paramètres plusieurs types génériques différents. Il suffit alors de préciser autant de types différents entre les chevrons qu’il y a de types génériques différents :
static void Main(string[] args)
{
int i = 5;
int j = 5;
double d = 9.5;
Console.WriteLine(EstEgal(i, j));
Console.WriteLine(EstEgal(i, d));
}
public static bool EstEgal<T, U>(T t, U u)
{
return t.Equals(u);
}
Ici, la méthode EstEgal() prend en paramètres potentiellement deux types différents. Nous l’appelons une première fois avec deux entiers et ensuite avec un entier et un double.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une classe générique fonctionne comme pour les méthodes. C’est une classe où nous pouvons indiquer de 1 à N types génériques. C’est comme cela que fonctionne la liste que nous avons déjà beaucoup manipulée.
En fait, la liste n’est qu’une espèce de tableau évolué. Nous pourrions très bien imaginer créer notre propre liste sur ce principe, sachant que c’est complètement absurde car elle sera forcément moins bien que cette classe, mais c’est pour l’étude.
Le principe est d’avoir un tableau plus ou moins dynamique qui grossit si jamais le nombre d’éléments devient trop grand pour sa capacité. Pour déclarer une classe générique, nous utiliserons à nouveau les chevrons à la fin de la ligne qui déclare la classe :
public class MaListeGenerique<T>
{
}
Nous allons réaliser une implémentation toute basique de cette classe histoire de voir un peu à quoi ressemble une classe générique. Cette classe n’a d’intérêt que pour étudier les génériques, vous lui préférerez évidemment la classe List<> du framework .NET.
Nous avons besoin de trois variables privées. La capacité de la liste, le nombre d’éléments dans la liste et le tableau générique.
public class MaListeGenerique<T>
{
private int capacite;
private int nbElements;
private T[] tableau;
public MaListeGenerique()
{
capacite = 10;
nbElements = 0;
tableau = new T[capacite];
}
}
Notons la déclaration du tableau. Il utilise le type générique. Concrètement, cela veut dire que quand nous utiliserons la liste avec un entier, nous aurons un tableau d’entiers. Lorsque nous utiliserons la liste avec un objet Voiture, nous aurons un tableau de Voiture, etc.
Nous initialisons ces variables membres dans le constructeur, en décidant complètement arbitrairement que la capacité par défaut de notre liste est de 10 éléments. La dernière ligne instancie le tableau en lui indiquant sa taille.
Il reste à implémenter l’ajout dans la liste :
public class MaListeGenerique<T>
{
[Code enlevé pour plus de clarté]
public void Ajouter(T element)
{
if (nbElements >= capacite)
{
capacite *= 2;
T[] copieTableau = new T[capacite];
for (int i = 0; i < tableau.Length; i++)
{
copieTableau[i] = tableau[i];
}
tableau = copieTableau;
}
tableau[nbElements] = element;
nbElements++;
}
}
Il s’agit simplement de mettre la valeur que l’on souhaite ajouter à l’emplacement adéquat dans le tableau. Nous le mettons en dernière position, c'est-à-dire à l’emplacement correspondant au nombre d’éléments.
Au début, nous avons commencé par vérifier si le nombre d’éléments était supérieur à la capacité du tableau. Si c’est le cas, alors nous devons augmenter la capacité du tableau, j’ai ici décidé encore complètement arbitrairement que je doublais la capacité. Il ne reste plus qu’à créer un nouveau tableau de cette nouvelle capacité et à copier les éléments du premier tableau dans celui-ci.
Vous aurez noté que le paramètre de la méthode Ajouter est bien du type générique. Pour le plaisir, rajoutons enfin une méthode permettant de récupérer l’élément à un indice donné :
public class MaListeGenerique<T>
{
[Code enlevé pour plus de clarté]
public T ObtenirElement(int indice)
{
return tableau[indice];
}
}
Il s’agit juste d’accéder au tableau pour renvoyer la valeur à l’indice concerné. L’élément intéressant ici est de constater que le type de retour de la méthode est bien du type générique.
Cette liste peut s’utiliser de la manière suivante :
MaListeGenerique<int> maListe = new MaListeGenerique<int>();
maListe.Ajouter(25);
maListe.Ajouter(30);
maListe.Ajouter(5);
Console.WriteLine(maListe.ObtenirElement(0));
Console.WriteLine(maListe.ObtenirElement(1));
Console.WriteLine(maListe.ObtenirElement(2));
for (int i = 0; i < 30; i++)
{
maListe.Ajouter(i);
}
Ici, nous utilisons la liste avec un entier, mais elle fonctionnerait tout aussi bien avec un autre type. N’hésitez pas à passer en debug dans la méthode Ajouter() pour observer ce qu’il se passe exactement lors de l’augmentation de capacité. Voilà comment on crée une classe générique !
Une fois qu’on a compris que le type générique s’utilise comme n’importe quel autre type, cela devient assez facile. Rappelez-vous, toute classe qui manipule des object est susceptible d’être améliorée en utilisant les génériques.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous aurez remarqué dans l’implémentation de la liste du dessus que si nous essayons d’obtenir un élément du tableau à un indice qui n’existe pas, nous aurons une erreur. Ce comportement est une bonne chose, il est important de gérer les cas limites. En l’occurrence ici, on délègue au tableau la gestion du cas limite.
On pourrait envisager de gérer nous-mêmes ce cas limite en affichant un message et en renvoyant une valeur nulle. Seulement, pour un objet Voiture, qui est un type référence, il est tout à fait pertinent d’avoir null. Mais pour un int, qui est un type valeur, cela n’a pas de sens.
C’est là qu’intervient le mot-clé default.
Comme son nom l’indique, il renvoie la valeur par défaut du type. Pour un type référence, c’est null, pour un type valeur c’est 0. Ce qui donnerait :
public T ObtenirElement(int indice)
{
if (indice < 0 || indice >= nbElements)
{
Console.WriteLine("L'indice n'est pas bon");
return default(T);
}
return tableau[indice];
}
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les interfaces peuvent aussi être génériques. D’ailleurs, ça me fait penser que plus haut, je vous ai indiqué qu’un code était moche et que j’en parlerai plus tard… Il s’agissait du chapitre sur les interfaces où nous avions implémentés l’interface IComparable. Nous souhaitions comparer des voitures entre elles et nous avions obtenu le code suivant :
public class Voiture : IComparable
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
public int CompareTo(object obj)
{
Voiture voiture = (Voiture)obj;
return Vitesse.CompareTo(voiture.Vitesse);
}
}
Je souhaite pouvoir comparer des voitures entre elles, mais le framework .NET me fournit un object en paramètres de la méthode CompareTo(). Quelle idée ! Comme si je voulais pouvoir comparer des voitures avec des chats ou des chiens. Cela me force en plus à faire un cast. Pourquoi il ne me passe pas directement une Voiture en paramètres ?
Vous le sentez venir et vous avez raison. Un object ! Berk, oserais-je dire ! Et sans parler des performances.
C’est là où les génériques vont pouvoir voler à notre secours. L’interface IComparable date de la première version du framework .NET. Le C# ne possédait pas encore les types génériques. Depuis leur apparition, il est possible d’implémenter la version générique de cette interface.
Pour cela, nous faisons suivre l’interface du type que nous souhaitons utiliser entre les chevrons. Cela donne :
public class Voiture : IComparable<Voiture>
{
public string Couleur { get; set; }
public string Marque { get; set; }
public int Vitesse { get; set; }
public int CompareTo(Voiture obj)
{
return Vitesse.CompareTo(obj.Vitesse);
}
}
Nous devons toujours implémenter la méthode CompareTo() sauf que nous avons désormais un objet Voiture en paramètres, ce qui nous évite de le caster.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une méthode ou une classe générique c’est bien, mais peut-être voulons-nous qu’elles ne fonctionnent pas avec tous les types. Aussi, le C# permet de définir des restrictions sur les types génériques. Pour ce faire, on utilise le mot-clé where.
Il existe 6 types de restrictions :
Contrainte
Description
where T : struct
Le type générique doit être un type valeur
where T : class
Le type générique doit être un type référence
where T : new()
Le type générique doit posséder un constructeur par défaut
where T : IMonInterface
Le type générique doit implémenter l’interface IMonInterface
where T : MaClasse
Le type générique doit dériver de la classe MaClasse
where T1 : T2
Le type générique doit dériver du type générique T2
Par exemple, nous pouvons définir une restriction sur une méthode générique afin qu’elle n’accepte en type générique que des types qui implémentent une interface.
Soit l’interface suivante :
public interface IVolant
{
void DeplierLesAiles();
void Voler();
}
Qui est implémentée par deux objets :
public class Avion : IVolant
{
public void DeplierLesAiles()
{
Console.WriteLine("Je déplie mes ailes mécaniques");
}
public void Voler()
{
Console.WriteLine("J'allume le moteur");
}
}
public class Oiseau : IVolant
{
public void DeplierLesAiles()
{
Console.WriteLine("Je déplie mes ailes d'oiseau");
}
public void Voler()
{
Console.WriteLine("Je bats des ailes");
}
}
Nous pouvons créer une méthode générique qui s’occupe d’instancier ces objets et d’appeler les méthodes de l’interface :
public static T Creer<T>() where T : IVolant, new()
{
T t = new T();
t.DeplierLesAiles();
t.Voler();
return t;
}
Ici, la restriction se porte sur deux niveaux. Il faut dans un premier temps que le type générique implémente l’interface IVolant et possède également un constructeur, bref qu’il soit instanciable.
Nous pouvons donc utiliser cette méthode de cette façon :
Oiseau oiseau = Creer<Oiseau>();
Avion a380 = Creer<Avion>();
Nous appelons la méthode Créer() avec le type générique Oiseau, qui implémente bien IVolant et qui est aussi instanciable. Grâce à cela, nous pouvons utiliser l’opérateur new pour créer notre type générique, appeler les méthodes de l’interface et renvoyer l’instance.
Ce qui donne :
Je déplie mes ailes d’oiseau
Je bats des ailes
Je déplie mes ailes mécaniques
J’allume le moteur
Si nous tentons d’utiliser la méthode avec un type qui n’implémente pas l’interface IVolant, comme :
Voiture v = Creer<Voiture>();
Nous aurons l’erreur de compilation suivante :
Le type 'MaPremiereApplication.Voiture' ne peut pas être utilisé comme paramètre de type 'T' dans le type ou la méthode générique 'MaPremiereApplication.Program.Creer<T>()'. Il n'y a pas de conversion de référence implicite de 'MaPremiereApplication.Voiture' en 'MaPremiereApplication.IVolant'.
Globalement, il nous dit que l’objet Voiture n’implémente pas IVolant.
Oui mais dans ce cas, plutôt que d’utiliser une méthode générique, pourquoi la méthode ne renvoie pas IVolant ?
C’est une judicieuse remarque. Mais qui nécessite quelques modifications de code. En effet, il faudrait indiquer quel type instancier.
Nous pourrions par exemple faire :
public enum TypeDeVolant
{
Oiseau,
Avion
}
public static IVolant Creer(TypeDeVolant type)
{
IVolant volant;
switch (type)
{
case TypeDeVolant.Oiseau:
volant = new Oiseau();
break;
case TypeDeVolant.Avion:
volant = new Avion();
break;
default:
return null;
}
volant.DeplierLesAiles();
volant.Voler();
return volant;
}
Et instancier nos objets de cette façon :
Oiseau oiseau = (Oiseau)Creer(TypeDeVolant.Oiseau);
Avion a380 = (Avion)Creer(TypeDeVolant.Avion);
Ce qui complique un peu les choses et rajoute des cast dont on pourrait volontiers se passer. De plus, si nous créons un nouvel objet qui implémente cette interface, il faudrait tout modifier. Avouez qu’avec les types génériques, c’est quand même plus propre. :p
Nous pouvons bien sûr avoir des restrictions sur les types génériques d’une classe. Pour le montrer, nous allons créer une classe dont l’objectif est d’avoir des types valeur qui pourraient ne pas avoir de valeur. Pour les types référence, il suffit d’utiliser le mot-clé null. Mais pour les types valeur comme les entiers, nous n’avons rien pour indiquer que ceux-ci n’ont pas de valeur.
Par exemple :
public class TypeValeurNull<T> where T : struct
{
private bool aUneValeur;
public bool AUneValeur
{
get { return aUneValeur; }
}
private T valeur;
public T Valeur
{
get
{
if (aUneValeur)
return valeur;
throw new InvalidOperationException();
}
set
{
aUneValeur = true;
valeur = value;
}
}
}
Ici, nous utilisons une classe possédant un type générique qui sera un type valeur, grâce à la condition where T : struct. Cette classe encapsule le type générique pour indiquer avec un booléen si le type a une valeur ou pas. Ne faites pas attention à la ligne :
throw new InvalidOperationException();
qui permet juste de renvoyer une erreur, nous étudierons les exceptions un peu plus loin. Elle pourra s’utiliser ainsi :
TypeValeurNull<int> entier = new TypeValeurNull<int>();
if (!entier.AUneValeur)
{
Console.WriteLine("l'entier n'a pas de valeur");
}
entier.Valeur = 5;
if (entier.AUneValeur)
{
Console.WriteLine("Valeur de l'entier : " + entier.Valeur);
}
Et si nous souhaitons avoir pareil pour un autre type valeur, il n’y a rien à faire de plus :
TypeValeurNull<double> valeur = new TypeValeurNull<double>();
C’est quand même super pratique comme classe !! Mais ne rêvons-pas, cette idée ne vient pas de moi. C’est en fait une fonctionnalité du framework .NET : les types nullables.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
En fait, la classe que nous avons vue au-dessus existe déjà dans le framework .NET, et en mieux ! Évidemment. Elle permet de faire exactement ce que j’ai décrit, c'est-à-dire permettre à un type valeur d’avoir une valeur nulle. Elle est mieux faite dans la mesure où elle tire parti de certaines fonctionnalités du framework .NET qui en simplifie l’écriture. Il s’agit de la classe Nullable<>.
Aussi, nous pourrons créer un entier pouvant être null grâce au code suivant :
Nullable<int> entier = null;
if (!entier.HasValue)
{
Console.WriteLine("l'entier n'a pas de valeur");
}
entier = 5;
if (entier.HasValue)
{
Console.WriteLine("Valeur de l'entier : " + entier.Value);
}
Le principe est grosso modo le même sauf que nous pouvons utiliser le mot-clé null ou affecter directement la valeur à l’entier en utilisant l'opérateur d'affectation, sans passer par la propriété Valeur. Il peut aussi être comparé au mot-clé null ou être utilisé avec l’opérateur +, etc. Ceci est possible grâce à certaines fonctionnalités du C# que nous n’avons pas vues et qui sortent de l’étude de ce tutoriel.
Cette classe est tellement pratique que le compilateur a été optimisé pour simplifier son écriture. En effet, utiliser Nullable<> est un peu long pour nous autres informaticiens qui sommes des paresseux. :) Aussi, l’écriture :
Nullable<int> entier = null;
peut se simplifier en :
int? entier = null;
c’est le point d’interrogation qui remplace la déclaration de la classe Nullable<>.
En résumé
Avec les génériques, vous pouvez créer des méthodes ou des classes qui sont indépendantes d'un type. On les appellera des méthodes génériques et des types génériques.
On utilise les chevrons <> pour indiquer le type d'une classe ou d'une méthode générique.
Les interfaces peuvent aussi être génériques, comme l'interface IEnumerable<>.
Les types nullables constituent un exemple d'utilisation très pratique des classes génériques.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ahh, un peu de pratique histoire de vérifier que nous avons bien compris les génériques. C'est un concept assez facile à appréhender mais relativement difficile à mettre en œuvre. Quand en ai-je besoin ? Comment ?
Voici donc un petit exercice qui va vous permettre d'essayer de mettre en œuvre une classe générique.
Instructions pour réaliser la première partie du TP
Dans la première partie du TP, nous allons réaliser une liste chaînée. Il s’agit du grand classique des TP d’informatique en C. Je vous rappelle le principe.
La liste chaînée permet de naviguer d’élément en élément. Quand nous sommes sur le premier élément, le suivant est accessible par sa propriété Suivant. Lorsque nous accédons au suivant, l’élément précédent est accessible par la propriété Precedent et le suivant toujours accessible par la propriété Suivant. S’il n’y a pas de précédent ou pas de suivant, l’élément est null :
Si on insère un élément à la position 1, les autres se décalent :
Voilà, il faut donc créer une telle liste chaînée d’éléments. Le but est bien sûr de faire en sorte que l’élément soit générique. N’hésitez pas à réfléchir un peu avant de vous lancer. Cela pourrait paraître un peu simpliste, mais en fait cela occasionne quelques nœuds au cerveau.
Toujours est-il que je souhaiterais disposer d’une propriété en lecture seule permettant d’accéder au premier élément ainsi qu’une autre propriété également en lecture seule permettant d’accéder au dernier élément. Bien sûr, il faut pouvoir naviguer d’élément en élément avec des propriétés précédent et suivant.
Il faut évidemment une méthode permettant d’ajouter un élément à la fin de la liste. Nous aurons également besoin d’une méthode permettant d’accéder à un élément à partir de son indice et enfin d’une méthode permettant d’insérer un élément à un indice, décalant tous les suivants. Voilà pour la création de la classe !
Ensuite, notre programme instanciera notre liste chaînée pour lui ajouter les entiers 5, 10 et 4. Puis nous afficherons les valeurs de cette liste en nous basant sur la première propriété et en naviguant d’élément en élément. Nous afficherons ensuite les différents éléments en utilisant la méthode d’accès à un élément par son indice. Enfin, nous insérerons la valeur 99 à la première position (position 0), puis la valeur 33 à la deuxième position et enfin la valeur 30 à nouveau à la deuxième position. Puis nous afficherons tout ce beau monde.
Fin de l’énoncé, ouf ! :)
Pour ceux qui n’ont pas besoin d’aide, les explications sont terminées. Ouvrez vos Visual C# Express (ou vos Visual Studio si vous êtes riches ;) ) et à vos claviers.
Pour les autres, je vais essayer de vous guider un peu plus en essayant tout de même de ne pas trop vous donner d’indications non plus.
En fait, votre liste chainée n’est pas vraiment une liste, comme pourrait l’être la List<> que nous connaissons. Cette liste chainée possède un point d’entrée qui est le premier élément. L’ajout du premier élément est très simple, il suffit de mettre à jour une propriété. Pour ajouter l’élément suivant, il faut en fait brancher la propriété Suivant du premier élément à l’élément que nous sommes en train d’ajouter. Et inversement, la propriété Precedent de l’élément que nous souhaitons ajouter sera mise à jour avec le premier élément.
On se rend compte que l’élément est un peu plus complexe qu’un simple type. Nous allons donc avoir une classe générique possédant trois propriétés (Precedent, Suivant et Valeur). Et nous aurons également une classe du même type générique possédant la propriété Premier et la propriété Dernier et les méthodes d’ajout, d’obtention de l’élément et d’insertion.
Allez, je vous en ai assez dit. À vous de jouer ! ^^
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pas si facile hein ? Mais bon, comme vous êtes super entrainés, cela n’a pas dû vous poser trop de problèmes.
Voici la correction que je propose. La première chose à faire est de créer la classe générique permettant de stocker un élément :
public class Chainage<T>
{
public Chainage<T> Precedent { get; set; }
public Chainage<T> Suivant { get; set; }
public T Valeur { get; set; }
}
C’est une classe générique toute simple qui possède une valeur du type générique et deux propriétés du même type que l’élément pour obtenir le précédent ou le suivant. Peut-être que la plus grande difficulté réside ici, de bien modéliser la classe qui permet d’encapsuler l’élément. Il faudra ensuite créer la liste générique et ses méthodes :
public class ListeChainee<T>
{
}
La liste chainée possède également un type générique. Nous créons sa propriété Premier :
public class ListeChainee<T>
{
public Chainage<T> Premier { get; private set; }
}
Là, c’est très simple, il s’agit juste d’une propriété en lecture seule stockant le premier élément. C’est la méthode Ajouter() qui permettra de mettre à jour cette valeur. Notez quand même que nous utilisons le type générique comme type générique de la classe encapsulante.
Par contre, pour la propriété Dernier, c’est un peu plus compliqué. Pour la retrouver, nous allons parcourir tous les éléments à partir de la propriété Premier. Ce qui donne :
public class ListeChainee<T>
{
[…Code supprimé pour plus de clarté…]
public Chainage<T> Dernier
{
get
{
if (Premier == null)
return null;
Chainage<T> dernier = Premier;
while (dernier.Suivant != null)
{
dernier = dernier.Suivant;
}
return dernier;
}
}
}
On parcourt les éléments en bouclant sur la propriété Suivant, tant que celle-ci n’est pas nulle. Il s’agit là d’un parcours assez classique où on utilise une variable temporaire qui passe au suivant à chaque itération.
Nous pouvons à présent créer la méthode Ajouter :
public class ListeChainee<T>
{
[…Code supprimé pour plus de clarté…]
public void Ajouter(T element)
{
if (Premier == null)
{
Premier = new Chainage<T> { Valeur = element };
}
else
{
Chainage<T> dernier = Dernier;
dernier.Suivant = new Chainage<T> { Valeur = element, Precedent = dernier };
}
}
}
Cette méthode traite dans un premier temps le cas du premier élément. Il s’agit simplement de mettre à jour la propriété Premier. De même, grâce au calcul interne de la propriété Dernier, il sera facile d’ajouter un nouvel élément en se branchant sur la propriété Suivant du dernier élément.
Notez que vu que nous ne la renseignons pas, la propriété Suivant du nouvel élément sera bien à null.
Pour obtenir un élément à un indice donné, il suffira de reprendre le même principe que lors du parcours pour obtenir le dernier élément, sauf qu’il faudra s’arrêter au bon moment :
public class ListeChainee<T>
{
[…Code supprimé pour plus de clarté…]
public Chainage<T> ObtenirElement(int indice)
{
Chainage<T> temp = Premier;
for (int i = 1; i <= indice; i++)
{
if (temp == null)
return null;
temp = temp.Suivant;
}
return temp;
}
}
Ici, plusieurs solutions. J’ai choisi d’utiliser une boucle for. Nous aurions très bien pu garder la boucle while comme pour la propriété Dernier.
Enfin, il ne reste plus qu’à insérer un élément :
public class ListeChainee<T>
{
[…Code supprimé pour plus de clarté…]
public void Inserer(T element, int indice)
{
if (indice == 0)
{
Chainage<T> temp = Premier;
Premier = new Chainage<T> { Suivant = temp, Valeur = element };
temp.Precedent = Premier;
}
else
{
Chainage<T> elementAIndice = ObtenirElement(indice);
if (elementAIndice == null)
Ajouter(element);
else
{
Chainage<T> precedent = elementAIndice.Precedent;
Chainage<T> temp = precedent.Suivant;
precedent.Suivant = new Chainage<T> { Valeur = element, Precedent = precedent, Suivant = temp };
}
}
}
}
Nous traitons dans un premier temps le cas où l’on doit insérer l'en-tête. Il suffit de mettre à jour la valeur du premier en ayant au préalable décalé ce dernier d’un cran. Attention, si Premier est null, nous allons avoir un problème. Dans ce cas, soit nous laissons le problème, en effet, peut-on vraiment insérer un élément avant les autres s'il n'y en a pas ? Soit nous gérons le cas et décidons d'insérer l'élément en tant que Premier :
public class ListeChainee<T>
{
[…Code supprimé pour plus de clarté…]
public void Inserer(T element, int indice)
{
if (indice == 0)
{
if (Premier == null)
Premier = new Chainage<T> { Valeur = element };
else
{
Chainage<T> temp = Premier;
Premier = new Chainage<T> { Suivant = temp, Valeur = element };
temp.Precedent = Premier;
}
}
else
{
Chainage<T> elementAIndice = ObtenirElement(indice);
if (elementAIndice == null)
Ajouter(element);
else
{
Chainage<T> precedent = elementAIndice.Precedent;
Chainage<T> temp = precedent.Suivant;
precedent.Suivant = new Chainage<T> { Valeur = element, Precedent = precedent, Suivant = temp };
}
}
}
}
Pour les autres cas, si nous tentons d’insérer à un indice qui n’existe pas, nous insérons à la fin en utilisant la méthode Ajouter() existante. Sinon, on intercale le nouvel élément dans la liste en prenant soin de brancher le précédent sur notre nouvel élément et de brancher le suivant sur notre nouvel élément.
Bon, c’est très bien de pouvoir accéder à un élément par son indice. Mais une liste sur laquelle on ne peut pas faire un foreach, c’est quand même bien dommage. Attaquons désormais la deuxième partie du TP. Toujours dans l’optique de manipuler les génériques, nous allons faire en sorte que notre liste chainée puisse être parcourable en utilisant un foreach.
Nous avons dit plus haut qu’il suffisait d’implémenter l’interface IEnumerable. En l’occurrence, nous allons implémenter sa version générique, vu que nous travaillons avec une classe générique.
Voilà le but de ce TP. Si vous vous le sentez, allez-y ! :)
Je pense par contre que vous allez avoir besoin d’être un peu guidés car c’est une opération un peu particulière. Vous l’aurez deviné, il faut que notre liste implémente l’interface IEnumerable<T>. Le fait d’implémenter cette interface va vous forcer à implémenter deux méthodes GetEnumerator(), la version normale et la version explicite. Sachez dès à présent que les deux méthodes feront exactement la même chose.
Mais, qu’est-ce qu’il raconte ? Implémenter une interface explicitement ? On n’a jamais vu ça !
C’est vrai ! Allez, je vous en parle après la correction. Pour l’instant, cela ne devrait pas vous perturber car les deux méthodes font exactement la même chose. En l’occurrence, elles renverront un Enumerator personnalisé.
Il va donc falloir créer cet Enumerator qui va s’occuper de la mécanique permettant de naviguer dans notre liste. Il s’agit d’une nouvelle classe qui va devoir implémenter l’interface IEnumerator<T>, c’est-à-dire :
public class ListeChaineeEnumerator<T> : IEnumerator<T>
{
}
Cette interface permet d’indiquer que notre enumérateur va respecter le contrat lui permettant de fonctionner avec un foreach. Avec cette interface, vous allez devoir implémenter :
La propriété Current.
La propriété explicite Current (qui sera la même chose que la précédente).
La méthode MoveNext qui permet de passer à l’élément suivant.
La méthode Reset, qui permet de revenir au début de la liste.
Et la méthode Dispose.
La méthode Dispose est en fait héritée de l’interface IDisposable dont hérite l’interface IEnumerator<T>. C’est une interface particulière qui offre l’opportunité de faire tout ce qu’il faut pour nettoyer la classe, c’est-à-dire libérer les variables qui en auraient besoin. En l’occurrence, ici nous n’aurons rien à faire mais il faut quand même que la méthode soit présente. Elle sera donc vide.
Pour implémenter les autres méthodes, il faut que l’énumérateur connaisse la liste qu’il doit énumérer. Il faudra donc que la classe ListeChaineeEnumerator prenne en paramètre de son constructeur la liste à énumérer. Dans ce constructeur, on initialise la variable membre indice qui contient l’indice courant. La propriété Current renverra l’élément à l’indice courant. La méthode MoveNext passe à l’élément suivant et renvoie faux s’il n’y a plus d’éléments, vrai sinon. Enfin la méthode Reset repasse l’indice à sa valeur initiale.
À noter que la valeur initiale de l’indice est -1, car la boucle foreach commence par appeler la méthode MoveNext qui commence par aller à l’élément suivant, c’est-à-dire à l’élément 0. Il ne reste plus qu’à vous dire exactement quoi mettre dans les méthodes GetEnumerator de la liste chainée, car vous ne trouverez peut-être pas du premier coup :
public IEnumerator<T> GetEnumerator()
{
return new ListeChaineeEnumerator<T>(this);
}
IEnumerator IEnumerable.GetEnumerator()
{
return new ListeChaineeEnumerator<T>(this);
}
C’est à vous de jouer pour la suite.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Encore moins facile. Tant qu’on ne l’a pas fait une première fois, implémenter l’interface IEnumerable est un peu déroutant. Après, c’est toujours pareil.
Voici donc ma correction. Tout d’abord, la liste chaînée doit implémenter IEnumerable<T>, ce qui donne :
public class ListeChainee<T> : IEnumerable<T>
{
[…Code identique au TP précédent…]
public IEnumerator<T> GetEnumerator()
{
return new ListeChaineeEnumerator<T>(this);
}
IEnumerator IEnumerable.GetEnumerator()
{
return new ListeChaineeEnumerator<T>(this);
}
}
Là, c’est du tout cuit vu que je vous avais donné la solution un peu plus tôt ! :) J’espère que vous avez au moins réussi ça. ^^
Maintenant, il faut donc créer un nouvel énumérateur personnalisé en lui passant notre liste chainée en paramètres. Cet énumérateur doit implémenter l’interface IEnumerator, ce qui donne :
public class ListeChaineeEnumerator<T> : IEnumerator<T>
{
}
Comme prévu, il faut donc un constructeur qui prend en paramètre la liste chainée :
public class ListeChaineeEnumerator<T> : IEnumerator<T>
{
private int indice;
private ListeChainee<T> listeChainee;
public ListeChaineeEnumerator(ListeChainee<T> liste)
{
indice = -1;
listeChainee = liste;
}
public void Dispose()
{
}
}
Cette liste sera enregistrée dans une variable membre de la classe. Tant que nous y sommes, nous ajoutons un indice privé que nous initialisons à -1, comme déjà expliqué. Notez également que la méthode Dispose() est vide. Reste à implémenter le reste des méthodes :
public class ListeChaineeEnumerator<T> : IEnumerator<T>
{
private int indice;
private ListeChainee<T> listeChainee;
public ListeChaineeEnumerator(ListeChainee<T> liste)
{
indice = -1;
listeChainee = liste;
}
public void Dispose()
{
}
public bool MoveNext()
{
indice++;
Chainage<T> element = listeChainee.ObtenirElement(indice);
return element != null;
}
public T Current
{
get
{
Chainage<T> element = listeChainee.ObtenirElement(indice);
if (element == null)
return default(T);
return element.Valeur;
}
}
object IEnumerator.Current
{
get { return Current; }
}
public void Reset()
{
indice = -1;
}
}
Commençons par la méthode MoveNext(). Elle passe à l’indice suivant et renvoie faux ou vrai en fonction de si on arrive au bout de la liste ou pas. N’oubliez pas que c’est la première méthode qui sera appelée dans le foreach, donc pour passer à l’élément suivant, on incrémente l’indice pour le positionner à l’élément 0. C’est pour cela que l’indice a été initialisé à -1. On utilise ensuite la méthode existante de la liste pour obtenir l’élément à un indice afin de savoir si notre liste peut continuer à s’énumérer.
La propriété Current renvoie l’élément à l’indice courant, pour cela on utilise l’indice pour accéder à l’élément courant, en utilisant les méthodes de la liste. L’autre propriété Current fait la même chose, il suffit d’appeler la propriété Current.
Enfin, la méthode Reset permet de réinitialiser l’énumérateur en retournant à l’indice initial.
Finalement, ce n’est pas si compliqué que ça. Mais il faut avouer que la première fois, c’est un peu déroutant.
À mon sens, c’est un bon exercice pratique. Peut-être que mes explications ont suffi à vous guider. Sans doute avez-vous dû regarder un peu la documentation de IEnumerable sur internet. Dans tous les cas, devoir implémenter une interface du framework .NET est une situation que vous allez fréquemment devoir rencontrer. Il est bon de s’y entrainer !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Vous me direz qu’il fallait le deviner qu’on avait besoin d’une classe indépendante qui permettait de gérer l’énumérateur.
En fait, ce n’est pas obligatoire. On peut très bien faire en sorte que notre classe gère la liste chainée et son énumérateur. Il suffit de faire en sorte que la liste chainée implémente également IEnumerator<T> et de gérer la logique à l’intérieur de la classe.
Par contre, ce n'est pas recommandé. D'une manière générale il est bien qu'une classe n'ait à s'occuper que d'une seule chose. On appelle cela le principe de responsabilité unique (en anglais SRP : Single Responsibility Principle). Plus une classe fait de choses et plus une modification impacte les autres choses. Ici, il est judicieux de garder le découplage des deux classes.
Il y a quand même une chose que l'on peut améliorer dans le code de la correction. En effet, cette liste n’est pas extrêmement optimisée car lorsque nous obtenons un élément, nous re-parcourons toute la liste depuis le début, notamment dans le cas de la gestion de l’énumérateur. Il pourrait être judicieux qu’à chaque foreach, nous ne parcourions pas tous les éléments et qu'on évite d'appeler continuellement la méthode ObtenirElement(). Cela pourrait se faire en éliminant l’indice et en utilisant une variable de type Chainage<T>, par exemple :
public class ListeChaineeEnumerator<T> : IEnumerator<T>
{
private Chainage<T> courant;
private ListeChainee<T> listeChainee;
public ListeChaineeEnumerator(ListeChainee<T> liste)
{
courant = null;
listeChainee = liste;
}
public void Dispose()
{
}
public bool MoveNext()
{
if (courant == null)
courant = listeChainee.Premier;
else
courant = courant.Suivant;
return courant != null;
}
public T Current
{
get
{
if (courant == null)
return default(T);
return courant.Valeur;
}
}
object IEnumerator.Current
{
get { return Current; }
}
public void Reset()
{
courant = null;
}
}
Ici, c’est la variable courant qui nous permet d’itérer au fur et à mesure de la liste chainée. C’est le même principe que dans la méthode ObtenirElement, sauf qu’on ne re-parcoure pas toute la liste à chaque fois. Dans cet exemple, l'optimisation est négligeable. Elle peut s’avérer intéressante si notre liste grossit énormément. Dans tous les cas, ça ne fait pas de mal d’aller plus vite. :)
Remarquons avant de terminer qu'il est possible de simplifier encore la classe grâce à un mot-clé que nous découvrirons dans la partie suivante : yield. Il permet de créer facilement des énumérateurs. Ce qui fait que le code complet de la liste chainée pourra être :
public class ListeChainee<T> : IEnumerable<T>
{
public Chainage<T> Premier { get; private set; }
public Chainage<T> Dernier
{
get
{
if (Premier == null)
return null;
Chainage<T> dernier = Premier;
while (dernier.Suivant != null)
{
dernier = dernier.Suivant;
}
return dernier;
}
}
public void Ajouter(T element)
{
if (Premier == null)
{
Premier = new Chainage<T> { Valeur = element };
}
else
{
Chainage<T> dernier = Dernier;
dernier.Suivant = new Chainage<T> { Valeur = element, Precedent = dernier };
}
}
public Chainage<T> ObtenirElement(int indice)
{
Chainage<T> temp = Premier;
for (int i = 1; i <= indice; i++)
{
if (temp == null)
return null;
temp = temp.Suivant;
}
return temp;
}
public void Inserer(T element, int indice)
{
if (indice == 0)
{
if (Premier == null)
Premier = new Chainage<T> { Valeur = element };
else
{
Chainage<T> temp = Premier;
Premier = new Chainage<T> { Suivant = temp, Valeur = element };
temp.Precedent = Premier;
}
}
else
{
Chainage<T> elementAIndice = ObtenirElement(indice);
if (elementAIndice == null)
Ajouter(element);
else
{
Chainage<T> precedent = elementAIndice.Precedent;
Chainage<T> temp = precedent.Suivant;
precedent.Suivant = new Chainage<T> { Valeur = element, Precedent = precedent, Suivant = temp };
}
}
}
public IEnumerator<T> GetEnumerator()
{
Chainage<T> courant = Premier;
while (courant != null)
{
yield return courant.Valeur;
courant = courant.Suivant;
}
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
Remarquons que nous n'avons plus besoin de la classe ListeChaineeEnumerator. L'implémentation devient très facile. Nous reviendrons sur ce mot-clé dans la partie suivante.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
J’en profite ici pour faire un aparté sur l’implémentation d’interface explicite.
J’ai choisi délibérément de ne pas le mettre dans le chapitre des interfaces car c’est un cas relativement rare mais qui se produit justement quand on implémente l’interface IEnumerable<T>. Cela vient du fait que l’interface IEnumerable, non générique, expose une propriété Current. De même, l’interface IEnumerable<T>, générique, qui hérite de IEnumerable, expose également une propriété Current.
Il y a donc une ambiguïté car les deux propriétés portent le même nom, mais ne renvoient pas la même chose. Ce qui est contraire aux règles que nous avons déjà vues. Pour faire la différence, il suffira de préfixer la propriété par le nom de l’interface et de ne pas mettre le mot-clé public.
L’implémentation explicite a également un intérêt dans le code suivant :
public interface ICarnivore
{
void Manger();
}
public interface IFrugivore
{
void Manger();
}
public class Homme : ICarnivore, IFrugivore
{
public void Manger()
{
Console.WriteLine("Je mange");
}
}
class Program
{
static void Main(string[] args)
{
Homme homme = new Homme();
homme.Manger();
((ICarnivore)homme).Manger();
((IFrugivore)homme).Manger();
}
}
Ici, ce code compile car la classe Homme implémente la méthode Manger qui est commune aux deux interfaces. Par contre, il n’est pas possible de faire la distinction entre le fait de manger en tant qu’homme, en tant que ICarnivore ou en tant que IFrugivore.
Ce code affichera :
Je mange
Je mange
Je mange
Si c’est le comportement attendu, tant mieux. Si ce n’est pas le cas, il va falloir implémenter au moins une des interfaces de manière explicite :
public class Homme : ICarnivore, IFrugivore
{
public void Manger()
{
Console.WriteLine("Je mange");
}
void IFrugivore.Manger()
{
Console.WriteLine("Je mange en tant que IFrugivore");
}
void ICarnivore.Manger()
{
Console.WriteLine("Je mange en tant que ICarnivore");
}
}
Avec ce code, notre exemple affichera :
Je mange
Je mange en tant que ICarnivore
Je mange en tant que IFrugivore
Si vous vous rappelez, nous avions vu au moment du chapitre sur les interfaces que Visual C# Express nous proposait de nous aider dans l’implémentation de l’interface. Par le bouton droit, vous aviez également accès à sous menu « implémenter l’interface explicitement ». Vous pouvez vous en servir dans ce cas précis.
Je m’arrête là sur l’implémentation d’interface explicite, même s’il y aurait d’autres points à voir. Globalement dans la vraie vie, ils ne vous serviront jamais.
Voilà pour ce TP. Nous avons créé une classe générique permettant de gérer les listes chainées. Ceci nous a permis de manipuler ces types ô-combien indispensables et de nous entrainer à la généricité. Nous en avons même profité pour voir comment faire en sorte qu’une classe soit énumérable, en implémentant la version générique de IEnumerable.
Notez bien sûr que cette classe est fonctionnellement incomplète. Il aurait été judicieux de rajouter une méthode permettant de supprimer un élément par exemple. D’ailleurs, n’hésitez pas à la créer et à la proposer si vous souhaitez continuer à vous entrainer. D’autres méthodes pourraient être intéressantes, comme vider la liste d’un seul coup…
J’espère que ce TP n’a pas été trop compliqué à réaliser. ^^
À noter qu’une classe qui fait à peu près le même travail existe dans le framework .NET, elle s’appelle LinkedList.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
En général, pour ajouter des fonctionnalités à une classe, nous pourrons soit modifier le code source de la classe, soit créer une classe dérivée de notre classe et ajouter ces fonctionnalités.
Dans ce chapitre nous allons voir qu'il existe un autre moyen pour étendre une classe : ceci est possible grâce aux méthodes d'extension. Elles sont intéressantes si nous n'avons pas la main sur le code source de la classe ou si la classe n'est pas dérivable.
Comme son nom l’indique, une méthode d’extension permet d’étendre une classe en lui rajoutant des méthodes. Ceci est pratique lorsque nous ne possédons pas le code source d’une classe et qu’il s’avère difficile de la modifier.
D’une manière générale, lorsque l’on souhaite modifier une classe dont on n’a pas le code source, on utilise une classe dérivée. Ceci est impossible avec des objets qui ne sont pas dérivables, comme c’est le cas pour les structures comme int ou double. Mais également comme c’est le cas pour la classe String. En effet, String n’est pas dérivable. Nous verrons plus tard comment cela est possible, mais pour l’instant, admettons-le.
Si vous ne me croyez pas, vous pouvez toujours tenter de compiler le code suivant :
public class StringEvoluee : String
{
}
:p
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Si par exemple nous souhaitons créer une méthode permettant de crypter une chaine de caractères dans un format que nous seuls comprenons, il serait judicieux de créer une méthode dans une classe StringCryptee qui dérive de string. Comme ceci n’est pas possible, la seule chose qui nous reste c’est de créer une méthode statique utilitaire faisant cet encodage :
class Program
{
static void Main(string[] args)
{
string chaineNormale = "Bonjour à tous";
string chaineCryptee = Encodage.Crypte(chaineNormale);
Console.WriteLine(chaineCryptee);
chaineNormale = Encodage.Decrypte(chaineCryptee);
Console.WriteLine(chaineNormale);
}
}
public static class Encodage
{
public static string Crypte(string chaine)
{
return Convert.ToBase64String(Encoding.Default.GetBytes(chaine));
}
public static string Decrypte(string chaine)
{
return Encoding.Default.GetString(Convert.FromBase64String(chaine));
}
}
Bon, ok, notre encodage secret ne l’est pas tant que ça :D . Il s’avère que j’utilise ici un encodage en base 64, algorithme archi connu. Mais bon, c’est pour l’exemple.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Ces méthodes statiques jouent bien leur rôle. Mais il est possible de faire en sorte que ces deux méthodes deviennent des méthodes d’extensions de la classe string. Il suffit d’utiliser le mot-clé this devant le premier paramètre de la méthode afin de créer une méthode d’extension :
public static class Encodage
{
public static string Crypte(this string chaine)
{
return Convert.ToBase64String(Encoding.Default.GetBytes(chaine));
}
public static string Decrypte(this string chaine)
{
return Encoding.Default.GetString(Convert.FromBase64String(chaine));
}
}
Nous pourrons désormais utiliser ces méthodes comme si elles faisaient parties de la classe String :
Pas mal non ? De plus, si nous regardons dans la complétion automatique, nous pourrons voir apparaître nos fameuses méthodes :
Plutôt pratique.
Évidemment, en créant une méthode d’extension, nous n’avons bien sûr pas accès aux méthodes privées ou variables membres internes à la classe. La preuve, les méthodes d’extensions sont des méthodes statiques qui travaillent hors de toute instance de classe.
Par contre, il faut faire attention à l’espace de nom où se situent nos méthodes d’extensions. Si le using correspondant n’est pas inclus, nous ne verrons pas les méthodes d’extension.
Remarquez que les méthodes d’extension fonctionnent aussi avec les interfaces. Plus précisément, elles viennent étendre toutes les classes qui implémentent une interface. Par exemple, avec deux classes implémentant l’interface IVolant :
public interface IVolant
{
void Voler();
}
public class Oiseau : IVolant
{
public void Voler()
{
Console.WriteLine("Je vole");
}
}
public class Avion : IVolant
{
public void Voler()
{
Console.WriteLine("Je vole");
}
}
si je crée une méthode d’extension prenant en paramètres un IVolant, préfixé par this :
public static class Extentions
{
public static void Atterir(this IVolant volant)
{
Console.WriteLine("J'attéris");
}
}
je pourrais accéder à cette méthode pour les objets Avion et Oiseau :
Avion a = new Avion();
Oiseau b = new Oiseau();
a.Atterir();
b.Atterir();
À noter que le framework .NET se sert de ceci pour proposer un grand nombre de méthodes d’extension sur les objets implémentant IEnumerable, nous les étudierons un peu plus tard.
En résumé
Une méthode d'extension permet d'étendre une classe en lui rajoutant des méthodes.
Il n'est pas recommandé d'utiliser des méthodes d'extension lorsqu'on dispose déjà du code source de la classe ou qu'on peut facilement en créer un type dérivé.
On utilise le mot-clé this en premier paramètre d'une classe statique pour étendre une classe.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans ce chapitre, nous allons aborder les délégués, les événements et les expressions lambdas. Les délégués et les événements sont des types du framework .NET que nous n'avons pas encore vus. Ils permettent d'adresser des solutions notamment dans le cadre d'une programmation par événements, comme c'est le cas lorsque nous réalisons des applications nécessitant de réagir à une action faite par un utilisateur. Nous verrons dans ce chapitre que les expressions lambdas vont de pair avec les délégués.
Les délégués (en anglais delegate) en C# ne s’occupent pas de la classe, ni du personnel... Ils permettent de créer des variables spéciales. Ce sont des variables qui « pointent » vers une méthode. C’est un peu comme les pointeurs de fonctions en C ou C++, sauf qu’ici on sait exactement ce que l’on utilise, car le C# est un langage fortement typé.
Le délégué va nous permettre de définir une signature de méthode et avec lui, nous pourrons pointer vers n’importe quelle méthode qui respecte cette signature.
En général, on utilise un délégué quand on veut passer une méthode en paramètres d’une autre méthode. Un petit exemple sera sans doute plus parlant qu’un long discours. Ainsi, le code suivant :
public class TrieurDeTableau
{
private delegate void DelegateTri(int[] tableau);
}
crée un délégué privé à la classe TrieurDeTableau qui permettra de pointer vers des méthodes qui ne retournent rien (void) et qui acceptent un tableau d’entier en paramètres.
C’est justement le cas des méthodes TriAscendant() et TriDescendant() que nous allons rajouter à la classe (ça tombe bien !) :
Vous aurez compris que la méthode TriAscendant utilise la méthode Array.Sort pour trier un tableau par ordre croissant. Inversement, la méthode TriDescendant() trie le tableau par ordre décroissant en triant par ordre croissant et en inversant le tableau ensuite.
Il ne reste plus qu’à créer une méthode dans la classe permettant d’utiliser le tri ascendant et le tri descendant, grâce à notre délégué :
public class TrieurDeTableau
{
[…Code supprimé pour plus de clarté…]
public void DemoTri(int[] tableau)
{
DelegateTri tri = TriAscendant;
tri(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
Console.WriteLine();
tri = TriDescendant;
tri(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
}
}
Nous voyons ici que dans la méthode DemoTri nous commençons par déclarer une variable du type du délégué DelegateTri, qui est le délégué que nous avons créé. Puis nous faisons pointer cette variable vers la méthode TriAscendant().
Nous invoquons ensuite la méthode TriAscendant() à travers la variable qui va permettre de trier le tableau par ordre croissant avant d’afficher son contenu. Cette fois-ci, il faut bien sûr utiliser les parenthèses car nous invoquons la méthode. Puis nous faisons pointer la variable vers la méthode TriDescendant() qui va nous permettre de faire la même chose mais avec un tri décroissant.
Nous pouvons appeler cette classe de cette façon :
Notre code affichera au final les entiers triés par ordre croissant, puis les mêmes entiers triés par ordre décroissant.
Ok, mais pourquoi utiliser ce délégué ? On pourrait très bien appeler d’abord la méthode de tri ascendant et ensuite la méthode de tri descendant. Comme on l’a toujours fait !
Eh bien, l’intérêt ici est que le délégué est très souple et va permettre de réorganiser le code (on parle également de refactoriser du code). Ainsi, en rajoutant la méthode suivante dans la classe :
private void TrierEtAfficher(int[] tableau, DelegateTri methodeDeTri)
{
methodeDeTri(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
}
Nous pourrons grandement simplifier la méthode DemoTri :
Ce qui produira le même résultat que précédemment. Qu’avons-nous fait ici ?
Nous avons utilisé le délégué comme paramètre d’une méthode. Ce délégué est ensuite utilisé pour invoquer une méthode que nous aurons passée en paramètres. C’est ce que nous faisons en disant d’utiliser la méthode TrierEtAfficher une première fois avec la méthode TriAscendant() et une deuxième fois avec la méthode TriDescendant().
Plutôt pas mal non ?
Il est même possible de définir la méthode qui sera utilisée à l’intérieur de TrierEtAfficher() sans avoir à l’écrire complètement dans le corps de la classe. Cela peut être utile si la méthode est vouée à n'être utilisée que dans cette unique situation et qu’elle n’est jamais appelée à un autre endroit. Par exemple, plutôt que de définir complètement la méthode TriAscendant(), je pourrais la définir directement au moment de l’appel de la méthode :
public class TrieurDeTableau
{
private delegate void DelegateTri(int[] tableau);
private void TrierEtAfficher(int[] tableau, DelegateTri methodeDeTri)
{
methodeDeTri(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
}
public void DemoTri(int[] tableau)
{
TrierEtAfficher(tableau, delegate(int[] leTableau)
{
Array.Sort(leTableau);
});
Console.WriteLine();
TrierEtAfficher(tableau, delegate(int[] leTableau)
{
Array.Sort(leTableau);
Array.Reverse(leTableau);
});
}
}
Ainsi, je n’aurai plus besoin de la méthode TriAscendant() ni de la méthode TriDescendant().
Le fait de définir la méthode directement au niveau du paramètre d’appel est ce qu’on appelle « utiliser une méthode anonyme ». Anonyme car la méthode n’a pas de nom. Elle n’a de vie qu’à cet endroit-là. La syntaxe est un peu particulière, mais au lieu d’utiliser une variable de type delegate qui pointe vers une méthode, c’est comme si on écrivait directement la méthode. On utilise le mot-clé delegate suivi de la déclaration du paramètre. Évidemment, le délégué anonyme doit respecter la signature de DelegateTri que nous avons définie plus haut. Enfin, nous faisons suivre avec un bloc de code qui correspond au corps de la méthode anonyme.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il faut également savoir que le délégué peut être multicast, c'est à dire qu’il peut pointer vers plusieurs méthodes. Améliorons le premier exemple :
public class TrieurDeTableau
{
private delegate void DelegateTri(int[] tableau);
private void TriAscendant(int[] tableau)
{
Array.Sort(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
Console.WriteLine();
}
private void TriDescendant(int[] tableau)
{
Array.Sort(tableau);
Array.Reverse(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
}
public void DemoTri(int[] tableau)
{
DelegateTri tri = TriAscendant;
tri += TriDescendant;
tri(tableau);
}
}
Ici, j’utilise Console.WriteLine directement dans chaque méthode de tri afin de bien voir le résultat du tri du tableau. L’important est de voir que dans la méthode DemoTri, je commence par créer un délégué que je fais pointer vers la méthode TriAscendant. Puis j’ajoute à ce délégué, avec l’opérateur +=, une nouvelle méthode, à savoir TriDescendant. Désormais, le fait d’invoquer le délégué va invoquer en fait les deux méthodes. Ce qui produira en sortie :
1
4
5
6
8
10
10
8
6
5
4
1
Ce détail prend toute son importance avec les événements que nous verrons plus loin. À noter que le résultat de ce code est évidemment identique en utilisant les méthodes anonymes :
public void DemoTri(int[] tableau)
{
DelegateTri tri = delegate(int[] leTableau)
{
Array.Sort(leTableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
Console.WriteLine();
};
tri += delegate(int[] leTableau)
{
Array.Sort(tableau);
Array.Reverse(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
};
tri(tableau);
}
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
C’est très bien tout ça, mais cela veut dire qu’à chaque fois que je vais avoir besoin d’utiliser un délégué, je vais devoir créer un nouveau type en utilisant le mot-clé delegate ?
Pas forcément, c’est là qu’interviennent les délégués génériques Action et Func. Action est un délégué qui permet de pointer vers une méthode qui ne renvoie rien et qui peut accepter jusqu’à 16 types différents. Cela veut dire que le code précédent peut être remplacé par :
public class TrieurDeTableau
{
private void TrierEtAfficher(int[] tableau, Action<int[]> methodeDeTri)
{
methodeDeTri(tableau);
foreach (int i in tableau)
{
Console.WriteLine(i);
}
}
public void DemoTri(int[] tableau)
{
TrierEtAfficher(tableau, delegate(int[] leTableau)
{
Array.Sort(leTableau);
});
Console.WriteLine();
TrierEtAfficher(tableau, delegate(int[] leTableau)
{
Array.Sort(tableau);
Array.Reverse(tableau);
});
}
}
Notez que la différence se situe au niveau du paramètre de la méthode TrierEtAfficher qui prend un Action<int[]>. En fait, cela est équivalent à créer un délégué qui ne renvoie rien et qui prend un tableau d’entier en paramètre. Si notre méthode avait deux paramètres, il aurait suffi d’utiliser la forme de Action avec plusieurs paramètres génériques, par exemple Action<int[], string> pour avoir une méthode qui ne renvoie rien et qui prend un tableau d’entier et une chaine de caractères en paramètres.
Lorsque la méthode renvoie quelque chose, on peut utiliser le délégué Func<T>, sachant qu’ici, c’est le dernier paramètre générique qui sera du type de retour du délégué. Par exemple :
public class Operations
{
public void DemoOperations()
{
double division = Calcul(delegate(int a, int b)
{
return (double)a / (double)b;
}, 4, 5);
double puissance = Calcul(delegate(int a, int b)
{
return Math.Pow((double)a, (double)b);
}, 4, 5);
Console.WriteLine("Division : " + division);
Console.WriteLine("Puissance : " + puissance);
}
private double Calcul(Func<int, int, double> methodeDeCalcul, int a, int b)
{
return methodeDeCalcul(a, b);
}
}
Ici, dans la méthode Calcul, on utilise le délégué Func pour indiquer que la méthode prend deux entiers en paramètres et renvoie un double. Si nous utilisons cette classe avec le code suivant :
class Program
{
static void Main(string[] args)
{
new Operations().DemoOperations();
}
}
Nous aurons :
Division : 0,8
Puissance : 1024
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Non, il ne s’agit pas d’une expression qui danse la lambada, mais d’une façon simplifiée d’écrire les délégués que nous avons vus au-dessus. ;)
Ainsi, le code suivant :
DelegateTri tri = delegate(int[] leTableau)
{
Array.Sort(leTableau);
};
peut également s’écrire de cette façon :
DelegateTri tri = (leTableau) =>
{
Array.Sort(leTableau);
};
Cette syntaxe est particulière. La variable leTableau permet de spécifier le paramètre d’entrée de l’expression lambda. Ce paramètre est écrit entre parenthèses. Ici, pas besoin d’indiquer son type vu qu’il est connu par la signature associée au délégué. On utilise ensuite la flèche « => » pour définir l’expression lambda qui sera utilisée. Elle s’écrit de la même façon qu’une méthode, dans un bloc de code.
L’expression lambda « (leTableau) => » se lit : « leTableau conduit à ».
Dans le corps de la méthode, nous voyons que nous utilisons la variable leTableau de la même façon que précédemment. Dans ce cas précis, il est encore possible de raccourcir l’écriture car la méthode ne contient qu’une seule ligne, on pourra alors l’écrire de cette façon :
Quand il y a deux paramètres, on les sépare par une virgule. À noter qu’on n’indique nulle part le type de retour s’il y en a un. Notre expression lambda remplaçant le calcul de la division peut donc s’écrire ainsi :
Les événements sont un mécanisme du C# permettant à une classe d’être notifiée d’un changement. Par exemple, on peut vouloir s’abonner à un changement de prix d’une voiture.
La base des événements est le délégué. On pourra stocker dans un événement un ou plusieurs délégués qui pointent vers des méthodes respectant la signature de l’événement.
Un événement est défini grâce au mot-clé event. Prenons cet exemple :
public class Voiture
{
public delegate void DelegateDeChangementDePrix(decimal nouveauPrix);
public event DelegateDeChangementDePrix ChangementDePrix;
public decimal Prix { get; set; }
public void PromoSurLePrix()
{
Prix = Prix / 2;
if (ChangementDePrix != null)
ChangementDePrix(Prix);
}
}
Dans la classe Voiture, nous définissons un délégué qui ne retourne rien et qui prend en paramètre un décimal. Nous définissons ensuite un événement basé sur ce délégué, avec comme nous l’avons vu, l’utilisation du mot-clé event. Enfin, dans la méthode de promotion, après un changement de prix (division par 2), nous notifions les éventuels objets qui se seraient abonnés à cet événement en invoquant l’événement et en lui fournissant en paramètre le nouveau prix.
À noter que nous testons d’abord s’il y a un abonné à l’événement (en testant s’il est différent de null) avant de le lever. Pour s’abonner à cet événement, il suffit d’utiliser le code suivant :
class Program
{
static void Main(string[] args)
{
new DemoEvenement().Demo();
}
}
public class DemoEvenement
{
public void Demo()
{
Voiture voiture = new Voiture { Prix = 10000 };
Voiture.DelegateDeChangementDePrix delegateChangementDePrix = voiture_ChangementDePrix;
voiture.ChangementDePrix += delegateChangementDePrix;
voiture.PromoSurLePrix();
}
private void voiture_ChangementDePrix(decimal nouveauPrix)
{
Console.WriteLine("Le nouveau prix est de : " + nouveauPrix);
}
}
Nous créons une voiture, et nous créons un délégué du même type que l’événement. Nous le faisons pointer vers une méthode qui respecte la signature du délégué. Ainsi, à chaque changement de prix, la méthode voiture_ChangementDePrix va être appelée et le paramètre nouveauPrix possèdera le nouveau prix qui vient d’être calculé.
Appelons la promotion en invoquant la méthode ChangementDePrix(), nous pouvons nous rentre compte que l’application nous affiche le nouveau prix qui est l’ancien divisé par 2.
Lorsque nous commençons à écrire le code qui va permettre de nous abonner à l’événement, la complétion automatique nous propose facilement de créer une méthode qui respecte la signature de l’événement. Il suffit de taper l’événement de rajouter un += et il nous propose d’insérer tout automatiquement si nous appuyons sur la tabulation :
Ce qui génère le code suivant :
voiture.ChangementDePrix += new Voiture.DelegateDeChangementDePrix(voiture_ChangementDePrix);
ainsi que la méthode :
void voiture_ChangementDePrix(decimal nouveauPrix)
{
throw new NotImplementedException();
}
L’utilisation du « += » permet d’ajouter un nouveau délégué à l’événement. Il sera éventuellement possible d’ajouter un autre délégué avec le même opérateur, ainsi deux méthodes seront désormais notifiées en cas de changement de prix. Inversement, il est possible de se désabonner d’un événement en utilisant l’opérateur « -= ».
Les événements sont beaucoup utilisés dans les applications en C#, comme les applications clients lourds développées avec WPF par exemple. Ce sont des applications comme un traitement de texte ou un navigateur internet. Par exemple, lorsque l'on clique sur un bouton, un événement est levé.
Ces événements utilisent en général une construction à base du délégué EventHandler ou sa version générique EventHandler<>. Ce délégué accepte deux paramètres. Le premier de type object qui représente la source de l'événement, c'est-à-dire l'objet qui a levé l'événement. Le second est une classe qui dérive de la classe de base EventArgs.
Réécrivons notre exemple avec ce nouveau handler. Nous avons donc besoin en premier lieu d'une classe qui dérive de la classe EventArgs :
public class ChangementDePrixEventArgs : EventArgs
{
public decimal Prix { get; set; }
}
Plus besoin de déclaration de délégué, nous utilisons directement EventHandler dans notre classe Voiture :
public class Voiture
{
public event EventHandler<ChangementDePrixEventArgs> ChangementDePrix;
public decimal Prix { get; set; }
public void PromoSurLePrix()
{
Prix = Prix / 2;
if (ChangementDePrix != null)
ChangementDePrix(this, new ChangementDePrixEventArgs { Prix = Prix });
}
}
Et notre démo devient :
class Program
{
static void Main(string[] args)
{
new DemoEvenement().Demo();
}
}
public class DemoEvenement
{
public void Demo()
{
Voiture voiture = new Voiture { Prix = 10000 };
voiture.ChangementDePrix += voiture_ChangementDePrix;
voiture.PromoSurLePrix();
}
private void voiture_ChangementDePrix(object sender, ChangementDePrixEventArgs e)
{
Console.WriteLine("Le nouveau prix est de : " + e.Prix);
}
}
Remarquons la méthode voiture_ChangementDePrix qui prend désormais deux paramètres. Le premier représente l'objet Voiture, si nous en avions besoin, nous pourrions l'utiliser avec un cast adéquat. Le second représente l'objet contenant le prix de la voiture en promotion.
À noter qu'en général, nous allons beaucoup utiliser les événements définis par le framework .NET. Il est cependant assez rare d’avoir à en définir un soi-même.
En résumé
Les délégués permettent de créer des variables pointant vers des méthodes.
Les délégués sont à la base des événements.
On utilise les expressions lambdas pour simplifier l'écriture des délégués.
Les événements sont un mécanisme du C# permettant à une classe d'être notifiée d'un changement.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons parlé rapidement des erreurs dans nos applications C# en disant qu'il s'agissait d'exceptions. C'est le moment d'en savoir un peu plus et surtout d'apprendre à les gérer ! Dans ce chapitre, nous allons apprendre comment créer et intercepter une exception.
string chaine = "dix";
int valeur = Convert.ToInt32(chaine);
Si nous l’exécutons, nous aurons l’erreur suivante :
L’application nous affiche un message d’erreur et l’application « plante » lamentablement produisant un rapport d’erreur. Ce qu’il se passe en fait, c’est que lors de la conversion, si le framework .NET n’arrive pas à convertir correctement la chaine de caractères en entier, il lève une exception. Cela veut dire qu’il informe le programme qu’il rencontre un cas limite qui nécessite d’être géré. Si ce cas limite n’est pas géré, alors l’application plante et c’est le CLR qui intercepte l’erreur et qui fait produire un rapport au système d’exploitation.
Pourquoi une exception et pas un message d’erreur ?
L’intérêt des exceptions est qu'elles sont typées. Finis les codes d’erreurs incompréhensibles. C’est le type de l’exception, c'est-à-dire sa classe, qui va nous permettre d’identifier le problème.
Pour éviter le plantage de l’application, nous devons gérer ces cas limites et intercepter les exceptions. Pour ce faire, il faut encadrer les instructions pouvant atteindre des cas limites avec le bloc d’instruction try…catch, par exemple :
try
{
string chaine = "dix";
int valeur = Convert.ToInt32(chaine);
Console.WriteLine("Ce code ne sera jamais affiché");
}
catch (Exception)
{
Console.WriteLine("Une erreur s'est produite dans la tentative de conversion");
}
Si nous exécutons ce bout de code, l’application ne plantera plus et affichera qu’une erreur s’est produite…
Nous avons « attrapé » l’exception levée par la méthode de conversion grâce au mot-clé catch. Cette construction nous permet de surveiller l’exécution d’un bout de code, situé dans le bloc try et s’il y a une erreur, alors nous interrompons son exécution pour traiter l’erreur en allant dans le bloc catch. La suite du code dans le try, à savoir l’affichage de la ligne avec Console.WriteLine, ne sera jamais exécuté car lorsque la conversion échoue, il saute directement au bloc catch. Inversement, il est possible de ne jamais passer dans le bloc catch si les instructions ne provoquent pas d’erreur :
try
{
string chaine = "10";
int valeur = Convert.ToInt32(chaine);
Console.WriteLine("Conversion OK");
}
catch (Exception)
{
Console.WriteLine("Nous ne passons jamais ici ...");
}
Ainsi le code ci-dessus affichera bien uniquement que la conversion est bonne. Et en toute logique, il ne passera pas dans le bloc de traitement d’erreur, car il n’y en a pas eu. Il est possible d’obtenir des informations sur l’exception en utilisant un paramètre dans le bloc catch :
try
{
string chaine = "dix";
int valeur = Convert.ToInt32(chaine);
}
catch (Exception ex)
{
Console.WriteLine("Il y a un eu une erreur, plus d'informations ci-dessous :");
Console.WriteLine();
Console.WriteLine("Message d'erreur : " + ex.Message);
Console.WriteLine();
Console.WriteLine("Pile d'appel : " + ex.StackTrace);
Console.WriteLine();
Console.WriteLine("Type de l'exception : " + ex.GetType());
}
Ici, nous affichons le message d’erreur, la pile d’appel et le type de l’exception, ce qui donne :
D’une manière générale, la méthode ToString() de l’exception fournit des informations suffisantes pour identifier l’erreur :
try
{
string chaine = "dix";
int valeur = Convert.ToInt32(chaine);
}
catch (Exception ex)
{
Console.WriteLine("Il y a un eu une erreur : " + ex.ToString());
}
Ce qui donne :
Les exceptions peuvent être de beaucoup de formes. Ici nous remarquons que l’exception est de type System.FormatException. Cette exception est utilisée en général lorsque le format d’un paramètre ne correspond pas à ce qui est attendu. En l’occurrence ici nous attendons un paramètre de type chaine de caractères qui représente un entier. C’est une exception spécifique qui est dédiée à un type d’erreur précis.
Il faut savoir que comme beaucoup d’autres objets du framework .NET, les exceptions spécifiques dérivent d’une classe de base, à savoir la classe Exception. Il existe une hiérarchie entre les exceptions. Globalement, deux grandes familles d’exceptions existent : ApplicationException et SystemException. Elles dérivent toutes les deux de la classe de base Exception. La première est utilisée lorsque des erreurs récupérables sur des applications apparaissent, la seconde est utilisée pour toutes les exceptions générées par le framework .NET. Par exemple, l’exception que nous avons vue, FormatException dérive directement de SystemException qui dérive elle-même de la classe Exception.
Le framework .NET dispose de beaucoup d’exceptions correspondant à beaucoup de situations. Notons encore au passage une autre exception bien connue des développeurs qui est la NullReferenceException. Elle se produit lorsqu’on essaie d’accéder à un objet qui vaut null. Par exemple :
Voiture voiture = null;
voiture.Vitesse = 10;
Vous aurez remarqué que dans la construction suivante :
try
{
string chaine = "dix";
int valeur = Convert.ToInt32(chaine);
}
catch (Exception ex)
{
Console.WriteLine("Il y a un eu une erreur : " + ex.ToString());
}
nous voyons que le bloc catch prend en paramètre la classe de base Exception. Cela veut dire que nous souhaitons intercepter toutes les exceptions qui dérivent de Exception ; c’est-à-dire en fait toutes les exceptions, car pour avoir une exception, elle doit forcément dériver de la classe Exception. C’est utile lorsque nous voulons attraper toutes les exceptions. Mais savons-nous forcément quoi faire dans le cas de toutes les erreurs ? Il est possible d’être plus précis afin de n’attraper qu’un seul type d’exception. Il suffit de préciser le type de l’exception attendu comme paramètre du catch. Par exemple le code suivant nous permet d’intercepter toutes les exceptions du type FormatException :
Cela veut par contre dire que si nous avons une autre exception à ce moment-là, du style NullReferenceException, l’exception ne sera pas attrapée. Ce qui fait que le code suivant va planter :
try
{
Voiture v = null;
v.Vitesse = 10;
}
catch (FormatException ex)
{
Console.WriteLine("Erreur de format : " + ex);
}
En effet, nous demandons la surveillance de l’exception FormatException uniquement. Ainsi, l’exception NullReferenceException ne sera pas attrapée.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour attraper les deux exceptions, il est possible d’enchainer les blocs catchavec des paramètres différents :
try
{
// code provoquant une exception
}
catch (FormatException ex)
{
Console.WriteLine("Erreur de format : " + ex);
}
catch (NullReferenceException ex)
{
Console.WriteLine("Erreur de référence nulle : " + ex);
}
Dans ce code, cela veut dire que si le code surveillé provoque une FormatException, alors nous afficherons le message « Erreur de format … ». S’il provoque une NullReferenceException, alors nous afficherons le message « Erreur de référence nulle … ». Notez bien que nous ne pouvons rentrer à chaque fois que dans un seul bloc catch. Une autre solution serait d’attraper une exception plus généraliste par exemple SystemException dont dérive FormatException et NullReferenceException :
try
{
// code provoquant une exception
}
catch (SystemException ex)
{
Console.WriteLine("Erreur système : " + ex);
}
Par contre, il faut savoir que le code précédent attrape toutes les exceptions qui dérivent de SystemException. C’est le cas de FormatException et NullReferenceException, mais c’est aussi le cas pour beaucoup d’autres exceptions. Lorsqu’on surveille un bloc de code, on commence en général par surveiller toutes les exceptions les plus fines possibles qui nous intéressent et on remonte en considérant les exceptions plus générales, jusqu’à terminer par la classe Exception :
try
{
// code provoquant une exception
}
catch (FormatException ex)
{
Console.WriteLine("Erreur de format : " + ex);
}
catch (NullReferenceException ex)
{
Console.WriteLine("Erreur de référence nulle : " + ex);
}
catch (SystemException ex)
{
Console.WriteLine("Erreur système autres que FormatException et NullReferenceException : " + ex);
}
catch(Exception ex)
{
Console.WriteLine("Toutes les autres exceptions : " + ex);
}
À chaque exécution, c’est le bloc catch qui se rapproche le plus de l’exception levée qui est utilisé. C’est un peu comme une opération conditionnelle. .NET vérifie dans un premier temps que l’exception n’est pas une FormatException. Si ce n’est pas le cas, il vérifiera qu’il n’a pas à faire à une NullReferenceException. Ensuite, il vérifiera qu’il ne s’agit pas d’une SystemException. Enfin, il interceptera toutes les exceptions dans le dernier bloc de code car « Exception » étant la classe mère, toutes les exceptions sont interceptées avec ce type.
A noter qu’il est possible d’imbriquer les try…catch si cela s’avère pertinent. Par exemple :
string saisie = Console.ReadLine();
try
{
int entier = Convert.ToInt32(saisie);
Console.WriteLine("La saisie est un entier");
}
catch (FormatException)
{
try
{
double d = Convert.ToDouble(saisie);
Console.WriteLine("La saisie est un double");
}
catch (FormatException)
{
Console.WriteLine("La saisie n'est ni un entier, ni un double");
}
}
Ce code nous permet de tester si la saisie est un entier. Si une exception se produit, alors nous tentons de le convertir en double. S’il y a encore une exception, alors nous affichons un message indiquant que les deux conversions ont échoué.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu que lorsqu’un code était surveillé dans un bloc try…catch, on sortait du bloc try si jamais une exception était levée, pour atterrir dans le bloc catch. Cela veut dire qu’il est impossible de garantir qu’une instruction sera exécutée dans notre code, si jamais une exception nous fait sortir du bloc. C’est là qu’intervient le mot-clé finally. Il permet d’indiquer que dans tous les cas, un code doit être exécuté, qu’une exception intervienne ou pas. Par exemple :
try
{
string saisie = Console.ReadLine();
int valeur = Convert.ToInt32(saisie);
Console.WriteLine("Vous avez saisi un entier");
}
catch (FormatException)
{
Console.WriteLine("Vous avez saisi autre chose qu'un entier");
}
finally
{
Console.WriteLine("Merci d'avoir saisi quelque chose");
}
Nous demandons une saisie utilisateur. Nous tentons de convertir cette saisie en entier. Si la conversion fonctionne, nous restons dans le bloc try et nous affichons :
Si la conversion lève une FormatException, nous affichons :
Dans les deux cas, nous passons obligatoirement dans le bloc finally pour afficher le remerciement.
Le bloc finally est utile par exemple quand il s’agit de libérer la mémoire, d’enregistrer des données, d’écrire dans un fichier de log, etc.
Il est important de remarquer que peu importe la construction, le bloc finally est toujours exécuté. Ainsi, même si on relève une exception dans le bloc catch :
try
{
Convert.ToInt32("ppp");
}
catch (FormatException)
{
throw new NotImplementedException();
}
finally
{
Console.WriteLine("Je suis quand même passé ici");
}
nous afficherons toujours notre message...
Ou même lorsque nous souhaitons sortir d'une méthode avec le mot-clé return :
static void Main(string[] args)
{
MaMethode();
}
private static void MaMethode()
{
try
{
Convert.ToInt32("ppp");
}
catch (FormatException)
{
return;
}
finally
{
Console.WriteLine("Je suis quand même passé ici");
}
}
Ici, le bloc finally est quand même exécuté.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est possible de déclencher soi-même la levée d’une exception. C’est utile si nous considérons que notre code a atteint un cas limite, qu’il soit fonctionnel ou technique. Pour lever une exception, nous utilisons le mot-clé throw, suivi d’une instance d’une exception. Imaginons par exemple une méthode permettant de calculer la racine carrée d’un double. Nous pouvons obtenir un cas limite lorsque nous tentons de passer un double négatif :
public static double RacineCarree(double valeur)
{
if (valeur <= 0)
throw new ArgumentOutOfRangeException("valeur", "Le paramètre doit être positif");
return Math.Sqrt(valeur);
}
Ici, nous instancions une ArgumentOutOfRangeException en utilisant un constructeur à deux paramètres. Ceux-ci permettent d’indiquer le nom du paramètre ainsi que le message d’erreur. Cette exception est une exception du framework .NET utilisée pour indiquer qu’un paramètre est en dehors des plages de valeurs autorisées. C’est exactement ce qu’il nous faut ici. Puis nous levons l’exception avec le mot-clé throw. Nous pouvons utiliser la méthode ainsi :
Il aurait été possible de lever une exception plus générique avec la classe de base Exception :
throw new Exception("Le paramètre doit être positif");
Mais n’oubliez pas que plus l’exception est finement typée, plus elle sera facile à traiter précisément. Cela permet d’éviter d’attraper toutes les exceptions dans le même catch avec la classe de base Exception. À noter que lorsque notre programme rencontre le mot-clé throw, il arrête l’exécution du programme pour partir dans le bloc try…catch correspond (s’il existe). Cela veut dire qu’une méthode qui doit renvoyer un paramètre pourra compiler si son chemin se termine par une levée d’exception, comme c’est le cas pour le calcul de la racine carrée.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Il est important de noter que lorsqu’un bout de code se situe dans un bloc try…catch, tout le code qui est dessous est surveillé, même s’il y a plusieurs méthodes qui s’appellent les unes les autres. Par exemple, si nous appelons depuis la méthode Main() une Methode1() qui appelle une Methode2() qui appelle une Methode3() qui lève une exception, alors nous serons capable de l’intercepter depuis la méthode Main() avec un try…catch :
static void Main(string[] args)
{
try
{
Methode1();
}
catch (NotImplementedException)
{
Console.WriteLine("On intercepte l'exception de la méthode 3");
}
}
public static void Methode1()
{
Methode2();
}
public static void Methode2()
{
Methode3();
}
public static void Methode3()
{
throw new NotImplementedException();
}
À noter qu’une NotImplementedException est une exception utilisée pour indiquer qu’un bout de code n’a pas encore été implémenté. Il est également possible d’attraper une exception, de la traiter et de choisir qu’elle continue à se propager. Par exemple, imaginons que nous avons un bloc try…catch qui nous permet de surveiller tout notre programme et que nous ayons à surveiller un bout de code ailleurs dans le programme qui peut produire une situation limite :
static void Main(string[] args)
{
try
{
MaMethode();
}
catch (Exception ex)
{
// ici, on intercepte toutes les erreurs possibles en indiquant qu'un problème inattendu s'est produit
Console.WriteLine("L'application a rencontré un problème, un mail a été envoyé à l'administrateur ...");
EnvoyerExceptionAdministrateur(ex);
}
}
public static void MaMethode()
{
try
{
Console.WriteLine("Veuillez saisir un entier :");
string chaine = Console.ReadLine();
int entier = Convert.ToInt32(chaine);
}
catch (FormatException)
{
Console.WriteLine("La saisie n'est pas un entier");
}
catch (Exception ex)
{
EnregistrerErreurDansUnFichierDeLog(ex);
throw;
}
}
J’ai une saisie à faire et à convertir en entier. Si la conversion échoue, je suis capable de l’indiquer à l’utilisateur en surveillant la FormatException. Par contre, si une exception inattendue se produit, je souhaite pouvoir faire quelque chose, en l’occurrence enregistrer l’exception dans un fichier, mais comme c’est un cas limite non prévu je souhaite que l’exception continue à se propager afin qu’elle soit attrapée par le bloc try…catch qui permettra d’envoyer un mail à l’administrateur. Dans ce cas, j’utilise un catch généraliste pour traiter les exceptions inattendues afin de loguer l’exception puis j’utilise directement le mot-clé throw afin de permettre de relever l’exception.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Grâce au typage fort des exceptions, il est pratique d’utiliser un type d’exception pour reconnaitre un cas limite, comme une erreur de conversion ou une exception de référence nulle. Nous allons pouvoir utiliser certaines de ces exceptions pour nos besoins, comme ce que nous avions fait avec l’exception ArgumentOutOfRangeException. Bien sûr, il est possible de créer nous-mêmes nos exceptions afin de lever nos propres exceptions correspondant à des cas limites fonctionnels ou techniques. Par exemple, imaginons un site d’e-commerce qui affiche une page correspondant au descriptif d’un produit afin de pouvoir le commander. Nous chargeons le produit. Si le produit n’est plus en stock alors il peut être judicieux de lever une exception afin que le site puisse gérer ce cas limite et afficher un message en conséquence. Créons donc notre exception personnalisée : ProduitNonEnStockException…
Pour ce faire, il suffit de créer une classe qui dérive de la classe de base Exception :
public class ProduitNonEnStockException : Exception
{
}
Qui pourra être utilisée ainsi :
static void Main(string[] args)
{
try
{
ChargerProduit("TV HD");
}
catch (ProduitNonEnStockException ex)
{
Console.WriteLine("Erreur : " + ex.Message);
}
}
public static Produit ChargerProduit(string nomProduit)
{
Produit produit = new Produit(); // à remplacer par le chargement du produit
if (produit.Stock <= 0)
throw new ProduitNonEnStockException();
return produit;
}
Il serait intéressant de pouvoir rendre l’exception plus explicite en modifiant par exemple la propriété message de l’exception. Pour ce faire, il suffit d’utiliser la surcharge du constructeur prenant une chaine de caractères en paramètre afin de pouvoir mettre à jour la propriété Message (qui est en lecture seule) :
public class ProduitNonEnStockException : Exception
{
public ProduitNonEnStockException() : base("Le produit n'est pas en stock")
{
}
}
Nous pouvons également créer un constructeur qui prend le nom du produit en paramètre afin de rendre le message encore plus précis :
public class ProduitNonEnStockException : Exception
{
public ProduitNonEnStockException(string nomProduit) : base("Le produit " + nomProduit + " n'est pas en stock")
{
}
}
Que nous pourrons utiliser ainsi :
public static Produit ChargerProduit(string nomProduit)
{
Produit produit = new Produit(); // à remplacer par le chargement du produit
if (produit.Stock <= 0)
throw new ProduitNonEnStockException(nomProduit);
return produit;
}
Ce qui donne :
À noter que pour construire cette exception personnalisée, nous avons dérivé de la classe de base Exception. Il aurait pu également être possible de dériver de la classe ApplicationException pour conserver une hiérarchie cohérente d’exceptions.
En résumé
Les exceptions permettent de gérer les cas limites d'une méthode.
On utilise le bloc try…catch pour encapsuler un bout de code à surveiller.
Il est possible de créer des exceptions personnalisées en dérivant de la classe de base Exception.
On peut lever à tout moment une exception grâce au mot-clé throw.
Les exceptions ne doivent pas servir à masquer les bugs.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Bienvenue dans le dernier TP de cette partie. Tenez bon, après on change de domaine pour aborder d'autres notions. Dans ce TP, nous allons pratiquer les événements. Le but est de savoir en créer un et de pouvoir s'y abonner pour être notifié d'une information.
Nous allons réaliser ici un mini simulateur de météo qui sera utilisé par un statisticien afin d’en faire des statistiques (logique :p ). Bon, c’est le contexte, mais c’est juste un exemple. N’espérez pas non plus réaliser un vrai simulateur météo dans ce TP. :)
Bref. Nous devons créer un simulateur de météo. Lorsque celui-ci est démarré, il génère autant de nombres aléatoires que demandé, des nombres entre 0 et 100. Si le nombre aléatoire est inférieur à 5, alors cela veut dire que le temps est au soleil. S’il est supérieur ou égal à 5 et inférieur à 50, alors nous aurons des nuages. S’il est supérieur ou égal à 50 et inférieur à 90, alors nous aurons de la pluie. Sinon, nous aurons de l’orage.
Un événement sera levé à chaque changement de temps. Le but de notre statisticien est de s’abonner aux événements du simulateur météo afin de compter le nombre de fois où il a fait soleil et le nombre de fois où le temps a changé. Il affichera ensuite son rapport en indiquant ces deux résultats et le pourcentage de fois où il a fait soleil. (Je veux bien que ce pourcentage soit un entier).
C’est tout pour l’énoncé. Maintenant, vous avez assez de connaissances pour que je ne détaille pas plus. Bon courage !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Allez, c’est parti pour la correction. Tout d’abord, nous devons créer notre simulateur météo. Il sera représenté par une classe :
public class SimulateurMeteo
{
}
Nous aurons également besoin de quelque chose pour représenter le temps, soleil, nuage, pluie et orage. Une énumération semble appropriée :
public enum Temps
{
Soleil,
Nuage,
Pluie,
Orage
}
Enfin, nous aurons notre statisticien :
public class Statisticien
{
}
Commençons par le simulateur de météo. Nous aurons besoin de plusieurs variables membres afin de stocker notre générateur de nombre aléatoires, le dernier temps qu’il a fait et le nombre de répétitions. Le nombre de répétitions pourra être un paramètre du constructeur :
public class SimulateurMeteo
{
private Temps? ancienTemps;
private int nombreDeRepetitions;
private Random random;
public SimulateurMeteo(int nombre)
{
random = new Random();
ancienTemps = null;
nombreDeRepetitions = nombre;
}
}
Étant donné que nous allons déterminer plusieurs nombres aléatoires, il est pertinent de ne pas ré-allouer à chaque fois le générateur de nombre aléatoire. C’est pour cela qu’on le crée une unique fois dans le constructeur de la classe. Créons désormais une méthode permettant de démarrer le simulateur et codons les règles métiers du simulateur :
public class SimulateurMeteo
{
//[…] Code supprimé pour plus de clarté […]
public void Demarrer()
{
for (int i = 0; i < nombreDeRepetitions; i++)
{
int valeur = random.Next(0, 100);
if (valeur < 5)
GererTemps(Temps.Soleil);
else
{
if (valeur < 50)
GererTemps(Temps.Nuage);
else
{
if (valeur < 90)
GererTemps(Temps.Pluie);
else
GererTemps(Temps.Orage);
}
}
}
}
}
C’est très simple, on boucle sur le nombre de répétitions. Un nombre aléatoire est déterminé à chaque itération. La méthode GererTemps prend en paramètre le temps déterminé à partir du nombre aléatoire. C’est cette méthode GererTemps qui aura pour but de lever un événement quand le temps change :
public class SimulateurMeteo
{
public delegate void IlFaitBeauDelegate(Temps temps);
public event IlFaitBeauDelegate QuandLeTempsChange;
// […] Code supprimé pour plus de clarté […]
private void GererTemps(Temps temps)
{
if (ancienTemps.HasValue && ancienTemps.Value != temps && QuandLeTempsChange != null)
QuandLeTempsChange(temps);
ancienTemps = temps;
}
}
Ici, j’ai choisi de créer un seul événement quand le temps change et de lui indiquer le temps qu’il fait en paramètres. Nous avons donc besoin d’un délégué qui prend un Temps en paramètres et qui ne renvoie rien. (C’est d’ailleurs souvent le cas des événements). Puis nous avons besoin d’un événement du type du délégué. Ensuite, si le temps a changé et que quelqu’un s’est abonné à l’événement, alors nous levons l’événement.
Il ne reste plus qu’à remplir notre classe Statisticien. Cette classe a besoin de travailler sur une instance de la classe SimulateurMeteo, nous pouvons donc lui en passer une dans les paramètres du constructeur. Nous utiliserons également des variables membres privées permettant de stocker ses analyses :
public class Statisticien
{
private SimulateurMeteo simulateurMeteo;
private int nombreDeFoisOuLeTempsAChange;
private int nombreDeFoisOuIlAFaitSoleil;
public Statisticien(SimulateurMeteo simulateur)
{
simulateurMeteo = simulateur;
nombreDeFoisOuLeTempsAChange = 0;
nombreDeFoisOuIlAFaitSoleil = 0;
}
public void DemarrerAnalyse()
{
simulateurMeteo.QuandLeTempsChange += simulateurMeteo_QuandLeTempsChange;
simulateurMeteo.Demarrer();
}
public void AfficherRapport()
{
Console.WriteLine("Nombre de fois où le temps a changé : " + nombreDeFoisOuLeTempsAChange);
Console.WriteLine("Nombre de fois où il a fait soleil : " + nombreDeFoisOuIlAFaitSoleil);
Console.WriteLine("Pourcentage de beau temps : " + nombreDeFoisOuIlAFaitSoleil * 100 / nombreDeFoisOuLeTempsAChange + " %");
}
private void simulateurMeteo_QuandLeTempsChange(Temps temps)
{
if (temps == Temps.Soleil)
nombreDeFoisOuIlAFaitSoleil++;
nombreDeFoisOuLeTempsAChange++;
}
}
Notons que dans la méthode DemarrerAnalyse, nous nous abonnons à l’événement de changement de temps. La méthode qui est appelée lors de la notification est très simple, elle incrémente les compteurs. Enfin, l’affichage du rapport est trivial. Ici, comme nous n’avons que des entiers, la division produira un entier également. Il ne reste plus qu’à faire fonctionner nos objets :
class Program
{
static void Main(string[] args)
{
SimulateurMeteo simulateurMeteo = new SimulateurMeteo(1000);
Statisticien statisticien = new Statisticien(simulateurMeteo);
statisticien.DemarrerAnalyse();
statisticien.AfficherRapport();
}
}
Ici, je travaille sur 1000 répétitions. Lorsque j’exécute l’application, j’obtiens :
Évidemment, vu que nous travaillons avec des nombres aléatoires, chacun aura un résultat différent.
Et voilà, c’est terminé pour ce TP. Notre application est fonctionnelle … Terminé ? mmmhhh … pas tout à fait, allons un peu plus loin.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les valeurs augmentent … alors qu’elles ne devraient pas. Eh oui, nous ne réinitialisons pas les entiers permettant de stocker les statistiques. Ce n’est pas forcément un bug ici, comme je n’avais rien dit dans l’énoncé, il peut paraitre pertinent de continuer à incrémenter ces valeurs, comme ça, je peux travailler sur une moyenne. Bon, disons que nous souhaitons les réinitialiser à chaque fois, il suffit de remettre à zéro les compteurs dans la méthode :
Cependant, les compteurs augmentent toujours, moins vite, mais quand même ! Je suis sûr que vous l’avez deviné et que vous n’avez-vous-même pas fait l’erreur. En fait, cela vient de l’abonnement à l’événement. Chaque fois que nous démarrons l’analyse, nous nous réabonnons à l’événement. Comme l’événement est multidiffusion, nous rajoutons en fait à chaque fois un appel à la méthode avec le +=. Ce qui veut dire qu’à la deuxième fois, nous appellerons la méthode deux fois, ce qui fera doubler les résultats. À la troisième fois, ils triplent … Nous avons donc une erreur. Soit il faut s’abonner une seule fois à l’événement, par exemple dans le constructeur, soit nous pouvons nous désabonner à la fin de l’analyse, quand ce n’est plus utile de recevoir l’événement. C’est cela que je souhaite montrer. Il suffit de faire :
On utilise l’opérateur -= pour enlever la méthode du délégué.
Cela permet d’éviter d’encombrer la mémoire qui ne saurait pas forcément se libérer toute seule. Je n’en dis pas plus car ceci est un concept avancé de gestion de mémoire. Gardez seulement à l’esprit que si on a l’opportunité de se désabonner d’un événement, il faut le faire.
Enfin, nous pouvons simplifier notre code en ne créant pas notre délégué. Effectivement, dans la mesure où celui-ci possède un seul paramètre, il est possible de le remplacer par le délégué Action<T>. Il faut juste supprimer la déclaration du délégué et remplacer la déclaration de l’événement par :
public class SimulateurMeteo
{
public event Action<Temps> QuandLeTempsChange;
}
Voilà pour ce TP sur les événements. Il nous a permis de nous entrainer un peu sur les événements et de continuer à nous entrainer sur la modélisation d’applications en utilisant la POO. Pas très compliqué en soit, mais on peut vite se rendre compte qu’une application peut fonctionner dans un cas, mais avoir un comportement inadapté dans un autre cas. D’une manière générale, il est important de retenir qu’il faut se désabonner d’un événement quand cela est possible.
Ouf, c’est enfin fini pour ce chapitre.
Comme vous avez pu le constater, la programmation orientée objet appliquée au C# est un vaste domaine. Et encore, je n’ai pas tout montré pour conserver une taille raisonnable. Nous avons pu voir pas mal de choses dont les concepts de la programmation orientée objet et comment les utiliser en C#. Nous avons également vu que les génériques étaient un élément important du C#. Puis nous avons terminé le chapitre en étudiant les événements et les exceptions qui sont des éléments incontournables pour réaliser une vraie application.
Il y a beaucoup de domaines que je n’ai pas traité, n’hésitez pas à être curieux et à aller farfouiller dans la documentation ou sur internet.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour l'instant, nous n'avons créé que des projets de type application console. Il existe plein d'autres modèles de projet. Un des plus utiles est le projet permettant de créer des bibliothèques de classes. Il s'agit d'un projet qui va permettre de contenir des classes que nous pourrons utiliser dans des applications. Exactement comme la bibliothèque de classes du framework .NET qui nous permet d'utiliser la classe Math ou les exceptions, ou plein d'autres choses… Ce type de projet permet donc de créer une assembly sous la forme d'un fichier avec l'extension .dll. Ces assemblys sont donc des bibliothèques qui seront utilisables par n'importe quelle application utilisant un langage compatible avec le framework .NET.
Globalement pour deux raisons que nous allons détailler :
Réutilisabilité
Architecture
Réutilisabilité
Comme indiqué en introduction, le projet de type bibliothèque de classes permet d’obtenir des assemblys avec l’extension .dll. Nous pouvons y mettre tout le code C# que nous voulons, notamment des classes qui auront un intérêt à être utilisées à plusieurs endroits ou partagées par plusieurs applications. C’est le cas des assemblys du framework .NET. Elles possèdent plein de code très utile que nous aurons avantage à utiliser pour créer nos applications.
De la même façon, nous allons pouvoir créer des classes qui pourront être réutilisées à plusieurs endroits. Comme notre classe permettant de gérer les listes chainées. N’importe quel programme qui utilise des listes chainées aura intérêt à ne pas tout réinventer et à simplement réutiliser ce code prêt à l’emploi. Il suffira pour ce faire de réutiliser cette classe en référençant l’assembly, comme nous l’avons déjà vu.
Architecture :
L’autre avantage dans la création de bibliothèques de classes est de pouvoir architecturer son application de manière à faciliter sa mise en place, sa maintenabilité et l’évolutivité du code. L’architecture informatique c’est comme l’architecture d’une maison. Si nous mettons la douche au même endroit que le compteur électrique ou que la machine à laver est juste à côté de la chambre à coucher, cela peut poser des problèmes. De même, que penser d’un architecte s’il place les toilettes à côté du lit. Une maison mal architecturée est une maison où il ne fait pas bon vivre. De même qu’une application mal architecturée est une application où il ne fait pas bon faire la maintenance applicative ! :)
Architecturer son application est important surtout si l’application est grosse. Par exemple, une bonne pratique dans une application informatique est la décomposition en couches. Nous n’allons pas faire ici un cours d’architecture, mais le but est de séparer les composantes de l’application. Un grand nombre d’applications de gestions est composée d’une couche de présentation, d’une couche métier et d’une couche d’accès aux données, les couches communiquant entre-elles. Le but est de limiter les modifications d’une couche lors de la modification d’une autre. Si toutes les couches étaient mélangées alors chaque modification impliquerait une série de modifications en chaine. On peut faire une analogie avec un plat de lasagnes et un plat de spaghetti. Il est difficile de toucher à un spaghetti sans toucher les autres. Cependant, il pourrait être envisageable de toucher à la couche du dessus du plat de lasagnes pour rajouter un peu de fromage sans perturber ce qu’il y a dessous. Miam.
Il est donc intéressant d’avoir une bibliothèque de classes qui gère l’accès aux données, une autre qui gère les règles métier et une autre qui s’occupe d’afficher le tout. Je m’arrête là sur l’architecture, vous aurez l’occasion de vous y confronter bien assez tôt :p .
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour créer une bibliothèque de classes, on utilise l’assistant de création de nouveau projet (Fichier > Nouveau > Nouveau projet), comme on l’a fait pour une application console sauf qu’ici, on utilisera le modèle « bibliothèque de classes ». Ne le faisons pas encore.
Si nous faisons cela, Visual C# Express va nous créer une nouvelle solution contenant le projet de bibliothèques de classes. C’est possible sauf qu’en général, on ajoute une bibliothèque de classes pour qu’elle serve dans le cadre d’une application. Cela veut dire que nous pouvons ajouter ce nouveau projet à notre solution actuelle. Ainsi, celle-ci contiendra deux projets :
L’application console, qui sera exécutable par le système d’exploitation
La bibliothèque de classes, qui sera utilisée par l’application.
Pour ce faire, on peut faire un clic droit sur notre solution et faire Ajouter > Nouveau Projet.
Ici, on choisit le projet de type bibliothèque de classes, sans oublier de lui donner un nom, par exemple « MaBibliotheque ».
Visual C# Express nous créé notre projet et l’ajoute à la solution, comme on peut le voir dans l’explorateur de solutions.
Il le génère avec un fichier Class1.cs que nous pouvons supprimer.
Nous pouvons voir que notre application console est en gras. Cela veut dire que c’est ce projet que Visual C# Express va tenter de démarrer lorsque nous utiliserons ctrl + F5. Si ce n’est pas le cas, il peut tenter de démarrer la bibliothèque, ce qui n’a pas de sens vu qu’elle n’a pas de méthode Main(). Dans ce cas, vous pourrez le changer en faisant un clic droit sur le projet console et en choisissant « Définir comme projet de démarrage ».
Dans ce projet, nous pourrons désormais créer nos classes en ajoutant des nouvelles classes au projet, comme on l’a déjà fait avec l’application console.
Ajoutons par exemple la classe suivante :
namespace MaBibliotheque
{
public class Bonjour
{
public void DireBonjour()
{
Console.WriteLine("Bonjour depuis la bibliothèque MaBibliotheque");
}
}
}
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Si nous ouvrons les propriétés de notre projet (bouton droit sur le projet, Propriétés) :
La fenêtre des propriétés s’affiche :
Nous pouvons voir différentes informations et notamment dans l’onglet Application que le projet possède un nom d’assembly, qui correspond ici au nom du projet ainsi qu’un espace de nom par défaut, qui correspond également au nom du projet. Le nom de l’assembly servira à identifier l’assembly, alors que l’espace de nom par défaut sera celui donné lorsque nous ajouterons une nouvelle classe (ou autre) à notre projet. Cet espace de nom pourra être changé, mais en général on garde un nom cohérent avec les arborescences de notre projet.
Notons au passage qu’il y a une option permettant d’indiquer la version du framework .NET que nous souhaitons utiliser. Ici, nous gardons la version 4.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous pouvons alors compiler cette bibliothèque de classes, soit individuellement, soit en compilant tout le projet.
Rendons nous dans le répertoire où nous avons sauvegardé notre bibliothèque, nous voyons dans le répertoire de sortie (chez moi : C:\Users\Nico-PC\Documents\Visual Studio 2010\Projects\C#\MaPremiereApplication\MaBibliotheque\bin\Release) qu’il y a un fichier du nom de notre projet dont l’extension est .dll. C’est notre bibliothèque de classes (même s’il n’y a qu’une classe dedans !). Elle possède le même nom que celui que nous avons vu dans les propriétés du projet.
J’en profite pour vous faire remarquer qu’à son côté, il y a également un fichier du même nom avec l’extension .pdb. Je peux enfin vous révéler de quoi il s’agit. Ce fichier contient les informations de débogages, utiles lorsque nous déboguons notre application. Sans ce fichier, impossible de déboguer à l’intérieur du code de notre classe.
Revenons à l’assembly générée. C’est cette dll qu’il faudra référencer dans notre projet, comme nous avons vu au chapitre sur le référencement d’assemblys. Si vous avez un doute, n’hésitez pas à retourner le consulter. Ainsi, nous serons en mesure d’utiliser la classe de notre bibliothèque. Rappelez-vous, pour référencer une assembly, nous faisons un clic droit sur les références du projet et sélectionnons « Ajouter une référence ». Nous pourrons référencer notre bibliothèque soit en utilisant l’onglet Parcourir, qui va nous permettre de pointer directement le fichier dll contenant nos classes :
soit en référençant directement le projet de bibliothèque de classes qui se trouve dans notre solution en utilisant l’onglet Projet :
C’est ce choix qui doit être privilégié lorsque notre solution contient les projets à référencer. Généralement, vos bibliothèques vont évoluer en même temps que votre programme, donc il est judicieux de les avoir dans la même solution que son application. Nous pourrons donc faire des références projet. Si cependant les bibliothèques sont stables et ne sont pas sujettes à évoluer, alors vous pourrez les référencer directement à partir des dll, vous y gagnerez en temps de compilation. Utilisons désormais notre classe avec le code suivant :
MaBibliotheque.Bonjour bonjour = new MaBibliotheque.Bonjour();
bonjour.DireBonjour();
Vous pouvez aussi bien sûr inclure l’espace de nom MaBibliotheque pour éviter d’avoir à préfixer notre classe. En général, l’espace de nom d’une bibliothèque est différent de celui de l’application. Notez que pour qu’une classe, comme la classe Bonjour, puisse être utilisée par une application référençant son assembly, elle doit être déclarée en public afin qu’elle soit visible par tout le monde.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons déjà vu ce mot-clé lorsque nous parlions de visibilité avec notamment les autres mots-clés public, private et protected. C’est avec les assemblys que le mot-clé internal prend tout son sens. Il permet d’indiquer qu’une classe, méthode ou propriété ne sera accessible qu’à l’intérieur d’une assembly. Cela permet par exemple qu’une classe soit utilisable par toutes les autres classes de cette assembly mais qu’elle ne puisse pas être utilisée par une application référençant l’assembly.
Par exemple créons dans notre bibliothèque de classes les trois classes suivantes :
public class Client
{
private string login;
public string Login
{
get { return login; }
}
private string motDePasse;
public string MotDePasse
{
get { return motDePasse.Crypte(); }
}
public Client(string loginClient, string motDePasseClient)
{
login = loginClient;
motDePasse = motDePasseClient;
}
}
public static class Generateur
{
public static string ObtenirIdentifiantUnique()
{
Random r = new Random();
string chaine = string.Empty;
for (int i = 0; i < 10; i++)
{
chaine += r.Next(0, 100);
}
return chaine.Crypte();
}
}
internal static class Encodage
{
internal static string Crypte(this string chaine)
{
return Convert.ToBase64String(Encoding.Default.GetBytes(chaine));
}
internal static string Decrypte(this string chaine)
{
return Encoding.Default.GetString(Convert.FromBase64String(chaine));
}
}
Les deux premières sont des classes publiques qui peuvent être utilisées depuis n’importe où, comme depuis notre programme principal :
class Program
{
static void Main(string[] args)
{
Client client = new Client("Nico", "12345");
Console.WriteLine(client.MotDePasse);
Console.WriteLine(Generateur.ObtenirIdentifiantUnique());
}
}
Par contre, la classe Encodage n’est accessible que pour les deux autres classes, car elles sont dans la même assembly. Cela veut dire que si nous tentons de l’utiliser depuis notre méthode Main() :
Nous aurons des erreurs de compilation. Cet exemple permet d’illustrer l’intérêt pas toujours évident du mot-clé internal.
À noter qu’il existe enfin le mot-clé protected internal qui permet d’indiquer que des éléments sont accessibles à un niveau internal pour les classes d’une même assembly mais protected pour les autres assemblys, ce qui permet d’appliquer les principes de substitutions ou d’héritage.
Voilà, vous avez vu comment créer une bibliothèque de classes. N’hésitez pas à créer ce genre de projet afin d’y mettre toutes les classes qui peuvent être utilisées par plusieurs applications. Comme ça, il suffit d’une simple référence pour accéder au code qui y est contenu. Vous vous en servirez également pour mieux architecturer vos applications, le code s’en trouvera plus clair et plus maintenable.
En résumé
Un projet de bibliothèque de classes permet de regrouper des classes pouvant être utilisées entre plusieurs applications.
Les bibliothèques de classes génèrent des assemblys avec l'extension .dll.
Elles permettent également de mieux architecturer un projet.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Maintenant que nous en savons plus, nous allons pouvoir aborder quelques notions qui me paraissent importantes et que nous n'avons pas encore traitées. Ce sera l’occasion d’approfondir nos connaissances et de comprendre un peu mieux certains points qui auraient pu vous paraître obscurs.
Nous allons voir des instructions C# supplémentaires qui vont nous permettre de compléter nos connaissances en POO. Nous en profiterons également pour détailler comment le framework .NET gère les types en mémoire. Vous en saurez plus sur le formatage des chaînes et aurez un aperçu du côté obscur du framework .NET, la réflexion !
Bref, tout plein de nouvelles cordes à nos arcs nous permettant d'être de plus en plus efficace avec le C#. Ces nouveaux concepts vous serviront sans doute moins souvent, mais sont importants à connaître.
Parmi ces nouveaux concepts, nous allons voir comment il est possible de faire en sorte qu'une classe ne puisse pas être héritée. Rappelez-vous, à un moment j’ai dit qu’on ne pouvait pas créer une classe qui spécialise la classe String...
C’est quoi ce mystère ? Nous, quand nous créons une classe, n’importe qui peut en hériter. Pourquoi pas la classe String ?
C’est parce que je vous avais caché le mot-clé sealed. Il permet d’empêcher la classe d’être héritée. Tout simplement.
Pourquoi vouloir empêcher d’étendre une classe en la dérivant ? Pour plusieurs raisons, mais généralement nous allons recourir à ce mot-clé lorsqu’une classe est trop spécifique à une méthode ou à une bibliothèque et que l’on souhaite empêcher quelqu’un de pouvoir obtenir du code instable en étendant son fonctionnement. C’est typiquement le cas pour la classe String. Il y a beaucoup de classes dans le framework .NET qui sont marquées comme sealed afin d’éviter que l’on puisse faire n’importe quoi.
Il faut par contre faire attention car l’emploi de ce mot-clé restreint énormément la façon dont on pourrait employer cette classe. Pour déclarer une classe sealed (scellée en français) il suffit de précéder le mot-clé class du mot-clé sealed :
public sealed class ClasseImpossibleADeriver
{
}
Ainsi, toute tentative d’héritage :
public class MaClasse : ClasseImpossibleADeriver
{
}
se soldera par une erreur de compilation déshonorante :
impossible de dériver du type sealed 'MaPremiereApplication.ClasseImpossibleADeriver'
À noter que le mot-clé sealed fonctionne également pour les méthodes, dans ce cas, cela permet d’empêcher la substitution d’une méthode. Reprenons notre exemple du chien muet :
public class Chien
{
public virtual void Aboyer()
{
Console.WriteLine("Wouf");
}
}
public class ChienMuet : Chien
{
public sealed override void Aboyer()
{
Console.WriteLine("...");
}
}
Ici, nous marquons la méthode comme sealed, ce qui fait qu’une classe qui dérive de ChienMuet ne sera pas capable de remplacer la méthode permettant d’aboyer. Le code suivant :
public class ChienAvecSyntheseVocale : ChienMuet
{
public override void Aboyer()
{
Console.WriteLine("Bwarf");
}
}
entrainera l’erreur de compilation :
'MaPremiereApplication.ChienAvecSyntheseVocale.Aboyer()' : ne peut pas se substituer à un membre hérité 'MaPremiereApplication.ChienMuet.Aboyer()', car il est sealed
Voilà pour ce mot-clé, à utiliser en connaissance de cause.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu beaucoup de types différents au cours des chapitres précédents. Nous avons vu les structures, les classes, les énumérations, les délégués, etc. Certains sont des types valeur et d’autres des types référence. Et ils sont tous des objets.
Voici un petit schéma récapitulatif des types que nous avons déjà vus :
Nous avons dit brièvement qu’ils étaient gérés différemment par le framework .NET et que les variables de type valeur contenaient directement la valeur, alors que les variables de type référence possèdent un lien vers un objet en mémoire. Ce qu’il se passe en fait quand nous déclarons une variable de type valeur, c’est qu’il crée directement la valeur en mémoire dans ce qu’on appelle « la pile ». C’est une zone mémoire (limitée) où il est très rapide de mettre et de chercher des valeurs. De plus, cette mémoire n’a pas besoin d’être libérée par le ramasse-miettes (que nous verrons un peu plus bas). C’est pour cela que pour des raisons de performances on peut être amené à choisir les types valeur. Par exemple lorsque nous faisons :
int age = 10;
double pourcentage = 5.5;
il se passe ceci en mémoire :
La variable age est une adresse mémoire contenant la valeur 10. C’est la même chose pour la variable pourcentage sauf que l’emplacement mémoire est plus important car on peut stocker plus de choses dans un double que dans un int. En ce qui concerne les types valeur, lorsque nous instancions par exemple une classe, le C# instancie la variable maVoiture dans la pile et lui met dedans une référence vers le vrai objet qui lui est alloué sur une zone mémoire de capacité plus importante, mais à accès plus lent, que l’on appelle « le tas ». Comme il est géré par le framework .NET, on l’appelle « le tas managé ».
Si nous avons le code suivant :
public class Voiture
{
public int Vitesse { get; set; }
public string Marque { get; set; }
}
Voiture maVoiture = new Voiture { Vitesse = 10, Marque = "Peugeot" };
Nous aurons en mémoire :
À noter que lorsqu’une variable sort de sa portée et qu’elle n’est plus utilisable par qui que ce soit, alors la case mémoire sur la pile est marquée comme de nouveau libre. Voilà grosso modo comment est gérée la mémoire.
Il manque encore un élément fondamental du mécanisme de gestion mémoire : le ramasse-miettes. Nous en avons déjà parlé brièvement, le ramasse miette sert à libérer la mémoire qui n’est plus utilisée dans le tas managé. Il y aurait de quoi écrire un gros tutoriel rien que sur son fonctionnement, aussi nous allons expliquer rapidement comment il fonctionne sans trop rentrer dans les détails.
Pourquoi libérer la mémoire ? On a vu que quand une variable sort de portée, alors la case mémoire sur la pile est marquée comme à nouveau libre. C’est très bien avec les types valeur qui sont uniquement sur la pile. Mais avec les types référence ? Que donne le code suivant lorsque nous quittons la méthode CreerVoiture ?
public class Voiture
{
public int Vitesse { get; set; }
public string Marque { get; set; }
}
static void Main(string[] args)
{
CreerVoiture();
}
public static void CreerVoiture()
{
Voiture maVoiture = new Voiture { Vitesse = 10, Marque = "Peugeot" };
}
Nous avons dit que la mémoire sur la pile redevenait libre. La référence vers l’objet est donc cassée. Cependant, la mémoire sur le tas est toujours occupée.
Cela veut dire que notre objet est toujours en mémoire sauf que la variable maVoiture n’existe plus et donc, ne référence plus cet objet. Dans un langage comme le C++, nous aurions été obligés de vider explicitement la mémoire référencée par la variable. En C#, pas besoin ! C’est le ramasse-miettes qui le fait pour nous. Encore un truc de fainéant ça. ^^
En fait, c’est plutôt une sécurité qu’un truc de fainéant. C’est la garantie que la mémoire utilisée par les objets qui n’existent plus est vidée et, du coup, redevient disponible pour de nouveaux objets. Grâce au ramasse-miettes, nous évitons ce que l’on appelle les fuites mémoires.
Super génial ça. Mais, il passe quand ce ramasse-miettes ?
La réponse est simple : « on ne sait pas quand il passe ». En fait, il passe quand il a besoin de mémoire ou quand l’application semble ne rien faire. Évidemment, lorsque le ramasse-miettes passe, les performances de l’application sont un petit peu pénalisées. C’est pour cela que l’algorithme de passage du ramasse-miettes est optimisé pour essayer de déranger le moins possible l’application, lors des moments d’inactivité par exemple. Par contre, quand il y a besoin de mémoire, il ne se pose pas la question : il passe quand même.
Il y aurait beaucoup de choses à dire encore sur ce mécanisme mais arrêtons-nous là. Retenons que le ramasse-miettes est un superbe outil qui nous permet de garantir l’intégrité de notre mémoire et qu’il s’efforce au mieux de nous embêter le moins possible. Il est important de libérer les ressources dont on n'a plus besoin quand c’est possible, par exemple en se désabonnant d’un événement ou lorsque nous avons utilisé des ressources natives (ce que nous ne verrons pas dans ce tutoriel) ou lors d’accès à des fichiers ou des bases de données.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans la partie précédente sur la substitution, nous avons vu qu'on pouvait substituer une méthode grâce au mot-clé override. Cette méthode devait d'ailleurs s'être déclarée comme candidate à cette substitution grâce au mot-clé virtual. Rappelez-vous de ce code :
public class Chien
{
public virtual void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class Caniche : Chien
{
public override void Aboyer()
{
Console.WriteLine("Wiiff");
}
}
Si nous instancions des chiens et des caniches de cette façon :
static void Main(string[] args)
{
Chien chien = new Chien();
Caniche caniche = new Caniche();
Chien canicheTraiteCommeUnChien = new Caniche();
chien.Aboyer();
caniche.Aboyer();
canicheTraiteCommeUnChien.Aboyer();
}
Nous aurons :
Wouaf !
Wiiff
Wiiff
En effet, le premier objet est un chien et les deux suivants sont des caniches. Grâce à la substitution, nous faisons aboyer notre chien, notre caniche et notre caniche qui se fait manipuler comme un chien.
Il est possible de masquer des méthodes qui ne sont pas forcément marquées comme virtuelles grâce au mot-clé new. À ce moment-là, la méthode ne se substitue pas à la méthode dérivée mais la masque pour les types dérivés. Voyons cet exemple :
public class Chien
{
public void Aboyer()
{
Console.WriteLine("Wouaf !");
}
}
public class Caniche : Chien
{
public new void Aboyer()
{
Console.WriteLine("Wiiff");
}
}
Remarquons que la méthode Aboyer() de la classe Chien n’est pas marquée virtual et que la méthode Aboyer de la classe Caniche est marquée avec le mot-clé new. Il ne s’agit pas ici de substitution. Il s’agit juste de deux méthodes qui portent le même nom, mais la méthode Aboyer() de la classe Caniche se charge de masquer la méthode Aboyer() de la classe mère. Ce qui fait que les précédentes instanciations :
static void Main(string[] args)
{
Chien chien = new Chien();
Caniche caniche = new Caniche();
Chien canicheTraiteCommeUnChien = new Caniche();
chien.Aboyer();
caniche.Aboyer();
canicheTraiteCommeUnChien.Aboyer();
}
produiront cette fois-ci :
Wouaf !
Wiiff
Wouaf !
C’est le dernier cas qui peut surprendre. Rappelez-vous, il ne s’agit pas d’un remplacement de méthode cette fois-ci, et donc le fait de manipuler le caniche en tant que Chien ne permet pas de remplacer le comportement de la méthode Aboyer(). Dans ce cas, on appelle bien la méthode Aboyer correspondant au type Chien, ce qui a pour effet d’afficher « Wouaf ! ». Si nous n’avions pas utilisé le mot-clé new, nous aurions eu le même comportement mais le compilateur nous aurait avertis de ceci grâce à un avertissement :
'MaPremiereApplication.Caniche.Aboyer()' masque le membre hérité 'MaPremiereApplication.Chien.Aboyer()'. Utilisez le mot clé new si le masquage est intentionnel.</citation>
Il nous précise que nous masquons effectivement la méthode de la classe mère et que si c’est fait exprès, alors il faut l’indiquer grâce au mot-clé new afin de lui montrer que nous savons ce que nous faisons. Notez quand même que dans la majorité des cas, en POO, ce que vous voudrez faire c’est bien substituer la méthode et non la masquer.
C’est le même principe pour les variables, il est également possible de masquer une variable, quoiqu’en général, cela reflète plutôt une erreur dans le code. Si nous faisons :
public class Chien
{
protected int age;
}
public class Caniche : Chien
{
private int age;
public Caniche()
{
age = 0;
}
public override string ToString()
{
return "J'ai " + age + " ans";
}
}
Alors le compilateur nous indique que la variable age de la classe Caniche masque celle dont nous avons hérité de la classe Chien. Si c’est intentionnel, il nous propose de la marquer avec le mot-clé new. Sinon, cela nous permet de constater que cette variable est peut-être inutile… (sûrement d’ailleurs !)
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Nous avons vu dans le TP sur les génériques comment créer un énumérateur. C’est une tâche un peu lourde qui nécessite pas mal de code. Omettons un instant que la classe String soit énumérable et créons pour l’exemple une classe qui permette d’énumérer une chaine de caractères. Nous aurions pu faire quelque chose comme ça :
public class ChaineEnumerable : IEnumerable<char>
{
private string chaine;
public ChaineEnumerable(string valeur)
{
chaine = valeur;
}
public IEnumerator<char> GetEnumerator()
{
return new ChaineEnumerateur(chaine);
}
IEnumerator IEnumerable.GetEnumerator()
{
return new ChaineEnumerateur(chaine);
}
}
public class ChaineEnumerateur : IEnumerator<char>
{
private string chaine;
private int indice;
public ChaineEnumerateur(string valeur)
{
indice = -1;
chaine = valeur;
}
public char Current
{
get { return chaine[indice]; }
}
public void Dispose()
{
}
object IEnumerator.Current
{
get { return Current; }
}
public bool MoveNext()
{
indice++;
return indice < chaine.Length;
}
public void Reset()
{
indice = -1;
}
}
Nous avons une classe ChaineEnumerable qui encapsule une chaine de caractères de type string. Et une classe ChaineEnumerateur qui permet de parcourir une chaine et de renvoyer à chaque itération un caractère, représenté par le type char (qui est un alias de la structure System.Char).
Rien de bien sorcier, mais un code plutôt lourd.
Regardons à présent le code suivant :
public class ChaineEnumerable : IEnumerable<char>
{
private string chaine;
public ChaineEnumerable(string valeur)
{
chaine = valeur;
}
public IEnumerator<char> GetEnumerator()
{
for (int i = 0; i < chaine.Length; i++)
{
yield return chaine[i];
}
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
Il fait la même chose, mais d’une manière bien simplifiée. Nous remarquons l’apparition du mot-clé yield. Il permet de créer facilement des énumérateurs. Il permet, combiné au mot-clé return, de renvoyer un élément d’une collection et de passer à l’élément suivant. Il peut être combiné au mot-clé break également pour permettre d’arrêter l’énumération. Ce qui veut dire que nous aurions pu écrire la méthode GetEnumerator() également de cette façon :
public IEnumerator<char> GetEnumerator()
{
int i = 0;
while (true)
{
if (i == chaine.Length)
yield break;
yield return chaine[i];
i++;
}
}
Ce qui est plus laid, je le conçois :p , mais qui permet d’illustrer le mot-clé yield break.
Le mot-clé yield permet également de renvoyer un IEnumerable (ou sa version générique), ainsi un peu bêtement, on pourrait faire :
Cet exemple va surtout me permettre d’illustrer ce qu’il se passe exactement grâce au mode debug. Mettez un point d’arrêt au début du programme et lancez-le en mode debug :
Appuyez sur F11 plusieurs fois pour rentrer dans la méthode ObtenirListeDePrenoms, nous voyons l’indicateur se déplacer sur les différentes parties de l’instruction foreach. Puis nous arrivons sur la première instruction yield return :
Appuyons à nouveau sur F11 et nous pouvons constater que nous sortons de la méthode et que nous rentrons à nouveau dans le corps de la boucle foreach qui va nous afficher le premier prénom. Continuons les F11 jusqu’à repasser sur le mot-clé in et rentrer à nouveau dans la méthode ObtenirListeDePrenoms() et nous pouvons constater que nous retournons directement au deuxième mot-clé yield :
Et ainsi de suite jusqu’à ce qu’il n’y ait plus rien dans la méthode ObtenirListeDePrenoms() et que du coup le foreach se termine. À la première lecture, ce n’est pas vraiment ce comportement que nous aurions attendu…
Voilà pour le principe du yield return. À noter qu’un yield break nous aurait fait sortir directement de la boucle foreach.
Le mot-clé yield participe à ce qu’on appelle l’exécution différée. On évalue la méthode ObtenirListeDePrenoms() qu’au moment où on parcoure le résultat avec la boucle foreach, ce qui pourrait paraître surprenant. Par exemple, si nous faisons :
public static IEnumerable<string> ObtenirListeDePrenoms()
{
yield return "Nicolas";
yield return "Jérémie";
yield return "Delphine";
}
static void Main(string[] args)
{
IEnumerable<string> prenoms = ObtenirListeDePrenoms();
Console.WriteLine("On fait des choses ...");
foreach (string prenom in prenoms)
{
Console.WriteLine(prenom);
}
}
Et que nous mettons un point d’arrêt sur le Console.WriteLine et un autre point d’arrêt dans la méthode ObtenirListeDePrenoms(), alors étrangement, on va s’arrêter dans un premier temps sur le point d’arrêt positionné sur la ligne où il y a le Console.WriteLine et ensuite nous passerons dans le point d’arrêt positionné dans la méthode ObtenirListeDePrenoms(). En effet, on ne passera dans la méthode que lorsque nous itérerons explicitement sur les prénoms grâce au foreach. Nous reviendrons sur cette exécution différée un peu plus loin. C’est le mot-clé yield qui fait ça.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour l’instant, lorsque nous avons eu besoin de mettre en forme des chaines de caractères, nous avons utilisé la méthode Console.WriteLine avec en paramètres des chaines concaténées entre elles grâce à l’opérateur +. Par exemple :
int age = 30;
Console.WriteLine("J'ai " + age + " ans");
Il est important de savoir qu’il est possible de formater la chaine un peu plus simplement et surtout beaucoup plus efficacement. Ceci est possible grâce à la méthode string.Format. Le code précédent peut par exemple être remplacé par :
int age = 30;
string chaine = string.Format("J'ai {0} ans", age);
Console.WriteLine(chaine);
La méthode string.Format accepte en premier paramètre un format de chaine. Ici, nous lui indiquons une chaine de caractères avec au milieu un caractère spécial : {0}. Il permet de dire : « remplace-moi le {0} avec le premier paramètre qui va suivre », en l’occurrence ici la variable age. Si nous avons plusieurs valeurs, il est possible d’utiliser les caractères spéciaux {1}, puis {2}, etc … chaque nombre représentant l’indice correspondant au paramètre. Par exemple :
double valeur1 = 10.5;
double valeur2 = 4.2;
string chaine = string.Format("{0} multiplié par {1} s'écrit \"{0} * {1}\" et donne comme résultat : {2}", valeur1, valeur2, valeur1 * valeur2);
Console.WriteLine(chaine);
Ce qui donne :
10,5 multiplié par 4,2 s'écrit "10,5 * 4,2" et donne comme résultat : 44,1
Vous avez pu remarquer qu’il est possible d’utiliser le même paramètre à plusieurs endroits. La méthode Console.WriteLine dispose aussi de la capacité de formater des chaines de caractères. Ce qui veut dire que le code précédent peut s’écrire :
double valeur1 = 10.5;
double valeur2 = 4.2;
Console.WriteLine("{0} multiplié par {1} s'écrit \"{0} * {1}\" et donne comme résultat : {2}", valeur1, valeur2, valeur1 * valeur2);
Ce qui revient absolument au même.
Parlons culture désormais. N’ayez pas peur, rien à voir avec des questions pour des champions, la culture en informatique correspond à tout ce qui a trait aux différences entre les langues et les paramètres locaux. Par exemple, en France nous n'écrivons pas les dates de la même façon qu’aux États-Unis. En France, nous écririons le jour de Noël 2011 de cette façon :
Citation : En France
Le 25/12/2011
Alors qu’aux États-Unis, ils l’écriraient :
Citation : Aux États-Unis
The 12/25/2011
En inversant donc le mois et le jour. De la même façon, il existe des différences lorsque nous écrivons les nombres à virgule. En France, nous écririons :
Citation : En France
123,45
Alors qu’aux États-Unis, ils l’écriraient :
Citation : Aux États-Unis
123.45
Un point à la place d’une virgule, subtile différence. On a donc souvent des différences entre les langues. Et même plus, on peut avoir des différences entre les langues en fonction de l’endroit où elles sont parlées. Citons par exemple le français de France et le français du Canada. Il existe donc au sein du système d’exploitation tout une liste de « régions » représentées par un couple de lettres. Par exemple, le français est représenté par les lettres fr. Et même plus précisément, le français de France est représenté par fr-FR alors que celui du Canada est représenté par fr-CA. C’est ce que l’on retrouve dans les paramètres de notre système d’exploitation lorsqu’on va (sous Windows 7) dans le panneau de configuration, « Horloge langue et région » :
Puis « Modifier le format de la date, de l’heure ou des nombres ».
Nous pouvons adapter le format à celui que nous préférons :
Bref, ce choix, nous le retrouvons dans notre application si nous récupérons la culture courante :
Ce qui est intéressant, c’est que le formatage des chiffres ou des dates change en fonction de la culture. Ainsi, si nous utilisons le français de France, pour le code suivant :
public static void Main(string[] args)
{
Affiche();
}
public static void Affiche()
{
Console.WriteLine(System.Threading.Thread.CurrentThread.CurrentCulture);
decimal dec = 5.5M;
double dou = 4.8;
DateTime date = new DateTime(2011, 12, 25);
Console.WriteLine("Décimal : {0}", dec);
Console.WriteLine("Double : {0}", dou);
Console.WriteLine("Date : {0}", date);
}
Il est possible de changer la culture courante de notre application, si par exemple nous souhaitons qu’elle soit multiculture, en utilisant le code suivant :
System.Threading.Thread.CurrentThread.CurrentCulture = new CultureInfo("en-US");
Ici par exemple, j’indique à mon application que je souhaite travailler avec la culture des États-Unis. Ainsi, le code précédent, en changeant juste la culture :
public static void Main(string[] args)
{
System.Threading.Thread.CurrentThread.CurrentCulture = new CultureInfo("en-US");
Affiche();
}
public static void Affiche()
{
Console.WriteLine(System.Threading.Thread.CurrentThread.CurrentCulture);
decimal dec = 5.5M;
double dou = 4.8;
DateTime date = new DateTime(2011, 12, 25);
Console.WriteLine("Décimal : {0}", dec);
Console.WriteLine("Double : {0}", dou);
Console.WriteLine("Date : {0}", date);
}
produira un résultat légèrement différent :
en-US
Décimal : 5.5
Double : 4.8
Date : 12/25/2011 12:00:00 AM
Il s’agit exactement de la même information, mais formatée différemment.
À noter qu’il existe encore une autre information de culture, à savoir la langue du système d’exploitation que l’on retrouve dans la culture de l’interface graphique, dans la propriété :
Il s’agit ici de la CurrentUICulture, à ne pas confondre avec la CurrentCulture. Correspondant à la langue du système d’exploitation, nous nous en servirons plus volontiers pour rendre une application multi-langue.
Pour finir sur le formatage des chaines, il est possible d’utiliser des caractères spéciaux enrichis pour changer le formatage des types numériques ou de la date. Par exemple, il est possible d’afficher la date sous une forme différente avec :
DateTime date = new DateTime(2011, 12, 25);
Console.WriteLine("La date est {0}", date.ToString("dd-MM-yyyy"));
Ici, dd sert à afficher le jour, MM le mois et yyyy l’année sur quatre chiffre, ce qui donne :
La date est 25-12-2011
Il y a beaucoup d’options différentes que vous pouvez retrouver dans la documentation.
Cela fonctionne dans le même genre pour les numériques, qui nous permettent par exemple d’afficher le nombre de différentes façons. Ici par exemple, j’utilise la notation scientifique :
Pour les nombres, il existe différents formatages que l’on peut retrouver dans le tableau ci-dessous :
Format
Description
Remarque
{0:c}
Monnaie
Attention, la console affiche mal le caractère €
{0:d}
Décimal
Ne fonctionne qu’avec les types sans virgules
{0:e}
Notation scientifique
{0:f}
Virgule flottante
{0:g}
Général
Valeur par défaut
{0:n}
Nombre avec formatage pour les milliers
{0:r}
Aller-retour
Permet de garantir que la valeur numérique convertie en chaine pourra être convertie à nouveau en valeur numérique identique
{0:x}
Héxadécimal
Ne fonctionne qu’avec les types sans virgules
À noter que l’on peut également avoir du formatage grâce à la méthode ToString(). Il suffit de passer le format en paramètres, comme ici où cela me permet d’afficher uniquement le nombre de chiffres après la virgule qui m’intéressent ou des chiffres significatifs :
double valeur = 10.0 / 3;
Console.WriteLine("Avec 3 chiffres significatifs et 3 chiffres après la virgule : {0}", valeur.ToString("000.###"));
Qui donne :
Avec 3 chiffres significatifs et 3 chiffres après la virgule : 003,333
Mettre le format dans la méthode ToString() fonctionne aussi pour la date :
DateTime date = new DateTime(2011, 12, 25);
Console.WriteLine(date.ToString("MMMM"));
Ici, je n’affiche que le nom du mois :
décembre
Voilà pour le formatage des chaines de caractères. Lister tous les formatages possibles serait une tâche bien ennuyeuse. Vous aurez l’occasion de rencontrer d’autres formatages qui permettent de faire un peu tout et n’importe quoi. Vous pourrez retrouver la plupart des formatages à partir de ce lien.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans la liste des choses qui vont vous servir, on peut rajouter les attributs. Ils sont utilisés pour fournir des informations complémentaires sur une méthode, une classe, variables, etc. Ils vont nous servir régulièrement dans le framework .NET et nous aurons même la possibilité de créer nos propres attributs.
Un attribut est déclaré entre crochets avec le nom de sa classe. Il peut se mettre au-dessus d’une classe, d’une méthode, d’une propriété, etc. Par exemple, dans le code ci-dessous, je positionne l’attribut Obsolete au-dessus de la déclaration d’une méthode :
[Obsolete("Utilisez plutôt la méthode ToString() pour avoir une représentation de l'objet")]
public void Affiche()
{
// ...
}
Ici, j’utilise un attribut existant du framework .NET, l’attribut Obsolete qui permet d’indiquer qu’une méthode est obsolète et qu’il ne vaudrait mieux pas l’utiliser. En général, il est possible de fournir une information permettant de dire pourquoi la méthode est obsolète et par quoi il faut la remplacer. Ainsi, si nous tentons d’utiliser cette méthode :
public class Program
{
static void Main(string[] args)
{
new Program().Affiche();
}
[Obsolete("Utilisez plutôt la méthode ToString() pour avoir une représentation de l'objet")]
public void Affiche()
{
// ...
}
}
Le compilateur nous affichera l’avertissement suivant :
'MaPremiereApplication.Program.Affiche()' est obsolète : 'Utilisez plutôt la méthode ToString() pour avoir une représentation de l'objet'
Cet attribut est un exemple, il en existe beaucoup dans le framework .NET et vous aurez l’occasion d’en voir d’autres dans les chapitres suivants. Remarquons que la classe s’appelle ObsoleteAttribute et peut s’utiliser soit suffixée par Attribute, soit sans, et dans ce cas, ce suffixe est ajouté automatiquement.
Grâce à l’héritage, nous allons nous aussi pouvoir définir nos propres attributs. Il suffit pour cela de dériver de la classe de base Attribute. Par exemple, dans sa forme la plus simple :
public class DescriptionClasseAttribute : Attribute
{
}
Nous pourrons alors utiliser notre attribut sur une classe :
[DescriptionClasse]
public class Chien
{
}
Super, même si ça ne nous sert encore à rien :p .
Problème, j’ai appelé mon attribut DescriptionClasse et je peux quand même l’utiliser sur une méthode :
[DescriptionClasse]
public class Chien
{
[DescriptionClasse]
public void Aboyer()
{
}
}
Heureusement, il est possible d’indiquer des restrictions sur les attributs en indiquant par exemple qu’il n’est valable que pour les classes. Cela se fait avec … un attribut :D :
[AttributeUsage(AttributeTargets.Class, AllowMultiple = true)]
public class DescriptionClasseAttribute : Attribute
{
}
Ici par exemple, j’indique que mon attribut n’est valable que sur les classes et qu’il est possible de le mettre plusieurs fois sur la classe. Le code précédent où l’attribut est positionné sur une méthode ne compilera donc plus, avec l’erreur de compilation suivante :
L'attribut 'DescriptionClasse' n'est pas valide dans ce type de déclaration. Il n'est valide que dans les déclarations 'class'.
Ce qui nous convient parfaitement. :)
Il est intéressant de pouvoir fournir des informations complémentaires à notre attribut. Pour cela, on peut rajouter des propriétés, ou avoir une surcharge complémentaire du constructeur, comme on l’a fait pour le message de l’attribut Obsolete :
[AttributeUsage(AttributeTargets.Class, AllowMultiple = true)]
public class DescriptionClasseAttribute : Attribute
{
public string Description { get; set; }
public DescriptionClasseAttribute()
{
}
public DescriptionClasseAttribute(string description)
{
Description = description;
}
}
Ce qui nous permettra d’utiliser notre attribut de ces deux façons :
[DescriptionClasse(Description = "Cette classe correspond à un chien")]
[DescriptionClasse("Elle dérive de la classe Animal")]
public class Chien : Animal
{
}
C’est très bien ces attributs, mais nous ne sommes pas encore capables de les exploiter. Voyons comment le faire.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
La réflexion en C# ne donne pas mal à la tête, quoique … C’est une façon de faire de l’introspection sur nos types de manière à obtenir des informations sur eux, c'est-à-dire sur les méthodes, les propriétés, etc. La réflexion permet également de charger dynamiquement des types et de faire de l’introspection sur les assemblys. C’est un mécanisme assez complexe et plutôt couteux en termes de temps. Le point de départ est la classe Type qui permet de décrire n’importe quel type. Le type d’une classe peut être obtenu grâce au mot-clé typeof :
Type type = typeof(string);
Cet objet Type nous permet d’obtenir plein d’informations sur nos classes au moment de l’exécution. Par exemple si le type est une classe, c’est-à-dire ni un type valeur, ni une interface, alors le code suivant :
Type type = typeof(string);
Console.WriteLine(type.IsClass);
nous renverra true. En effet, la propriété IsClass permet d’indiquer si le type est une classe. Nous pouvons aussi obtenir le nom de méthodes grâce à la méthode GetMethods() :
Type type = typeof(string);
foreach (MethodInfo infos in type.GetMethods())
{
Console.WriteLine(infos.Name);
}
Qui nous donne :
Pas très exploitable comme résultat, mais bon c’est pour l’exemple. :) Il y a encore pleins d’infos dans cet objet Type, qui permettent d’obtenir ce que nous voulons. Cela est possible grâce aux métadonnées qui sont des informations de descriptions des types.
Vous me voyez venir… eh oui, nous allons pouvoir obtenir nos attributs ! Pour connaitre la liste des attributs d’un type, on peut utiliser la méthode statique Attribute.GetCustomAttributes(), en lui passant en paramètre le System.Type qui est hérité de la classe abstraite MemberInfo. Si l’on souhaite récupérer un attribut particulier, on peut le passer en paramètre de la méthode :
Ceci va nous permettre de récupérer les attributs de notre classe et en l’occurrence, d’obtenir leurs description. C’est ce que permet le code suivant :
public class Program
{
static void Main(string[] args)
{
new DemoAttributs().Demo();
}
}
public class DemoAttributs
{
public void Demo()
{
Animal animal = new Animal();
Chien chien = new Chien();
VoirDescription(animal);
VoirDescription(chien);
}
public void VoirDescription<T>(T obj)
{
Type type = typeof(T);
if (!type.IsClass)
return;
Attribute[] lesAttributs = Attribute.GetCustomAttributes(type, typeof(DescriptionClasseAttribute));
if (lesAttributs.Length == 0)
Console.WriteLine("Pas de description pour la classe " + type.Name + "\n");
else
{
Console.WriteLine("Description pour la classe " + type.Name);
foreach (DescriptionClasseAttribute attribut in lesAttributs)
{
Console.WriteLine("\t" + attribut.Description);
}
}
}
}
Nous commençons par instancier un objet animal et un objet chien. Puis nous demandons leurs descriptions. La méthode générique VoirDescription() s’occupe dans un premier temps d’obtenir le type de la classe grâce à typeof. On s’octroie une vérification permettant de nous assurer que le type est bien une classe. Ceci permet d’éviter d’aller plus loin car de toute façon, notre attribut ne s’applique qu’aux classes. Puis nous utilisons la méthode GetCustomAttributes pour obtenir les attributs de type DescriptionClasseAttribute. Et s’il y en a, alors on les affiche.
Ce qui donne :
Pas de description pour la classe Animal
Description pour la classe Chien
Elle dérive de la classe Animal
Cette classe correspond à un chien
Voilà pour les attributs, vous aurez l’occasion de rencontrer des attributs du framework .NET un peu plus loin dans ce tutoriel, mais globalement, il est assez rare d’avoir à créer soi-même ses attributs.
En ce qui concerne la réflexion, il faut bien comprendre que le sujet est beaucoup plus vaste que ça. Nous avons cependant vu ici un aperçu de ce que permet de faire la réflexion, en illustrant le mécanisme d’introspection sur les attributs.
En résumé
Il est possible d'empêcher une classe d'être dérivée grâce au mot-clé sealed.
Le garbage collector est le mécanisme permettant de libérer la mémoire allouée sur le tas managé qui n'est plus référencée dans une application.
Le mot-clé yield permet de créer des énumérateurs facilement et participe au mécanisme d'exécution différée.
Le framework .NET gère les différents formats des chaînes grâce à la culture de l'application.
La réflexion est un mécanisme d'introspection sur les types permettant d'obtenir des informations sur ces derniers lors de l'exécution.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans le cycle de vie d'une application, il est fréquent que de petites choses changent. Imaginons que mon application doive se connecter à un serveur FTP pour sauvegarder les données sur lesquelles j'ai travaillé. Pendant mes tests, effecutés en local, mon serveur FTP pourrait avoir l'adresse ftp://localhost avec un login et un mot de passe test. Évidemment, lors de l'utilisation réelle de mon application, l'adresse changera, et le login et le mot de passe varieront en fonction de l'utilisateur. Il faut être capable de changer facilement ces paramètres sans avoir à modifier le code ni à recompiler l'application.
C'est là qu'interviennent les fichiers de configuration : ils permettent de stocker toutes ces petites choses qui servent à faire varier notre application. Pour les clients lourds, comme nos applications console, il s’agit du fichier app.config : un fichier XML qui contient la configuration de notre application. Il stocke des chaînes de connexion à une base de données, une url de service web, des préférences utilisateurs, etc. Bref, tout ce qui va permettre de configurer notre application !
Vous ne connaissez pas les fichiers XML ? Si vous voulez en savoir plus, n’hésitez pas à faire un petit tour sur internet, c’est un format très utilisé dans l’informatique. Pour faire court, le fichier XML est un langage de balise, un peu comme le HTML, où l’on décrit de l’information. Les balises sont des valeurs entourées de < et > qui décrivent la sémantique de la donnée. Par exemple :
<prenom>Nicolas</prenom>
La balise <prenom> est ce qu’on appelle une balise ouvrante, cela signifie que ce qui se trouve après (en l’occurrence la chaine « Nicolas ») fait partie de cette balise jusqu’à ce que l’on rencontre la balise fermante </prenom> qui est comme la balise ouvrante à l’exception du / précédant le nom de la balise. Le XML est un fichier facile à lire par nous autres humains. On en déduit assez facilement que le fichier contient la chaine « Nicolas » et qu’il s’agit sémantiquement d’un prénom. Une balise peut contenir des attributs permettant de donner des informations sur la donnée. Les attributs sont entourés de guillemets " et " et font partis de la balise. Par exemple :
<client nom="Nicolas" age="30"></client>
Ici, la balise client possède un attribut « nom » ayant la valeur « Nicolas » et un attribut « age » ayant la valeur « 30 ». Encore une fois, c’est très facile à lire pour un humain. Il est possible que la balise n’ait pas de valeur, comme c’est le cas dans l’exemple ci-dessus. On peut dans ce cas-là remplacer la balise ouvrante et la balise fermante par cet équivalent :
<client nom="Nicolas" age="30"/>
Enfin, et nous allons terminer notre aperçu rapide du XML avec un dernier point. Il est important de noter que le XML peut imbriquer ses balises et qu’il ne peut posséder qu’un seul élément racine, ce qui nous permet d’avoir une hiérarchie de données. Par exemple nous pourrons avoir :
On voit tout de suite que le fichier décrit une liste de deux clients. Nous en avons un qui est un particulier, qui s’appelle Nicolas et qui a 30 ans alors que l’autre est un professionnel, prénommé Jérémie et qui a 40 ans.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
pour éviter de mettre des valeurs en dur dans le code. Imaginons que nous utilisions une url de service web dans notre application, si l'url change, on aimerait ne pas avoir à recompiler le code.
pour éviter d'utiliser la base de registre comme cela a beaucoup été fait dans les premières versions de Windows et de donner les droits de modification de base de registre.
Ces fichiers permettent d’avoir des informations de configuration, potentiellement typées. De plus, le framework .NET dispose de méthodes pour y accéder facilement. L'intérêt d'utiliser un fichier XML plutôt qu'un fichier binaire est que ce fichier est lisible et compréhensible facilement. On peut également le modifier à la main sans un système évolué permettant de faire des modifications. Voilà plein de raisons pour lesquelles on va utiliser ces fichiers.
Pour ajouter un fichier de configuration : faisons un clic droit sur le projet Ajouter > Nouvel élément
Et choisissons le modèle de fichier Fichier de configuration de l’application :
Gardez lui son nom et validez sa création. Ce fichier est presque vide :
Il possède sur sa première ligne un marqueur permettant d’identifier le fichier comme étant un fichier XML et une balise ouvrante configuration, suivie de sa balise fermante. C’est la structure de base du fichier de configuration. Nous mettrons nos sections de configuration à l’intérieur de cette balise. Nous retrouvons notre fichier de configuration dans notre projet et nous pouvons le voir dans l’explorateur de documents :
Compilons notre application et rendons-nous dans le répertoire où le fichier exécutable est généré. Nous y trouvons également un fichier qui porte le même nom que notre exécutable et dont l’extension est .exe.config. C’est bien notre fichier de configuration. Visual C# Express le déploie au même endroit que notre application et lui donne un nom qui va lui permettre d’être exploité par notre application. Pour être utilisables, ces fichiers doivent se situer dans le même répertoire que l'exécutable.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Avoir un fichier de configuration, c’est bien. Mais il faut savoir lire à l’intérieur si nous souhaitons pouvoir l’exploiter. Il existe plusieurs façons d’indiquer des valeurs de configuration, nous les découvrirons tout au long de ce chapitre. La plus simple est d’utiliser la section « AppSettings ». C'est une section où on peut mettre, comme son nom le suggère aux anglophones, les propriétés de l'application. Pour cela, on utilisera un système de clé / valeur pour stocker les informations. Par exemple, modifiez le fichier de configuration pour avoir :
En voyant ce fichier de configuration, l’être humain comprend assez facilement que nous allons avoir deux paramètres de configuration. Un premier qui est le prénom et qui va valoir Nicolas. Un deuxième qui est l’âge et qui sera de 30. Le savoir en tant qu’être humain, c’est bien. Pouvoir y accéder dans notre programme informatique, c’est encore mieux. :) Voyons comment faire. La première chose à faire est de référencer, si ce n’est déjà fait, l’assembly qui contient toutes les classes permettant de gérer la configuration. Elle s’appelle (sans surprise) System.Configuration :
Pour accéder au fichier de configuration, nous allons utiliser la classe statique ConfigurationManager. Pour accéder aux informations contenues dans la section AppSettings, nous utiliserons sa propriété AppSettings. Et nous pourrons accéder aux éléments de la configuration en utilisant l’opérateur d’indexation : []. Ce qui donne :
De plus, cela oblige à connaître l’ordre dans lequel les clés ont été mises dans le fichier. Il est possible aussi de boucler sur toutes les valeurs contenues dans la section :
La propriété AppSettings est en fait du type NameValueCollection. Il s'agit d'une collection d'éléments de type chaine de caractères qui sont accessibles à partir d'une clé de type chaine de caractères également. Une valeur est donc associée à une clé. À noter que la casse de la clé n’est pas importante pour accéder à la valeur associée à la clé. Le code suivant :
renverra bien notre valeur de configuration. Cependant, si la valeur n’existe pas, nous obtiendrons la valeur null dans la chaine de caractères. Il est important de remarquer que nous récupérons des chaines et que nous aurons besoin potentiellement de faire une conversion pour manipuler l’âge en tant qu’entier. Rien ne vous empêche d’écrire une petite méthode d’extension maintenant que vous savez faire :
public static class ConfigurationManagerExtensions
{
public static int ObtenirValeurEntiere(this NameValueCollection appSettings, string cle)
{
string valeur = appSettings[cle];
return Convert.ToInt32(valeur);
}
}
Que nous pourrons utiliser avec :
int age = ConfigurationManager.AppSettings.ObtenirValeurEntiere("age");
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Les chaines de connexion représentent un type de configuration particulier. Elles vont servir pour les applications ayant besoin de se connecter à une base de données. On va y stocker tout ce dont on a besoin, comme le nom du serveur ou les identifiants pour s’y connecter … Nous y reviendrons plus en détail plus tard, mais regardons la configuration suivante :
Nous définissons ici deux chaines de connexion qui permettent de se connecter en authentification Windows (Integrated Security=true) sur un serveur hébergé en local (.\SQLEXPRESS) dont le nom est SQLEXPRESS, qui utilisent SQL SERVER (providerName="System.Data.SqlClient), qui pointent sur les bases de données Base1 et Base2, identifiées chacune par les noms MaConnection et MaConnection2. Pour obtenir les informations de configuration individuellement, il faudra utiliser la propriété ConnectionStrings de la classe ConfigurationManager en y accédant par leurs noms :
Il est possible de créer sa propre section de configuration à partir d'un type prédéfini. Par exemple pour créer une section du même genre que la section appSettings, qui utilise une paire clé/valeur, on peut utiliser un DictionarySectionHandler. Il existe plusieurs types prédéfinis, que nous allons étudier ci-dessous.
DictionarySectionhandler
DictionarySectionhandler est une classe qui fournit les informations de configuration des paires clé / valeur d'une section de configuration.
Oui mais si tu nous dis que c’est un système de clé / valeur, c’est comme pour les AppSettings que nous avons vus. Pourquoi utiliser une section particulière DictionarySectionhandler alors ?
Le but de pouvoir faire des sections particulières est d'organiser sémantiquement son fichier de configuration, pour découper logiquement son fichier au lieu d'avoir tout dans la même section. Regardons cette configuration :
La première chose à voir est que nous indiquons à notre application que nous définissons une section de configuration du type DictionarySectionHandler et qui va s’appeler InformationsUtilisateur. Cela permet ensuite de définir notre propre section InformationsUtilisateur, qui ressemble beaucoup à la section AppSettings sauf qu’ici, on se rend tout de suite compte qu’il s’agit d’informations utilisateur. Pour accéder à notre section depuis notre programme, nous devrons utiliser le code suivant :
On utilise la méthode GetSection de la classe ConfigurationManager pour obtenir la section dont nous passons le nom en paramètre. On reçoit en retour une table de hachage (HashTable) et nous pourrons l’utiliser de cette façon pour obtenir les valeurs de nos clés :
C’est la même que juste précédemment, à l’exception du type de la section, qui cette fois-ci est NameValueSectionHandler. Ce qui implique que nous obtenons un type différent en retour de l’appel à la méthode GetSection, à savoir un NameValueCollection :
À vous de voir lequel des deux vous préférez, mais dans tous les cas, il faudra fonctionner avec un système de clé valeur.
SingleTagSectionHandler
Ce troisième type permet de gérer une section différente des deux précédentes. Il sera possible d’avoir autant d’attributs que l’on souhaite dans la section. Prenez par exemple cet exemple de configuration :
<configuration>
<configSections>
<section name="MonUtilisateur" type="System.Configuration.SingleTagSectionHandler" />
</configSections>
<MonUtilisateur prenom="Nico" age="30" adresse="9 rue des bois"/>
</configuration>
Nous voyons que je peux mettre autant d’attributs que je le souhaite. Par contre, il ne sera possible de faire apparaitre la section « MonUtilisateur » qu’une seule fois, alors que dans les sections précédentes, nous avions une liste de clé / valeur. Nous pourrons récupérer notre configuration avec le code suivant :
Attention par contre, cette fois-ci la casse est importante pour obtenir la valeur de notre attribut. Notons notre boucle habituelle permettant de retrouver tous les attributs de notre section :
foreach (DictionaryEntry d in section)
{
Console.WriteLine("Attribut : " + d.Key + " / Valeur : " + d.Value);
}
Voilà pour les sections utilisant un type prédéfini.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Super, nous savons définir des sections de configuration. Elles nous permettent d’organiser un peu mieux notre fichier de configuration. Par contre, si les sections se multiplient, cela va à nouveau être le bazar. Heureusement, les groupes de sections sont là pour remettre de l’ordre. Comme son nom l’indique, un groupe de section va permettre de regrouper plusieurs sections. Le but est de clarifier le fichier de configuration. Regardons l’exemple suivant :
Nous voyons ici que j’ai défini un groupe qui s’appelle Utilisateur, en utilisant la balise sectionGroup, contenant deux sections de configuration. Remarquons plus bas le contenu des sections et nous remarquons que la balise <Utilisateur> contient nos sections de configuration comme précédemment. Pour obtenir nos valeurs de configuration, la seule chose qui change est la façon de charger la section. Ici, nous mettons le nom de la section précédée du nom du groupe. Ce qui donne :
Nous allons étudier rapidement comment créer des sections de configuration personnalisées. Pour cela, il faut créer une section en dérivant de la classe ConfigurationSection. La classe ConfigurationSection permet de représenter une section d’un fichier de configuration. Donc, en toute logique, nous pouvons enrichir cette classe avec nos propriétés. Il suffit pour cela de décorer nos propres propriétés avec l’attribut ConfigurationProperty. Ce qui donne :
public class PersonneSection : ConfigurationSection
{
[ConfigurationProperty("age", IsRequired = true)]
public int Age
{
get { return (int)this["age"]; }
set { this["age"] = value; }
}
[ConfigurationProperty("prenom", IsRequired = true)]
public string Prenom
{
get { return (string)this["prenom"]; }
set { this["prenom"] = value; }
}
}
Le grand intérêt ici est de pouvoir typer les propriétés. Ainsi, nous pouvons avoir une section de configuration qui travaille avec un entier par exemple. Tout est fait par la classe mère ici et il suffit d’utiliser ses propriétés indexées en y accédant par son nom. Pour que notre section personnalisée soit reconnue, il faut la déclarer avec notre nouveau type :
Le nom du type est constitué du nom complet du type (espace de nom + nom de la classe) suivi d’une virgule et du nom de l’assembly. Ici, l’espace de nom est le même que l’assembly car j’ai créé mes classes à la racine du projet. Si vous avez un doute, vous devez vérifier l’espace de nom dans lequel est déclarée la classe. Ensuite, nous pourrons définir notre section, ce qui donne au final :
Ce qui est intéressant de remarquer ici, c’est qu’on accède directement à nos propriétés via notre section personnalisée. Ce qui est une grande force et permet de travailler avec un entier et une chaine de caractères ici. Il faudra faire attention à deux choses ici. La première est la casse. Comme on l’a vu dans le code, le nom est écrit en minuscule. Il faudra être cohérent entre le nom indiqué dans l’attribut ConfigurationProperty, celui indiqué en paramètre de l’opérateur d’indexation et celui écrit dans le fichier de configuration. Tout doit être orthographié de la même façon, sinon nous aurons une exception du genre :
De même, si nous ne saisissons pas une valeur entière dans l’attribut age, il va y avoir un problème de conversion :
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Dans le paragraphe du dessus, on constate qu’on ne peut définir qu’un élément dans notre section. Il pourrait être intéressant dans certains cas d'avoir une section personnalisée qui puisse contenir plusieurs éléments, par exemple pour avoir une liste de personnes.
public class ClientElement : ConfigurationElement
{
private static readonly ConfigurationPropertyCollection _proprietes;
private static readonly ConfigurationProperty age;
private static readonly ConfigurationProperty prenom;
static ClientElement()
{
prenom = new ConfigurationProperty("prenom", typeof(string), null, ConfigurationPropertyOptions.IsKey);
age = new ConfigurationProperty("age", typeof(int), null, ConfigurationPropertyOptions.IsRequired);
_proprietes = new ConfigurationPropertyCollection { prenom, age };
}
public string Prenom
{
get { return (string)this["prenom"]; }
set { this["prenom"] = value; }
}
public int Age
{
get { return (int)this["age"]; }
set { this["age"] = value; }
}
protected override ConfigurationPropertyCollection Properties
{
get { return _proprietes; }
}
}
Ici, je définis deux propriétés, Prenom et Age, qui me permettent bien sûr d’y stocker un prénom et un âge qui sont respectivement une chaine de caractères et un entier. À noter que nous avons besoin de décrire ces propriétés dans le constructeur statique de la classe. Pour cela, il faut lui indiquer son nom, c’est-à-dire la chaine qui sera utilisée comme attribut dans l’élément de la section de configuration. Puis nous lui indiquons son type, pour cela on utilise le mot-clé typeof qui permet justement de renvoyer le type (dans le sens objet Type) d’un type. Enfin nous lui indiquons une option, par exemple le prénom sera la clé de mon élément (qui est une valeur unique et obligatoire à saisir) et l’âge, qui sera un élément obligatoire à saisir également. Ensuite, nous avons besoin d’utiliser cette classe à travers une collection d’éléments. Pour ce faire, il faut créer une classe qui dérive de ConfigurationElementCollection :
public class ClientElementCollection : ConfigurationElementCollection
{
public override ConfigurationElementCollectionType CollectionType
{
get { return ConfigurationElementCollectionType.BasicMap; }
}
protected override string ElementName
{
get { return "Client"; }
}
protected override ConfigurationPropertyCollection Properties
{
get { return new ConfigurationPropertyCollection(); }
}
public ClientElement this[int index]
{
get { return (ClientElement)BaseGet(index); }
set
{
if (BaseGet(index) != null)
{
BaseRemoveAt(index);
}
BaseAdd(index, value);
}
}
public new ClientElement this[string nom]
{
get { return (ClientElement)BaseGet(nom); }
}
public void Add(ClientElement item)
{
BaseAdd(item);
}
public void Remove(ClientElement item)
{
BaseRemove(item);
}
public void RemoveAt(int index)
{
BaseRemoveAt(index);
}
public void Clear()
{
BaseClear();
}
protected override ConfigurationElement CreateNewElement()
{
return new ClientElement();
}
protected override object GetElementKey(ConfigurationElement element)
{
return ((ClientElement)element).Prenom;
}
}
Ces classes ont toujours la même structure. Ce qui est important de voir est qu’on utilise à l’intérieur la classe ClientElement pour indiquer le type de la collection. Nous indiquons également le nom de la balise qui sera utilisée dans le fichier de configuration, c’est la chaine « Client » que renvoie la propriété ElementName. Enfin, j’ai la possibilité de définir ma clé en substituant la méthode GetElementKey. Le reste des méthodes appellent les méthodes de la classe mère.
Enfin, il faut créer notre section personnalisée, qui dérive comme d’habitude de ConfigurationSection :
public class ListeClientSection : ConfigurationSection
{
private static readonly ConfigurationPropertyCollection proprietes;
private static readonly ConfigurationProperty liste;
static ListeClientSection()
{
liste = new ConfigurationProperty(string.Empty, typeof(ClientElementCollection), null, ConfigurationPropertyOptions.IsRequired | ConfigurationPropertyOptions.IsDefaultCollection);
proprietes = new ConfigurationPropertyCollection { liste };
}
public ClientElementCollection Listes
{
get { return (ClientElementCollection)base[liste]; }
}
public new ClientElement this[string nom]
{
get { return Listes[nom]; }
}
protected override ConfigurationPropertyCollection Properties
{
get { return proprietes; }
}
}
Notons dans cette classe comment nous utilisons l’opérateur d’indexation pour renvoyer un élément à partir de sa clé et renvoyer la liste des éléments. Maintenant, nous pouvons écrire notre configuration :
Nous avons besoin à nouveau de définir la section en indiquant son type. Puis nous pouvons créer notre section et positionner notre liste de clients. Pour accéder à cette section, nous pouvons charger notre section comme avant avec la méthode GetSection :
Voilà pour ce petit tour sur la configuration d’une application. Nous y avons découvert plusieurs façons d’y stocker des paramètres utilisables par notre application. Il faut savoir que beaucoup de composants du framework .NET sont intimement liés à ce fichier de configuration, comme une application web créée avec ASP.NET ou lorsqu’on utilise des services web.
Il est important de remarquer que ce fichier est un fichier de configuration d’application. Il y a d’autres endroits du même genre pour stocker de la configuration pour les applications .NET, comme le machine.config qui est un fichier de configuration partagé par toutes les applications de la machine. Il y a un héritage entre les différents fichiers de configuration. Si l’on définit une configuration au niveau machine (dans le machine.config), il est possible de la redéfinir pour notre application (app.config). En général, le fichier machine.config se trouve dans le répertoire d’installation du framework .NET, c'est-à-dire dans un sous répertoire du système d’exploitation, dépendant de la version du framework .NET installée. Chez moi par exemple, il se trouve dans le répertoire : C:\Windows\Microsoft.NET\Framework\v4.0.30319\Config.
Enfin, remarquons qu’il est possible de faire des modifications du fichier de configuration directement depuis le code de notre application. C’est un point qui est rarement utilisé et que j’ai choisi de ne pas présenter pour que le chapitre ne soit pas trop long.
En résumé
Les fichiers de configuration sont des fichiers XML qui possèdent les paramètres de configuration de notre application.
Pour les applications console, ils s'appellent app.config.
On peut définir toutes sortes de valeurs de configuration grâce aux sections prédéfinies ou en ajoutant son propre type de section personnalisée.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
LINQ signifie Language INtegrated Query. C'est un ensemble d'extensions du langage permettant de faire des requêtes sur des données en faisant abstraction de leur type. Il permet d'utiliser facilement un jeu d'instructions supplémentaires afin de filtrer des données, faire des sélections, etc. Il existe plusieurs domaines d'applications pour LINQ :
Linq To Entities ou Linq To SQL qui utilisent ces extensions de langage sur les bases de données.
Linq To XML qui utilise ces extensions de langage pour travailler avec les fichiers XML.
Linq To Object qui permet de travailler avec des collections d'objets en mémoire.
L'étude de LINQ nécessiterait un livre en entier, aussi nous allons nous concentrer sur la partie qui va le plus nous servir en tant que débutant et qui va nous permettre de commencer à travailler simplement avec cette nouvelle syntaxe, à savoir Linq To Object. Il s'agit d'extensions permettant de faire des requêtes sur les objets en mémoire et notamment sur toutes les listes ou collections. En fait, sur tout ce qui implémente IEnumerable<>.
Les requêtes Linq proposent une nouvelle syntaxe permettant d’écrire des requêtes qui ressemblent de loin à des requêtes SQL. Pour ceux qui ne connaissent pas le SQL, il s’agit d’un langage permettant de faire des requêtes sur les bases de données.
Pour utiliser ces requêtes, il faut ajouter l’espace de noms adéquat, à savoir :
using System.Linq;
Ce using est en général inclus par défaut lorsqu’on crée un nouveau fichier. Jusqu’à maintenant, si nous voulions afficher les entiers d’une liste d’entiers qui sont strictement supérieur à 5, nous aurions fait :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
foreach (int i in liste)
{
if (i > 5)
{
Console.WriteLine(i);
}
}
Grâce à Linq To Object, nous allons pouvoir filtrer en amont la liste afin de ne parcourir que les entiers qui nous intéressent, en faisant :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requeteFiltree = from i in liste
where i > 5
select i;
foreach (int i in requeteFiltree)
{
Console.WriteLine(i);
}
Qui donnera :
6
9
15
8
Nous avons ici créé une requête Linq qui contient des mots-clés, comme from, in, where et select. Ici, cette requête veut dire que nous partons (from) de la liste « liste » en analysant chaque entier de la liste dans (in) la variable i où (where) i est supérieur à 5. Dans ce cas, il est sélectionné comme faisant partie du résultat de la requête grâce au mot-clé select, qui fait un peu office de return. Cette requête renvoie un IEnumerable<int>. Le type générique est ici le type int car c’est le type de la variable i qui est retournée par le select. Le fait de renvoyer un IEnumerable<> va permettre potentiellement de réutiliser le résultat de cette requête pour un filtre successif ou une expression différente. En effet, Linq travaille sur des IEnumerable<> … Nous pourrions par exemple ordonner cette liste par ordre croissant grâce au mot-clé orderby. Cela donnerait :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requeteFiltree = from i in liste
where i > 5
select i;
IEnumerable<int> requeteOrdonnee = from i in requeteFiltree
orderby i
select i;
foreach (int i in requeteOrdonnee)
{
Console.WriteLine(i);
}
qui pourrait également s’écrire en une seule fois avec :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requete = from i in liste
where i > 5
orderby i
select i;
foreach (int i in requete)
{
Console.WriteLine(i);
}
Et nous aurons :
6
8
9
15
L’intérêt est que grâce à ces syntaxes, nous pouvons combiner facilement plusieurs filtres et construire des requêtes plus ou moins complexes. Par exemple, imaginons des clients :
public class Client
{
public int Identifiant { get; set; }
public string Nom { get; set; }
public int Age { get; set; }
}
que l’on souhaiterait savoir majeurs, puis triés par Age puis par Nom, nous pourrions faire :
List<Client> listeClients = new List<Client>
{
new Client { Identifiant = 1, Nom = "Nicolas", Age = 30},
new Client { Identifiant = 2, Nom = "Jérémie", Age = 20},
new Client { Identifiant = 3, Nom = "Delphine", Age = 30},
new Client { Identifiant = 4, Nom = "Bob", Age = 10}
};
IEnumerable<string> requete = from client in listeClients
where client.Age > 18
orderby client.Age, client.Nom
select client.Nom;
foreach (string prenom in requete)
{
Console.WriteLine(prenom);
}
Ce qui donnera :
Jérémie
Delphine
Nicolas
Notez ici que mon select « renvoie » le nom du client, qui est un string. Il est donc normal que ma requête renvoie un IEnumerable<string> car j’ai choisi qu’elle ne sélectionne que les noms, qui sont de type string. Il est assez fréquent de construire des objets anonymes à l’intérieur d’une requête. Par exemple, plutôt que de renvoyer uniquement le nom du client, je pourrais également renvoyer l’Age, mais comme je n’ai pas besoin de l’identifiant, je peux créer un objet anonyme juste avec ces deux propriétés :
List<Client> listeClients = new List<Client>
{
new Client { Identifiant = 1, Nom = "Nicolas", Age = 30},
new Client { Identifiant = 2, Nom = "Jérémie", Age = 20},
new Client { Identifiant = 3, Nom = "Delphine", Age = 30},
new Client { Identifiant = 4, Nom = "Bob", Age = 10},
};
var requete = from client in listeClients
where client.Age > 18
orderby client.Age , client.Nom
select new { client.Nom, client.Age };
foreach (var obj in requete)
{
Console.WriteLine("{0} a {1} ans", obj.Nom, obj.Age);
}
Et nous aurons :
Jérémie a 20 ans
Delphine a 30 ans
Nicolas a 30 ans
Mon objet anonyme contient ici juste une propriété Nom et une propriété Age. À noter que je suis obligé à ce moment-là d’utiliser le mot-clé var pour définir la requête, car je n’ai pas de type à donner à cette requête. De même, dans le foreach je dois utiliser le mot-clé var pour définir le type anonyme. Les requêtes peuvent être de plus en plus compliquées, comme faisant des jointures. Par exemple, rajoutons une classe Commande :
public class Commande
{
public int Identifiant { get; set; }
public int IdentifiantClient { get; set; }
public decimal Prix { get; set; }
}
Je peux créer des commandes pour des clients :
List<Client> listeClients = new List<Client>
{
new Client { Identifiant = 1, Nom = "Nicolas", Age = 30},
new Client { Identifiant = 2, Nom = "Jérémie", Age = 20},
new Client { Identifiant = 3, Nom = "Delphine", Age = 30},
new Client { Identifiant = 4, Nom = "Bob", Age = 10},
};
List<Commande> listeCommandes = new List<Commande>
{
new Commande{ Identifiant = 1, IdentifiantClient = 1, Prix = 150.05M},
new Commande{ Identifiant = 2, IdentifiantClient = 2, Prix = 30M},
new Commande{ Identifiant = 3, IdentifiantClient = 1, Prix = 99.99M},
new Commande{ Identifiant = 4, IdentifiantClient = 1, Prix = 100M},
new Commande{ Identifiant = 5, IdentifiantClient = 3, Prix = 80M},
new Commande{ Identifiant = 6, IdentifiantClient = 3, Prix = 10M},
};
Et grâce à une jointure, récupérer avec ma requête le nom du client et le prix de sa commande :
var liste = from commande in listeCommandes
join client in listeClients on commande.IdentifiantClient equals client.Identifiant
select new { client.Nom, commande.Prix };
foreach (var element in liste)
{
Console.WriteLine("Le client {0} a payé {1}", element.Nom, element.Prix);
}
Ce qui donne :
Le client Nicolas a payé 150,05
Le client Jérémie a payé 30
Le client Nicolas a payé 99,99
Le client Nicolas a payé 100
Le client Delphine a payé 80
Le client Delphine a payé 10
On utilise le mot-clé join pour faire la jointure entre les deux listes puis on utilise le mot-clé on et le mot-clé equals pour indiquer sur quoi on fait la jointure. À noter que ceci peut se réaliser en imbriquant également les from et en filtrant sur l’égalité des identifiants clients :
var liste = from commande in listeCommandes
from client in listeClients
where client.Identifiant == commande.IdentifiantClient
select new { client.Nom, commande.Prix };
foreach (var element in liste)
{
Console.WriteLine("Le client {0} a payé {1}", element.Nom, element.Prix);
}
Il est intéressant de pouvoir regrouper les objets qui ont la même valeur. Par exemple pour obtenir toutes les commandes, groupées par client, on ferra :
var liste = from commande in listeCommandes
group commande by commande.IdentifiantClient;
foreach (var element in liste)
{
Console.WriteLine("Le client : {0} a réalisé {1} commande(s)", element.Key, element.Count());
foreach (Commande commande in element)
{
Console.WriteLine("\tPrix : {0}", commande.Prix);
}
}
Ici, cela donne :
Le client : 1 a réalisé 3 commande(s)
Prix : 150,05
Prix : 99,99
Prix : 100
Le client : 2 a réalisé 1 commande(s)
Prix : 30
Le client : 3 a réalisé 2 commande(s)
Prix : 80
Prix : 10
Il est possible de cumuler le group by avec notre jointure précédente histoire d’avoir également le nom du client :
var liste = from commande in listeCommandes
join client in listeClients on commande.IdentifiantClient equals client.Identifiant
group commande by new {commande.IdentifiantClient, client.Nom};
foreach (var element in liste)
{
Console.WriteLine("Le client {0} ({1}) a réalisé {2} commande(s)", element.Key.Nom, element.Key.IdentifiantClient, element.Count());
foreach (Commande commande in element)
{
Console.WriteLine("\tPrix : {0}", commande.Prix);
}
}
Et nous obtenons :
Le client Nicolas (1) a réalisé 3 commande(s)
Prix : 150,05
Prix : 99,99
Prix : 100
Le client Jérémie (2) a réalisé 1 commande(s)
Prix : 30
Le client Delphine (3) a réalisé 2 commande(s)
Prix : 80
Prix : 10
À noter que le group by termine la requête, un peu comme le select. Ainsi, si l’on veut sélectionner quelque chose après le group by, il faudra utiliser le mot-clé into et la syntaxe suivante : Ce qui donnera :
var liste = from commande in listeCommandes
join client in listeClients on commande.IdentifiantClient equals client.Identifiant
group commande by new {commande.IdentifiantClient, client.Nom} into commandesGroupees
select
new
{
commandesGroupees.Key.IdentifiantClient,
commandesGroupees.Key.Nom,
NombreDeCommandes = commandesGroupees.Count()
};
foreach (var element in liste)
{
Console.WriteLine("Le client {0} ({1}) a réalisé {2} commande(s)", element.Nom, element.IdentifiantClient, element.NombreDeCommandes);
}
Avec pour résultat :
Le client Nicolas (1) a réalisé 3 commande(s)
Le client Jérémie (2) a réalisé 1 commande(s)
Le client Delphine (3) a réalisé 2 commande(s)
L’intérêt d’utiliser le mot-clé into est également de pouvoir enchainer avec une autre jointure ou autre filtre permettant de continuer la requête. Il est également possible d’utiliser des variables à l’intérieur des requêtes grâce au mot-clé let. Cela va nous permettre de stocker des résultats temporaires pour les réutiliser ensuite :
var liste = from commande in listeCommandes
join client in listeClients on commande.IdentifiantClient equals client.Identifiant
group commande by new {commande.IdentifiantClient, client.Nom} into commandesGroupees
let total = commandesGroupees.Sum(c => c.Prix)
where total > 50
orderby total
select new
{
commandesGroupees.Key.IdentifiantClient,
commandesGroupees.Key.Nom,
NombreDeCommandes = commandesGroupees.Count(),
PrixTotal = total
};
foreach (var element in liste)
{
Console.WriteLine("Le client {0} ({1}) a réalisé {2} commande(s) pour un total de {3}", element.Nom, element.IdentifiantClient, element.NombreDeCommandes, element.PrixTotal);
}
Par exemple, ici j’utilise le mot-clé let pour stocker le total d’une commande groupée dans la variable total (nous verrons la méthode Sum() un tout petit peu plus bas), ce qui me permet ensuite de filtrer avec un where pour obtenir les commandes dont le total est supérieur à 50 et de les trier par ordre de prix croissant.
Ce qui donne :
Le client Delphine (3) a réalisé 2 commande(s) pour un total de 90
Le client Nicolas (1) a réalisé 3 commande(s) pour un total de 350,04
Nous allons nous arrêter là pour cet aperçu des requêtes LINQ. Nous avons pu voir que le C# dispose d’un certain nombre de mots-clés qui permettent de manipuler nos données de manière très puissante mais d’une façon un peu inhabituelle. Cette façon d’écrire des requêtes LINQ s’appelle en anglais la « sugar syntax », que l’on peut traduire par « sucre syntaxique ». Il désigne de manière générale les constructions d'un langage qui facilitent la rédaction du code sans modifier l'expressivité du langage. Voyons à présent ce qu’il y a derrière cette jolie syntaxe.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
En fait, toute la sugar syntax que nous avons vue précédemment repose sur un certain nombre de méthodes d’extensions qui travaillent sur les types IEnumerable<T>. Par exemple, la requête suivante :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requeteFiltree = from i in liste
where i > 5
select i;
foreach (int i in requeteFiltree)
{
Console.WriteLine(i);
}
s'écrit véritablement :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requeteFiltree = liste.Where(i => i > 5);
foreach (int i in requeteFiltree)
{
Console.WriteLine(i);
}
Nous utilisons la méthode d’extensions Where() en lui fournissant une expression lambda servant de prédicat pour filtrer la liste. C’est de cette façon que le compilateur traduit la sugar syntax. Elle n’est donc qu’une façon plus jolie d’utiliser ces méthodes d’extensions. Chaque méthode d’extension renvoie un IEnumerable<T> ce qui permet d’enchainer facilement les filtres successifs. Par exemple, rajoutons une date et un nombre d’articles à notre classe Commande :
public class Commande
{
public int Identifiant { get; set; }
public int IdentifiantClient { get; set; }
public decimal Prix { get; set; }
public DateTime Date { get; set; }
public int NombreArticles { get; set; }
}
Nous pouvons obtenir les commandes dont le prix est supérieur à 100, où le nombre d’articles est supérieur à 10, triées par prix puis par date d’achat.
De plus, ces méthodes d’extensions font beaucoup plus de choses que ce que l’on peut faire avec la sugar syntax. Il existe pas mal de méthodes intéressantes, que nous ne pourrons pas toutes étudier. Regardons par exemple la méthode Sum() (qui a été utilisée dans le paragraphe précédent) qui permet de faire la somme des éléments d’une liste ou la méthode Average() qui permet de faire la moyenne :
Tout est déjà fait :) , pratique ! Évidemment, les surcharges de ces deux méthodes d’extensions ne fonctionnent qu’avec des types int ou double ou decimal… Qui envisagerait de faire une moyenne sur une chaine ? Par contre, il est possible de définir une expression lambda dans la méthode Sum() afin de faire la somme sur un élément d’un objet, comme le prix de notre commande :
Ici, je trie dans un premier temps ma liste par âge décroissant, et je prends les 5 premiers. Ce qui signifie que je prends les 5 plus vieux clients de ma liste. Et s’il y en a que 3 ? et bien il prendra uniquement les 3 premiers. :) Suivant le même principe, on peut utiliser la méthode First() pour obtenir le premier élément d’une liste :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
int premier = liste.Where(i => i > 5).First();
Où j’obtiens le premier élément de la liste qui est strictement supérieur à 5. À noter que le filtre peut également se faire dans l’expression lambda de la méthode First() :
int premier = liste.First(i => i > 5);
Ce qui revient exactement au même. Attention, s’il n’y a aucun élément dans la liste, alors la méthode First() lève l’exception :
Exception non gérée : System.InvalidOperationException: La séquence ne contient aucun élément.
Il est possible dans ce cas-là d’éviter une exception avec la méthode FirstOrDefault() qui renvoie la valeur par défaut du type de la liste (0 si c’est un type valeur, null si c’est un type référence) :
Client nicolas = listeClients.FirstOrDefault(client => client.Nom == "Nicolas");
if (nicolas == null)
Console.WriteLine("Client non trouvé");
Ici, je cherche le premier des clients dont le nom est Nicolas. S’il n’est pas trouvé, alors FirstOrDefault() me renvoie null, sinon, il me renvoie bien sûr le bon objet Client. Dans le même genre, nous pouvons compter grâce à la méthode Count() le nombre d’éléments d’une source de données suivant un critère :
int nombreClientsMajeurs = listeClients.Count(client => client.Age >= 18);
Ici, j’obtiendrais le nombre de clients majeurs dans ma liste. De la même façon qu’avec la sugar syntax, il est possible de faire une sélection précise des données que l’on souhaite extraire, grâce à la méthode Select() :
var requete = listeClients.Where(client => client.Age >= 18).Select(client => new { client.Age, client.Nom }) ;
Cela me permettra d’obtenir une requête contenant les clients majeurs. À noter qu’il y a aura dedans des objets anonymes possédant une propriété Age et une propriété Nom. Bien sûr, nous retrouverons nos jointures avec la méthode d’extension Join() ou les groupes avec la méthode GroupBy(). Il existe beaucoup de méthodes d’extensions et il n’est pas envisageable dans ce tutoriel de toutes les décrire. Je vais finir en vous parlant des méthodes ToList() et ToArray() qui comme leurs noms le suggèrent, permettent de forcer la requête à être mise dans une liste ou dans un tableau :
Plutôt que d’avoir un IEnumerable<>, nous obtiendrons cette fois-ci une List<> ou un tableau. Le fait d’utiliser ces méthodes d’extensions a des conséquences que nous allons décrire.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Alors, les méthodes d’extensions LINQ ou sa syntaxe sucrée c’est bien joli, mais quel est l’intérêt de s’en servir plutôt que d’utiliser des boucles foreach, des if ou autres choses ? Déjà, parce qu’il y a plein de choses déjà toutes faites, la somme, la moyenne, la récupération de X éléments, etc. Mais aussi pour une autre raison plus importante : l’exécution différée.
Nous en avons déjà parlé, l’exécution différée est possible grâce au mot-clé yield. Les méthodes d’extensions Linq utilisent fortement ce principe. Cela veut dire que lorsque nous construisons une requête, elle n’est pas exécutée tant qu’on itère pas sur le contenu de la requête. Ceci permet de stocker la requête, d’empiler éventuellement des filtres ou des jointures et de ne pas calculer le résultat tant qu’on n’en a pas explicitement besoin.
Ainsi, imaginons que nous souhaitions trier une liste d’entiers, avant nous aurions fait :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
liste.Sort();
liste.Add(7);
foreach (int i in liste)
{
Console.WriteLine(i);
}
Ce qui aurait affiché en toute logique la liste triée puis à la fin l’entier 7 rajouté, c'est-à-dire :
1
3
4
5
6
8
9
15
7
Avec Linq, nous allons pouvoir faire :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
var requete = liste.OrderBy(e => e);
liste.Add(7);
foreach (int i in requete)
{
Console.WriteLine(i);
}
Et si nous exécutons ce code, nous aurons :
1
3
4
5
6
7
8
9
15
Bien que nous ayons ajouté la valeur 7 après avoir trié la liste avec OrderBy, on se rend compte que tous les entiers sont quand même triés lorsque nous les affichons.
En effet, la requête n’a été exécutée qu’au moment du foreach. Ceci implique donc que le tri va tenir compte de l’ajout du 7 à la liste. La requête est construite en mémorisant les conditions comme notre OrderBy, mais cela fonctionne également avec un where, et tout ceci n’est exécuté que lorsqu’on le demande explicitement, c'est-à-dire avec un foreach dans ce cas-là. En fait, tant que le C# n’est pas obligé de parcourir les éléments énumérables alors il ne le fait pas. Ce qui permet d’enchainer les éventuelles conditions et éviter les parcours inutiles. Par exemple, dans le cas ci-dessous, il est inutile d’exécuter le premier filtre :
List<int> liste = new List<int> { 4, 6, 1, 9, 5, 15, 8, 3 };
IEnumerable<int> requete = liste.Where(i => i > 5);
// plein de choses qui n'ont rien à voir avec la requete
requete = requete.Where(i => i > 10);
car le deuxième filtre a tout intérêt à être combiné au premier afin d’être simplifié. Et encore, ici, on n’utilise même pas la requête, il y a encore moins d’intérêt à effectuer nos filtres si nous ne nous servons pas du résultat. Ceci peut paraître inattendu, mais c’est très important dans la façon dont Linq s’en sert afin d’optimiser ses requêtes. Ici, le parcours en mémoire pourrait paraître peu couteux, mais dans la mesure où Linq doit fonctionner aussi bien avec des objets, qu’avec des bases de données ou du XML (ou autres…), cette optimisation prend tout son sens.
Le maitre mot est la performance, primordial quand on accède aux bases de données. Cette exécution différée est gardée pour le plus tard possible. C'est-à-dire que le fait de parcourir notre boucle va obligatoirement entrainer l’évaluation de la requête afin de pouvoir retourner les résultats cohérents. Il en va de même pour certaines autres opérations, comme la méthode Sum(). Comment pourrions-nous faire la somme de tous les éléments si nous ne les parcourons pas ? C’est aussi le cas pour les méthodes ToList() et ToArray(). Par contre, ce n’est pas le cas pour les méthodes Where, ou Take, etc …
Il est important de connaitre ce mécanisme. L’exécution différée est très puissante et connaître son fonctionnement permet de savoir exactement ce que nous faisons et pourquoi nous pourrions obtenir parfois des résultats étranges.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Pour terminer avec Linq, voici un tableau récapitulatif des différents opérateurs de requête. Nous ne les avons pas tous étudiés ici car cela serait bien vite lassant. Mais grâce à leurs noms et leurs types, il est assez facile de voir à quoi ils servent afin de les utiliser dans la construction de nos requêtes.
Aggregate, Average, Count, LongCount, Max, Min, Sum
Non
N’hésitez pas à consulter la documentation de ces méthodes d’extensions ou à aller voir des exemples sur internet. Il y a beaucoup de choses à faire avec ces méthodes. Il est important également de bien savoir les maîtriser afin d’éviter les problèmes de performances. En effet, l’évaluation systématique des expressions peut être coûteuse, surtout quand c’est imbriqué dans des boucles. À utiliser judicieusement.
Voilà pour ce petit aperçu de Linq ! Rappelez-vous bien que Linq est une abstraction qui permet de manipuler des sources de données différentes. Nous avons vu son utilisation avec les objets implémentant IEnumerable<>, avec ce qu’on appelle Linq To Objects. Il est possible de faire du Linq en allant manipuler des données en base de données, on utilisera pour cela Linq To SQL ou Linq To Entity. De même, il est possible de manipuler les fichiers XML avec Linq To XML.
Linq apporte des méthodes d’extensions et une syntaxe complémentaire afin d’être efficace avec la manipulation de sources de données.
Sachez enfin qu’il est possible de requêter n’importe quelle source de données à partir du moment où un connecteur spécifique a été développé. Cela a été fait par exemple pour interroger Google ou Amazon, mais aussi pour requêter sur active directory, ou JSON, etc.
En résumé
Linq consiste en un ensemble d’extensions du langage permettant de faire des requêtes sur des données en faisant abstraction de leur type.
Il existe plusieurs domaines d'applications de Linq, comme Linq to Object, Linq to Sql, etc.
La sugar syntax ajoute des mots-clés qui permettent de faire des requêtes qui ressemblent aux requêtes faites avec le langage SQL.
Derrière cette syntaxe se cache un bon nombre de méthodes d'extension qui tirent parti des mécanismes d'exécution différée.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Une des grandes préoccupations des créateurs de logiciels est d’être certains que leur application informatique fonctionne et surtout qu’elle fonctionne dans toutes les situations possibles. Nous avons tous déjà vu notre système d’exploitation planter, ou bien notre logiciel de traitement de texte nous faire perdre les 50 pages de rapport que nous étions en train de taper. Ou encore, un élément inattendu dans un jeu où l'on arrive à passer à travers un mur alors qu’on ne devrait pas…
Bref, pour être sûr que son application fonctionne, il faut faire des tests.
Qu’est-ce qu’un test unitaire et pourquoi en faire ?
Un test constitue une façon de vérifier qu’un système informatique fonctionne.
Tester son application c’est bien. Il faut absolument le faire. C’est en général une pratique plutôt laissée de côté et rébarbative. Il y a plusieurs façons de faire des tests. Celle qui semble la plus naturelle est celle qui se fait manuellement. On lance son application, on clique partout, on regarde si elle fonctionne. Celle que je vais présenter ici constitue une pratique automatisée visant à s’assurer que des bouts de code fonctionnent comme il faut et que tous les scénarios d’un développement sont couverts par un test. Lorsque les tests couvrent tous les scénarios d’un code, nous pouvons assurer que notre code fonctionne. De plus, cela permet de faire des opérations de maintenance sur le code tout en étant certain que ce code n’aura pas subi de régressions. De la même façon, les tests sont un filet de sécurité lorsqu’on souhaite refactoriser son code ou l’optimiser. Cela permet dans certains cas d’avoir un guide pendant le développement, notamment lorsqu’on pratique le TDD. Le Test Driven Development (TDD) (ou en Français développement piloté par les tests) est une méthode de développement de logiciel qui préconise d'écrire les tests unitaires avant d'écrire le code source d'un logiciel. Nous y reviendrons ultérieurement.
En général, un test se décompose en trois partie, suivant le schéma « AAA », qui correspond aux mots anglais « Arrange, Act, Assert », que l’on peut traduire en français par Arranger, Agir, Auditer.
Arranger : Il s’agit dans un premier temps de définir les objets, les variables nécessaires au bon fonctionnement de son test (initialiser les variables, initialiser les objets à passer en paramètres de la méthode à tester, etc.).
Agir : Ensuite, il s’agit d’exécuter l’action que l’on souhaite tester (en général, exécuter la méthode que l’on veut tester, etc.)
Auditer : Et enfin de vérifier que le résultat obtenu est conforme à nos attentes.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Imaginons que nous voulions tester une méthode toute simple qui fait l’addition entre deux nombres, par exemple la méthode suivante :
public static int Addition(int a, int b)
{
return a + b;
}
Faire un test consiste à écrire des bouts de code permettant de s’assurer que le code fonctionne. Cela peut-être par exemple :
static void Main(string[] args)
{
// arranger
int a = 1;
int b = 2;
// agir
int resultat = Addition(a, b);
// auditer
if (resultat != 3)
Console.WriteLine("Le test a raté");
}
Ici, le test passe bien, ouf ! Pour être complet, le test doit couvrir un maximum de situations, il faut donc tester notre code avec d’autres valeurs, et ne pas oublier les valeurs limites :
static void Main(string[] args)
{
int a = 1;
int b = 2;
int resultat = Addition(a, b);
if (resultat != 3)
Console.WriteLine("Le test a raté");
a = 0;
b = 0;
resultat = Addition(a, b);
if (resultat != 0)
Console.WriteLine("Le test a raté");
a = -5;
b = 5;
resultat = Addition(a, b);
if (resultat != 0)
Console.WriteLine("Le test a raté");
}
Voilà pour le principe. Ici, nous considérons avoir écrit suffisamment de tests pour nous assurer que cette méthode est bien fonctionnelle. Bien sûr, cette méthode était par définition fonctionnelle, mais il est important de prendre le réflexe de tester des fonctionnalités qui sont déterminantes pour notre application.
Voyons maintenant comment nous pourrions tester une méthode avec l’approche TDD. Pour rappel, lors d’une approche TDD, le but est de pouvoir faire un développement à partir des cas de tests préalablement établis par la personne qui exprime le besoin ou suivant les spécifications fonctionnelles.
Imaginons que nous voulions tester une méthode qui calcule la factorielle d’un nombre. Nous savons que la factorielle de 0 vaut 1, la factorielle de 1 vaut 1. Commençons par écrire les tests :
static void Main(string[] args)
{
int valeur = 0;
int resultat = Factorielle(valeur);
if (resultat != 1)
Console.WriteLine("Le test a raté");
valeur = 1;
resultat = Factorielle(valeur);
if (resultat != 1)
Console.WriteLine("Le test a raté");
}
Le code ne compile pas ! Forcément, nous n’avons pas encore créé la méthode Factorielle. C’est la première étape. La suite de la méthode est de faire en sorte que le test compile, mais il échouera puisque la méthode n’est pas encore implémentée :
public static int Factorielle(int a)
{
throw new NotImplementedException();
}
Il faudra ensuite écrire le code minimal qui servira à faire passer nos deux tests. Cela peut-être :
public static int Factorielle(int a)
{
return 1;
}
Si nous exécutons nos tests, nous voyons que cette méthode est fonctionnelle car ils passent tous. La suite de la méthode consiste à refactoriser le code, à l’optimiser. Ici, il n’y a rien à faire tellement c’est simple. On se rend compte par contre qu'on n'a pas couvert énormément de cas de tests, juste des tests avec 0 et 1 c'est un peu léger... Nous savons que la factorielle de 2 vaut 2, la factorielle de 3 vaut 6, la factorielle de 4 vaut 24, ... Continuons à écrire des tests. (Il faut bien sûr garder les anciens tests afin d’être sûr qu’on couvre un maximum de cas) :
static void Main(string[] args)
{
int valeur = 0;
int resultat = Factorielle(valeur);
if (resultat != 1)
Console.WriteLine("Le test a raté");
valeur = 1;
resultat = Factorielle(valeur);
if (resultat != 1)
Console.WriteLine("Le test a raté");
valeur = 2;
resultat = Factorielle(valeur);
if (resultat != 2)
Console.WriteLine("Le test a raté");
valeur = 3;
resultat = Factorielle(valeur);
if (resultat != 6)
Console.WriteLine("Le test a raté");
valeur = 4;
resultat = Factorielle(valeur);
if (resultat != 24)
Console.WriteLine("Le test a raté");
}
Et nous pouvons écrire une méthode Factorielle qui fait passer ces tests :
public static int Factorielle(int a)
{
if (a == 2)
return 2;
if (a == 3)
return 6;
if (a == 4)
return 24;
return 1;
}
Lançons les tests, nous voyons que tout est OK. Cependant, nous n’allons pas faire des if en déclinant tous les cas possible, il faut donc repasser par l’étape d’amélioration et de refactorisation du code, afin d’éviter les redondances de code, d’améliorer les algorithmes, etc. Cette opération devient sans risque puisque le test est là pour nous assurer que la modification que l’on vient de faire est sans régression, si le test passe toujours bien sûr… Nous voyons que nous pouvons améliorer le code en utilisant la vraie formule de la factorielle :
public static int Factorielle(int a)
{
int total = 1;
for (int i = 1 ; i <= a ; i ++)
{
total *= i;
}
return total;
}
Ce qui permet d’illustrer que par exemple la factorielle de 5 est égale à 1*2*3*4*5. Relançons nos tests, ils passent tous. Parfait. Nous sommes donc certains que notre changement de code n’a pas altéré la fonctionnalité car les tests continuent de passer. On peut même rajouter des tests pour le plaisir, comme la factorielle de 10, histoire d’avoir quelque chose d’un peu plus grand :
valeur = 10;
resultat = Factorielle(valeur);
if (resultat != 3628800)
Console.WriteLine("Le test a raté");
Est-ce que cette méthode est optimisable ? Sûrement. Est-ce qu’il y a un risque à optimiser cette méthode ? Aucun ! En effet, nos tests nous garantissent que s’ils continuent à passer, alors une optimisation n’entraine pas de régression dans la fonctionnalité.
On sait par exemple qu'il y a un autre moyen pour calculer une factorielle. Par exemple, pour calculer la factorielle de 5, il suffit de multiplier 5 par la factorielle de 4. Pour calculer la factorielle de 4, il faut multiplier 4 par la factorielle de 3, et ainsi de suite jusqu'à arriver à 1... Bref, pour obtenir une factorielle on peut se servir du résultat de la factorielle du nombre précédent. Ce qui peut s’écrire :
public static int Factorielle(int a)
{
if (a <= 1)
return 1;
return a * Factorielle(a - 1);
}
Ici la méthode Factorielle est une méthode récursive, c’est-à-dire qu’elle s’appelle elle-même. Cela nous permet de d’indiquer que la factorielle d’un nombre correspond à ce nombre multiplié par la factorielle du nombre précédent. Bien sûr, il faut s’arrêter à un moment dans la récursion. On s’arrête ici quand on atteint le chiffre 1. Pour s’assurer que cette factorielle fonctionne bien, il suffit de relancer les tests. Tout est OK, c’est parfait ! :)
Voilà donc un exemple de TDD. Bien sûr, la méthode est ici poussée au maximum pour que vous compreniez l’intérêt de cette pratique. On peut gagner du temps en partant directement sur la bonne implémentation. Mais vous verrez qu’il y a toujours des premiers essais qui satisfont les tests mais qu’il sera possible d’améliorer régulièrement notre code. Ceci devient possible grâce aux tests qui nous assurent que tout continue à bien fonctionner. La pratique du TDD dépend de la façon dont le développeur appréhende sa philosophie de développement. Elle est présentée ici pour sensibiliser ce dernier à cette pratique mais son utilisation n’est pas du tout obligatoire. Voilà pour les tests basiques. Cependant, utiliser une application console pour faire ses tests, ce n’est pas très pratique, vous en conviendrez. Nous avons besoin d’outils !
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Un framework de test est aux tests ce que l’IDE est au développement. Il fournit un environnement structuré permettant l’exécution de test et des méthodes pour aider au développement de ceux-ci. Il existe plusieurs frameworks de test. Microsoft dispose de son framework, mstest, qui est disponible dans les versions payantes de Visual Studio. Son intérêt est qu’il est fortement intégré à l’IDE. Son défaut est qu’il ne fonctionne pas avec les versions gratuites de l’environnement de développement. Comme nous sommes partis dans ce tutoriel avec la version gratuite, Visual C# Express, nous n’allons pas pouvoir utiliser mstest.
Par contre, il existe d’autres framework de test, gratuits, comme le très connu NUnit. NUnit est la version .NET du framework XUnit, qui se décline pour plusieurs environnements, avec par exemple PHPUnit pour le langage PHP, JUnit, pour java, etc.
Première chose à faire, installer NUnit, pour cela, rendez-vous à cet emplacement pour le télécharger : http://www.NUnit.org/?p=download. La version que j’utilise dans ce tutoriel est la version 2.5.10.
Démarrez l’installation :
L’installation est en anglais, mais assez facile à suivre. Cliquez sur Next pour aller à l’écran suivant. Après avoir accepté la licence, vous pouvez choisir l’installation classique :
À la fin de l’installation, nous pouvons voir que tout s’est bien passé :
Une fois le framework de test installé, nous pouvons créer un nouveau projet qui contiendra une fonctionnalité à tester. Je l’appelle MaBibliothequeATester. D’une manière générale, nous allons surtout tester des assemblys avec NUnit. Ici, je crée donc un projet de type bibliothèque de classes. Ce projet ne sera donc pas exécutable, car il ne s’agit pas d’une application console. Et dedans, je vais pouvoir créer une classe utilitaire, disons Math, qui contiendra notre fameuse méthode de calcul de factoriel :
public static class Math
{
public static int Factorielle(int a)
{
if (a <= 1)
return 1;
return a * Factorielle(a - 1);
}
}
Puis ajoutons un nouveau projet de type bibliothèque de classes où nous allons mettre nos tests unitaires, appelons le MathTests.Unit. Ce n’est pas une norme absolue, mais je vous conseille de suffixer vos projets de test avec .Unit, ce qui permet de les identifier facilement.
Les tests doivent se mettre dans une classe spéciale. Ici aussi, pas de règle de nommage obligatoire, mais il est intéressant d’avoir une norme pour facilement s’y retrouver. Je vous propose de nommer les classes de tests en commençant par le nom de la classe que l’on doit tester, suivie du mot Tests. Ce qui donne : MathTests. Pour être reconnue par le framework de test, la classe doit respecter un certain nombre de contrainte. Elle doit dans un premier temps être décorée de l’attribut [TestFixture]. Il s’agit d’un attribut qui permet à NUnit de reconnaitre les classes qui contiennent des tests.
Cet attribut étant dans une assembly de NUnit, vous devez rajouter une référence à l’assembly NUnit.framework :
et inclure l’espace de nom adéquat :
using NUnit.Framework;
Nous allons pouvoir créer des méthodes à l’intérieur de cette classe. De la même façon, une méthode pourra être reconnue comme une méthode de test si elle est décorée de l’attribut [Test]. Ici aussi, il est intéressant de suivre une règle de nommage afin de pouvoir identifier rapidement l’intention de la méthode de test. Je vous propose le nommage suivant : MethodeTestee_EtatInitial_EtatAttendu()
Par exemple, une méthode de test permettant de tester la factorielle pourrait s’appeler :
[TestFixture]
public class MathTests
{
[Test]
public void Factorielle_AvecValeur3_Retourne6()
{
// test à faire
}
}
Il existe plein d’autres attributs que vous découvrirez ultérieurement. Il est temps de passer à l’écriture du test et surtout à la vérification du résultat. Pour cela, on utilise des méthodes de NUnit qui nous permette de vérifier par exemple qu’une valeur est égale à une autre attendue. Cela se fait grâce à la méthode Assert.AreEqual() :
[Test]
public void Factorielle_AvecValeur3_Retourne6()
{
int valeur = 3;
int resultat = MaBibliothequeATester.Math.Factorielle(valeur);
Assert.AreEqual(6, resultat);
}
Elle permet de vérifier que la variable valeur vaut bien 6. Rajoutons tant qu’on y est une méthode de test qui échoue :
[Test]
public void Factorielle_AvecValeur10_Retourne1()
{
int valeur = 10;
int resultat = MaBibliothequeATester.Math.Factorielle(valeur);
Assert.AreEqual(1, resultat, "La valeur doit être égale à 1");
}
J’en ai profité pour rajouter un message qui permettra d’indiquer des informations complémentaires si le test échoue. Compilons maintenant notre projet et rendez-vous dans le répertoire d’installation de NUnit (par défaut : C:\Program Files\NUnit 2.5.10\bin et-2.0) et lancez l’application NUnit.exe :
La première chose à faire est de créer un nouveau projet :
Appelez-le ProjetTest par exemple. Il faut ensuite ajouter une assembly de test, allez dans Project > Add Assembly :
Et allez pointer l’assembly de tests, à savoir MathTests.Unit.dll. NUnit analyse l’assembly et fait apparaitre la liste des tests qui composent notre assembly (en se basant sur les attributs TestFixture et Test) :
Nous pouvons à présent lancer les tests en cliquant sur Run, et nous obtenons :
Ce qui nous permet de voir rapidement qu’il y a un test qui passe (icône verte) et un test qui échoue (icône rouge). Forcément, notre test n’était pas bon, il faut le réécrire. Nous voyons également qu’il nous indique que le résultat attendu était 1 alors que le résultat obtenu est de 3628800. Nous pouvons également voir le message que nous avons demandé d’afficher en cas d’erreur. Le souci avec NUnit, c’est qu’à partir du moment où il a chargé la dll pour lancer les tests, il n’est plus possible de faire des modifications, car toute tentative de compilation provoquera une erreur où il sera mentionné qu’il ne peut pas faire de modifications car le fichier est déjà utilisé ailleurs. Ce qui est vrai. Ce qui va nous obliger à fermer NUnit et à le ré-ouvrir. À noter que dans les versions payantes de Visual Studio, nous avons la possibilité de configurer NUnit en tant qu’outil externe, ce que nous ne pouvons pas faire avec la version gratuite. Il va falloir faire avec… Tristesse de la gratuité… :'( Nous pouvons cependant un peu tricher en définissant un événement de post-compilation, qui consiste à lancer NUnit automatiquement. Pour cela, allez dans les propriétés du projet, onglet événement de builds et tapez la commande suivante : "C:\Program Files\NUnit 2.5.10\bin et-2.0\NUnit.exe" $(TargetFileName)
Ici, nous indiquons qu'après la compilation, il va lancer le programme NUnit.exe en prenant en paramètre le résultat de la compilation, représenté par la variable interne de Visual C# Express : $(TargetFileName).
Par contre, cela veut dire que NUnit va se lancer à chaque compilation, ce qui n’est peut-être pas le but recherché… Il faudra également fermer NUnit avant de pouvoir faire quoi que soit d’autre. À noter que maintenant que nous savons faire de l’introspection sur les méthodes et les attributs d’une classe, nous devrions être capables de créer une petite application qui exécute les tests automatiquement… Pour en finir avec NUnit, notons qu’il y a beaucoup de méthodes permettant de vérifier si un résultat est correct. Regardons les assertions suivantes :
bool b = true;
Assert.IsTrue(b);
string s = null;
Assert.IsNull(s);
int i = 10;
Assert.Greater(i, 6);
Elles parlent d’elles-mêmes. La première permet de vérifier qu’une condition est vraie. La deuxième permet de vérifier la nullité d’une variable. La dernière permet de vérifier que la variable est bien supérieure à une autre. À noter qu’elles ont chacune leur pendant (IsFalse, IsNotNull, Less). En regardant la complétion automatique, vous découvrirez d’autres méthodes de vérification, mais celles-ci sont globalement suffisantes. Nous pouvons également utiliser une syntaxe un peu plus parlante comme :
Assert.That(i, Is.EqualTo(10));
Mais cette syntaxe est peut-être un peu plus parlante aux anglophones… Il est également possible d’utiliser un attribut pour vérifier qu’une méthode lève bien une exception, par exemple :
[Test]
[ExpectedException(typeof(FormatException))]
public void ToInt32_AvecChaineNonNumerique_LeveUneException()
{
Convert.ToInt32("abc");
}
Dans ce cas, le test passe si la méthode lève bien une FormatException.
Avant de terminer, présentons deux attributs supplémentaires : les attributs SetUp et TearDown. Ils permettent de décorer des méthodes qui seront appelées respectivement avant chaque test et après chaque test. C'est l'endroit idéal pour factoriser des initialisations ou des nettoyages dont dépendent tous les tests.
[TestFixture]
public class MathTests
{
[SetUp]
public void InitialisationDesTests()
{
// rajouter les initialisations
}
[Test]
public void Factorielle_AvecValeur3_Retourne6()
{
// test à faire
}
[TearDown]
public void NettoyageDesTests()
{
// nettoyer les variables, ...
}
}
Il existe plein d’autres choses utiles à dire sur NUnit, comme la description des autres attributs, ce que je ne vais pas faire ici. N’hésitez pas à aller voir sur internet des informations plus poussées pour approfondir votre maitrise des tests.
Fatigué(e) de lire sur un écran ? Découvrez ce cours en livre.
Un framework de simulacre fournit un moyen de tester une méthode en l’isolant du reste du système. Imaginons par exemple une méthode qui permet de récupérer la météo du jour, en allant la lire dans une base de données. Nous avons ici un problème car lorsque nous exécutons le test le lundi, il pleut. Quand nous exécutons le test le mardi, il fait beau, etc. Nous avons une information qui varie au cours du temps. Il est donc difficile de tester automatiquement que la méthode arrive bien à construire la météo du jour à partir de ces informations, vu qu’elles varient. Le but de ces frameworks est de pouvoir bouchonner le code dont notre développement dépend afin de pouvoir le tester unitairement, sans dépendance et isolé du reste du système. Cela veut dire que dans notre test, nous allons remplacer la lecture en base de données par une fausse méthode qui renvoie toujours qu’il fait beau. Cependant, ceci doit se faire sans modifier notre application, sinon cela n’a pas d’intérêt. Voilà à quoi servent ces framework de simulacres. Il en existe plusieurs, plus ou moins complexe. Citons par exemple Moq (prononcez « moque-you ») ou encore Moles (il y en a plein d’autres). L’intérêt de Moq est qu’il est simple d’accès, nous allons le présenter rapidement. Il permet de faire des choses simples et facilement. Tandis que Moles est un peu plus évolué mais plus complexe à prendre en main. Vous y reviendrez sans doute ultérieurement. Pour le télécharger, rendez-vous sur : http://code.google.com/p/moq/downloads/list Pas de système d’installation évolué, il y aura juste une dll à référencer. Ajoutez donc la référence à la dll moq.dll qui se trouve dans le sous-répertoire NET40. Ensuite, pour pouvoir bouchonner facilement une classe, elle doit implémenter une interface. Imaginons la classe d’accès aux données suivante :
public class Dal : IDal
{
public Meteo ObtenirLaMeteoDuJour()
{
// ici, c'est le code pour lire en base de données
// mais finalement, peu importe ce qu'on y met vu qu'on va bouchonner la méthode
throw new NotImplementedException();
}
}
Qui implémente l’interface suivante :
public interface IDal
{
Meteo ObtenirLaMeteoDuJour();
}
Avec l’objet Meteo suivant :
public class Meteo
{
public double Temperature { get; set; }
public Temps Temps { get; set; }
}
Et l’énumération Temps suivante :
public enum Temps
{
Soleil,
Pluie
}
Nous pourrons écrire un test qui bouchonne l’appel à la méthode ObtenirLaMeteoDuJour, qui doit normalement aller lire en base de données, pour renvoyer un objet à la place. Pour bien montrer ce fonctionnement, j’ai fait en sorte que la méthode lève une exception, comme ça, si on passe dedans ça sera tout de suite visible. La méthode de test classique devrait être :
[Test]
public void ObtenirLaMeteoDuJour_AvecUnBouchon_RetourneSoleil()
{
IDal dal = new Dal();
Meteo meteoDuJour = dal.ObtenirLaMeteoDuJour();
Assert.AreEqual(25, meteoDuJour.Temperature);
Assert.AreEqual(Temps.Soleil, meteoDuJour.Temps);
}
Si nous exécutons le test, nous aurons une exception. Utilisons maintenant Moq pour bouchonner cet appel et le remplacer par ce que l’on veut :
[Test]
public void ObtenirLaMeteoDuJour_AvecUnBouchon_RetourneSoleil()
{
Meteo fausseMeteo = new Meteo { Temperature = 25, Temps = Temps.Soleil };
Mock<IDal> mock = new Mock<IDal>();
mock.Setup(dal => dal.ObtenirLaMeteoDuJour()).Returns(fausseMeteo);
IDal fausseDal = mock.Object;
Meteo meteoDuJour = fausseDal.ObtenirLaMeteoDuJour();
Assert.AreEqual(25, meteoDuJour.Temperature);
Assert.AreEqual(Temps.Soleil, meteoDuJour.Temps);
}
On utilise l’objet générique Mock pour créer un faux objet du type de notre interface. On utilise la méthode Setup à travers une expression lambda pour indiquer que la méthode ObtenirLaMeteoDuJour retournera en fait un faux objet météo. Cela se fait tout naturellement en utilisant la méthode Returns(). L’avantage de ces constructions est que la syntaxe claire parle d’elle-même à partir du moment où on connait les expressions lambdas. On obtient ensuite une instance de notre objet grâce à la propriété Object et c’est ce faux objet que nous pourrons comparer à nos valeurs. Bien sûr, ici, ce test n’a pas grand intérêt. Mais il faut le voir à un niveau plus général. Imaginons que nous ayons besoin de tester la fonctionnalité qui met en forme cet objet météo récupéré de la base de données ou bien l’algorithme qui nous permet de faire des statistiques sur ces données météos… Là, nous sommes sûrs de pouvoir nous baser sur une valeur connue de la dépendance à la base de données. Cela permettra également de décliner tous les cas possibles en changeant la valeur du bouchon et de faire les tests les plus exhaustifs possibles. Nous pouvons faire la même chose avec les propriétés. Imaginons la classe suivante dont la propriété valeur retourne un nombre aléatoire :
public interface IGenerateur
{
int Valeur { get; }
}
public class Generateur : IGenerateur
{
private Random r;
public Generateur()
{
r = new Random();
}
public int Valeur
{
get
{
return r.Next(0, 100);
}
}
}
Nous pourrions avoir besoin de bouchonner cette propriété pour qu’elle renvoie un nombre connu à l’avance. Cela se fera de la même façon :
Mock<IGenerateur> mock = new Mock<IGenerateur>();
mock.Setup(generateur => generateur.Valeur).Returns(5);
Assert.AreEqual(5, mock.Object.Valeur);
Ici, la propriété Valeur renverra toujours 5 en se moquant bien du générateur de nombre aléatoire… Je m’arrête là pour l’aperçu de ce framework de simulacre. Nous avons pu voir qu’il pouvait facilement bouchonner des dépendances nous permettant de faciliter la mise en place de nos tests unitaires. Rappelez-vous, pour qu’un test soit efficace, il doit pouvoir se concentrer sur un point précis du code sans être embêté par les dépendances éventuelles qui peuvent perturber l’état du test à un instant t.
En résumé
Les tests unitaires sont un moyen efficace de tester des bouts de code dans une application afin de garantir son bon fonctionnement.
Ils sont un filet de sécurité permettant de faire des opérations de maintenance, de refactoring ou d'optimisation sur le code.
Les frameworks de tests unitaires sont en général accompagnés d'outils permettant de superviser le bon déroulement des tests et la couverture de tests.
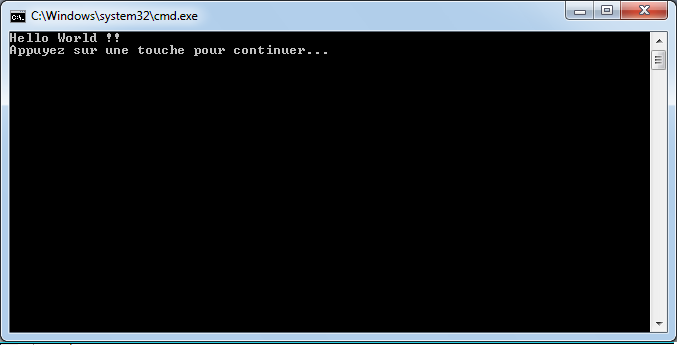
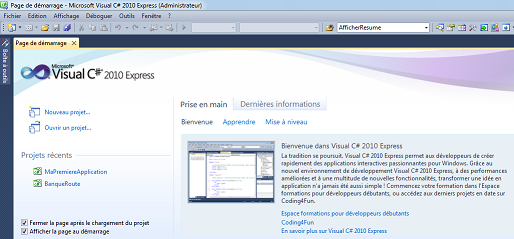
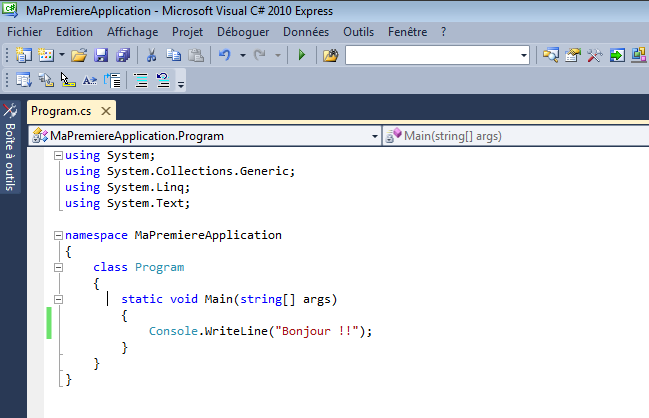
 Ce cours vous plaît ?
Ce cours vous plaît ?