Dans son tutoriel, lexou présente un nouveau type de structure de données: les listes chainées. En lisant son tutoriel, vous êtes alors capables de vous fabriquer votre propre petit module vous permettant de manipuler vos listes chainées. Seulement, son tutoriel ne fait uniquement objet des listes simplement chainées. lexou vous parle alors dans sa conclusion des listes doublement chainées.
Dans la continuité du tutoriel de lexou, je vous propose d'apprendre à manier les listes dites doublement chainées. A la fin de ce tutoriel, vous devriez être capables de mettre en place votre propre module de manipulation des listes doublement chainées. Il est aussi à noter qu'à la fin de ce tutoriel, nous aurons l'occasion d'étudier un cas d'utilisation de nos listes doublement chainées.
Afin de suivre et de comprendre pleinement les notions évoquées par ce tutoriel, je vous recommande la lecture du tutoriel de lexou ci-dessus. Il est aussi bien entendu évident qu'une lecture du tutoriel de M@teo jusqu'aux pointeurs et l'allocation dynamique est obligatoire.
Vous voilà avertis. Commençons sans plus attendre.
Avant de commencer à programmer quoi que ce soit, nous nous devons de voir la théorie concernant les listes doublements chainées. Tout d'abord, faisons quelques rappels.
Les listes chainées se présentent comme une alternative aux tableaux pour le stockage de certaines données. En effet, dans certaines situations, l'usage des tableaux peut se révéler inefficace.
Pourquoi les tableaux ne suffisent t-ils pas ?
Vous devriez savoir que lorsque vous créez un tableau, vous connaissez sa taille à l'avance, que ce soit avec l'utilisation ou non de malloc. Ainsi, vous vous retrouvez limités par la taille de votre tableau. Il est cependant possible à tout moment d'agrandir un tableau, mais ceci n'est pas la meilleur solution envisageable. Pour pallier à cette limitation, nous allons donc utiliser des listes chainées. Alors que les éléments d'un tableau sont contigües en mémoire, les éléments d'une liste chainées sont quant à eux tous reliés via une série de pointeurs. Ainsi, lorsque chaque élément d'une liste chainée pointe vers l'élément suivant, nous parlons de liste simplement chainée. Lorsque chaque élément d'une liste pointe à la fois vers l'élément suivant et précédent, nous parlons alors de liste doublement chainée. Retenez donc qu'une liste chainée nous permet de stoquer un nombre inconnu d'éléments.
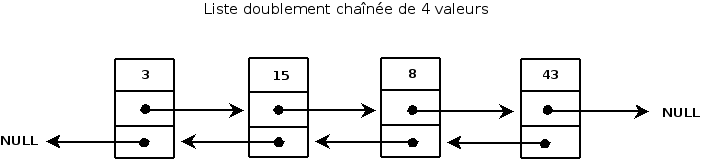
Voici une représentation schématique des listes doublement chainées:
Vous pouvez donc voir sur ce schéma que chaque élément d'une liste doublement chainée contient :
Une donnée (ici un simple entier)
Un pointeur vers l'élément suivant (NULL si l'élément suivant n'existe pas)
Un pointeur vers l'élément précédent (NULL si l'élément précédent n'existe pas)
Passons maintenant à la représentation de ces listes en langage C.
Qu'allons nous utiliser pour nous représenter ces listes en langage C. La réponse est toute simple. Nous allons tout simplement utiliser une structure. En effet, en langage C, les structures sont très pratiques pour créer de nouveaux types de données. Pour être plus précis, nous allons utiliser exactement deux structures. Voici la première :
Cette première structure va nous permettre de représenter un 'node' (élément) de notre liste chaînée. Nous pouvons alors voir que chaque élément de notre liste contiendra un élément de type int. D'autre part :
p_next pointera vers l'élément suivant (ou NULL s'il s'agit du dernier élément de la liste)
p_prev pointera vers l'élément précédent (ou NULL s'il s'agit du premier élément)
Les liens entre les différents éléments de notre liste chaînée sont donc assurés par nos deux pointeurs p_next et p_prev.
Pour représenter notre liste chaînée à proprement parler, nous utiliserons une deuxième liste que voici :
Attends attends, c'est quoi ça size_t ? Et ça veut dire quoi p_tail et p_head ?
Tout d'abord, nous utilisons une variable nommée length contenant la taille de notre liste chaînée (length = taille en anglais). Grâce à cette variable, nous aurons accès au nombre d'éléments de notre liste chaînée. Cependant, cette variable peut paraître un peu particulière puisqu'elle est de type size_t. Ce fameux size_t correspond à un entier non signé c'est à dire un entier positif (ça tombe bien car notre liste chaînée ne pourra pas contenir -1 élément). Ce type est de ce fait communément utilisé pour tout ce qui concerne les tailles (taille d'un tableau, ...). Enfin, éclaircissons ce fameux p_tail et p_head, à quoi vont-ils bien nous servir ? Ceci est tout simple. p_head va pointer vers le premier élément de notre liste alors que p_tail va pointer vers le dernier élément. Ainsi, nous garderons de manière permanente un pointeur vers le début et la fin de la liste.
Ok, mais à quoi ça va nous servir ?
Et bien cela va tout simplement servir à faciliter les différentes opérations que nous effectuerons sur nos listes. En effet, pour exemple, lorsque nous souhaiterons ajouter un élément en fin de liste, nous n'aurons pas besoin de parcourir la liste dans sa totalité pour ajouter l'élément en fin car nous disposerons directement d'une référence vers la fin de liste ;) . Enfin, afin de faciliter l'écriture, nous créons un alias de notre structure grâce à l'opérateur typedef. Nous appelons cet alias Dlist pour Double List. Pour utiliser une liste dans nos programmes nous utiliserons alors :
Dlist *list = NULL; /* Déclaration d'une liste vide */
Voilà, vous savez maintenant comment est définie une liste doublement chaînée en langage C. Voyons maintenant comment la manipuler.
Nous savons désormais comment déclarer une liste doublement chaînée en langage C. Nous allons maintenant créer des fonctions nous permettant de réaliser plusieurs opérations sur ces fameuses listes.
Commençons alors par notre première fonction.
Allouer une nouvelle liste
Avant de pouvoir commencer à utiliser notre liste chaînée, nous allons créer une fonction nous permettant d'allouer de l'espace mémoire pour notre liste chaînée. La fonction retournera la liste chaînée nouvellement créée. Voici cette fameuse fonction
Comment fonctionne cette fonction ? Je pense que vous l'aurez deviné sans trop de problèmes. Tout d'abord, nous créons une variable p_new qui sera notre nouvelle liste. Nous utilisons alors malloc pour réserver de l'espace mémoire pour cette liste.
Ensuite et de manière générale, il est nécessaire de vérifier si notre malloc n'a pas échoué. En effet, si celui-ci renvoie NULL, et que nous essayons d'accéder aux éléments de notre structure Dlist, c'est le drame :D . Enfin, nous mettons nos pointeurs p_head ainsi que p_tail à NULL (vu que notre liste est vide), puis nous initialisons la taille de notre liste à 0 et nous retournons notre nouvelle liste.
Ajouter un élément
Après avoir alloué une nouvelle liste chaînée, voyons maintenant comment ajouter un élément dans celle-ci.
Ajout en fin de liste
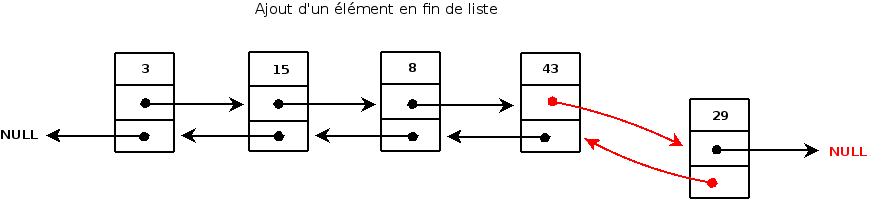
Grâce à la forme de notre structure, l'ajout en fin de liste va être simplifié. En effet, rappelez-vous, nous gardons toujours un pointeur vers la fin de notre liste, nous n'avons donc nul besoin de parcourir la liste en entier afin d'arriver au dernier élément, nous l'avons déjà. Voici comment va se passer l'ajout en fin de liste:
A partir de ce schéma, essayons d'en déduire un algorithme. Tout d'abord, nous devons vérifier si notre liste n'est pas NULL. Si elle ne l'est pas, nous allons créer un nouvel élément (nouveau node). Une fois celui-ci créé, nous devons stoquer notre donnée dans le champ donnée (data) de notre structure puis faire pointer p_next vers NULL car ce sera le dernier élément de notre liste. A partir de là, deux possibilités s'offrent à nous :
S'il n'existe pas de dernier élément (donc la liste est vide) Alors
Nous faisons pointer p_prev vers NULL
Nous faisons pointer la tête et la fin de liste vers notre nouvel élément
Sinon
Nous rattachons le dernier élément de notre liste à notre nouvel élément (début du chaînage)
Nous faisons pointer p_prev vers le dernier élément de notre liste
Nous faisons pointer notre fin de liste vers notre nouvel élément (fin du chaînage)
Enfin, nous incrémentons notre champ length de notre liste puis nous retournons la liste. Tout ceci constitue alors l'algorithme d'ajout en fin de liste. Essayez tout d'abord de le coder par vous même, cela sera bénéfique pour vous et vous aidera à comprendre le concept. Si vous bloquez, munissez vous d'une feuille et d'une crayon et essayez de représenter toutes les étapes sur votre feuille. Ensuite, réessayez de coder l'algorithme. Voici l'implémentation :
Dlist *dlist_append(Dlist *p_list, int data)
{
if (p_list != NULL) /* On vérifie si notre liste a été allouée */
{
struct node *p_new = malloc(sizeof *p_new); /* Création d'un nouveau node */
if (p_new != NULL) /* On vérifie si le malloc n'a pas échoué */
{
p_new->data = data; /* On 'enregistre' notre donnée */
p_new->p_next = NULL; /* On fait pointer p_next vers NULL */
if (p_list->p_tail == NULL) /* Cas où notre liste est vide (pointeur vers fin de liste à NULL) */
{
p_new->p_prev = NULL; /* On fait pointer p_prev vers NULL */
p_list->p_head = p_new; /* On fait pointer la tête de liste vers le nouvel élément */
p_list->p_tail = p_new; /* On fait pointer la fin de liste vers le nouvel élément */
}
else /* Cas où des éléments sont déjà présents dans notre liste */
{
p_list->p_tail->p_next = p_new; /* On relie le dernier élément de la liste vers notre nouvel élément (début du chaînage) */
p_new->p_prev = p_list->p_tail; /* On fait pointer p_prev vers le dernier élément de la liste */
p_list->p_tail = p_new; /* On fait pointer la fin de liste vers notre nouvel élément (fin du chaînage: 3 étapes) */
}
p_list->length++; /* Incrémentation de la taille de la liste */
}
}
return p_list; /* on retourne notre nouvelle liste */
}
Le code ci-dessus est entièrement commenté, il ne sera donc pas nécessaire d'ajouter de commentaires. N'hésitez pas à relire ce morceau de code. Si vous avez des difficultés à le comprendre, jouez le rôle du compilateur et imaginez vous le déroulement de chaque instruction ;) .
Ajout en début de liste
Pour ajouter un élément en début de liste, nous allons utiliser exactement le même procédé que pour l'ajout en fin de liste. Et oui, grâce à nos pointeurs en début et en fin de liste, nous pouvons nous permettre de reprendre nos implémentations. Si vous avez bien compris comment se passait l'ajout en fin de liste, vous n'aurez aucun de mal à réaliser l'ajout en début de liste. Là aussi, essayez d'abord par vous même de programmer cet algorithme.
Il y a comme des ressemblances entre les deux fonctions vous ne trouvez pas :D .
Insérer un élément
Nous disposons désormais de fonctions permettant d'ajouter un élément en début ainsi qu'en fin de liste. Mais si l'on désire ajouter un élément nimporte où dans notre liste ? Et bien nous allons justement créer une fonction pour ceci. Comment allons-nous procéder ? Posons-nous et réfléchissons cinq minutes. Tout d'abord, nous aurons besoin de parcourir notre liste. Nous aurons aussi besoin d'un compteur (que l'on nommera) i afin de nous arrêter à la position où nous souhaitons insérer notre nouvel élément. Jusqu'ici, rien de bien sorcier. Il nous faut alors réfléchir des différents cas de figure qui peuvent intervenir lorsque nous aurons trouvé notre position:
Soit nous sommes en fin de liste
Soit nous sommes en début de liste
Soit nous sommes en milieu de liste
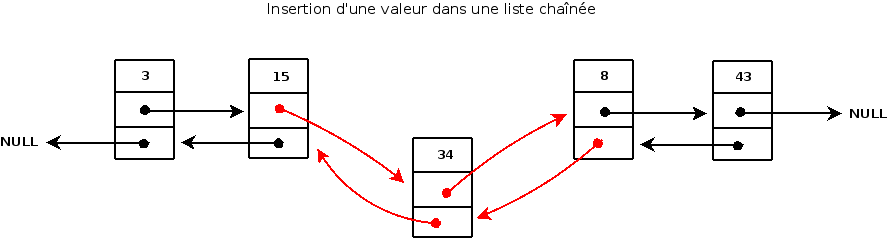
Cependant, les deux premiers cas sont très faciles à traîter. Enfin, nous disposons de fonctions permettant d'ajouter un élément en début et en fin de liste, il nous suffit donc de les réaliser. Le plus gros de notre travail sera alors de gérer le cas où nous nous trouvons en milieu de liste. Voici un petit schéma permettant de mieux cerner la situation:
Le chaînage va être légèrement plus compliqué. En effet, nous devrons tout d'abord relier nos éléments suivant et précédent à notre nouvel élément puis, inversement, nous devrons relier notre nouvel élément aux éléments suivant et précédent. Le chaînage va alors se dérouler en 4 étapes. A noter qu'il sera nécessaire d'avoir préalablement créé un nouvel élément sans quoi le chaînage ne pourra pas avoir lieu. Pour parcourir notre liste, nous récupérerons le pointeur vers notre début de liste dans un pointeur temporaire. C'est ce pointeur temporaire qui nous servira à parcourir notre liste. Schématiquement, notre liste sera parcourue de gauche à droite. Notre compteur sera bien évidemment incrémenté lors du parcours de chaque maillon de la liste.
Voici ce que cela donne:
Dlist *dlist_insert(Dlist *p_list, int data, int position)
{
if (p_list != NULL)
{
struct node *p_temp = p_list->p_head;
int i = 1;
while (p_temp != NULL && i <= position)
{
if (position == i)
{
if (p_temp->p_next == NULL)
{
p_list = dlist_append(p_list, data);
}
else if (p_temp->p_prev == NULL)
{
p_list = dlist_prepend(p_list, data);
}
else
{
struct node *p_new = malloc(sizeof *p_new);;
if (p_new != NULL)
{
p_new->data = data;
p_temp->p_next->p_prev = p_new;
p_temp->p_prev->p_next = p_new;
p_new->p_prev = p_temp->p_prev;
p_new->p_next = p_temp;
p_list->length++;
}
}
}
else
{
p_temp = p_temp->p_next;
}
i++;
}
}
return p_list;
}
Si vous avez compris les codes précédemment établis, je ne pense pas que vous aurez des difficultés à comprendre celui-ci. Cependant, voici quelques explications supplémentaires: pour notre parcours de liste, nous utilisons un pointeur nommé p_temp. Au tout début, celui-ci pointe vers le premier élément de notre liste (p_list->p_head). Pour parcourir notre liste, nous utilisons une structure de type while. Tant que nous n'avons pas atteint la fin de liste (p_temp != NULL) et tant que nous ne sommes pas à la position où nous voulons insérer notre élément (position <= i), nous bouclons. Dès lors que nous avons atteint notre position (position == i), nous devons alors effectuer nos trois tests :
Si nous sommes en fin de liste (p_temp->p_next == NULL), nous utilisons notre fonction dlist_append
Sinon, si nous sommes en début de liste (p_temp->p_prev == NULL), nous utilisons notre fonction dlist_prepend
Sinon, nous devons créer un nouvel élément et réaliser notre chaînage sans oublier de stoquer la donnée dans notre champ data
Logiquement, grâce au schéma précédent et aux explications fournies, vous ne devriez pas avoir de mal à comprendre le chaînage. Enfin, si nous n'avons pas encore atteint notre position, nous passons à l'élément suivant (p_temp = p_temp->p_next).
Libérer une liste
Après avoir utilisé notre liste, nous nous devons de libérer tous nos éléments alloués par nos fonctions sous peine d'obtenir ce que l'on nomme des fuites de mémoire (leak memory). Pour accomplir ceci, rien de plus facile. Regardons le code:
Dans ce code, nous pouvons remarquer qu'une petite chose change par rapport à nos codes précédents. Dans cette fonction, nous utilisons un double pointeur. En effet, notre fonction delete doit directement effectuer les modifications sur notre liste. Autrement dit, celle-ci doit faire des modifications sur un objet de type Dlist *. C'est pour cela que nous ne devons pas disposer d'un pointeur simple, mais bel et bien d'un pointeur double. En premier lieu, nous vérifions si la liste que nous avons récupérée n'est pas NULL. Si celle-ci venait à être NULL et que nous essayions de la manipuler, nous aboutirions à un beau plantage. Nous parcourons ensuite chaque élément de la liste comme dans notre fonction précédente (à noter la présence de parenthèses afin de résoudre la priorité de l'opérateur -> sur l'opérateur *). Seulement, nous prenons garde de sauvegarder l'élément courant dans un pointeur p_del (qui sera comme vous l'aurez compris l'élément que nous supprimerons). En effet, si nous n'utilisons pas de pointeur intermédiaire, lorsque nous supprimerons notre premier élément, p_temp->p_next n'existera plus puisque notre élément aura été supprimé, nous aurons donc un beau plantage. C'est pour cela que nous sauvegardons d'abord notre élément courant, puis nous passons à l'élément suivant et enfin nous supprimons notre élément courant (p_del). Quand tous les éléments sont supprimés, nous terminons par supprimer notre liste puis nous la remettons à NULL.
Exercice
Passons maintenant à un petit exercice afin de mettre en œuvre vos connaissances. Ecrivez une fonction dlist_display prenant en paramètre une liste et affichant tous les éléments de la liste séparés par des '>'. Lorsque la fin de liste sera atteinte, NULL sera affiché. Exemple :
Comme vous pouvez le voir, ceci n'a rien de sorcier. Il suffit tout simplement de parcourir la liste entièrement puis d'afficher les éléments un à un. Lorsque la boucle est terminée, nous terminons par afficher "NULL".
Dans la partie précédente, nous avons réalisé quelques fonctions basiques de manipulation de listes chainées. Nous bénéficions désormais de fonctions d'allocation, ajout, insertion ainsi que de libération de liste. Nous allons alors compléter notre petite bibliothèque en créant des fonctions supplémentaires. Nous allons tout d'abord nous occuper de fonctions de suppression.
Supprimer un élément d'une liste
Supprimer un élément selon sa valeur
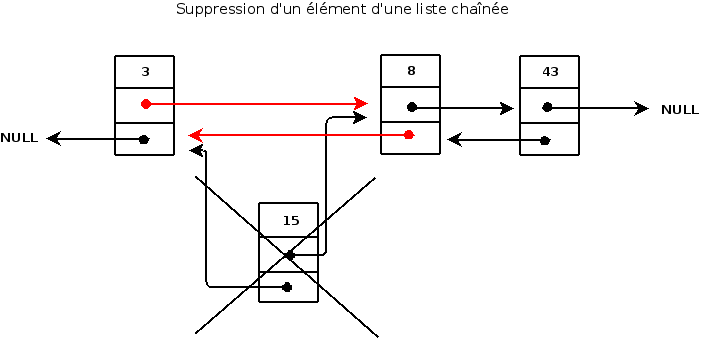
Nous allons tout d'abord voir la manière de supprimer un élément en fonction de sa valeur. A nouveau, voici un schéma pour vous aider à mieux visualiser le procédé:
Ici, nous décidons de supprimer l'élément portant la valeur 15. Comment allons-nous nous y prendre ? Tout d'abord, comme vous pourrez l'imaginer, il va nous falloir parcourir notre liste à la rechercher de notre élément à supprimer. Dès que l'on aura trouver la valeur correspondante, trois possibilités s'offreront à nous:
l'élément se trouve en fin de liste
l'élément se trouve en début de liste
l'élément se trouve en milieu de liste
Si l'élément se trouve en fin de liste, Alors il faudra faire pointer notre p_tail vers l'avant dernier élément et faire pointer le pointeur vers l'élément suivant de l'avant dernier élément vers NULL. Sinon, si l'élément se trouve en début de liste, Alors il faudra faire pointer notre p_head vers le second élément et faire pointer le pointeur vers l'élément précédent du second élément vers NULL. Sinon, il faudra relier l'élément précédent à l'élément que l'on veut supprimer vers l'élément suivant à l'élément que l'on veut supprimer et il faudra aussi relier l'élément suivant à l'élément su l'on veut supprimer vers l'élément précédent à l'élément que l'on veut supprimer. Une fois ceci fait, il ne nous restera plus qu'à supprimer notre élément trouver et à décrémenter la taille de notre liste. Tout ceci constitue notre algorithme. A sa lecture, celui-ci peut sembler rebutant mais lors de la réalisation en langage C, il vous deviendra beaucoup plus clair ;) . Avec ces explications, vous devriez être capable de réaliser le code tout seul.
Dlist *dlist_remove(Dlist *p_list, int data)
{
if (p_list != NULL)
{
struct node *p_temp = p_list->p_head;
int found = 0;
while (p_temp != NULL && !found)
{
if (p_temp->data == data)
{
if (p_temp->p_next == NULL)
{
p_list->p_tail = p_temp->p_prev;
p_list->p_tail->p_next = NULL;
}
else if (p_temp->p_prev == NULL)
{
p_list->p_head = p_temp->p_next;
p_list->p_head->p_prev = NULL;
}
else
{
p_temp->p_next->p_prev = p_temp->p_prev;
p_temp->p_prev->p_next = p_temp->p_next;
}
free(p_temp);
p_list->length--;
found = 1;
}
else
{
p_temp = p_temp->p_next;
}
}
}
return p_list;
}
Vous voyez donc que traduit en langage C, l'algorithme devient plus intuitif ;) . A noter cependant que nous utilisons une variable supplémentaire nommée found pour nous arrêter au premier élément trouvé. Lorsque l'élément est trouvé, cette variable change d'état et prend la valeur 1, marquant ainsi l'arrêt de la boucle de parcours.
Supprimer un ensemble d'éléments suivant une même valeur
L'algorithme précédent ne nous permettait de supprimer uniquement le premier élément trouvé. Nous allons maintenant écrire un code supprimant toutes les valeurs trouvées dans la liste. Et devinez quoi ? Et bien comme vous pouvez vous en douter, il s'agit exactement du même code que précédemment, mis à part le fait qu'ici nous n'utilisons plus de variable found, mais nous parcourons notre liste dans sa totalité.
Passons maintenant à la dernière fonction de suppression. Nous allons créer une fonction permettant de supprimer le n-ème élément d'une liste doublement chaînée. Comment procéder ? Et bien il s'agit exactement du même procédé utilisé précédemment, mis à part le fait que nous aurons besoin d'une variable supplémentaire nous permettant de stoquer la position à laquelle nous nous trouvons. Et comme par hasard, nous allons nommer cette variable i :D . Au vu de ce que nous avons réalisé précédemment, vous devriez parvenir à écrire ce bout de code par vous même. Essayez et persévérez ;) .
Voici la dite fonction:
Dlist *dlist_remove_id(Dlist *p_list, int position)
{
if (p_list != NULL)
{
struct node *p_temp = p_list->p_head;
int i = 1;
while (p_temp != NULL && i <= position)
{
if (position == i)
{
if (p_temp->p_next == NULL)
{
p_list->p_tail = p_temp->p_prev;
p_list->p_tail->p_next = NULL;
}
else if (p_temp->p_prev == NULL)
{
p_list->p_head = p_temp->p_next;
p_list->p_head->p_prev = NULL;
}
else
{
p_temp->p_next->p_prev = p_temp->p_prev;
p_temp->p_prev->p_next = p_temp->p_next;
}
free(p_temp);
p_list->length--;
}
else
{
p_temp = p_temp->p_next;
}
i++;
}
}
return p_list;
}
Comme vous le voyez, tant que nous n'avons pas atteint la fin de liste, et tant que nous ne sommes pas à la bonne position, nous bouclons et nous incrémentons notre variable i. Lorsque nous avons trouvé la bonne place (position == i), nous supprimons alors notre élément courant en suivant exactement la même méthode que précédemment.
Avoir la taille d'une liste chaînée
Voyons maintenant comment obtenir la taille de notre liste chaînée. Rien de plus facile, allez-vous me dire, nous disposons déjà d'un champ length dans notre structure, nous allons donc l'utiliser. La réponse est évidente, néanmoins, il faudra au préalable vérifier si notre liste n'est pas nulle. En effet, si tel est le cas et que nous essayons d'accéder au champ length, alors nous aboutirons à une belle erreur de Segmentation. Prenez donc garde à vérifier la validité de la liste.
Voici la fonction
size_t dlist_length(Dlist *p_list)
{
size_t ret = 0;
if (p_list != NULL)
{
ret = p_list->length;
}
return ret;
}
Je ne pense pas que ce code nécessite une explication supplémentaire, vous devriez aisément le comprendre ;) (nous utilisons juste une variable ret de type size_t pour retourner le résultat. Par défaut, nous renvoyons 0 si la liste n'existe pas).
Rechercher un élément
Recherche un élément selon sa valeur
Pour compléter notre petite bibliothèque, il se peut que nous ayons besoin d'une fonction de recherche. Cette fonction de recherche sera un tout petit peu particulière. En effet, celle-ci ne renverra pas l'élément qu'elle aura trouvé mais une liste contenant l'élément qu'elle aura trouvé. Ceci facilitera de ce fait notre gestion. Comment faire ? Vous vous souvenez de la fonction de suppression ? Et bien nous allons utiliser le même style. Nous allons parcourir notre liste tant que nous n'aurons pas trouvé notre élément (variable found). Si nous trouvons notre élément, nous utilisons alors les fonctions déjà à notre disposition (dlist_new et dlist_append) pour créer notre liste qui sera retourné.
Dlist *dlist_find(Dlist *p_list, int data)
{
Dlist *ret = NULL;
if (p_list != NULL)
{
struct node *p_temp = p_list->p_head;
int found = 0;
while (p_temp != NULL && !found)
{
if (p_temp->data == data)
{
ret = dlist_new();
ret = dlist_append(ret, data);
found = 1;
}
else
{
p_temp = p_temp->p_next;
}
}
}
return ret;
}
Désormais, cette fonction doit vous paraître anodine ;) . Si jamais nous ne trouvons aucun élément correspondant à une valeur donnée, nous retournons alors une liste nulle.
Recherche un ensemble d'éléments selon une même valeur
Pour compléter notre fonction de recherche, nous allons maintenant créer une fonction qui non pas s'arrête au premier élément trouvé, mais qui retourne tous les éléments trouvés. Et devinez quoi ? Et bien oui, il s'agit exactement du même code que précédemment, mais cette fois ci, sans l'utilisation de la variable found. Ainsi, toute la liste est parcourue:
Dlist *dlist_find_all(Dlist *p_list, int data)
{
Dlist *ret = NULL;
if (p_list != NULL)
{
struct node *p_temp = p_list->p_head;
while (p_temp != NULL)
{
if (p_temp->data == data)
{
if (ret == NULL)
{
ret = dlist_new();
}
ret = dlist_append(ret, data);
}
p_temp = p_temp->p_next;
}
}
return ret;
}
Bon, je vous l'accorde, il y a quand même une toute petite différence avec l'autre code. En effet, nous ne pouvons pas créer notre liste de retour à chaque fois que nous trouvons un élément. Il faut alors la créer dès lorsque l'on aura trouvé notre élément. Ensuite, nous nous contenterons d'ajouter tous les autres éléments trouvés, d'où l'intêrèt du
if (ret == NULL)
Voilà, dûr hein :D .
Et bien voilà, nous en avons maintenant terminé avec nos fonctions de manipulation de listes chaînées. Passons maintenant à un petit exercice pour vérifier vos acquis.
Exercice
Le but de cet exercice est de créer une fonction dlist_reverse permettant "d'inverser" une liste chaînée. Tous les éléments doivent alors être inversés un par un (le premier doit se retrouver dernier, le deuxième avant-dernier, ...). De plus, notre structure de liste nous donne une flexibilité incroyable car nous pouvons de choisir de partir soit en début de liste, soit en fin. Mais j'en ai déjà trop dit, à vous de jouer.
Correction:
Dlist *dlist_reverse(Dlist *p_list)
{
Dlist *ret = NULL;
if (p_list != NULL)
{
struct node *p_temp = p_list->p_tail;
ret = dlist_new();
while (p_temp != NULL)
{
ret = dlist_append(ret, p_temp->data);
p_temp = p_temp->p_prev;
}
}
return ret;
}
Comme vous le voyez, j'ai choisi de partir en fin de liste puis d'ajouter en début de liste. Mais l'inverse est aussi tout à fait envisageable ;) .
La pratique est tout aussi importante si ce n'est plus que l'aspect théorique d'un concept. La pratique permet alors de s'exercer sur un concept récemment abordé et d'apprendre à résoudre par soi-même un problème grâce à ce nouveau concept.
C'est pourquoi j'ai choisi de créer un second tutoriel sur le sujet qui vous présentera un aspect pratique des listes chaînées. Ce tutoriel est basé sur un petit TP fabriqué de toute pièce par moi-même. Vous serez alors guidés vers une résolution d'un problème donné. Si vous ne parvenez pas à le résoudre, une correction avec des explications vous sera présentée.
Et bien voilà, ce tutoriel est désormais terminé. Comme vous avez pu le constater, les listes chainées sont parfois très utiles, notamment lorsque l'on travaille sur des données dont nous ne connaissons le nombre à l'avance. Si cela vous intéresse, vous pouvez alors regarder la documentation dédiée aux listes doublement chainées implémentées par la Glib, une bibliothèque Gnome ;) .