Vous souhaitez manipuler dans vos programmes en C de très grands nombres et/ou des nombres à virgule ? Ou alors vous avez déjà essayé mais vous rencontrez des problèmes incompréhensibles ? Ce cours vous est destiné ! Vous y apprendrez tout ce qu'il faut savoir sur les nombres à virgule en C.
Au programme :
quelques rappels (ou pas) sur les nombres à virgule en C (types, syntaxe…) ;
la représentation en mémoire d'un nombre à virgule dite « flottante » (selon la norme IEEE 754), et les propriétés qui en découlent (valeurs possibles, etc.) ;
les inconvénients des nombres à virgule flottante en C ;
effectuer une comparaison de nombres flottants ;
le point de vue de la norme C, et les implémentations.
Prérequis :
connaître un minimum le langage C ! Au moins jusqu'au chapitre sur les pointeurs (chapitre 2 de la partie II) du tutoriel de M@teo21 si vous le suivez ;
avoir quelques notions mathématiques (rien de bien méchant) sur les puissances (de 10 et de 2, dans notre cas), et idéalement les bases numériques (mais ce n'est pas indispensable) ;
maîtriser les notions de bit, d'octet, de binaire, etc., ainsi que les deux façons principales de représenter un nombre relatif en mémoire (le bit de signe ou le complément à 2) ; si ce n'est pas le cas, vous pouvez lire ce tutoriel sur le « vrai visage des variables » en mémoire ;
ce tutoriel-ci, à la fois clair et complet, vous introduit toutes les notions listées ci-dessus, et je vous invite à le lire s'il vous manque quelque chose (arrêtez-vous après avoir lu la partie sur les nombres entiers, la suite gâcherait mon suspense) ;
Tout d'abord, une présentation des nombres à virgule flottante !
Bon, je ne vais pas vous expliquer ce qu'est un nombre à virgule. Si vous ne savez pas ce que c'est, ce tutoriel ne vous sera d'aucune utilité. :lol: On parle de virgule flottante car on peut faire varier la place de la virgule en variant la puissance de 10 (puisque tout nombre peut être écrit avec une puissance de 10). Par exemple : 42,1337 = 42,1337 ×100 = 0,421337 ×102 = 42133,7 ×10-3.
En informatique, on parle de virgule flottante par opposition à virgule fixe, qui indique une méthode de représentation en mémoire d'un nombre avec un nombre fixe de chiffres après la virgule. En C, nous avons des nombres à virgule flottante.
Remarque : On parle de la partie entière pour désigner la partie qui se trouve avant la virgule, et de partie décimale (ou fractionnaire) pour celle qui se trouve après. Je pourrai également parler de la notation scientifique. Ce terme désigne le nombre écrit avec un seul chiffre avant la virgule et multiplié par une puissance de 10 ; par exemple, l’écriture scientifique de 3141,6 sera 3,1416 ×103. Enfin, on appelle partie significative d'un nombre, ce nombre écrit écrit en notation scientifique sans la puissance de 10 qui va derrière (c'est-à-dire le nombre à virgule avec un seul chiffre avant la virgule) ; par exemple, 3,1416 est la partie significative dans notre exemple précédent.
La base de la base
Les types pour représenter un nombre à virgule
En C, un nombre à virgule flottante peut être représenté par les types float et double (il existe aussi long double). Comme pour les types entiers, leur taille en mémoire dépend de l'architecture de l'ordinateur, mais les valeurs sont très fréquemment 32 bits (4 octets) pour un float et 64 bits (8 octets) pour un double. Pour vous assurer de la taille chez vous, vous pouvez faire :
printf("taille d'un float : %u bytes\n", sizeof(float));
printf("taille d'un double : %u bytes\n", sizeof(double));
Intérêt des nombres flottants
Vous pouvez utiliser les types flottants dans vos programmes si vous souhaitez manipuler des nombres à virgule, mais également pour stocker de très grands nombres. En effet, un float permet d'atteindre 1038, et un double 10308 ! Toutefois, pour des raisons de précision, vous ne pourrez évidemment pas conserver la valeur exacte d’un nombre à 38 ou 308 chiffres, ce serait trop beau (il y aurait besoin de bien plus de 32 ou 64 bits) : votre nombre sera arrondi.
Écrire une constante
La syntaxe pour écrire un nombre à virgule est : -3141.59e7 (ou -3141.59E7, avec un E majuscule), ce qui signifie -3141,59 ×107. Attention, on met un point et non une virgule ! La lettre E collée au nombre signifie « exposant ». Celui-ci peut très bien être négatif comme dans 945.68e-3 (ce qui signifie 945.68 ×10-3).
De plus, si la partie entière ou la partie décimale d’un nombre vaut 0, on peut l’omettre ; de même pour l’exposant. Toutefois, il doit toujours y avoir au moins un point ou un exposant d'écrit, pour signifier au compilateur qu’on veut un nombre à virgule). Par exemple, les constantes suivantes sont équivalentes :
0.0e0 ; 0.0 ;
0.e0 ; 0. ;
.0e0 ; .0 ;
0e0 ;
En revanche, écrire 0 tout court produira un entier. En effet, le compilateur ne voyant ni point ni lettre E, il ne peut pas savoir qu'il s'agit d'un nombre à virgule flottante.
Le type par défaut d'une constante à virgule flottante est double, mais on peut le changer avec un suffixe collé après la constante :
la lettre F (minuscule ou majuscule) demande un float ;
la lettre L (minuscule ou majuscule) demande un long double.
Par exemple, .1e-3f sera de type float, 42.1337e-3l de type long double.
Enfin, il peut être utile de savoir que le C99 permet aussi d'écrire ses constantes flottantes en hexadécimal ! :diable: Pour cela :
ajoutez le préfixe 0x (ou 0X) avant votre constante (mais après le signe) ;
écrivez la partie significative en base 16 (c'est-à-dire avec les chiffres de 0 à 9 et les lettres de A à F) ;
l'exposant est obligatoire ; il doit être écrit en base 10 comme d'habitude (et non en hexadécimal), mais précédé de la lettre p (ou P) au lieu de e. De plus, il se réfère à une puissance de 2 et non de 10.
Par exemple, -0xC45.8p3 signifie - 0x C45,8 ×23 (soit - 3141,5 ×23 = - 25 132).
L'intérêt à part faire mal au crâne ? Obtenir un nombre exact ! Les explications suivent…
Des constantes inexactes
Attention : tous les nombres décimaux (c'est-à-dire écrits en base 10) ne sont pas forcément représentables de façon finie en binaire, et certains sont donc arrondis ! Ainsi, 0,1 en base 10 s'écrit en binaire 0b0,00011001100110011… avec une infinité de 0011 (de même que 1/3 = 0,3333… en base 10). Une partie significative écrite en base 10 ainsi qu'une puissance de 10 négative (c'est-à-dire qu'on divise par une puissance de 10) peuvent donc mener à des nombres inexacts.
En fait, seuls les nombres dont la partie décimale est le résultat d'une division par une puissance de 2 (comme .5 = 1/2, .75 = 3/4 ou encore .625 = 5/8) sont représentables en binaire avec un nombre fini de décimales. Spécifier la partie significative en hexadécimal (base 16) et l'exposant en termes de puissance de 2 permet donc un nombre exact (dans la limite de la capacité du type, bien sûr ^^ ).
Quelques informations pratiques
Les fonctions d'entrée et de sortie formatées : printf & scanf
Vous voudrez sûrement savoir quels sont les formateurs pour lire ou écrire des nombres flottants. Voici un petit tableau résumé. Pour des infos complètes sur l'utilisation de printf et scanf (il y a plein d’options pour configurer l’affichage) : RTFM, biensûr !
Formateurs
Utilisation
"%f", "%F"
Affiche le double « simplement », comme vous avez l'habitude de l'écrire : l'affichage est du type [-]XXXX.XXX, où les X sont des chiffres de 0 à 9 et [-] symbolise le signe « moins » éventuel.
"%e", "%E"
Affiche le double en écriture scientifique, c'est-à-dire avec un seul chiffre avant la virgule et un exposant introduit par la lettre e (ou E pour "%E") ; l'affichage est donc du type [-]X.XXXXXXeYY (ou [-]X.XXXXXXEYY).
"%g", "%G"
Une sorte de « combinaison » des formateurs précédents : utilise le premier style si le nombre n'est pas trop grand ou trop petit, le deuxième style sinon.
Remarquez que tous ces formateurs attendent des flottants de type double. Il n'existe pas de formateurs pour float, ce qui n'est pas dramatique car vous pouvez convertir vos nombres de float vers double pour les afficher (ce qui est fait automatiquement avec la syntaxe de printf). Le C99 vous permet d'ajouter la lettre L majuscule entre % et le formateur afin de correspondre à un long double.
Formateurs
Utilisation
"%e", "%E", "%f", "%F", "%g", "%G"
Lit un nombre à virgule flottante et l'écrit dans la variable de type float indiquée. Le nombre lu doit être écrit de la même manière que vous écrivez une constante dans votre code source.
Contrairement à printf, tous ces formateurs sont équivalents.
Attention ! Contrairement à printf, scanf travaille par défaut avec des float. Pour lire un double, il faut ajouter la lettre 'l' minuscule entre % et le formateur ; pour un long double, il faut ajouter 'L' (ou 'll').
Les fonctions mathématiques avec <math.h>
Matheux, vous serez comblés : la bibliothèque standard du C met à votre disposition toute une gamme de fonctions mathématiques : valeur absolue, maximum de deux nombres, arrondis en tous sens, puissances, fonctions trigonométriques, exponentielles et logarithmes, etc. Ces fonctions sont définies dans le header <math.h>, qu'il vous faudra donc inclure dans vos sources.
Comme vous faire la liste complète et détaillée des fonctions disponibles serait inutile et fastidieux, je vous invite à consulter le manuel qui est fait pour ça (tout ça pour ne pas dire encore une fois : RTFM…). De plus, chacune des fonctions existantes ci-dessus se décline en fait en trois versions :
une qui travaille avec des double : celle qui porte le nom « de base » (par exemple, floor, qui arrondit à l’inférieur) ;
une qui travaille avec des float : il faut ajouter la lettre 'f' à la fin du nom de la fonction (floorf dans notre exemple) ;
une qui travaille avec des long double : il faut ajouter la lettre 'l' à la fin du nom de la fonction (floorl dans notre exemple).
Vous devez néanmoins retenir une chose. Ces fonctions ne sont pas incluses dans l'exécutable avec le reste de la bibliothèque standard, lors de l'édition des liens (la phase suivant la compilation). Il faut les lier manuellement. Sous GCC, cela se fait en passant le paramètre -lm lors de cette phase. Si vous travaillez avec Code::Blocks, alors il est probable que ce dernier ajoute automatiquement cette liaison. Si ce n'est pas le cas, vous pouvez suivre la démarche suivante :
dans le champ Link libraries (à gauche), cliquez sur Add et entrez le nom de la bibliothèque à lier, soit « m », puis validez ;
autre possibilité pour cette dernière étape : taper simplement « -lm » dans le champ Other linker options (à gauche).
Voilà, les fonctions de <math.h> seront désormais incluses dans vos programmes !
Voilà, on a fini avec les fondamentaux. Vous avez maintenant des connaissances suffisantes pour manier les nombres à virgule en C, vous pouvez aller jouer dans le jardin mais ce serait dommage de s'arrêter en si bon chemin… Après cette brève introduction en la matière, nous allons nous plonger au cœur des nombres flottants pour en étudier le moindre détail. Pas trop fatigué ? Il vaudrait mieux, parce qu'on vient à peine de commencer. Yêêêhaaa !
On va maintenant s'intéresser à la manière dont sont représentés en mémoire les nombres à virgule flottante ! Attention, on va faire une grosse partie théorique, alors préparez vos barres céréalées en cas d'hypoglycémie. :D
Ce que vais vous raconter dans cette partie n'est pas dans la norme C. La suite de ce cours se base sur la norme IEEE 754 (ou plus précisément ANSI/IEEE Std 754-1985). Celle-ci spécifie :
la manière de représenter les nombres flottants en mémoire avec plusieurs formats ;
cinq opérations associées : l'addition (+), la soustraction (-), la multiplication (*), la division (/) et la racine carrée (sqrt()) ;
des modes d'arrondi ;
des exceptions.
Ne vous inquiétez pas pour les deux derniers points, on en reparlera.
Elle est proposée par l'IEEE (Institute of Electrical and Electronics Engineers, l'Institut des Ingénieurs Électriciens et Électroniciens), une organisation américaine qui est devenue une référence en matière d'informatique. Cette norme est très suivie (en fait, sur la très grande majorité des ordinateurs aujourd'hui), mais vous pouvez très bien tomber sur une implémentation qui utilise un autre mode de représentation. :( Un point sur la norme C sera fait à la fin de ce chapitre (ainsi qu'une manière de déterminer si IEEE 754 est bien employé sur votre implémentation). Ce format aura son importance plus loin dans ce tutoriel.
Principes généraux
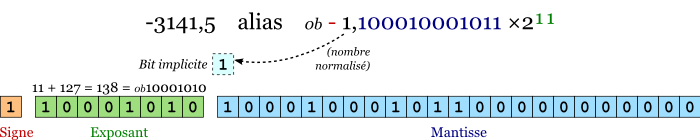
Tout nombre à virgule peut être écrit en notation scientifique, c'est-à-dire avec un seul chiffre avant la virgule et multiplié par une puissance de b (b étant la base dans laquelle on écrit le nombre : 10 pour la base décimale, 2 pour le binaire, 16 pour l'hexa, etc.). Par exemple, le nombre -3141,5 est égal à -3,1415 ×103 . L'écriture binaire de ce nombre est 0b -110001000101,1, soit 0b-1,100010001011 ×211.
Pour stocker un nombre à virgule flottante, on se base sur sa notation binaire scientifique. En mémoire, un nombre flottant se décompose donc en 3 parties. À partir du bit de poids fort, on a :
le signe, codé sur un bit : ce bit vaut 0 si le nombre est positif, 1 s'il est négatif. Remarquez ici que la représentation du signe des nombres flottants se fait selon le bit de poids fort et non selon la règle du complément à 2. En conséquence, il existe deux représentations pour zéro, un positif et un négatif (c'est néanmoins un défaut mineur, les implémentations gérant cette dualité ; par exemple, +0.0==-0.0 renverra vrai), et les valeurs possibles sont totalement « symétriques » par rapport à zéro (c'est la raison pour laquelle j'utiliserai souvent le symbole ±, « plus ou moins », par la suite) ;
l'exposant, c'est-à-dire la puissance à laquelle il faut élever 2 (et non 10 !). Le nombre de bits qu'il occupe dépend de la taille du type. Ce nombre est un entier et peut être négatif. Pour le représenter, on n'utilise ni la règle du bit de signe, ni celle du complément à 2 (car cela rendrait la comparaison de nombres plus difficile, comme on le verra ensuite) ; on opère un décalage de l'exposant réel en lui ajoutant 2e-1-1, où e représente le nombre de bits occupés par l'exposant ; en clair, ce nombre représente la valeur où tous les bits sauf celui de poids fort sont à 1 (c'est-à-dire 127 = 0b01111111 si l'exposant est codé sur 8 bits, ou 1023 = 0b01111111111 s'il est codé sur 11 bits) ;
la mantisse, c'est-à-dire la valeur de la partie décimale en notation binaire scientifique (avec un seul chiffre avant la virgule). On ne garde que la partie décimale car, du fait de la notation binaire, la partie entière est forcément égale à 1 (sauf dans les cas particuliers de zéro et de certains nombres très petits dont on reparlera). On parle de bit implicite (un bit « caché » représentant la partie entière, qui ici vaudrait 1). On économise ainsi un bit, ce qui permet d'avoir une précision plus grande. La mantisse occupe les bits de poids faibles restants.
IEEE 754 spécifie deux grands formats basés sur ce modèle ; les deux types principaux du C pour les nombres à virgule flottante correspondent à ces deux formats.
Nom dans la norme IEE 754
Type en C
Taille (en bits)
Chiffres significatifs (en base 10)
Valeurs absolues possibles
Total
s
e
m
minimum
maximum
simple précision
float
32 bits
1
8
23
7
1,2 ×10-38
3,4 ×10+38
double précision
double
64 bits
1
11
52
16
2,2 ×10-308
1,8 ×10+308
Nous détaillerons plus tard les deux dernières colonnes.
En résumé (pour un float de 32 bits), la représentation de -3141,5 est :
Les différents types de nombres représentables
Il y a cependant des cas particuliers, car un nombre à virgule flottante peut représenter autre chose que des nombres « normaux ». Il peut aussi valoir :
l'infini positif ou négatif (noté \infty par les mathématiciens). C'est par exemple le résultat de la division d'un nombre non nul par zéro (le signe dépendant alors du signe du numérateur et du zéro en dénominateur) ;
NaN (not a number, pas un nombre). NaN est une valeur spéciale qui est utilisée pour signaler une erreur (0 \div 0 ou \sqrt{-1} par exemples). N'importe quel calcul avec un NaN doit renvoyer NaN (sauf quelques exceptions), et n'importe quelle comparaison avec un NaN doit renvoyer faux (sauf !=) ; un NaN n'est même pas égal à lui-même, c'est pourquoi x==x peut renvoyer faux ;
enfin, on n'a pas encore réglé le problème de zéro.
Quelques calculs avec ces valeurs particulières :
\begin{matrix} ext{Le symbole}\pm ext{dans le r\'esultat d'une division signifie que le signe} \\ ext{d\'epend de ceux du num\'erateur et du d\'enominateur selon la r\`egle suivante :} \\ ext{- deux signes identiques : signe +} \\ ext{- deux signes diff\'erents : signe -} \\ \end{matrix}
\begin{matrix} x \div 0 &=& \pm\infty \\ 0 \div 0 &=& NaN \\ \\ x \div \infty &=& \pm0 \\ \infty \div \infty &=& NaN \\ \\ 0 imes \infty &=& NaN \\ \\ (+\infty) + (+\infty) &=& +\infty \\ (+\infty) - (+\infty) &=& NaN \\ \end{matrix}
Pour représenter tout ce petit monde, on utilise des valeurs spéciales de l'exposant (qui ne peuvent donc pas être utilisées pour des nombres normaux) :
Si l'exposant vaut sa valeur maximale (tous les bits à 1) et que la mantisse n'est pas nulle, alors c'est NaN.
Si l'exposant vaut sa valeur maximale et que la mantisse est nulle, alors c'est l'infini (positif ou négatif, selon le bit de signe).
Si l'exposant décalé vaut 0 et que la mantisse est nulle, alors c'est zéro (positif ou négatif, selon le bit de signe).
Si l'exposant décalé vaut 0 et que la mantisse n'est pas nulle, alors c'est un nombre dénormalisé : on considère que le bit implicite (la partie entière en notation scientifique) vaut 0.
Dans tous les autres cas, c'est un nombre normalisé : on considère que le bit implicite vaut 1. C’est le cas « normal ».
Un petit tableau pour récapituler tout ça de manière visuelle (pour un float de 32 bits)…
Notez que pour passer d'un nombre positif à son équivalent négatif, il suffit d'additionner 0x 8000 0000 à sa représentation en mémoire (ou 0x 8000 0000 0000 0000 s'il s'agit d'un double). Ceci nous servira plus tard. ;)
Courage, cette partie théorique n'est pas encore finie, et peut-être que vous trouvez ça barbant, mais ça nous servira pour la suite.
Nombres dénormalisés
Nous allons maintenant nous attarder sur les nombres dénormalisés. C'est qu'ils sont traîtres, les bougres.
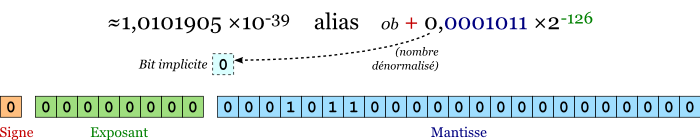
Un nombre dénormalisé est un nombre si petit (en valeur absolue) que l'on ne peut pas le représenter en mémoire en se basant sur son écriture scientifique. Par exemple, 0b 1011 ×2-133 (soit environ 1,0101905 ×10-39) a pour écriture scientifique 0b 1,011 ×2-130 ; cependant, on ne peut pas stocker l'exposant -130 dans un float.
On ruse donc en écrivant le nombre avec le plus petit exposant possible.Question : quel est cet exposant (pour un float) ? Si vous avez répondu -127 (et je suis sûr que vous l'avez fait, si vous suivez encore ce cours), vous êtes tombés dans le piège. Mouahaha. :p
Mais pourtant, c'est bien l'exposant non-décalé minimal, celui qui sert pour représenter des nombres dénormalisés ?
Tout à fait. En fait, les gens de chez IEEE (qui sont très très intelligents, si si) ont décidés de compliquer la chose. Ils ont choisi que, bien que l'exposant non-décalé en mémoire soit -127 (pour un float), l'exposant réel d'un nombre dénormalisé serait -126, c'est-à-dire le même que pour les plus petits nombres normalisés !
Pourquoi cela ? Pour assurer une sorte de continuité avec les premiers nombres normalisés. Puisqu'ils ont le même exposant réel, les nombres dénormalisés et les premiers nombres normalisés sont à intervalles réguliers :
Citation : liste des nombres dénormalisés et premiers nombres normalisés (pour un float)
0b 0,00000000000000000000000 ×2-126 // zéro 0b 0,00000000000000000000001 ×2-126 // 1er nombre dénormalisé 0b 0,00000000000000000000010 ×2-126 // nombre dénormalisé suivant … 0b 0,11111111111111111111110 ×2-126 // avant-dernier nombre dénormalisé 0b 0,11111111111111111111111 ×2-126 // dernier nombre dénormalisé 0b 1,00000000000000000000000 ×2-126 // 1er nombre normalisé 0b 1,00000000000000000000001 ×2-126 // nombre normalisé suivant … 0b 1,11111111111111111111110 ×2-126 // avant-dernier nombre normalisé de cet exposant 0b 1,11111111111111111111111 ×2-126 // dernier nombre normalisé de cet exposant
Revenons à nos moutons. Comme je le disais, on écrit donc le nombre avec le plus petit exposant possible, soit dans notre exemple 0b+ 0,0001011 ×2-126. On traduit ensuite ceci de façon similaire à ce qu'on a fait pour un nombre normalisé : suivez les couleurs !
Vous comprenez maintenant pourquoi le bit implicite est à 0 pour un nombre dénormalisé.
Pour un double, l'exposant sera -1022 ; de manière générale, il s'agit de 1 - d\'ecalage.
Mais pourquoi avoir inventé les nombres dénormalisés ? o_O Il aurait été plus simple de décider qu'à l'exposant décalé nul correspondaient également des nombres habituels (dont l'exposant réel aurait bien été -127 et non -126).
C'est vrai, on peut cependant trouver plusieurs raisons :
Historiquement, l'exposant minimal servait pour représenter zéro, quelle que soit la valeur de la mantisse ; les nombres dénormalisés ont été introduits en 1985 avec la première version de la norme IEEE 754.
D'ailleurs, si l'on avait choisi des nombres normalisés pour « remplir » cette plage de valeurs, la représentation de zéro n'aurait plus été cohérente. En effet, on se serait retrouvé avec ±zéro = ± 1,00000000000000000000000 ×2-127 (le bit implicite valant 1). Cela dit, les nombres dénormalisés introduisent eux-même une incohérence, puisqu'il y a deux types de nombres qu'il faut interpréter différemment ; de plus, on aurait été tout à fait capable de gérer cette incohérence pour interpréter correctement zéro.
Les nombres dénormalisés permettent de représenter des nombres bien plus petits (plus proches de zéro) que si l'on avait choisi des nombres normalisés. En effet, le plus petit nombre dénormalisé est ± 0b 0,00000000000000000000001 ×2-126, soit ±1 ×2-149 (-126-23 = -149) ; si l'on avait choisi des nombres normalisés, le plus petit aurait été ± 0b 1,00000000000000000000001 ×2-127.
Cependant, un reproche qu'on pourrait faire aux nombres dénormalisés est qu'en plus de tout compliquer pour nous autres pauvres humains, ils perdent en précision au fur et à mesure qu'ils se rapprochent de zéro : c'est ce que nous allons voir dans la partie suivante.
Dans cette partie, nous allons continuer à approfondir les aspects théoriques. Elle va se révéler très mathématique. >_
Retrouver la valeur du nombre flottant
Non, restez ! Bon, si vraiment le mot « mathématiques » vous fait pousser des boutons, vous pouvez passer cette partie, mais elle est intéressante pour bien comprendre la conversion de la représentation en mémoire vers la valeur.
Pour la suite, on note :
flottant la valeur du flottant représenté ;
m et e le nombre de bits occupés par la mantisse et l'exposant (respectivement) ;
mantisse la mantisse (plus précisément, sa représentation entière) ;
exposant l'exposant non-décalé (en termes de puissances de 2) ; le décalage de l'exposant est d\'ecalage= 2^{e-1}-1, on en déduit les valeurs limites de l'exposant :
la valeur minimale de l'exposant non-décalé, réservée aux zéros et nombres dénormalisés, est exposantMin=\quad 0 - d\'ecalage \quad= 1 - 2^{e-1} (mais l'exposant réel des dénormalisés est exposantMin+1) ;
la valeur maximale de l'exposant non-décalé, réservée aux infinis et NaN, est exposantMax=\quad (2^e-1) - d\'ecalage \quad= 2^{e-1}.
Pour retrouver la partie significative de la notation scientifique, il suffit de faire 1+\frac{mantisse}{2^m} si le nombre est normalisé, ou 0+\frac{mantisse}{2^m} s'il est dénormalisé.
1 ou 0 représente la partie entière du flottant (c'est-à-dire le bit implicite).
La fraction qui suit représente la partie décimale (on a 0\le\frac{mantisse}{2^m}<1 ).
Ensuite, il suffit de multiplier par la puissance de 2 indiquée par l'exposant réel, et d'adapter le signe selon le bit de signe :
\[\begin{aligned}flottant &=\quad +\enspace (0 + \frac{ extit{0b} hinspace 00010110000000000000000}{2^{23}}) imes2^{-127+1}\\ &=\quad +\enspace (0 + \frac{720896}{2^{23}}) imes2^{-126} \quad\quad\approx\enspace +\enspace 1{,}0101905 imes10^{-39}\end{aligned}\] Là aussi, on retrouve bien le nombre de départ.
Intervalle entre les nombres en fonction de l'exposant
Selon la norme IEEE 754, les nombres consécutifs de même exposant (qu'ils soient normalisés ou pas) sont « placés » à intervalle régulier. En effet, pour passer d'un nombre au nombre suivant, on ajoute toujours \delta=\quad 0{,}00000000000000000000001 imes2^{exposant} \enspace= \frac{1}{2^m} imes2^{exposant} \enspace= 2^{exposant-m}.
Cet intervalle double quand on passe d'un exposant à l'exposant supérieur. Quelques valeurs remarquables pour un float (ne les apprenez pas !) :
2-126 - 23 = 2-149 ≈ 1,40 ×10-45 : écart entre les nombres dénormalisés et les premiers nombres normalisés (et valeur du tout premier nombre dénormalisé) ;
20 - 23 ≈ 1,19 ×10-7 : écart entre les nombres normalisés compris entre 1 et 2 ;
1 : écart entre les nombres normalisés d'exposant non-décalé 23 ;
2127 - 23 ≈ 2,03 ×1031 : écart entre les plus grands nombres normalisés.
Précision et chiffres significatifs
Vous aurez remarqué une colonne « chiffres significatifs » dans le premier tableau. C'est ce dont on va parler ici.
Mais qu'est-ce qu'un chiffre significatif ? Le nombre de chiffres significatifs d'un nombre, c'est tout simplement le nombre de chiffres utilisés pour écrire ce nombre (dans une base numérique donnée). Par exemple, 43,1337 a 6 chiffres significatifs.
En physique et en chimie, on y voue une attention particulière. En effet, les mesures n'étant jamais exactes, on s'en sert pour indiquer le degré de précision de la mesure (qui varie selon les instruments). En conséquence, pour un physicien, 42,1337 est différent de 42,13370 ; le second nombre est plus précis, car il indique quel est le 5e chiffre après la virgule tandis que le premier nombre s'arrête au 4e (le 5e chiffre pourrait être 0, 1, 2, 3, 4, on n’en sait pas plus).
On compte les chiffres significatifs à partir du premier chiffre de gauche différent de 0, ce qui signifie que 3,1416 et 003,1416 sont équivalents (ils ont tous les deux 5 chiffres significatifs).
Vous pouvez maintenant comprendre la colonne du tableau : elle indique le nombre de chiffres significatifs en base 10 que nous permet chaque format :
le format 32 bits garantit grosso modo7 chiffres significatifs en base 10 ;
le format 64 bits garantit grosso modo16 chiffres significatifs en base 10.
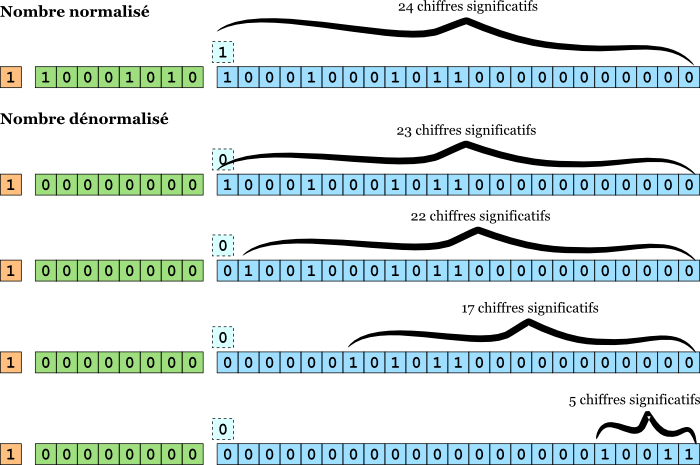
Maintenant, contrôle surprise : combien de chiffres significatifs en base 2 permettent ces formats ? :diable: Mais si, vous pouvez tout à fait répondre, réfléchissez un peu. C'est tout simple : la mantisse représentant la partie significative du nombre, un nombre flottant a autant de chiffres significatifs en base 2 que sa mantisse occupe de bits. Hmm hmm. Vous êtes certain ? N'oubliez pas le bit implicite ! Il faut donc ajouter 1 à ce nombre. En vérité, un nombre normalisé a donc m+1 chiffres significatifs en binaire, soit 23+1=24 pour le format 32 bits, ou 52+1=53 pour le format 64 bits. On appelle souvent le nombre de chiffres significatifs en base 2 la précision tout court.
Mais ce n'est pas aussi simple ! Cette « formule » pour la précision n'est valable que pour les nombre normalisés. Voyez-vous pourquoi ? Rappelez-vous que pour les nombres dénormalisés, le bit implicite, c'est-à-dire la partie entière du nombre, est 0. Comme c'est le premier chiffre, on ne le compte pas dans les chiffres significatifs.
Ah bah alors, pour un nombre dénormalisé, la précision c'est juste le nombre de bits de la mantisse ?
Que nenni, jeune padawan. Un court schéma vaut mieux que de longues explications.
Comme vous le voyez, plus un nombre dénormalisé est proche de zéro, moins il est précis.
Bien. On vient de se farcir deux chapitres de théorie pure sur la représentation en mémoire d'un nombre à virgule flottante. Vous en avez marre ? Tant mieux, on change de sujet ! Bon, ça va rester théorique, mais un peu moins quand même. La norme IEEE 754 ne se limite pas à la représentation des flottants ; elle définit également des exceptions et des modes d'arrondis. Décortiquons tout ça.
Les exceptions
Une exception est une sorte de « signal qui est envoyé dans certains cas, afin de traiter les erreurs les cas particuliers qui, s'ils étaient ignorés, seraient des erreurs. Cette définition est en fait générale (le terme vous est peut-être familier si vous faites du C++).
C'est encore flou pour vous ? Ça ne fait rien, vous allez mieux comprendre avec cette liste. IEEE définit cinq exceptions :
invalid operation (opération invalide) : se produit lorsqu'une opération interdite est effectuée ; le résultat du calcul en question sera NaN ;
division by zero (division par zéro) : se produit lorsqu'on tente de diviser un nombre (non nul) par zéro ; le résultat sera ± \infty ;
overflow : se produit lorsque le résultat d'un calcul est trop grand (en valeur absolue) pour être stocké ; on arrondit à ± \infty ;
underflow : se produit lorsque le résultat d'un calcul est trop petit (en valeur absolue) pour être stocké ; on arrondit à zéro ;
inexact : se produit lorsqu'on effectue un autre arrondi pour pouvoir stocker un nombre flottant (parce que le résultat a plus de chiffres significatifs qu'on peut en stocker).
Et là, j'ai une transition de malââââde !…
Les arrondis
Les nombres stockés en mémoire ayant un nombre fini de chiffres significatifs (essayez de stocker un nombre infini de chiffres…), les calculs peuvent mener à des arrondis. IEEE 754 définit quatre modes d'arrondis :
au nombre le plus proche : c'est le comportement par défaut (si le nombre à arrondir tombe pile-poil entre deux, alors on arrondit à celui dont le dernier bit vaut 0) ;
vers zéro ;
vers +\infty ;
vers -\infty.
C'est là que ça devient intéressant (enfin ça l'était déjà avant, c'est une façon de parler, n'est-ce-pas). Les imprécisions s'accumulent au fil des calculs, et au final vous pouvez obtenir quelque chose d'incohérent !
Ces imprécisions se manifestent par exemple lorsqu'on manipule deux nombres dont les exposants sont très éloignés. Par exemple, 4.2e17 + 13.37 devrait donner 42000000000000001337 soit 4.2000000000000001337e17, mais il y a plus de chiffres significatifs qu'on ne peut en stocker ; le nombre sera donc arrondi, et finalement il vaudra 4.2e17 comme si l'opération n'avait pas eu lieu ! Certains opérateurs entraînent beaucoup d'arrondis, comme l'addition ou la soustraction. Au contraire, d'autres, tels la multiplication ou la division, sont beaucoup plus sûrs. L'exemple précédent devrait vous aider à comprendre pourquoi. ;)
Autre source de problèmes : comme vu précédemment, tous les nombres décimaux ne sont pas représentables de façon finie en binaire, et certains (comme 1.0/10.0 = .1) sont donc arrondis.
Enfin, et en conséquence de ce qui vient d'être dit :
Citation : Mewtow
Les opérations avec les flottants ne sont pas associatives : l'ordre dans lequel on fait un calcul change le résultat. Par exemple, 1 - (.2 + .2 + .2 + .2 + .2) aura un résultat différent de (((((1-.2)-.2)-.2)-.2)-.2).
De façon plus générale, il faut rester vigilant lorsqu'on écrit des expressions impliquant des flottants, car des expressions a priori équivalentes, du point de vue d'un humain, se révèlent en fait différentes en pratique. >_ L'exemple précédent l'illustre bien. D'autres cas parlants sont imaginables.
Il y a pas mal de cas où ce qui change d'une expression à l'autre est le signe du zéro obtenu. Par exemple, x-y et -(y-x) ne sont pas équivalents car si les deux nombres sont égaux, alors la première expression donne +0.0 mais la deuxième -0.0.
Il y a aussi des cas où les expressions ne sont pas équivalentes si on considère les valeurs « spéciales » des nombres, à savoir zéro, l'infini ou NaN :
x-x ne vaut pas 0.0 si x vaut l'infini ou NaN ;
0*x ne vaut pas 0.0 si x vaut -0.0, l'infini ou NaN ;
x/x ne vaut pas 1.0 si x vaut zéro, l'infini ou NaN ;
x==x est faux si x vaut NaN ; :euh:
x!=x est vrai si x vaut NaN.
Cette liste est tirée de la norme C99 (ISO/IEC 9899:TC3), que je vous invite à consulter si vous en voulez une plus complète (localisation dans le draft PDF de la norme : Annex F — F.8.2 Expression transformations & F.8.3 Relational operators (p. 464-466)).
L'environnement des flottants : <fenv.h>
Cet ensemble de paramètres (les exceptions et le mode d'arrondi) forme ce qu'on appelle en informatique (c'est une définition générale) un environnement. C'est le cadre dans lequel on travaille.
Cet environnement pour les flottants est accessible avec le header standard (C99) <fenv.h>. Il permet de manipuler les exceptions (les surveiller, en lever, etc.) et les modes d'arrondis (savoir quel est le mode utilisé et en changer). Je ne détaillerai pas son utilisation. Si vous voulez en savoir plus, consultez (par exemple) cette page Wikipédia ou cette page du site d'Open Group.
Bon. On a donc vu que l'utilisation des flottants en C est semée d'embûches : on risque des arrondis et des expressions « normalement » équivalentes ne le sont pas. Mais ce n'est pas tout ! Les comparaisons vont aussi vous donner du fil à retordre. :( En effet, l'opérateur de comparaison == renvoie vrai si ses deux opérandes sont EXACTEMENT égales, ou s'il compare un zéro positif et un zéro négatif. Or, avec les problèmes d'arrondis, une différence minuscule peut s'être glissée entre les deux nombres testés. Ainsi, vous risquez de vous retrouver avec des égalités qui devraient être vraies, mais qui sont fausses !
Cela peut faire planter lamentablement un programme (boucles infinies, instructions dans un bloc conditionnel jamais exécutées…), et la source du problème est difficilement identifiable pour un œil non averti.
Un petit exemple ? 4.2e17 == 4.2e17 + 13.37 renverra vrai (d'après l'exemple précédent).
Évidemment, ces exemples sont stupides, mais ils permettent de mieux saisir dans quels cas se pose ce problème.
Les utilisateurs de GCC seront intéressés de savoir qu'il existe une option -Wfloat-equal qui déclenche un warning dès que l'on utilise l'opérateur == sur des nombres flottants.
Citation : Vous
Argghh…! mais c'est abominable !
Hé oui, c'est horrible. Il est encore temps d'abandonner définitivement l'informatique et de vous mettre au patchwork.
Non attendez, revenez ! Bien sûr, il existe des astuces. Et heureusement !
Alors, récapitulons : on cherche à comparer deux nombres à virgule flottante (float ou double) en tenant compte d'une marge d'erreur due aux arrondis ; on va pour cela écrire une fonction qui renverra un booléen (vrai ou faux, 1 ou 0), pour remplacer l'opérateur ==.
L'écart absolu & l'écart relatif
La première méthode consiste tout simplement à mesurer l'écart entre les deux nombres. On parle d'écart absolu (par opposition à l'écart relatif que nous verrons par la suite). Si cet écart est inférieur à une certaine valeur (souvent appelée epsilon, ce qui pour un mathématicien signifie « valeur très petite »), alors on considère que les deux nombres sont égaux.
#include <math.h> // pour la fonction fabs, renvoyant la valeur absolue d'un flottant
#define EPSILON 1e-8
/* ici pour des doubles, mais on fait la même chose pour des floats */
int doublesAreEqual(double a, double b) {
return fabs(a-b) <= EPSILON;
/* La fonction fabs renvoie la valeur absolue (c'est-à-dire positive) du nombre
de type double passé en argument ; ses équivalents (C99) sont fabsf pour les
float, et fabsl pour les long double (pensez donc à adapter votre code en
conséquence pour comparer les autres types flottants). */
}
Ici, fabs nous renvoie l'écart absolu entre a et b. Le reste est facile à comprendre. Simple, non ?
Oui, mais c'est encore loin d'être parfait : en effet, un écart de 1e-8 (soit 0.00000001) peut s'avérer judicieux pour comparer des nombres compris entre 0,1 et 1 (par exemple, en fonction de la précision que vous souhaitez), mais trop petit pour des nombres entre 100 et 1000, ou trop grand pour des nombres entre 0,00001 et 0,0001 ; si vous comparez des nombres compris entre 0,00000001 et 0,0000001, vous avez même une marge d'erreur de 100% ! N'employez donc cette méthode que si vous êtes sûr de l'ordre de grandeur des nombres à comparer, et choisissez un epsilon adapté.
Pour pallier à ce problème et faire une fonction plus générique, une solution serait de passer l'écart maximal en argument à la fonction et non de se baser sur une constante de préprocesseur ; ainsi, l'utilisateur pourrait fournir un écart adapté à l'ordre de grandeur des nombres qu'il veut comparer. Allons plus loin. On va employer l'écart relatif. Celui-ci ramène l'écart absolu dans les proportions des nombres comparés :
#include <math.h>
#define EPSILON 1e-8
int doublesAreEqual(double a, double b) {
if(a==b) return 1; // si a et b valent zéro (explications plus bas)
double absError= fabs(a-b); // écart absolu
a= fabs(a); // on ne garde que les valeurs absolues pour la suite …
b= fabs(b); // … pour pouvoir calculer le nombre le plus grand en valeur absolue
return ( absError / (a>b? a:b) ) <= EPSILON;
}
On divise l'écart absolu par le plus grand des deux nombres en valeur absolue (signification du ternaire), pour avoir quelque chose d'adapté à l'ordre de grandeur des deux nombres.
La ligne commençant par if(a==b) vous paraît sans doute bizarre. Elle est là pour gérer le cas où a et b sont égaux à zéro. En effet, sans elle, on aurait une division par zéro qui vaudrait NaN, et la comparaison serait donc toujours fausse. On compare donc les deux nombres pour que la fonction renvoie vrai s'ils sont identiques et égaux à zéro (positif ou négatif).
Cependant, il subsiste un problème : dans le cas de deux nombres très proches de zéro, l'écart relatif sera très important (car on divise par un tout petit nombre) alors que ces deux nombres seront très proches… Pour y remédier, on réintroduit l'écart absolu : la fonction retournerait vrai si l'écart absolu ou l'écart relatif (au moins l'un des deux) est inférieur à une valeur donnée (qu'on passe en argument à la fonction). D'où le code définitif :
Maintenant, vous avez du code à peu près potable et fonctionnel. Toutefois, il existe une autre manière de faire, plus pratique mais un peu plus hard. Accrochez-vous, ça va secouer. :pirate:
Imaginez qu'au lieu de se baser sur l'écart entre les deux nombres, on cherche à déterminer combien de nombres possibles les séparent ? Ainsi, on aimerait placer une marge d'erreur, non sur la valeur elle-même des nombres flottants, mais sur leur « éloignement », pour pouvoir dire par exemple : « J'accepte les 5 nombres en dessous et les 5 nombres au dessus de la valeur machin ».
Eh bien, grâce au format de l'IEEE, c'est possible !
Ce format garantit que « si deux nombres du même type à virgule flottante sont consécutifs, alors leurs représentations entières le sont aussi (selon le bit de poids fort pour déterminer le signe, et non la règle du complément à 2). »
Que signifie ce charabia ? Eh bien, prenons 2 nombres de type float codés sur 32 bits selon le format IEEE 754 (évidemment, cela s'applique aussi aux double) :
Valeur du float représentation en mémoire
binaire hexadécimal en base 10
+1.9999998 0 0111111 1 1111111 11111111 11111110 3F FF FF FE 1073741822
+1.9999999 0 0111111 1 1111111 11111111 11111111 3F FF FF FF 1073741823
Ces 2 nombres sont « consécutifs », il ne peut pas y avoir d'autre nombre du même type dont la valeur serait comprise entre les 2. Or, que constate-t-on ? Leurs représentations en mémoire, si on les lit comme des nombres entiers, sont également consécutives !
Pour savoir si les deux nombres à comparer sont « voisins », il suffit donc de comparer leur représentation en mémoire convertie en nombre entier.
Mais comment accéder à cette représentation entière ?
Ben, c'est simple, il suffit de faire (int)monFloat … Surtout pas ! En faisant ça, on convertit le nombre à virgule en nombre entier, et on obtient donc le nombre de départ arrondi à l'unité. Ça n'a rien à voir avec ce que l'on veut. La bonne formule est donc, tenez-vous bien : *(int*)&monFloat Je vous laisse méditer là-dessus. :p Ce n'est pas vraiment compliqué, quand on y pense. Quelques explications si vraiment vous bloquez :
pour comprendre cette expression, il faut en fait la lire de droite à gauche :
&monFloat renvoie l'adresse de la variable de type float, donc un pointeur sur float (un float*) ;
(int*) convertit ce pointeur sur float en un pointeur sur int ; ainsi, l'ordinateur considérera la variable pointée comme un int et non plus plus un float ;
et hop ! le tour est joué, il ne nous reste plus qu'à déréférencer ce pointeur avec * pour accéder à la variable pointée, cette fois lue comme un entier (int) et non comme un flottant.
Maintenant, du code avec ce que je viens de vous dire :
#include <stdlib.h> // pour la fonction abs, renvoyant la valeur absolue d'un entier
#include <stdint.h> /* header du C99, qui fournit des types entiers de taille fixe :
— int32_t, int64_t : entier signé de 32 ou 64 bits ;
— uint32_t, uint64_t : entier non-signé de 32 ou 64 bits. */
#define INTREPOFFLOAT(f) ( *(int32_t*)&(f) ) // représentation entière d'un float (32 bits)
#define INTREPOFDOUBLE(d) ( *(int64_t*)&(d) ) // représentation entière d'un double (64 bits)
#define MAXULPS 5
/* ici pour des floats, mais on fait exactement pareil pour des doubles */
int floatsAreEqual(float a, float b) {
if(a==b) return 1;
return abs( INTREPOFFLOAT(a) - INTREPOFFLOAT(b) ) <= MAXULPS;
/* attention à la fonction abs, qui prend un int en argument ; un int fait 16
ou 32 bits : il peut donc être trop petit pour contenir les 32 bits de la
représentation entière d'un float, et sera de toutes façons insuffisant
pour les 64 bits de celle d'un double. Voyez la fonction labs qui prend un
long int, ou llabs (C99) qui prend un long long int, ou mieux, écrivez vos
propres fonctions de valeur absolue, pour 32 et 64 bits (avec les types de
<stdint.h>) ; ainsi, vous n'aurez plus de problèmes de taille des types
pouvant varier. Ici, je garde les fonctions standards par souci de clarté. */
}
La constante MAXULPS (de ULP, « Unit of Least Precision », c'est-à-dire la valeur qui sépare deux flottants consécutifs) nous fournit notre marge d'erreur. Si l'écart entre les représentations entières est inférieur à MAXULPS, alors on considère que les nombres sont égaux. :)
Ici, la ligne commençant par if(a==b) est là pour gérer le cas où les deux nombres seraient +0.0 et -0.0. En effet, +0.0 et -0.0 ont des représentations entières très différentes, ce qui fait que la fonction retournerait faux sans ce test préalable.
En outre, remarquez qu'on utilise les types entiers définis dans le header standard <stdint.h> au lieu des types habituels (int, long int…). En effet, la taille de ces derniers dépend de l'implémentation et n'est donc pas connue, il serait donc dangereux (non portable) de s'appuyer dessus ; au contraire, la taille de int32_t et int64_t est connue et fixe. Ce header a été introduit avec C99, c'est pourquoi je vous ai dit qu'on allait devoir se baser sur cette version du langage C.
Un peu de maths pour vous aider à choisir votre marge d'erreur !
Une variation de \Delta mantisse dans la représentation entière de la mantisse codée sur m bits correspond à une variation de la valeur du flottant donnée par la formule suivante : \Delta flottant=\enspace \frac{\Delta mantisse}{2^m} imes 2^{exposant} \enspace= \Delta mantisse imes 2^{exposant-m} (où exposant est l'exposant réel). Cette formule provient directement de celle donnant l'intervalle entre les nombres consécutifs en fonction de l'exposant.
Pour un nombre flottant compris entre 1 et 2, une variation d'un ULP correspond donc à une variation de valeur du nombre flottant de \frac{1}{2^{23}} \approx 1{,}192 imes10^{-7} pour un float et \frac{1}{2^{52}} \approx 2{,}220 imes10^{-16} pour un double.
Si vous choisissez comme moi une marge de 5 ULP, alors votre marge de valeur (pour un nombre flottant compris entre 1 et 2) sera \frac{5}{2^{23}} \approx 5{,}960 imes10^{-7} pour un float et \frac{5}{2^{52}} \approx 1{,}110 imes10^{-15} pour un double.
Mais (hé oui, encore un « mais ») il reste encore un détail à régler, et à ce stade j'aimerais que vous leviez tous la main pour me le dire. Allez, un indice : ça concerne la parenthèse de la phrase en italique de tout à l'heure… :-° Ben oui, le signe ! Les flottants, selon la norme IEEE 754, sont signés selon le principe du bit de signe et non du complément à 2. Or, les entiers (du moins sur la grande majorité des ordinateurs aujourd'hui) sont stockés… selon la règle du complément à 2.
Un exemple pour bien voir (je ne vous met plus le binaire, vous êtes grands maintenant) :
Valeur du float représentation en mémoire
hexadécimal en base 10 selon le complément à 2
+4.2038954 e-45 00 00 00 03 3
+2.8025969 e-45 00 00 00 02 2
+1.4012985 e-45 00 00 00 01 1
+0.0000000 00 00 00 00 0
-0.0000000 80 00 00 00 -2147483648
-1.4012985 e-45 80 00 00 01 -2147483647
-2.8025969 e-45 80 00 00 02 -2147483646
-4.2038954 e-45 80 00 00 03 -2147483645
Comme vous le voyez, le dernier nombre est inférieur à l'avant-dernier, et pourtant sa représentation entière (en signed comme en unsigned) est supérieure ! En vérité, cela ne porte pas à conséquence si l'on compare deux nombres négatifs, car on ne s'intéresse qu'à l'écart entre les représentations entières, qui lui ne change pas ; le problème se pose lorsque l'on compare deux nombres de signes opposés.
Heureusement, il existe une solution. Il suffit de convertir les nombres négatifs selon la règle du bit de signe, en nombres négatifs selon la règle du complément à 2. Je vous laisse chercher ; aidez-vous de l'exemple ci-dessus… Trouvé ? Il suffit de garder la valeur telle quelle si le flottant est positif, ou s'il est négatif de soustraire 0x 80 00 00 00 à la représentation entière puis d'inverser le signe de cette représentation. Cela revient à faire l'opération suivante : représentation = 0x 8000 0000 - représentation ; Similairement, pour un double de 64 bits, on fera représentation = 0x 8000 0000 0000 0000 - représentation.
On obtient alors ceci :
Valeur du float représentation transformée
hexadécimal en base 10 selon le complément à 2
+4.2038954 e-45 00 00 00 03 3
+2.8025969 e-45 00 00 00 02 2
+1.4012985 e-45 00 00 00 01 1
+0.0000000 00 00 00 00 0
-0.0000000 00 00 00 00 0 * (* = a été transformé)
-1.4012985 e-45 FF FF FF FF -1 *
-2.8025969 e-45 FF FF FF FE -2 *
-4.2038954 e-45 FF FF FF FD -3 *
Comme vous le voyez, les représentations entières sont maintenant cohérentes, on peut les comparer sans problème. Et même les deux zéros (positif/négatif) sont égaux !
Du code, du code !
#include <stdlib.h>
#include <stdint.h>
#define INTREPOFFLOAT(f) ( *(int32_t*)&(f) )
#define INTREPOFDOUBLE(d) ( *(int64_t*)&(d) )
#define MAXULPS 5
int floatsAreEqual(float a, float b) {
int32_t aInt= INTREPOFFLOAT(a); // représentations entières
int32_t bInt= INTREPOFFLOAT(b);
if(aInt<0) aInt= 0x80000000 - aInt; // ou 0x8000000000000000 pour des doubles
if(bInt<0) bInt= 0x80000000 - bInt;
/* NOTE: on teste (aInt<0) et non (a<0). En effet, si a==-0.0 (zéro négatif),
alors le test (a<0) renverrait faux, et on garderait la représentation de
-0.0, à savoir 0x80000000. La règle du complément à 2 garde l'avantage du
bit de signe : si le bit de poids fort est à 1, alors le nombre entier est
négatif, et réciproquement ; on peut donc utiliser le test sur l'entier et
non sur le flottant pour savoir s'il faut « transformer » la représentation. */
return abs( aInt - bInt ) <= MAXULPS;
}
Attention à bien utiliser les types signés (int32_t et int64_t) et non les non signés (uint32_t et uint64_t).
Bon, ce n'est pas encore parfait, mais c'est très convenable. Quelques points améliorables :
les infinis : comme vu précédemment, les infinis sont adjacents aux plus grands nombres en valeur absolue. Notre fonction pourrait par exemple nous dire qu'un nombre positif très très très grand et +\infty sont égaux, alors que ce n'est pas vrai (ne discutez pas, d'un point de vue mathématique c'est faux :lol: ) ;
les NaN : de même, certains NaN pourraient être comparés comme égaux à l'infini ou à un nombre extrêmement grand en valeur absolue, voire à un autre NaN. Or, normalement, n'importe quelle comparaison avec un NaN (hormis !=) devrait valoir faux.
Ces détails peuvent être corrigés avec des vérifications supplémentaires. À ce sujet, les macros de test de nombres flottants (C99) peuvent servir. En résumé (je vous invite à consulter le manuel avec le lien précédent) :
Citation : Le manuel : fpclassify, isfinite, isnormal, isnan, isinf
Depuis le C99, le header <math.h> définit les macros isfinite, isnormal, isnan et isinf ; elles prennent toutes un nombre flottant en argument (peu importe son type), et renvoient un booléen indiquant respectivement si le nombre est fini, normalisé, NaN ou infini (le retour de isinf n'est pas forcément 1 ou 0). La macro fpclassify est également définie. On l'utilise comme les autres, et sa valeur de retour indique le type du nombre flottant (FP_ZERO, FP_SUBNORMAL, FP_NORMAL, FP_INFINITE, FP_NAN).
Code complet
Je vous propose finalement un code complet.
J'y ai introduit une fonction cmpFloats (ou cmpDoubles) de mon cru qui permet une comparaison plus générale : en effet, à la manière de strcmp, elle renvoie -1 si a>b, 0 si a==b ou 1 si a<b ; elle renvoie par ailleurs -2 si l'un des deux nombres au moins est NaN. Ainsi, il devient plus facile de tester les deux nombres (j'ai de plus écrit des macros simples pour faciliter les comparaisons). En effet, avant, pour tester par exemple a<b (strictement inférieur), il fallait faire if(a<b && !floatsAreEqual(a,b)), ce qui était plus lourd à écrire.
Header
#ifndef INCLUDE_CMPFLOATS_H
#define INCLUDE_CMPFLOATS_H
#include <stdint.h>
#include <math.h> /* pour les macros de test des nombres
flottants ( isnan() et isinf() ) */
/* représentation entière du nombre en virgule flottante */
#define INTREPOFFLOAT(f) ( *(int32_t*)&(f) )
#define INTREPOFDOUBLE(d) ( *(int64_t*)&(d) )
/* marge maximale séparant deux nombres flottants considérés comme égaux,
en termes d'ULP (« Unit of Least Precision ») */
#define MAXULPSFLOAT 5
#define MAXULPSDOUBLE 5
/* renvoie vrai (1) si les 2 nombres sont égaux, faux (0) sinon */
int floatsAreEqual(float a, float b);
int doublesAreEqual(double a, double b);
/* renvoie -1 si a>b, 0 si a==b, 1 si a<b, ou -2 si a ou b est NaN */
int cmpFloats(float a, float b);
int cmpDoubles(double a, double b);
/* macros booléennes (à utiliser dans des tests simples) */
#define CMPFLOATS_EQUAL(a,b) (cmpFloats((a),(b))==0) // => a==b
#define CMPFLOATS_UNEQUAL(a,b) (cmpFloats((a),(b))!=0) // => a!=b
#define CMPFLOATS_GT(a,b) (cmpFloats((a),(b))==-1) // => a>b
#define CMPFLOATS_LT(a,b) (cmpFloats((a),(b))==1) // => a<b
//#define CMPFLOATS_GTEQUAL(a,b) (cmpFloats((a),(b))!=1) // => a>=b
//#define CMPFLOATS_LTEQUAL(a,b) (cmpFloats((a),(b))!=-1) // => a<=b
#define CMPFLOATS_GTEQUAL(a,b) ((cmpFloats((a),(b))-1)&2) // => a>=b
#define CMPFLOATS_LTEQUAL(a,b) (cmpFloats((a),(b))>=0) // => a<=b
#define CMPFLOATS_NAN(a,b) (cmpFloats((a),(b))==-2) // => a==NaN || b==NaN
#define CMPDOUBLES_EQUAL(a,b) (cmpDoubles((a),(b))==0) // => a==b
#define CMPDOUBLES_UNEQUAL(a,b) (cmpDoubles((a),(b))!=0) // => a!=b
#define CMPDOUBLES_GT(a,b) (cmpDoubles((a),(b))==-1) // => a>b
#define CMPDOUBLES_LT(a,b) (cmpDoubles((a),(b))==1) // => a<b
//#define CMPDOUBLES_GTEQUAL(a,b) (cmpDoubles((a),(b))!=1) // => a>=b
//#define CMPDOUBLES_LTEQUAL(a,b) (cmpDoubles((a),(b))!=-1) // => a<=b
#define CMPDOUBLES_GTEQUAL(a,b) ((cmpDoubles((a),(b))-1)&2) // => a>=b
#define CMPDOUBLES_LTEQUAL(a,b) (cmpDoubles((a),(b))>=0) // => a<=b
#define CMPDOUBLES_NAN(a,b) (cmpDoubles((a),(b))==-2) // => a==NaN || b==NaN
#endif //INCLUDE_CMPFLOATS_H
Remarquez que j'ai mis des macros en commentaires (correspondant à <= et >=), qui on été remplacées par d'autres. En effet, ces macros ne sont plus valables si cmp… renvoie -2 (qui est le code pour NaN).
L'utilisation de ces macros est conseillée dans le cas d'un test « simple », c'est-à-dire avec un seul test ; par exemple :
En revanche, il vaut mieux éviter de les enchaîner pour traiter différentes possibilités (si a<b, faire machin, si a>b, faire truc...) le else est aussi à éviter (car il engloberait aussi le cas de NaN, ce qui dans la plupart des cas n'est pas voulu) :
instructions1;
if(CMPFLOATS_GT(a,b)) { // a>b
instructions2;
}
else if(CMPFLOATS_LT(a,b)) { // a<b
/* /!\ on appelle la fonction cmpFloats 2 fois */
instructions2b;
}
else // a==b
instructions2t; /* /!\ ce code est aussi exécuté dans le cas de NaN ! */
}
instructions3;
Il vaut mieux utiliser un switch dans ce cas, qui n'appelle la fonction qu'une seule fois tout en permettant un contrôle précis :
instructions1;
switch(cmpFloats(a,b)) {
case -1: // a>b
instructions2;
break;
case 0: // a==b
instructions2t;
break;
case 1: // a<b
instructions2b;
break;
default: break; // NaN
}
instructions3;
Autre exemple pour bien saisir l'utilisation du switch :
instructions1;
switch(cmpFloats(a,b)) {
case -1: // a>b
case 0: // a==b
instructions2; // ce code est donc exécuté si a>=b
break;
case 1: // a<b
instructions2b;
break;
default: break; // NaN
}
instructions3;
Fichier source
#include "cmpfloats.h"
/* valeur absolue d'un entier de 32 ou 64 bits */
uint32_t abs32(int32_t x) { return x<0? -x : x; }
uint64_t abs64(int64_t x) { return x<0? -x : x; }
int floatsAreEqual(float a, float b) {
/* vérification pour NaN : si l'un des deux nombres est NaN, alors on
retourne toujours faux */
if(isnan(a) || isnan(b))
return 0;
/* vérification pour les infinis : si l'un des deux nombres est infini,
alors on ne retourne vrai que si les deux nombres sont strictement
égaux (tous les deux +inf ou -inf) */
if(isinf(a) || isinf(b))
return a==b;
int32_t aInt= INTREPOFFLOAT(a);
int32_t bInt= INTREPOFFLOAT(b);
if(aInt<0) aInt= 0x80000000 - aInt;
if(bInt<0) bInt= 0x80000000 - bInt;
return abs32( aInt - bInt ) <= MAXULPSFLOAT;
}
int doublesAreEqual(double a, double b) {
if(isnan(a) || isnan(b))
return 0;
if(isinf(a) || isinf(b))
return a==b;
int64_t aInt= INTREPOFDOUBLE(a);
int64_t bInt= INTREPOFDOUBLE(b);
if(aInt<0) aInt= 0x8000000000000000LL - aInt;
if(bInt<0) bInt= 0x8000000000000000LL - bInt;
return abs64( aInt - bInt ) <= MAXULPSDOUBLE;
}
int cmpFloats(float a, float b) {
if(isnan(a) || isnan(b))
return -2; // -2 si on a au moins un NaN
if(isinf(a) || isinf(b))
return (a<b)? -1 : (a>b)? 1 : 0; // gestion des infinis similaire à ci-dessous
int32_t aInt= INTREPOFFLOAT(a);
int32_t bInt= INTREPOFFLOAT(b);
if(aInt<0) aInt= 0x80000000 - aInt;
if(bInt<0) bInt= 0x80000000 - bInt;
return (abs32(aInt-bInt) <= MAXULPSFLOAT)? 0 // 0 si les nombres sont égaux
: (aInt<bInt)? 1 // 1 si a<b
: -1; // -1 si a>b
}
int cmpDoubles(double a, double b) {
if(isnan(a) || isnan(b))
return -2;
if(isinf(a) || isinf(b))
return (a<b)? -1 : (a>b)? 1 : 0;
int64_t aInt= INTREPOFDOUBLE(a);
int64_t bInt= INTREPOFDOUBLE(b);
if(aInt<0) aInt= 0x8000000000000000LL - aInt;
if(bInt<0) bInt= 0x8000000000000000LL - bInt;
return (abs64(aInt-bInt) <= MAXULPSDOUBLE)? 0
: (aInt<bInt)? 1
: -1;
}
Ce code est à compiler en C99.
Si vous programmez en C++, pourquoi ne pas surcharger les opérateurs de comparaison ? Cela vous simplifiera la vie (toutefois, vous risquerez alors, à la longue, d'oublier que vous avez fait quelque chose pour comparer tranquillement des flottants, et un jour ça ne marchera plus car vous n'aurez plus inclus votre petit header magique.) :-°
Rassurez-vous, si vous êtes fatigués, vous pouvez passer cette partie. Elle se destine aux petits curieux qui voudraient aller plus loin pour savoir plus précisément quelle relation entretient IEEE 754 vis à vis de la norme C, et comment déterminer si le compilateur suit bien les formats IEEE 754 ou pas. Car en C, il y a foule de gourous barbus qui se cramponnent à la norme comme une huître à son rocher, la citent comme un texte sacré, et viennent hurler à l’hérésie au moindre bout de code non « portable ». Et ils ont bien raison.
IEEE 754 et la norme C
La norme C90 était très floue sur ce sujet, et n'imposait ni ne privilégiait aucun format pour les nombres à virgule flottante. Le C99 a changé cela. En effet, la norme C99 (alias ISO/IEC 9899:TC3, téléchargeable ici en PDF) introduit le support de la norme IEEE 754.
Voici un extrait le montrant (issu de la liste des changements majeurs depuis le C90) :
Citation : ISO/IEC 9899:TC3 — Foreword (§5, p. xi-xii)
This second edition cancels and replaces the first edition, ISO/IEC 9899:1990 […]. Major changes from the previous edition include: […] — IEC 60559 (also known as IEC 559 or IEEE arithmetic) support […]
Quoi ? C'est quoi IEC 60559 ? Encore une nouvelle norme au nom tordu !
Oulala, pas de panique ! IEC 60559, c'est juste un autre nom de IEEE 754.
Cette norme est donc supportée par le langage C depuis sa version C99. Attention ! Supporté ne veut pas dire imposé. Les compilateurs ne sont pas obligés d'adopter les formats IEEE 754. C'est juste que s'ils le font, ils doivent suivre les règles de support spécifiées par la norme C99.
Ce passage le montre clairement :
Citation : ISO/IEC 9899:TC3 — 6.2.6: Representation of types — General (§1, p.37)
The representations of all types are unspecified except as stated in this subclause. […]
Cela signifie que la représentation de n'importe quel type (et pas seulement les flottants) est inconnue ; elle reste aux choix du compilateur.
Certains compilateurs peuvent supporter plusieurs formats ; dans ce cas, vous devrez spécifier lequel utiliser avec des arguments (sauf si vous voulez garder le format par défaut). GCC, pour sa part, implémente IEEE 754 par défaut, ses utilisateurs peuvent donc dormir sur leurs deux oreilles. :)
Mais quelles sont les règles de support de IEEE 754 selon le C99 ?
La norme C99 comporte une annexe (l'annexe F) dédiée aux nombres flottants, où se trouve la réponse à cette question. En voici le début :
This annex specifies C language support for the IEC 60559 floating-point standard. […] An implementation that defines __STDC_IEC_559__ shall conform to the specifications in this annex. […]
F.2 Types
The C floating types match the IEC 60559 formats as follows: — The float type matches the IEC 60559 single format. — The double type matches the IEC 60559 double format. — The long double type matches an IEC 60559 extended format, else a non-IEC 60559 extended format, else the IEC 60559 double format. Any non-IEC 60559 extended format used for the long double type shall have more precision than IEC 60559 double and at least the range of IEC 60559 double. Recommended practice The long double type should match an IEC 60559 extended format.
[…]
This annex specifies C language support for the IEC 60559 floating-point standard. […] An implementation that defines __STDC_IEC_559__ shall conform to the specifications in this annex. […]
F.2 Types
The C floating types match the IEC 60559 formats as follows: — The float type matches the IEC 60559 single format. — The double type matches the IEC 60559 double format. — The long double type matches an IEC 60559 extended format, else a non-IEC 60559 extended format, else the IEC 60559 double format. Any non-IEC 60559 extended format used for the long double type shall have more precision than IEC 60559 double and at least the range of IEC 60559 double. Recommended practice The long double type should match an IEC 60559 extended format.
[…]
The C floating types match the IEC 60559 formats as follows: — The float type matches the IEC 60559 single format. — The double type matches the IEC 60559 double format. — The long double type matches an IEC 60559 extended format, else a non-IEC 60559 extended format, else the IEC 60559 double format. Any non-IEC 60559 extended format used for the long double type shall have more precision than IEC 60559 double and at least the range of IEC 60559 double. Recommended practice The long double type should match an IEC 60559 extended format.
[…]
La deuxième partie dit que le type float du langage C doit correspondre au format simple précision (32 bits) de IEC 60559 (alias IEEE 754), etc., etc. Il est aussi question du type long double, dont j'ai peu parlé dans ce tutoriel ; sachez qu'en C, son format est moins bien défini, mais qu'il correspond souvent au format de double précision étendue de IEEE 754 (dont je n'ai pas parlé non plus), ou alors au format de double précision tout court (comme un double).
Je ne parlerai pas de la suite de cette annexe, vous pouvez la lire si vous voulez (vous êtes grands). Elle décrit notamment le comportement des opérations sur les flottants.
Enfin, sachez que :
Citation : Taurre
un système peut visiblement encoder les nombres flottants suivant le format défini par la norme IEEE 754, sans pour autant remplir toutes les conditions de l'annexe F de la norme C99 (cf ce sujet).
Les conditions en questions sont surtout des détails du comportement des calculs. Dans le cadre de ce tutoriel, qui s'est surtout focalisé sur les formats de représentation des flottants, ça ne devrait pas poser trop de problèmes.
Le non-respect partiel de la norme IEEE 754 peut aussi être le fait d'options du compilateur. Par exemple, l'option d'optimisation -ffast-math de GCC améliore les performances en accélérant les calculs sur les nombres flottants, mais enfreint certaines règles de IEEE 754.
Je reviens sur l'introduction, elle contient quelque chose d'intéressant. Il est dit que si la macro __STDC_IEC_559__ est définie, alors c'est le format IEEE 754 qui est utilisé. Cela peut vous être utile pour faire des tests ou adapter votre code. ;) Cependant, le contraire n'est pas vrai ! Vous pouvez parfaitement avoir une implémentation qui suit IEEE 754 mais qui ne définit pas cette constante. Cela semble être le cas de GCC sous Windows (portage MinGW par exemple), car GCC laisse cette définition aux headers du système ; or, ceux de Windows ne définissent pas __STDC_IEC_559__, en partie parce qu'il y aurait un risque d'incompatibilité entre GCC et la bibliothèque C de Windows.
En pratique : savoir si l'implémentation utilise IEEE 754
Puisqu'on ne peut pas compter sur la constante __STDC_IEC_559__ pour nous renseigner, il faut trouver un autre moyen de déterminer si oui ou non on travaille avec IEEE 754.
Pour cela, le meilleur moyen reste de se renseigner auprès de votre compilateur favori et/ou de votre plateforme cible.
Toutefois, si vous tenez vraiment à faire cette vérification avec du code, je peux vous offrir des pistes…
dynamiquement (c'est-à-dire au moment de l'exécution de votre programme) : Vous pouvez par exemple déclarer un certain nombre de variables de type à virgule flottante, puis vérifier que leur représentation mémoire correspond à celle attendue en se basant sur IEEE 754. Il faudrait effectuer cette série de tests pour les différents types de nombres (zéros, dénormalisés, normalisés, infinis, NaN). Un tel code ne serait pas infaillible (on peut très bien imaginer des formats ressemblant à IEEE 754, qui passeraient avec succès tous les tests) mais il permet d'éliminer certains formats.
L'inconvénient est que du code inutile est intégré à l'exécutable, et que l'on perd du temps à chaque exécution du programme lorsqu'on effectue ces vérifications. À éviter en pratique, donc. D'un point de vue technique, cela reste cependant un bon exercice. :ange:
statiquement (c'est-à-dire lors de la compilation) : Pour cela, il faut vous appuyer sur votre ami le préprocesseur. Sans détailler, vous pouvez tester la valeur des macros définies dans le header <float.h> du C99 ; celles-ci caractérisent l'implémentation des nombres flottants : précision, exposants minimum et maximum, valeurs minimales et maximales… Tout cela en 3 variantes pour chacun des 3 types à virgule flottante du C.
Cette approche présente l'avantage de ne garder que le code nécessaire lors de la compilation et de ne pas faire cette vérification à l'exécution. Mais avouez que c'est fichtrement moins rigolo.
L'avantage est que le bon fonctionnement du code serait indépendant du compilateur utilisé, facilitant ainsi les échanges de code.
Notez toutefois que les propositions ci-dessus vérifient la représentation en mémoire, mais pas les différentes opérations sur les flottants.
Voilà, ce cours touche à sa fin ! Il a été très théorique, j'espère que vous avez digéré. Vous savez maintenant comment vous servir des nombres à virgule en C, et comment ils fonctionnent sous le capot. On a aussi vu les difficultés de leur utilisation, et comment les contourner.
J'espère que vous avez apprécié le voyage, et bon code ! Faites-nous de beaux programmes mathématiques, je compte sur vous. :D
Si vous voulez aller encore plus loin, je ne peux que vous conseiller de lire ce tutoriel qui décrit comment sont gérés les nombres flottants au niveau matériel (le processeur).
Sources :
articles de Wikipédia : virgule flottante, IEEE 754 (n'hésitez pas à aller sur les articles anglais qui sont bien plus complets) ;
pages du manuel de la lib GNU C concernant les flottants (concepts, constantes fournies par <float.h>, exemple pour IEEE 754) : floating type macros(en) ;
site très pratique permettant de calculer la représentation en mémoire d'un nombre à virgule et l'inverse, pour les deux formats principaux de IEEE 754 (32 et 64 bits) : IEEE-754 Analysis(en).